随着ASP.NET MVC 1.0的发布,关注MVC的园友们越来越多,我们整理了园子里的ASP.NET MVC原创内容,制作了这个MVC专题,供大家学习参考。

详情请点击:ASP.NET MVC专题
相关话题: WebForms与MVC

随着ASP.NET MVC 1.0的发布,关注MVC的园友们越来越多,我们整理了园子里的ASP.NET MVC原创内容,制作了这个MVC专题,供大家学习参考。
详情请点击:ASP.NET MVC专题
相关话题: WebForms与MVC
Google搜索引擎优化入门指南
作者:Google 网站管理员中心翻译:个篱
欢迎来到Google 的搜索引擎优化SEO 向导。这个文档最初仅仅用于Google 内部团队,但是我们想也许它
对那些才刚刚接触搜索引擎优化(SEO)并且希望让自己的网站在用户和搜索引擎两者上都得到很好交互
性的网站管理员们有所帮助,便把它发布了出来。虽然这个手册并不能告诉你任何关于如何把你的网站
自动置于Google 查询第一位置的秘密,但是适当地遵循下面给出的最优方案可以让搜索引擎更好的爬行
和索引你网站的内容。
搜索引擎搜索常常是指对你网站的某些部分作适当的修饰。对个别访问而言这些改变或许看起来是逐渐增
加的;但是和其它优化结合起来时,不管是对你网站的访问者还是在搜索引擎结果上的表现这些改变的
影响都是显而易见的。也许你已经非常熟悉下面列出的一些帮助性提示,因为它们几乎是所有网页的构成
元素,但你也可能不会用到其中的大部分。
可能有不少朋友遇到过这样的问题:
update或delete语句忘带了where子句,或where子句精度不够,执行之后造成了严重的后果,
这种情况的数据恢复只能利用事务日志的备份来进行,所以如果你的SQL没有进行相应的全库备份
或不能备份日志(truncate log on checkpoint选项为1),那么就无法进行数据的恢复了,或者
只能恢复到最近一次的备份的数据了。
以下简单说明恢复数据方法:
1,如果误操作之前存在一个全库备份(或已有多个差异备份或增量备份),首先要做的事就是进
进行一次日志备份(如果为了不让日志文件变大而置trunc. log on chkpt.选项为1那你就死翘了)
backup log dbName to disk='fileName'
2,恢复一个全库备份,注意需要使用with norecovery,如果还有其他差异或增量备份,则逐个恢
复
restore database dbName from disk='fileName' with norecovery
3,恢复最后一个日志备份即刚做的日志备份,指定恢复时间点到误操作之前的时刻
restore log dbName from disk='fileName'
with stopat='date_time'
当然,如果误操作是一些不记日志的操作比如truncate table,select into等操作,那么是无法利
用上述方法来恢复数据的…
契约式编程不是一门崭新的编程方法论。C/C++ 时代早已有之。Microsoft 在 .NET 4.0 中正式引入契约式编程库。博主以为契约式编程是一种相当不错的编程思想,每一个开发人员都应该掌握。它不但可以使开发人员的思维更清晰,而且对于提高程序 性能很有帮助。值得一提的是,它对于并行程序设计也有莫大的益处。
我们先看一段很简单的,未使用契约式编程的代码示例。
// .NET 代码示例 public class RationalNumber { private int numberator; private int denominator; public RationalNumber(int numberator, int denominator) { this.numberator = numberator; this.denominator = denominator; } public int Denominator { get { return this.denominator; } } }
上述代码表示一个在 32 位有符号整型范围内的有理数。数学上,有理数是一个整数 a 和一个非零整数 b 的比,通常写作 a/b,故又称作分数(题外话:有理数这个翻译真是够奇怪)。由此,我们知道,有理数的分母不能为 0 。所以,上述代码示例的构造函数还需要写些防御性代码。通常 .NET 开发人员会这样写:
// .NET 代码示例 public class RationalNumber { private int numberator; private int denominator; public RationalNumber(int numberator, int denominator) { if (denominator == 0) throw new ArgumentException("The second argument can not be zero."); this.numberator = numberator; this.denominator = denominator; } public int Denominator { get { return this.denominator; } } }
下面我们来看一下使用契约式编程的 .NET 4.0 代码示例。为了更加方便的说明,博主在整个示例上都加了契约,但此示例并非一定都加这些契约。
// .NET 代码示例 public class RationalNumber { private int numberator; private int denominator; public RationalNumber(int numberator, int denominator) { Contract.Requires(denominator != 0, "The second argument can not be zero."); this.numberator = numberator; this.denominator = denominator; } public int Denominator { get { Contract.Ensures(Contract.Result<int>() != 0); return this.denominator; } } [ContractInvariantMethod] protected void ObjectInvariant() { Contract.Invariant(this.denominator != 0); } }
详细的解释稍后再说。按理,既然契约式编程有那么多好处,那在 C/C++ 世界应该很流行才对。为什么很少看到关于契约式编程的讨论呢?看一下 C++ 的契约式编程示例就知道了。下面是 C++ 代码示例:
//typedef long int32_t; #include <stdint.h> template inline void CheckInvariant(T& argument) { #ifdef CONTRACT_FULL argument.Invariant(); #endif } public class RationalNumber { private: int32_t numberator; int32_t denominator; public: RationalNumber(int32_t numberator, int32_t denominator) { #ifdef CONTRACT_FULL ASSERT(denominator != 0); CheckInvaraint(*this); #endif this.numberator = numberator; this.denominator = denominator; #ifdef CONTRACT_FULL CheckInvaraint(*this); #endif } public: int32_t GetDenominator() { #ifdef CONTRACT_FULL // C++ Developers like to use struct type. class Contract { int32_t Result; Contract() { } ~Contract() { } } #endif #ifdef CONTRACT_FULL Contract contract = new Contract(); contract.Result = denominator; CheckInvairant(*this); #endif return this.denominator; #ifdef CONTRACT_FULL CheckInvaraint(*this); #endif } protected: #ifdef CONTRACT_FULL virtual void Invariant() { this.denominator != 0; } #endif }
Woo…, 上述代码充斥了大量的宏和条件编译。对于习惯了 C# 优雅语法的 .NET 开发人员来说,它们是如此丑陋。更重要的是,契约式编程在 C++ 世界并未被标准化,因此项目之间的定义和修改各不一样,给代码造成很大混乱。这正是很少在实际中看到契约式编程应用的原因。但是在 .NET 4.0 中,契约式编程变得简单优雅起来。.NET 4.0 提供了契约式编程库。实际上,.NET 4.0 仅仅是针对 C++ 宏和条件编译的再次抽象和封装。它完全基于 CONTRACTS_FULL, CONTRACTS_PRECONDITIONS Symbol 和 System.Diagnostics.Debug.Assert 方法、System.Environment.FastFail 方法的封装。
那么,何谓契约式编程?
