[转载]SQL Server数据库帐号密码安全设计 – 听风吹雨 – 博客园.
一、背景
作为一个DBA,或许你有很多的系统需要管理,而且不同的系统使用了不同的数据库,通常的情况下,我们都是通过sa进行设置密码的,而且在config文件里面明文的写上我们的帐号和密码,这样的设计我们是否太大方了呢?
或许你会说,我们的数据库是安全的,因为我们的数据库是只有内网可以访问的,但是那台机器的安全性呢?因为能进入操作系统就能看到我们的帐号密码了。再加上有些时候我们不希望客户能看到数据库密码的。那么应该如何保证我们的数据库账号密码的安全性呢?
二、架构设计
针对上面的安全性问题,我设计了下面的方案,主要是运用加密算法进行加密,再通过分离一些职责,设置几道关卡,加强数据的安全性。
下面是这个方案的总体架构图:
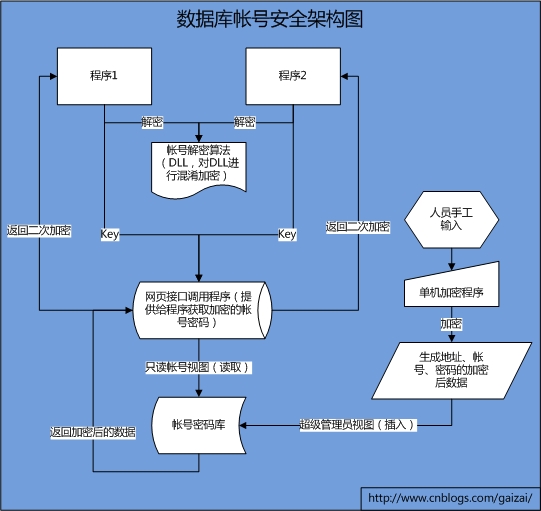
(架构图)
三、架构解析说明
1. 程序1,程序2表示我们的应用程序,在程序的config中再也没有明文的数据库帐号和密码的了,它调用一个公用的webservice,只需要传入一个唯一的key值(有DBA发布这个key值),获取数据库IP、帐号、密码;
2. 网页接口调用程序是我们提供的一个webservice,它使用只读帐号视图,查询key值所对应加密后的数据库IP、帐号、密码;如下图所示:
[LinkName] 表示key值;
[En_LinkIP]表示程序需要链接的数据库IP地址;
[En_LinkSa]表示数据库使用的帐号;
[En_LinkPassword]表示数据库帐号所对应的密码;
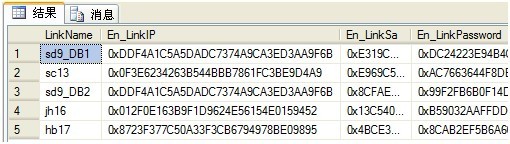
(只读账号视图)
3. 把上图获取到的数据返回给网页接口调用程序,把这些值以|符号进行串联成一个字符串,再进行二次加密(使用不同的加密算法);再把加密后的字符串返回给程序1、程序2;
4. 当程序拿到这些加密后的字符串后,使用我们发布的DLL进行解密,这里的解密包括两个解密算法,把解密后的值返回给程序;
5. 那这些记录是怎么录入的呢?你猜对了,那就是DBA,DBA收集这些帐号和密码进行管理,只要开发人员告知数据库的相关信息(或许根本就不需要,因为部署是DBA的事情,或许开发人员根本就不需要知道这个数据库在哪里),我就使用单机机密程序,加密我们的数据库IP、帐号、密码,并生成唯一的key值,把这个key告诉开发人员。
把加密后的数据插入到数据库;超级管理员视图如下图所示:

(超级管理员视图)
四、特别说明
1. 就安全性考虑,LinkIP的值尽量能使用端口进行设置,修改默认的1433端口;
2. 虽然在程序中可以获取到明文的帐号密码,但是这比明文写在config上要安全很多倍了;
3. 对字符串进行二次加密是为了防止数据的拦截的;
4. 如果网页接口调用程序给爆掉了,拿到的数据还是加密后的数据;而且这个帐号是只读数据的,是没有insert、update、delete的权限的;
5. 有这个超级管理员帐号,这个帐号可以只有为数几个人知道,与网页接口调用程序的数据库帐号是完全分离的;
6. 程序中可能需要在使用帐号密码的时候需要捕获一下异常,就是当我们DBA修改了帐号密码后引起的链接异常;
7. 这个帐号表中,我们可以通过State字段进行控制这个帐号是否可用(甚至你可以直接删掉这条记录),这样当我们的业务系统泄漏了数据帐号的时候,我们可以很快速的修改帐号密码,不需要通知开发人员去修改config文件;
8. 只读账号视图现在只是简单的MD5加密,你完全可以设计自己算法;
9. LinkName是需要唯一的,所以在表设计的时候是使用了这个作为主键的;
10. 其实上面的设计我是为了体现出只读帐号视图和超级管理员视图的区别的;可以参考:SQL Server 2005控制用户权限访问表,其实你完全可以让网页接口调用程序调用数据库的config的帐号密码也进行一次加密,让程序去解密,这样只需要做一次就够了。
五、SQL代码
—创建表
CREATE TABLE [dbo].[LinkConfigTest](
[Id] [int] IDENTITY(1,1) NOT NULL,
[LinkName] [nvarchar](50) NOT NULL,
[LinkIP] [varchar](50) NULL,
[LinkSa] [varchar](50) NULL,
[LinkPassword] [varchar](50) NULL,
[Description] [nvarchar](100) NULL,
[State] [int] NULL CONSTRAINT [DF_LinkConfigT_State] DEFAULT ((0)),
[StateDescription] [nvarchar](50) NULL,
[HostName] [nvarchar](50) NULL,
[CreateTime] [datetime] NULL,
[En_LinkIP] [varchar](50) NULL,
