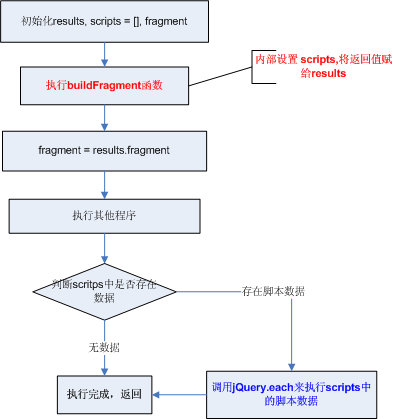
[转载]从事ASP.NET开发两年多,谈谈对两三年工作经验的ASP.NET程序员的基本见解 – 问题最终都是时间问题,烦恼其实都是自寻烦恼。 – 博客园.
粗略算来,自己从事.NET开发工作2年有余,也来谈谈自己对两三年工作经验的.NET程序员的基本见解。
我想众所周知,Microsoft的东西入门都是比较简单的,但是提高并不容易,这也就导致了很多培训机构借此良机,忽悠了大批的 甚至对编程压根不知所以然的人加入.NET的开发阵营,然后告诉他们包教,包会,包就业的三包政策。当然也有另一部分人是受过高等教育,之后出来从 事.NET开发工作,但是他们或者也是受到了一些环境的影响,在WEBFORM的开发模式中,很喜欢托拉控件,编辑模板之类的操作,甚至不知道这些控件最 终被解析成什么东西,只知道我实现了,而不问其所以然,或者是效率如何,等等。
下面谈谈几点个人愚见,希望能对两三年工作经验的.NET开发人员一点提醒:
1、Gridview之错,错,错
我想从事ASP.NET开发工作的应当有相当一部分人是做基于信息管理系统类软件开发的,这样一来可能就会经常与数据报表打交道,Gridview这个东 西可能就是在熟悉不过了。但是我想不通的是为什么有这么多的人喜欢用它呢?我总结了这种控件的缺点,如下:
(1)糟糕的编辑环境,看不见TR,TD,写样式也变得异常麻烦

 代码
代码
<Columns>
<asp:TemplateField HeaderText=“行号“>
<ItemTemplate>
<asp:Label ID=“lblRowId“ runat=“server“ Text=‘<%# Container.DataItemIndex +1%>‘></asp:Label>
</ItemTemplate>
</asp:TemplateField>
<asp:BoundField DataField=“XXX1“ HeaderText=“XXX1“ />
<asp:BoundField DataField=“XXX2“ HeaderText=“XXX2“ />
<asp:BoundField DataField=“XXX3“ HeaderText=“XXX3“ />
<asp:BoundField DataField=“XXX4“ HeaderText=“XXX4“ />
<asp:BoundField DataField=“XXX5“ HeaderText=“XXX5“ />
<asp:BoundField DataField=“XXX6“ HeaderText=“XXX6“ />
<asp:BoundField DataField=“XXX7“ HeaderText=“XXX7“ />
<asp:BoundField DataField=“XXX8“ HeaderText=“XXX8“ />
</Columns>
</asp:GridView>
(2)有人甚至喜欢在模板列里面编辑,我看着就一个字晕

