【重磅开源】Hawk-数据抓取工具:简明教程 – FerventDesert – 博客园
- C#
- 2016-05-03
- 218热度
- 0评论
来源: 【重磅开源】Hawk-数据抓取工具:简明教程 - FerventDesert - 博客园
Hawk: Advanced Crawler& ETL tool written in C#/WPF
1.软件介绍
HAWK是一种数据采集和清洗工具,依据GPL协议开源,能够灵活,有效地采集来自网页,数据库,文件, 并通过可视化地拖拽,
快速地进行生成,过滤,转换等操作。其功能最适合的领域,是爬虫和数据清洗。
Hawk的含义为“鹰”,能够高效,准确地捕杀猎物。
HAWK使用C# 编写,其前端界面使用WPF开发,支持插件扩展。通过图形化操作,能够快速建立解决方案。
GitHub地址:https://github.com/ferventdesert/Hawk
其Python等价的实现是etlpy:
http://www.cnblogs.com/buptzym/p/5320552.html
笔者专门为其开发的工程文件已公开在GitHub:
https://github.com/ferventdesert/Hawk-Projects
使用时,点击文件,加载工程即可加载。
不想编译的话,可执行文件在:
https://github.com/ferventdesert/Hawk/tree/master/Versions
编译路径在:
Hawk.Core\Hawk.Core.sln
