搜索引擎 创意 shell
主要功能:shell版的搜索引擎
自由言论:在web上用用shell也是一件挺有意思的事情,蛮有一种复古的感觉。感谢google提供这种shell检索的方式(help查看可用命令)。
页面截图:


搜索引擎 创意 shell
主要功能:shell版的搜索引擎
自由言论:在web上用用shell也是一件挺有意思的事情,蛮有一种复古的感觉。感谢google提供这种shell检索的方式(help查看可用命令)。
页面截图:
前两天写了一篇立主机无限二级域名解释的方式,不过由于服务器出了点问题,自己比较忙,这篇就拖了点时间才写出来!
现在实现无限二级域名解释的方式,如重写url的组件也相当多!实现方式也不少!实现方式也不难。
独立主机的实现方法最简单的一个可以参考:http://www.cnblogs.com/flyboy/archive/2009/01/06/1369932.html
不过不幸的是所有这些都要求主机支持域名泛解析,一旦拿到虚拟主机上,一切都枉然!
我也是在自己机器上做好后拿到虚拟主机上发现完全作废!不过也不是没办法!
下面就讲讲如何实现虚拟主机上实现二级别域名解析(泛解析) (ASP.NET)吧!
1、首先,在域名解析里,要把*.iloveyou.io 隐含转向指向你网站的某个转门用来判断的页面,注意,必须是隐含!我们假设为 http://www.iloveyou.io/wr.aspx
2、在http://www.iloveyou.io/wr.aspx 页面取的来路的路径!
protected void Page_Init(object sender, EventArgs e)
{
string path = Request.UrlReferrer.AbsoluteUri.ToLower();
。。。
}
这里取得的不是当前路径,而是来路路径,也就是转向前url的路径了!
取得后就进行你需要的处理! 用上一节的例子来讲,把 http://liangsan.iloveyou.io 解析到 http://www.iloveyou.io/love/?toName=liangsan 这个页面。
3、 用 Response.Redirect(newurl);来实现跳转~!
protected void Page_Init(object sender, EventArgs e)
{
string path = Request.UrlReferrer.AbsoluteUri.ToLower();//得到的如path =http://liangsan.iloveyou.io/
。。。
string newurl=…//如 http://www.iloveyou.io/love/?toName=liangsan
Response.Redirect(newurl);
}
具体的例子可以上一个爱情表白的网站看下: http://www.iloveyou.io
缺点,不过这个方法有个缺点就是,百度收录页面看不到二级域名页面的内容,不利搜索引擎!
不过因为我没有自己独立主机,又要实现,用户可以申请 “心上人名字.iloveyou.io"的域名做为表白使用,只能放弃搜索引擎了!
不知道朋友你有没什么更好的解决方法,有的话请告知小弟!谢谢!
以上就是本人所知道和已经实现的虚拟主机上实现二级别域名解析(泛解析) (ASP.NET),如有不足请指正!谢谢!
在进行ASP.NET调试的时候,我们经常需要借助一些外部工具来辅助我们。俗话说,工欲善其事 必先利其器。可别小看了这些工具,它是你解决复杂问题的必备利器。比较常用的有这些:
HTTP抓包工具: Microsoft Network Monitor,Fiddler2,HttpWatcher 等,主要用来查看HTTP消息的header,以及body。
代码查看器: Reflector,利用反编译来查看assembly里的代码。通过这个工具,我们可以很轻易的看到.NET Framework的一些功能是怎么实现的。
文件监视器: Process Monitor,可以用来监视系统的哪些文件正在被修改,注册表中有什么改动等等,功能非常强大。
数据库工具:SQL Sever Profiler,可以用来查看SQL Server正在执行哪些脚本。对于和SQL Server通信的程序的调试,它是非常实用的。
其实还有很多好用的工具,但是如果能熟练使用这几个工具了,大部分的问题都能轻易解决了。下次将会介绍一下IIS 7中调试ASP.NET程序的一些实用的方法。
原文:A Million-user Comet Application with Mochiweb, Part 1
参考资料:Comet–基于 HTTP 长连接、无须在浏览器端安装插件的“服务器推”技术为“Comet”
MochiWeb–建立轻量级HTTP服务器的Erlang库
在这个系列中,我将详述我所发现的mochiweb是怎样支持那么巨大的网络连接的,为大家展示怎样用mochiweb构建一个comet应用,这个应用 中每个mochiweb连接都被注册到负责为不同用户派送消息的路由器上。最后我们建立一个能够承受百万并发连接的可工作的应用,更重要的我们将知道这样 的应用需要多少内存才能使它跑起来。
本部分内容如下:
本系列续作将包括怎样建立一个真正的信息路由系统,降低内存使用的技巧,100K和1m并发连接的测试。
基础是你需要知道一些linux命令行操作和一点Erlang知识,否则看不懂别怪我呀,呵呵
概括如下:
/your-mochiweb-path/scripts/new_mochiweb.erl mochiconntest cd mochiconntest 之后编辑 src/mochiconntest_web.erl 这部分代码(mochiconntest_web.erl)只是接收连接并且每十秒用块传输方式给客户端发送一个初始的欢迎信息。
mochiconntest_web.erl
make && ./start-dev.sh
缺省的Mochiweb在所有网卡接口的8000端口上进行监听,假如是在桌面系统上做这些事,你可以使用任何浏览器访问http://localhost:8000/test/foo 进行测试。
这里只是命令行测试:
$ lynx --source "http://localhost:8000/test/foo" Mochiconntest welcomes you! Your Id: foo<br/> Chunk 1 for id foo<br/> Chunk 2 for id foo<br/> Chunk 3 for id foo<br/> ^C
是的,它可以工作。 现在,让我们使劲整它,呵呵。
为节省时间我们需要在进行大量并发连接测试之前调整内核的tcp设置参数,否则你的测试将会失败,你将看到大量的Out of socket memory 信息(假如在伪造将得到, nf_conntrack: table full, dropping packet. )
下面的是我用到的sysctl设置 – 你的配置可能不一样,但是大致就是这些:
# General gigabit tuning: net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.ipv4.tcp_syncookies = 1 # this gives the kernel more memory for tcp # which you need with many (100k+) open socket connections net.ipv4.tcp_mem = 50576 64768 98152 net.core.netdev_max_backlog = 2500 # I was also masquerading the port comet was on, you might not need this net.ipv4.netfilter.ip_conntrack_max = 1048576
把这些写到 /etc/sysctl.conf中然后运行 sysctl -p 使其生效。不需要重启,现在你的内核能够处理大量的连接了,yay。
有很多方法可以用. Tsung 就十分好, 也有很多其他比较好的工具如ab, httperf, httpload等等可以生成大量的无用请求。 但是它们中任何一款都不适合测试comet应用, 正好我也想找个借口测试一下Erlang的http客户端, 因此我写了一个基本的测试程序用以发起大量的连接。
