- SQLite不支持对列的改名和修改类型等操作,想要操作官方给出的方法是先备份原表数据到临时表,然后删除原表,再创建新的表结构,然后导入临时表的数据,官方解释如下:(11) How do I add or delete columns from an existing table in SQLite.
SQLite has limited ALTER TABLE support that you can use to add a column to the end of a table or to change the name of a table. If you want to make more complex changes in the structure of a table, you will have to recreate the table. You can save existing data to a temporary table, drop the old table, create the new table, then copy the data back in from the temporary table.
For example, suppose you have a table named “t1” with columns names “a”, “b”, and “c” and that you want to delete column “c” from this table. The following steps illustrate how this could be done:
BEGIN TRANSACTION; CREATE TEMPORARY TABLE t1_backup(a,b); INSERT INTO t1_backup SELECT a,b FROM t1; DROP TABLE t1; CREATE TABLE t1(a,b); INSERT INTO t1 SELECT a,b FROM t1_backup; DROP TABLE t1_backup; COMMIT;
- 推荐几个学习SQLite有用的官方链接:
http://www.sqlite.org/syntaxdiagrams.html#column-def
http://www.sqlite.org/faq.html#q11

[原创]SQLite学习笔记:ALTER TABLE操作限制
- SQLite不支持对列的改名和修改类型等操作,想要操作官方给出的方法是先备份原表数据到临时表,然后删除原表,再创建新的表结构,然后导入临时表的数据,官方解释如下:(11) How do I add or delete columns from an existing table in SQLite.
SQLite has limited ALTER TABLE support that you can use to add a column to the end of a table or to change the name of a table. If you want to make more complex changes in the structure of a table, you will have to recreate the table. You can save existing data to a temporary table, drop the old table, create the new table, then copy the data back in from the temporary table.
For example, suppose you have a table named “t1” with columns names “a”, “b”, and “c” and that you want to delete column “c” from this table. The following steps illustrate how this could be done:
BEGIN TRANSACTION; CREATE TEMPORARY TABLE t1_backup(a,b); INSERT INTO t1_backup SELECT a,b FROM t1; DROP TABLE t1; CREATE TABLE t1(a,b); INSERT INTO t1 SELECT a,b FROM t1_backup; DROP TABLE t1_backup; COMMIT;
[转载]SQLite 入门教程(三)好多约束 Constraints
[转载]SQLite 入门教程(三)好多约束 Constraints – 左洸 – 博客园.
一、约束 Constraints在上一篇随笔的结尾,我提到了约束, 但是在那里我把它翻译成了限定符,不太准确,这里先更正一下,应该翻译成约束更贴切一点。 那么什么是约束呢? 我们在数据库中存储数据的时候,有一些数据有明显的约束条件。 比如一所学校关于教师的数据表,其中的字段列可能有如下约束:
上面提到的大于、默认、不能为空、唯一等等,就是数据的约束条件。 我们在用 CREATE TABLE 创建表的时候,就应该将每个字段列的约束条件事先说明(如果有的话), 以后再往表里输入数据的时候,系统会自动为我们检查是否满足约束条件,如果不满足系统会报错。 |
SQLite 常用约束如下
- NOT NULL – 非空
- UNIQUE – 唯一
- PRIMARY KEY – 主键
- FOREIGN KEY – 外键
- CHECK – 条件检查
- DEFAULT – 默认
二、主键 PRIMARY KEY
我们还是进入 SQLite 命令行环境,建立一个 test.db 数据库用来做实验,如下:
myqiao@ubuntu:~/My Documents/db$ sqlite3 test.db
-- Loading resources from /home/myqiao/.sqliterc
SQLite version 3.7.4
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite> .tables
sqlite>
[/sql]
运行 .tables 命令没有返回,说明数据库是空的。如果你的数据库里面有内容并影响到下面的实验, 你可以用我们上一篇学的 DROP TABLE 来删除造成影响的表, 或者用 ALTER TABLE ... RENAME TO ... 来改名。
<hr />下面言归正转,我们来说说主键 PRIMARY KEY 。
<ul>
<li>首先,数据表中每一条记录都有一个主键, 这就像我们每的身份证号码、员工号、银行帐号; 反过来也可以说,每一个主键对应着一条数据记录。 所以,主键必须是唯一的。</li>
<li>其次,一般情况下主键同时也是一个索引,所以通过主键查找记录速度比较快。</li>
<li>第三,在关系型数据库中,一个表的主键可以作为另外一个表的外键, 这样,这两个表之间就通过这个键建立了关系。</li>
<li>最后,主键一般是整数或者字符串,只要保证唯一就行。 在 SQLite 中,主键如果是整数类型,该列的值可以自动增长。</li>
</ul>
<hr />下面我们来做实验:
sqlite>
sqlite> CREATE TABLE Teachers(Id integer PRIMARY KEY,Name text);
sqlite> .tables
Teachers
sqlite> INSERT INTO Teachers(Name) Values('张三');
sqlite> INSERT INTO Teachers(Name) Values('李四');
sqlite> INSERT INTO Teachers(Name) Values('王二麻子');
sqlite> SELECT * FROM Teachers;
Id Name
---------- ----------
1 张三
2 李四
3 王二麻
sqlite> INSERT INTO Teachers(Id,Name) Values(2,'孙悟空');
Error: PRIMARY KEY must be unique
sqlite>
我们先新建了一个 Teachers 表,并设置了两个字段列,其中 Id 字段列为主键列。 然后,我们向其中插入三条数据并查询,反馈一切正常。
注意:在插入前三条数据的时候,命令中并没有明确指明 Id 的值,系统自动赋值,并且数值自动增长。
插入第四条数据的时候,我给了一个明确的 Id 编号为 2,因为李四的编号已经是 2 了, 所以系统提示我错误:主键必须唯一。
三、默认值 DEFAULT
有一些特别的字段列,在每一条记录中,他的值基本上都是一样的。只是在个别情况下才改为别的值,这样的字段列我们可以给他设一个默认值。
下面我们来做实验:
sqlite>
sqlite> DROP TABLE Teachers;
sqlite> .tables
sqlite>
sqlite> CREATE TABLE Teachers(Id integer PRIMARY KEY,Name text,Country text DEFAULT '中国');
sqlite> .tables
Teachers
sqlite> INSERT INTO Teachers(Name) Values('张三');
sqlite> INSERT INTO Teachers(Name) Values('李四');
sqlite> INSERT INTO Teachers(Name) Values('王二麻子');
sqlite> INSERT INTO Teachers(Name,Country) Values('孙悟空','天庭');
sqlite> SELECT * FROM Teachers;
Id Name Country
---- --------------- ---------------
1 张三 中国
2 李四 中国
3 王二麻子 中国
4 孙悟空 天庭
sqlite>
先把之前的 Teachers 表删除,然后重新创建。这回 Teachers 表多了一个 Country 字段, 并且设置默认值为“中国”,然后我们插入四条数据到 Teachers 表。
前三条数据都没有明确指明 Country 字段的值,只有第四条数据指明了“孙悟空”的 Country 为“天庭”。
查询数据,发现前三条数据都填上了默认值,实验成功。
数据显示有点走样,命令 .width 4 15 15 设置的列宽,可以通过 .show 查看, 可能是因为中文的原因,所以没有对齐。
四、非空 NOT NULL
有一些字段我们可能一时不知到该填些什么,同时它也没设定默认值, 当添加数据时,我们把这样的字段空着不填,系统认为他是 NULL 值。
但是还有另外一类字段,必须被填上数据,如果不填,系统就会报错。 这样的字段被称为 NOT NULL 非空字段,需要在定义表的时候事先声明。
下面我们来做实验
sqlite>
sqlite> DROP TABLE Teachers;
sqlite> .tables
sqlite>
sqlite> CREATE TABLE Teachers(Id integer PRIMARY KEY,Name text,Age integer NOT NULL,City text);
sqlite> .tables
Teachers
sqlite> INSERT INTO Teachers(Name,Age) Values('Alice',23);