契约是减少大型项目成本的突破性技术。它一般由 Precondition(前置条件), Postcondition(后置条件) 和 Invariant(不变量) 等概念组成。.NET 4.0 除上述概念之外,还增加了 Assert(断言),Assume(假设) 概念。这可以由枚举 ContractFailureKind 类型一窥端倪。
契约的思想很简单。它只是一组结果为真的表达式。如若不然,契约就被违反。那按照定义,程序中就存在纰漏。契约构成了程序规格说明的一部分,只不过该说明从文档挪到了代码中。开发人员都知道,文档通常不完整、过时,甚至不存在。将契约挪移到代码中,就使得程序可以被验证。
正如前所述,.NET 4.0 对宏和条件编译进行抽象封装。这些成果大多集中在 System.Diagnostics.Contracts.Contract 静态类中。该类中的大多数成员都是条件编译。这样,我们就不用再使用 #ifdef 和定义 CONTRACTS_FULL 之类的标记。更重要的是,这些行为被标准化,可以在多个项目中统一使用,并根据情况是否生成带有契约的程序集。
Assert(断言)是最基本的契约。.NET 4.0 使用 Contract.Assert() 方法来特指断言。它用来表示程序点必须保持的一个契约。
Contract.Assert(this.privateField > 0); Contract.Assert(this.x == 3, "Why isn’t the value of x 3?");
断言有两个重载方法,首参数都是一个布尔表达式,第二个方法的第二个参数表示违反契约时的异常信息。
当断言运行时失败,.NET CLR 仅仅调用 Debug.Assert 方法。成功时则什么也不做。
.NET 4.0 使用 Contract.Assume() 方法表示 Assume(假设) 契约。
Contract.Assume(this.privateField > 0); Contract.Assume(this.x == 3, "Static checker assumed this");
Assume 契约在运行时检测的行为与 Assert(断言) 契约完全一致。但对于静态验证来说,Assume 契约仅仅验证已添加的事实。由于诸多限制,静态验证并不能保证该契约。或许最好先使用 Assert 契约,然后在验证代码时按需修改。
当 Assume 契约运行时失败时, .NET CLR 会调用 Debug.Assert(false)。同样,成功时什么也不做。
.NET 4.0 使用 Contract.Requires() 方法表示 Preconditions(前置条件) 契约。它表示方法被调用时方法状态的契约,通常被用来做参数验证。所有 Preconditions 契约相关成员,至少方法本身可以访问。
Contract.Requires(x != null);
Preconditions 契约的运行时行为依赖于几个因素。如果只隐式定义了 CONTRACTS PRECONDITIONS 标记,而没有定义 CONTRACTS_FULL 标记,那么只会进行检测 Preconditions 契约,而不会检测任何 Postconditions 和 Invariants 契约。假如违反了 Preconditions 契约,那么 CLR 会调用 Debug.Assert(false) 和 Environment.FastFail 方法。
假如想保证 Preconditions 契约在任何编译中都发挥作用,可以使用下面这个方法:
Contract.RequiresAlways(x != null);
为了保持向后兼容性,当已存在的代码不允许被修改时,我们需要抛出指定的精确异常。但是在 Preconditions 契约中,有一些格式上的限定。如下代码所示:
if (x == null) throw new ArgumentException("The argument can not be null."); Contract.EndContractBlock(); // 前面所有的 if 检测语句皆是 Preconditions 契约
这种 Preconditions 契约的格式严格受限:它必须严格按照上述代码示例格式。而且不能有 else 从句。此外,then 从句也只能有单个 throw 语句。最后必须使用 Contract.EndContractBlock() 方法来标记 Preconditions 契约结束。
看到这里,是不是觉得大多数参数验证都可以被 Preconditions 契约替代?没有错,事实的确如此。这样这些防御性代码完全可以在 Release 被去掉,从而不用做那些冗余的代码检测,从而提高程序性能。但在面向验证客户输入此类情境下,防御性代码仍有必要。再就是,Microsoft 为了保持兼容性,并没有用 Preconditions 契约代替异常。
Postconditions 契约表示方法终止时的状态。它跟 Preconditions 契约的运行时行为完全一致。但与 Preconditions 契约不同,Postconditions 契约相关的成员有着更少的可见性。客户程序或许不会理解或使用 Postconditions 契约表示的信息,但这并不影响客户程序正确使用 API 。
对于 Preconditions 契约来说,它则对客户程序有副作用:不能保证客户程序不违反 Preconditions 契约。
.NET 4.0 使用 Contract.Ensures() 方法表示标准 Postconditions 契约用法。它表示方法正常终止时必须保持的契约。
Contract.Ensures(this.F > 0);
当从方法体内抛出一个特定异常时,通常情况下 .NET CLR 会从方法体内抛出异常的位置直接跳出,从而辗转堆栈进行异常处理。假如我们需要在异常抛出时还要进行 Postconditions 契约验证,我们可以如下使用:
Contract.EnsuresOnThrows<T>(this.F > 0);
其中小括号内的参数表示当异常从方法内抛出时必须保持的契约,而泛型参数表示异常发生时抛出的异常类型。举例来说,当我们把 T 用 Exception 表示时,无论什么类型的异常被抛出,都能保证 Postconditions 契约。哪怕这个异常是堆栈溢出或任何不能控制的异常。强烈推荐当异常是被调用 API 一部分时,使用 Contract.EnsuresOnThrows<T>() 方法。
以下要讲的这几个特殊方法仅限使用在 Postconditions 契约内。
方法返回值 在 Postconditions 契约内,可以通过 Contract.Result<T>() 方法表示,其中 T 表示方法返回类型。当编译器不能推导出 T 类型时,我们必须显式指出。比如,C# 编译器就不能推导出方法参数类型。
Contract.Ensures(0 < Contract.Result<int>());
假如方法返回 void ,则不必在 Postconditions 契约内使用 Contract.Result<T>() 。
前值(旧值) 在 Postconditions 契约内,通过 Contract.OldValue<T>(e) 表示旧有值,其中 T 是 e 的类型。当编译器能够推导 T 类型时,可以忽略。此外 e 和旧有表达式出现上下文有一些限制。旧有表达式只能出现在 Postconditions 契约内。旧有表达式不能包含另一个旧有表达式。一个很重要的原则就是旧有表达式只能引用方法已经存在的那些旧值。比如,只要方法 Preconditions 契约持有,它必定能被计算。下面是这个原则的一些示例:
Contract.OldValue(xs.Length); // 很可能错误
Contract.OldValue(Contract.Result<int>() + x); // 错误
Contract.ForAll(0, Contract.Result<int>(), i => Contract.OldValue(xs[i]) > 3); // 错误
Contract.ForAll(0, xs.Length, i => Contract.OldValue(xs[i]) > 3); // OK
Contract.ForAll(0, xs.Length, i => Contract.OldValue(i) > 3); // 错误
Foo( ... (T t) => Contract.OldValue(... t ...) ... ); // 错误
因为契约出现在方法体前面,所以大多数编译器不允许在 Postconditions 契约内引用 out 参数。为了绕开这个问题,.NET 契约库提供了 Contract.ValueAtReturn<T>(out T t) 方法。
public void OutParam(out int x) { Contract.Ensures(Contract.ValueAtReturn(out x) == 3); x = 3; }
跟 OldValue 一样,当编译器能推导出类型时,泛型参数可以被忽略。该方法只能出现在 Postconditions 契约。方法参数必须是 out 参数,且不允许使用表达式。
需要注意的是,.NET 目前的工具不能检测确保 out 参数是否正确初始化,而不管它是否在 Postconditions 契约内。因此, x = 3 语句假如被赋予其他值时,编译器并不能发现错误。但是,当编译 Release 版本时,编译器将发现该问题。
对象不变量表示无论对象是否对客户程序可见,类的每一个实例都应该保持的契约。它表示对象处于一个“良好”状态。
在 .NET 4.0 中,对象的所有不变量都应当放入一个受保护的返回 void 的实例方法中。同时用[ContractInvariantMethod]特性标记该方法。此外,该方法体内在调用一系列 Contract.Invariant() 方法后不能再有其他代码。通常我们会把该方法命名为 ObjectInvariant 。
