Cocomo发布beta版
http://www.flashcomguru.com/index.cfm/2008/11/17/cocomo-public-beta
Flash Media Server 3.5正式版公布
http://www.flashcomguru.com/index.cfm/2008/11/17/fms3_5-announced
Adobe air 1.5发布
http://get.adobe.com/air/
Thermo取名为Catalyst
http://labs.adobe.com/technologies/flashcatalyst
Flash Catalyst 小组博客
http://thermoteamblog.com/
Adobe与ARM联手提升手机上网体验
http://www.cnbeta.com/article.php?sid=69982
Adobe将发布Windows Mobile版Flash Player
http://www.cnbeta.com/article.php?sid=69970
Adobe Flash视频是否能如愿出现在iPhone上?
http://www.cnbeta.com/article.php?sid=70030
ColdFusion 新的IDE
New ColdFusion IDE Announced ("Bolt")
http://www.adobe.com/go/boltprerelease
http://labs.adobe.com/wiki/index.php/Bolt
C++ To AVM : Alchemy
http://labs.adobe.com/technologies/alchemy/
Server Side ActionScript 3.0: Coming to a ColdFusion Server Near You
http://www.joeflash.ca/blog/2008/11/61.html

[SQL]Select查询原理
转载自:http://www.cnblogs.com/ASPNET2008/archive/2008/11/19/1336329.html
我并非专业DBA,但做为B/S架构的开发人员,总是离不开数据库,一般开发员只会应用SQL的四条经典语句:select ,insert,delete,update。但是我从来没有研究过它们的工作原理,这篇我想说一说select在数据库中的工作原理。B/S架构中最经 典的话题无非于三层架构,可以大概分为数据层,业务逻辑层和表示层,而数据层的作用一般都是和数据库交互,例如查询记录。
我们经常是写好查询SQL,然后调用程序执行SQL。但是它内部的工作流程是怎样的呢?先做哪一步,然后做哪一步等,我想还有大部分朋友和我一样都不一定清楚。
第一步:应用程序把查询SQL语句发给服务器端执行。
我们在数据层执行SQL语句时,应用程序会连接到相应的数据库服务器,把SQL语句发送给服务器处理。
第二步:服务器解析请求的SQL语句。
1:SQL计划缓存,经常用查询分析器的朋友大概都知道这样一个事实,往往一个查询语句在第一次运行的时候需要执行特别长的时间,但是如果你马上或者在一定时间内运行同样的语句,会在很短的时间内返回查询结果。
原因:
1):服务器在接收到查询请求后,并不会马上去数据库查询,而是在数据库中的计划缓存中找是否有相对应的执行计划,如果存在,就直接调用已经编译好的执行计划,节省了执行计划的编译时间。
2):如果所查询的行已经存在于数据缓冲存储区中,就不用查询物理文件了,而是从缓存中取数据,这样从内存中取数据就会比从硬盘上读取数据快很多,提高了查询效率.数据缓冲存储区会在后面提到。
2:如果在SQL计划缓存中没有对应的执行计划,服务器首先会对用户请求的SQL语句进行语法效验,如果有语法错误,服务器会结束查询操作,并用返回相应的错误信息给调用它的应用程序。
注意:此时返回的错误信息中,只会包含基本的语法错误信息,例如select 写成selec等,错误信息中如果包含一列表中本没有的列,此时服务器是不会检查出来的,因为只是语法验证,语义是否正确放在下一步进行。
3:语法符合后,就开始验证它的语义是否正确,例如,表名,列名,存储过程等等数据库对象是否真正存在,如果发现有不存在的,就会报错给应用程序,同时结束查询。
4:接下来就是获得对象的解析锁,我们在查询一个表时,首先服务器会对这个对象加锁,这是为了保证数据的统一性,如果不加锁,此时有数据插入,但因为没有加锁的原因,查询已经将这条记录读入,而有的插入会因为事务的失败会回滚,就会形成脏读的现象。
5:接下来就是对数据库用户权限的验证,SQL 语句语法,语义都正确,此时并不一定能够得到查询结果,如果数据库用户没有相应的访问权限,服务器会报出权限不足的错误给应用程序,在稍大的项目中,往往 一个项目里面会包含好几个数据库连接串,这些数据库用户具有不同的权限,有的是只读权限,有的是只写权限,有的是可读可写,根据不同的操作选取不同的用户 来执行,稍微不注意,无论你的SQL语句写的多么完善,完美无缺都没用。
6:解析的最后一步,就是确定最终的执行计划。 当语法,语义,权限都验证后,服务器并不会马上给你返回结果,而是会针对你的SQL进行优化,选择不同的查询算法以最高效的形式返回给应用程序。例如在做 表联合查询时,服务器会根据开销成本来最终决定采用hash join,merge join ,还是loop join,采用哪一个索引会更高效等等,不过它的自动化优化是有限的,要想写出高效的查询SQL还是要优化自己的SQL查询语句。
当确定好执行计划后,就会把这个执行计划保存到SQL计划缓存中,下次在有相同的执行请求时,就直接从计划缓存中取,避免重新编译执行计划。
第三步:语句执行。
服务器对SQL语句解析完成后,服务器才会知道这条语句到底表态了什么意思,接下来才会真正的执行SQL语句。
些时分两种情况:
1):如果查询语句所包含的数据行已经读取到数据缓冲存储区的话,服务器会直接从数据缓冲存储区中读取数据返回给应用程序,避免了从物理文件中读取,提高查询速度。
2):如果数据行没有在数据缓冲存储区中,则会从物理文件中读取记录返回给应用程序,同时把数据行写入数据缓冲存储区中,供下次使用。
