来源: 12个Visual Studio调试效率技巧 – 芝麻麻雀 – 博客园

在这篇文章中,我们假定读者了解VS基本的调试知识,如:
- F5 开始使用调试器运行程序
- F9 在当前行设置断点
- F10 运行到下一个断点处
- F5 从被调试的已停止程序恢复执行
- F11 步进到函数内(如果当前程序指针指向一个函数)
- F10 步过函数(如果当前程序指针指向一个函数)
- Shift+F11 步出执行的函数
- 暂停执行
- 附加到进程
- 鼠标悬停时快速查看源代码中的元素
- 调试窗口:局部变量、监视、即时窗口、模块、调用堆栈、异常设置
许多开发人员使用这个功能强大的工具包来处理调试会话。然而,Visual Studio调试工具提供了更多的功能。下面是一系列Visual Studio调试效率技巧。注意,这些提示和快捷方式已经在的Visual studio 2019 16.6 EN-US版本中进行了验证,验证时Visual studio没有安装扩展。
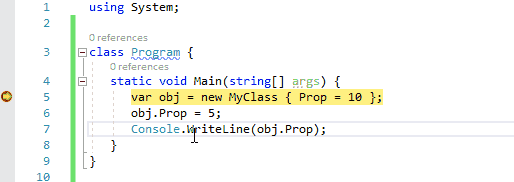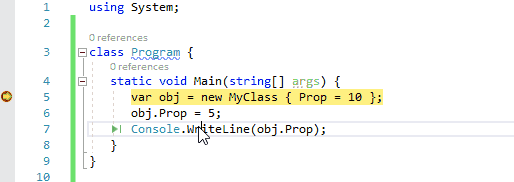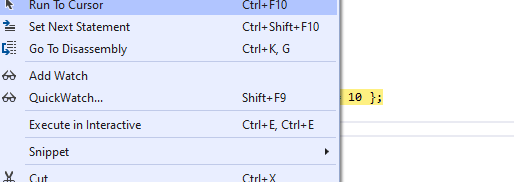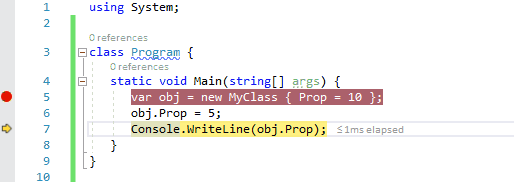
1、运行到光标位置
使用快捷键Ctrl+F10,您可以让调试器运行到光标所在行位置。
2、通过点击鼠标,运行到当前位置
在调试运行的程序时,通过鼠标悬停在当前行的代码上时,出现绿色的符号,可以点击此符号,直接让断点运行到此处。
