ORM之炀,打造自已独特的开发框架CRL – hubro – 博客园
- C#
- 2020-02-10
- 209热度
- 0评论
来源: ORM之炀,打造自已独特的开发框架CRL - hubro - 博客园
ORM一直是长久不衰的话题,各种重复造轮子的过程一直在进行,轮子都一样是圆的,你的又有什么特点呢?
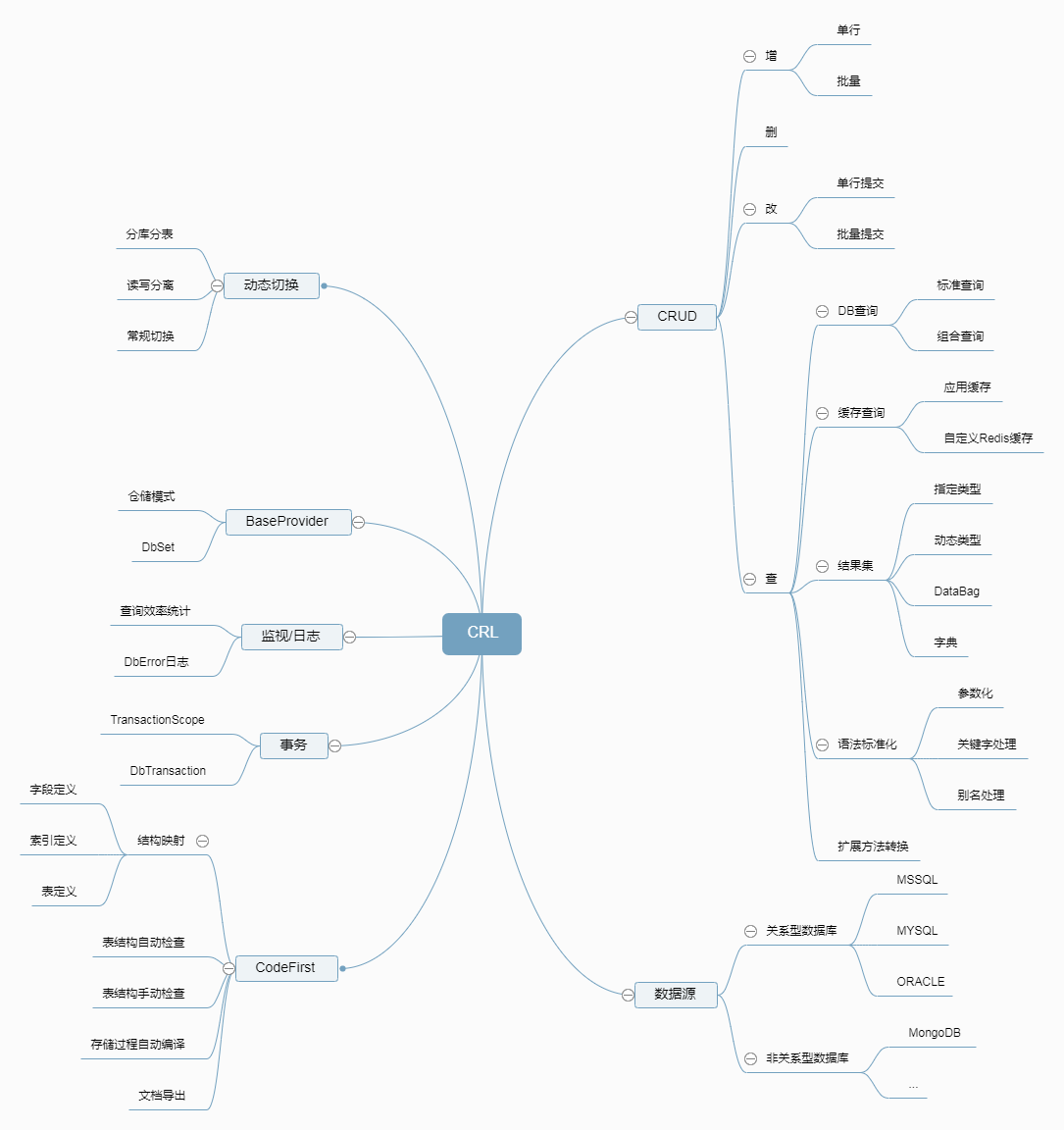
CRL这个轮子造了好多年,功能也越来越标准完备,在开发过程中,解决了很多问题,先上一张脑图描述CRL的功能
开发框架的意义在于
- 开发更标准,更统一,不会因为不同人写的代码不一样
- 开发效率更高,无需重新造轮子,重复无用的代码,同时简化开发流程
- 运行效率得到控制,程序稳定性得到提高
围绕这几点,抛开常规的增删改查,我们来讲些与众不同的
1.与众不同之一,动态数据源,天生适合分库分表
可动态配置的功能总比静态的灵活,扩展性强
目前看到的框架多数访问对象实例化都类似于
var context = new MsSqlContext(ConnectionString);
在对象初始时,就绑定上了数据库连接串, 这样写没什么问题,但是不好扩展
如:需要动态切换库,表,根据租户信息访问不同的数据库,或不同类型的数据库,或是读写分离,这时,急需处理的技术问题就来了,分库分表的解决方案,读写分离的方案
在数据连接绑定的情况下,这种问题很不好解决
又或者传入多个连接串,在调用时,手动选择调用的库或表,对于这种方式,只能说耦合太严重,得关心配置,又得关心调用,在CRL之前的版本里,有这样实现过,弃用了
然而根据IOC的理念,这种问题也不是不好解决,让数据访问对象抽象化实现就能办到了
数据查询方法不再直接调用数据访问对象,而是调用抽象工厂方法,由抽象工厂方法来实例化访问对象,过程表示为
数据查询方法(组件内) => 抽象工厂(组件内) => 抽象实现(组件外)
基于这样的理念,CRL在设计之初,就使用了的这样的方式,以代码为例
!数据访问实现
以下实现了分库分表和mongoDB切换
以下在程序启动时初始

var builder = new CRL.SettingConfigBuilder();
builder.UseMongoDB();//引用CRL.Mongo 使用MongoDB
//注册自定义定位,按MemberSharding传入数据定义数据源位置
//注册一
builder.RegisterLocation<Code.Sharding.MemberSharding>((t, a) =>
{
var tableName = t.TableName;
if (a.Name == "hubro")//当名称为hubro,则定位到库testdb2 表MemberSharding1
{
tableName = "MemberSharding1";
return new CRL.Sharding.Location("testdb2", tableName);
}
//返回定位库和表名
return new CRL.Sharding.Location("testdb", tableName);
});
//注册二
builder.RegisterDBAccessBuild(dbLocation =>
{
if (dbLocation.ManageName == "mongo")
{
var conn = CRL.Core.CustomSetting.GetConfigKey("mongodb");
return new CRL.DBAccessBuild(DBType.MongoDB, conn);
}