[ContractInvariantMethod] protected void ObjectInvariant() { Contract.Invariant(this.y >= 0); Contract.Invariant(this.x > this.y); }
同样,Object Invariants 契约的运行时行为和 Preconditions 契约、Postconditions 契约行为一致。CLR 运行时会在每个公共方法末端检测 Object Invariants 契约,但不会检测对象终结器或任何实现 System.IDisposable 接口的方法。
.NET 4.0 契约库中的 Contract 静态类还提供了几个特殊的方法。它们分别是:
Contract.ForAll() 方法有两个重载。第一个重载有两个参数:一个集合和一个谓词。谓词表示返回布尔值的一元方法,且该谓词应用于集合中的每一个元素。任何一个元素让谓词返回 false ,ForAll 停止迭代并返回 false 。否则, ForAll 返回 true 。下面是一个数组内所有元素都不能为 null 的契约示例:
public T[] Foo<T>(T[] array) { Contract.Requires(Contract.ForAll(array, (T x) => x != null)); }
它和 ForAll 方法差不多。
因为 C#/VB 编译器不允许接口内的方法带有实现代码,所以我们如果想在接口中实现契约,需要创建一个帮助类。接口和契约帮助类通过一对特性来链接。如下所示:
[ContractClass(typeof(IFooContract))] interface IFoo { int Count { get; } void Put(int value); } [ContractClassFor(typeof(IFoo))] sealed class IFooContract : IFoo { int IFoo.Count { get { Contract.Ensures(Contract.Result<int>() >= 0); return default(int); // dummy return } } void IFoo.Put(int value) { Contract.Requires(value >= 0); } }
.NET 需要显式如上述声明从而把接口和接口方法相关联起来。注意,我们不得不产生一个哑元返回值。最简单的方式就是返回 default(T),不要使用 Contract.Result<T> 。
由于 .NET 要求显式实现接口方法,所以在契约内引用相同接口的其他方法就显得很笨拙。由此,.NET 允许在契约方法之前,使用一个局部变量引用接口类型。如下所示:
[ContractClassFor(typeof(IFoo))] sealed class IFooContract : IFoo { int IFoo.Count { get { Contract.Ensures(Contract.Result<int>() >= 0); return default(int); // dummy return } } void IFoo.Put(int value) { IFoo iFoo = this; Contract.Requires(value >= 0); Contract.Requires(iFoo.Count < 10); // 否则的话,就需要强制转型 ((IFoo)this).Count } }
同接口类似,.NET 中抽象类中的抽象方法也不能包含方法体。所以同接口契约一样,需要帮助类来完成契约。代码示例不再给出。
所有的契约方法都有一个带有 string 类型参数的重载版本。如下所示:
Contract.Requires(obj != null, "if obj is null, then missiles are fired!");
这样当契约被违反时,.NET 可以在运行时提供一个信息提示。目前,该字符串只能是编译时常量。但是,将来 .NET 可能会改变,字符串可以运行时被计算。但是,如果是字符串常量,静态诊断工具可以选择显示它。
这两个特性,我们已经在接口契约和抽象方法契约里看到了。ContractClass 特性用于添加到接口或抽象类型上,但是指向的却是实现该类型的帮助类。ContractClassFor 特性用来添加到帮助类上,指向我们需要契约验证的接口或抽象类型。
这个特性用来标记表示对象不变量的方法。
Pure 特性只声明在那些没有副作用的方法调用者上。.NET 现存的一些委托可以被认为如此,比如 System.Predicate<T> 和 System.Comparison<T>。
这是个程序集级别的特性(具体如何,俺也不太清楚)。
这个特性用在字段上。它被用在方法契约中,且该方法相对于字段来说,更具可见性。比如私有字段和公共方法。如下所示:
[ContractPublicPropertyName("PublicProperty")] private int field; public int PublicProperty { get { ... } }
这个特性用来假设程序集、类型、成员是否可被验证执行。我们可以使用 [ContractVerification(false)] 来显式标记程序集、类型、成员不被验证执行。
接下来,讲一讲 .NET 契约库目前所存在的一些问题。
Well,.NET 契约式编程到这里就结束了。嗯,就到这里了。
在VelocityEngine初始化前,可以通过ExtendedProperties配置NVelocity的运行环境参数,当执行 VelocityEngine的Init(ExtendedProperties)后,NVelocity会合并自定义配置和默认配置。 NVelocity在NVelocity.Runtime.RuntimeConstants中定义了默认配置项的名称,在内嵌资源文件 NVelocity.Runtime.Defaults.nvelocity.properties中定义了所有默认配置项的值。下面列出一些常用配置:
模板编码:
input.encoding=ISO-8859-1 //模板输入编码
output.encoding=ISO-8859-1 //模板输出编码
#foreach配置
directive.foreach.counter.name = velocityCount //计数器名称
directive.foreach.counter.initial.value = 1 //计数器初始值
directive.foreach.maxloops = -1 //最大循环次数,-1为默认不限制 directive.foreach.iterator.name = velocityHasNex //迭代器名称
#set配置
directive.set.null.allowed = false //是否可设置空值
#include配置
directive.include.output.errormsg.start = <!– include error : //错误信息提示开始字符串
directive.include.output.errormsg.end = see error log –> //错误信息提示结束字符串
#parse配置
directive.parse.max.depth = 10 //解析深度
模板加载器配置
resource.loader = file //模板加载器类型,默认为文件,可定义多个
file.resource.loader.description = Velocity File Resource Loader //加载器描述
file.resource.loader.class = NVelocity.Runtime.Resource.Loader.FileResourceLoader //加载器类名称
file.resource.loader.path = . //模板路径
file.resource.loader.cache = false //是否启用模板缓存
file.resource.loader.modificationCheckInterval = 2 //检查模板更改时间间隔
宏配置
velocimacro.permissions.allow.inline = true //是否可以行内定义
velocimacro.permissions.allow.inline.to.replace.global = false //是否可以用行内定义代替全局定义
velocimacro.permissions.allow.inline.local.scope = false //行内定义是否只用于局部
velocimacro.context.localscope = false //宏上下文是否只用于局部
velocimacro.max.depth = 20 //解析深度
velocimacro.arguments.strict = false //宏参数是否启用严格模式
资源管理器配置
resource.manager.class = NVelocity.Runtime.Resource.ResourceManagerImpl //管理器类名称
resource.manager.cache.class = NVelocity.Runtime.Resource.ResourceCacheImpl //缓存器类名称
解析器池配置
parser.pool.class = NVelocity.Runtime.ParserPoolImpl //解析池类名称
parser.pool.size = 40 //初始大小
#evaluate配置
directive.evaluate.context.class = NVelocity.VelocityContext //上下问类名称
可插入introspector配置
本文讲解ViewEngine的作用, 并且深入解析了实现ViewEngine相关的所有接口和类, 最后演示了如何开发一个自定义的ViewEngine. 本系列文章已经全部更新为ASP.NET MVC 1.0版本.希望大家多多支持!