说明:SQL缓存分好几种,这里有兴趣的朋友可以去搜索一下,有时因为缓存的存在,使得我们很难马上看出优化的结果,因为第二次执行因为有缓存的存在,会特别快速,所以一般都是先消除缓存,然后比较优化前后的性能表现,这里有几个常用的方法:
DBCC DropCLEANBUFFERS
从缓冲池中删除所有清除缓冲区。
DBCC FREEPROCCACHE
从过程缓存中删除所有元素。
DBCC FREESYSTEMCACHE
从所有缓存中释放所有未使用的缓存条目。SQL Server 2005 数据库引擎会事先在后台清理未使用的缓存条目,以使内存可用于当前条目。但是,可以使用此命令从所有缓存中手动删除未使用的条目。
这只能基本消除SQL缓存的影响,目前好像没有完全消除缓存的方案,如果大家有,请指教。
结论:只有知道了服务执行应用程序提交的SQL的操作流程才能很好的调试我们的应用程序。
1:确保SQL语法正确;
2:确保SQL语义上的正确性,即对象是否存在;
3:数据库用户是否具有相应的访问权限。
注:
本文引用:
http://database.ctocio.com.cn/tips/210/7791210.shtml
http://tech.it168.com/a2008/0805/199/000000199573.shtml
[Flex]Java正在让位于Flex吗?
Java正在让位于Flex吗?
作者 Moxie Zhang译者 张龙 发布于 2008年11月15日 上午8时14分
随着富Internet应用(RIA)技术的不断成熟,开发者可选择的余地也越来越大了,这样他们就不可避免地会对已有的技术如Java造成冲击。最近,游戏开发公司Sharendipitous Moments发表了一篇名为“我们正转向Flash,这就是原因”的博文,讨论了Java是否正在让位于RIA技术,如Flex。
这篇博文首先说到Java技术依然很棒:
Java语言要远远优于ActionScript,Java编译器也更加先进。Java能做的事情更多。还有,尽管Flex Builder构建在Eclipse之上,而针对Java的Eclipse开发环境已经出来好几年了。但公正的说,我们只是将800个类和将近 60,000行的Java代码转化为了ActionScript。
Sharendipitous Moments之所以转到基于Flash的开发(Flex),主要原因在于Java的品牌。该博文说到:
Java的品牌太失败了。Sun很早就鼓吹JavaFX是用来拯救Java的,但它的发布时间太长了。同时,Flash继续占据着统治地位。Silverlight也是一个竞争者,但它还需要很长一段时间才能达到Flash那样的市场占有率。
根据这篇博文所述,品牌失败导致的结果是:“如果你看到Java applet正在被加载,那么你就会在页面上随便点一个链接而转向其他页面。”
很多开发者并不认可Sharendipitous Moments的观点。正如一个开发者所说:
没人用Flex处理关键的事情。但是这篇博文的博主却不敢苟同。他们都在说Java有多么地差,Flash是多么地好。具备即时 编译JavaScript能力的浏览器即将面世。你认识到这一点了么?Flash的目标不是Java,而是完全基于浏览器的应用。同时,Java既可以应 用在服务器端,也可以应用在客户端。
然而另一些开发者与Sharendipitous Moments的立场是一样。例如,Artima Developer的高级编辑Frank Sommers说到:“我刚刚将一个规模庞大的Swing应用移植到了Flex上,整个过程让我非常满意。我真正缺少的东西就是一个好的IDE,如 IntelliJ。Flex Builder 3要想达到IntelliJ那样的高度还有很长一段路要走”。
来自Sun的Ken Russell也加入了这场争论:
我对Sharendipity(很有特点的JOGL应用之一)迁移到Flash感到很失望。我们刚在Java SE 6 Update 10中完成了对Java Plug-In的重写,这会使Java applet的部署更加可靠、强大且轻便。6u10现在可以用在Linux、Solaris及Windows上,同时Sun也正在积极地与Apple合作 以完成Mac版本。对于重新激起Java平台上的客户端开发来说,这是万里长征的第一步。
软件开发咨询师Martin Wildam的态度比较中立:
我觉得你的想法站不住脚。从一般用户的角度来看,我觉得你说的很对,因为他们很可能在看到Java starting之前就已经转到别的页面去了。但我记得Flash的加载时间更长。用户是不会认识到这一点的,因为出现在他们面前的只是不同的动画而已。 如果总是看到相同的Flex-loading图标,他们很可能也不会再等了。
Java World说到:
与此同时,Java Lobby上的一篇文章对于Java开发者转到Adobe RIA平台很有帮助。但这对于可怜的JavaFX来说还不是世界末日,Artima Developer的Frank Sommers认为还在发展初期的RIA语言从Swing中借鉴了大量的东西。
该博文的作者Dale Beermann对以上讨论进行了总结,他说到:“我喜欢这种对话。这种讨论是没有限制的,我渴望不同的声音。来吧,朋友”。
[MVC]让ASP.NET MVC页面返回不同类型的内容
在ASP.NET MVC的controller中大部分方法返回的都是ActionResult,更确切的是ViewResult。它返回了一个View,一般情况下是一 个HTML页面。但是在某些情况下我们可能并不需要返回一个View,我们可能需要的是一个字符串,一个json或xml格式的文本,一个图片。
ActionResult是一个抽象类,我们平时比较常用的ViewResult是它的派生类,所以我们也可以写一个StringResult、 XmlResult、ImageResult来实现上面提到的需求。由于返回字符串可以有更简单的方法,直接将需要返回字符串的方法的返回值设置成 string型就可以了,JsonResult在ASP.NET MVC中已经有提供。所以下面只演示XmlResult和ImageResult。