只是因为你可以但并不意味着你就这样做.. 一个连接就用一个进程确实有点浪费。我用一个进程从文件中调入一批url链接,另一个进程建立连接并接收数据 (当定时器的进程每10秒打印一份报告)。所有从服务器接收来的数据都被丢弃,但是它增加计数,这样我们能够跟踪到底有多少http数据块被传输了。
floodtest.erl
每个连接我们都要用一个临时的端口,每个端口也是一个文件描述符, 缺省情况下这被限制为1024。为了避免Too many open files问题出现,你需要为你当前shell更改这个限制 ,可以通过修改/etc/security/limits.conf ,但是这需要注销再登陆。目前你只需要用sudo修改当前shell就可以了(假如你不想运行在root状态下,调用ulimit后请su回非权限用户):
udo bash # ulimit -n 999999 # erl
你也可以把临时端口的范围区间增到最大:
# echo "1024 65535" > /proc/sys/net/ipv4/ip_local_port_range
为压力测试程序生成一个url列表文件
( for i in `seq 1 10000`; do echo "http://localhost:8000/test/$i" ; done ) > /tmp/mochi-urls.txt
现在在erlang提示符下你可以编译调用floodtest.erl 了:
erl> c(floodtest).
erl> floodtest:start("/tmp/mochi-urls.txt", 100).
这将每秒钟建立十个连接 (也就是每个连接100毫秒).
它将以{Active, Closed, Chunks}的形式输出状态信息 ,Active表示已建立连接数, Closed表示因每种原因被终止的连接数,Chunks是mochiweb以块传输模式处理的数据块数。 Closed应该为0,Chunks应该大于Active,因为每个活跃连接接收多个数据块 (10秒一个)。
10,000个活跃连接的mochiweb进程的固定大小是450MB-也就是每个连接45KB。 CPU占用率就好像预想中的一样微乎其微.
第一次尝试是可以理解的。每个连接45KB内存看起来有些高 – 用libevent再做些调整我可以把它做到将近4.5KB每个连接 (只是猜猜, 谁有这方面的经验请留个回复). 如果就代码量和时间效率上对erlang和c做下考量,我想多花点内存还是有情可原的。
后续中,我将建立一个消息路由器 (我们可以把mochiconntest_web.erl中的 25行和41-43行的注释取消 )也探讨一下减少内存用量的方法。我也会分享当100k和1M个连接时的测试结果。
1. 时间点(指定时间点内有效);
2. KEY值(KEY值作Cache项标识);
3. 文件或目录(指定文件或目录变更,则原Cache项不可用);
代码:
 using System;using System.Collections;using System.Text.RegularExpressions;using System.Web;using System.Web.Caching;namespace Ycweb.Components
using System;using System.Collections;using System.Text.RegularExpressions;using System.Web;using System.Web.Caching;namespace Ycweb.Components {
{ public class SiteCache
public class SiteCache { private static readonly Cache _cache; public static readonly int DayFactor; private static int Factor; public static readonly int HourFactor; public static readonly int MinuteFactor; static SiteCache() { DayFactor = 17280; HourFactor = 720; MinuteFactor = 12; Factor = 5; _cache = HttpRuntime.Cache;
{ private static readonly Cache _cache; public static readonly int DayFactor; private static int Factor; public static readonly int HourFactor; public static readonly int MinuteFactor; static SiteCache() { DayFactor = 17280; HourFactor = 720; MinuteFactor = 12; Factor = 5; _cache = HttpRuntime.Cache; } private SiteCache() { } public static void Clear() { IDictionaryEnumerator enumerator = _cache.GetEnumerator(); while (enumerator.MoveNext()) { _cache.Remove(enumerator.Key.ToString()); } } public static object Get(string key) { return _cache[key]; } public static void Insert(string key, object obj) { Insert(key, obj, null, 1); } public static void Insert(string key, object obj, int seconds) { Insert(key, obj, null, seconds); } public static void Insert(string key, object obj, CacheDependency dep) { Insert(key, obj, dep, HourFactor*12); } public static void Insert(string key, object obj, int seconds, CacheItemPriority priority) { Insert(key, obj, null, seconds, priority); } public static void Insert(string key, object obj, CacheDependency dep, int seconds) { Insert(key, obj, dep, seconds, CacheItemPriority.Normal); } public static void Insert(string key, object obj, CacheDependency dep, int seconds, CacheItemPriority priority) { if (obj != null) { _cache.Insert(key, obj, dep, DateTime.Now.AddSeconds((double) (Factor*seconds)), TimeSpan.Zero, priority, null); } } public static void Max(string key, object obj) { Max(key, obj, null); } public static void Max(string key, object obj, CacheDependency dep) { if (obj != null) { _cache.Insert(key, obj, dep, DateTime.MaxValue, TimeSpan.Zero, CacheItemPriority.AboveNormal, null); } } public static void MicroInsert(string key, object obj, int secondFactor) { if (obj != null) { _cache.Insert(key, obj, null, DateTime.Now.AddSeconds((double) (Factor*secondFactor)), TimeSpan.Zero); } } public static void Remove(string key) { _cache.Remove(key); } public static void RemoveByPattern(string pattern) { IDictionaryEnumerator enumerator = _cache.GetEnumerator(); Regex regex1 = new Regex(pattern, RegexOptions.Singleline | RegexOptions.Compiled | RegexOptions.IgnoreCase); while (enumerator.MoveNext()) { if (regex1.IsMatch(enumerator.Key.ToString())) { _cache.Remove(enumerator.Key.ToString()); } } } public static void ReSetFactor(int cacheFactor) { Factor = cacheFactor; } }
