
Introduction
“It’s been months since you and your team have developed and deployed a site successfully in the internet. You have a pretty satisfied client so far as the site was able to attract thousands of users to register and use the site within a small amount of time. Your client, management, team and you – everybody is happy.
Life is not a bed of roses. As the number of users in the site was started growing at a rapid rate day by day, problem started occurring. E-mails started to arrive from the client complaining that the site is performing too slowly (Some of them ware angry mails). The client claimed that, they started losing users.
You started investigating the application. Soon you discovered that, the production database was performing extremely slowly when application was trying to access/update data. Looking into the database you found that the database tables have grown large in size and some of them were containing hundreds of thousands of rows. The testing team performed a test on the production site and they found that the order submission process was taking 5 long minutes to complete whereas it used to take only 2/3 seconds to complete in the test site before production launch”.
This is the same old story for thousands of application projects developed worldwide. Almost every developer including me has taken part in the story sometime in his/her development life. So, I know why such situation took place, and, I can tell you what to do to overcome this.
Let’s face it. If you are part of this story, you must have not written the data access routines in your application in the best possible way and it’s time to optimize those now. I want to help you doing this by sharing my data access optimization experiences and findings with you in this series of articles. I just hope, this might enable you to optimize your data access routines in the existing systems, or, to develop the data access routines in the optimized way in your future projects.
Scope
Please note that, the primary focus of these series of articles is “Data access performance optimization in transactional (OLTP) SQL Server databases”. But, most of the optimization techniques are roughly the same for other database platforms.
Also, the optimization techniques I am going to discuss are applicable for the software application developers only. That is, as a developer, I’ll focus on the issues that you need to follow to make sure that you have done everything that you could do to optimize the data access codes you have written or you are going to write in future. The Database Administrators (DBA) also has great roles to play in optimizing and tuning the database performance. But, optimization scopes that fall into a DBA’s area are out of scope for these articles.
We have a database to optimize, let’s start it!
When a database based application performs slowly, there is a 90% probability that, the data access routines of that application are not optimized, or, not written in the best possible way. So, you need to review and optimize your data access/manipulation routines for improving the overall application’s performance.
So, let us start our optimization mission in a step-by-step process:
Step1: Apply proper indexing in the table columns in the database
Well, some could argue whether implementing proper indexing should be the first step in performance optimization process in the database. But, I would prefer applying indexing properly in the database in the first place, because of following two reasons:
- This will allow you to improve the best possible performance in the quickest amount of time in a production system.
- Applying/creating indexes in the database will not require you to do any application modification and thus will not require any build and deployment.
Of course, this quick performance improvement can be achieved if you find that, indexing is not properly done in the current database. However, if indexing is already done, I would still recommend you to go through this step.
What is indexing?
I believe, you know what indexing is. But, I’ve seen many people being unclear on this. So, let us try to understand indexing once again. Lets us read a small story.
Long ago there was a big library in an ancient city. It had thousands of books, but, the books ware not arranged in any order in the book shelves. So, each time a person asked for a book to the librarian, the librarian had no way but to check every book to find the required book that the person wants. Finding the desired book used to take hours for the librarian, and, most of the times the persons who ask for books had to wait for a long time.
[Hm..seems like a table that has no primary key. So, when any data is searched in the table, the database engine has to scan through the entire table to find the corresponding row, which performs very slow.]
Life was getting miserable for that librarian as the number of books and persons asking for books were increasing day by day. Then one day, a wise guy came to the library, and, seeing the librarian’s measurable life, he advised him to number each book and arrange these in the book shelves according to their numbers. “What benefit would I get?” Asked the librarian. The wise guy answered, “well, now if somebody gives you a book number and ask for that book, you will be able to find the shelves quickly that contains the book’s number, and, within that shelve, you can find that book very quickly as these are arranged according to their number”.
[Numbering the books sounds like creating primary key in a database table. When you create a primary key in a table, a clustered index tree is created and all data pages containing the table rows are physically sorted in the file system according to their primary key values. Each data page contains rows which are also sorted within the data page according to their primary key values. So, each time you ask any row from the table, the database server finds the corresponding data page first using the clustered index tree (Like, finding the book shelve first) and then finds the desired row within the data page that contains the primary key value (Like, finding the book within the shelve)]
“This is what I exactly need!” The excited librarian instantly starts numbering the books and arranging these across different book shelves. He spent a whole day to do this arrangement, but, at the end of the day, he tested and found that that a book now could be found using the number within no time at all! The librarian was extremely happy.
[That’s exactly what happens when you create a primary key in a table. Internally, a clustered index tree is created, and, the data pages are physically sorted within the data file according to the primary key values. As you can easily understand, only one clustered index can be created for a table as the data can be physically arranged only using one column value as the criteria (Primary key). It’s like the books can only be arranged using one criterion (Book number here)]
Wait! The problem was not completely solved yet. In the very next day, a person asked a book by the book’s name (He didn’t have the book’s number, so, all he had the book’s name). The poor librarian had no way but to scan all numbered book from 1 to N to find the one the person asked for. He found the book in the 67th shelves. It took 20 minutes for the librarian to find the book. Earlier, he used to take 2-3 hours to find a book when these were not arranged in the shelves, so, that’s an improvement still. But, comparing to the time to search a book using it’s number (30 seconds), this 20 minute seemed to be a very high amount of time to the librarian. So, he asked the wise man how to improve on this.
[This happens when you have a Product table where you have a primary key ProductID, but, you have no other index in the table. So, when a product is to be searched using the Product Name, the database engine has no way but to scan all physically sorted data pages in the file to find the desired named book]
The wise man told the librarian “Well, as you already have arranged your books using their serial numbers, you cannot re-arrange these. So, better create a catalog or index where you will have all the book’s names and their corresponding serial numbers. But, in this catalog, arrange the book names in their alphabetic number and group the book names using each alphabet so that, if any one wants to find a book named “Database Management System”, you just follow these steps to find the book
- Jump into the section “D” of your “Book name “catalog” and find the book name there
- Read the corresponding serial number of the book and find the book using the serial number (You already know how to do this)
“You are a genius! Exclaimed the librarian. Spending some hours he immediately created the “Book name” catalog and on a quick test he found that he only required 1 minute (30 seconds to find the book’s serial number in the “Book name” catalog and another 30 seconds to find the book using the serial number) to find a book using the book name.
The librarian thought that, people might ask for books using several other criteria like book name and/or author’s name etc. so, he created another similar catalog for author names and after creating these catalogs the librarian could find any book using the some common book finding criteria (Serial number, Book name, Author’s name) within a maximum 1 minute of time. The miseries of the librarian ended soon and lots of persons started gathering at the library for books as they could get the book really fast and the library became very popular.
The librarian started passing his life happily ever after. The story ends.
By this time, I am sure you have understood what indexes really are, why they are important and what their inner workings are. For example if we have a “Products” table, along with creating a clustered index (That is automatically created when creating the primary key in the table), we should create a non-clustered index on the ProductName column. If we do this, the database engine creates an index tree for the non-clustered index (Like, the “book name” catalog in the story) where the product names will be sorted within the index pages. Each index page will contain some range of product names along with their corresponding primary key values. So, when a Product is searched using the product name in the search criteria, the database engine will first seeks the non-clustered index tree for Product name to find the primary key value of the book. Once found, the database engine then searches the clustered index tree with the primary key to find the row for the actual book that is being searched.
Following is how an index tree looks like:
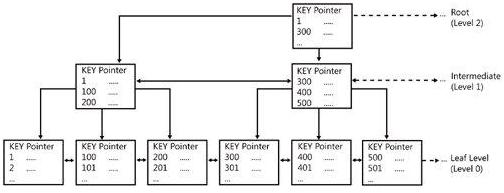
Figure : Index tree structure
This is called a B+ Tree (Balanced tree). The intermediate nodes contain range of values and direct the SQL engine where to go while searching for a specific index value in the tree starting from the root node. The leaf nodes are the nodes which contain the actual index values. If this is a clustered index tree, the leaf nodes are the physical data pages. If this is a non-clustered index tree, the leaf nodes contain index values along with clustered index keys (Which the database engine uses to find the corresponding row in the clustered index tree.
Usually, finding a desired value in the index tree and jumping to the actual row from there takes an extremely small amount of time for the database engine. So, indexing generally improves the data retrieval operations.
So, time to apply indexing in your database to retrieve results fast!
Follow these steps to ensure proper indexing in your database
Make sure that every table in your database has a primary key.
This will ensure that every table has a Clustered index created (And hence, the corresponding pages of the table are physically sorted in the disk according to the primary key field). So, any data retrieval operation from the table using primary key, or, any sorting operation on the primary key field or any range of primary key value specified in the where clause will retrieve data from the table very fast.
Create non-clustered indexes on columns which are:
- Frequently used in the search criteria
- Used to join other tables
- Used as foreign key fields
- Of having high selectivity (Column which returns a low percentage (0-5%) of rows from a total number of rows on a particular value)
- Used in the orDER BY clause
- Of type XML (Primary and secondary indexes need to be created. More on this in the coming articles)
Following is an example of an index creation command on a table:
Create INDEX
NCLIX_OrderDetails_ProductID ON
dbo.OrderDetails(ProductID)
Alternatively, you can use the SQL Server Management Studio to create index on the desired table
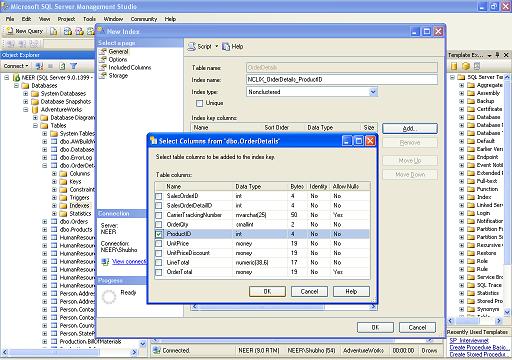
Figure : Creating index using SQL Server Management Studio
Step2 : Create appropriate covering indexes
So, you have created all appropriate indexes in your database, right? Suppose, in this process you have created an index on a foreign key column (ProductID) in the Sales(SelesID,SalesDate,SalesPersonID,ProductID,Qty) table. Now, assuming that, the ProductID column is a “Highly selective” column (Selects less than 5% of the total number of rows rows using any ProductID value in the search criteria) , any Select query that reads data from this table using the indexed column (ProductID) in the where clause should run fast, right?
Yes, it does, comparing to the situation where no index created on the foreign key column (ProductID) in which case, a full table scan (scanning all related pages in the table to retrieve desired data). But, still, there is further scope to improve this query.
Let’s assume that, the Sales table contains 10,000 rows, and, the following SQL selects 400 rows (4% of the total rows)
Select SalesDate, SalesPersonID FROM Sales Where ProductID = 112
Let’s try to understand how this SQL gets executed in the SQL execution engine
- The Sales table has a non-clustered index on ProductID column. So, it “seeks” the non-clustered index tree for finding the entry that contains ProductID=112
- The index page that contains the entry ProductID = 112 also contains the all Clustered index keys (All Primary key values, that is SalesIDs, that have ProductID = 112 assuming that primary key is already created in the Sales table)
- For each primary key (400 here), the SQL server engine “seeks” into the clustered index tree to find the actual row locations in the corresponding page.
- For each primary key, when found, the SQL server engine selects the SalesDate and SalesPersonID column values from the corresponding rows.
Please note that, in the above steps, for each of the primary key entries (400 here) for ProductID = 112, the SQL server engine has to search the clustered index tree (400 times here) to retrieve the additional columns (SalesDate, SalesPersonID) in the query.
It seems that, along with containing clustered index keys (Primary key values) if the non-clustered index page could also contain two other column values specified in the query (SalesDate, SalesPersonID), the SQL server engine would not have to perform the step 3 and step 4 in the above steps, and, thus, would be able to select the desired results even faster just by “seeking” into the non clustered index tree for ProductID column, and, reading all three mentioned column values directly from that index page.