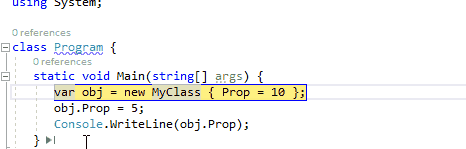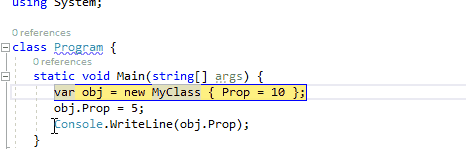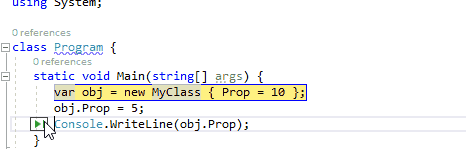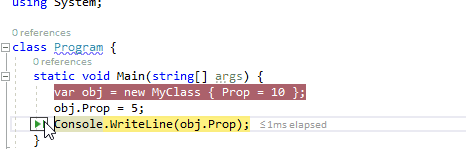
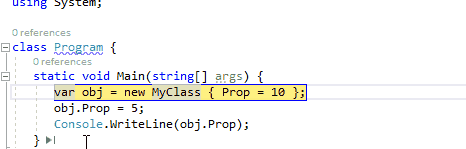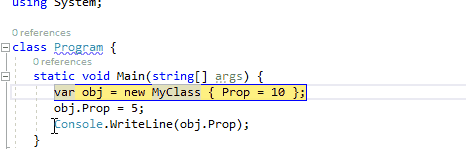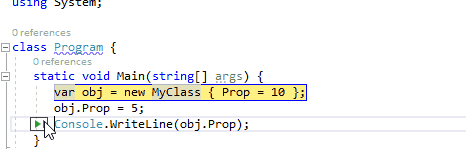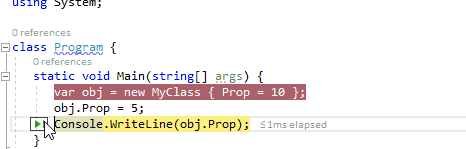
3、在此处作为下一条要执行的语句
在调试运行的程序时,通过鼠标悬停在当前行的代码上时,通过按住Ctrl键转换为将此处作为下一条要执行的语句。它与通过绿色箭头符号运行到这里不同,此功能将会跳过中间的语句,直接将断点跳转到此处。因此,在下面的动图中,我们可以在监视窗口中引用obj仍然为null,中间的MyClass构造函数并没有被执行。
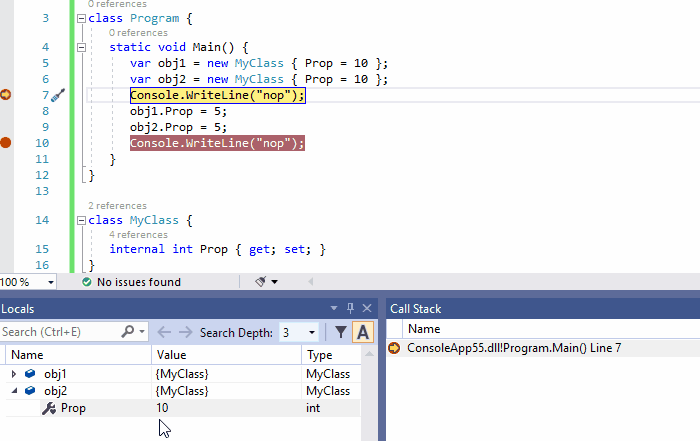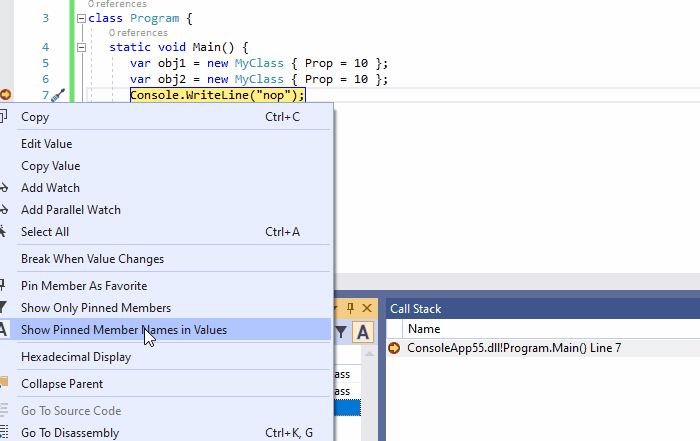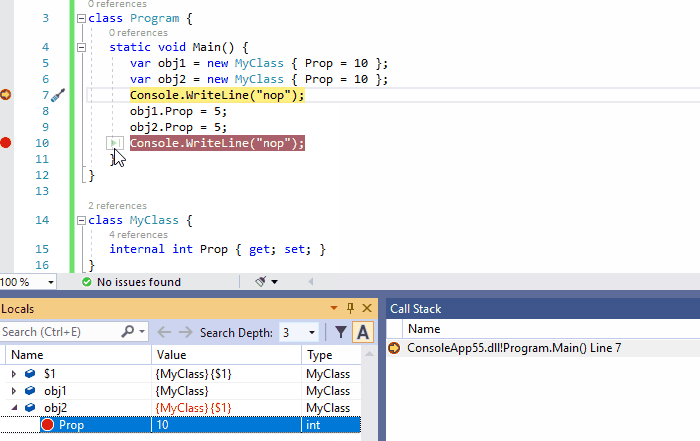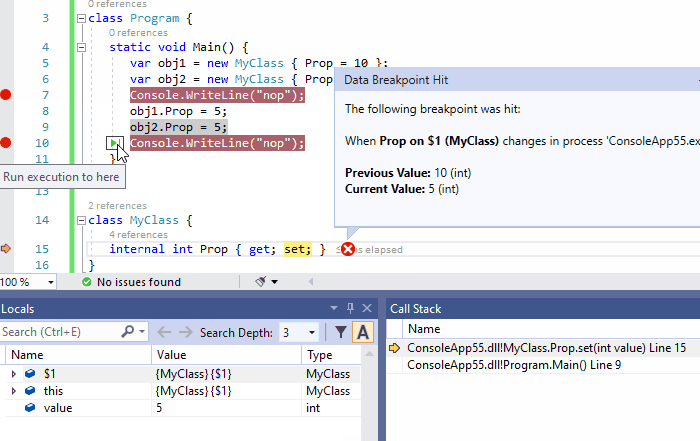
4、数据断点:当值发生变化时,触发中断(值更改时中断)
当你设置一个非静态的设置器为断点时,当所有对象的属性的值发生更改时触发断点。通过局部窗口(监视器窗口)右键点击:值更改时中断菜单,单个对象也可以获得相同的行为。