sqlite> INSERT INTO Teachers(Name,Age) Values('Bob',29);
sqlite> INSERT INTO Teachers(id,Name,Age) Values(6,'Jhon',36);
sqlite> SELECT * FROM Teachers;
Id Name Age City
---- --------------- --------------- ---------------
1 Alice 23 NULL
2 Bob 29 NULL
6 Jhon 36 NULL
sqlite> INSERT INTO Teachers(Name) Values('Mary');
Error: Teachers.Age may not be NULL
sqlite>
还是先删除旧表,创建新表。
这回 Teachers 表声明了一个 NOT NULL 字段 Age,同时还有一个可以为 NULL 的字段 City
插入前三条数据都没有指定 City 的值,查询可以看到 City 字段全部为空
注意:这里的 NULL 只是对“什么都没有”的一种显示形式, 可以通过 .nullvalue 命令改为别的形式,具体见第一篇
插入第四条数据时没有指定 Age 的值,系统就报错了: Teachers.Age 不能为空
五、 唯一 UNIQUE
这一约束很好理解,除了主列以为,还有一些列也不能有重复值。不多说,直接看代码:
sqlite>
sqlite> DROP TABLE Teachers;
sqlite> .tables
sqlite>
sqlite> CREATE TABLE Teachers(Id integer PRIMARY KEY,Name text UNIQUE);
sqlite> .tables
Teachers
sqlite> INSERT INTO Teachers(Name) VALUES('Alice');
sqlite> INSERT INTO Teachers(Name) VALUES('Bob');
sqlite> INSERT INTO Teachers(Name) VALUES('Jane');
sqlite> INSERT INTO Teachers(Name) VALUES('Bob');
Error: column Name is not unique
sqlite>
这次的 Teachers 表只有 Name 这一列,但是 Name 列不能有重复值。可以看到,到我们第二次插入 Bob 时,系统就报错了。
六、 条件检查 CHECK
某些值必须符合一定的条件才允许存入,这是就需要用到这个 CHECK 约束。
sqlite> sqlite> DROP TABLE Teachers; sqlite> .tables sqlite> sqlite> CREATE TABLE Teachers(Id integer PRIMARY KEY,Age integer CHECK(Age>22)); sqlite> .tables Teachers sqlite> INSERT INTO Teachers(Age) VALUES(45); sqlite> INSERT INTO Teachers(Age) VALUES(33); sqlite> INSERT INTO Teachers(Age) VALUES(23); sqlite> INSERT INTO Teachers(Age) VALUES(21); Error: constraint failed sqlite>
Age 字段要求必须大于 22,当插入的数据小于22时,系统报错。
七、外键 FOREIGN KEY
现在,我们的数据库中已经有 Teachers 表了,假如我们再建立一个 Students 表, 要求 Students 表中的每一个学生都对应一个 Teachers 表中的教师。
很简单,只需要在 Students 表中建立一个 TeacherId 字段,保存对应教师的 Id 号, 这样,学生和教师之间就建立了关系。
问题是:我们有可能给学生存入一个不在 Teachers 表中的 TeacherId 值, 而且发现不了这个错误。
这种情况下,可以把 Students 表中 TeacherId 字段声明为一个外键, 让它的值对应到 Teachers 表中的 Id 字段上。
这样,一旦在 Students 表中存入一个不存在的教师 Id ,系统就会报错。
sqlite> sqlite> .tables Teachers sqlite> CREATE TABLE Students (Id integer PRIMARY KEY, TeacherId integer, FOREIGN KEY(TeacherId) REFERENCES Teachers(id) ); sqlite> .tables Students Teachers sqlite> SELECT * FROM Teachers; Id Age ---- --------------- 1 40 2 33 3 23 sqlite> INSERT INTO Students(TeacherId) VALUES(1); sqlite> INSERT INTO Students(TeacherId) VALUES(3); sqlite> INSERT INTO Students(TeacherId) VALUES(9); sqlite> SELECT * FROM Students; Id TeacherId ---- --------------- 1 1 2 3 3 9 sqlite>
这里建立了 Students 表,并且把 TeacherId 作为外键与 Teachers 表的 Id 列相对应。
问题来了:插入的前两条数据没问题,因为 Id 编号 1、3 都在 Teachers 表中; 但是数字 9 并不在 Teachers 表中,不但没有报错,系统还保存进去了,这是为什么呢?
据说 SQLite 的外键约束默认情况下并不是开启的,如果你需要这个功能,你可能需要下载源代码版本,设置每个编译参数,然后重新编译,这样你就得到支持外键的 SQLite 了。
[转载]SQLite 入门教程(二)创建、修改、删除表
[转载]SQLite 入门教程(二)创建、修改、删除表 – 左洸 – 博客园.
一、数据库定义语言 DDL在关系型数据库中,数据库中的表 Table、视图 View、索引 Index、关系 Relationship 和触发器 Trigger 等等,构成了数据库的架构 Schema。 在 SQL 语句中,专门有一些语句用来定义数据库架构,这些语句被称为“数据库定义语言”,即 DDL。 SQLite 数据库引擎支持下列三种 DDL 语句:
其中,CREATE 语句用来创建表 Table、视图 View、索引 Index、关系 Relationship 和触发器 Trigger, DROP语句用来删除表 Table、视图 View、索引 Index、关系 Relationship 和触发器 Trigger, ALTER TABLE 语句用来改变表的结构。 今天这一篇只涉及到表的相关内容,视图、触发器等到后面再讲。 |
二、SQLite 中的数据类型
SQLite 数据库中的数据一般由以下几种常用的数据类型组成:
- NULL – 空值
- INTEGER – 有符号整数
- REAL – 浮点数
- TEXT – 文本字符串
- BLOB – 二进制数据,如图片、声音等等
SQLite 也可以接受其他数据类型。
三、创建表 CREATE TABLE
首先,创建一个 test.db 数据库并进入 SQLite 命令行环境,还记得怎么做吗?
myqiao@ubuntu:~$ sqlite3 test.db -- Loading resources from /home/myqiao/.sqliterc SQLite version 3.7.4 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> .tables sqlite>
向上面这样,我们就在终端中创建了一个 test.db 数据库, 并且通过 .tables 命令查询数据库中的表,结果没有任何返回, 因为数据库本来就是空的嘛。
下面我们创建一个 Student 表,其中包含 Id、Name、Age 等字段.
sqlite> sqlite> CREATE TABLE Students(Id integer,Name text,age integer); sqlite> .tables Students sqlite> .schema Students CREATE TABLE Students(Id integer,Name text,age integer); sqlite>
向上面这样,一个 Students 表就被建立了,这回再运行 .tables 命令就有响应了, 系统告诉我们数据库中现在有一个 Students 表, 运行 .schema 命令,返回了我们创建这个表的 SQL 命令。
四、修改表 ALTER TABLE
SQLite 仅仅支持 ALTER TABLE 语句的一部分功能, 我们可以用 ALTER TABLE 语句来更改一个表的名字,也可向表中增加一个字段(列), 但是我们不能删除一个已经存在的字段,或者更改一个已经存在的字段的名称、数据类型、限定符等等。
- 改变表名 – ALTER TABLE 旧表名 RENAME TO 新表名
- 增加一列 – ALTER TABLE 表名 ADD COLUMN 列名 数据类型 限定符
下面我们来演示一下,将前面的 Students 表的名字改为 Teachers
sqlite> sqlite> .tables Students sqlite> ALTER TABLE Students RENAME TO Teachers; sqlite> .tables Teachers sqlite>
原来数据库中只有一个 Students 表,改名以后再运行 .tables 命令,发现 Students 表已经没了,现在变成了 Teachers 表。
下面改变 Teachers 表的结构,增加一个 Sex 列
sqlite> sqlite> .schema Teachers CREATE TABLE "Teachers"(Id integer,Name text,age integer); sqlite> ALTER TABLE Teachers ADD COLUMN Sex text; sqlite> .schema Teachers CREATE TABLE "Teachers"(Id integer,Name text,age integer, Sex text); sqlite>
五、删除表 DROP TABLE
删除一个表很简单,只要给出表名即可
- 删除表 – DROP TABLE 表名
下面,我们将 test.db 中的 Teachers 表删除
sqlite> sqlite> .tables Teachers sqlite> DROP TABLE Teachers; sqlite> .tables sqlite>
删除 Teachers 表后再运行 .tables 命令,发现数据库已经空了。
六、后续内容
其实创建一个表远没有这么简单,表的每一列可以有很多限定符,比如主列、非空、限制、默认值、唯一、键等等,这些内容留到下一篇吧
[转载]SQLite 入门教程(一)基本控制台(终端)命令
[转载]SQLite 入门教程(一)基本控制台(终端)命令 – 左洸 – 博客园.