Fortunately, there is a way to implement this feature. This is what is called “Covered index”. You create “Covered indexes” in table columns to specify what are the additional column values the index page should store along with the clustered index key values (primary keys). Following is the example of creating a covered index on the ProductID column in Sales table:
Create INDEX NCLIX_Sales_ProductID--Index name
ON dbo.Sales(ProductID)--Column on which index is to be created
INCLUDE(SalesDate, SalesPersonID)--Additional column values to include
Please note that, Covered index should be created including a few columns that are frequently used in the select queries. Including too many columns in the covered indexes would not give you too much benefit. Rather, doing this would require too much memory to store all the covered index column values resulting in over consumption of memory and slow performance.
Use Database Tuning Advisor’s help while creating covered index
We all know, when an SQL is issued, the optimizer in the SQL server engine dynamically generates different query plans based on:
- Volume of Data
- Statistics
- Index variation
- Parameter value in TSQL
- Load on server
That means, for a particular SQL, the execution plan generated in the production server may not be the same execution plan that is generated in the test server, even though, the table and index structure is the same. This also indicates that, an index created in the test server might boost some of your TSQL performance in the test application, but, creating the same index in the production database might not give you any performance benefit in the production application! Why? Well, because, the SQL execution plans in the test environment utilizes the newly created indexes and thus gives you better performance. But, the execution plans that are being generated in the production server might not use the newly created index at all for some reasons (For example, a non-clustered index column is not “highly” selective in the production server database, which is not the case in the test server database).
So, while creating indexes, we need to make sure that, the index would be utilized by the execution engine to produce faster result. But, how can we do this?
The answer is, we have to simulate the production server’s load in the test server, and then need to create appropriate indexes and test those. Only then, if the newly created indexes improves performance in the test environment, these will most likely to improve performance in the production environment.
Doing this should be hard, but, fortunately, we have some friendly tools to do this. Follow these instructions:
- Use SQL profiler to capture traces in the production server. Use the Tuning template (I know, it is advised not to use SQL profiler in the production database, but, sometimes you have to use it while diagnosing performance problem in the production). If you are not familiar with this tool, or, if you need to learn more about profiling and tracing using SQL profiler, read http://msdn.microsoft.com/en-us/library/ms181091.aspx.
- Use the trace file generated in the previous step to create a similar load in the test database server using the Database tuning advisor. Ask the Tuning advisor to give some advice (Index creation advice most of the cases). You are most likely to get good realistic (index creation) advice from the tuning advisor (Because, the Tuning advisor loaded the test database with the trace generated from the production database and then tried to generate best possible indexing suggestion) . Using the Tuning advisor tool, you can also create the indexes that it suggests. If you are not familiar with the Tuning advisor tool, or, if you need to learn more about using the Tuning advisor, read http://msdn.microsoft.com/en-us/library/ms166575.aspx.
Step3 : Defragment indexes if fragmentation occurs
OK, you created all appropriate indexes in your tables. or, may be, indexes are already there in your database tables. But, you might not still get the desired good performance according to your expectation.
There is a strong chance that, index fragmentation have occurred.
What is index fragmentation?
Index fragmentation is a situation where index pages split due to heavy insert, update, and delete operations on the tables in the database. If indexes have high fragmentation, either scanning/seeking the indexes takes much time or the indexes are not used at all (Resulting in table scan) while executing queries. So, data retrieval operations perform slow.
Two types of fragmentation can occur:
Internal Fragmentation: Occurs due to the data deletion/update operation in the index pages which ends up in distribution of data as sparse matrix in the index/data pages (create lots of empty rows in the pages). Also results in increase of index/data pages that increase query execution time.
External Fragmentation: Occurs due to the data insert/update operation in the index/data pages which ends up in page splitting and allocation of new index/data pages that are not contiguous in the file system. That reduces performance in determining query result where ranges are specified in the “where” clauses. Also, the database server cannot take advantage of the read-ahead operations as, the next related data pages are not guaranteed to be contiguous, rather, these next pages could be anywhere in the data file.
How to know whether index fragmentation occurred or not?
Execute the following SQL in your database (The following SQL will work in SQL Server 2005 or later databases. Replace the database name ‘AdventureWorks’ with the target database name in the following query):
Select object_name(dt.object_id) Tablename,si.name
IndexName,dt.avg_fragmentation_in_percent AS
ExternalFragmentation,dt.avg_page_space_used_in_percent AS
InternalFragmentation
FROM
(
Select object_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats (db_id('AdventureWorks'),null,null,null,'DETAILED'
)
Where index_id <> 0) AS dt INNER JOIN sys.indexes si ON si.object_id=dt.object_id
AND si.index_id=dt.index_id AND dt.avg_fragmentation_in_percent>10
AND dt.avg_page_space_used_in_percent<75 ORDER BY avg_fragmentation_in_percent DESC
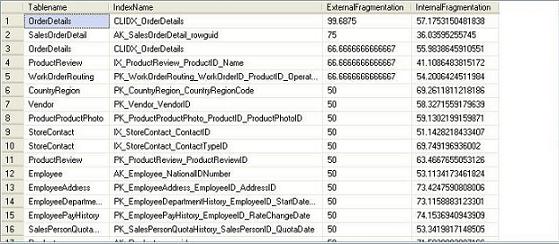
Figure : Index fragment information
Analyzing the result, you can determine where index fragmentation have occurred, using the following rules:
- ExternalFragmentation value > 10 indicates External fragmentation occurred for corresponding index
- InternalFragmentation value < 75 indicates Internal fragmentation occurred for corresponding index
How to defragment indexes?
You can do this in two ways:
- Reorganize fragmented indexes: Execute the following command to do this:
Alter INDEX ALL ON TableName REORGANIZE
- Rebuild indexes: Execute the following command to do this:
Alter INDEX ALL ON TableName REBUILD WITH (FILLFACTOR=90,ONLINE=ON)
You can also rebuild or reorganize individual indexes in the tables by using the index name instead of the ‘ALL’ keyword in the above queries. Alternatively, you can also use the SQL Server Management Studio to do index defragmentation.
