
来源: 表变量与临时表的优缺点_Gordennizaicunzai的博客-CSDN博客
表变量:
DECLARE @tb table(id int identity(1,1), name varchar(100))
INSERT @tbSELECT id, name FROM mytable WHERE name like ‘zhang%’
临时表:
SELECT name, address
INTO #ta FROM mytable
WHERE name like ‘zhang%’(if exists (select * from tempdb.dbo.sysobjects where id = object_id(N’tempdb..#ta’) and type=’U’)
drop table #ta)
表变量和临时表的比较:
- 临时表是利用了硬盘(tempdb数据库) ,表名变量是占用内存,因此小数据量当然是内存中的表变量更快。当大数据量时,就不能用表变量了,太耗内存了。大数据量时适合用临时表。
- 表变量缺省放在内存,速度快,所以在触发器,存储过程里如果数据量不大,应该用表变量。
- 临时表缺省使用硬盘,一般来说速度比较慢,那是不是就不用临时表呢?也不是,在数据量比较大的时候,如果使用表变量,会把内存耗尽,然后使用 TEMPDB的空间,这样主要还是使用硬盘空间,但同时把内存基本耗尽,增加了内存调入调出的机会,反而降低速度。这种情况建议先给TEMPDB一次分配合适的空间,然后使用临时表。
- 临时表相对而言表变量主要是多了I/O时间,但少了对内存资源的占用。数据量较大的时候,由于对内存资源的消耗较少,使用临时表比表变量有更好的性能。
- 建议:触发器、自定义函数用表变量;存储过程看情况,大部分用表变量;特殊的应用,大数据量的场合用临时表。
- 表变量有明确的作用域,在定义表变量的函数、存储过程或批处理结束时,会自动清除表变量。
- 在存储过程中使用表变量与使用临时表相比,减少了存储过程的重新编译量。
- 涉及表变量的事务只在表变量更新期间存在。这样就减少了表变量对锁定和记录资源的需求。
- 表变量需要事先知道表结构,普通临时表,只在当前会话中可用与表变量相同into一下就可以了,方便;全局临时表:可在多个会话中使用存在于temp中需显示的drop。(不知道表结构情况下临时表方便一些)
- 全局临时表的功能是表变量没法达到的。
- 表变量不必删除,也就不会有命名冲突,临时表特别是全局临时表用的时候必须解决命名冲突。
- 应避免频繁创建和删除临时表,减少系统表资源的消耗。
- 在新建临时表时,如果一次性插入数据量很大,那么可以使用select into代替create table,避免log,提高速度;如果数据量不大,为了缓和系统表的资源,建议先create table,然后insert。
- 如果临时表的数据量较大,需要建立索引,那么应该将创建临时表和建立索引的过程放在单独一个子存储过程中,这样才能保证系统能够很好的使用到该临时表的索引。
- 如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先truncate table,然后drop table,这样可以避免系统表的较长时间锁定。
- 慎用大的临时表与其他大表的连接查询和修改,减低系统表负担,因为这种操作会在一条语句中多次使用tempdb的系统表。
解答 1:
与临时表相比,表变量具有下列优点:| • | 如 SQL Server 联机丛书“表”(Table) 一文中所述,表变量(如局部变量)具有明确定义的范围,在该范围结束时会自动清除这些表变量。 |
| • | 与临时表相比,表变量导致存储过程的重新编译更少。 |
| • | 涉及表变量的事务仅维持表变量上更新的持续时间。因此,使用表变量时,需要锁定和记录资源的情况更少。因为表变量具有有限的范围并且不是持久性数据库的一部分,所以事务回滚并不影响它们。 |
问题 2:如果说使用表变量比使用临时表导致存储过程的重新编译更少,这意味着什么?