首先注意: 我会将大家在MVC之前一直使用的ASP.NET页面编程模型称作ASP.NET WebForm编程模型.
上 一讲中我们已经学习了如何向View传递Model, 以及如何在View中使用Model对象. 目前为止我们使用的都还是ASP.NET WebForm的页面模型,比如aspx页面,用户控件,母版页等. 最后这些页面中都要转换为HTML代码. 比如页面中的内嵌代码:
<% = ViewData["model"] %>
你是否思考过, 为何页面会支持<% %>这种语法? 为何最后一个aspx页面会在浏览器中以HTML代码的形式展现?
有人会回答这是ASP.NET自带的语法和功能. 没有错, ASP.NET帮我们做了编译页面, 输出HTML, 返回HTML给客户端浏览器等一系列工作.但是这些工作在MVC框架中有很多是属于View角色的职责. 为了继续使用原有的ASP.NET WebForm页面引擎, ASP.NET MVC抽象出来了ViewEngine这个角色. 顾名思义ViewEngine即视图引擎, 其主要作用就是找到View对象, 编译View对象中的语言代码(执行语言逻辑), 并且输出HTML. 下面讲解的WebFormViewEngine就是使用ASP.NET WebForm的页面编译/呈现功能实现的.
下面将讲解和ViewEngine有关的各个接口和类.
IView接口是对MVC结构中View对象的抽象, 此接口只有一个方法:
void Render(ViewContext viewContext, TextWriter writer);
Render方法的作用就是展示View对象, 通常是将页面HTML写入到Writer中供浏览器展示.
在本系列第三篇文章中我曾经分析过, 虽然IView对象是MVC中View角色的抽象, 并且提供了Render方法, 但是实际上真正的View角色的显示逻辑在ViewPage/ViewUserControl类中. 这是由于ASP.NET MVC提供的WebFormViewEngine视图引擎是使用原有的ASP.NET Web From的页面显示机制, 我们无法直接将WebForm模型中的页面转化为IView对象.
于是最后使用了一个折中的办法:
在IView对象的Render方法中调用WebForm页面的Render方法. WebFormView是目前ASP.NET MVC中唯一实现了IView接口的类
所以如果我们使用自定义的ViewEngine引擎, 就可以直接创建一个实现了IView接口的类实现Render方法.
ViewEngine即视图引擎, 在ASP.NET MVC中将ViewEngine的作用抽象成了 IViewEngine 接口.
虽然IViewEngine的职责是寻找View对象, 但是其定义的两个方法:
返回的结果是ViewEngineResult对象, 并不是View对象. 我们可以将ViewEngineResult理解为一次查询的结果, 在ViewEngineResult对象中包含有本次找到的IView对象.
ASP.NET MVC 提供了下面两个实现了IViewEngine接口的类:
WebFormViewEngine是VirtualPathProviderViewEngine的派生类.
VirtualPathProviderViewEngine类实现了FindPartialView/FindView方法, 更够根据指定的路径格式搜索页面文件, 并且使用了提供了Cache机制缓存数据. 注意因为使用的是ASP.NET Cache,依赖HttpContext对象, 这就导致Cache无法在WebService或者WCf等项目中使用. VirtualPathProviderViewEngine寻找页面的方法依赖下面三个属性:
在VirtualPathProviderViewEngine中只定义了这三个属性, 具体的值在派生类WebFormViewEngine中指定:
public WebFormViewEngine() { MasterLocationFormats = new[] { "~/Views/{1}/{0}.master", "~/Views/Shared/{0}.master" }; ViewLocationFormats = new[] { "~/Views/{1}/{0}.aspx", "~/Views/{1}/{0}.ascx", "~/Views/Shared/{0}.aspx", "~/Views/Shared/{0}.ascx" }; PartialViewLocationFormats = ViewLocationFormats; }
上面的代码中我们可以一步了然ViewEngine都搜索哪些路径.甚至还可以添加我们自己的路径和文件类型.
因为有了VirtualPathProviderViewEngine类, 在开发自定义的ViewEngine时不需要再编写搜索View文件的逻辑了.只需要定义搜索路径即可. 如果不使用ASP.NET WebForm的页面显示方式, 就需要自己定义的View对象如何显最后转化为HTML代码.
在后面的实例中会演示创建一个我们自定义的ViewEngine.
ViewEngineResult是ViewEngine寻找View的查询结果.ViewEngineResult类没有派生类, 也就是说不同的ViewEngine返回的结果都是ViewEngineResult对象.
ViewEngineResult类有一个很重要的构造函数:
public ViewEngineResult(IView view, IViewEngine viewEngine)
以WebFormViewEngine为例, 在WebFormViewEngine类中定义了 MasterLocationFormats/ViewLocationFormats /PartialViewLocationFormats , 在调用FindPartialView/FindView方法时, 首先找到View对象的磁盘路径, 然后使用CreatePartialView/CreateView方法将磁盘路径转化实现了IView接口的WebFormView对象.
WebFormView中依然保存这页面对象的磁盘路径, 在调用Render时会根据磁盘路径创建ViewPage对象, 调用页面的Render方法.ASP.NET MVC编译页面时, 使用了.NET Framework 2.0以上的版本中提供的根据虚拟路径编译页面的函数:
BuildManager.CreateInstanceFromVirtualPath(string virtualPath, Type requiredBaseType)
命名空间为System.Web.Compilation.
ViewEngineCollection是IViewEngine对象的集合类. 在我们的系统中可以使用多个ViewEngine, 在寻找时会返回第一个匹配的ViewEngineResult, 下面是ViewEngineCollection类的Find方法代码:
private ViewEngineResult Find(Func<IViewEngine, ViewEngineResult> cacheLocator, Func<IViewEngine, ViewEngineResult> locator) { ViewEngineResult result; foreach (IViewEngine engine in Items) { if (engine != null) { result = cacheLocator(engine); if (result.View != null) { return result; } } } List<string> searched = new List<string>(); foreach (IViewEngine engine in Items) { if (engine != null) { result = locator(engine); if (result.View != null) { return result; } searched.AddRange(result.SearchedLocations); } } return new ViewEngineResult(searched); }
通过上面的代码我们了解到, ViewEngineCollection会首先从Cache中搜索, 如果没有搜索到结果,则根据路径格式搜索. 如果最后还是没有搜索到View对象则抛出找不到View的异常.所以虽然我们可以添加多个ViewEngine, 但是永远不要为两个ViewEngine指定同样的搜索格式(路径+文件类型), 因为如果出现一个页面对象符合两个ViewEngine的搜索格式的情况, 将无法控制使用哪一个ViewEngine输出页面.
在ViewBaseResult.ExecuteResult() 方法中, 调用了ViewEngineCollection.Find方法获取ViewEngineResult对象,并调用其中的IView.Render()方法完成View对象的显示.