| 一、基本简介
SQLite 数据库引擎实现了主要的 SQL-92 标准,引擎本身只有一个文件,大小不到 300k ,但是并不作为一个独立的进程运行,而是动态或者静态的链接到其他应用程序中。它生成的数据库文件是一个普通的磁盘文件,可以放置在任何目录下。 SQLite 本身是 C 语言开发的,开源也跨平台,并且被所有的主流编程语言支持。 相关资源
|
二、下载安装
Windows 版的下载地址为:sqlite-shell-win32-x86-3070701.zip
我们这里下载的是命令行版本,所以是一个可执行文件,还有一个动态链接库版本,如果你的应用程序需要嵌入式数据库,可以下载这个版本。当然,如 果你愿意折腾,下载源代码自己编译也是可以的。下载完成,解压出来就一个文件: sqlite3.exe ,可以放置到任意一个路径下,然后把这个路径加入到 PATH 环境变量中,这样我们就可以随时在控制台中运行 SQLite 命令行工具了。
三、基本命令
1、进入命令行环境:sqlite3
打开一个控制台窗口,输入 sqlite3 回车,这时你就进入了 SQLite 命令行环境,如图
它显示了版本号,并告诉你每一条 SQL 语句必须用分号 ; 结尾
2、命令行帮助:.help
在命令行环境下输入 .help 回车,显示所有可使用的命令以及这些命令的帮助。注意:所有的命令开头都是一个点
3、退出命令行环境
.quit 或者 .exit 都可以退出
四、数据库和表的相关命令
1、创建一个新的数据库:sqlite3 文件名
先建立一个 Db 目录,并在 Db 目录中创建一个 test.db 数据库文件,打开控制台窗口,命令如下:
mkdir Db
cd Db
sqlite3 test.db
2、打开一个已经存在的数据库:sqlite3 已经存在的文件名
创建一个新数据库和打开一个已经存在的数据库命令是一模一样的,如果文件在当前目录下不存在,则新建;如果存在,则打开。
3、导入数据:.read 数据文件
打开记事本,并将下列 SQL 语句复制到记事本中,保存为 test.sql 到上面说到的 Db 目录下,在命令行环境中输入
.read test.sql
即将所有的数据导入到 test.db 数据库中。
BEGIN TRANSACTION;
CREATE TABLE Cars(Id integer PRIMARY KEY, Name text, Cost integer);
INSERT INTO Cars VALUES(1,'Audi',52642);
INSERT INTO Cars VALUES(2,'Mercedes',57127);
INSERT INTO Cars VALUES(3,'Skoda',9000);
INSERT INTO Cars VALUES(4,'Volvo',29000);
INSERT INTO Cars VALUES(5,'Bentley',350000);
INSERT INTO Cars VALUES(6,'Citroen',21000);
INSERT INTO Cars VALUES(7,'Hummer',41400);
INSERT INTO Cars VALUES(8,'Volkswagen',21600);
COMMIT;
BEGIN TRANSACTION;
CREATE TABLE Orders(Id integer PRIMARY KEY, OrderPrice integer CHECK(OrderPrice>0),
Customer text);
INSERT INTO Orders(OrderPrice, Customer) VALUES(1200, "Williamson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(200, "Robertson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(40, "Robertson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(1640, "Smith");
INSERT INTO Orders(OrderPrice, Customer) VALUES(100, "Robertson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(50, "Williamson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(150, "Smith");
INSERT INTO Orders(OrderPrice, Customer) VALUES(250, "Smith");
INSERT INTO Orders(OrderPrice, Customer) VALUES(840, "Brown");
INSERT INTO Orders(OrderPrice, Customer) VALUES(440, "Black");
INSERT INTO Orders(OrderPrice, Customer) VALUES(20, "Brown");
COMMIT;
BEGIN TRANSACTION;
CREATE TABLE Friends(Id integer PRIMARY KEY, Name text UNIQUE NOT NULL,
Sex text CHECK(Sex IN ('M', 'F')));
INSERT INTO Friends VALUES(1,'Jane', 'F');
INSERT INTO Friends VALUES(2,'Thomas', 'M');
INSERT INTO Friends VALUES(3,'Franklin', 'M');
INSERT INTO Friends VALUES(4,'Elisabeth', 'F');
INSERT INTO Friends VALUES(5,'Mary', 'F');
INSERT INTO Friends VALUES(6,'Lucy', 'F');
INSERT INTO Friends VALUES(7,'Jack', 'M');
COMMIT;
BEGIN TRANSACTION;
CREATE TABLE IF NOT EXISTS Customers(CustomerId integer PRIMARY KEY, Name text);
INSERT INTO Customers(Name) VALUES('Paul Novak');
INSERT INTO Customers(Name) VALUES('Terry Neils');
INSERT INTO Customers(Name) VALUES('Jack Fonda');
INSERT INTO Customers(Name) VALUES('Tom Willis');
CREATE TABLE IF NOT EXISTS Reservations(Id integer PRIMARY KEY,
CustomerId integer, Day text);
INSERT INTO Reservations(CustomerId, Day) VALUES(1, '2009-22-11');
INSERT INTO Reservations(CustomerId, Day) VALUES(2, '2009-28-11');
INSERT INTO Reservations(CustomerId, Day) VALUES(2, '2009-29-11');
INSERT INTO Reservations(CustomerId, Day) VALUES(1, '2009-29-11');
INSERT INTO Reservations(CustomerId, Day) VALUES(3, '2009-02-12');
COMMIT;
BEGIN TRANSACTION;
CREATE TABLE Names(Id integer, Name text);
INSERT INTO Names VALUES(1,'Tom');
INSERT INTO Names VALUES(2,'Lucy');
INSERT INTO Names VALUES(3,'Frank');
INSERT INTO Names VALUES(4,'Jane');
INSERT INTO Names VALUES(5,'Robert');
COMMIT;
BEGIN TRANSACTION;
CREATE TABLE Books(Id integer PRIMARY KEY, Title text, Author text,
Isbn text default 'not available');
INSERT INTO Books VALUES(1,'War and Peace','Leo Tolstoy','978-0345472403');
INSERT INTO Books VALUES(2,'The Brothers Karamazov',
'Fyodor Dostoyevsky','978-0486437910');
INSERT INTO Books VALUES(3,'Crime and Punishment',
'Fyodor Dostoyevsky','978-1840224306');
COMMIT
4、列出所有的数据表: .tables
完成上面所有的工作以后,我们就可以列出所有的数据表了

5、显示数据库结构:.schema
其实就是一些 SQL 语句,他们描述了数据库的结构,如图
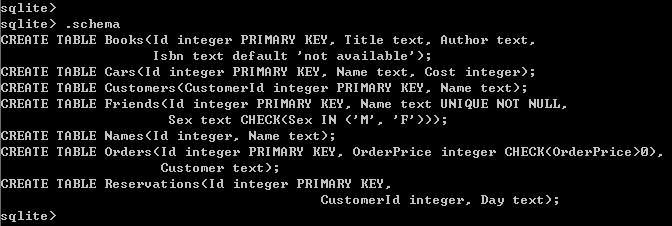
6、显示表的结构:.schema 表名
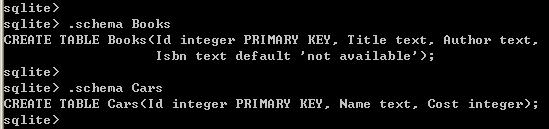
7、导出某个表的数据: .dump 表名
这时我们可以看到,整个表以 SQL 语句的形式为导出来了,但是只是显示在终端上,如何把它导出到文件中呢?
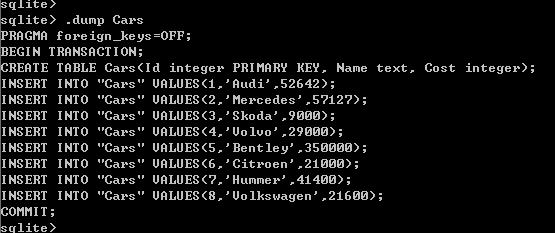
8、设置导出目标:
.output 文件名
或者
.output stdout
先运行 .output cars.sql ,然后再运行 .dump 命令试试看?如果要回复成导出到终端(标准输出),则运行 .output stdout
五、数据显示相关命令
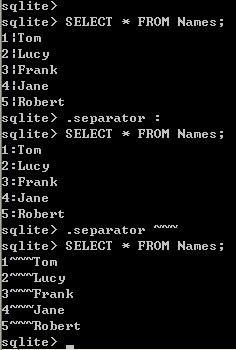
1、设置分隔符:.separator 分隔符
我们可以首先运行 SELECT * FROM Names; ,可以看到默认的分隔符是 |
运行.separator : 以后,再 SELECT * FROM Names;,可以看到分隔符已经变成 : 了
2、设置显示模式:.mode 模式
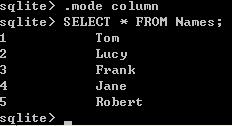
有好几种显示模式,默认的是 list 显示模式,一般我们使用 column 显示模式,还有其他几种显示模式可以 .help 看 mode 相关内容。看看下面的图,和上面是不是显示的不一样了?