解答 2:下面的文章讨论了重新编译存储过程的一些原因:
“由于某些临时表操作引起的重新编译”一节还列出了为避免一些问题(例如使用临时表导致重新编译)而需要满足的一些要求。这些限制不适用于表变量。
表变量完全独立于创建这些表变量的批,因此,当执行 CREATE 或 ALTER 语句时,不会发生“重新解析”,而在使用临时表时可能会发生“重新解析”。临时表需要此“重新解析”,以便从嵌套存储过程引用该表。表变量完全避免了此问题,因此存储过程可以使用已编译的计划,从而节省了处理存储过程的资源。
问题 3:表变量有哪些缺陷?
解答 3:与临时表相比,它存在下列缺陷:
| • | 在表变量上不能创建非聚集索引(为 PRIMARY 或 UNIQUE 约束创建的系统索引除外)。与具有非聚集索引的临时表相比,这可能会影响查询性能。 |
| • | 表变量不像临时表那样可以维护统计信息。在表变量上,不能通过自动创建或使用 CREATE STATISTICS 语句来创建统计信息。因此,在大表上进行复杂查询时,缺少统计信息可能会妨碍优化器确定查询的最佳计划,从而影响该查询的性能。 |
| • | 在初始 DECLARE 语句后不能更改表定义。 |
| • | 表变量不能在 INSERT EXEC 或 SELECT INTO 语句中使用。 |
| • | 表类型声明中的检查约束、默认值以及计算所得的列不能调用用户定义的函数。 |
| • | 如果表变量是在 EXEC 语句或 sp_executeSQL 存储过程外创建的,则不能使用 EXEC 语句或sp_executeSQL 存储过程来运行引用该表变量的动态 SQL Server 查询。由于表变量只能在它们的本地作用域中引用,因此 EXEC 语句和 sp_executesql 存储过程将在表变量的作用域之外。但是,您可以在 EXEC 语句或 sp_executesql 存储过程内创建表变量并执行所有处理,因为这样表变量本地作用域将位于 EXEC 语句或 sp_executesql 存储过程中。 |
问题 4:与临时表或永久表相比,表变量的仅存在于内存中的结构保证了更好的性能,是否因为它们是在驻留在物理磁盘上的数据库中维护的?
解答 4:表变量不是仅存在于内存中的结构。由于表变量可能保留的数据较多,内存中容纳不下,因此它必须在磁盘上有一个位置来存储数据。与临时表类似,表变量是在 tempdb 数据库中创建的。如果有足够的内存,则表变量和临时表都在内存(数据缓存)中创建和处理。
问题 5:必须使用表变量来代替临时表吗?
解答 5:答案取决于以下三个因素:
| • | 插入到表中的行数。 |
| • | 从中保存查询的重新编译的次数。 |
| • | 查询类型及其对性能的指数和统计信息的依赖性。 |
在某些情况下,可将一个具有临时表的存储过程拆分为多个较小的存储过程,以便在较小的单元上进行重新编译。
通常情况下,应尽量使用表变量,除非数据量非常大并且需要重复使用表。在这种情况下,可以在临时表上创建索引以提高查询性能。但是,各种方案可能互不相同。Microsoft 建议您做一个测试,来验证表变量对于特定的查询或存储过程是否比临时表更有效。
一直以来大家对临时表与表变量的孰优孰劣争论颇多,一些技术群里的朋友甚至认为表变量几乎一无是处,比如无统计信息,不支持事务等等.但事实并非如此.这里我就临时表与表变量做个对比,对于大多数人不理解或是有歧义的地方进行详细说明.
注:这里只讨论一般临时表,对全局临时表不做阐述.
生命周期
临时表:会话中,proc中,或使用显式drop
表变量:batch中
这里用简单的code说明表变量作用域

DECLARE @t TABLE(i int) ----定义表变量@t SELECT *FROM @t -----访问OK insert into @t select 1 -----插入数据OK select * from @t -------访问OK go -------结束批处理 select * from @t -------不在作用域出错
注意:虽然说sqlserver在定义表变量完成前不允许你使用定义的变量.但注意下面情况仍然可正常运行!
if 'a'='b' begin DECLARE @t TABLE(i int) end SELECT *FROM @t -----仍然可以访问!