以获取大众点评的所有北京美食为例,使用本软件可在10分钟内完成配置,在1小时之内自动并行抓取全部内容,并能监视子线程工作情况。而手工编写代码,即使是使用python,一个熟练的程序员也可能需要一天以上:
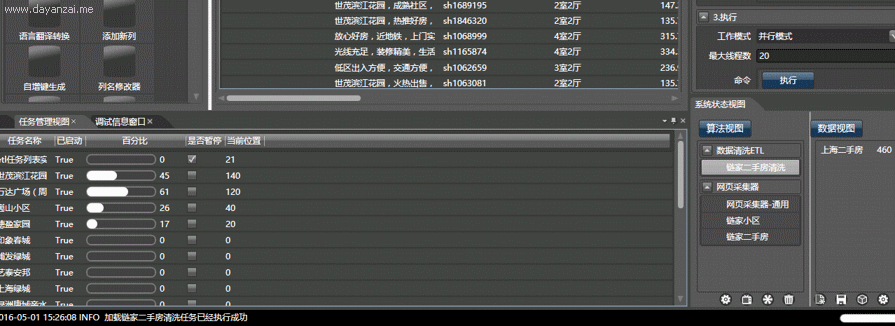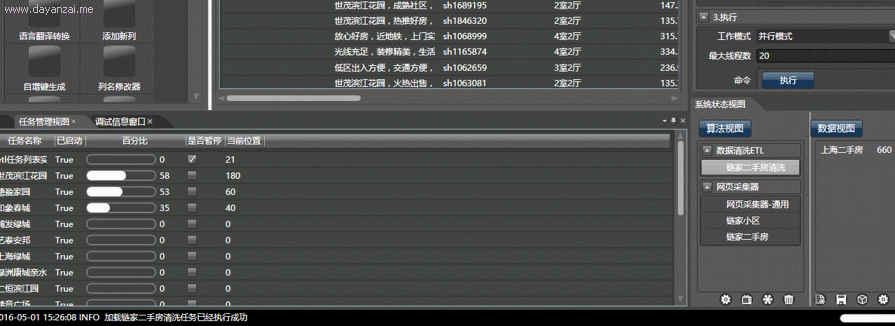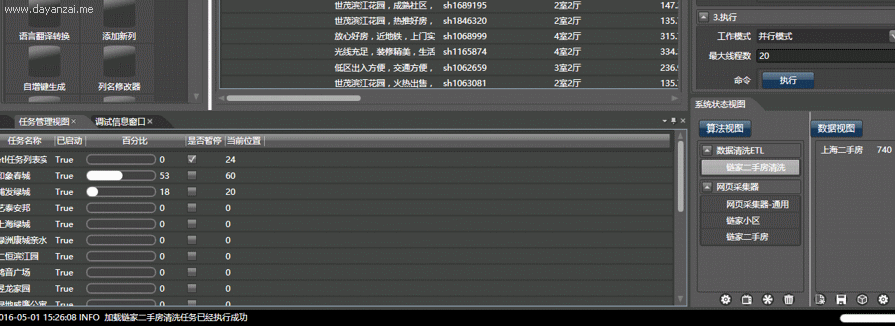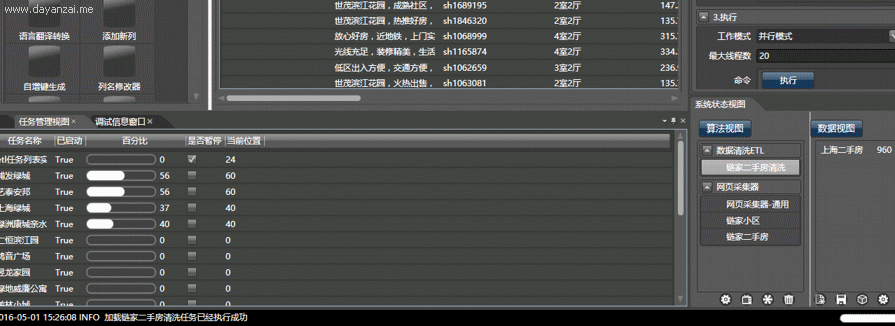
视频演示,复杂度由小到大:
2.界面和组件介绍
2.1 界面介绍
软件采用类似Visual Studio和Eclipse的Dock风格,所有的组件都可以悬停和切换。包括以下核心组件:
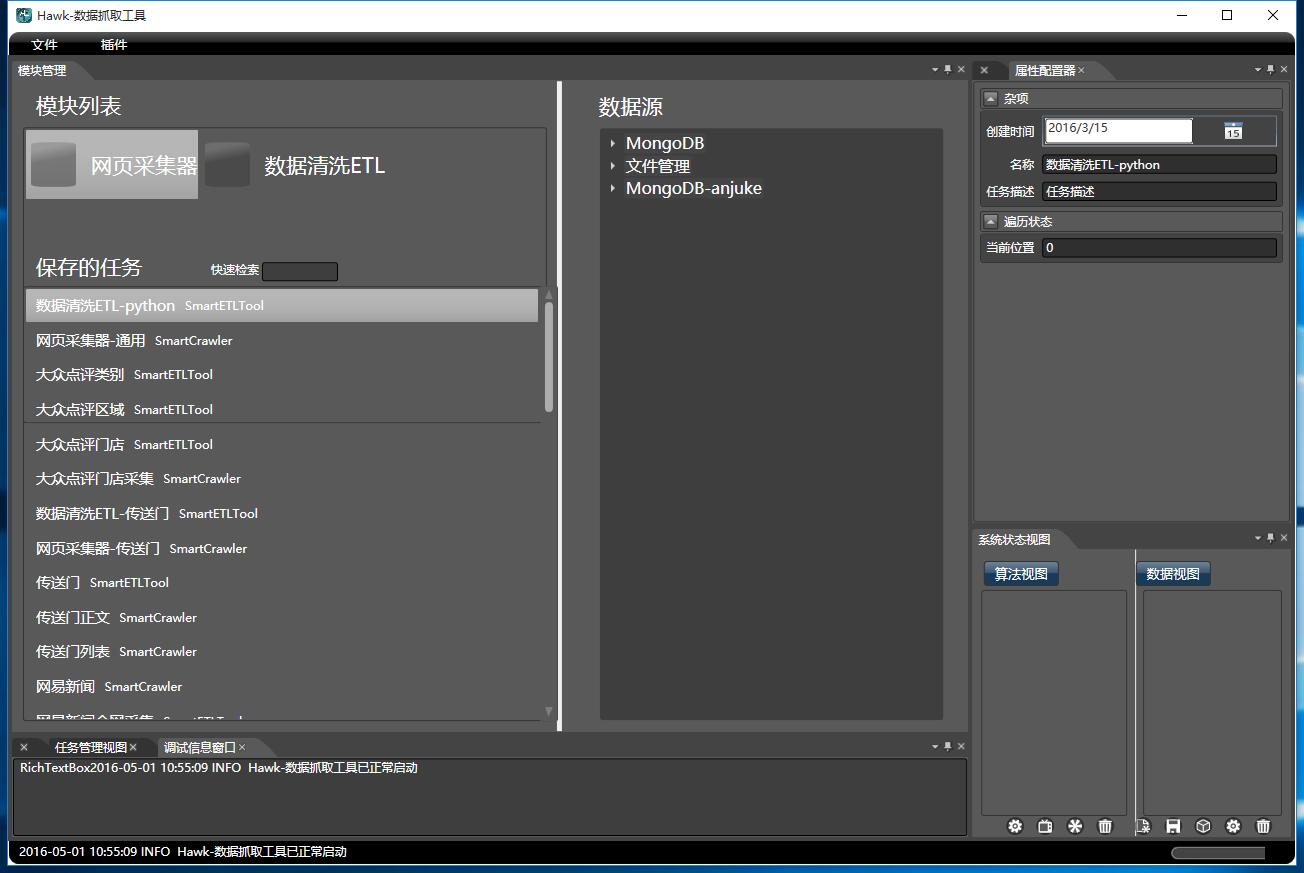
- 左上角区域:主要工作区,可模块管理。
- 下方: 输出调试信息,和任务管理,监控一项任务完成的百分比。
- 右上方区域: 属性管理器,能对不同的模块设置属性。
- 右下方区域: 显示当前已经加载的所有数据表和模块。
2.2 数据管理
能够添加来自不同数据源的连接器, 并对数据进行加载和管理:
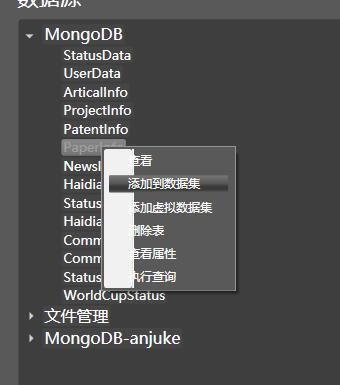
在空白处,点击右键,可增加新的连接器。在连接器的数据表上,双击可查看样例,点击右键,可以将数据加载到内存中。也可以选择加载虚拟数据集,此时系统会维护一个虚拟集合, 当上层请求分页数据时, 动态地访问数据库, 从而有效提升性能。
2.3 模块管理
目前系统仅仅提供了两个模块: 网页采集器和数据清洗ETL, 双击即可加载一个新的模块。