} private SiteCache() { } public static void Clear() { IDictionaryEnumerator enumerator = _cache.GetEnumerator(); while (enumerator.MoveNext()) { _cache.Remove(enumerator.Key.ToString()); } } public static object Get(string key) { return _cache[key]; } public static void Insert(string key, object obj) { Insert(key, obj, null, 1); } public static void Insert(string key, object obj, int seconds) { Insert(key, obj, null, seconds); } public static void Insert(string key, object obj, CacheDependency dep) { Insert(key, obj, dep, HourFactor*12); } public static void Insert(string key, object obj, int seconds, CacheItemPriority priority) { Insert(key, obj, null, seconds, priority); } public static void Insert(string key, object obj, CacheDependency dep, int seconds) { Insert(key, obj, dep, seconds, CacheItemPriority.Normal); } public static void Insert(string key, object obj, CacheDependency dep, int seconds, CacheItemPriority priority) { if (obj != null) { _cache.Insert(key, obj, dep, DateTime.Now.AddSeconds((double) (Factor*seconds)), TimeSpan.Zero, priority, null); } } public static void Max(string key, object obj) { Max(key, obj, null); } public static void Max(string key, object obj, CacheDependency dep) { if (obj != null) { _cache.Insert(key, obj, dep, DateTime.MaxValue, TimeSpan.Zero, CacheItemPriority.AboveNormal, null); } } public static void MicroInsert(string key, object obj, int secondFactor) { if (obj != null) { _cache.Insert(key, obj, null, DateTime.Now.AddSeconds((double) (Factor*secondFactor)), TimeSpan.Zero); } } public static void Remove(string key) { _cache.Remove(key); } public static void RemoveByPattern(string pattern) { IDictionaryEnumerator enumerator = _cache.GetEnumerator(); Regex regex1 = new Regex(pattern, RegexOptions.Singleline | RegexOptions.Compiled | RegexOptions.IgnoreCase); while (enumerator.MoveNext()) { if (regex1.IsMatch(enumerator.Key.ToString())) { _cache.Remove(enumerator.Key.ToString()); } } } public static void ReSetFactor(int cacheFactor) { Factor = cacheFactor; } } }
}
有了SiteCache类,接下来看看如何使用它。还是以读取新闻TonN列表为例:
public static RecordSet GetNewsSetTopN(string classCode,int topN,SortPostsBy orderBy, SortOrder sortOrder, string language){ string cacheKey = string.Format("NewsSetTopN-LG:{0}:CC:{1}:TN:{2}:OB:{3}:SO:{4}", language,classCode,topN.ToString(), orderBy.ToString(),sortOrder.ToString()); //从上下文中读缓存项 RecordSet newsSet = HttpContext.Current.Items[cacheKey] as RecordSet; if (newsSet == null) { //从HttpRuntime.Cache读缓存项 newsSet = SiteCache.Get(cacheKey) as RecordSet; if (newsSet == null) { //直接从数据库从读取 CommonDataProvider dp=CommonDataProvider.Instance(); newsSet =dp.GetNewsSetTopN(language,classCode,topN,orderBy,sortOrder); //并将结果缓存到HttpRuntime.Cache中 SiteCache.Insert(cacheKey, newsSet, 60, CacheItemPriority.Normal); } }return newsSet;}
/// <summary>/// 删除匹配的NewsSetTopN列表的Cache项/// </summary>public static void ClearNewsSetTopNCache(string language,string classCode,int topN){ string cacheKey = string.Format("NewsSetTopN-LG:{0}:CC:{1}:TN:{2}",language,classCode,topN.ToString()); SiteCache.RemoveByPattern(cacheKey);}发布新闻后调用静态方法ClearNewsSetTopNCache()强行清除原来的TopN缓存项,例如:
/// <summary>/// 发布(新建)新闻/// </summary>/// <param name="post">新闻实例</param>/// <returns>返回状态</returns>public static int Create(News post){ int status; CommonDataProvider dp=CommonDataProvider.Instance(); dp.CreateUpdateDeleteNews(post, DataAction.Create, out status); //强制清除匹配的缓存项 ClearNewsSetTopNCache (post.Language, post.ClassCode,Globals.GetSiteSetting.NewsListTopN); return status;}
That's all.若有不妥之处还望各位同行指正。
Flex之于Java,就像美丽之于大脑,或者还有别的说法?谁能告诉我?我所知道的是,Flex和Java真的是能配合得很好,能创建出难以置信 的富 Internet应用(RIA)。你会问Flex是什么?Flex是一个开源框架,你可以通过基于标签的MXML语言(以及ActionScript 3)来构建Flash应用。
请观看:Jack有关Flex与JSON及XML互操作的演讲 (QuickTime格式,33MB)。
你可以从Adobe的站点下载(http://adobe.com/flex)Flex IDE即所谓Flex Builder,并由此开始你的开发之旅。Flex Builder是个商业产品,但它有很长的免费试用阶段,能让你有足够时间想清楚是不是值得掏这个钱。在这篇文章中,我会演示如何一起使用Flex和 Java。Java会运行在服务器端,而Flex运行在客户端。这两端间的通信协议可以是任何你想要的协议。但在这里,我会先使用XML,然后再使用 JSON,因为这两种技术是我们在Web 2.0的世界里最常见的。
XML示例由列表1中显示的简单JSP文件开始:
列表1. xml.jsp
<jsp:root xmlns:jsp="http://java.sun.com/JSP/Page" version="1.2">
<jsp:directive.page import="java.text.*"/>
<jsp:directive.page import="java.lang.*"/>
<jsp:directive.page contentType="text/xml"/>
<days><jsp:scriptlet>
<![CDATA[
double compa = 1000.0;
double compb = 900.0;
for (int i = 0; i<=30; i++) {
compa += ( Math.random() * 100 ) - 50;
compb += ( Math.random() * 100 ) - 50;
]]>
</jsp:scriptlet>
<day>
<num><jsp:expression>i</jsp:expression></num>
<compa><jsp:expression>compa</jsp:expression></compa>
<compb><jsp:expression>compb</jsp:expression></compb>
</day>
<jsp:scriptlet>
<![CDATA[ }
]]>
</jsp:scriptlet>
</days>
</jsp:root>
这个服务会每三十天为两家公司(compa和compb)导出一些随机的股票数据。第一家公司的数值从1000美元开始,第二家从900美元开始,而JSP代码会每天为这两个数值增加一个随机数。
当我从命令行使用curl客户端去访问这个服务时,我获得的是下面这样的结果:
% curl "http://localhost:8080/jsp-examples/flexds/xml.jsp" <days><day><num>0</num><compa>966.429108587301</compa> <compb>920.7133933216961</compb> </day>...</days>
根标签是<days>标签,它包含了一个<day>标签的集合。每个<day>标签都 有一个<num>标签来表示天数,一个<compa>值来表示公司A的股票价格,以及<compb>值来表示公司B 的股票价格。两只股票的数值随着每次请求而不同,因为它们是随机生成的。
现在我们已经有了一个web服务来输出股票的价格,我们还需要一个客户端应用来展现它。我们要构建的第一个界面是表格风格的界面,用它来简单的显示 数字。为了创建Flex项目,我们在Flex Builder IDE的新建菜单中选择Flex Project。显示如图1:

图1. 新Flex项目对话框
在这我们要做的就是给项目起个名字。我把它叫做xmldg,意思是XML数据表格。这样就会创建出一个名叫xmldg.mxml的文件,其中只包含一个空白标签。下面我会使用列表2中的代码来代替这个空白标签。
列表2. xmldg.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:XML source="http://localhost:8080/jsp-examples/flexds/xml.jsp" id="stockData" />
<mx:Panel title="Stock Data" width="100%" height="100%">
<mx:DataGrid dataProvider="{stockData..day}" width="100%" height="100%">
<mx:columns>
<mx:DataGridColumn dataField="compa" />
<mx:DataGridColumn dataField="compb" />
</mx:columns>
</mx:DataGrid>
</mx:Panel>
</mx:Application>
xmldg应用程序代码有两个主要的组件。第一个是<mx:XML>标签,它告诉Flex这是个XML数据源,并提供了URL。这样就会创建一个叫做stockData(由id属性指定)的局部变量,而<mx:DataGrid>组件可以把它当作dataProvider来使用。
代码的剩余部分就是界面了。<mx:Panel>对象为表格提供了一个简洁的包装。而<mx:DataGrid>用来显示数据。在<mx:DataGrid>中,是一串<mx:DataGridColumn>对象,来告诉表格显示什么数据。
如果我们从Flex Builder运行这个界面,你就会看到像图2的这个样子:

图2. xmldg应用运行界面
我们可以拉动滚动条,改变窗口大小,并且看到数据表格也会改变大小。如果需要添加一点过滤的功能,我们就需要使用<mx:HSlider>控件来更新代码,为它添加一个水平的滑块,来指定表格从哪一天开始显示数据。
比如,如果我们设置滑块到6,它就会只显示从第六天开始的数据。代码如列表3所示:
列表3. xmldg2.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:XML source="http://localhost:8080/jsp-examples/flexds/xml.jsp" id="stockData" />
<mx:Panel title="Stock Data" width="100%" height="100%" layout="vertical"
paddingBottom="10" paddingLeft="10" paddingRight="10" paddingTop="10">
<mx:HBox>
<mx:Label text="Start Day" />
<mx:HSlider minimum="0" maximum="30" id="dayslider" snapInterval="1" />
</mx:HBox>
<mx:DataGrid dataProvider="{stockData..day.(num >= daySlider.value )}" width="100%" height="100%">
<mx:columns>
<mx:DataGridColumn dataField="num" headerText="day" />
<mx:DataGridColumn dataField=="compa" headerText="Company A" />
<mx:DataGridColumn dataField=="compb" headerText="Company B" />
</mx:columns>