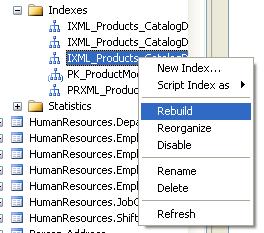
Figure : Rebuilding index using SQL Server Management Studio
When to reorganize and when to rebuild indexes?
You should “Reorganize” indexes when the External Fragmentation value for the corresponding index is in between 10-15 and Internal Fragmentation value is in between 60-75. Otherwise, you should rebuild indexes.
One important thing with index rebuilding is, while rebuilding indexes for a particular table, the entire table will be locked (Which does not occur in case of index reorganization). So, for a large table in the production database, this locking may not be desired, because, rebuilding indexes for that table might take hours to complete. Fortunately, in SQL Server 2005, there is a solution. You can use the ONLINE option as ON while rebuilding indexes for a table (See index rebuild command given above). This will rebuild the indexes for the table along with making the table available for transactions.
Last words
It's really tempting to create index on all eligible columns in your database tables. But, if you are working with a transactional database (An OLTP system where update operations take place most of the times), creating indexes on all eligible columns might not be desirable every time. In fact, creating heavy indexing on OLTP systems might reduce overall database performance (As most operations are update operations, updating data means updating indexes as well).
A rule of thumb can be suggested as follows: If you work on a transactional database, you should not create more than 5 indexes on the tables on an average. On the other hand, if you work on a Data warehouse application, you should be able to create up to 10 indexes on the tables on an average.
What's next?
Applying indexing properly in your database would enable you to increase performance a lot, in a quick amount of time. But there are lots of other things you should do to optimize your database, including some advance indexing features in the SQL Server database. These will be covered in the other optimization steps provided in the next articles.
Take a look at the next optimization steps in the article “Top 10 steps to optimize data access in SQL Server. Part II (Re-factor TSQLs and apply best practices)”. Have fun.
Introduction
Remember we ware in a mission? Our mission was to optimize the performance of an SQL Server database. We had an application that was built on top of that database. The application was working pretty fine while tested, but, soon after deployment at production, it started to perform slowly as the data volume was increased in the database. Within a very few months, the application started performing so slowly that, the poor developers (including me) had to start this mission to optimize the database and thus, optimize the application.
Please have a look at the previous article to know how it started and what did we do to start the optimization process.
Top 10 steps to optimize data access in SQL Server. part I (Use Indexing)
Well, in the first 3 steps (Discussed in the previous article), we had implemented indexing in our database. That was because; we had to do something that improves the database performance in a quick amount of time, with a least amount of effort. But, what if we wrote the data access codes in an inefficient way? What if we wrote the TSQLs poorly?
Applying indexing will obviously improve the data access performance, but, at the most basic level in any data access optimization process, you have to make sure that you have written your data access codes and TSQLs in the most efficient manner, applying the best practices.
So, in this article, we are going to focus on writing or refactoring the data access codes using the best practices. But, before we start playing the game, we need to prepare the ground first. So let’s do the groundwork at this very next step:
Step4: Move TSQL codes from application into the database server
I know you may not like this suggestion at all. You might have used an orM that does generate all the SQLs for you on the fly. or, you or your team might have a “principle” of keeping SQLs in your application codes (In the Data access layer methods). But, still, if you need to optimize the data access performance, or, if you need to troubleshoot a performance problem in your application, I would suggest you to move your SQL codes into your database server (Using Stored procedure, Views, Functions and Triggers) from your application. Why? Well, I do have some strong reasons for this recommendation:
- Moving the SQLs from application and implementing these using stored procedures/Views/Functions/Triggers will enable you to eliminate any duplicate SQLs in your application. This will also ensure re-usability of your TSQL codes.
- Implementing all TSQLs using the database objects will enable you to analyze the TSQLs more easily to find possible inefficient codes that are responsible for slow performance. Also, this will let you manage your TSQL codes from a central point.
- Doing this will also enable you to re-factor your TSQL codes to take advantage of some advanced indexing techniques (going to be discussed in later parts in this series of articles). Also, this will help you to write more “Set based” SQLs along with eliminating any “Procedural” SQLs that you might have already written in your application.
Despite the fact that indexing (In Step1 to Step3) will let you troubleshoot the performance problems in your application in a quick time (if properly done), following this step 4 might not give you a real performance boost instantly. But, this will mainly enable you to perform other subsequent optimization steps and apply different other techniques easily to further optimize your data access routines.
If you have used an orM (Say, NHibernate) to implement the data access routines in your application, you might find your application performing quite well in your development and test environment. But, if you face performance problem in a production system where lots of transactions take place each second, and where too many concurrent database connections are there, in order to optimize your application’s performance you might have to re-think with your orM based data access logics. It is possible to optimize an orM based data access routines, but, it is always true that if you implement your data access routines using the TSQL objects in your database, you have the maximum opportunity to optimize your database.
If you have come this far while trying to optimize your application’s data access performance, come on, convince your management and purchase some time to implement a TSQL object based data operational logic. I can promise you, spending one or two man-month doing this might save you a man-year in the long run!
OK, let’s assume that you have implemented your data operational routines using the TSQL objects in your database. So, having done this step, you are done with the “ground work” and ready to start playing. So, let’s move towards the most important step in our optimization adventure. We are going to re-factor our data access codes and apply the best practices.
Step5: Identify inefficient TSQLs, re-factor and apply best practices
No matter how good indexing you apply in your database, if you use poorly written data retrieval/access logic, you are bound to get slow performance.
We all want to write good codes, don’t we? While we write data access routines for a particular requirement, we really have lots of options to follow for implementing particular data access routines (And application’s business logics). But, most of the cases, we have to work in a team with members of different calibers, experience and ideologies. So, while at development, there are strong chances that our team members may write codes in different ways and some of them miss following the best practices. While writing codes, we all want to “get the job done” first (Most of the cases). But, while our codes run in production, we start to see the problems.
Time to re-factor those codes now. Time to implement the best practices in your codes.