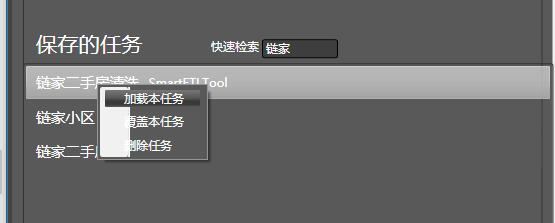
之前配置好的模块,可以保存为任务, 双击可加载一个已有任务:
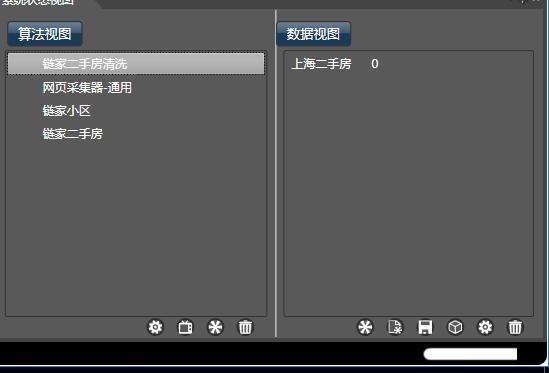
2.4 系统状态管理
当加载了数据集或模块时,在系统状态管理中,就可对其查看和编辑:
点击右键,可以对数据集进行删除,修改名称等。也可以将数据集拖拽到下方的图标上,如拖到回收站,即可删除该模块。
双击数据集或模块,可查看模块的内容。 将数据集拖拽到数据清洗( 数据视图的下方第一个图标),可直接对本数据集做数据清洗。
3.网页采集器
3.1 原理(建议阅读)
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定字段(如JD某商品的价格和介绍, 在页面中只有一个)。因此需要设置其读取模式。传统的采集器需要编写正则表达式,但方法过分复杂。如果认识到html是一棵树,只要找到了承载数据的节点 即可。XPath就是一种在树中描述路径的语法。指定XPath,就能搜索到树中的节点。
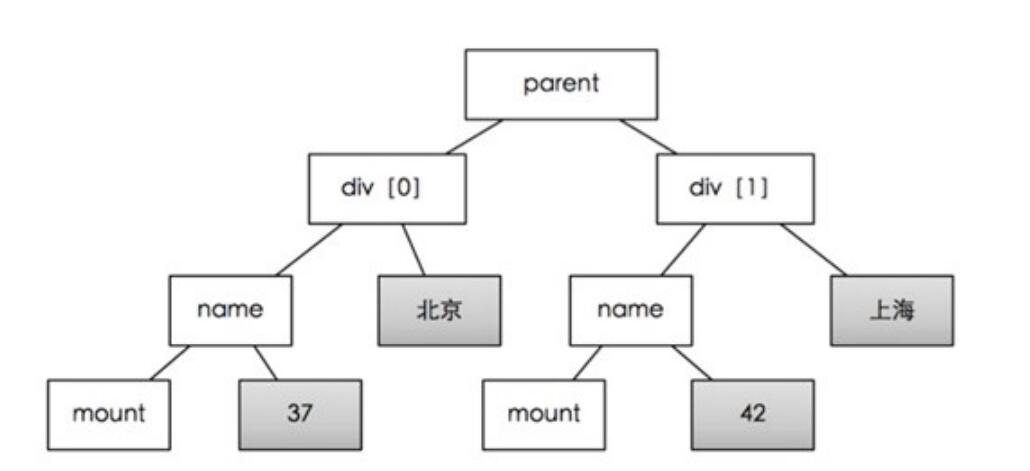
手工编写XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件就会从树中递归搜索包含该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div1这两个列表元素。通过div[0]和div1两个节点的比较,我们就能自动发现相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供北京和37,此时,公共节点是div[0], 这不是列表。