return null;
});
//注册三
builder.RegisterDBAccessBuild(dbLocation =>
{
//自定义定位,由注册一传入
if (dbLocation.ShardingLocation != null)
{
return new CRL.DBAccessBuild(DBType.MSSQL, "Data Source=.;Initial Catalog=" + dbLocation.ShardingLocation.DataBaseName + ";User ID=sa;Password=123");
}
return new CRL.DBAccessBuild(DBType.MSSQL, "server=.;database=testDb; uid=sa;pwd=123;");
});
!数据访问类,类似于仓储的形式,根据实际业务实现
定位使用示例
public class MemberManage : CRL.Sharding.BaseProvider<MemberSharding>
{
}
var instance=new MemberManage();
instance.Add(new MemberSharding(){Name="hubro"});
根据定位规则 运行到注册一,此数据将会插入到 库testdb2 表MemberSharding1
常规切换示例
|
1
2
3
4
5
6
|
public class MongoDBTestManage : CRL.BaseProvider<MongoDBModel2>{ public override string ManageName => "mongo";}var instance=new MongoDBTestManage();instance.Add(new MongoDBModel2(){name="hubro"}); |
根据数据访问规则,运行到注册二,此数据将会插入mongodb
可以看到,在上面代码中,没有看到任何数据连接串的传入,数据的访问都由初始时动态分配,对于方法调用是不透明的,调用者不用关心数据源的问题
2.与众不同之二,表结构自动维护
在新技术的支持下,程序和数据库的绑定关系越来越模糊,现在可能是用的SQLSERVER,回头可能改成MySql了,或者改成mongoDB
依赖数据库开发变成越来越不可取,效率也很低
再后来出现了DBFirst方式,虽解决了部份问题,但也很麻烦,如:
建立数据库模型=>导入数据库=>T4模版生成代码(修修补补)
而使用CRL后,过程一步到位,在别人还在用PM设计表结构索引时,你已经设计好了业务结构,效率杠杠的
编写实体类,实现对象访问=>调试运行,自动创建表结构(关键字,长度,索引)
同时,CRL还提供了手动维护方法,使能够按实体结构重建/检查数据表
也提供了对象结构文档导出,不用提心文档的问题
详细介绍看这里
https://www.cnblogs.com/hubro/p/6038118.html
3.与众不同之三,动态缓存
使用缓存可以大大提高程序的运行效率,使用REDIS或MONGODB之类的又需要额外维护
对于单应用程序,程序集内缓存非常有用
CRL内置了缓存实现和维护
只需按方法调用就行了,缓存创建维护全自动
如:
从数据库查
var item = instance.QueryItem(b => b.Id==1)
从缓存查
var item = instance.QueryItemFromCache(b=>b.Id==1);
也支持按查询自定义缓存