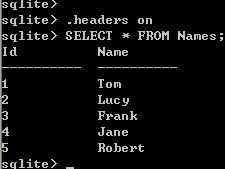
3、显示标题栏:.headers on
看看,是不是又不太一样了?
4、设置每一列的显示宽度:.width w1,w2,w3………
一些内容,默认的宽度显示不下,这个命令就有用了
5、设置 NULL 值显示成什么样子: .nullvalue 你想要的NULL值格式
默认情况下NULL值什么也不显示,你可以设置成你自己想要的样子

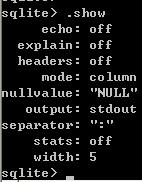
6、列出当前显示格式设置情况:.show
7、配置文件 .sqliterc
如果我们每次进入命令行都要重新设置显示格式,很麻烦,其实 .show 命令列出的所有设置项都可以保存到一个 .sqliterc 文件中,这样每次进入命令行就自动设置好了。.sqlterc 文件在 Linux 下保存在用户的 Home 目录下,在 Windows 下可以保存到任何目录下,但是需要设置环境变量让数据库引擎能找到它,感兴趣的可以看看帮助。
[转载].NET实现之(自己动手写高内聚插件系统)
[转载].NET实现之(自己动手写高内聚插件系统) – 南京.王清培 – 博客园.
今天跟大家分享一下本人在“.NET简谈构件系统开发模式”一文中提到的软件架构设计思路的具体实现细节。
大家看了我这篇文章后,总问我为什么要起个这么怪异的名字“构件”而不用“插件”。其实这个名字在我脑子漂浮了很久,一直找不到合适的场合用它。
在一本书上是这样解释构件的:构件是可以更换的部件,并且这个部件是由一系列很小的部件组成,同样这些小的部件由更小的部件组成;我为什么要区分插 件与构件主要原因是这两个名字所表达的思想不同。插件是可插、可卸的过程,没有强调无限极的递归实现子插件的意思,所以本人将其区分开来;当然也可以将这 两种架构用同一名词描述,其实是大同小异了。下面我给大家带来怎么用这种设计思路来开发具体的系统。[王清培版权所有,转载请给出署名]
一:问题分析
在进行开发之前我们需要对整个系统有个分析,插件系统所强调的核心思想是能让所开发出来的系统应变日常需求,在功能升级的时候能很方便的进行更新。 但这不是插件系统的最大的好处,我们用传统的三层、MVC开发也能实现这种好处,无非是将DLL文件放到目录下然后在重启就行了。
但是由于插件系统将功能点分的很细,大部分的功能在没有必要的情况下是不需要操作更新的。东西分的越小越好控制,但是开发的成本也随着控制粒度而变大。所以这个平衡点需要我们自己把握,不是所有的项目都适应这种架构。
插件系统是采用面向接口开发而不是面向类开发,在我们系统需求出来之后需要抽取功能点以进行插件抽象。这个时候就是考验一个项目的架构师的设计能力 了。设计的不好导致后期开发无法进行下去,这类问题有很多种,比如:接口定义不明确、返回类型不明确、接口的公共部分是否抽象完全,也就是基类实现的是否 合理等等;这些问题都很复杂,真正开发大型系统时,这些问题不能马虎,搞不好项目失败。从需求中抽出插件然后进行概要文档的编写、详要文档的编写。在一些 大的方面设计文档可能很实用,但是我们程序员知道,一个设计文档不能通用,不是任何系统结构都能相同的设计文档,这就牵扯到了公司的文档编写方面了。如果 设计文档无法应付这些复杂的系统结构,可以由架构师编写项目的架构设计文档,只有这样才能让开发人员一目了然,程序员才能发挥自主能动力能力,才能使项目 完美收工。
我们刚才讲了,插件系统是采用面向接口设计、开发,也就是面向对象领域所提倡的开发思想。既然我们是以面向接口设计的,那么我们的插件是完全依赖于 某些接口,就好比COM一样,你的接口不变,我就能找到你。最大的好处就是如果我的项目是需要第三方去实现的,那么我们的程序集文件DLL不需要签名,而 不能由其他人跟换的插件使用签名,这样系统显的很有柔韧性。我喜欢大师们的开发思想,将自己的项目比作大型的机器人,任何部件是可装配、可更换的。不要将 自己的项目开发的那么臃肿,那么脆弱。
插件系统对程序员的自身技术要求也是比较高的,这里面纵横交错,都是需要很深厚的技术功底的。都说这个语言好、那个语言好、只要精通什么都好。这个 时候就考验你是否真的掌握了这门语言。语言本身是为了满足某些需求而存在的,JS是为了实现HTMLDOM的交互、CSS是为了修饰HTMLDOM、 HTML是一种结构表示语言,这样语言的存在和使用都是有方向的,千万不要把语言和语言相比。由于插件自己的耦合几乎为零,这个时候我们都是通过接口进行 调用,比如:我在一个接口里面操作了某些功能,同时这些同能要能及时的反馈到另一个插件中去。这样一个小小的功能,就需要我们运用很复杂的调用关系,任何 一步处理的不到位,都会给后期的改动带来麻烦,甚至是灾难性的。
二:真实项目解析
我用了这种结构进行了系统开发,前期的构思是很头疼,但是后期的效果很不错的。
我在“.NET简谈构件系统开发模式”一文中已经进行了基本理论的分析,就不在讲了。直接用代码看吧;
1.主程序实现
在主程序要想使用某个插件的时候我们需要用统一的方法或者说是接口吧,能拿到我这个模块所对应的插件;请看代码:
/// <summary>
/// DataSourceOpen插件接口,上下文使用;
/// </summary>
BaseCome basecome;
/// <summary>
/// 打开SQLServer数据源
/// </summary>
private void Tools_SQLmenu_Click(object sender, EventArgs e)
{
basecome = NewBaseCome();
(basecome as DataSourceOpen).PassDataEvent += new PassDataHandler(FrmDbServer_PassDataEvent);
basecome.StartCome();
}
private void FrmDbServer_PassDataEvent(List<string> param, params string[] par)
{
if (par.Length > 0)
if (!IsOpenSource(par[0]))
BindTreeView(param, par);
}
这 是我的一个菜单的单击事件,这个菜单是主程序中的功能菜单,我需要在主程序中调用相对应的插件;上面的BaseCome是插件基类,实现了所有插件共同的 一些特征,便于调用和实现;我在事件中使用了一个NewBaseCome()方法,这个方式是当前窗体中的公共方法,请看代码:
/// <summary>
/// 统一获取构件基类
/// </summary>
/// <returns>BaseCome对象</returns>
private BaseCome NewBaseCome()
{
return (PlugManager.PlugKernelManager.MainEventProcess(“http://www.emed.cc/CodeBuilderStudio/Details/DataSourceOpen”) as BaseCome);
}
我通过这个公共方法获取到当前功能需要用的插 件,PlugManager.PlugKernelManager.MainEventProcess()是插件管理器中的一个共有方法,这个方法会根据 你传入的XML命名空间获取配置文件中的插件配置节点名称,你可能会问:“为什么要用这种结构的XML配置文件?”。其实我的个人习惯是使用有结构意义的 XML文件,这是其一。其二是,我必须确定插件配置文件的唯一性,由于插件系统支持第三方实现,所以我更本不知道插件的名称是什么,所以我用XML命名空 间进行规定。当我需要的时候,我直接通过XML命名空间就能获取到当前插件了。我们一起来看插件管理器的实现,请看代码:
2.插件管理器实现
/// <summary>
/// 主程序发生事件,需要启动相应构件
/// </summary>
/// <param name=”xmlnamespace”>构件所属的命名空间</param>
/// <returns>本构件加载是否成功true:成功,false失败</returns>
public static object MainEventProcess(string xmlnamespace)
{
try
{
PlugDom dom = domcollection[xmlnamespace];
if (dom == null)
throw new System.Exception(
“在系统当前上下文构件集合中未能查找出” + xmlnamespace + “命名空间构件,请检查构件配置文件LoadConfig.xml是否进行了相应的设置;”);
ComeLoadEvent(dom.Assembly);//构件初始化成功
return ReflectionDomObject(dom);//通过反射DLL文件,启动实现构件
}
catch (Exception err)
{
ComeCommonMethod.LogFunction.WritePrivateProfileString(
“MainEventProcess”, err.Source + “->” + err.TargetSite, err.Message, Environment.CurrentDirectory + “\\PlugManagerLog.ini”);
return null;
}
}
/// <summary>
/// 主程序发生事件,释放构件资源
/// </summary>
/// <param name=”comeobject”>构件对象</param>
public static void MainDisposeProcess(object comeobject)
{
try
{
(comeobject as Main.Interface.ComeBaseModule.BaseCome).Dispose();
ComeExitEvent((comeobject as Main.Interface.ComeBaseModule.BaseCome).ComeName);
}
catch (Exception err)
{
ComeCommonMethod.LogFunction.WritePrivateProfileString(
“MainDisposeProcess”, err.Source + “->” + err.TargetSite, err.Message, Environment.CurrentDirectory + “\\PlugManagerLog.ini”);
}
}
由于管理器中的代码比较多,我只找了关键的代码。其实插件管理器的主要任务是起到一个衔接的作用,在主程序中通过插件管理器获取到插件对象。
插件管理器的大概实现的功能是这样的,系统启动时读取插件配文件,将配置文件进行对象化,也就是将XML节点进行抽取形成对象,这样便于我们使用。
在用户需要某个插件的时候,我们需要将插件以基类的形式给用户,这样可以消除插件管理器与接口之间的耦合。插件管理器只针对与插件基类。请看代码:
/// <summary>
/// 内部方法,根据Assembly构件宿主程序集名称动态加载内部构件对象
/// </summary>
/// <param name=”dom”>构件文档对象模型PlugDom</param>
private static object ReflectionDomObject(PlugDom dom)
{
try
{
Assembly ass = Assembly.LoadFile(Path.Combine(_comeloadpath, dom.Assembly));
Type[] entrytype = ass.GetTypes();
foreach (Type type in entrytype)
{
//所有构件基类,查找构件的入口点
if (type.BaseType.FullName == “Main.Interface.ComeBaseModule.BaseCome”)
{
Main.Interface.ComeBaseModule.BaseCome basecome =
System.Activator.CreateInstance(type, type.FullName, _comeloadpath, DateTime.Now)
as Main.Interface.ComeBaseModule.BaseCome;
//注册事件
NoteComeLifecycleProcess(basecome);
return basecome;
}
}
throw new Exception(“为能实现” + dom.XmlNameSpace + “标识构件,请检查构件配置文件”);
}
catch (Exception err)
{
ComeCommonMethod.LogFunction.WritePrivateProfileString(
“GetDomObjectByXmlns”, err.Source + “->” + err.TargetSite, err.Message, Environment.CurrentDirectory + “\\PlugManagerLog.ini”);
return null;
}
}
/// <summary>
/// 记录所有构件共有的生命周期事件数据
/// </summary>
private static void NoteComeLifecycleProcess(Main.Interface.ComeBaseModule.BaseCome basecome)
{
basecome.ComeStartGoodsEvent += new Main.Interface.ComeBaseModule.OnStartGoodsHandler(basecome_ComeStartGoodsEvent);
basecome.ComeExitGoodsEvent += new Main.Interface.ComeBaseModule.OnExitGoodsHandler(basecome_ComeExitGoodsEvent);
basecome.ComeExceptionEvent += new Main.Interface.ComeBaseModule.OnExceptionHandler(basecome_ComeExceptionEvent);
}
这 是插件管理器中比较重要的实现代码。包括反射、事件注册都在这里。Main.Interface.ComeBaseModule.BaseCome 就是插件基类,由于所有的插件需要进行整个生命周期管理,比如释放一些非托管资源、句柄之类的。所以我要进行统一的管理。在此进行事件注册,以方便监听。 我们再看一下实现接口的插件代码:
3.插件实现
/*
*author:南京.王清培
*coding time:2011.5.28
*copyright:江苏华招网信息技术有限公司
*function:开发数据源构件实现,DataSourceOpen.Come项目;
*/
using System;
using System.Collections.Generic;
using System.Text;
using Main.Interface.ComeBaseModule;
namespace DataSourceOpen.Come
{
/// <summary>
/// 继承构件基类,没有完全实现构件,继续向下传递实现;
/// </summary>
[Main.Interface.Attribute.WheTherNextTransfer(IfNextTransfer = true,
ChildAssembly = “CodeBuilderStudio.DataSourceOpen.Childe1”,
ChildInterface = “DataSourceOpen.Interface.NextComeInterface”)]
public class ControlContent : BaseCome, Main.Interface.DataSourceOpen
{
这个插件继承了BaseCome对象,也就是插件基类。然后又实现了Main.Interface.dataSourceOpen接口,当主程序调用的时候就能拿到这个对象了。
总结:插件系统实现大概就讲完了,包扩接口、插件管理器等知识,希望能给各位需要进行插件开发的起到一个抛砖引玉的作用吧。
[转载]百度地图API:如何利用地图API制作汽车沿道路行驶的动画?
[转载]【百度地图API】如何利用地图API制作汽车沿道路行驶的动画?——如何获得道路层数据 – 酸奶小妹 – 博客园.
有几个做汽车导航的朋友问我说,他们想在地图上制作一辆车沿着道路行驶的动画。可是,百度地图的道路数据并没有公开。所以,应该怎么办呢?
一、
我们先来学习如何把百度地图“弄”出来。把下面这段代码保存为htm格式,用浏览器打开,就能看到百度地图了。
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>点沿直线运动</title>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=1.2&services=true"></script>
</head>
<body>
<div style="width:520px;height:340px;border:1px solid gray" id="container"></div>
</body>
</html>
<script type="text/javascript">
var map = new BMap.Map("container"); //创建地图容器
map.centerAndZoom(new BMap.Point(116.404, 39.915), 15); //设置中心点和地图级别
</script>
二、
再分析一下汽车导航制作者的这个需求:
1、车辆——用自定义图片的marker实现
var carMk = new BMap.Marker(pts[0],{icon:myIcon});
var myIcon = new BMap.Icon("Mario.png", new BMap.Size(32, 70), { //小车图片
//offset: new BMap.Size(0, -5), //相当于CSS精灵
imageOffset: new BMap.Size(0, 0) //图片的偏移量。为了是图片底部中心对准坐标点。
});
2、获取道路数据——虽然百度地图API并未公开道路层数据,但我们可以巧妙的“拿到”。具体请往下看。
三、
如何利用百度地图API拿到道路层的数据呢?
答案很简单:驾车导航。
首先讨论一下,为什么要用驾车导航,而不用步行和公交导航?
1、步行导航:步行导航显然能“穿越”公园、甚至小区,得到的肯定不是道路层的数据;
2、公交导航:公交导航虽然都是道路层的数据,但很局限,因为只有有公交车的地方,才有公交方案。并且,公交方法是包含了地铁线路的。
3、驾车导航:拥有所有道路层的数据,并且没有地铁、小区里、花园内这样的无效数据。
驾车导航示例:
var myP1 = new BMap.Point(116.380967,39.913285); //起点
var myP2 = new BMap.Point(116.424374,39.914668); //终点
var driving2 = new BMap.DrivingRoute(map, {renderOptions:{map: map, autoViewport: true}}); //驾车实例
driving2.search(myP1, myP2); //显示一条公交线路
四、
那么,如何获得道路层的数据呢?