</mx:DataGrid>
</mx:Panel>
</mx:Application>
还有其他的一些标签,但规则基本上还是一样的。<mx:Panel>标签可以包含所有内容。其中可以是<mx:HBox> (水平 格)标签,并且box还包含着<mx:Label>和<mx:HSlider>控件。slider用 于<mx:DataGrid>的dataProvider字段。
让我们来更进一步看看dataProvider属性:
{stockData..day.(num >= daySlider.value )}
这里使用的是ActionScript的E4X语法来减少<mx:DataGrid>控件的数据集合,使其只包含那些<num>值大于或等于滑块值的标签。Flex非常智能,它能观察到滑块的变化事件,并自动更新数据表格。
当我们从Flex Builder运行这个界面时,它看起来就像是图3这样:

图3. 可过滤性网格
我们可以调整滑块的位置,并查看到表格中的数据如何变化。图4显示的是我把滑块设到12时的样子:

图4. 滑块设为12时的显示界面
这只是个使用ActionScript中E4X的简单例子。E4X语法使得处理XML变得非常容易,以至于你不会再愿意使用任何其他办法来处理XML了。
数据表格有点让人厌倦了,至少对我来说是这样。我喜欢有图像的。那么让我们来干点什么——在界面上放置一张图表。我们创建了一个新的名叫xmlgph(意思是XML图表)的项目,并用列表4中的代码来代替自动生成的xmlgph.xml文件。
列表4. xmlgph.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:XML source="http://localhost:8080/jsp-examples/flexds/xml.jsp" id="stockData" />
<mx:Panel title="Stock Data" width="100%" height="100%" layout="vertical"
paddingBottom="10" paddingLeft="10" paddingRight="10" paddingTop="10">
<mx:HBox>
<mx:Label text="Start Day" />
<mx:HSlider? minimum="0" maximum="30" id="dayslider" snapInterval="1" />
</mx:HBox>
<mx:LineChart id="chart" dataProvider="{stockData..day.(num >= daySlider.value )}"
width="100%" height="100%">
<mx:series>
<mx:LineSeries xField="num" yField="compa" displayName="Company A" />
<mx:LineSeries xField="num" yField="compb" displayName="Company B" />
</mx:series>
</mx:LineChart>
<mx:Legend dataProvider="{chart}" />
</mx:Panel>
</mx:Application>
代码就跟xmldb2一样,但<mx:LineChart>控件替代了<mx:DataGrid>控件,用来显示一张数值 图表, 而不是一个表格。另外还有个<mx:Legend>控件来显示不同颜色线条代表的公司名称。而两 个<mx:LineSeries>对象就类似于<mx:DataGridColumn>的功能。它们让线性图表知道在哪个轴上显 示什么数据。
当我们从Flex Builder运行这个界面是,看到的会是图5这个样子:

图5. 线形图例
还不错吧?因为<mx:HSlider>控件还在那里,所以我们可以移动滑块的位置来改变图表的起始日期。
事实上,只需要一点点小的改变,我们就可以为用户在滑块上提供两个滑动杆,这样它们就能独立移动来让这个图表只显示一段日期内的数据。代码显示如列表5所示:
列表5. xmlgph2.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:XML source="http://localhost:8080/jsp-examples/flexds/xml.jsp" id="stockData " />
<mx:Panel title="Stock Data " width="100% " height="100% " layout="vertical "
paddingBottom="10 " paddingLeft="10 " paddingRight="10 " paddingTop="10 ">
<mx:HBox>
<mx:Label text="Date Range " />
<mx:HSlider minimum="0 " maximum="30 " id="daySlider " snapInterval="1 "
thumbCount="2 " values="[0,30] " />
</mx:HBox>
<mx:LineChart id="chart"
dataProvider="{stockData..day.(num>=daySlider.values[0] &&
num<=daySlider.values[1])}"
width="100%" height="100%">
<mx:series>
<mx:LineSeries xField="num" yField="compa" displayName="Company A" />
<mx:LineSeries xField="num" yField="compb" displayName="Company B" />
</mx:series>
</mx:LineChart>
<mx:Legend dataProvider="{chart}" />
</mx:Panel>
</mx:Application>
我们需要做的就是为<mx:HSlider>标签添加thumbCount和values属性,并更 新<mx:DataGrid>标签中的dataProvider。因为这是段XML,我必须对dataProvider中的部分实体进行编 码。如果从Flex Builder运行这段代码,我们会看到图6显示的那样:

图6.窗口型线形图
以上这些就是范例演示的XML部分。下面开始我会演示如何构建一个能调用JSON服务的Flex应用程序。
我们由创建一个JSON数据源作为开端,来创建JSON阅读应用程序。同样,我们还是使用可靠的JSP来给构建JSON编码的数据流。这段服务器上的JSP代码显示如列表6:
列表6. json.jsp
<jsp:root xmlns:jsp="http://java.sun.com/JSP/Page" version="1.2">
<jsp:directive.page import="java.text.*"/>
<jsp:directive.page import="java.lang.*"/>
<jsp:directive.page contentType="text/json"/>
[<jsp:scriptlet>
<![CDATA[
double compa = 1000.0;
double compb = 900.0;
for (int i = 0; i<=30; i++) {
compa += ( Math.random() * 100 ) - 50;
compb += ( Math.random() * 100 ) - 50;
if ( i > 0 ) out.print( "," );
]]> </jsp:scriptlet>{"compa":<jsp:expression>compa</jsp:expression>,"compb":<jsp:expres
sion>compb</jsp:expression>}<jsp:scriptlet>
<![CDATA[ }
]]>
</jsp:scriptlet>]
</jsp:root>
这就跟XML服务一样,但我们创建的不是XML标签,而是JSON编码的数据。
当我从命令行运行curl时,得到的页面如下所示:
% curl "http://localhost:8080/jsp-examples/flexds/json.jsp"
[{"compa":992.2139849199265,"compb":939.89135379532}, ...]