ASP.NET MVC项目是开源的(可以在http://www.codeplex.com/aspnet下载源代码),所以我们可以参考其中ViewResult和JsonResult的代码进行改写。主要的思路是设置返回数据流HTTP Header中的Content-Type,然后将要返回的内容写入Response中。
先演示XmlResult
XmlResult的代码:
1 public class XmlResult:ActionResult
2 {
3 // 可被序列化的内容
4 object Data { get; set; }
5
6 // Data的类型
7 Type DataType { get; set; }
8
9 // 构造器
10 public XmlResult(object data,Type type)
11 {
12 Data = data;
13 DataType = type;
14 }
15
16 // 主要是重写这个方法
17 public override void ExecuteResult(ControllerContext context)
18 {
19 if (context == null)
20 {
21 throw new ArgumentNullException("context");
22 }
23
24 HttpResponseBase response = context.HttpContext.Response;
25
26 // 设置 HTTP Header 的 ContentType
27 response.ContentType = "text/xml";
28
29 if (Data != null)
30 {
31 // 序列化 Data 并写入 Response
32 XmlSerializer serializer = new XmlSerializer(DataType);
33 MemoryStream ms = new MemoryStream();
34 serializer.Serialize(ms,Data);
35 response.Write(System.Text.Encoding.UTF8.GetString(ms.ToArray()));
36 }
37 }
38 }
2 {
3 // 可被序列化的内容
4 object Data { get; set; }
5
6 // Data的类型
7 Type DataType { get; set; }
8
9 // 构造器
10 public XmlResult(object data,Type type)
11 {
12 Data = data;
13 DataType = type;
14 }
15
16 // 主要是重写这个方法
17 public override void ExecuteResult(ControllerContext context)
18 {
19 if (context == null)
20 {
21 throw new ArgumentNullException("context");
22 }
23
24 HttpResponseBase response = context.HttpContext.Response;
25
26 // 设置 HTTP Header 的 ContentType
27 response.ContentType = "text/xml";
28
29 if (Data != null)
30 {
31 // 序列化 Data 并写入 Response
32 XmlSerializer serializer = new XmlSerializer(DataType);
33 MemoryStream ms = new MemoryStream();
34 serializer.Serialize(ms,Data);
35 response.Write(System.Text.Encoding.UTF8.GetString(ms.ToArray()));
36 }
37 }
38 }
在controller中调用它
1 public ActionResult Xml()
2 {
3 // 创建一个DemoModal对象,No属性为1,Title属性为Test
4 DemoModal dm = new DemoModal() { No = 1, Title = "Test" };
5
6 // 序列化为XML格式显示
7 XmlResult xResult = new XmlResult(dm, dm.GetType());
8 return xResult;
9 }
2 {
3 // 创建一个DemoModal对象,No属性为1,Title属性为Test
4 DemoModal dm = new DemoModal() { No = 1, Title = "Test" };
5
6 // 序列化为XML格式显示
7 XmlResult xResult = new XmlResult(dm, dm.GetType());
8 return xResult;
9 }
显示出来的结果

下面演示的是ImageResult
ImageResult的代码
1 public class ImageResult:ActionResult
2 {
3 // 图片
4 public Image imageData;
5
6 // 构造器
7 public ImageResult(Image image)
8 {
9 imageData = image;
10 }
11
12 // 主要需要重写的方法
13 public override void ExecuteResult(ControllerContext context)
14 {
15 if (context == null)
16 {
17 throw new ArgumentNullException("context");
18 }
19
20 HttpResponseBase response = context.HttpContext.Response;
21
22 // 设置 HTTP Header
23 response.ContentType = "image/jpeg";
24
25 // 将图片数据写入Response