我们可以想象一下,驾车导航的路线,在API中是属于折线。
折线是由无数的点构成的。
也就是说,只要找到这些点,我们就能获取道路层的数据了。
我们发现,Route里有个接口getPath,可以获得路线的地理坐标点数组。并且,以point数组的形式返回。
Route类参考:http://dev.baidu.com/wiki/map/index.php?title=Class:%E6%9C%8D%E5%8A%A1%E7%B1%BB/Route
利用创建好的驾车实例DrivingRoute,先search,得到一个驾车方案;
驾车方案中,选择第一条Route;
最后获得该Route的全部点。
注意,由于ajax的异步加载机制,我们需要利用搜索后的回调函数setSearchCompleteCallback,来进行道路数据的获得。
driving.setSearchCompleteCallback(function(){
var pts = driving.getResults().getPlan(0).getRoute(0).getPath(); //通过驾车实例,获得一系列点的数组
var paths = pts.length; //获得有几个点
}
五、
道路数据获取完毕。接下来是汽车图片的展示。可以通过改变marker的坐标点来实现,改变marker坐标的接口setPosition。
我们假设每100毫秒改变一次,利用延时函数setTimeout。
同样,由于ajax异步加载原因,需要异步给i赋值。
i=0;
function resetMkPoint(i){
carMk.setPosition(pts[i]);
if(i < paths){
setTimeout(function(){
i++;
resetMkPoint(i);
},100);
}
}
setTimeout(function(){
resetMkPoint(1);
console.log(i);
},100)
六、
接下来,可以点击这里,运行示例。
点击左侧的“开始”按钮,动画开始播放。
点击下侧的“获取代码”按钮,可得到全部源代码。
七、
最后,放出全部源代码:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>点沿直线运动</title>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=1.2&services=true"></script>
</head>
<body>
<div style="width:520px;height:340px;border:1px solid gray" id="container"></div>
<input type="button" value="开始" onclick="run();" />
</body>
</html>
<script type="text/javascript">
var map = new BMap.Map("container");
map.centerAndZoom(new BMap.Point(116.404, 39.915), 15);
var myP1 = new BMap.Point(116.380967,39.913285); //起点
var myP2 = new BMap.Point(116.424374,39.914668); //终点
var myIcon = new BMap.Icon("Mario.png", new BMap.Size(32, 70), { //小车图片
//offset: new BMap.Size(0, -5), //相当于CSS精灵
imageOffset: new BMap.Size(0, 0) //图片的偏移量。为了是图片底部中心对准坐标点。
});
var driving2 = new BMap.DrivingRoute(map, {renderOptions:{map: map, autoViewport: true}}); //驾车实例
driving2.search(myP1, myP2); //显示一条公交线路
function run(){
var driving = new BMap.DrivingRoute(map); //驾车实例
driving.search(myP1, myP2);
driving.setSearchCompleteCallback(function(){
var pts = driving.getResults().getPlan(0).getRoute(0).getPath(); //通过驾车实例,获得一系列点的数组
var paths = pts.length; //获得有几个点
var carMk = new BMap.Marker(pts[0],{icon:myIcon});
map.addOverlay(carMk);
i=0;
function resetMkPoint(i){
carMk.setPosition(pts[i]);
if(i < paths){
setTimeout(function(){
i++;
resetMkPoint(i);
},100);
}
}
setTimeout(function(){
resetMkPoint(5);
console.log(i);
},100)
});
}
</script>
[转载]分享一些我的创业心得
其实这算是第二次创业 了,第一次是两年前,以个人之力用工作业余时间做了一个免费的在线记账的网站,因为一些客观的原因没有能坚持下去,其实现在想想,没什么困难解决不了的。 这次创业虽然现在不是已经成功,但我想把我们这次创业过程中的一些心得与大家分享和讨论,希望对大家有帮助。
我想提前声明一下,我并不是忽悠大家都去创业!因为创业风险真的很大,光我见过周围的朋友失败的就不少,有的把自己所有的积蓄都赔了进去。
创业有方式和方法,我在这分享一些适合程序员创业的方法,欢迎大家提出意见。
创业不一定有了资金才能开始,也不一定要辞职
你可能会问“创业基金从哪来?”,如果是传统行业创业,比如说开一间餐厅,开一个超市,可能真是需要一比启动资金,但做互联网创业,启动资金不是必须的, 刚开始可以利用业余时间,都不用辞职。等产品基本成型了,有天使投资了或非常有信心盈利了,再辞职也不晚,这样风险也是最低的。就算创业失败了,也不会对你有什么损失,反而给了一笔巨大的财富—创业经验。在互联网这么发达的今天,创业其实也不是一件困难的事情了,现在并不是和以前一样,一定要成立公司,要有很多人才能创业,很多条件都降低了从程序员创业门槛。比如说Apple的AppStore,李开复的创新工厂等等。
自挠其痒
很多人会说没有好的想法,好的点子,其实可以做的东西真的很多。
创造一款伟大的产品或者服务的最直接、最简单的方法就是去做你自己想用的。因为自己是最了解需求是什么,怎样可以满足,并能立即明白你做的东西是否靠谱,价值多大。
我们做的产品就是为了解决自己的问题, 那时公司想找一款CRM软件来记录,跟踪销售过程,公司是个小公司,没必要自己买服务器、软件进行部署,所以SaaS的CRM应用是最合适的,在试用了国 内好几家的产品后,让我们很失望。原因很简单,注册之后基本不会 用,十几个功能菜单,好多专业词汇,一看就让人头晕,其实我们就是想找一款简单、实用的工具,解决我们的问题:比如,想关注我们商谈过的某人的动向,我们 说过什么,以及什么时候我们再跟进;这周的日程怎么安排的,明天都有哪些任务要完成。但现有的通讯录太简单,800客这样重量级的太复杂、难用,所以我们 决定自己做一个适合中小型企业用的在线CRM(我真的不想说我们做的是CRM,因为国内好多软件公司做的系统已给人们非常不好的印象)我们想把它叫做是一 个非常简单好用的联系人管理工具。
其实很多发明家都是为了解决自己遇到的问题,而发明创造的。
发明家 James Dyson 就是自挠其痒。当他在家里使用吸尘器时, 他发现真空袋吸尘器的抽吸动力总是失灵, 灰尘阻塞了袋子里的小孔,堵塞气流。这不是某人想出来的问题。 这是他真实亲身经历。所以他决定解决这个问题,于是有了世界上第一台气旋式吸尘器。
田径教练 Bill Bowerman 觉得他的队伍需要更好,更轻便的跑鞋。于是他去到车间, 把橡胶倒入家庭用的华夫烤盘里。这就是 Nike 著名的华夫鞋底的诞生。
解决你实际遇到的问题,才会让你爱上你做的事,只有做自己喜欢的事,才能把它做好。这已成为我们团队的理念了。
团队要高效
创业不一定要很多人,我们团队就只有三个人,但是最高效的。我们没有留任何空间给没有实际工作的人。在WorkXP团队里的每个人几乎都跟我们产品的某些 东西有直接的关系。从编写员编写和更新支持文档,到设计人员设计用户界面,到程序员给使用用户开发代码,都在尽自己的职责,我们没有一个拿着薪水只是去告 诉别人去做什么的议院议员。
高效的团队成员之间应该是平等的,不应该有上下级之分,不应该有审批,各自负责一部分任务并且承担起来。
比如说麦当劳,过去员工没有权利给顾客超过两包以上的番茄酱,而要请示主管,而近些年来麦当劳已经改变这种方式,员工可以自己做主了,顾客满意度高了很多。 如果每次顾客要番茄酱都要请示主管,这会高效吗?
我认为目前小公司唯一的活路就是高效率的小规模团队,这样的团队才能充分发挥小公司灵活创新的特点,才有可能在某些方面战胜大公司,也才有可能在人才竞争方面胜出。
产品是小团队的核心竞争力
一定要做出最棒的产品,哪怕这个产品功能非常少,但一定要是最好用,最简单的。
天使投资人Stevebell说过“创业公司无法和大公司比如何做市场 — 创业公司赢在“产品”上!能赢的创业公司开发“绝棒的”产品,产品成为用户们的“所爱”,因此她们在朋友中奔走相告。伟大的创业公司不花一分钱广告费,但是能开发出使用户“惊喜”的产品。”
同样是做SaaS,我们选择的是和Salesforce不一样的路线,做中国的37signals。当所有的软件提供者都在强调自己的产品功能如何多而 全,如何灵活定制,如何能满足几乎所有需求的时候,我们并没有单纯比拼功能,而是把其中最实用的功能做到最好用。实则上,软件不需要去适应所有的情况,有时候,它不能干某些事情才恰恰凸显它的价值。我们只把这一小块功能做到最简单,最方便使用,给用户带来惊喜!
贵在坚持
我第一个创业失败的原因就是没有坚持下去,现在很后悔。坚持很重 要,我的经验是,最好找到一个和你志同道合的朋友一起创业,因为这样两个人互相鼓励,互相打气,很多困难就可以慢慢解决掉。但创业时,也别太多的人,能三 个人创业就别四个人,能二个人就别三个人,否则很多精力可能会花在团队内部的事情上。
其实创业很简单,只要你决定去做,并坚持下去,那成功已经离你不远了!希望大家成功!
[转载]25个非常棒的 Photoshop 网页设计教程
[转载]25个非常棒的 Photoshop 网页设计教程 – 梦想天空(山边小溪) – 博客园.