下面的动画说明了这个功能,只有当obj2.Prop发生变化时,命中断点,而obj1.Prop发生变化时没有命中断点。
注意:数据断点绑定到活动对象时,旨在调试期间起作用。因此,一旦调试过程停止,设置的断点就会丢失,在以后的调试过程中不能重用它。
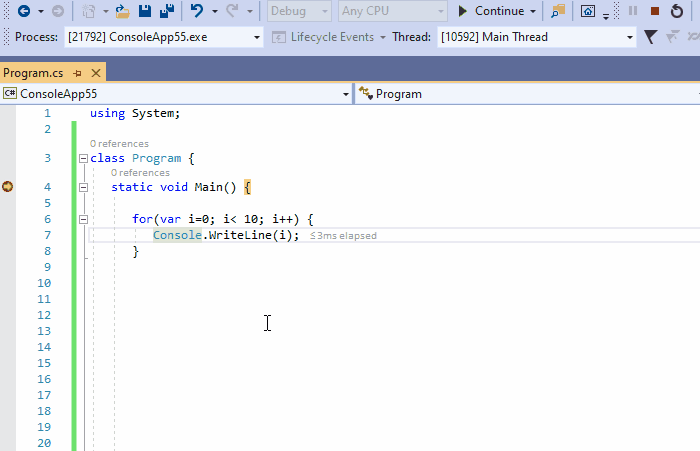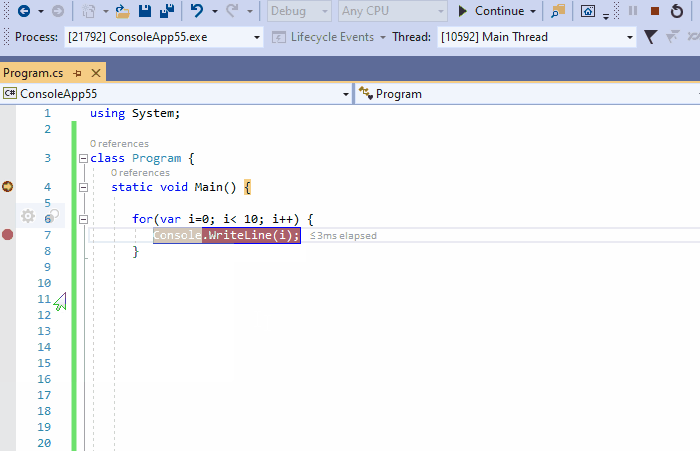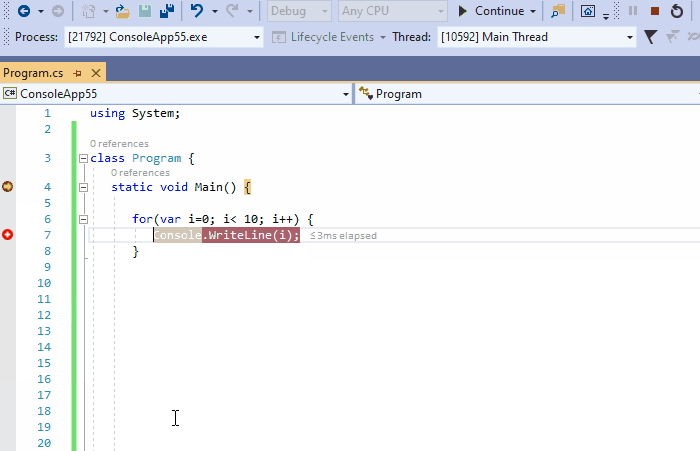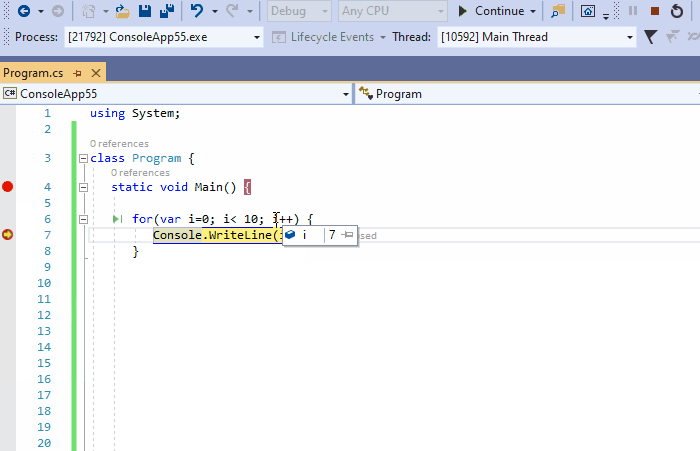
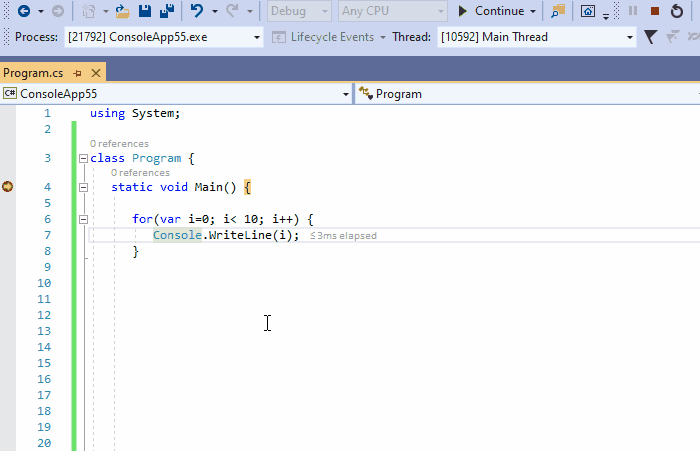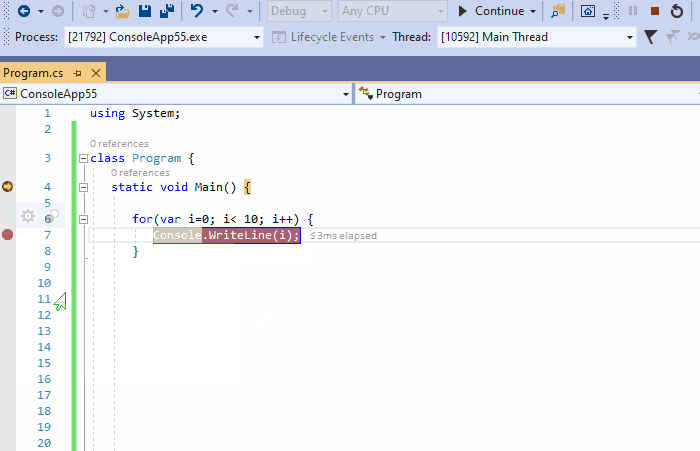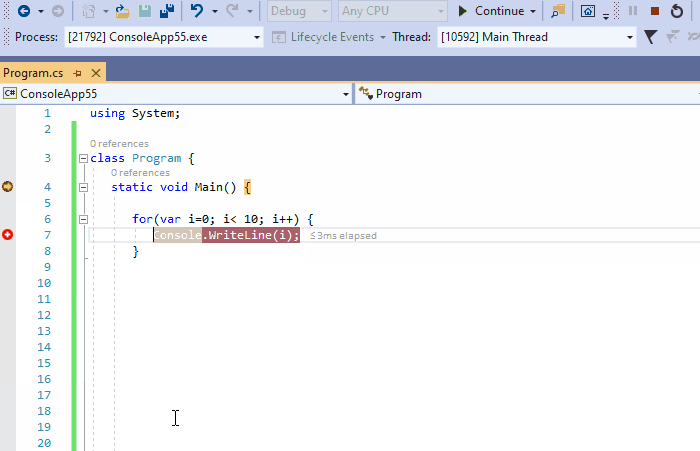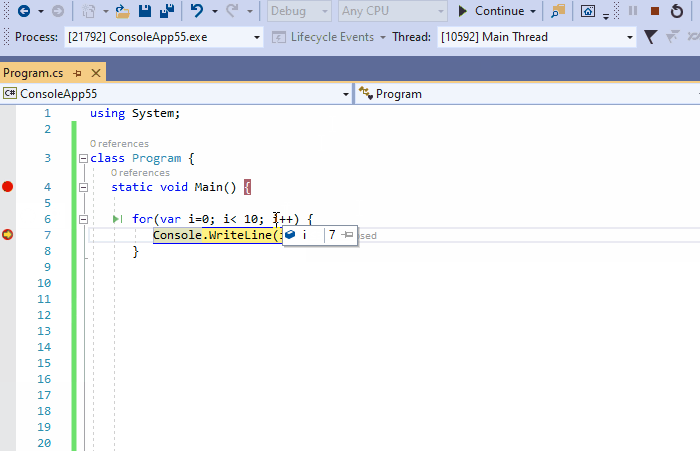
5、条件断点
可以将条件附加到断点中,以便尽在特定场景中触发中断。在下面的动图中,我们在循环中定义条件i>6的断点。然后点击继续,可以看到一旦断点停止,i的值实际上变成了7。
6、跟踪断点
在遇到断点时,停止程序执行时最常见的操作。但是,你可以选择在输出窗口中不终止(或带终止)打印一些跟踪信息。下面的动图说明了这种可能性。我们在输出窗口中跟踪i从0到9的值。注意:跟踪断点在编辑器的断点显示位置显示为菱形形状。
注意,条件和跟踪操作都可以在断点上指定。
7、跟踪超出作用域的对象