日志机制
临时表与表变量都会记录在tempdb中记录日志
不同的是临时表的活动日志在事务完成前是不能截断的.
这里应注意的是由于表变量不支持truncate,所以完全清空对象结果集时临时表有明显优势,而表变量只能delete
事务支持
临时表:支持
表变量:不支持
我们通过简单的实例加以说明
create table #t (i int) declare @t table(i int) BEGIN TRAN ttt insert into #t select 1 insert into @t select 1 SELECT * FROM #t ------returns 1 rows SELECT * FROM @t ------returns 1 rows ROLLBACK tran ttt SELECT * FROM #t -------no rows SELECT * FROM @t -------still 1 rows drop table #t ----no use drop @t in session
锁机制(select)
临时表 会对相关对象加IS(意向共享)锁
表变量 会对相关对象加SCH-S(架构共享)锁(相当于加了nolock hint)
可以看出虽说锁的影响范围不同,但由于作用域都只是会话或是batch中,临时表的IS锁虽说兼容性不如表变量的SCH-S但绝大多数情况基本无影响.
感兴趣的朋友可以用TF1200测试
索引支持
临时表 支持
表变量 条件支持(仅SQL2014)
没错,在sql2014中你可以在创建表的同时创建索引 图1-1
注:在sql2014之前表变量只支持创建一个默认的唯一性约束 code
DECLARE @t TABLE
(
col1 int index inx_1 CLUSTERED,
col2 int index index_2 NONCLUSTERED,
index index_3 NONCLUSTERED(col1,col2)
)

图1-1
用户自定义函数(UDFs)
临时表 不支持作为UDF的结果集返回
表变量 支持作为UDF的结果集返回
注:当表变量作为UDF的结果集返回时分为TVF(Table-Valued Function),TVP(Table-Valued Parameters)两种类型,只有TVF支持plan cache
如图1-2 Code
CREATE FUNCTION TVP_Customers (@cust nvarchar(10))
RETURNS TABLE
AS
RETURN
(SELECT RowNum, CustomerID, OrderDate, ShipCountry
FROM BigOrders
WHERE CustomerID = @cust);
GO
CREATE FUNCTION TVF_Customers (@cust nvarchar(10))
RETURNS @T TABLE (RowNum int, CustomerID nchar(10), OrderDate date,
ShipCountry nvarchar(30))
AS
BEGIN
INSERT INTO @T
SELECT RowNum, CustomerID, OrderDate, ShipCountry
FROM BigOrders
WHERE CustomerID = @cust
RETURN
END;
DBCC FREEPROCCACHE
GO
SELECT * FROM TVF_Customers('CENTC');
GO
SELECT * FROM TVP_Customers('CENTC');
GO
SELECT * FROM TVF_Customers('SAVEA');
GO
SELECT * FROM TVP_Customers('SAVEA');
GO
select b.text,a.execution_count,a.* from sys.dm_exec_query_stats a
cross apply sys.dm_exec_sql_text(a.sql_handle) b
where b.text like '%_Customers%'
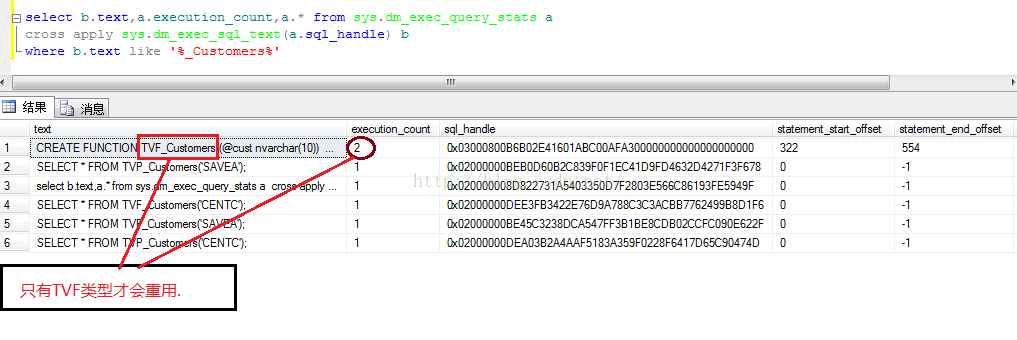
图1-2
其它方面
表变量不支持select into,alter,truncate,dbcc等
表变量不支持table hint 如(force seek)
执行计划预估
我想这里可能是引起使用何种方式争论比较突出的地方,由于表变量没有统计信息,无法添加索引等使得大家对其在执行计划中的性能表现嗤之以鼻,但实际情况呢?我们需要深入分析.