曾经和大分享过几篇优秀的 Photoshop 网页设计教程,喜欢的人非常多。今天,本文继续向大家分享最新25个实用的 Photoshop 网页设计教程。其实,网页设计并没有你想的那么难,相信看完这些教程,你也可以设计出漂亮的网页。
1. Clean Style Portfolio Layout

2. Create an Elegant Photography Web Layout in Photoshop

3. Create a Portfolio Web Layout in Photoshop

4. How to Make a Vibrant Portfolio Web Design in Photoshop

5. Clean Blog Layout in Photoshop
6. Photo Gallery Website Layout in Photoshop

7. Create a Movie Video Streaming Website
8. How to Build a Stylish Portfolio Web Design Concept
9. Create a Modern Lab Theme Web Design in Photoshop

10. Create an Extremely Simple Dark Web Design in Photoshop
11. How to Create a Sleek Grid Based Website Design
12. How to Create a Vintage Photoshop Website Layout
13. Create a Simple Clean Portfolio Layout in Photoshop
14. 3D Portfolio Dark Layout in Photoshop
15. Design a Clean and Colorful Ecommerce Layout in Photoshop
16. Design an Innovative Portfolio Site Using Alternative UI/UX
17. Design a Sleek Mobile App Website

18. Design a Warm, Cheerful Website Interface in Adobe Photoshop
19. Impressive Videographer Website Portfolio Layout in Photoshop
20. How to Create a WordPress Theme in Photoshop
21. Design a Bold and Vibrant Portfolio
22. Create an Elegant Patterned Web Design in Photoshop

23. Design a Clean Corporate Website Layout

24. Design a Textured “Coming Soon” Web Page in Photoshop

25. How to Create a Colorful Business Web Layout

[转载]分享一些如何从:领域、对象、角色、职责、对象交互、场景等这些方面去分析和设计具有动态行为的领域模型的经验(附源码)
[转载]分享一些如何从:领域、对象、角色、职责、对象交互、场景等这些方面去分析和设计具有动态行为的领域模型的经验(附源码) – netfocus – 博客园.
好久没有写文章了,最近比较忙,另一方面也是感觉自己在这方面没什么实质性的突破。但是今天终于感觉自己小有所成,有些可以值得和大家分享的东西,并且完成了两个可以表达自己想法的Demo。因此,趁现在有点时间,是写文章和大家分享的时候了。
首先给出这两个Demo的源代码的压缩包的下载地址,因为之前有博友说他没有装VS2010而没办法运行Demo,所以这次我分别用VS2008和VS2010实现了两个版本。
http://files.cnblogs.com/netfocus/DCIBasedDDD.rar
下面先分享一下我最近研究的一些知识及我对这些知识的自我感悟,然后再结合Demo中的示例讲解如何将这些感悟应用到实际。
一.理论知识:
我最近一直在学习下面这些东西:
- 面向对象分析与设计,即Object Oriented Analysis and Design(OOA\D)
- 领域驱动设计,即Domain Driven Design(DDD)
- 四色原型:MI原型、Role原型、PPT原型、Description原型
- DCI架构:Data Context Interaction
- CQRS架构: 命令查询职责分离原则,即Command Query Responsibility Segregation
通过学习以上这些知识,让我对面向对象的分析、设计、实现有了一些新的认识。
1. 碰到一个业务系统,我们该如何分析业务,分析需求,并最后得到一个只包含业务概念的模型?答案是通过四色原型进行业务建模。四色原型的中心思想是:一个什 么什么样的人或组织或物品或地点以某种角色在某个时刻或某段时间内参与某个活动。 其中“什么什么样的”就是DESC,“人或组织或物品或地点”就是PPT,“角色”就是Role,而”某个时刻或某段时间内的某个活动”就是MI。更具体 的说明请参看我之前整理的一篇文章:http://www.cnblogs.com/netfocus/archive/2011/03/05/1971899.html
2. 业务模型建好了,该如何通过面向对象的分析与设计方法来进行对象建模呢? DDD和DCI思想可以帮助我们。首先,DDD能够指导我们建立一个静态的领域模型,该领域模型能够清楚的告诉我们建立出来的对象“是什么”,但是DDD 却不能很自然的解决“做什么”的问题。大家都知道DDD在对象设计的部分实际上是一种充血模型的方式,它强调对象不仅有属性还会有行为,如果行为是跨多个 领域对象的,则在DDD中用领域服务解决。但是DDD却没有完整的考虑对象与对象之间的交互如何完成,虽然它通过领域服务的方式协调多个对象之间进行交互 或者在应用层协调多个对象进行交互。但是在DDD中,对象往往会拥有很多不该拥有的属性或行为。在我学习了DCI架构之后,我认识到了DDD的很多不足。
以下是DCI的核心思想:
- 对象扮演某个角色进入场景,然后在场景中进行交互,场景的参与者就是对象所扮演的角色;
- 一个对象可以扮演多个角色,一个角色也可以被多个对象扮演;
- 对 象的属性和行为分为:A:核心属性和行为,这些属性或行为是不依赖于任何场景的;B: 场景属性和行为,对象通过扮演某个角色进入某个特定场景时拥有的属性或行为,一旦对象离开了这个场景,不再扮演了这个角色后,这些场景属性或行为也就不再 属于该对象了;比如人有核心的属性和行为:身高、体重、吃饭、睡觉,然后当人扮演教师的角色在教室里上课时,他则具有上课的行为,一旦回到家里,就又变成 了一个普通的人;比如一个物品,在生产时叫产品,在销售时叫商品,坏了的时候叫废品,它在不同阶段扮演不同的角色所具有的属性是不一样的;
- 场景的生命周期,场景是一个时间与空间的结合,可以理解为某个活动;一旦活动结束,则场景也就消失;
- DCI 中的D可以理解为DDD中的领域模型;场景中交互的是角色,而不是领域实体。场景属于DSL的思考层面,更接近于需求和用例。而领域也是伟大的出现,但是 不能为了领域而领域,为什么呢?因为场景是大哥用例是大哥。领域的存在是为了控制固定概念的部分,这样在某种成度上控制了一定的复杂性和提高了可控性,而 DCI则解决了可变性和需求的问题。从某种意义上来说,“领域层(在DCI中可能不会太凸显领域层,不如OLD DDD那么凸显)” 是为了DCI架构服务的。
- 角色是人类的主观意识,用于对象分析和设计阶段,但是在运行阶段,角色和对象实体是一体的,软件运行过程中只有对象,只是这些对象在参与某个活动时扮演了某个角色而已;
3. 领域驱动设计中的对象设计部分的一些要点:
-
DDD的在对象设计方面的最大贡献之处在于其实体、值对象,以及聚合边界的三个部分,通过这三个概念,我们可以将对象的静态结构设计好。
- 领域对象所包含的属性必须是只读的,只读的含义是一旦对象被创建好,则只有对象自己才能修改其属性,属性的类型可能是基本数据类型或值类型,即ValueObject;
- 领域模型设计时不应考虑ORM等技术性的东西,而应该只专注于业务,不要让你的领域模型依赖于技术性的东西;
- 领域对象的属性和方法设计时要完全根据业务的含义和需要来进行,不要动不动就把每个属性定义为get;set,这会导致领域模型的不安全;
- 仓储(Repository)不是解决让领域模型不依赖于外部数据存储的唯一方式,我觉得还有更优雅的方式那就是事件驱动;
- 设计领域模型时不要考虑分层架构方面的东西,因为领域模型与分层架构无关;
- 不 要认为领域模型可以做任何事情,比如查询。领域模型只能帮你处理业务逻辑,你不要用它来帮你做查询的工作,那不是它擅长的领地,因为它的存在目的不是为了 查询;CQRS的思想就是指导我们:命令和查询因该完全分离,领域模型适合处理命令的部分,而查询可以用其他任何的不依赖于领域模型的技术来实现,甚至可 以直接写SQL也可以;
- 分析领域模型及其对象之间的交互时,要分清什么是交互的参与者,什么是交互的驱动者,通常情况下,比如人是交互 的驱动者,而人在系统中注册的某个帐号所扮演的角色就是交互的参与者;比如我用A的图书卡去图书馆借书,则我是借书活动的驱动者,而A的图书卡对应的帐号 所扮演的借书者(Borrower)角色就是借书活动的参与者;
二.结合Demo讲解如何将理论应用到实际:
前面的介绍看起来比较枯燥,但对我来说是非常宝贵的经验积累。下面我通过一个例子分析如何运用这些知识:
以图书管理系统中的借书和还书的场景进行说明:
1. 借书场景:某个人拿着某张借书卡去图书馆借书;
2. 还书场景:某个人拿着某张借书卡去图书馆还书;
根据四色原型的分析方法,我们可以得出:某个“人”以图书借阅者的角色向图书馆借书。从这里我们可以得出三个角色:1)借阅者(Borrower);2)被借的图书(BorrowedBook);3)图书馆。那么这三个角色的扮演者对象是谁呢?其实这是问题的关键!