I do have some SQL best practices for you that you can follow. But, I am sure that you already know most of them. Problem is, in reality, you just don’t implement these good stuffs in your code (Of course, you always have some good reasons for not doing so). But what happens, at the end of the day, your code runs slowly and your client becomes unhappy.
So, knowing the best practices is not enough at all. The most important part is, you have to make sure that you follow the best practices while writing TSQLs. This is the most important thing.
Some TSQL Best practices
Don’t use “Select*" in SQL Query
- Unnecessary columns may get fetched that adds expense to the data retrieval time.
- The Database engine cannot utilize the benefit of “Covered Index” (Discussed in the previous article), hence, query performs slowly.
Avoid unnecessary columns in Select list and unnecessary tables in join conditions
- Selecting unnecessary columns in select query adds overhead to the actual query, specially if the unnecessary columns are of LOB types.
- Including unnecessary tables in the join conditions forces the database engine to retrieve and fetch unnecessary data that and increase the query execution time.
Do not use the COUNT() aggregate in a subquery to do an existence check:
- Do not use
Select column_list FROM table Where 0 < (Select count(*) FROM table2 Where ..)
Instead, use
Select column_list FROM table Where EXISTS (Select * FROM table2 Where ...)
- When you use COUNT(), SQL Server does not know that you are doing an existence check. It counts all matching values, either by doing a table scan or by scanning the smallest nonclustered index.
- When you use EXISTS, SQL Server knows you are doing an existence check. When it finds the first matching value, it returns TRUE and stops looking. The same applies to using COUNT() instead of IN or ANY.
Try to avoid joining between two types of columns
- When joining between two columns of different data types, one of the columns must be converted to the type of the other. The column whose type is lower is the one that is converted.
- If you are joining tables with incompatible types, one of them can use an index, but the query optimizer cannot choose an index on the column that it converts. For example:
Select column_list FROM small_table, large_table Where
smalltable.float_column = large_table.int_column
In this case, SQL Server converts the integer column to float, because int is lower in the hierarchy than float. It cannot use an index on large_table.int_column, although it can use an index on smalltable.float_column.
Try to avoid deadlocks
- Always access tables in the same order in all your stored procedures and triggers consistently.
- Keep your transactions as short as possible. Touch as few data as possible during a transaction.
- Never, ever wait for user input in the middle of a transaction.
Write TSQLs using “Set based approach” rather than using “Procedural approach”
- The database engine is optimized for set based SQLs. Hence, procedural approach (Use of Cursor, or, UDF to process rows in a result set) should be avoided when large result set (More than 1000) has to be processed.
- How to get rid of “Procedural SQLs”? Follow these simple tricks:
-Use inline sub queries to replace User Defined Functions.
-Use correlated sub queries to replace Cursor based codes.
-If procedural coding is really necessary, at least, use a table variable Instead of a
cursor to navigate and process the result set.
For more info on "set" and "procedural" SQL , see Understanding “Set based” and “Procedural” approaches in SQL.
Try not to use COUNT(*) to obtain the record count in the table
- To get the total row count in a table, we usually use the following select statement:
Select COUNT(*) FROM dbo.orders
This query will perform full table scan to get the row count.
- The following query would not require any full table scan. (Please note that, this might not give you 100% perfect result always, but, this is handy only if you don't need a perfect count)
Select rows FROM sysindexes
Where id = OBJECT_ID('dbo.Orders') AND indid < 2
Try to avoid dynamic SQLs
Unless really required, try to avoid the use of dynamic SQL because:
- Dynamic SQLs are hard to Debug and troubleshoot.
- If the user provides input to the dynamic SQL, then there is possibility of SQL injection attacks.
Try to avoid the use of Temporary Tables
- Unless really required, try to avoid the use of temporary tables. Rather, try to use Table variables.
- Almost in 99% case, Table variables resides in memory, hence, it is a lot faster. But, Temporary tables resides in TempDb database. So, operating on Temporary table requires inter db communication and hence, slower.
Instead of LIKE search, Use Full Text Search for searching textual data
Full text search always outperforms the LIKE search.
- Full text search will enable you to implement complex search criteria that can’t be implemented using the LIKE search such as searching on a single word or phrase (and optionally ranking the result set), searching on a word or phrase close to another word or phrase, or searching on synonymous forms of a specific word.
- Implementing full text search is easier to implement the LIKE search (Especially, in case of complex searching requirements).
- For more info on Full Text Search, see http://msdn.microsoft.com/en-us/library/ms142571(SQL.90).aspx
Try to use UNION to implement “OR” operation
- Try not to use “OR” in the query. Instead and use “UNION” to combine the result set of two distinguished queries. This will improve query performance.
- (Better, use UNION ALL) if distinguished result is not required. UNION ALL is faster than UNION as it does not have to sort the result set to find out the distinguished values.
Implement a lazy loading strategy for the large objects
- Store the Large Object columns (Like VARCHAR(MAX), Image Text etc) in a different table other than the main table and put a reference to the large object in the main table.
- Retrieve all the main table data in the query, and, if large object is required to load, retrieve the large object data from the large object table only when this is required.
Use VARCHAR(MAX), VARBINARY(MAX) and NVARCHAR(MAX)
- In SQL Server 2000, a row cannot exceed 8000 bytes in size. This limitation is due to the 8 KB internal page size SQL Server. So, to store more data in a single column, you needed to use the TEXT, NTEXT, or IMAGE data types (BLOBs) which are stored in a collection of 8 KB data pages .
- These are unlike the data pages that store the other data in the same table. Rather, these pages are arranged in a B-tree structure. These data cannot be used as variables in a procedure or a function and they cannot be used inside string functions such as REPLACE, CHARINDEX or SUBSTRING. In most cases, you have to use READTEXT, WRITETEXT, and UpdateTEXT.
- To solve this problem, Use VARCHAR(MAX), NVARCHAR(MAX) and VARBINARY(MAX) in SQL Server 2005. These data types can hold the same amount of data BLOBs can hold (2 GB) and they are stored in the same type of data pages used for other data types.