var query = Code.ProductDataManage.Instance.GetLambdaQuery(); //缓存会按条件不同缓存不同的数据,条件不固定时,慎用 query.Where(b => b.Id < 700); int exp = 10;//过期分钟 query.Expire(exp); var list = query.ToList();
基于这样的形式,可以将所有查询都走缓存,再也不用担心数据库查询效率了,简值中小项目开发利器
详细介绍看这里
https://www.cnblogs.com/hubro/p/6038540.html
4.与众不同之四,应对复杂查询
因为没有查询分支的概念,处理复杂的查询,一票ORM估计得退场了,虽然合理的结构设计会减少查询复杂度,但谁能保证呢
CRL查询分支过程如下
主查询 => CreateQuery子查询 => 返回匿名对象筛选LambdaQueryResultSelect => 主查询嵌套子查询 => 返回结果
理论上只要符合调用逻辑,可以无限嵌套
示例:
var q1 = Code.OrderManage.Instance.GetLambdaQuery();//主查询
var q2 = q1.CreateQuery<Code.ProductData>();//创建一个子查询
q2.Where(b => b.Id > 0);
var view = q2.CreateQuery<Code.Member>().GroupBy(b => b.Name).Where(b => b.Id > 0).Select(b => new { b.Name, aa = b.Id.COUNT() });//GROUP查询
var view2 = q2.Join(view, (a, b) => a.CategoryName == b.Name).Select((a, b) => new { ss1 = a.UserId, ss2 = b.aa });//关联GROUP
q1.Join(view2, (a, b) => a.Id == b.ss1).Select((a, b) => new { a.Id, b.ss1 });//再关联
var result = view2.ToList();
var sql = q1.ToString();
生成SQL打印如下
SELECT t1.[Id] AS Id, t2.[ss1] AS ss1 FROM [OrderProduct] t1 with(nolock) INNER JOIN (SELECT t2.[UserId] AS ss1, t3.[aa] AS ss2 FROM [ProductData] t2 with(nolock) INNER JOIN (SELECT t3.[Name] AS Name, COUNT(t3.Id) AS aa FROM [Member] t3 with(nolock) WHERE (t3.[Id]>@par1) GROUP BY t3.[Name]) t3 ON (t2.[CategoryName]=t3.[Name]) WHERE (t2.[Id]>@par0) ) t2 ON (t1.[Id]=t2.[ss1])
不管是JOIN后再GROUP,还是GROUP后再GROUP,还是GROUP后再JOIN,通通不是问题
详细介绍看这里
https://www.cnblogs.com/hubro/p/6096544.html
5.与众不同之五,查询抽象,非关系型数据库支持
通过对Lambda表达式的解析,可以实现不同的查询转换,如MongoDB,或ElasticSearch(目前只实现了MongoDB)
有人问,这样有什么用呢?