26 imageData.Save(context.HttpContext.Response.OutputStream, ImageFormat.Jpeg);
27 }
28 }
2 {
3 // 图片
4 public Image imageData;
5
6 // 构造器
7 public ImageResult(Image image)
8 {
9 imageData = image;
10 }
11
12 // 主要需要重写的方法
13 public override void ExecuteResult(ControllerContext context)
14 {
15 if (context == null)
16 {
17 throw new ArgumentNullException("context");
18 }
19
20 HttpResponseBase response = context.HttpContext.Response;
21
22 // 设置 HTTP Header
23 response.ContentType = "image/jpeg";
24
25 // 将图片数据写入Response
26 imageData.Save(context.HttpContext.Response.OutputStream, ImageFormat.Jpeg);
27 }
28 }
在controller中调用
1 public ActionResult Img()
2 {
3 // 获取博客园空间顶部的banner图片
4 WebRequest req = WebRequest.Create("http://space.cnblogs.com/images/a4/banner.jpg");
5 WebResponse res = req.GetResponse();
6 Stream resStream = res.GetResponseStream();
7 Image img = Image.FromStream(resStream);
8
9 // 输出给客户端
10 ImageResult r = new ImageResult(img);
11 return r;
12 }
2 {
3 // 获取博客园空间顶部的banner图片
4 WebRequest req = WebRequest.Create("http://space.cnblogs.com/images/a4/banner.jpg");
5 WebResponse res = req.GetResponse();
6 Stream resStream = res.GetResponseStream();
7 Image img = Image.FromStream(resStream);
8
9 // 输出给客户端
10 ImageResult r = new ImageResult(img);
11 return r;
12 }
结果图
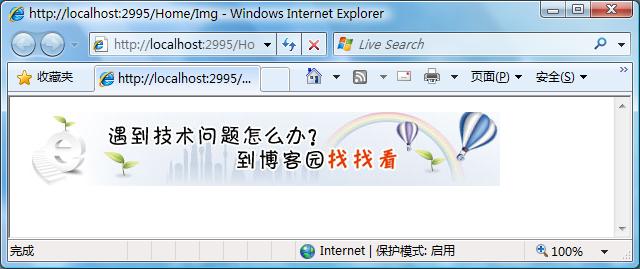
这个比较多用在向客户端传送验证码图片时。
转载:http://www.cnblogs.com/Snowdreams/archive/2008/11/15/let-aspnet-mvc-view-return-different-type-content.html
[Flash]Flash与3D编程探秘(八)- 3D物体着色基础知识
http://www.cnblogs.com/yangzhou1030/archive/2008/11/14/1333608.html
[C#]BlogEngine.Net架构与源代码分析系列part15:总结篇
本文是这个系列的总结篇,在这篇文章里,仅从我个人的角度发表一下对BlogEngine.Net的一些看法。内容包括BlogEngine.Net的优缺点,性能问题,如何阅读源代码等。
重申一下写这个系列的目的
1.使自己更加深入的理解BlogEngine.Net的架构,对BlogEngine.Net的代码能够更深刻的掌握。
2.给那些想学习BlogEngine.Net的源代码,但是不知道从何开始或者比较迷茫的朋友们一个学习指南。
3.在博客园上永远的保存下来,方便你我查看。因为这方面的资料实在太少了。
关于如何阅读源代码
其实BlogEngine.Net的注释已经很清晰了,但是由于它确实很大,很强 壮,我在学习它的源代码时还是走了不少弯路,曾经放弃过很多次,不过最后还是找到了感觉。BlogEngine.Net的最大特点就是麻雀虽小,五脏俱 全,从使用上看不到太多,但是它里面的东西真是很经典,设计和实现得很漂亮。我个人觉得我们在研究它时只要坚持以下几点就行了:
1.按照文章的顺序一块一块的研究:这个系列的写作顺序就是我觉得最佳的学习路线。
2.坚持住整体把握,细致入微的原则。也就是对它的源代码该宏观考虑的时候就要宏观考虑,该细细推敲的时候就要细细推敲。看代码时首先看看这段代码大概是做什么的,之后再去一行一行的看。对于弄不明白的地方,可以先放在一旁,以后你自然会知道的。
3.对于不确定的部分要一边调试一边看,就是F10,F11这样看。
关于BlogEngine.Net的性能问题的一点看法
BlogEngine.Net最初是一个单人博客,目前支持多人写博客,但是和 cnblogs这种社区博客还是有大区别的。其实我觉得BlogEngine.Net的市场定位也就是使用托管服务的单人博客系统。从它的实现代码中我们 可以看出对于Post等的处理方式是从持久存储设备完全填充到内存中的对象,评论中有的朋友提出这样处理的内存膨胀问题。其实我的看法是这样的,像 BlogEngine.Net这种市场定位的Blog系统中的Post再多也多不到哪去,Post中等存储的都是纯文本,对于图片,文件等大资源还是存储 在磁盘上的,这样的需求完全可以满足。再者BlogEngine.Net支持导出备份,我们完全可以在一定情况下将一些Post文本部分导出成 BlgoXML格式存储起来,之后删除一些Post,但是那些图片等依然保存不动,这样HttpHandler处理时依然有效。那么 BlogEngine.Net这样处理业务对象带来了什么好处呢?我觉得主要有以下两点:
1.控制上的灵活,数据的控制完全交给了业务对象,数据库等只是一个持久存储功能。