而这恰恰是JavaScript客户端能够理解的东西。
Flex是用Flash播放器的编程语言ActionScript 3编写的。它和JavaScript很类似,但它没有eval方法。那么我们如何将JSON文本转换成ActionScript数据呢?幸运的是,免费的ActionScript 3核心库(http://as3corelib.googlecode.com)包含了JSON解码器和JSON编码器。
列表7中的代码演示了JSONDecoder对象的用法:
列表7. jsondg.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical"
creationComplete="jsonservice.send()">
<mx:Script>
<![CDATA[
import mx.rpc.events.ResultEvent;
import com.adobe.serialization.json.JSONDecoder;
private function onJSONResult( event:ResultEvent ) : void {
var data:String = event.result.toString();
data = data.replace( /\s/g, '' );
var jd:JSONDecoder = new JSONDecoder( data );
dg.dataProvider = jd.getValue();
}
]]>
</mx:Script>
<mx:HTTPService id="jsonservice"
url="http://localhost:8080/jsp-examples/flexds/json.jsp"
resultFormat="text" result="onJSONResult(event)" />
<mx:Panel title="Stock Data " width="100% " height="100% ">
<mx:DataGrid id="dg" width="100%" height="100%">
<mx:columns>
<mx:DataGridColumn dataField="compa " />
<mx:DataGridColumn dataField="compb " />
</mx:columns>
</mx:DataGrid>
</mx:Panel>
</mx:Application>
因为服务器返回的是JSON文本,我们无法使用<mx:XML>标签来取得数据。因此我们用的 是<mx:HTTPService>标签。它的工作原理跟<mx:XML>很像。你需要给它一个服务的URL,并且告诉它结果的 格式(比如文本)以及HTTP服务发回响应数据时需要调用的ActionScript方法。
在这个例子中,我为结果处理方法指定的是在<mx:Script>标签中定义的onJSONResult方法。这个方法会去掉所有空 格,并把 JSON文本传递给JSONDecoder对象。接着它将<mx:DataGrid>控件的dataProvider设置成 JSONDecoder返回的处理结果。
所有这些都是安全的,因为ActionScript不支持eval方法。JSONDecoder类是个简单状态机解析器,来实时地从文本构建出对象。最糟糕的情况可能是这样的过程会需要一段比较长的时间,如果JSON文本太大的话。
Flex是基于Flash的,而Flash可以跟任何技术进行交互。它可以直接与基于SOAP的web服务交互。它甚至能跟AMF(Adobe Message Format)这样的协议进行二进制数据的通信。
如果这是你第一次使用Flex,你可能会想着如何用Flex来构建一个Flash小部件,放到自己的网站上以更吸引人的方式来显示数据。为了确保 Flash应用的尺寸足够小方便下载,记得一定要使用新版本Flash播放器中的运行时共享库(Runtime Shared Library,RSL)。这可以让你在客户端缓存大尺寸的库(比如Flex库),并在不同的Flash应用中重用这些库。
Flex和Java是一个强大的组合。Java提供了优秀的的服务器后端支持。而Flex和ActionScript 3提供的是一个易于编写和采用的通用跨平台的GUI层。
查看英文原文:Flex for XML and JSON。
code2plan是由Jesse Johnston和Denis Morozov创建的一个敏捷软件项目管理工具,作为一款Visual Studio插件,其beta版已经免费发布了。该工具还能以独立应用的方式运行,可用来跟踪项目、迭代、用户故事、测试、缺陷及构建。
敏捷的软件项目管理正变得越来越流行,因此你也不会对另一个敏捷工具的出现而大惊小怪。该工具吸引人的地方在于其与Visual Studio 2008的集成,但它还能以独立应用的方式运行。要想运行该工具则需要.NET Framework 3.5 SP1,如果没有的话,那么在安装该工具时会自动安装。
当前code2plan会跟踪如下内容:项目、迭代、用户故事、特性、测试、缺陷及构建。该工具还可以通过跟踪阶段(而不是迭代)及需求(而不是故事)管理传统项目。它能够为这两类项目创建燃尽图。
code2plan可以使用自己的数据库,也能连接到团队的数据库,它同时支持SQL 2005及2008。通过使用团队的数据库,团队成员能共享项目并对其进行编辑。团队中的每个成员都可以更新当前视图以及时查看其它成员的修改。我们可以 离线编辑项目,一旦连接到网络上,这些改变就会自动地与团队进行同步。它对于团队成员的数量没有限制。
code2plan是免费的,也不需要注册和license。这个二人组打算将来发布一个功能更多的应用——很可能不再免费了,但他们承诺其基础版会一直免费下去。该项目并不开源,也不打算开源。不久他们会发布一个SDK,其他开发者可以借助其API来增强该工具。
Read a free sample chapter from each of these upcoming ASP.NET MVC Books

ASP.NET MVC in Action
by Jeffrey Palermo, Dave Verwer, and Ben Scheirman

ASP.NET MVC Framework Unleashed
by Stephen Walther

Pro ASP.NET MVC Framework Preview
by Steve Sanderson

Professional ASP.NET 3.5 MVC
by Rob Conery, Scott Hanselman, Phil Haack

Programming ASP.NET MVC
by Alex Horovitz
多线程可以提高应用程序的效率,这是肯定的,但是,效率是不是最优的呢,是不是觉得多线程很复杂呢?
前面学习线程的知道,用多线程需要CreateThread创建线程,还要关闭线程。另外,多线程有时候还要对资源进行同步,也就是说,需要用到事件,信标,互斥对象。
当然,线程与进程比较,无论速度,对资源的访问,安全性上面线程都有非常大的优势。但是,创建与销毁线程并不是免费的。
要创建一个线程,需要分配和初始化一个内核对象,也需要分配和初始化线程的堆栈空间,而且 Windows® 为进程中的每个 DLL 发送一个 DLL_THREAD_ATTACH 通知,使磁盘中的页分配到内存中,从而执行代码。当线程终止时,给每个 DLL 都发送一个 DLL_THREAD_DETACH 通知,线程的堆栈空间被释放,内核对象亦被释放(如果其使用数达到 0)。因此,与创建和销毁线程相关的许多开销都和创建线程原本要执行的工作无关。
为了更优化效率,Windows提供了线程池的概念。
线程池使创建,管理与撤销线程变得更容易。
我觉得,线程池可以:
*初始化线程,动态得创建线程。
*预分配线程池的内存空间
*优先级的排队
*管理线程,撤销线程。
Jeffer Richter在"CLR线程池"文章中讲到CLR中线程的特性:
当 CLR 初始化时,其线程池中不含有线程。当应用程序要创建线程来执行任务时,该应用程序应请求线程池线程来执行任务。线程池知道后将创建一个初始线程。该新线程 经历的初始化和其他线程一样;但是任务完成后,该线程不会自行销毁。相反,它会以挂起状态返回线程池。如果应用程序再次向线程池发出请求,那么这个挂起的 线程将激活并执行任务,而不会创建新线程。这节约了很多开销。只要线程池中应用程序任务的排队速度低于一个线程处理每项任务的速度,那么就可以反复重用同一线程,从而在应用程序生存期内节约大量开销。
那么,如果线程池中应用程序任务排队的速度超过一个线程处理任务的速度,则线程池将创建额外的线程。当然,创建新线程确实会产生额外开销,但应用程序在其 生存期中很可能只请求几个线程来处理交给它的所有任务。因此,总体来说,通过使用线程池可以提高应用程序的性能。
现在您可能想知道,如果线程池包含许多线程而应用程序的工作负荷又在减少,将会发生什么事情。这种情况下,线程池包含几个长期挂起的线程,浪费着操作系统 的资源。Microsoft 也考虑到了这个问题。当线程池线程自身挂起时,它等待 40 秒钟。如果 40 秒过去后线程无事可做,则该线程将激活并自行销毁,释放出它使用的全部操作系统资源(堆栈、内核对象,等等)。同时,激活并自行销毁线程可能并不影响应用 程序的性能,因为应用程序做的事情毕竟不是太多,否则就会恢复执行该线程。顺便说一句,尽管我说线程池中的线程是在 40 秒内自行激活的,但实际上这个时间并没有验证并可以改变。
线程池的一个绝妙特性是:它是启发式的。如果您的应用程序需要执行很多任务,那么线程池将创建更多的线程。如果您的应用程序的工作负载逐渐减少,那么线程池线程将自行终止。线程池的算法确保它仅包含置于其上的工作负荷所需要的线程数!