关于临时表的预估这里我就不做介绍了,主要对表变量的预估做详细阐述.
表变量在sql2000引入的一个原因就是为了在一些执行过程中减少重编译.以获得更好的性能.当然带来好处的同时也会带来一定弊端.由于其不涉及重编译,优化器其实并不知道表变量中的具体行数,此时他采取了保守的预估方式:预估行数为1行.如图2-1
Code
declare @t table (i int) select * from @t-----此时0行预估行数为1行 insert into @t select 1 select * from @t-----此时1行,预估行数仍为1行 insert into @t values (2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(14),(15),(16),(17),(18),(19),(20) select * from @t ----此时19行,预估行数仍为1行 --....无论实际@t中有多少行,由于没有重编译,预估均为1行
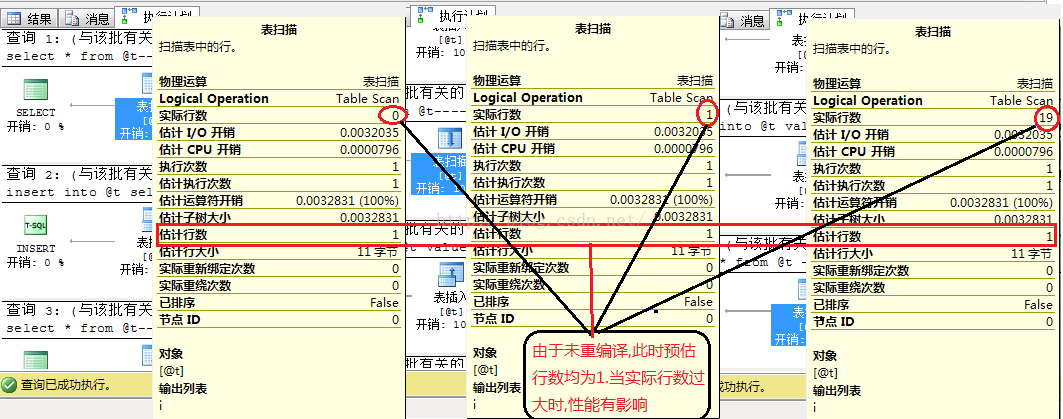
图2-1
所以当我们加上重编译的的操作,此时优化器就知道了表变量的具体行数.如图2-2
Code
declare @t table (i int) select * from @t option(recompile)-----此时0行预估行数为1行 insert into @t select 1 select * from @t option(recompile)-----此时1行,预估行数为1行 insert into @t values (2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(14),(15),(16),(17),(18),(19),(20) select * from @t option(recompile)----此时19行,预估行数为19行 --....当加入重编译hint时,优化器就知道的表变量的行数.