在监视窗口中,通过当前执行范文内引用的名称来跟踪对象。但是,当这样的跟踪引用超出作用域时,即使在引用对象仍处于活动状态时,它在监视窗口的上下文也不安的毫无意义并且被禁用。
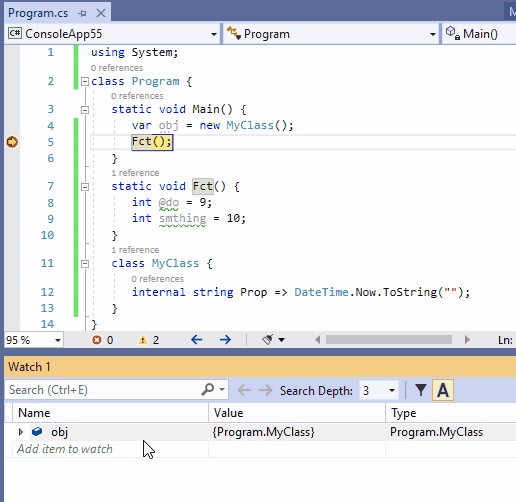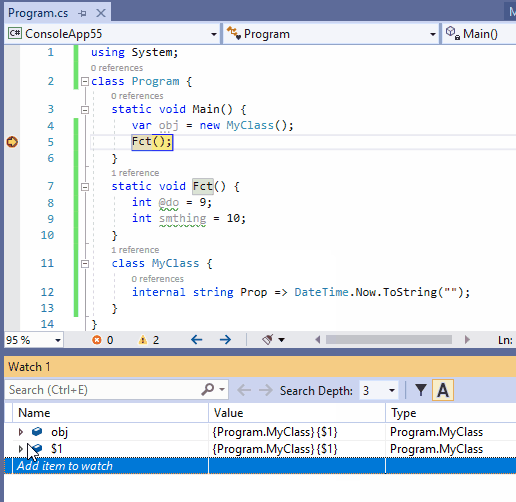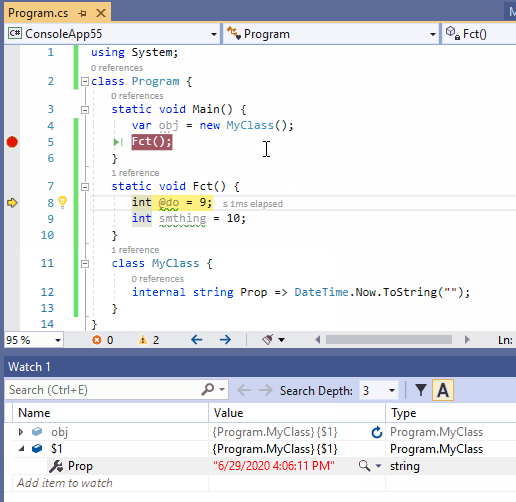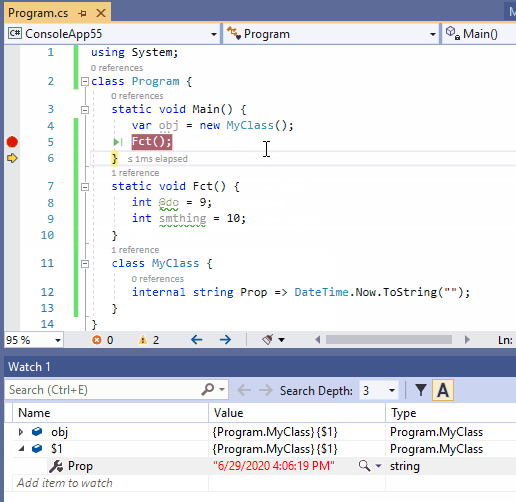
在许多情况下,我们想继续跟踪作用域外对象的状态。为此,请在监视窗口中右键单击此类引用,单击菜单[Make Object ID] 创建对象ID(M),并要在监视器中添加$1(或者$2,$3,…,取决于你已经创建了多个对象ID)。
下面的动图演示了如何跟踪作用域外对象的属性获取器的状态,该属性获取器以字符串的形式返回实际的日期时间。它很好地显示了当引用obj在Fct()上下文中超出作用域时,要观看的obj项将被禁用,而$1仍然会获得更新。
8、查看函数返回的值
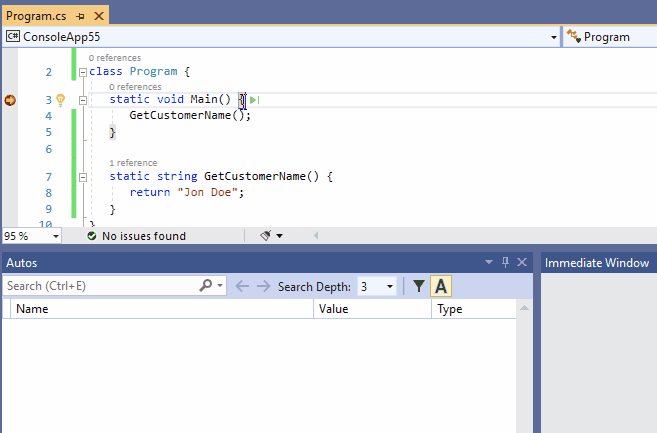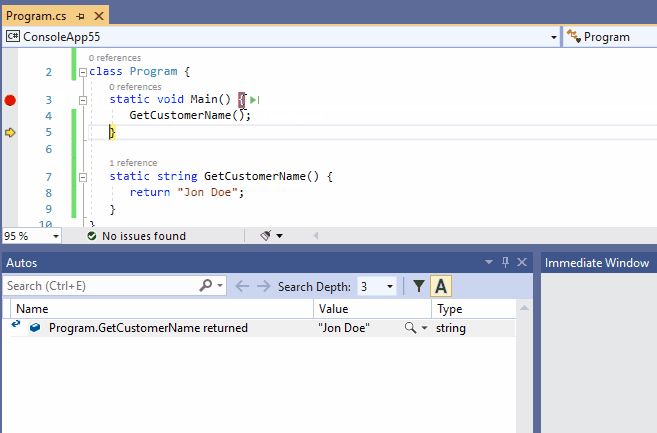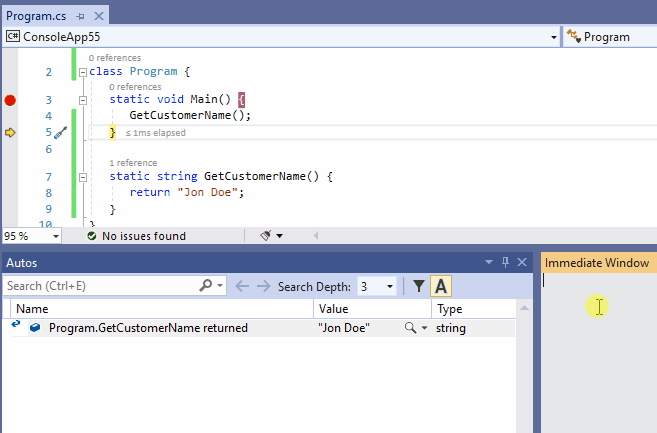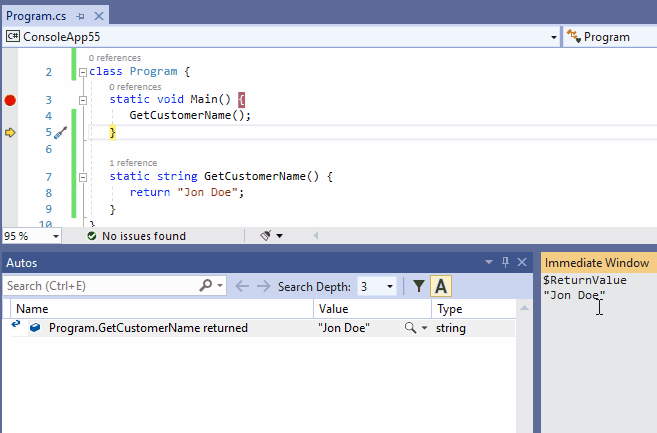
函数返回的值有时在源代码中被忽略,或者有时这个值在调试时无法被显示的访问。
这样的返回值可以显示在调试->窗口->自动窗口中。伪变量$ReturnValue也可以在即时窗口和监视窗口中使用,以方便查看最后一个函数调用的返回值。