下面通过示例演示如何开发自己的ViewEngine.其中要用到StringTemplate这个模板引擎, 在老赵的的MVC视频教程中也使用的此引擎演示ViewEngine. StringTemplate负责翻译一个模板页上面的占位符(aspx页面中的内嵌代码), 输出HTML.目前在StringTemplate的官方网站上已经提供了针对Asp.Net Mvc的ViewEngine.但是官方的ViewEngine模板没有使用VirtualPathProviderViewEngine基类.下面我将 提供一种不能说更好但至少是另一种实现的StringTemplateViewEngine.其中需要使用StringTemplate的模版功能.
要开发一个自己的ViewEngine, 首先要创建实现了IView接口的类, 在此我们创建了名为StringTemplateView的类
public class StringTemplateView : IView { #region 属性 Properties /// <summary> /// StringTemplate 对象, 在构造函数中创建 /// </summary> private StringTemplate StringTemplate { get; set; } #endregion #region 构造函数 Constructed Function private StringTemplateView() { //不用于使用不带参数的构造函数 this.StringTemplate = new StringTemplate(); } public StringTemplateView(StringTemplate template) { //null check if (template == null) throw new ArgumentNullException("template"); //set template this.StringTemplate = template; } #endregion #region IView 成员 void IView.Render(ViewContext viewContext, System.IO.TextWriter writer) { foreach(var item in viewContext.ViewData) { this.StringTemplate.SetAttribute(item.Key.ToString(), item.Value.ToString()); } //为StringTemplate设置HttpContext this.StringTemplate.SetAttribute("context", viewContext.HttpContext); //输出模板 NoIndentWriter noIndentWriter = new NoIndentWriter(writer); this.StringTemplate.Write(noIndentWriter); } #endregion }
StringTemplateView是在StringTemplate视图引擎中View角色的抽象, 所以功能是实现呈现页面的Render方法. StringTemplate的核心功能就是一套自己定义的模板输出引擎, 所以在构造StringTemplateView对象是必须传入一个StringTemplate实例,在Render时只是调用 StringTemplate对象的模板输出方法.
有了IView对象. 接下来就要实现最核心的IViewEngine接口. 在具体的StringTemplateViewEngine类中, 要返回一个带有StringTemplateView对象的ViewEngineResult.
在我的实现方法中,使用了ASP.NET MVC已经提供的VirtualPathProviderViewEngine类作为我们的基类. VirtualPathProviderViewEngine类实现了IViewEngine接口的方法, 提供了在程序中寻找View物理文件路径的机制, 搜索时要使用在派生类中赋值的搜索路径.
下面是我们的StringTemplateViewEngine类实现:
public class StringTemplateViewEngine : VirtualPathProviderViewEngine { private string _AppPath = string.Empty; #region 属性 Properties public static FileSystemTemplateLoader Loader { get; private set; } public static StringTemplateGroup Group { get; private set; } #endregion public StringTemplateViewEngine(string appPath) { _AppPath = appPath; Loader = new FileSystemTemplateLoader(appPath); Group = new StringTemplateGroup("views", Loader); MasterLocationFormats = new[] { "/Views/{1}/{0}.st", "/Views//Shared/{0}.st" }; ViewLocationFormats = MasterLocationFormats; PartialViewLocationFormats = MasterLocationFormats; } protected override IView CreatePartialView(ControllerContext controllerContext, string partialPath) { return this.CreateView(controllerContext, partialPath, String.Empty); } protected override IView CreateView(ControllerContext controllerContext, string viewPath, string masterPath) { StringTemplate stringTemplate = Group.GetInstanceOf(viewPath.Replace(".st", "")); StringTemplateView result = new StringTemplateView(stringTemplate); return result; } }
注意首先在我们的StringTemplateViewEngine中,提供了搜索模板文件的路径,即先从View/{controller}中搜 索,再从View/Share中搜索. 这样VirtualPathProviderViewEngine基类的方法就可以找到我们.st模板文件的具体路径, 然后使用StringTemplateViewEngine中提供的创建StringTemplateView的方法, 根据具体路径创建StringTemplateView对象.
在一些开源的ViewEngine中,尤其是MvcContrib项目中的ViewEngine都将创建View对象的功能放在一个 ViewFactory类中, 个人认为这个更好的设计, 但是由于我们的StringTemplateViewEngine要继承VirtualPathProviderViewEngine, 所以没办法拆分创建View的方法.
至此我们已经完成了StringTemplateViewEngine的全部工作.
首先做一些准备工作. 因为我们的StringTemplate模板文件后缀是".st", 里面写的大部分都是HTML代码. 默认情况下Visual Studio是不会在编辑.st功能的时候提供智能感知支持的. 但是可以通过如下设置实现:
单击菜单中的"工具"->"选项":

在"文本编辑器"的文件扩展名中, 如图所示的为.st扩展名增加"HTML编辑器".
接下来在.st文件中就可以识别HTML代码了:

StringTemplate引擎支持模板的嵌套, 所以可以讲两个页面公用的菜单栏放在menu.st文件中. 而且我们将此文件放在share文件夹中以便供所有模板页调用. menu.st文件代码如下:
<ul id="menu"> <li><a href="/StringTemplate/HelloST">HelloST</a></li> <li><a href="/StringTemplate/SharedST">SharedST</a></li> </ul>
在Controller文件夹中, 创建StringTemplateController用于跳转到我们的模板页:
public class StringTemplateController : Controller { public ActionResult HelloST() { ViewData["msg"] = "Hello String Template ! "; return View("HelloST"); } }
在View文件夹中创建StringTemplate文件夹, 添加一个HelloST.st文件:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>在Shared文件夹中的st页面</title> <link href="../Content/Site.css" rel="stylesheet" type="text/css" /></head> <body> <div class="page"> <h1>StringTemplateViewEngine示例程序</h1> <div id="menucontainer"> $Views/Shared/menu()$ </div> <div id="main"> $msg$ </div> </div> </body> </html>
示例中的代码十分简单, "$msg$"是StringTemplate的模板语言, 可以识别名称为"msg"的变量. "$Views/Shared/menu()$"也是StringTemplate中的语法, 作用是加载名为menu的模板.
虽然Controller和View文件都建立好了, 但是因为ASP.NET MVC默认的视图引擎是WebFormViewEngine, 但是可以同时使用多个视图引擎, 比如可以为所有".st"后缀名的文件使用StringTemplateViewEngine视图引擎.在Global.asax文件中, 在程序启动时注册我们的ViewEngine:
protected void Application_Start() { RegisterRoutes(RouteTable.Routes); //添加StringTemplate视图引擎 StringTemplateViewEngine engine = new StringTemplateViewEngine(Server.MapPath("/")); ViewEngines.Engines.Add(engine); }
现在, 访问"localhost/StringTemplate/HelloST"
,就可以看到我们的自定义的模板引擎的输出结果了:

在文章最后会提供本实例附带StringTemplateViewEngine的完整源代码.
除了自己开发, 目前已经有了很多为ASP.NET MVC提供的ViewEngine:
MVCContrib项目中的ViewEngine:
StringTemplateViewEngine
这是StringTemplate项目为ASP.NET MVC开发的ViewEngine, 官方以及下载网址是
http://www.stringtemplate.org/
另外在著名的MonoRail项目中, 还有一些类似于StringTemplate的页面显示引擎, 虽然都没有为ASP.NET MVC开发专门的ViewEngine, 但是还是很有参考价值的.我们可以用上面介绍的方法, 在页面显示引擎的基础上自己开发ASP.NET MVC的ViewEngine:
MonoRail项目中的三个ViewEngine:
本篇文章详细介绍了ViewEngine相关类, 已经如何开发自己的ViewEngine. 花了2周时间创作完成, 让大家久等了. 说道最近博客园首页的文章问题, 我觉得一篇文章除了要有知识点, 还有能够很好的讲解, 让大家明白比让自己明白更重要.我没有为了速度草草发表文章,就是希望写出来的东西能够有资格发表到博客园首页.