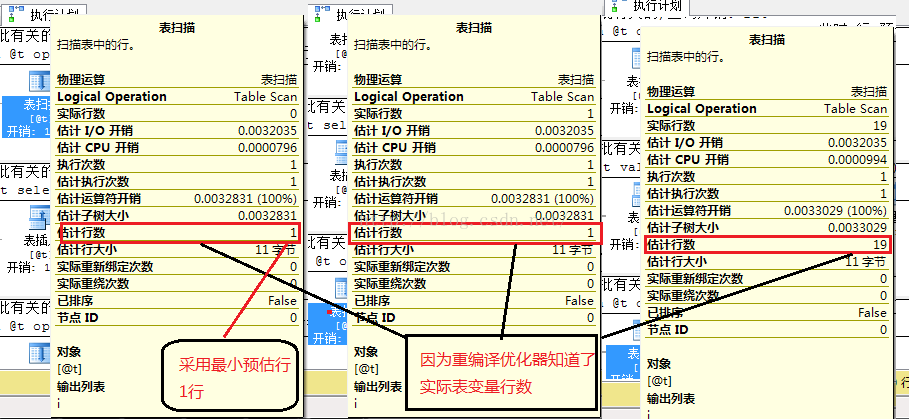
图2-2
至此,我们可以看到优化器知道了表变量中的行数.这样在表变量扫描的过程中,尤其针对数据量较大的情形,不会因为预估总是1而引起一些问题.
如果你刚知道这里的预估原理,现有的代码都加上重编译那工作量可想而知了..这里介绍一个新的跟踪标记,Trace Flag 2453.
TF2453可以一定程度上替代重编译Hint,但只是在非简单计划(trivial plans)的情形下
注:TF2453只在sql2012 SP2和SQL2014中的补丁中起作用
表变量谓词预估
由于表变量木有统计信息,在优化器知道整体行数的前提下将会根据谓词的情形
采用不同的规则"猜"来进行预估.
注:这里有些规则笔者未找到微软相应的算法文档,经过自己根据数据推算得出.
看到这里的朋友请为我点个赞J(很长时间推算得出.可能数学忘得差不多了)
注:由于检索对象本身及为变量,谓词为变量,或是常数无影响
常见谓词下预估算法:
a ">", "<" 运算符 按照表变量数据量的30%进行预估
b "like" 运算符 按照表变量数据量的10%进行预估
c "=" 运算符 按照表变量数据量的0.75次方预估
实例如图2-3
code
declare @i int set @i=13 DECLARE @T TABLE(I INT); INSERT INTO @T VALUES (0),(1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(14),(15),(16),(17),(18),(19),(20) ------表变量中存在个数字 select * from @T where I < 1 option(recompile) ------20*30% 预估数为6 select * from @T where I > @i option(recompile) --------20*30%预估数为6 select * from @T where I like @i option(recompile) --------20*10% 预估数为2 select * from @T where I like 1 option(recompile) --------20*10 预估数为2 select * from @T where I = @i option(recompile) --------POWER(20.00000,0.75) 预估数为9.45742 select * from @T where I = 1 option(recompile) --------POWER(20.00000,0.75) 预估数为9.45742 insert into @T select DatabaseLogID from AdventureWorks2008R2.dbo.DatabaseLog------insert new records select * from @T option(recompile) ------------此时数据为行 select * from @T where I = 1 option(recompile)--------------------POWER(1617.00000,0.75) 预估数为254.99550
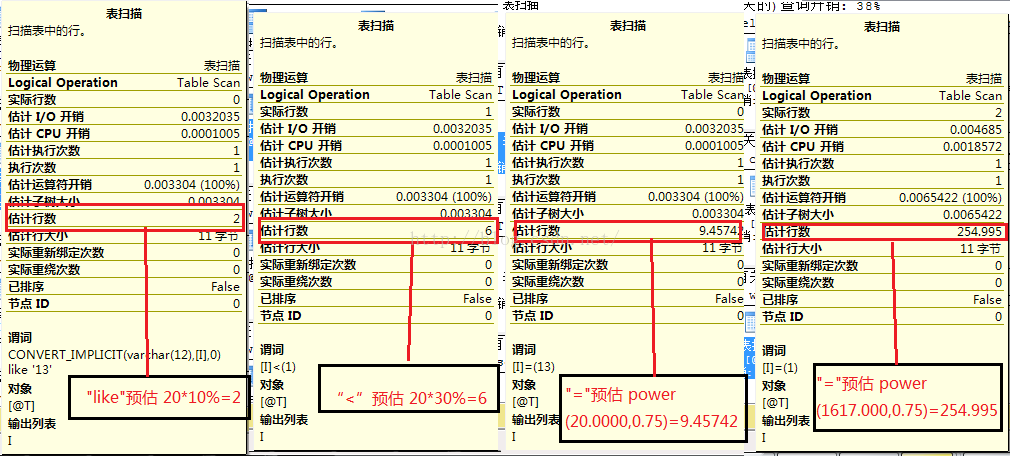
图2-3
可以看出根据不同的谓词优化器会采用不同的预估方式,虽然它不如统计信息下的密度,直方图等来的精确(尤其是等值预估,在数据量巨大的情形下,其效果可能接近统计信息),但在了解数据的前提下如果适合表变量我们还是可以大胆使用的.
Tempdb竞争
tempdb的竞争本身涵盖的知识面比较大,这里我们只讨论临时表与表变量的孰优孰劣.
通过前面的介绍我们知道临时表是支持事务的,而表变量时不支持的.正因如此很多人放弃了表变量的使用.但任何事情都有两方面,支持就一定好吗?由于临时表对事务的支持,在高并发的情形中可能正因为其事务的支持造成系统表锁,总而影响并发.
我们通过一个简单的实例来说明
日常管理中,我发现很多开发人员在使用临时表时采用select * into #t from …的语法,这样的写法如果数据量稍大,将会造成事务持有系统表锁的时间变长,从而影响并发,吞吐.我们通过一个简单的实例说明.如图3-1
Code 我们通过sqlquerystress模拟并发
----SSMS测试数据 Use tempdb create table t ( id int identity,str1 char(8000))----more pages for many records insert into t select 'a' go 100 ----sqlquerystress select * into #t from t----57s ----sqlquerystress declare @t table ( id int,str1 char(8000)) insert into @t select * from t-----1s
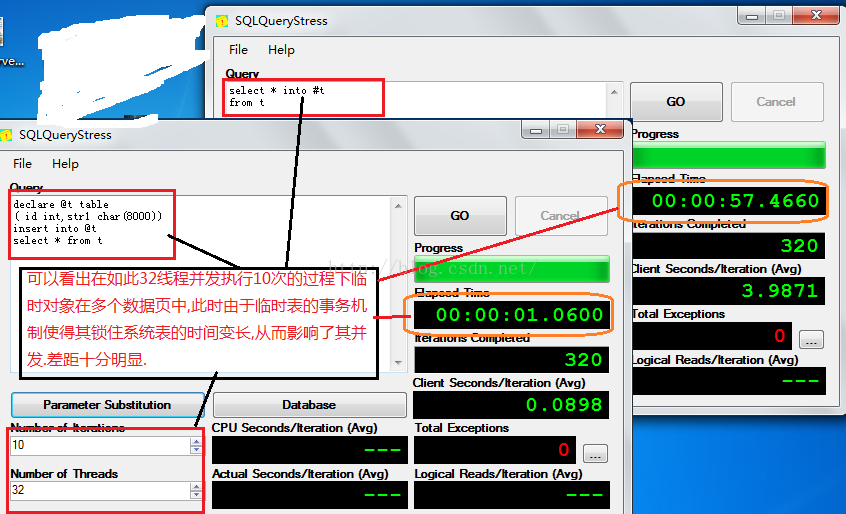
图3-1
通过图3-1可以看出上述情形中临时表简直不堪重负.临时表与表变量到底该如何应用不是看谁比谁的优点多,应视具体情形而定
结语:借用火影忍者中宇智波. 鼬的一句名言:”任何术都是有缺陷的” 同样,在数据库的世界里没有哪项技术是完美无缺的.根据实际的场景,情形,选择合理的实现方式才是我们的初衷.
转自:http://www.cnblogs.com/shanksgao/p/3988089.html