(3)生成糟糕的HTML标签
(4)Gridview操作起来很不灵活
这句话的意思是我想要方便的控制Table的TR,TD,譬如在合并单元格,等等很多问题的处理上很不方便,以下是我用Repeater在处理合并单元格 的问题的实例:
HTML部分:
代码
<HeaderTemplate>
<%
if (rpList.Items.Count == 0)
{
%><div id=“dNoData“>No Data</div><%
}
else {
%>
<table>
<th>XXX1</th>
<th>XXX2</th>
<th>XXX3</th>
<th>XXX4</th>
<th>XXX5</th>
<th>XXX6</th>
<th>XXX7</th>
</tr>
<%
} %>
</HeaderTemplate>
<ItemTemplate>
<tr>
<td id=“tdContainerNo“ runat=“server“ ><%#Eval(“ContainerNo“)%></td>
<td><%#Eval(“X1“)%></td>
<td><%#Eval(“X2“)%></td>
<td><%#Eval(“X3“)%></td>
<td><%#Eval(“X4“)%></td>
<td><%#Eval(“X5“)%></td>
<td id=“tdtotal“ runat=“server“><%#Eval(“X6“)%></td>
</tr>
</ItemTemplate>
<FooterTemplate>
</table>
</FooterTemplate>
</asp:Repeater>
CS部分:
代码
{
HtmlTableCell tdContainerNo_previous = this.rpList.Items[i – 1].FindControl(“tdContainerNo“) as HtmlTableCell;
HtmlTableCell tdContainerNo = this.rpList.Items[i].FindControl(“tdContainerNo“) as HtmlTableCell;
HtmlTableCell tdtotal_previous
= this.rpList.Items[i – 1].FindControl(“tdtotal“) as HtmlTableCell;HtmlTableCell tdtotal = this.rpList.Items[i].FindControl(“tdtotal“) as HtmlTableCell;
tdContainerNo.RowSpan
= (tdContainerNo.RowSpan == –1) ? 1 : tdContainerNo.RowSpan;tdContainerNo_previous.RowSpan = (tdContainerNo_previous.RowSpan == –1) ? 1 : tdContainerNo_previous.RowSpan; if (tdContainerNo.InnerText == tdContainerNo_previous.InnerText)
{
tdContainerNo.Visible = false;
tdContainerNo_previous.RowSpan += tdContainerNo.RowSpan;
}
tdtotal.RowSpan
= (tdtotal.RowSpan == –1) ? 1 : tdtotal.RowSpan;tdtotal_previous.RowSpan = (tdtotal_previous.RowSpan == –1) ? 1 : tdtotal_previous.RowSpan; if (tdContainerNo.InnerText == tdContainerNo_previous.InnerText && tdtotal.InnerText == tdtotal_previous.InnerText)
{
tdtotal.Visible = false;
tdtotal_previous.RowSpan += tdtotal.RowSpan;
}
}
(5)Gridview生成的效率问题
Gridview集成了这么多的东西,我想在效率上,应该也好不到哪里去吧。
最后:当然Gridview还有诸多其他问题,这里就不一一列举了,这里只列举几个最常见得问题,让我想不通的是,有些人像Repeater这么简 单易用的控件,为什么不用,而去用Gridview这种不易掌控的控件呢?
2、为啥还有人用FormView
有些人喜欢在设计界面的时候托一个FormView控件,然后在里面放一些Textbox、Button、Label之类的服务器端控件,这样在后台操作 的时候可以统一绑定,而后呢如果会经常有一些方法,要操作FormView中的服务器端控件,那么经常有些程序员会声明很多局部变量,先从 FormView去Findcontrol这些服务器端控件赋给这些全局变量,而后去再操作这些全局变量,如下CODE:
//声明部分
private TextBox X1;
private TextBox X2;
private DropDownList X3;
private TextBox X4;
private TextBox X5;
private TextBox X6;
//赋值部分
看到这样的CODE真是让人无语,而且更让人无语的是,这些人仿佛很喜欢在模板列里面编辑内容。
3、疯狂的SQL 代码拼接
虽然说在在MS SQL 2005以后的版本中,对很长的SQL代码的执行效率,比执行由这段SQL生成的存储过程的时间多的有限,但是我们知道,存储过程是预先编译好的存放在数 据库中的,你要调用它,只需要传一个很短的字符串,加N个参数而已。而超长的SQL代码呢,你需要预先将其拼接成要执行的SQL 代码(SQL代码很长,要分为很多行写),然后传到数据库中,数据库要将其编译(可能会编译出错,你这个时候才知道),然后在执行这段SQL代码。你别说 我还真见到过很多人是这样写的,为什么不一句存储过程了事呢,改起来也很方便。
4、恐怖的viewstate
有些.NET程序员压根对viewstate不知其所以然,甚至在用webform的过程中,对其开发生成的HTML源码视而不见,下面我们来看看 viewstate产生的乱码:

这还是算小的了,数据控件在显示数量大的时候,你如果将这些东西拷贝到TXT文件中,然后看看他们的大小,是很恐怖的,虽然在开发webform过 程中,很多情况下viewstate确实帮我们节省了不少开发时间,也方便我很多,但是我要说的是,根据实际情况决定你的viewstate,能禁掉就禁 掉吧。
5、很喜欢到服务器端做验证(修正:应该 client/Server同时验证)
在开发过程中,我们会经常遇到这样的问题,验证用户输入内容的格式正不正确,例如,用户输入个EMail,我们就需要判 断输入的格式正不正确,然后有很多程序员就喜欢在CS文件中取this.txtXX.Text的内容作验证,然后弄个弹出框提示用户,殊不知这个简单的验 证,还要跑到Server上做,为什么不写个JS提示一下呢,不是很简单吗?
6、不知其所以然
很多两三经验的.NET程序在开发过程中托控件托习惯了,都不知道最后控件被解析什么样子,甚至不知道自己开发的 ASP.NET程序的工作流程,原理,完全被Microsoft傻瓜化了,只知道我这样做就实现了功能,却不知道你这样做为什么能实现。这是一个很恐怖的 信号,希望活跃在.NET的兄弟们在开发程序的时候能知其然,知其所以然。
7、吃老本,不学习新的技术
众所周知,Microsoft的技术是更新很快的,有些人会抱怨跟不上节奏,索性不问,老是沉迷于过去式中,认为老的 技术成熟,而且自己很熟悉,殊不知,这是一种退化的表现。我们应该明白,新事物的出 现,肯定是为了补充旧事物的所缺少的地方,是为了更完美,更便捷的处理实际问题,我们不能一概的去否定它,而应该去了解他,学习他。Linq不是很好用 吗,但是到现在还发现很多人对Linq是一知半解。
今天就写到这里吧,以上内容是我经常见到的,所以写在这里,希望给两三工作经验的程序员朋友提个醒!
作者:Tonny Yang
出处:http://www.cnblogs.com/yangtongnet/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。