我希望大家都通过自律来建设博客园, 明白分享知识是一件光荣而且快乐的事情!
文章示例代码下载:
随着 B/S 模式应用开发的发展,使用这种模式编写应用程序的程序员也越来越多。但是由于这个行业的入门门槛不高,程序员的水平及经验也参差不齐,相当大一部分程序员 在编写代码的时候,没有对用户输入数据的合法性进行判断,使应用程序存在安全隐患。用户可以提交一段数据库查询代码,根据程序返回的结果,获得某些他想得 知的数据,这就是所谓的 SQL Injection,即SQL注入。
SQL注入是从正常的 WWW 端口访问,而且表面看起来跟一般的 Web 页面访问没什么区别,所以目前市面的防火墙都不会对SQL注入发出警报,如果管理员没查看 IIS 日志的习惯,可能被入侵很长时间都不会发觉。
但是,SQL注入的手法相当灵活,在注入的时候会碰到很多意外的情况。能不能根据具体情况进行分析,构造巧妙的SQL语句,从而成功获取想要的数据,是高手与“菜鸟”的根本区别。
根 据国情,国内的网站用 ASP+Access 或 SQLServer 的占 70% 以上,PHP+MySQ 占 20%,其他的不足 10%。在本文,我们从分入门、进阶至高级讲解一下 ASP 注入的方法及技巧,PHP 注入的文章由 NB 联盟的另一位朋友 zwell 撰写,希望对安全工作者和程序员都有用处。了解 ASP 注入的朋友也请不要跳过入门篇,因为部分人对注入的基本判断方法还存在误区。大家准备好了吗? Lets Go…
如果你以前没试过SQL注入的话,那么第一步先把 IE 菜单 =>工具 => Internet 选项 => 高级 => 显示友好 HTTP 错误信息 前面的勾去掉。否则,不论服务器返回什么错误,IE都只显示为 HTTP 500 服务器错误,不能获得更多的提示信息。
第一节、SQL注入原理
以下我们从一个网站 www.mytest.com 开始(注:本文发表前已征得该站站长同意,大部分都是真实数据)。
在网站首页上,有名为“ IE 不能打开新窗口的多种解决方法”的链接,地址为:http://www.mytest.com/showdetail.asp?id=49,我们在这个地址后面加上单引号’,服务器会返回下面的错误提示:
Microsoft JET Database Engine 错误 80040e14
字符串的语法错误 在查询表达式 ID=49 中。
/showdetail.asp,行8
从这个错误提示我们能看出下面几点:
从上面的例子我们可以知道,SQL注入的原理,就是从客户端提交特殊的代码,从而收集程序及服务器的信息,从而获取你想到得到的资料。
第二节、判断能否进行SQL注入
看完第一节,有一些人会觉得:我也是经常这样测试能否注入的,这不是很简单吗? 其实,这并不是最好的方法,为什么呢?
首先,不一定每台服务器的 IIS 都返回具体错误提示给客户端,如果程序中加了 cint(参数) 之类语句的话,SQL注入是不会成功的,但服务器同样会报错,具体提示信息为处理 URL 时服务器上出错。请和系统管理员联络。
其次,部分对SQL注入有一点了解的程序员,认为只要把单引号过滤掉就安全了,这种情况不为少数,如果你用单引号测试,是测不到注入点的
那么,什么样的测试方法才是比较准确呢?答案如下:
这就是经典的 1=1、1=2 测试法 了,怎么判断呢?看看上面三个网址返回的结果就知道了,可以注入的表现:
不可以注入就比较容易判断了,1 同样正常显示,2 和 3 一般都会有程序定义的错误提示,或提示类型转换时出错。
当然,这只是传入参数是数字型的时候用的判断方法,实际应用的时候会有字符型和搜索型参数,我将在中级篇的“SQL注入一般步骤”再做分析。
第三节、判断数据库类型及注入方法
不同的数据库的函数、注入方法都是有差异的,所以在注入之前,我们还要判断一下数据库的类型。一般 ASP 最常搭配的数据库是 Access 和 SQLServer,网上超过 99% 的网站都是其中之一。
怎么让程序告诉你它使用的什么数据库呢?来看看: SQLServer 有一些系统变量,如果服务器 IIS 提示没关闭,并且 SQLServer 返回错误提示的话,那可以直接从出错信息获取,方法如下:
这 句语句很简单,但却包含了 SQLServer 特有注入方法的精髓,我自己也是在一次无意的测试中发现这种效率极高的猜解方法。让我看来看看它的含义:首先,前面的语句是正常的,重点在 and user>0,我们知道,user 是 SQLServer 的一个内置变量,它的值是当前连接的用户名,类型为 nvarchar。拿一个 nvarchar 的值跟 int 的数 0 比较,系统会先试图将 nvarchar 的值转成 int 型,当然,转的过程中肯定会出错, SQLServer 的出错提示是:将 nvarchar 值 ”abc” 转换数据类型为 int 的列时发生语法错误,呵呵,abc 正是变量 user 的值,这样,不废吹灰之力就拿到了数据库的用户名。在以后的篇幅里,大家会看到很多用这种方法的语句。
顺便说几句,众所周 知,SQLServer 的用户 sa 是个等同 Adminstrators 权限的角色,拿到了 sa 权限,几乎肯定可以拿到主机的 Administrator 了。上面的方法可以很方便的测试出是否是用 sa 登录,要注意的是:如果是 sa 登录,提示是将 ”dbo” 转换成 int 的列发生错误,而不是”sa”。
如果服务器 IIS 不允许返回错误提示,那怎么判断数据库类型呢?我们可以从 Access 和 SQLServer 和区别入手,Access 和 SQLServer 都有自己的系统表,比如存放数据库中所有对象的表,Access 是在系统表 [msysobjects ]中,但在 Web 环境下读该表会提示“没有权限”,SQLServer 是在表 [sysobjects] 中,在 Web 环境下可正常读取。
在确认可以注入的情况下,使用下面的语句:
如 果数据库是 SQLServer,那么第一个网址的页面与原页面 http://www.mytest.com/showdetail.asp?id=49 是大致相同的;而第二个网址,由于找不到表 msysobjects,会提示出错,就算程序有容错处理,页面也与原页面完全不同。
如果数据库用的是 Access,那么情况就有所不同,第一个网址的页面与原页面完全不同;第二个网址,则视乎数据库设置是否允许读该系统表,一般来说是不允许的,所以与原 网址也是完全不同。大多数情况下,用第一个网址就可以得知系统所用的数据库类型,第二个网址只作为开启 IIS 错误提示时的验证。
在入门篇,我们学会了SQL注入的判断方法,但真正要拿到网站的保密内容,是远远不够的。接下来,我们就继续学习如何从数据库中获取想要获得的内容,首先,我们先看看SQL注入的一般步骤:
第一节、SQL注入的一般步骤
首先,判断环境,寻找注入点,判断数据库类型,这在入门篇已经讲过了。
其次,根据注入参数类型,在脑海中重构SQL语句的原貌,按参数类型主要分为下面三种:
接着,将查询条件替换成SQL语句,猜解表名,例如:
如果页面就与 ID=49 的相同,说明附加条件成立,即表 Admin 存在,反之,即不存在(请牢记这种方法)。如此循环,直至猜到表名为止。 表名猜出来后,将 Count(*) 替换成 Count(字段名),用同样的原理猜解字段名。
有 人会说:这里有一些偶然的成分,如果表名起得很复杂没规律的,那根本就没得玩下去了。说得很对,这世界根本就不存在 100% 成功的黑客技术,苍蝇不叮无缝的蛋,无论多技术多高深的黑客,都是因为别人的程序写得不严密或使用者保密意识不够,才有得下手。 有点跑题了,话说回来,对于 SQLServer 的库,还是有办法让程序告诉我们表名及字段名的,我们在高级篇中会做介绍。
最后,在表名和列名猜解成功后,再使用 SQL 语句,得出字段的值,下面介绍一种最常用的方法-Ascii 逐字解码法,虽然这种方法速度很慢,但肯定是可行的方法。
我们举个例子,已知表 Admin 中存在 username 字段,首先,我们取第一条记录,测试长度:
先说明原理:如果 top 1 的 username 长度大于 0,则条件成立;接着就是 >1、>2、>3 这样测试下去,一直到条件不成立为止,比如 >7成立,>8 不成立,就是 len(username)=8
当然没人会笨得从 0,1,2,3 一个个测试,怎么样才比较快就看各自发挥了。在得到 username 的长度后,用 mid(username,N,1) 截取第 N 位字符,再 asc(mid(username,N,1)) 得到 ASCII 码,比如:
同样也是用逐步缩小范围的方法得到第 1 位字符的 ASCII 码,注意的是英文和数字的 ASCII 码在 1-128 之间,可以用折半法加速猜解,如果写成程序测试,效率会有极大的提高。
第二节、SQL注入常用函数
有 SQL 语言基础的人,在SQL注入的时候成功率比不熟悉的人高很多。我们有必要提高一下自己的 SQL 水平,特别是一些常用的函数及命令。
第三节、中文处理方法
在注入中碰到中文字符是常有的事,有些人一碰到中文字符就想打退堂鼓了。其实只要对中文的编码有所了解,“中文恐惧症”很快可以克服。 先说一点常识:
了解了上面的两点后,是不是觉得中文猜解其实也跟英文差不多呢?除了使用的函数要注意、猜解范围大一点外,方法是没什么两样的。
看完入门篇和进阶篇后,稍加练习,破解一般的网站是没问题了。但如果碰到表名列名猜不到,或程序作者过滤了一些特殊字符,怎么提高注入的成功率?怎么样提高猜解效率?请大家接着往下看高级篇。
第一节、利用系统表注入SQLServer数据库
SQLServer 是一个功能强大的数据库系统,与操作系统也有紧密的联系,这给开发者带来了很大的方便,但另一方面,也为注入者提供了一个跳板,我们先来看看几个具体的例子:
以上 6 点是我研究 SQLServer 注入半年多以来的心血结晶,可以看出,对 SQLServer 的了解程度,直接影响着成功率及猜解速度。在我研究 SQLServer 注入之后,我在开发方面的水平也得到很大的提高,呵呵,也许安全与开发本来就是相辅相成的吧。
第二节、绕过程序限制继续注入
在入门篇提到,有很多人喜欢用’号测试注入漏洞,所以也有很多人用过滤’号的方法来“防止”注入漏洞,这也许能挡住一些入门者的攻击,但对SQL注入比较熟悉的人,还是可以利用相关的函数,达到绕过程序限制的目的。
在“SQL注入的一般步骤”一节中,我所用的语句,都是经过我优化,让其不包含有单引号的;在“利用系统表注入SQLServer数据库”中,有些语句包含有’号,我们举个例子来看看怎么改造这些语句:
简 单的如where xtype='U',字符U对应的ASCII码是85,所以可以用where xtype=char(85)代替;如果字符是中文的,比如where name='用户',可以用where name=nchar(29992)+nchar(25143)代替。
第三节、经验小结
SQL 注入漏洞可谓是“千里之堤,溃于蚁穴”,这种漏洞在网上极为普遍,通常是由于程序员对注入不了解,或者程序过滤不严格,或者某个参数忘记检查导致。在这 里,我给大家一个函数,代替 ASP 中的 Request 函数,可以对一切的 SQL 注入 Say NO,函数如下:
Function SafeRequest(ParaName,ParaType)
'ParaName:参数名称-字符型
'ParaType:参数类型-数字型(1表示以上参数是数字,0表示以上参数为字符)
Dim ParaValue
ParaValue=Request(ParaName)
If ParaType=1 then
If not isNumeric(ParaValue) then
Response.write "参数" & ParaName & "必须为数字型!"
Response.end
End if
Else
ParaValue=replace(ParaValue,"","")
End if
SafeRequest=ParaValue
End function
文章到这里就结束了,不管你是安全人员、技术爱好者还是程序员,我都希望本文能对你有所帮助。 (作者:小竹)
继续上一篇开讲:
PR决定了网站的收录速度和排名位置,可以看到博客园的PR值是6,google爬虫每天都会来(至于一天来几次,大家可以看看自己网站的日志或通过 robots.txt访问时间来判断),网站文章的收录速度那真是一个快。那么提高PR值到底该从哪几方面入手呢?大致总结如下:
一、sitemap.xml地图
二、友情链接
三、及时更新
四、各大目录网站的提交
关于以上几点,也要做一下具体说明:
1.sitemap地图对一个建站时间早,更新快的站点来说用处是不大的。但对于一个新的网站来说,sitemap指引google爬虫快速收录网页是非常有效果的。一般提交stiemap.xml文件6小时内甚至30分钟以内就能收录部分页面。
sitemap.xml文件的在线制作地址:http://www.xml-sitemaps.com/ , 将自动生成好的内容存成sitemap.xml文件上传至服务器根目录。然后在google提交验证即可。但这个制作网站会把你所有的页面都生成列表,所 以大家可以根据情况删除掉一些不必要的项目,特别是更新很快的网站(一般来说,sitemap里面存放栏目列表和比较单一的文件列表即可,如 www.xx.com | www.xx.com/news/ | soft.xx.com |之类的目录和二级域名),但在这个列表的页面中千万不可出现死链和错误链接。否则爬虫将随时中止抓取。
2.友情链接。这个大家都比较清楚了。就是与各大网站交换链接。让别人的网站内的某个链接指向你的站点。我们也可以把友情链接称之为外部链接。友情链接是提高PR值最有效的途径。但做友情链接切记以下几点:
(1)不要做无PR值网站的链接(长久来看,这点可以忽略,不因为它的PR值迟早会上去的。呵呵)
(2)不要做被K掉的网站的链接(严重的话可能会殃及到你的网站)
(3)不要做"链接厂家"的链接(就是指一个页面有上百个或几百个友情链接这样的网站,这样效果不大)
(4)尽量多做相关网站的链接(即同行业的网站)
那么友情链接的提高PR值的算法是怎样的呢(在这里给出别人地址:http://bbs.51cto.com/archiver/tid-1781.html ,我不再详述)
当然友情链接的位置也很重要。上篇我们说过页面的权重:一级域名的权重比二级域名的权重高,二级域名比目录(栏目)权重高,目录比内页权重高,静态页比动态页权重高 , 所 以用上面所列四点排除那些无效站点,再把链接放在别人的网站首页,如果放不到。就放二级域名的首页,如果还放不到就放目录首页,依此类推。越前越好。现在 网络上有很多推广之类的软件(就是把你的网站以文字或图片方式自动发送到各个BBS,BLOG之类的网站),在我看来,这样虽然外链多了。 但这样的外链一般没有质量。所以效果也并不一定好。但我并不反对这样的尝试,因为我也在用这一套。但这种方法切不可过火,呵呵!!所以重要的还是自己要有一套稳定的,质量高的外链资源。质量高的外链(即PR值高的外链)才是王道啊。。。
google查看网站收录数命令:site:www.xx.com(www.xx.com即你的网址)
google查看网站外链数命令:link:www.xx.com(同上), 结合SEOquake可以看到你的外链质量
3.即时更新网站:能提高你的页面收录数,提高google的对网站内容重要性的评估。非常重要,不再多说
4,向各大网站提交你的网站。
我必去的:www.dmoz.org (非常严格,我的一个新站提交三个多月了,还没有收录),提交时切记不可出现与政治有关的字眼,最好不要出现china,asia之类的单词(TMD可能有部分审核员对中国在认识上有原则性的错误,看到这些就K你。如果是中文站还是向domz中文站提交吧)
delicious.com,一个开放式书签网站。非常强大
digg.com ,开放式的新闻提交网站。非常强大
国内也有很多类似于dmoz的网站一大把。大家可以搜搜。多提交也是未尝不可。