{kind=link}
软件在不提供关键字的情况下,也能通过html文档的特征,去计算最可能是列表父节点(如图中的parent)的节点,但当网页特别复杂时,猜测可能会出错,所以需要至少提供两个关键字( 属性)。
本算法原理是原创的,可查看源码或留言交流。
3.2 基本列表
我们以爬取链家二手房为例,介绍网页采集器的使用。首先双击图标,加载采集器:

在最上方的地址栏中,输入要采集的目标网址,本次是http://bj.lianjia.com/ershoufang/。并点击刷新网页。此时,下方展示的是获取的html文本。原始网站页面如下:
由于软件不知道到底要获取哪些内容,因此需要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。
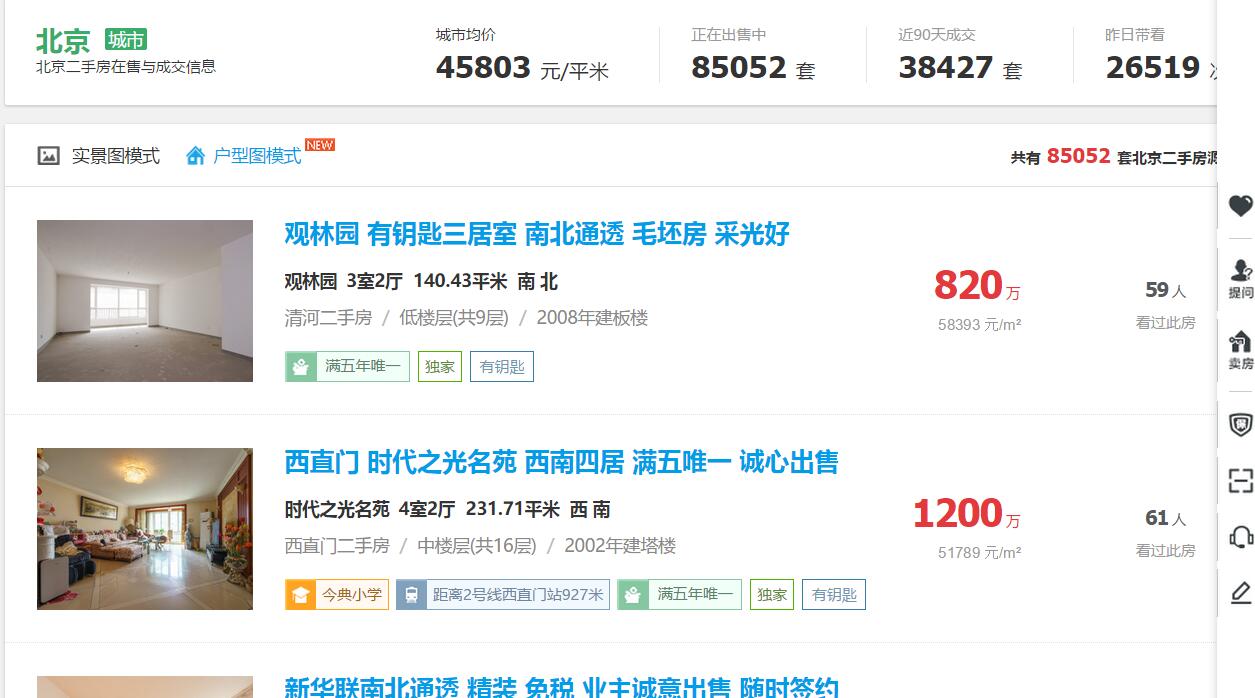
以上述页面为例,通过检索820万和51789(单价,每次采集时都会有所不同),我们就能通过DOM树的路径,找出整个房源列表的根节点。
下面是实际步骤
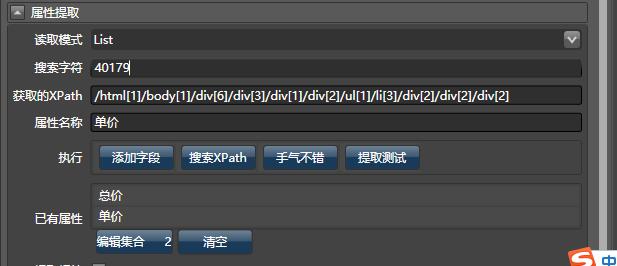
由于要抓取列表,所以读取模式选择List。 填入搜索字符700, 发现能够成功获取XPath, 编写属性为“总价” ,点击添加字段,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
如果发现有错误,可点击编辑集合, 对属性进行删除,修改和排序。