2.性能上的提升,BlogEngine.Net的那种搜索方式只能使用这样的业务对象数据处理方式才可以满足。
所以BlogEngine.Net在大用户量下的优势我觉得就会很明显,这也是这样的博客系统所需求的。我觉得像BlogEngine.Net这样的系统架构适合于应用在数据是动态的,数据量不是很大,但是用户量很多的系统设计中。
BlogEngine.Net的特性和优缺点
关于BlogEngine.Net的特性,大家可以参照一下官方的说明,表格上说明的很全,大家在阅读源代码时可以参照它,如果您弄清楚了所有这些特性的源代码,你实际上也就掌握了它。对于BlogEngine.Net的优缺点总结也都是我自己的个人看法,仅供参考,也欢迎大家讨论。
值得参考:
1.支持很多现有的XML标准格式,例如BlogXML,Apml,Rss等。
2.架构设计得很好,利用了很多面向对象设计的特性。很多地方使用了继承。
3.最大限度的利用了.Net Framework已有资源,例如Provider等。
4.很好的利用了C#的语言特性,例如泛型,特性等。
5.正则表达式,缓存等大量应用。
6.开发扩展的设计部分。Extension,Widget等扩展模型。
7.自定义的HttpHandler和HttpModule应用得很合适。
8.部分代码实现应用到了几个典型的设计模式带来了更好的解决办法。
9.Ajax的使用也很合适,达到了一定的页面效果。
10.代码分隔的很好,结构很清晰。
……
不推荐部分:
1.ExtensionManager部分还有待完善(前面有一篇文章提及过)。
2.Ajax在线预览有些地方不够完美(上文也提及过)。
行了,给BlogEngine.Net点面子,就先说这两点吧,实际上也想不出来了,因为我觉得它真是太完美了,也可能是我见识短吧。BlogEngine.Net的团队很优秀。
结束语
第一次写系列的文章,以前单篇文章也很少发布,现在知道写文章很不容易啊!最主要的是我的这个系列文章能给大家带来收获,哪怕一点点,我就会很高兴。
博客园是一块圣地,我把我两周以来收获的果实种在这块圣地上,希望能给匆匆茫茫的过客带来一点收获。
最后一句话:BlogEngine.Net真的是一件好东西!
本系列完!祝大家学习愉快,工作顺利!
上一篇:BlogEngine.Net架构与源代码分析系列part14:实现分析(下)——网站页面上值得参考的部分
[C#]BlogEngine.Net架构与源代码分析系列part14:实现分析(下)——网站页面上值
BlogEngine.Net 的成功不仅在于它的架构设计,它的代码实现细节也都是很经典的,每个结构分割的很清晰很自然,希望大家多多品位一下。在这篇文章里我将给大家介绍一下 BlogEngine.Net的Web实现上的几个亮点,包括Web.config,Ajax的运用等。
Web.config中的几个结点说明
让我们看一下appSettings结点中的各个选项的含义,以便您对整个BlogEngine.Net的认识更加清晰。
BlogEngine.FileExtension:在这里我们可以自定义Url请求的后缀名称,默认是.aspx。您可以定义自己喜欢的扩展名,例如.extguo,那么对于文章等生成的Url就成了类似http://HostName/CategoryName/PostTitle.extguo的形式。这个结点的使用在很多地方都可以见到,例如:







 }
} }
}BlogSettings.Instance.FileExtension就是读取这个结点获得的扩展名。
BlogEngine.VirtualPath:主要是为一些文章等的链接而服务的。我们可以使用虚拟目录安装我们的BlogEngine.Net,那么我们只要设置一下这里就可以得到和直接在根目录下一样的效果。我们需要注意一下Utils关于Url处理的部分,其中:
就是获得相对Web目录。
BlogEngine.MobileDevices:它的值是一个正则表达式,主要是对移动设备做出判断,并给移动设备使用设置的主题。它在这里被使用:
之后在BlogSetting的Theme中返回。
BlogEngine.AdminRole:管理员角色名,可以动态配置管理员角 色,也就是说系统对是否是管理员的判断中的管理员名称实际上是从这儿获得的。比如有一天我们想把某个角色改为管理员,那么就直接修改这儿就行了,不过这儿 需要的数据肯定也是角色管理中的一个角色名称。
StorageLocation:数据的存储位置,主要是给数据存储是XML格式时使用。在DataStore.cs文件中StorageLocation方法会涉及到。
BlogEngine.HardMinify: 对于JavaScript脚本指定强行压缩(去除一些不必要的字符)的文件名称。我们知道BlogEngine.Net中对于JavaScript请求都 是通过JavaScriptHandler进行的,JavaScriptHandler有一个HardMinify来判断是否已经指定强行压缩。 JavaScriptHandler中会涉及到这部分的引用。注意对WebResource.axd的请求在BlogBasePage中替换成对于 js.axd的请求,之后JavaScriptHandler的处理是使用RetrieveRemoteScript来输出脚本的。
Ajax的运用
BlogEngine.Net的很多部分使用原生的Ajax完成。例如 评论的打分,widget的管理等部分。我们在讲述BlogBasePage时提到的AddLocalizationKeys实际上就是初始化页面脚本的 一些变量,之后使用AddJavaScriptInclude(Utils.RelativeWebRoot + "blog.js")引入blog.js,如果是管理员(Widget可被管理)又使用 AddJavaScriptInclude(Utils.RelativeWebRoot + "admin/widget.js")引入widget.js,使用 AddStylesheetInclude(Utils.RelativeWebRoot + "admin/widget.css")引入widget样式,注意先后顺序,因为widget.js需要使用核心的blog.js。blog.js中这段代码就是Ajax调用的核心:
在线评论预览与评论的提交
结合blog.js与User controls\CommentView.ascx,我们看一下它的处理过程。CommentView可以显示文章的评论列表和提交新评论。当点击 Preview时,会调用blog.js中的ToggleCommentMenu:
请注意isPreview的引入与它的逻辑,这个Preview实际上也是需要回调到服务器端的程序的,之后生成预览的Render,当 点击Save时isPreview为false,这时回调服务器端的代码时才真正的保存,然后浏览器回调客户端的AppendComment完成一些初始 化工作。CommentView是一个UserControl并实现了 ICallbackEventHandler接口,这个接口有两个方法GetCallbackResult和RaiseCallbackEvent,在 RaiseCallbackEvent中我们可以看出,提交的评论参数使用"-|-"作为分隔符,经过一系列处理最后将这个新评论的呈现给了 _Callback,_Callback由GetCallbackResult返回。浏览端使用 WebForm_DoCallback('ctl00$cphBody$CommentView1',argument, callback,'comment',null,false);在这部分里我们只要实现ICallbackEventHandler接口就行了,实现的 细节都已经有.Net提供了,感兴趣细节的朋友可以查一查ASP.NET的回调方面的资料。
Widget排序的实现
当我们用鼠标拖住一个Widget移动到某个位置再放开鼠标时,发现这个Widget在WidgetZone中的排序被永久存储了,甚至 在你清空cookie时依然生效,BlogEngine.Net是在服务器端进行的存储,DataStore的be_WIDGET_ZONE中的 Widget的顺序就是在页面上Widget的显示顺序。这实际上是通过间接调用WidgetEditor.aspx中的MoveWidgets方法实现 的(前文提及过)。那么在浏览器端是如何处理这些排序问题的呢?
在widget.js中的大部分代码都是用来处理拖放排序的,initdragableElements主要完成使某个Widget可以 被拖动的初始化工作,widget.js的最后一句代码addLoadEvent(initdragableElements)使其在页面加载时执行。注 意initdragableElements中:
当鼠标onmouseup时执行stop_dragDropElement,在stop_dragDropElement中通过调用 saveData,saveData使用上文提到的CreateCallback完成服务器端的回调,其中saveString就是已排序的字符串,主要 用于发送给服务器端程序处理。
总结
实际上在BlogEngine.Net的Web站点中还有很多比较有用的东西值得我们去研究,例如FilterByApml的实现,对文 章的评分,邮件的发送等,这里就不做更多的讨论。关于在线评论预览我个人觉得没有必要去回调服务器,完全可以由客户端搞定,不知道大家是怎么想的。那个 Widget的排序一直都深深的吸引着我,这种处理我见得很少,所以拿出来分享。
在本系列的最后一篇文章中我会就BlogEngine.Net的优秀部分和不太推荐的部分做一个总结,并谈一下我对它的感受,希望大家继续关注。
坚持写完,坚持看完。
上一篇:BlogEngine.Net架构与源代码分析系列part13:实现分析(上)——HttpHandlers与HttpModules
[Flash]Flash加密和破解大法
FLASH的破解与加密大法
转载:http://hi.baidu.com/lisa910502/blog/item/7719e306827fc97e03088166.html
一、破解篇
一、破解篇
这里所谈的破解,包括提取swf、破解已加密及未加密的swf,即通常所说的“swf
获取swf的工具:
使用Temporary
偶尔会有网友问笔者关于网上
Temporary
使用
有时,部分资源会被隐藏。查看
可以将
Internet
从Word中提取Flash
测试环境:WindowsXP
1.
2.
3.
4.
5.
常用破解工具
谈到破解,很多朋友都会想到时下流行的闪客精灵。以下为常用的破解工具,按笔者使用的频繁程度,分别有:
*
*
*
(这是笔者最早认识的用来还原swf的工具,可惜一直在关注也没有发现2.0以上的破解版,只有1.6.9.8的破解版,这已经是3年前的版本了,只对Flash6.0以下有效。)
*
以上四款,以Decompiler最为常用。ASV虽然强大,但在实用性方面却不如Decompiler,这应当也是为什么数年来
1.
2.
破解附言
破解swf,依赖的主要是现成工具,多款工具综合使用,一款不行试另一款,如果作者有意加密,视破解者自身水平,在获取
———————————————————————–
二、加密篇
加密方法流传不少,此处只谈笔者所知的较为实用的方法:
更改后缀,避开
此方法可有效避开
限制
url
/*
以下判断网址的前
*/
if(_url.substring(0,
gotoAndStop(2);
/*
这里可以做一些东西,例如:将发布设置中的“本地回放安全性”设为“只访问网络”,然后在这里做无数的弹窗
onEnterFrame
getURL("http://www.zhugao.cn",
}
*/
}else{
gotoAndPlay(3);
}
为了便于阅读,以下是没有注释的代码:
url
if(_url.substring(0,
gotoAndStop(2);
}else{
gotoAndPlay(3);
}
如果要允许多个域名,可以这样写:
url
url2
if((_url.substring(0,
gotoAndPlay(3);
}else{
gotoAndStop(2);
}
注意:用此方法,设计过程中导出时的技巧:
用IE打开先打开指定目标网址,以避免在导出时频繁弹出窗口,如果无效,请将默认浏览器设置成IE,关闭导出时的player窗口即可继续编辑。有时Flash软件会因此发生错误而被强行结束,导出前请保存文档,切记!
常用加密工具
*
*
可轻易防止闪客精灵目前的版本对其所加密作品的AS查看,加密后的文件几乎保持原文件大小。遗憾的是不能防止
适当应用与JavaScript结合
加密JS,从而实现间接加密swf。相关工具及例子:
*
用于javascript的混淆加密。
*
加密网页脚本,包括
*
*
在Word中插入Flash
测试环境:WindowsXP
可用在独立文件给客户看的时候,尽管可以用前述方法从word中提取swf,然而此方法仍然具有一定防范效果。
1.
2.
3.
4.
5.
打包成加壳exe
用Flash的默认程序打包的exe很容易转成swf,SWFKit是一款很不错的加壳打包软件,不易被还原。
三、后记
破解时需要多种方法或工具综合使用,加密亦然,需根据用途综合加密。对于网络用swf的推荐加密方案:更改后缀,限制在指定域名播放,分解成多个swf并用SWF
| 几款常用的FLASH | |
| |
|
|
Imperator–最好的FLASH破解工具
FLASH破解利器 Flash Decompiler v2.9.0.349
|
[搜索引擎]Apache Solr : 基于Lucene的可扩展集群搜索服务器
Apache Solr : 基于Lucene的可扩展集群搜索服务器
作者 Ryan Slobojan译者 崔康 发布于 2008年11月13日 上午7时27分
Apache Solr项目,是一款基于Apache Lucene的开源企业搜索服务器,最近发布了1.3版。InfoQ采访了Solr的创建者Yonik Seeley,了解了新版本的更多信息和Solr提供给最终用户的功能。
Seeley首先描述了目标用户:“需要搜索框、分面浏览(导航)或者两者结合的任何人”,Solr的关键特性包括:
- 基于标准的开放接口——Solr搜索服务器支持通过XML、JSON和HTTP查询和获取结果。
- 易管理——Solr可以通过HTML页面管理,服务器统计数据以JMX输出,Solr配置通过XML完成。
- 分面浏览——搜索结果自动分类。
- 突出显示命中词——匹配的字符自动在搜索结果中高亮显示。
- 可伸缩性——快速增量更新和快照分发/复制到其他服务器。
- 灵活的插件体系——新功能能够以插件的形式方便的添加到Solr服务器上。
Seeley同时谈到了该版本中的主要新功能:
- 分布式搜索——索引现在可以透明的分割成多个部分,单个Solr服务器基于各个配置和模式支持多索引,无须停止Solr服务器就可以改动主要的配置。
- 扩展了查询功能——包含了一个新的Java客户端(SolrJ)和若干新功能,例如直接配置对于特定查询哪些文档首先命中、近似命中、搜索过期、记录分面时间和拼写检查
- 增强了数据导入工具——数据库和其他结构化数据源现在都可以导入、映射和转化。
- 更多可定制扩展点——存在一个新的更新处理器链,允许在查询时修改和重定向文档;一个搜索组件链修改和添加查询结果、用户查询分析器和插件式功能。
- 性能增强——显著提高了索引速度,二进制响应格式和快速查询删除功能。
详细的更新日志可以这里获得。
Seeley谈到了更多Solr在伸缩性、功能和实用性方面的细节:
Solr已经部署过数以百万计容量的文档,如果借助分布式搜索,Solr应该能够处理数十亿的文档集合。
Solr基于Lucene,具有优秀的全文相关性,可以很方便的提供词组接近性增强、近期文档增强、编辑增强和基于数字值的专有函数的定制评分机制。
AOL正在使用Solr增强它的频道功能:音乐、橄榄球运动、食谱、参考中心、房地产和汽车都使用这项技术。Solr的搜索功能也应用于Netflix、 Zappos、Gamespot、和Internet Archive。还有很多大客户我目前还不能透漏。
关于Solr的未来计划,Seeley提到了更多的可扩展性、对大集群更方便的配置和管理、基于区域和实时的搜索、重构以使用Spring配置插件。Seeley同时提供了一个邮件列表,在那里他详细讨论了Solr未来、特别是2.0版的计划。
查看英文原文:Apache Solr: Extensible, Clustered Search Server Built on Lucene
[C#]BlogEngine.Net架构与源代码分析系列part13:实现分析(上)——HttpHa
这已经是系列 的第13篇了,实际上到现在为止您应该对BlogEngine.Net的整体设计有了一定的把握,对部分实现细节有了比较深刻的认识,在阅读 BlogEngine.Net时希望坚持到最后,并把握住宏观,深入到微观。本文将详细介绍BlogEngine.Net中的HttpHandlers与 HttpModules,主要说明它们要实现的功能以及如何使用,并对几个必要的HttpHandler或HttpModule进行比较细致的分析。
HttpHandler和HttpModule
对于HttpHandler和HttpModule我这里不想多说了, 因为关于它们讲解的文章实在太多太多了,大家可以在博客园的找找看中直接输入“HttpHandler和HttpModule”就可以找到。我的理解就是 一个HttpHandler要实现IHttpHandler接口,主要是对某个请求进行直接处理,一个HttpModule要实现IHttpModule 接口,主要是在HttpApplication的生命周期的事件中对请求和响应进行过滤。它们都可以在Web.config文件中进行配置。
BlogEngine.Net中的HttpHandler
BlogEngine.Net中的HttpHandler都在BlogEngine.Core.Web.HttpHandlers空间下(除了MetaWeblogHandler,已经讲过,这里就不包含它了),通过Web.config我们可以看到它们的映射关系:
下面对它们进行一一描述:
FileHandler:主要完成对于一些物理文件的请求,例如在文章中插入的文件资源的请求就由它来处理。它的实现比较简单,就直接去磁盘的文件保存目录中读取,我们只要留意一下SetContentType就行了。
ImageHandler:与FileHandler类似,不过它处理的是图片。与FileHandler分开的原因主要就是图片需要在页面上展现(ContentType必须给浏览器讲清楚或采用默认)。
SyndicationHandler:它比较复杂,主要完成各种订阅需求的处理,需要结合 SyndicationFormat(格式枚举)和SyndicationGenerator(按照SyndicationFormat的格式生成 XML)一起使用。我们可以看一下它的实现过程,首先根据请求的查询字符串生成标题,格式,列表(GenerateItemList使用了Search 等),使用CleanList进行了一个过滤,分页处理,SetHeader,最后使用SyndicationGenerator的WriteFeed进 行了输出。这里考虑的情况比较多,但是BlogEngine.Net使用的分割方法很好的解决了复杂的订阅问题,值得研究一下。
SiteMap:网站地图,可以给一些搜索引擎提供更好的搜索信息,以XML格式将一些文章等页面的链接输出。
TrackbackHandler:接收Trackback信息的处理,前文已经讲过,这里不多说了。
PingbackHandler:接收Pingback信息的处理,前文已经讲过,这里也不多说了。
OpenSearchHandler:提供公开搜索处理,前文已经讲过,这里也不多说了。
RsdHandler:这个处理器很有用,它完成将BlogEngine.Net中的一些公开的接口等信息发布出去,类似WebService的WSDL文件。
CssHandler:主要处理了页面中的Css文件的压缩,上文中讲述BlogBasePage中提及过。处理器的实现很值得关注,压缩可以使用gzip或deflate两种格式,
并提供了一些事件供外界Hookup处理。压缩之前去掉空格等字符,分为从本地获得文件和从远程使用WebClient下载文件。并使用了缓存。
JavaScriptHandler:主要处理页面中引用的脚本的压缩,与Css处理方式类似。注意StripWhitespace的处理与Css的不同。
RatingHandler:主要完成给Post打分的功能,记得上文中有部分涉及到,从PostViewBase中的Rating可以看出,这个请求实际上是通过Ajax发送过来的。
OpmlHandler:获得OPML列表文件,类似收藏文章的列表。
BlogMLExportHandler:BlogEngine.Net中的文章导出处理,以前的文章讲过。
Sioc、Foaf、Apml的注释都是“Based on John Dyer's (http://johndyer.name/) extension.”,这个应该是对于某个标准XML的输出吧,主要提供了本博客系统中的一些公开的信息。关于它们不做太多的研究,我想这并不影响我们 对BlogEngine.Net的研究。
实际上这些HttpHandlers的请求链接很多都是在BlogBasePage加入到Html的Head中的,或者给浏览器使用,或者给搜索引擎使用。
BlogEngine.Net中的HttpModule
BlogEngine.Net中的HttpModule都在BlogEngine.Core.Web.HttpModules空间下,通过Web.config我们可以看到它们的映射关系:
请注意它们的注册顺序,因为WwwSubDomainModule和UrlRewrite都Hookup了HttpApplication的BeginRequest事件。下面对它们进行一一描述:
WwwSubDomainModule:Hookup了HttpApplication的BeginRequest事件,主要是对请求的URL中的"www"的处理以得到绝对的链接。
UrlRewrite:Hookup了HttpApplication的BeginRequest事 件,对一些URL的重写,实际上WwwSubDomainModule和UrlRewrite都是在处理URL,我们在看BlogEngine.Net中 的源代码时多留意一下它的URL,包括Post中的各种链接的URL等,注意区分它们都是做什么用的。
ReferrerModule:主要是对于请求的Referrer进行统计,纪录这些请求都是从哪里发送来的,提供了相应的事件供外部Hookup,注意IsSpam的实现和对于纪录日志使用了新线程来异步完成。
CompressionModule:一个Page页面的压缩处理模块,同样根据请求来判断是使用 gzip还是deflate,对于页面中链接的WebResource也是用WebResourceFilter进行了过滤处 理,WebResourceFilter实现了Stream,
在重写的Write中主要是将webresource.axd转交给了JavaScriptHandler处理以达到压缩的目的。注意它是在PreRequestHandlerExecute中Hookup的,都是给Response提供的流过滤器。
总结
由于篇幅所限,对于BlogEngine.Net中一些 HttpHandlers和HttpModules我并没有作更多的深入讨论,这里只是提供给大家一个学习指南,希望有所帮助。 BlogEngine.Net中大量使用了正则匹配,Url处理,压缩,缓存等都是比较通用的,值得我们关注与学习。
通用的处理方法值得我们去收藏
上一篇:BlogEngine.Net架构与源代码分析系列part12:页面共同的基类——BlogBasePage