- When data in a MAX data type exceeds 8 KB, an over-flow page is used (In the ROW_OVERFLOW allocation unit) and a pointer to the page is left in the original data page in the IN_ROW allocation unit.
Implement following good practices in User Defined Function
- Do not call functions repeatedly within your stored procedures, triggers, functions and batches. For example, you might need the length of a string variable in many places of your procedure, but don't call the LEN function whenever it's needed, instead, call the LEN function once, and store the result in a variable, for later use.
Implement following good practices in Stored Procedure:
- Do NOT use “SP_XXX” as a naming convention. It causes additional searches and added I/O (Because the system Stored Procedure names start with “SP_”). Using “SP_XXX” as the naming convention also increases the possibility of conflicting with an existing system stored procedure.
- Use “Set Nocount On” to eliminate Extra network trip
- Use WITH RECOMPILE clause in the EXECUTE statement (First time) when index structure changes (So that, the compiled version of the SP can take advantage of the newly created indexes).
- Use default parameter values for easy testing.
Implement following good practices in Triggers:
- Try to avoid the use of triggers. Firing a trigger and executing the triggering event is
an expensive process. - Do never use triggers that can be implemented using constraints
- Do not use same trigger for different triggering events (Insert,Update,Delete)
- Do not use Transactional codes inside a trigger. The trigger always runs within the
transactional scope of the code that fired the trigger.
Implement following good practices in Views:
- Use views for re-using complex TSQL blocks and to enable it for Indexed views (Will be discussed later)
- Use views with SCHEMABINDING option if you do not want to let users modify the table schema accidentally.
- Do not use views that retrieve data from a single table only (That will be an unnecessary overhead). Use views for writing queries that access columns from multiple tables
Implement following good practices in Transactions:
- Prior to SQL Server 2005, after BEGIN TRANSACTION and each subsequent modification statement, the value of @@ERROR had to be checked. If its value was non-zero then the last statement caused an error and if any error occurred, the transaction had to be rolled back and an error had to be raised (For the application). In SQL Server 2005 and onwards the Try..Catch.. block can be used to handle transactions in the TSQLs. So, try to used Try…Catch based transactional codes.
- Try to avoid nested transaction. Use @@TRANCOUNT variable to determine whether Transaction needs to be started (To avoid nested transaction)
- Start transaction as late as possible and commit/rollback the transaction as fast as possible to reduce the time period of resource locking.
And, that’s not the end. There are lots of best practices out there! Try finding some of them clicking on the following URL:
Remember, you need to implement the good things that you know, otherwise, you knowledge will not add any value to the system that you are going to build. Also, you need to have a process for reviewing and monitoring the codes (That are written by your team) whether the data access codes are being written following the standards and best practices.
How to analyze and identify the scope for improvement in your TSQLs?
In an ideal world, you always prevent diseases rather than cure. But, in reality you just can’t prevent always. I know your team is composed of brilliant professionals. I know you have good review process, but still bad codes are written, still poor design takes place. Why? Because, no matter what advanced technology you are going to use, your client requirement will always be way much advanced and this is a universal truth in the Software development. As a result, designing, developing and delivering a system based on the requirement will always be a challenging job for you.
So, it’s equally important that you know how to cure. You really need to know how to troubleshoot a performance problem after it happens. You need to learn the ways to analyze the TSQLs, identify the bottlenecks and re-factor those to troubleshoot the performance problem. To be true, there are numerous ways to troubleshoot database and TSQL performance problems, but, at the most basic levels, you have to understand and review the execution plan of the TSQLs that you need to analyze.
Understanding the query execution plan
Whenever you issue an SQL in the SQL Server engine, the SQL Server first has to determine the best possible way to execute it. In order to carry this out, the Query optimizer (A system that generates the optimal query execution plan before executing the query) uses several information like the data distribution statistics, index structure, metadata and other information to analyze several possible execution plans and finally selects one that is likely to be the best execution plan most of the cases.
Did you know? You can use the SQL Server Management Studio to preview and analyze the estimated execution plan for the query that you are going to issue. After writing the SQL in the SQL Server Management Studio, click on the estimated execution plan icon (See below) to see the execution plan before actually executing the query.
(Note: Alternatively, you can switch the Actual execution plan option “on” before executing the query. If you do this, the Management Studio will include the actual execution plan that is being executed along with the result set in the result window)
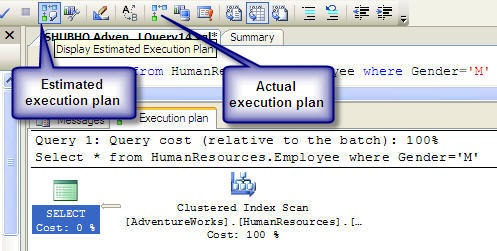
Figure: Estimated execution plan in Management Studio
Understanding the query execution plan in detail
Each icon in the execution plan graph represents one action item (Operator) in the plan. The execution plan has to be read from right to left and each action item has a percentage of cost relative to the total execution cost of the query (100%).
In the above execution plan graph, the first icon in the right most part represents a “Clustered Index Scan” operation (Reading all primary key index values in the table) in the HumanResources Table (That requires 100% of the total query execution cost) and the left most icon in the graph represents a Select operation (That requires only 0% of the total query execution cost).
Following are the important icons and their corresponding operators you are going to see frequently in the graphical query execution plans:
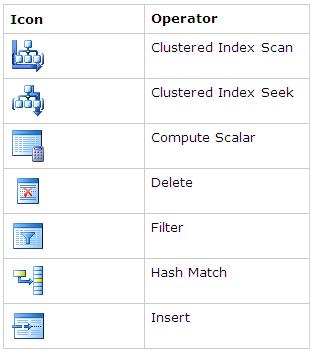
(Each icon in the graphical execution plan represents a particular action item in the query. For a complete list of the icons and their corresponding action item, go to http://technet.microsoft.com/en-us/library/ms175913.aspx )
Note the “Query cost” in the execution plan given above. It has 100% cost relative to the batch. That means, this particular query has 100% cost among all queries in the batch as there is only one query in the batch. If there were multiple queries simultaneously executed in the query window, each query would have its own percentage of cost (Less than 100%).