你可以类似的将所有要抓取的特征字段添加进去,或是直接点击手气不错,系统会根据目前的属性,推测其他属性:
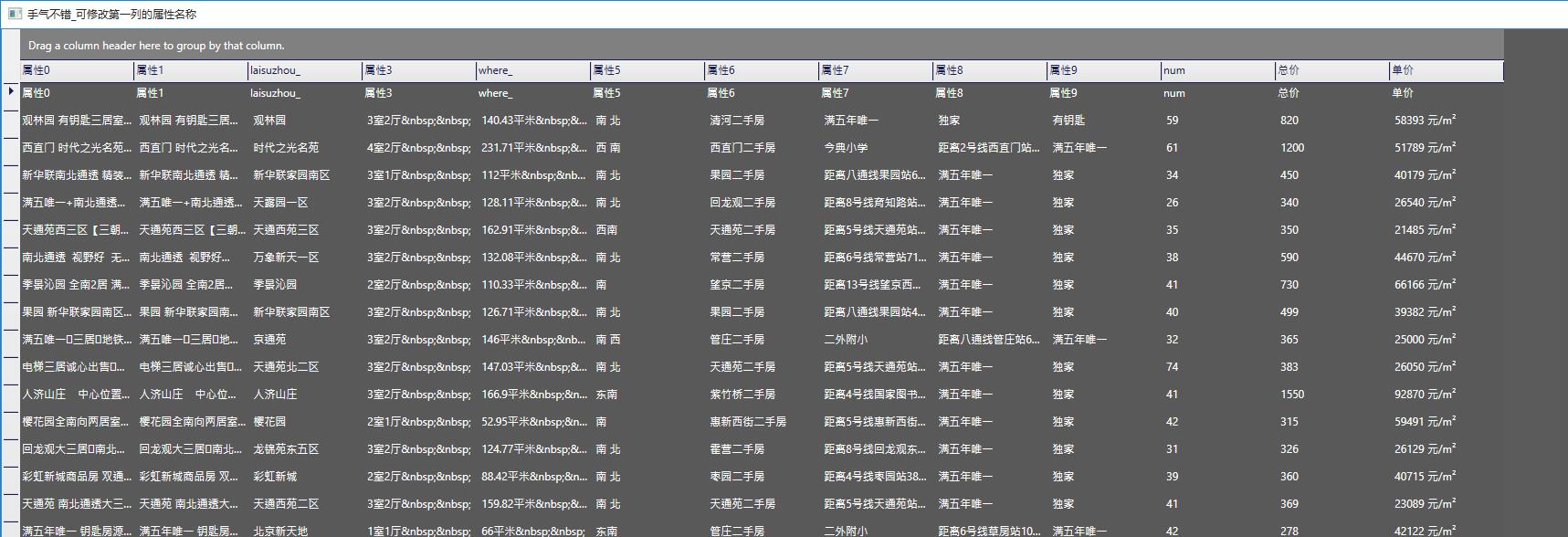
属性的名称是自动推断的,如果不满意,可以修改列表第一列的属性名, 在对应的列中敲键盘回车提交修改。之后系统就会自动将这些属性添加到属性列表中。
工作过程中,可点击提取测试 ,随时查看采集器目前的能够抓取的数据内容。这样,一个链家二手房的网页采集器即可完成。可属性管理器的上方,可以修改采集器的模块名称,这样就方便数据清洗 模块调用该采集器。
4. 数据清洗
数据清洗模块,包括几十个子模块, 这些子模块包含四类:生成, 转换, 过滤和执行

4.0 原理(可跳过)
4.0.1 C#版本的解释
数据清洗的本质是动态组装Linq,其数据链为IEnumerable<IFreeDocument>。 IFreeDocument是 IDictionary<string, object>
接口的扩展。 Linq的Select函数能够对流进行变换,在本例中,就是对字典不同列的操作(增删改),不同的模块定义了一个完整的Linq
流:
result= source.Take(mount).where(d=>module0.func(d)).select(d=>Module1.func(d)).select(d=>Module2.func(d))….借助于C#编译器的恩赐, Linq能很方便地支持流式数据,即使是巨型集合(上亿个元素),也能够有效地处理。
4.0.2 Python版本的解释