[En_LinkSa] [varchar](50) NULL,
[En_LinkPassword] [varchar](50) NULL,
CONSTRAINT [PK_LinkConfigT] PRIMARY KEY NONCLUSTERED
(
[LinkName] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
—插入测试数据
INSERT [LinkConfigTest] ([LinkName],[LinkIP],[LinkSa],[LinkPassword],[Description],[State],[HostName],[CreateTime],[En_LinkIP],[En_LinkSa],[En_LinkPassword]) VALUES ( ‘sd9_DB1’,‘192.168.1.147,14339’,‘sd158admin’,‘sd158admin+-987’,‘内网_DB1′,1,‘SERVR9’,‘2012-3-7 14:08:52’,‘0xddf4a1c5a5dadc7374a9ca3ed3aa9f6b’,‘0xe319cb7bedd3b0d400c3da3484c6a6e3’,‘0xdc24223e94b4c4d754cfc40230680156’)
INSERT [LinkConfigTest] ([LinkName],[LinkIP],[LinkSa],[LinkPassword],[Description],[State],[HostName],[CreateTime],[En_LinkIP],[En_LinkSa],[En_LinkPassword]) VALUES ( ‘sc13’,‘192.168.1.25,13433’,‘sc13admin’,‘sc13adminasdfg’,‘内网_DB1′,1,‘BAREOT-4’,‘2012-3-7 14:08:52’,‘0x0f3e6234263b544bbb7861fc3be9d4a9’,‘0xe969c53b6c44990ac38a92f1c6ad2d97’,‘0xac7663644f8de76a3da122257a6593ea’)
INSERT [LinkConfigTest] ([LinkName],[LinkIP],[LinkSa],[LinkPassword],[Description],[State],[StateDescription],[HostName],[CreateTime],[En_LinkIP],[En_LinkSa],[En_LinkPassword]) VALUES ( ‘sd9_DB2’,‘192.168.1.147,14339’,‘gd14admin’,‘sc13admin#$’,‘内网_DB2′,0,‘停用‘,‘SERVR9’,‘2012-3-7 14:08:52’,‘0xddf4a1c5a5dadc7374a9ca3ed3aa9f6b’,‘0x8cfaec93141b6fb3fc5de4cef40c8648’,‘0x99f2fb6b0f14d47fa725a79c62ae60c3’)
INSERT [LinkConfigTest] ([LinkName],[LinkIP],[LinkSa],[LinkPassword],[Description],[State],[HostName],[CreateTime],[En_LinkIP],[En_LinkSa],[En_LinkPassword]) VALUES ( ‘jh16’,‘192.168.1.30,16433’,‘jh16admin’,‘sc13admin$%as’,‘内网_DB1′,1,‘SERVR16’,‘2012-3-7 14:08:52’,‘0x012f0e163b9f1d9624e56154e0159452’,‘0x13c540aff4fe6d61f48de0e097fd1c66’,‘0xb59032aaffddc07b72d9958359a5da97’)
INSERT [LinkConfigTest] ([LinkName],[LinkIP],[LinkSa],[LinkPassword],[Description],[State],[HostName],[CreateTime],[En_LinkIP],[En_LinkSa],[En_LinkPassword]) VALUES ( ‘hb17’,‘192.168.1.35,17433’,‘hb17admin’,‘sc13admin$%asdf’,‘内网_DB5′,1,‘BAEF-1’,‘2012-3-7 14:08:52’,‘0x8723f377c50a33f3cb6794978be09895’,‘0x4bce38f66dfba3f8779f070636a6a70d’,‘0x8cab2ef5b6a6c5c48d499c5ef84c3436’)




