To know more detail for each particular action item in the query plan, move the mouse pointer on each item/icon. You will see a window that looks like the following:
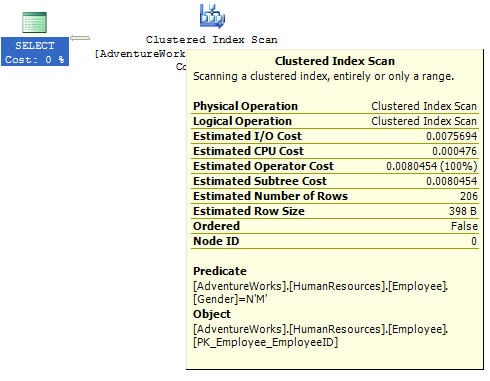
This window provides detailed estimated information about a particular query item in the execution plan. The above window shows the estimated detailed information for the clustered index scan and it looks for the row(s) which have/has Gender = ‘M’ in the Employee table in HumanResources schema in the AdventureWorks database. The window also shows estimated IO, CPU number of rows with size of each row and other costs that is uses to compare with other possible execution plans to select the optimal plan.
I found an article that can help you further understanding and analyzing the TSQL execution plans in detail. You can take a look at it here: http://www.simple-talk.com/sql/performance/execution-plan-basics/
What information do we get by viewing the execution plans?
Whenever any of your query performs slowly, you can view the estimated (And, actual if required) execution plan and can identify the item that is taking the most amount of time (In terms of percentage) in the query. When you start reviewing any TSQL for any optimization, most of the cases, the first thing you would like to do is to view the execution plan. You will most likely to quickly identify the area in the SQL that is creating the bottlenecks in the overall SQL.
Keep watching for the following costly operators in the execution plan of your query. If you find one of these, you are likely to have problems in your TSQL and you need to re-factor the TSQL to try to improve performance.
Table Scan: Occurs when the corresponding table does not have a clustered index. Most likely, creating clustered index or defragmenting indexes will enable you to get rid of it.
Clustered Index Scan: Sometimes considered equivalent to Table Scan. Takes place when non-clustered index on an eligible column is not available. Most of the cases, creating non-clustered index will enable you to get rid of it.
Hash Join: Most expensive joining methodology. This takes place when the joining columns between two tables are not indexed. Creating indexes on those columns will enable you to get rid of it.
Nested Loops: Most cases, this happens when a non-clustered index does not include (Cover) a column that is used in the Select column list. In this case, for each member in the non-clustered index column the database server has to seek into the clustered index to retrieve the other column value specified in the Select list. Creating covered index will enable you to get rid of it.
RID Lookup: Takes place when you have a non-clustered index, but, the same table does not have any clustered index. In this case, the database engine has to look up the actual row using the row ID which is an expensive operation. Creating a clustered index on the corresponding table would enable you to get rid of it.
TSQL Refactoring-A real life story
Knowledge comes into values only when applied to solve real-life problems. No matter how knowledgeable you are, you need to utilize your knowledge in an effective way in order to solve your problems.
Let’s read a real life story. In this story, Mr. Tom is one of the members of the development team that built the application that we have mentioned earlier.
When we started our optimization mission in the data access routines (TSQLs) of our application, we identified a Stored Procedure that was performing way below the expected level of performance. It was taking more than 50 seconds to process and retrieve sales data for one month for particular sales items in the production database. Following is how the stored procedure was getting invoked for retrieving sales data for ‘Caps’ for the year 2009:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009,’Cap’
Accordingly, Mr. Tom was assigned to optimize the Stored Procedure.
Following is a stored procedure that is somewhat close to the original one (I can’t include the original stored procedure for proprietary issue you know).
Alter PROCEDURE uspGetSalesInfoForDateRange
@startYear DateTime,
@endYear DateTime,
@keyword nvarchar(50)
AS
BEGIN
SET NOCOUNT ON;
Select
Name,
ProductNumber,
ProductRates.CurrentProductRate Rate,
ProductRates.CurrentDiscount Discount,
orderQty Qty,
dbo.ufnGetLineTotal(SalesOrderDetailID) Total,
orderDate,
DetailedDescription
FROM
Products INNER JOIN orderDetails
ON Products.ProductID = orderDetails.ProductID
INNER JOIN orders
ON orders.SalesOrderID = orderDetails.SalesOrderID
INNER JOIN ProductRates
ON
Products.ProductID = ProductRates.ProductID
Where
orderDate between @startYear and @endYear
AND
(
ProductName LIKE '' + @keyword + ' %' OR
ProductName LIKE '% ' + @keyword + ' ' + '%' OR
ProductName LIKE '% ' + @keyword + '%' OR
Keyword LIKE '' + @keyword + ' %' OR
Keyword LIKE '% ' + @keyword + ' ' + '%' OR
Keyword LIKE '% ' + @keyword + '%'
)
ORDER BY
ProductName
END
GO
Analyzing the indexes
As a first step, Mr. Tom wanted to review the indexes of the tables that are being queried in the Stored Procedure. He had a quick look into the query and identified the fields that the tables should have indexes on (For example, fields that have been used in the join queries, Where conditions and orDER BY clause). Immediately he found that, several indexes are missing on some of these columns. For example, indexes on following two columns were missing:
OrderDetails.ProductID
OrderDetails.SalesOrderID
He created non-clustered indexes on those two columns and executed the stored procedure as follows:
exec uspGetSalesInfoForDateRange ‘1/1/2009’, 31/12/2009 with recompile
The Stored Procedure’s performance was improved now, but still below the expected level (35 seconds). (Note the “with recompile” clause. It forces the SQL Server engine to recompile the stored procedure and re-generate the execution plan to take advantage of the newly built indexes).
Analyzing the query execution plan
Mr. Tom’s next step was to see the execution plan in the SQL Server Management Studio. He did this by writing the ‘exec’ statement for the stored procedure in the query window and viewing the “Estimated execution plan”. (The execution plan is not included here as it is quite a big one that is not going to fit in screen).