由于Python没有Linq, 因此组装的是生成器(generator), 对生成器进行操作,即可定义出类似Linq的完整链条:
for tool in tools:
generator = transform(tool, generator)详细源代码,可以参考Github上的开源项目https://github.com/ferventdesert/etlpy/
4.1 以链家为例的抓取
4.1.1构造url列表
在3.1节介绍了如何实现一个页面的采集,但如何采集所有二手房数据呢? 这涉及到翻页。

还是以链家为例,翻页时,我们会看到页面是这样变换的:
http://bj.lianjia.com/ershoufang/pg2/
http://bj.lianjia.com/ershoufang/pg3/
…因此,需要构造一串上面的url. 聪明的你肯定会想到, 应当先生成一组序列, 从1到100(假设我们只抓取前100页)。
- 双击数据清洗ETL左侧的搜索栏中搜索生成区间数, 将该模块拖到右侧上方的栏目中:
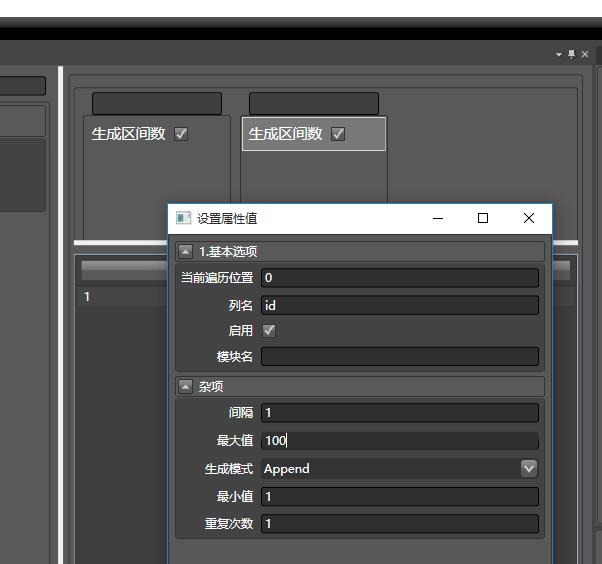
- 在右侧栏目中双击生成区间数,可弹出设置窗口, 为该列起名字(id), 最大值填写为100,生成模式默认为Append:
为什么只显示了前20个? 这是程序的虚拟化机制, 并没有加载全部的数据,可在ETL属性的调试栏目中,修改采样量(默认为20)。 - 将数字转换为url, 熟悉C#的读者,可以想到string.format, 或者python的%符号:搜索合并多列,并将其拖拽到刚才生成的id列, 编写format为下图的格式,即可将原先的数值列变换为一组url