好处就是,在CRL框架下,一套LambdaQuery走天下,不用写各种差异很大的查询方法了,在动态数据源的支持下,数据拆分游刃有余
如:
之前有个报表存在MSSQL里,发现数据量太大了,查询慢,改由MongoDB,程序不用怎么调整,直接在配置里改为MongoDB即可
以MongoDB为例
CRLLambdaQuery=>CRLExpression=>BsonDocument=>MongoDB
在[数据访问实现]示例中,演示了如何切换到MongoDB
代码实现见项目:CRL.Mongo
6.题外之六,请使用仓储模式
在上文提到,好多框架会直接返回一个数据访问对象,如
var obj1context.Query<TestEntity>(b=>b.Id==1).ToSingle();
然而这样会导致滥用,直接在WEB层用,在Service层随意用,如
var obj2=context.Query<TestEntity2>(b=>b.Id==1).ToSingle(); var obj3=context.Query<TestEntity3>(b=>b.Id==1).ToSingle();
某一天,TestEntity3要换库了,查找一下引用,傻眼了,上百个引用(接手别人的项目,亲身体验过这种痛苦,一个个改)
好在CRL开始就杜绝了这种情况发生,对据的访问必须通过BaseProvider实现,而BaseProvider就是一个仓储的形式
7.题外之七,查询效率
ORM效率无非分两点,实体映射效率和语法解析效率,
对于映射反映在,一次返回多行数据,转换为实体集合
对于语法解析效率,按参数调用多次,返回一行数据,转换为实体
测式程序和SQL为本机,CPU空闲正常,2核6G服务器
一张图表明一切(不同机器实际情况可能有差异)
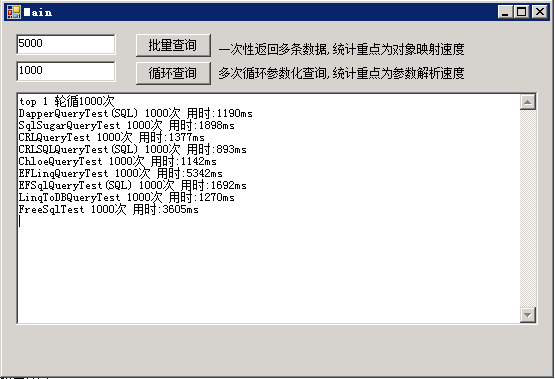
CRL效率虽不是最高的,但也不是最差的,测试项目见:
https://github.com/hubro-xx/CRL5/tree/master/Test/TestConsole
大概列举了以上几项,还有好多特有的东西,轮子好不好,东西南北滚滚试试
CRL开发框架虽然写好长时间,但一直在DEBUG状态中, 最近又升级了,分离了数据访问层,不同数据库引用不同的数据访问层,数据访问层实现也很简单,只需要写两个文件,如MySql,实现MySqlHelper和MySQLDBAdapter
见:https://github.com/hubro-xx/CRL5/tree/master/CRL.Providers/CRL.MySql
同时,版本也升级到5.1,项目结构发生了改变
源码地址:https://github.com/hubro-xx/CRL5
CRL目前.NET版本为.net 4.5, 有时间了再整理整理netstandard版本
除了ORM,CRL还带 动态API,RPC,WebSocket,api客户端代理实现
https://www.cnblogs.com/hubro/p/11652687.html
微服务注册,发现,调用集成参见:
https://github.com/hubro-xx/CRL5/blob/master/Consul/ConsulTest/Program.cs