线程池可以提供的功能:
1.异步调用功能:一般我们调用函数都是同步的,即函数返回后,才执行下一句代码。但是,用线程池可以异步的调用我们的函数,调用后,马上执行下一句,至于线程的什么时候返回,是主线程所不知道的。
另外,请注意,永远不要调用任何可以自己创建线程的方法; 如果需要,CLR 的线程池将自动创建线程,如果可能还将重用现有的线程。另外,线程处理回调方法后不会立即销毁该线程;它将返回到线程池并准备处理队列中的其他工作项。使 用System.Theading.TheadPool中的QueueUserWorkItem 会使您的应用程序更有效,因为您将不需要为每个客户端请求创建和销毁线程。
例:下面写了一个线程池来实现异步调用的方法:
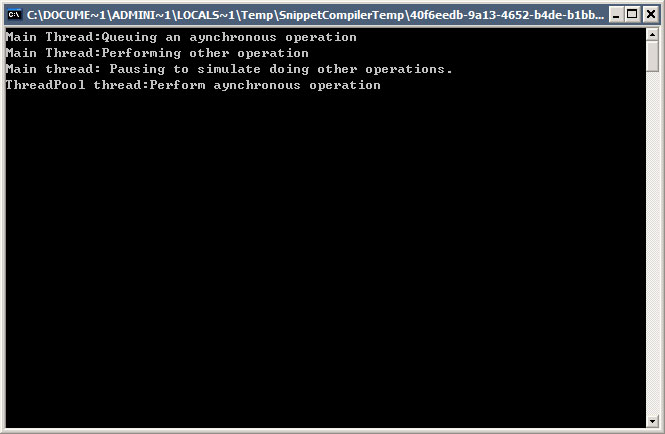
using System;using System.Collections;using System.Threading;public class MyClass{ public static void Main() { Console.WriteLine("Main Thread:Queuing an aynchronous operation"); ThreadPool.QueueUserWorkItem(new System.Threading.WaitCallback(MyAsyncOperation)); Console.WriteLine("Main Thread:Performing other operation"); Console.WriteLine("Main thread: Pausing to simulate doing other operations."); Console.ReadLine(); } static void MyAsyncOperation(object state) { Console.WriteLine("ThreadPool thread:Perform aynchronous operation"); Thread.Sleep(5000); }} 知道它的结果是什么吗?如果是传统的调用MyAsyncOperation函数,可以肯定得出结论,是输出:
Main Thread:Queuing an aynchronous operation
ThreadPool thread:Perform aynchronous operat
Main Thread:Performing other operation
Main thread: Pausing to simulate doing other operations
但是,用了线程池,创建一个线程来执行这个函数,结果却大不一样。以下是执行结果的截图:
2.以一定的时间间隔调用方法:
如果应用程序需要在某个时间执行某项任务,或者定时执行某个任务。那么,就使用线程池吧。
System.Threading.Timer类可以为你构造这样的功能。函数原型如下:
public Timer(TimerCallback callback, Object state, Int32 dueTime, Int32 period);用户定义的线程函数可以这样定义:
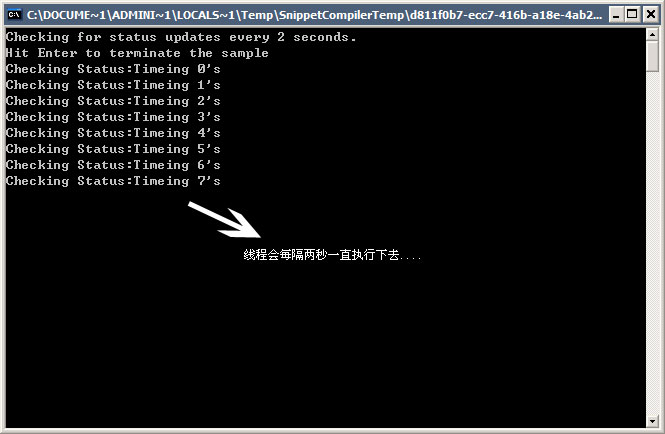
public delegate void TimerCallback(Object state); 我们写一下让线程池线程立即调用一个方法,并且每隔 2000 毫秒(或两秒)再次调用的应用程序。
以下是程序:
using System;using System.Collections;using System.Threading;public class MyClass{ static int Times=0; public static void Main() { Console.WriteLine("Checking for status updates every 2 seconds."); Console.WriteLine("Hit Enter to terminate the sample"); Timer timer = new Timer(new TimerCallback(CheckStatus),"Timeing",0,2000); Console.ReadLine(); } static void CheckStatus(object state) { Console.WriteLine("Checking Status:"+Convert.ToString(state)+" "+(Times++).ToString()+"'s"); }} 以下是输出的截图:
3.当单个内核对象得到信号通知时调用方法
Jeffer Richter文章中说到:
Microsoft 研究人员在做性能研究时发现,许多应用程序生成线程,只是为了等待某单个内核对象得到信号通知。一旦该对象得到信号通知,这个线程就将某种通知发送给另一 个线程,然后环回,等待该对象再次发出信号。有些开发人员编写的代码中甚至有几个线程,而每个线程都在等待一个对象。这是系统资源的巨大浪费。因此,如果 当前您的应用程序中有多个线程在等待单个内核对象得到信号通知,那么线程池仍将是您提高应用程序性能的最佳资源。
至于它应该怎么使用呢?