(如果需要多个列合并为一个列, 则在“其他项” 栏目中填写其他列的列名,用空格分割, 并在format中用{1},{2}..等表示)
(由于设计的问题,数据查看器的宽度不超过150像素,因此对长文本显示不全,可以在右侧属性对话框点击查看样例, 弹出的编辑器可支持拷贝数据和修改列宽。
4.1.2 使用配置好的网页采集器
生成这串URL之后,我们即可将刚才已经完成的网页采集器与这串url进行合并。
拖拽从爬虫转换到当前的url,双击该模块:将刚才的网页采集器的名称, 填入爬虫选择 栏目中。
之后,系统就会转换出爬取的前20条数据:
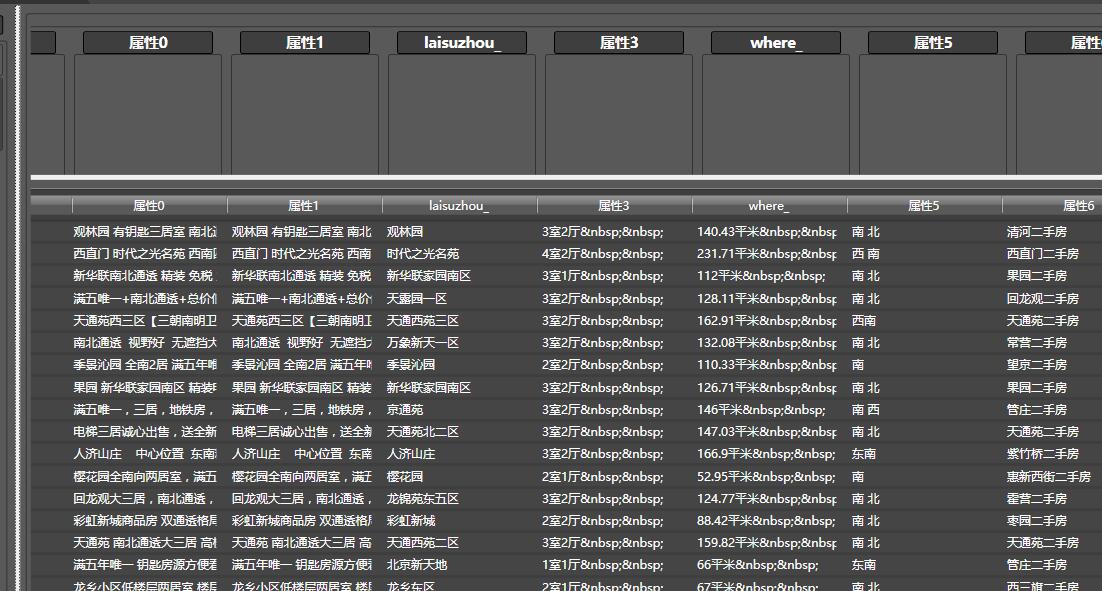
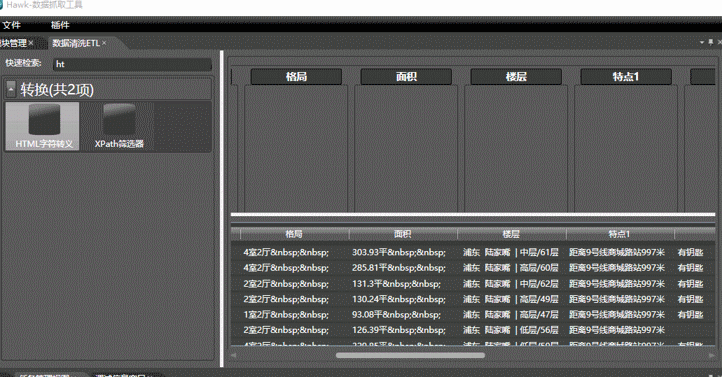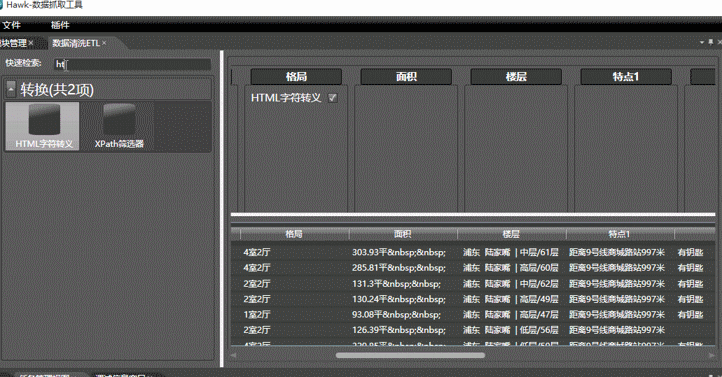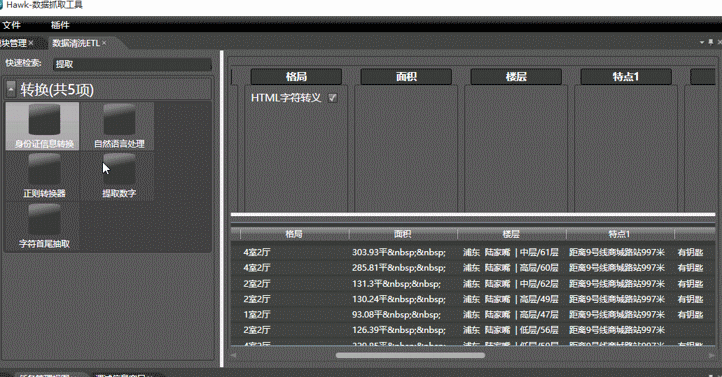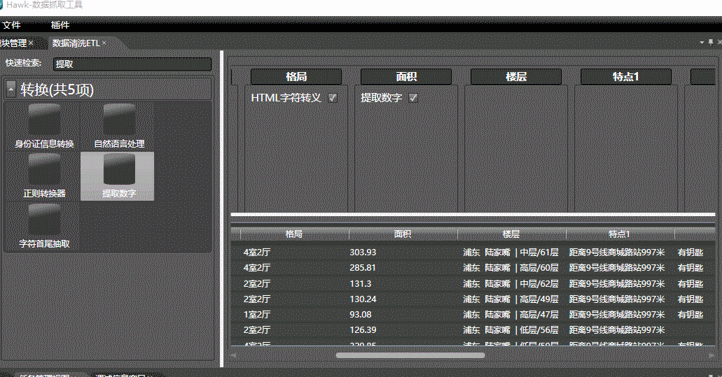
可以看到, 数据中“属性3” 列包含html转义符, 拖拽html字符转义,到属性3列,即可自动转换所有转义符。

如果要修改列名,在最上方的列名上直接修改, 点击回车即可修改名字。
where(面积)列中包含数字,想把数字提取出来,可以将提取数字模块拖拽到该列上,所有数字即可提取出来。
类似地,可以拖拽字符分割或正则分割 到某一列,从而分割文本和替换文本。此处不再赘述。
有一些列为空,可以拖拽空对象过滤器 到该列,那么该列为空的话会自动过滤这一行数据。
4.1.4 保存和导出数据
需要保存数据时,可以选择写入文件,或者是临时存储(本软件的数据管理器),或是数据库。因此可以将“执行” 模块, 拖入清洗链的后端:
拖写入数据表到任意一列, 并填入新建表名(如链家二手房)

下图是这次操作的所有子模块列表:

之后,即可对整个过程进行操作:
选择串行模式或并行模式, 并行模式使用线程池, 可设定最多同时执行的线程数(最好不要超过100)。推荐使用并行模式,
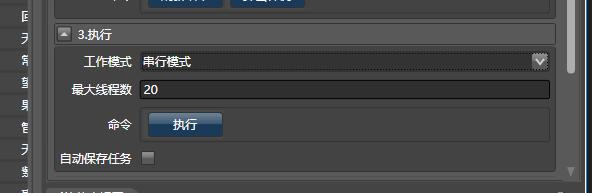
点击执行按钮,即可在任务管理视图中采集数据。

之后,在数据管理的数据表链家二手房上点击右键, 选择另存为, 导出到Excel,Json等,即可将原始数据导出到外部文件中。
类似的, 你可以在清洗流程中拖入执行器,则保存的是中间过程,也可以在结尾拖入多个执行器,这样就能同时写入数据库或文件, 从而获得了极大的灵活性。
4.1.5 保存任务
在右下角的算法视图中的任意模块上点击右键,保存任务,即可在任务视图中保存新任务(任务名称与当前模块名字一致),下次可直接加载即可。如果存在同名任务, 则会对原有任务进行覆盖。
在算法视图的空白处,点击保存所有模块,会批量保存所有的任务。
你可以将一批任务,保存为一个工程文件(xml),并在之后将其加载和分发。
5.总结
上文以抓取房地产网站链家为例,介绍了软件的整体使用流程。当然,Hawk功能远远不限于这些。之后我们将通过一系列文章来介绍其使用方法。
值得提醒的是,由于软件功能在不断地升级,可能会出现视频和图片与软件中不一致的情况,因此所有的介绍和功能以软件的实际功能为准。