1) 是谁扮演了借阅者这个角色?很多人认为是走进图书馆的那个人,其实不是。 人所持的图书卡对应的那个人才是真正的借阅者角色的扮演者;试想张三用李四的图 书卡借书,借书的是谁?应该是李四,此时相当于李四被张三操控了而已;当然这里假设图书馆不会对持卡人和卡的真正拥有者进行身份核对。所以,借阅者角色的 扮演者应该是借书卡对应的帐号(借书卡帐号本质上是某个人在图书馆里系统中的镜像)。那么图书卡帐号和借阅者角色有什么区别?图书卡帐号是一个普通的领域 对象,只包含一些核心的基本的属性,如AccountNumber,Owner等;但是Borrower角色则具有借书还书的行为;
2)是谁扮演了被借的书这个角色?这个问题比较好理解,肯定是图书了。那图书和被借的图书有什么区别吗?大家都知道图书是指还没被借走的还是放在书架上的书本,而被借的书则包含了更多的含义,比如被谁借的,什么时候借的,等等;
3) 为什么图书馆也是一个角色?图书馆只是一个地点,它不管有没有参与到借书场景中,都叫图书馆,并且它的属性也不会因为参与到场景中而改变。没错!但是他确 实是一个角色,只不过它比较特殊,因为在参与到借书场景时它是“本色演出”,即它本身就是一个角色;举两个其他的例子你可能就好理解一点了:比如教室,上 课时是课堂,考试时是考场;比如土地,建造房子时是工地,种植粮食时是田地,是有可能增加依赖场景的行为和属性的。
有了场景和角色的之后,我们就可以写出角色在场景中交互的代码了。我们此时完全不用去考虑对象如何设计,更不用考虑如何存储之类的技术性东西。因为我们现在已经清晰的分析清楚1)场景参与者;2)参与者“做什么”;代码如下,应该比较好懂:
/// <summary>
/// 借阅者角色定义
/// </summary>
public interface IBorrower : IRole<UniqueId>
{
IEnumerable<IBorrowedBook> BorrowedBooks { get; } //借了哪些书
void BorrowBook(Book book);//借书行为
Book ReturnBook(UniqueId bookId);//还书行为
}
/// <summary>
/// 图书馆角色定义
/// </summary>
public interface ILibrary : IRole<UniqueId>
{
IEnumerable<Book> Books { get; }//总共有哪些书
Book TakeBook(UniqueId bookId);//书的出库
void PutBook(Book book);//书的入库
}
/// <summary>
/// 被借的书角色定义
/// </summary>
public interface IBorrowedBook : IRole<UniqueId>
{
Book Book { get; } //书
DateTime BorrowedTime { get; }//被借时间
}
/// <summary>
/// 借书场景
/// </summary>
public class BorrowBooksContext
{
private ILibrary library;//场景参与者角色1:图书馆角色
private IBorrower borrower;//借书参与者角色2:借阅者角色
public BorrowBooksContext(ILibrary library, IBorrower borrower)
{
this.library = library;
this.borrower = borrower;
}
/// <summary>
/// 启动借书场景,各个场景参与者开始进行交互
/// </summary>
public void Interaction(IEnumerable<UniqueId> bookIds)
{
foreach (var bookId in bookIds)
{
borrower.BorrowBook(library.TakeBook(bookId));//
}
}
}
/// <summary>
/// 还书场景
/// </summary>
public class ReturnBooksContext
{
private ILibrary library;
private IBorrower borrower;
public ReturnBooksContext(ILibrary library, IBorrower borrower)
{
this.library = library;
this.borrower = borrower;
}
public void Interaction(IEnumerable<UniqueId> bookIds)
{
foreach (var bookId in bookIds)
{
library.PutBook(borrower.ReturnBook(bookId));
}
}
}
接下来考虑角色扮演者如何设计与实现:
角色扮演者就是DDD中的领域对象,在这个例子中主要有:借书卡帐号(LibraryAccount)、书本(Book)、图书馆(Library);下面是这几个实体类的实现:
public class LibraryAccount : Object<UniqueId>
{
#region Constructors
public LibraryAccount(LibraryAccountState state) : this(new UniqueId(), state)
{
}
public LibraryAccount(UniqueId id, LibraryAccountState state) : base(id, state)
{
}
#endregion
public string Number { get; private set; }
public string OwnerName { get; private set; }
}
public class Book : Object<UniqueId>
{
#region Constructors
public Book(BookState state) : this(new UniqueId(), state)
{
}
public Book(UniqueId id, BookState state) : base(id, state)
{
}
#endregion
public string BookName { get; private set; }
public string Author { get; private set; }
public string Publisher { get; private set; }
public string ISBN { get; private set; }
public string Description { get; private set; }
}
public class Library : Object<UniqueId>, ILibrary
{
private List<Book> books = new List<Book>();
public Library(LibraryState state) : this(new UniqueId(), state)
{
}
public Library(UniqueId id, LibraryState state) : base(id, state)
{
if (state != null && state.Books != null)
{
this.books = new List<Book>(state.Books);
}
}
[Mannual]
public IEnumerable<Book> Books
{
get
{
return books.AsReadOnly();
}
}
public Book TakeBook(UniqueId bookId)
{
var book = books.Find(b => b.Id == bookId);
books.Remove(book);
return book;
}
public void PutBook(Book book)
{
books.Add(book);
}
}
以上几个实体类还有很多细节的东西需要说明,但暂时不是重点。大家可以慢慢体会为什么我要这样设计这些类,比如属性为什么是只读的?
好了,理论上有了角色扮演者、角色,以及场景后,我们就可以写出借书和还书的完整过程了。代码如下:
private static void BorrowReturnBookExample()
{
//创建图书馆
var library = new Library(null);
Repository.Add<Library>(library);
//创建5本书
var book1 = new Book(new BookState {
BookName = "C#高级编程",
Author = "Jhon Smith",
ISBN = "56-YAQ-23452",
Publisher = "清华大学出版社",
Description = "A very good book." });
var book2 = new Book(new BookState {
BookName = "JQuery In Action",
Author = "Jhon Smith", ISBN = "09-BEH-23452",
Publisher = "人民邮电出版社",
Description = "A very good book." });
var book3 = new Book(new BookState {
BookName = ".NET Framework Programming",
Author = "Jhon Smith",
ISBN = "12-VTQ-96786",
Publisher = "机械工业出版社",
Description = "A very good book." });
var book4 = new Book(new BookState {
BookName = "ASP.NET Professional Programming",
Author = "Jim Green",
ISBN = "43-WFW-87560",
Publisher = "浙江大学出版社",
Description = "A very good book." });
var book5 = new Book(new BookState {
BookName = "UML and Design Pattern",
Author = "Craig Larmen",
ISBN = "87-OPM-44651",
Publisher = "微软出版社",
Description = "A very good book." });
Repository.Add<Book>(book1);
Repository.Add<Book>(book2);
Repository.Add<Book>(book3);
Repository.Add<Book>(book4);
Repository.Add<Book>(book5);
//将这5本书添加进图书馆
library.PutBook(book1);
library.PutBook(book2);
library.PutBook(book3);
library.PutBook(book4);
library.PutBook(book5);
//创建一个图书卡卡号,用户凭卡号借书,实际过程则是用户持卡借书
var libraryAccount = new LibraryAccount(new LibraryAccountState { Number = GenerateAccountNumber(10), OwnerName = "汤雪华" });
Repository.Add<LibraryAccount>(libraryAccount);
//创建借书场景并进行场景交互
new BorrowBooksContext(
library.ActAs<ILibrary>(),
libraryAccount.ActAs<IBorrower>()
).Interaction(new List<UniqueId> { book1.Id, book2.Id });
//创建还书场景并进行场景交互
new ReturnBooksContext(
library.ActAs<ILibrary>(),
libraryAccount.ActAs<IBorrower>()
).Interaction(new List<UniqueId> { book1.Id });
}
从上面的高亮代码中,我们可以清晰的看到领域对象扮演其角色参与到活动。对象在参与活动时因为扮演了某个角色,因此自然也就有了该角色所对应的行为了。但是有人已经想到了,之前我们仅仅只是定义了角色的接口,并且对象本身也不具备角色所对应的属性或行为,那么对象扮演角色时,角色的属性或行为的具体实现在哪里呢?这个问题大家自己去看Demo的源代码吧,今天太晚了,眼睛实在快要闭上了。上面我已经把整个场景的参与者角色、角色扮演者、领域对象通过什么方法扮演(ActAs)角色、如何触发场景、领域对象和角色的区别等关键问题说明清楚了。而关于如何把角色的行为注入到领域对象之中,我自己思考了很久,思考如何利用C#实现一个既优雅又能确保强类型语言的优势但同时又能动态将角色的属性和行为注入到某个对象的设计方式,一切尽在源码之中!