要让线程池线程在内核对象得到信号通知时调用您的回调方法,您可以再次利用 System.Threading.ThreadPool 类中定义的一些静态方法。要让线程池线程在内核对象得到信号通知时调用方法,您的代码必须调用一个重载的 RegisterWaitHandle 方法
它的原型如下:
public static RegisterWaitHandle RegisterWaitForSingleObject( WaitHandle h, WaitOrTimerCallback callback, Object state, UInt32 milliseconds, Boolean executeOnlyOnce);public static RegisterWaitHandle RegisterWaitForSingleObject( WaitHandle h, WaitOrTimerCallback callback, Object state, Int32 milliseconds, Boolean executeOnlyOnce);public static RegisterWaitHandle RegisterWaitForSingleObject( WaitHandle h, WaitOrTimerCallback callback, Object state, TimeSpan milliseconds, Boolean executeOnlyOnce);public static RegisterWaitHandle RegisterWaitForSingleObject( WaitHandle h, WaitOrTimerCallback callback, Object state, Int64 milliseconds, Boolean executeOnlyOnce); 第一个参数h表示你要等待的内核对象,第二个参数callback表示调用的用户线程函数,第三参数state是传递给用户线程函数的参数,第四个参数 milliseconds表示线程池内核对象得到信号通知前应该等待的时间,通常传递-1(就跟前面提到的函数WaitForSingleObject第 二个参数作用相同),表示无限超时。第五个参数executeOnlyOnce 为真,那么线程池线程将仅执行回调方法一次。但是,如果 executeOnlyOnce 为假,那么线程池线程将在内核对象每次得到信号通知时执行回调方法。
客户端定义的函数原型:
public delegate void WaitOrTimerCallback(Object state,Boolean timedOut); 当调用回调方法时,会传递给它状态数据和 Boolean 值 timedOut。如果 timedOut 为假,则该方法知道它被调用的原因是内核对象得到信号通知。如果 timedOut 为真,则该方法知道它被调用的原因是内核对象在指定时间内没有得到信号通知。回调方法应该执行所有必需的操作。
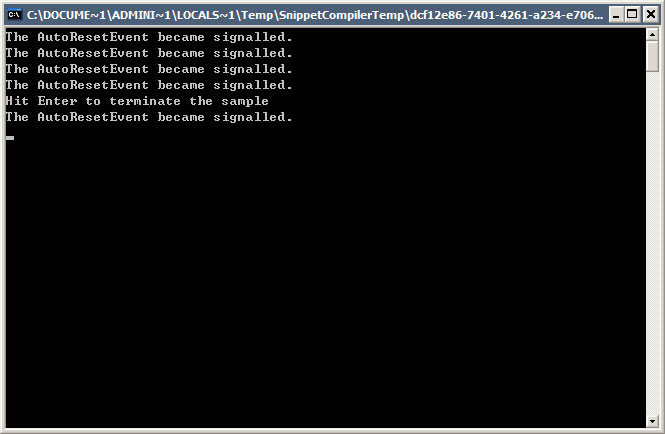
看具体的代码:
using System;using System.Collections;using System.Threading;public class MyClass{ public static void Main() { AutoResetEvent are = new AutoResetEvent(false); //自动事件对象 RegisteredWaitHandle rwh = ThreadPool.RegisterWaitForSingleObject( are, new WaitOrTimerCallback(EventSignalled), null, –1, false); for (Int32 x = 0 ; x < 5; x++) { Thread.Sleep(5000); are.Set(); } rwh.Unregister(null); Console.WriteLine("Hit Enter to terminate the sample"); Console.ReadLine(); } static void EventSignalled(object state,Boolean timedOut) { if (timedOut) Console.WriteLine("Timed-out while waiting for the AutoResetEvent."); else Console.WriteLine("The AutoResetEvent became signalled."); }}执行如图所示:
Jeff的原文:http://blog.chinaunix.net/article.php?articleId=43400&blogId=5958
Jurgen Appelo上个月发表了一篇博客“敏捷团队当如群鸟飞”,他写到,“在敏捷软件开发中不应该限定规则,只应当做基本的限制”。
他开篇提出:
在组织中,人们总是试图通过引入某些规则来解决问题,例如,“在X情况下,你必须要做Y”。
我认为这绝不是最好的方式。规则应该是留给团队自己决定,你只需要设定一些限制就行了。
紧接着,他举了一个在计算机上为鸟群行为建模的例子,模拟鸟群的行为非常简单,只需要三条基本限制:
Jurgen Appelo认为,鸟群的行为可以很容易映射到软件开发团队上来:
自然,这样几条简简单单的限制是无法保证能把事情做好的,但是给团队制定规则就能管用么?敏捷宣言中提到过:
鼓舞起每个人的积极性,以个人为中心构建项目,提供所需的环境、支持与信任。
最好的架构、需求和设计出自于自组织的团队。
团队会定期就如何更有效的工作进行回顾,继而调整行为。
那么,你有没有因为担心组织或者团队出现混乱,而从外部强加过多约束呢?
Jurgen Appelo接着说道:
在管理软件项目的时候,敏捷软件开发是一种很自然而然的方式。它设置了一些限制,如“跟客户协作”、“允许频繁的变化”、“只交付可以工作的成品”,剩下的规则就由团队自己选择。
……
这也表明,敏捷软件开发并不是天生就代表了结对编程、TDD、迭代……(注意,敏捷宣言根本没提到这些!)当然,这些实践很不错,但你要是想把它们当做固定规则来实施,你就……
当然,也就失去了敏捷的能力。
各位读者朋友,你对团队建设、团队管理持有何种态度呢?你有没有想办法组建自组织的团队?当团队能力和工作态度没有满足你的预期时,你采用了什么方式来提高生产效率,转变大家的心态?欢迎留下评论,与大家分享经验。
如果你有切实行之有效的实践经验,也欢迎为InfoQ中文站投稿,请mail至lijian[at]cn.infoq.com。