Analyzing the execution plan he identified some important scopes for improvement
- A table scan was taking place on a table while executing the query even though the table has proper indexing implementation. The table scan was taking 30% of the overall query execution time.
- A “Nested loop join” (One of three kinds of joining implementation) was occurring for selecting a column () from a table specified in the Select list in the query.
Being curious about the table scan issue, Mr. Tom wanted to know if any index fragmentation took place or not (Because, all indexes were properly implemented). He ran a TSQL that reports the index fragmentation information on table columns in the database (He collected this from a CodeProject article on Data access optimization) and was surprised to see that, 2 of the existing indexes (In the corresponding tables used in the TSQL in the Stored Procedure) had fragmentation that were responsible for the Table scan operation. Immediately, he defragmented those 2 indexes and found out that the table scan was not occurring and the stored procedure was taking 25 seconds now to execute.
In order to get rid of the “Nested loop join”, he implanted a “Covered index” in the corresponding table including the column in the Select list. As a result, when selecting the column, the database engine was able to retrieve the column value in the non-clustered index node. Doing this reduced the query performance up to 23 seconds now.
Implementing some best practices
Mr. Tom now decided to look for any piece of code in the stored procedure that did not conform to the best practices. Following were the changes that he did to implement some best practices:
Getting rid of the “Procedural code”
Mr. Tom identified that, a UDF ufnGetLineTotal(SalesOrderDetailID) was getting executed for each row in the result set and the UDF simply was executing another TSQL using a value in the supplied parameter and was returning a scalar value. Following was the UDF definition:
Alter FUNCTION [dbo].[ufnGetLineTotal]
(
@SalesOrderDetailID int
)
RETURNS money
AS
BEGIN
DECLARE @CurrentProductRate money
DECLARE @CurrentDiscount money
DECLARE @Qty int
Select
@CurrentProductRate = ProductRates.CurrentProductRate,
@CurrentDiscount = ProductRates.CurrentDiscount,
@Qty = orderQty
FROM
ProductRates INNER JOIN orderDetails ON
orderDetails.ProductID = ProductRates.ProductID
Where
orderDetails.SalesOrderDetailID = @SalesOrderDetailID
RETURN (@CurrentProductRate-@CurrentDiscount)*@Qty
END
This seemed to be a “Procedural approach” for calculating the order total and Mr. Tom decided to implement the UDF’s TSQL as an inline SQL in the original query. Following was the simple change that he had to implement in the stored procedure:
dbo.ufnGetLineTotal(SalesOrderDetailID) Total -- Old Code
(CurrentProductRate-CurrentDiscount)*OrderQty Total -- New Code
Immediately after executing the query Mr. Tom found that the query was taking 14 seconds now to execute.
Getting rid of the unnecessary Text column in the Select list
Exploring for further optimization scopes Mr. Tom decided to take a look at the column types in the Select list in the TSQL. Soon he discovered that one Text column (Products.DetailedDescription) were included in the Select list. Reviewing the application code Mr. Tom found that this column values were not being processed by the application immediately. Few columns in the result set were being displayed in a listing page in the application, and, when user clicks on a particular item in the list, a detail page was appearing containing the Text column value.
Excluding that Text column from the Select list dramatically reduced the query execution time from 14 seconds to 6 seconds! So, Mr. Tom decided to apply a “Lazy loading” strategy to load this Text column using a Stored Procedure that accepts an “ID” parameter and selects the Text column value. After implementation he found out that, the newly created Stored Procedure executes in a reasonable amount of time when user sees the detail page for an item in the item list. He also converted those two “Text” columns to “VARCHAR(MAX) columns and that enabled him to use the len() function on one of these two columns in the TSQLs in other places (That also allowed him to save some query execution time because, he was calculating the length using len(Text_Column as Varchar(8000)) in the earlier version of the code.
Optimizing further : Process of elimination
What’s next? All the optimization steps so far reduced the execution time to 6 seconds. Comparing to the execution time of 50 seconds before optimization, this is a big achievement so far. But, Mr. Tom thinks the query could have further improvement scopes. Reviewing the TSQLs Mr. Tom didn’t find any significant option left for further optimization. So, he indented and re-arranged the TSQL (So that each individual query statement (Say, Product.ProductID = orderDetail.ProductID) is written in a particular line) and starts executing the Stored Procedure again and again by commenting out each line that he suspects for having improvement scope.
Surprise! Surprise! The TSQL had some LIKE conditions (The actual Stored procedure basically performed a keyword search on some tables) for matching several patterns against some column values. When he commented out the LIKE statements, suddenly the Stored Procedure execution time jumped below 1 second. Wow!
It seemed that, having done with all the optimizations so far, the LIKE searches were taking the most amount of time in the TSQL. After carefully looking at the LIKE search conditions, Mr. Tom became pretty sure that the LIKE search based SQL could easily be implemented using the Full Text search. It seemed that two columns needed to be full text search enabled. These were: ProductName and Keyword.
It just took 5 minutes for him to implement the FTS (Creating the Full text catalog, making the two columns full text enabled and replacing the LIKE clauses with the FREETEXT function) and the query started executing now within a stunning 1 second!
Great achievement, isn’t it?
What’s next?
We’ve learned lots of things in optimizing the data access codes, but, we’ve still miles to go. Data access optimization is an endless process that gives you endless thrills and fun. No matter how big systems you have, no matter how complex your business processes are, believe me, you can make them run faster, always!
So, let’s not stop here. Let’s go through the next article in this series:
"Top 10 steps to optimize data access in SQL Server. Part III (Apply advanced indexing and denormalization)"
keep optimizing. Have fun!
History
First Version : 19th April 2009
License
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
About the Author
M.M.Al-Farooque Shubho Member |
A passionate software developer who loves to think, learn and observe the world around. Working in the .NET based software application development for quite a few years. My LinkedIn profile will tell you more about me. Have a look at My other CodeProject articles. Learn about my visions, thoughts and findings at My Blog. Awards: Prize winner in Competition "Best Asp.net article of May 2009" Prize winner in Competition "Best overall article of May 2009" Prize winner in Competition "Best overall article of April 2009"
|


