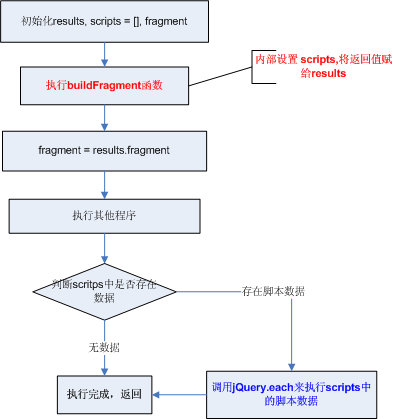
[转载]Xml中SelectSingleNode方法中的xpath用法 – wf520pb的专栏 – CSDN博客.
- 最常见的XML数据类型 有:Element, Attribute,Comment, Text.
- Element, 指形如<Name>Tom<Name>的节点。它可以包 括:Element, Text, Comment, ProcessingInstruction, CDATA, and EntityReference.
- Attribute, 指在<Employee >中的粗体部分。
- Comment,指形如:<!– my comment –> 的 节点。
- Text, 指在<Name>Tom<Name>的粗体部分。
- 在XML中,可以用XmlNode对象 来参照各种XML数据类型。
- 2.1 查询已知绝对路径的节点(集)
- objNodeList = objDoc.SelectNodes(“Company/Department/Employees/Employee”)
- 或者
- objNodeobjNodeList = objNode.SelectNodes(“/Company/Department/Employees/Employee”)
- 以上两种方法可返回一个 NodeList对象,如果要返回单个节点可使用SelectSingleNode方法,该方法如果查询到一个或多个节点,返回第一个节点;如果没有查询 的任何节点返回 Nothing。例如:
- objNodeobjNode = objNode.SelectSingleNode(“/Company/Department/Employees/Employee”)
- If Not (objNode is Nothing) then
- ‘- Do process
- End If
- 2.2 查询已知相对路径的节点 (集)
- 可 使用类似于文件路径的相对路径的方式来查询XML的数据
- objNode = objDoc.SelectSingleNode(“Company/Department”)
- objNodeobjNodeList = objNode.SelectNodes(“../Department)
- objNodeobjNode = objNode.SelectNode(“Employees/Employee”)
- 2.3 查询已知元素名的节点 (集)
- 在 使用不规则的层次文档时,由于不知道中间层次的元素名,可使用//符号来越过中间的节点,查询其子,孙或多层次下的其他所有元素。例如:
- objNodeList = objDoc.SelectNodes(“Company//Employee”)
- 2.4 查询属性 (attribute)节点
- 以上的各种方法都返回元素(element)节点(集),返回属性(attribute),只需要采用相应的方 法,在属性名前加一个@符号即可,例如:
- objNodeList = objDoc.SelectNodes(“Company/Department/Employees/Employee/@id”)
- objNodeList = objDoc.SelectNodes(“Company//@id”)
- 2.5 查询Text节点
- 使用text()来获取Text节 点。
- objNode = objDoc.SelectSingleNode(“Company/Department/Deparmt_Name/text()”)
- 2.6 查询特定条件的节点
- 使用[]符号来查询特定条件的节点。例 如:
- a. 返 回id号为 10102的Employee节点
- objNode = objDoc.SelectSingleNode(“Company/Department/Employees/Employee[@id=’10102’]”)
- b. 返回Name为Zhang Qi 的Name 节点
- objNode = objDoc.SelectSingleNode(“Company/Department/Employees/Employee/Name[text()=’Zhang Qi’]”)
- c. 返回部门含有职员22345的 部门名称节点
- objNode = objDoc.SelectSingleNode(“Company/Department[Employees/Employee/@id=‘22345’]/Department_Name”)
- 2.7 查询多重模式的节点
- 使用 | 符号可以获得多重模式的节 点。例如:
- objNodeList = objDoc.SelectNodes(“Company/Department/Department_Name | Company/Department/Manager”)
- 2.8 查询任意子节点
- 使用*符号可以返回当前节点的所有子节 点。
- objNodeList = objDoc.SelectNodes(“Company/*/Manager)
- 或者
- objNodeobjNodeList = objNode.ChildNodes
- 3 XML数据的编辑
- 3.1 增加一个元素的属性 (attribute)节点
- Dim objNodeAttr As XmlNode
- objNodeAttr = objDoc.CreateAttribute(“id”, Nothing)
- objNodeAttr.InnerXml = “101”
- objNode.Attributes.Append(objNodeAttr)
- 3.2 删除一个元素的属性
- objNode.Attributes.Remove(objNodeAttr)
- 3.3 增加一个子元素 (Element)
- Dim objNodeChild As XmlNode
- objNodeChild = objDoc.CreateElement(Nothing, “ID”, Nothing)
- objNodeChild.InnerXml = “101”
- objNode.AppendChild(objNodeChild)
- 3.4 删除一个子元素
- objNode.RemoveChild(objNodeChild)
- 3.5 替换一个子元素
- objNOde.ReplaceChild(newChild,oldChild)
- 4 参考数据
- <?xml version=“1.0” encoding=“UTF-8”?>
- <Company>
- <Department >
- <Department_Name>Cai WuBu</Department_Name>
- <Manager>Zhang Bin</Manager>
- <Employees>
- <Employee >
- <Employee_ID>12345</Employee_ID>
- <Name>Zhang Bin</Name>
- <Gender>male</Gender>
- </Employee>
- <Employee >
- <Employee_ID>10101</Employee_ID>
- <Name>Zhang QI</Name>
- <Gender>female</Gender>
- </Employee>
- <Employee >
- <Employee_ID>10102</Employee_ID>
- <Name>Zhang Xia</Name>
- <Gender>male</Gender>
- </Employee>
- <Employee >
- <Employee_ID>10201</Employee_ID>
- <Name>ZhangChuang</Name>
- <Gender>male</Gender>
- </Employee>
- <Employee >
- <Employee_ID>10202</Employee_ID>
- <Name>Zhang Jun</Name>
- <Gender>male</Gender>
- </Employee>
- </Employees>
- </Department>
- <Department >
- <Department_Name>KaiFa Bu</Department_Name>
- <Manager>Wang Bin</Manager>
- <Employees>
- <Employee >
- <Employee_ID>22345</Employee_ID>
- <Name>Wang Bin</Name>
- <Gender>male</Gender>
- </Employee>
- <Employee >
- <Employee_ID>20101</Employee_ID>
- <Name>Wang QI</Name>
- <Gender>female</Gender>
- </Employee>
- <Employee >
- <Employee_ID>20102</Employee_ID>
- <Name>Wang Xia</Name>
- <Gender>male</Gender>
- </Employee>
- <Employee >
- <Employee_ID>20201</Employee_ID>
- <Name>Wang Chuang</Name>
- <Gender>male</Gender>
- </Employee>
- <Employee >
- <Employee_ID>20201</Employee_ID>
- <Name>Wang Jun</Name>
- <Gender>male</Gender>
- </Employee>
- </Employees>
- </Department>
- </Company>