注意,菜单调试->窗口->自动窗口仅在Visual Studio调试器附加到进程并且程序被调试器暂停时可用。
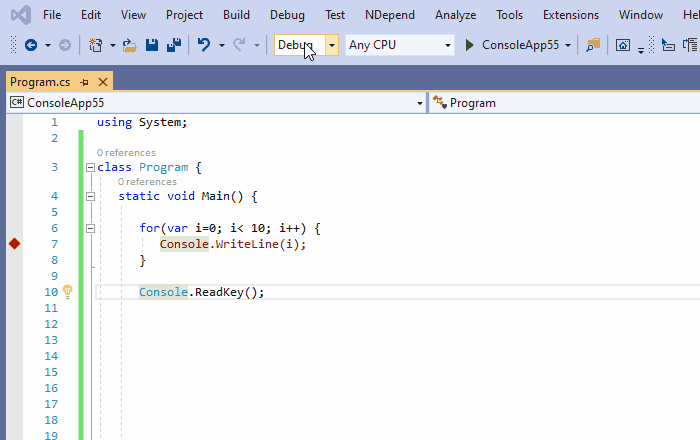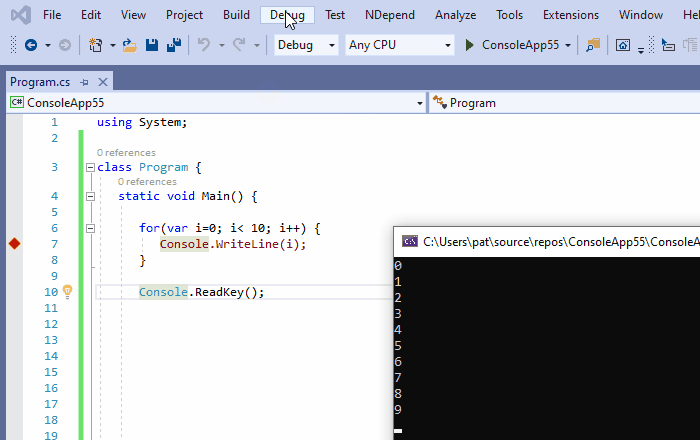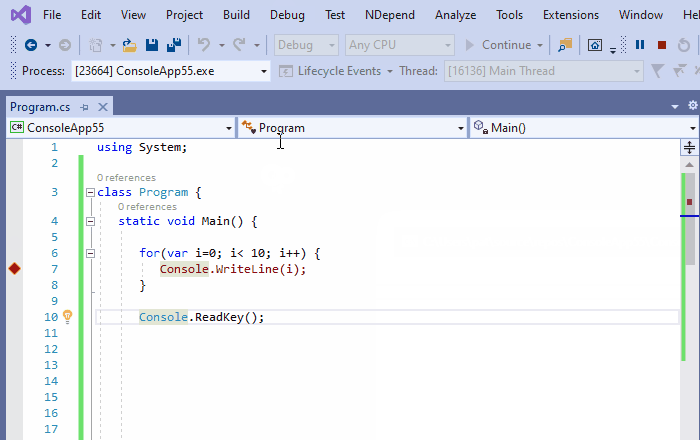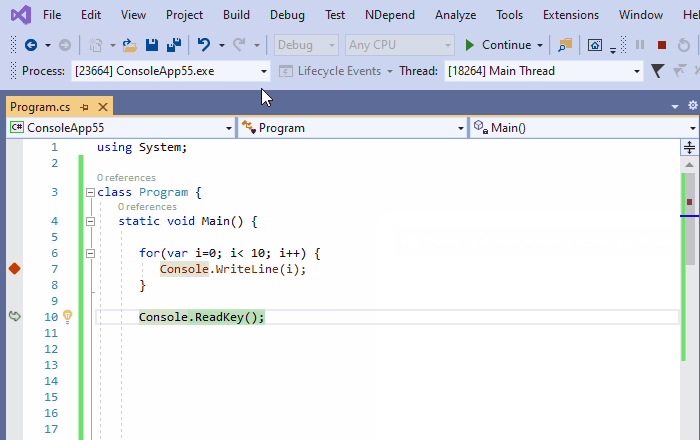
9、重新附加到进程
从Visual Studio 2017开始,重新附加到进程Shift+Alt+P工具被提出,并且非常方便。将调试器附加到某个进程后,Visual Studio会记住它,并建议将调试器重新附加到同一进程。斜体也一样,因为这里有一个关于进程标识的启发式方法:
- 如果已附加的进程仍然运行着,重新附加到进程,重新附加到它。
- 否则,
Visual Studio将尝试查找和前一个进程名具有相同名称的单进程,并将调试器重新附加到该进程。
- 如果找到几个使用此名称的进程,则打开“附加到进程”对话框,只显示名称相同的进程
- 如果找不到具有此名称的进程,则显示“附加到进程”对话框
重新附加到进程也适用于涉及多个进程的调试会话。在这种情况下,Visual Studio会尝试使用上述相同的启发式方法来查找它附加到的所有进程。
10、在即时窗口和在观察窗口的No-Side-Effect评估
有时,在即时窗口或监视窗口中评估表达式时,某些状态会更改。这种行为通常时不希望发生的。你不想仅仅因为需要评估表达式的值而破坏调试程序的状态。这种情况被称为Heisenbug,该术语时物理学家Werner Heisenberg的双关语,它首先断言了量子力学的观察者效应,该现象指出,观察系统的行为不可避免的会改变器状态。
为了避免更改任何状态,你可以在表达式后面加上nse(No-Side-Effect)。下面的动图说明了这种可能性(在监视窗口中监视State的值是否有变化)。
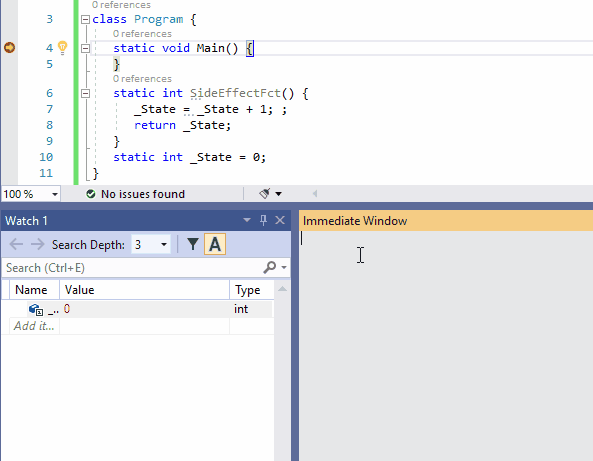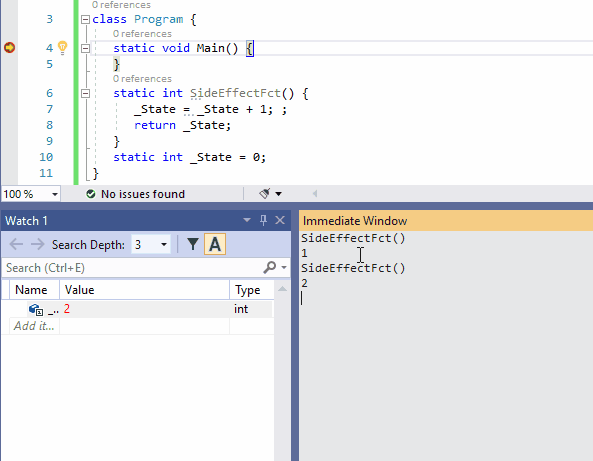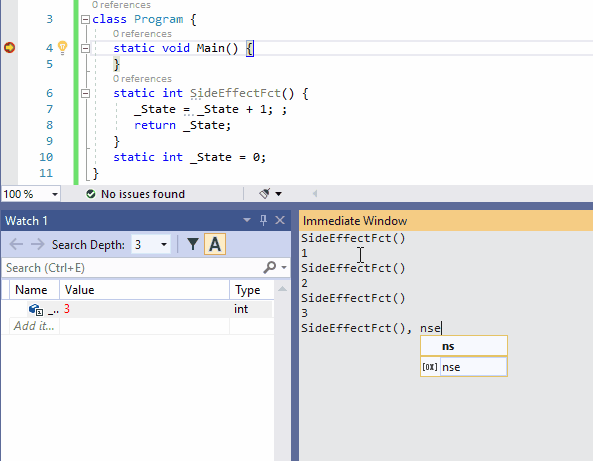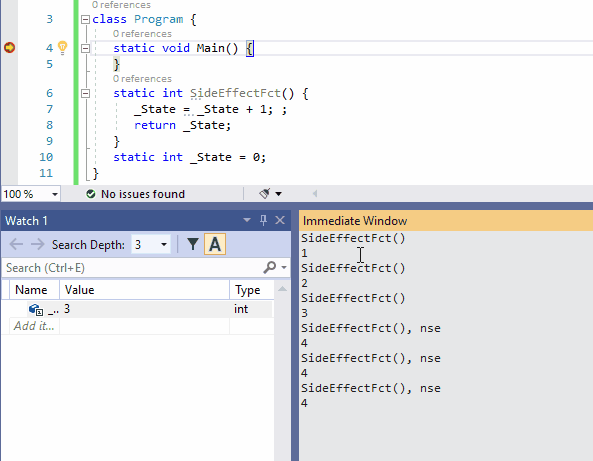
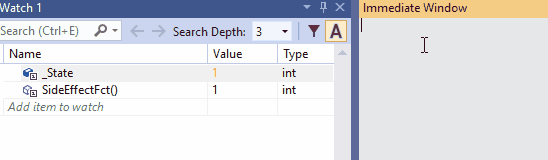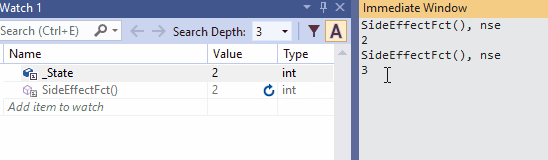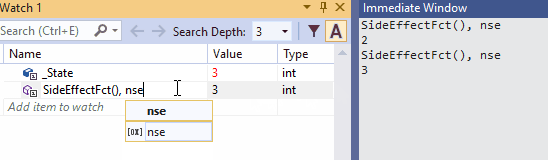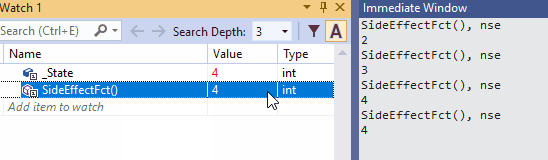
下面这种动图是nse在监视窗口的使用。由于SideEffectFct()所观察的项中有Refresh评估按钮,所以此示例比前一个示例更简单。
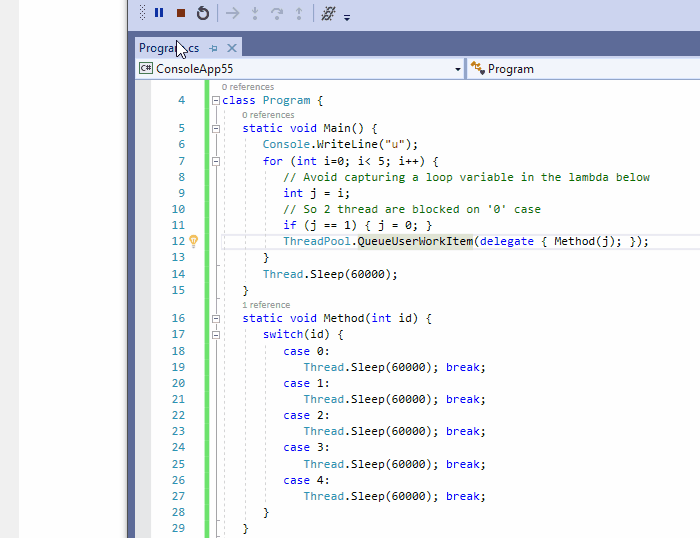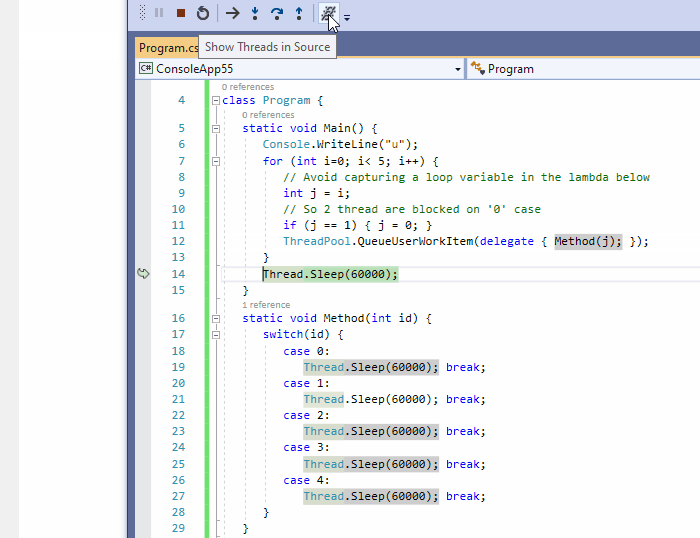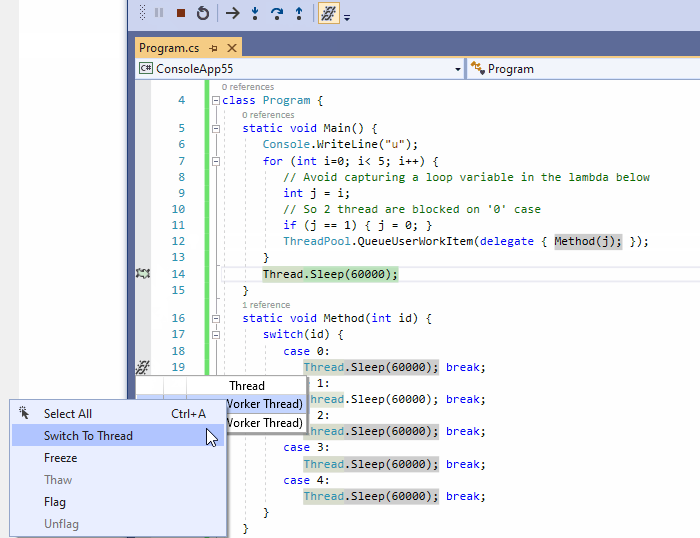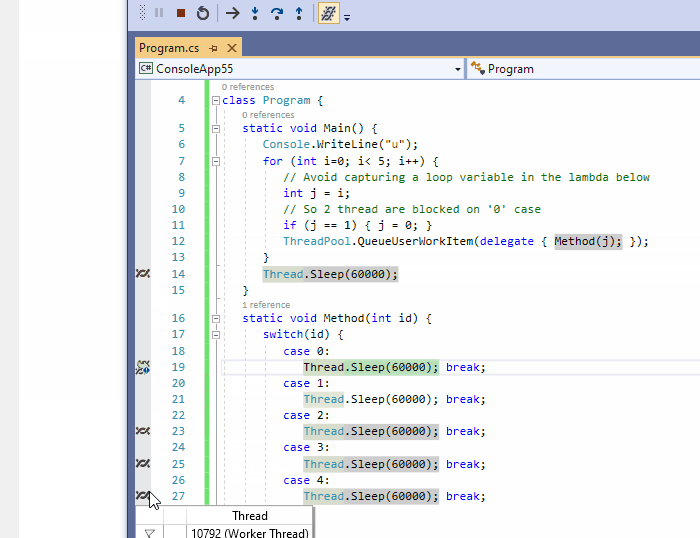
11、在源码中显示线程
调试多线程应用程序是有名的复杂。希望在源码中显示线程按钮能提供很大的帮助。它在编辑器的左侧边栏引入标记图标,以跟踪其他线程被暂停的位置。这个标记可以用来显示线程ID,并最终切换到另一个线程。注意:如果至少两个线程在同一位置暂停,则会显示不同的标记符号。
更多调试多线程应用程序的技巧可以在这个微软文档中找到:Get started debugging multithreaded applications (C#, Visual Basic, C++)
https://docs.microsoft.com/en-us/visualstudio/debugger/get-started-debugging-multithreaded-apps?view=vs-2019
下面是这个演示的源代码,如果你想演示它,可以进行参考:
using System;
using System.Threading;
class Program {
static void Main() {
for (int i=0; i< 5; i++) {
int j = i;
if (j == 1) { j = 0; }
ThreadPool.QueueUserWorkItem(delegate { Method(j); });
}
Thread.Sleep(60000);
}
static void Method(int id) {
switch(id) {
case 0:
Thread.Sleep(60000); break;
case 1:
Thread.Sleep(60000); break;
case 2:
Thread.Sleep(60000); break;
case 3:
Thread.Sleep(60000); break;
case 4:
Thread.Sleep(60000); break;
}
}
}
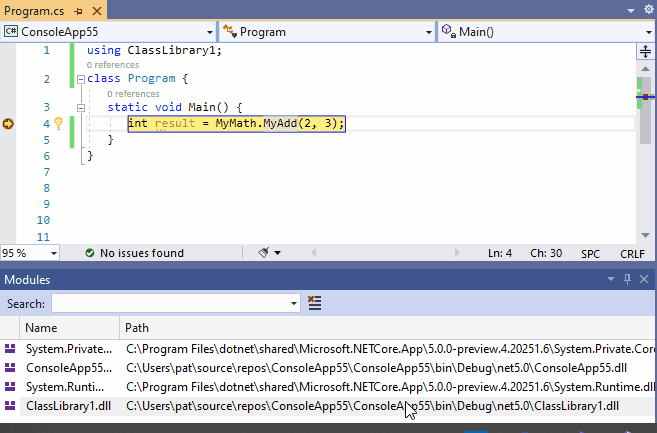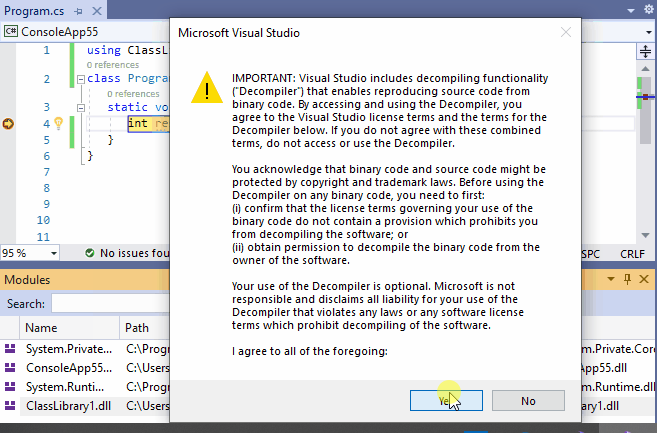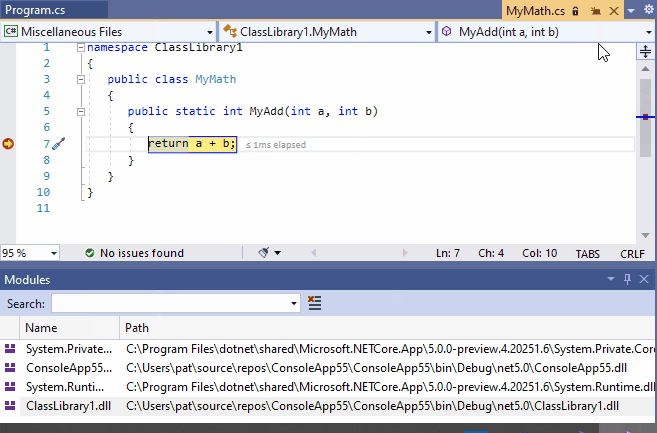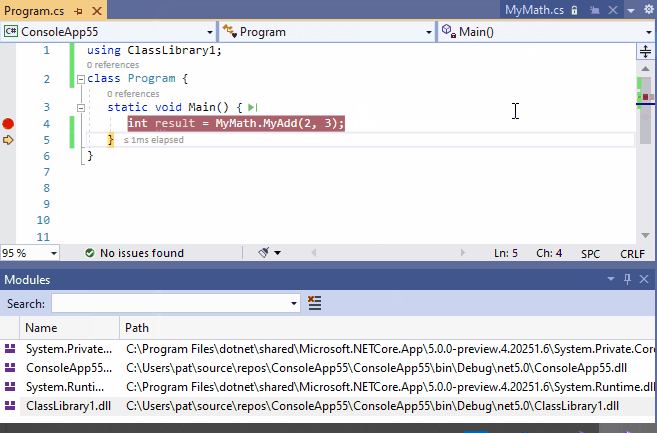
12、从反编译的IL代码中调试源代码
我们经常依赖一些黑盒组件:我们没有源代码的组件。
但是,在调试复杂行为时,观察甚至调试引用的黑盒组件引用的逻辑。这就是为什么从16.5版本开始,Visual Studio 2019可以从编译好的程序中生成一些源代码。这样的源代码是可以调试的。这个特性是基于开源软件(OSS)工程:ILSpy(https://github.com/icsharpcode/ILSpy)。
反编译菜单可以在模块窗口的组件右键菜单(如下面的动图所示)和Source Not Found或No Symbols Loaded对话框中给出。
将IL代码反编译为源代码不可能是完美的,因为一些源代码信息在编译时丢失了。因此,这个特性有一些限制,在这个官方文档的最后会解释:Generate source code from .NET assemblies while debugging
https://docs.microsoft.com/en-us/visualstudio/debugger/decompilation?view=vs-2019
结尾
Visual Studio非常出色,在调试方面尤其出色。 在这里,我试图选择一些既隐藏又经常有用的技巧,希望它们能帮助您提高生产率。