写在最后:多注意你的外链是否减少了。是否无效了。网站是否被K了。排名是否下降了。即时要做调整哦。其实做SEO最重要的就是要勤劳和那么一点点智慧。
某人Email给你:给我500块,预知你的未来,可以提前通知你,明天国王跟火箭队的比赛,火箭队会赢!
你当然不信啦,但是第二天的比赛,火箭队真的赢了,你说:巧合,巧合而已。
过了几天,他又email给你:给我500快,预知你的未来,可以提前通知你,明天湖人跟火箭队的比赛,湖人赢了。
你有点好奇,但你是绝对不会把钱给他的,但是第二天的比赛,湖人真赢了,你说:诶?难道是潜规则?
又过了几天,他又email给你:给我500快,预知你的未来,可以提前通知你,明天湖人跟七六人队的比赛,湖人赢了。
你开始猜,是不是真的啊?但第二天的比赛,湖人又赢了。
……
经过若干次循环后,你终于想要预知你的未来了。但是当你把钱汇出去没有得到答复时,你才知道上当了!
因为事情是这样的:
第一次发信8192封,一半说国王赢,一般说火箭赢;
第二次只给说火箭赢的4096人发信,分为2048人为湖人赢,2048为火箭赢;
第三次只给说湖人赢的2048人发信,分为1024人为湖人赢,1024为七六人赢;
……
很有可能他最终欺骗到的人只有10,但是这已经足够!
所以你可以说钓鱼式攻击一点技术含量都没有,不过可能你仍会因此被骗。
另外钓鱼者超多,请小心诱饵!
NVelocity是java velocity的C#实现,目前我在CodePlex维护着与Velocity同步的版本。NVelocity也在项目中使用着,在社区也有国外开发者的一些反馈。
下面是一个在ASP.NET如何使用NVelocity的非常简单例子:
定义HttpHandler:
 namespace NVelocity.TestWebsite
namespace NVelocity.TestWebsite {
{ using System; using System.Collections.Generic; using System.IO; using System.Web; using Commons.Collections; using NVelocity.App; using NVelocity.Context; using NVelocity.Runtime;
using System; using System.Collections.Generic; using System.IO; using System.Web; using Commons.Collections; using NVelocity.App; using NVelocity.Context; using NVelocity.Runtime; /// <summary> ///
/// <summary> ///  /// </summary> public class NVelocityHandler : IHttpHandler { #region IHttpHandler Members public bool IsReusable { get { return false; } } public void ProcessRequest(HttpContext context) { VelocityEngine velocity = new VelocityEngine(); ExtendedProperties props = new ExtendedProperties(); //定义模板路径 props.SetProperty(RuntimeConstants.FILE_RESOURCE_LOADER_PATH, Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "Views")); //初始化 velocity.Init(props); List<City> list = new List<City>(); list.Add(new City() { Name = "sh", Id = 21 }); list.Add(new City() { Name = "bj", Id = 22 }); list.Add(new City() { Name = "tj", Id = 23 }); IContext c = new VelocityContext(); //添加到上下文中 c.Put("cities", list); //根据请求输出 velocity.MergeTemplate(context.Request.QueryString["vm"] + ".vm", "UTF-8", c, context.Response.Output); } #endregion } /// <summary> /// 城市 /// </summary> public class City { /// <summary> /// ID /// </summary> public int Id { get; set; } /// <summary> /// 名称 /// </summary> public string Name { get; set; } }
/// </summary> public class NVelocityHandler : IHttpHandler { #region IHttpHandler Members public bool IsReusable { get { return false; } } public void ProcessRequest(HttpContext context) { VelocityEngine velocity = new VelocityEngine(); ExtendedProperties props = new ExtendedProperties(); //定义模板路径 props.SetProperty(RuntimeConstants.FILE_RESOURCE_LOADER_PATH, Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "Views")); //初始化 velocity.Init(props); List<City> list = new List<City>(); list.Add(new City() { Name = "sh", Id = 21 }); list.Add(new City() { Name = "bj", Id = 22 }); list.Add(new City() { Name = "tj", Id = 23 }); IContext c = new VelocityContext(); //添加到上下文中 c.Put("cities", list); //根据请求输出 velocity.MergeTemplate(context.Request.QueryString["vm"] + ".vm", "UTF-8", c, context.Response.Output); } #endregion } /// <summary> /// 城市 /// </summary> public class City { /// <summary> /// ID /// </summary> public int Id { get; set; } /// <summary> /// 名称 /// </summary> public string Name { get; set; } } }
}一个用于测试的default.vm模板文件:
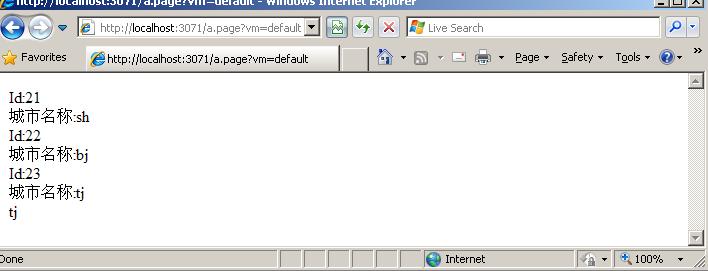
##循环输出#foreach($city in $cities)Id:$city.id<br />城市名称:$city.name<br />#end##索引获取数据$cities.get_item(2).name在Web.config中配置上面定义的HttpHandler:
请求及输出效果: