
大家应该知道,微软的URLRewrite能够对URL进行重写,但是也只能对域名之后的部分进行重写,而不能对域名进行重写,如:可将 http://www.abc.com/1234/ 重写为 http://www.abc.com/show.aspx?id=1234 但不能将
http://1234.abc.com 重写为 http://www.abc.com/show.aspx?id=1234。
要实现这个功能,前提条件就是 www.abc.com 是泛解析的,再就是要修改一下URLRewriter了。
总共要修改2个文件
1.BaseModuleRewriter.cs
改为
就是将 app.Request.Path 替换成了 app.Request.Url.AbsoluteUri
2.ModuleRewriter.cs
改为
将
string lookFor = "^" + RewriterUtils.ResolveUrl(app.Context.Request.ApplicationPath, rules[i].LookFor) + "$";
改成了
string lookFor = "^" + rules[i].LookFor + "$";
完成这2处改动之后重新编译项目,将生成的dll复制到bin目录下。
再就是写web.config里的重写正则了
 <RewriterRule> <LookFor>http://(\d+)\.abc\.com</LookFor> <SendTo>/show.aspx?id=$1</SendTo> </RewriterRule>
<RewriterRule> <LookFor>http://(\d+)\.abc\.com</LookFor> <SendTo>/show.aspx?id=$1</SendTo> </RewriterRule>好了大功告成,你在IE地址栏输入http://1234.abc.com,就可以看到http://www.abc.com/show.aspx?id=1234
的结果了
完成这2处改动之后重新编译项目,将生成的dll复制到bin目录下。
修改完了这后,我们再把此 UrlRewriter.dll COPY 到我们项目的Bin目录下。这样就结了么?没有。
首先请确定你的项目之前有按我上篇文章中写到的那样做过UrlRewriter的配置,否则请先回过头来看看那篇文章。
如果你的项目已配置过,那么,我们还要为此做以下几件事情:
1。请确定你的域名是支持泛解析的。然后你的网站为默认网站,否则将不能实现(至少我现在还没有找到好办法)
2。在IIS配置:在IIS\ 你的站点\属性\主目录\配置\映谢 在通配符应用程序配置处插入一个新的映谢。把可执行文件设为和上面ASPX页面同样的配置即可(注意不要勾选 “确定文件是否存在”)。(用处就是使所有请求通过 ASP.NET 的ISAPI来处理,只有这样才能对所有地址进行重写嘛。)
3。查看下你的网站主机头,里面的第一个主机头值必须为空,否则会出现错误的请求。后面就随你加了,看你想绑定多少域名了。(这个办法是江大鱼想出来的。为这个错误我们都想了好多办法。在这里感谢江大鱼。。。)
4。最后改写你的 web.config 文件。
把上节中说到的
<httpHandlers>
<add verb="*" path="*.aspx" type="URLRewriter.RewriterFactoryHandler, URLRewriter" />
<add verb="*" path="*.html" type="URLRewriter.RewriterFactoryHandler, URLRewriter" />
</httpHandlers>
改为:
<httpModules>
<add type="URLRewriter.ModuleRewriter, URLRewriter" name="ModuleRewriter" />
</httpModules>
(就是改用HTTP 模块来执行重写,而不用HTTP 程序,否则无法重写地址前面。)
然后就来修改我们的重写正则了:
<RewriterRule>
<LookFor>http://(.[0-9]*)\.178b2b\.com/</LookFor>
<SendTo>~/Search/Search_Sell.aspx?id=$1</SendTo>
</RewriterRule>
好了,现在你输入 http://1.178b2b.com/ 就能搜索出相应分类了。但是聪明的你马上就发现。晕死,首页进不去了。呵呵。当然喽。你还得为首页加入重写正则。
<RewriterRule>
<LookFor>http://www\.178b2b\.com/</LookFor>
<SendTo>~/index.htm</SendTo>
</RewriterRule>
大功告成。感觉爽死了吧。呵呵。莫急,如果你二级域名指向的目录下面的页面都用的相对地址连接的图片和其它页面的话,呵呵,你有得忙了,你要全部改成如下方式:
<a href=http://www.178b2b.com/cxlm/league.html target="_blank">诚信联盟</a>
以上就是用UrlRewriter实现二级域名的方法了。
网 上很多朋友看到我这篇文章,按照我的方法做了,但是还是没有得到想要的效果,其实有些问题需要注意一下,我上篇文章也只是提出了解决这一问题的办法的最核 心的内容,有些朋友可能在实际运用中可能会碰到一些问题其实可以根据自己的经验作出相应处理应该可以解决,我在这里帮大家列出几点以帮助大家快速解决问 题。
1.域名解析问题
输入了域名http://1234.abc.com,浏览器提示找不到网页。首先,你应该确认你的域名是否支持泛域名解析,就是让所有的二级,三级域名都指向你的server。其次,要保证你的站点是服务器上的默认站点,就是80端口主机头为空的站点即可以直接用IP可以访问的http://1234.abc.com,要么要提示你的站点的错误信息,要么会正确的执行你定义的URLRewrite,要么显示你的站点的首页。
2.不能执行重写的问题
如果你确认你的域名解析是正确的,但是还是不能重写,访问http://1234.abc.com会提示路径"/"找不到…,
如果是这样的话,你先添加 ASPNET_ISAPI的通配符应用程序映射(这一步是必需的,Sorry!没有在上篇文章中提出来)。
操作方法:IIS站点属性 ->主目录 -> 配置
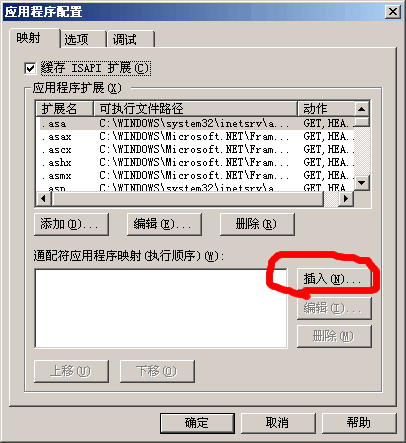
点击插入按键
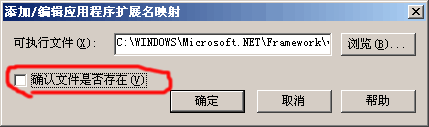
选择或输入C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\aspnet_isapi.dll
取消"确认文件是否存在"前的钩.
确定
在来访问http://1234.abc.com 应该是没有问题了。
3. 默认首页失效,因为把请球直接交给ASP.NET处理,IIS定义的默认首页将会失效,出现这种情形:
访问http://www.abc.com 不能访问首页,而通过http://1234.abc.com/default.aspx可以访问。
为解决这个问题,请自己在Web.Config中设置 lookfor / to /default.aspx 或 index.aspx ..的重写,完全可以解决问题。
OK,我列出了应该会普遍出现的问题的解决方法,如果你出现了我这里没有列出的问题而你自己又不能解决的,请在此回复提问或者给我发邮件或者加我QQ.







 }
} }
} 引用内容
引用内容