[转载]Asp.net MVC2.0系列文章-显示列表和详细页面操作 – 灵动生活 – 博客园.
上一篇文章,我们简单地完成了新闻的添加操作(ASP.NET MVC2.0系列文章–添加操作)此篇文章,我们使用ASP.NET MVC2.0实现新闻清单的展示和新闻详细页面。
创建View视图Index和NewsDetails
创建新闻首页,用来显示新闻列表。
在Views/News目录下,单击右键,选择Add->View, 修改相关配置如下图所示
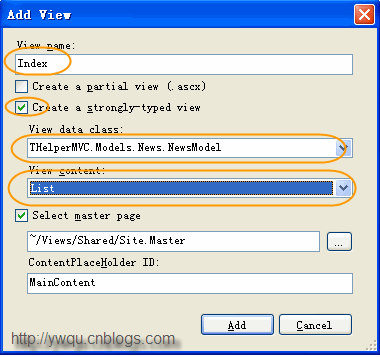
在生成的HTML代码中,进行相关 展示方面的修改。主要代码如下:
|
<% foreach (var item in Model) { %>
<tr> <td> <%: Html.ActionLink(“Edit”, “NewsEdit”, new { id=item.Id }) %> | <%: Html.ActionLink(“Details”, “NewsDetails”, new { id=item.Id })%> | <%: Html.ActionLink(“Delete”, “Delete”, new { /* id=item.PrimaryKey */ })%> </td> <td> <%: item.Title %> </td> <td> <%: String.Format(“{0:g}”, item.CreateTime) %> </td> <td> <%: item.Content %> </td> </tr> <% } %> |
使用Foreach循环遍历新 闻List中的记录。
<%: Html.ActionLink(“Details”, “NewsDetails”, new { id=item.Id })%> 此连接URL会 寻找当前Controller下的NewsDetails Action方法,以新闻编号Id为参数进行传值。
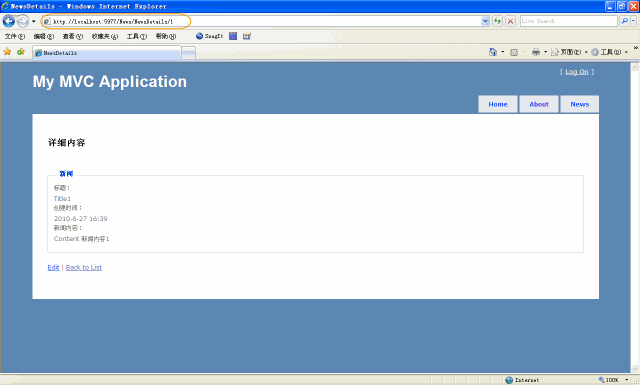
同样的方法创建新闻详细页面视图NewsDetails.asp

生成的核心代码如下:
|
<asp:Content ID=”Content2″ ContentPlaceHolderID=”MainContent” runat=”server”> <h2>详细内容</h2> <fieldset> <legend>新闻</legend> <div class=”display-label”>标题</div> <div class=”display-field”><%: Model.Title %></div>
<div class=”display-label”>创建时间</div> <div class=”display-field”><%: String.Format(“{0:g}”, Model.CreateTime) %></div>
<div class=”display-label”>新闻内容</div> <div class=”display-field”><%: Model.Content %></div>
</fieldset> <p> <%: Html.ActionLink(“Edit”, “NewsEdit”, new { id=Model.Id }) %> | <%: Html.ActionLink(“Back to List”, “Index”) %> </p> </asp:Content> |
<%: Html.ActionLink(“Edit”, “NewsEdit”, new { id=Model.Id }) %> | 此连接会跳转到新闻编辑页面,同样以新闻编号Id传值。
修改Controller文件
在Controllers/News文件下
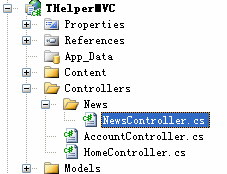
修改Action Name=Index的方法,以使Index.aspx页面初始化数据,此处未读读取数据库,而是伪造了一些数据,且放到静态变量中:
public static List<THelperMVC.Models.News.NewsModel> newsList;
Index Action 代码如下:
|
public ActionResult Index() { newsList= new List<THelperMVC.Models.News.NewsModel>(); for (int i = 0; i < 10; i++) { THelperMVC.Models.News.NewsModel news=new THelperMVC.Models.News.NewsModel(); news.Id = i; news.Title = “Title” + i.ToString(); news.CreateTime = System.DateTime.Now; news.Content = “Content 新?闻?内¨²容¨Y” + i.ToString(); newsList.Add(news); } return View(newsList); } |
使用For循环生成10条新闻记录。
修改NewsDetails.Aspx所对应的Action方法,如下
|
// GET: /News/Details/5 public ActionResult NewsDetails(int id) { THelperMVC.Models.News.NewsModel news=newsList[id]; return View(news); } |
根据URL传过来的参数(即新闻编号Id),从全局静态变量中寻找NewsModel实体,从而初始化新闻详细页面。
最后修改母版页中的,News连接,如下图所示:

此时,点击首页的News超链接,会寻找NewsController文件夹下的Index方法,从而初始化Views/News/Index.aspx页面。
程序运行效果
按下Ctrl+F5运行程序, 如下图所示:
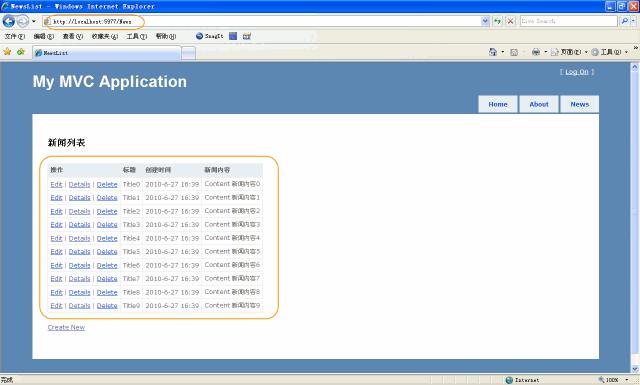
点击上图中的【News】超链接,跳转到 新闻列表页面,如下图所示:
点击Details超链接,会 跳转到相应记录的详细页面,如下图所示: