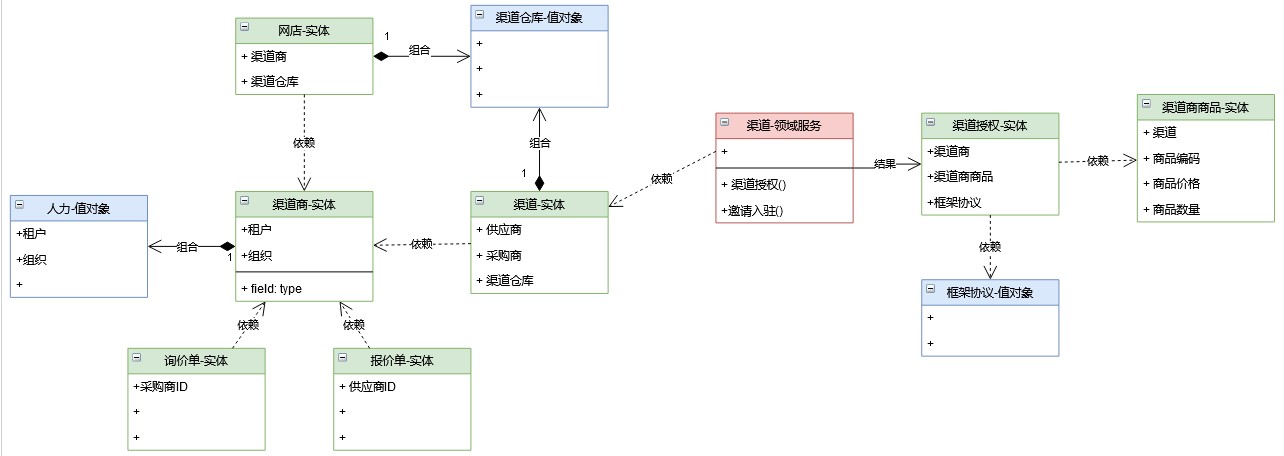
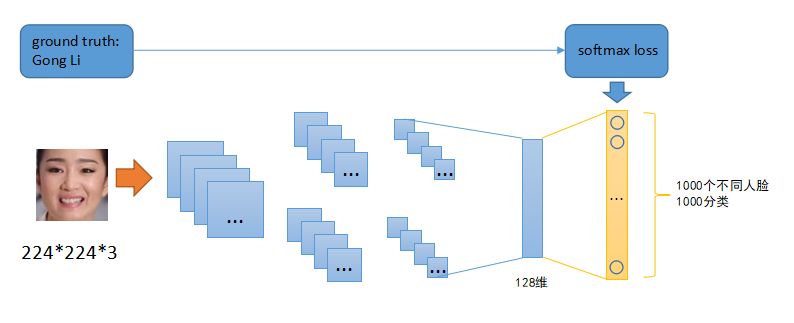
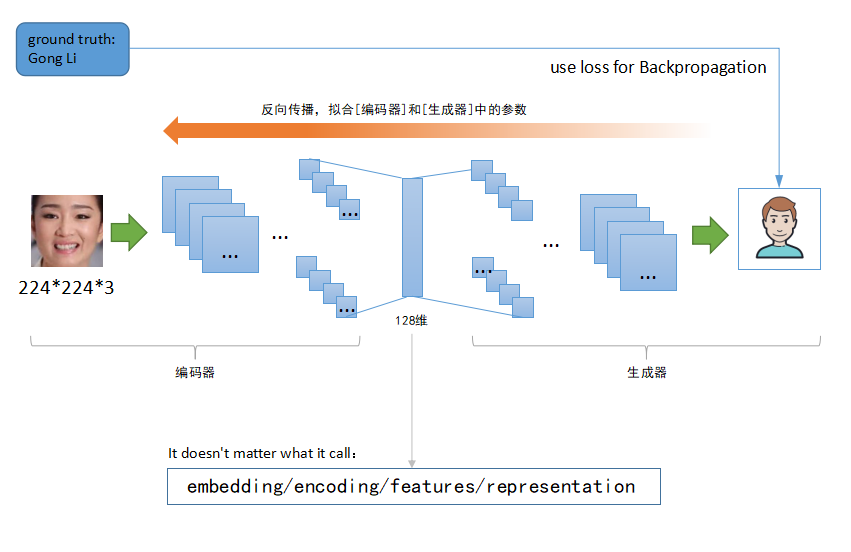
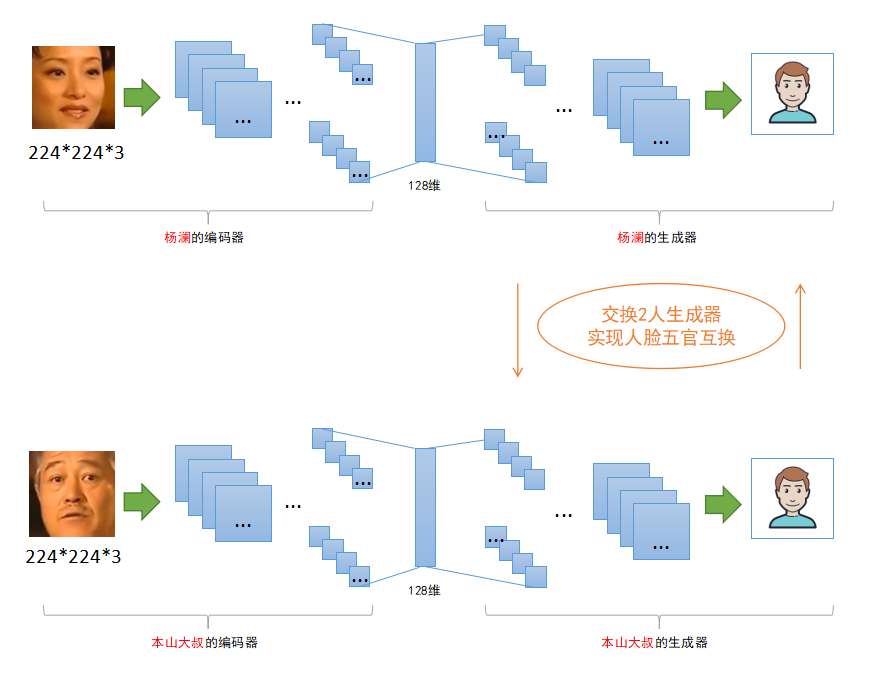
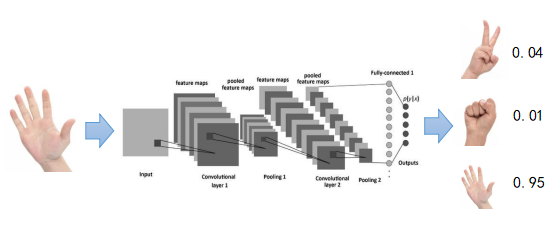
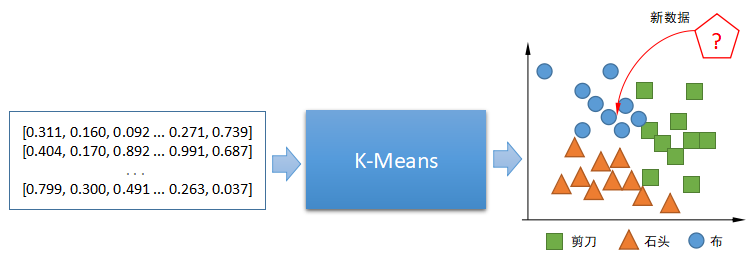
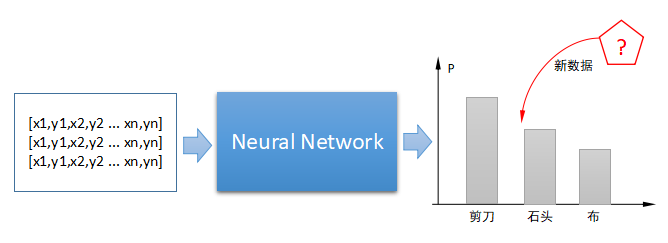
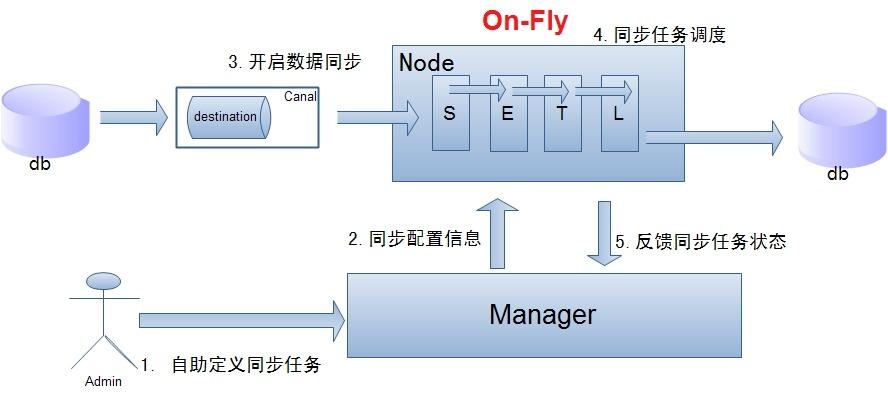
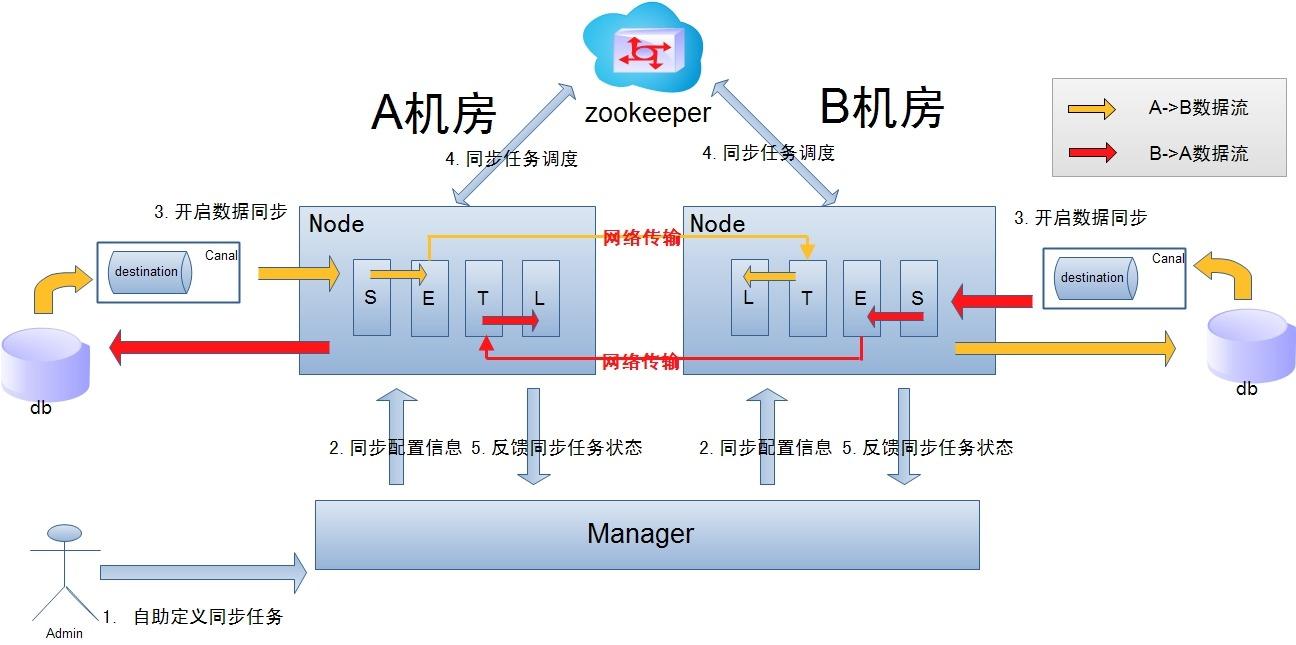
在《vivo 营销自动化技术解密 |开篇》中,我们从整体上介绍了vivo营销自动化平台的业务架构、核心业务模块功能、系统架构和几大核心技术设计。
本次带来的是系列文章的第2篇,本文详细解析设计模式和相关应用如何帮助营销自动化业务提升系统扩展性,以及实践过程中的思考和总结。
一、引言
营销业务本身极具复杂多变性,特别是伴随着数字化营销蓬勃发展的趋势,在市场的不同时期、公司发展的不同阶段、面向不同的用户群体以及持续效果波动迭代,都会产生不同的营销策略决策。
当面对随时变化的业务场景时,系统的扩展性就显得非常重要。而在谈到系统设计扩展性的时候,总是首先会想到设计原则和设计模式。但设计模式不是银弹,并不能解决所有问题,它只是前人提炼总结出来的招式方法,需要开发者根据实际业务场景进行合理的选择、合适的变通,才能真正去解决实际场景中的问题,并总结形成自己的方法论。
那么接下来我们看看设计模式是如何帮助我们在营销策略引擎中提升系统扩展性的。
二、营销策略引擎
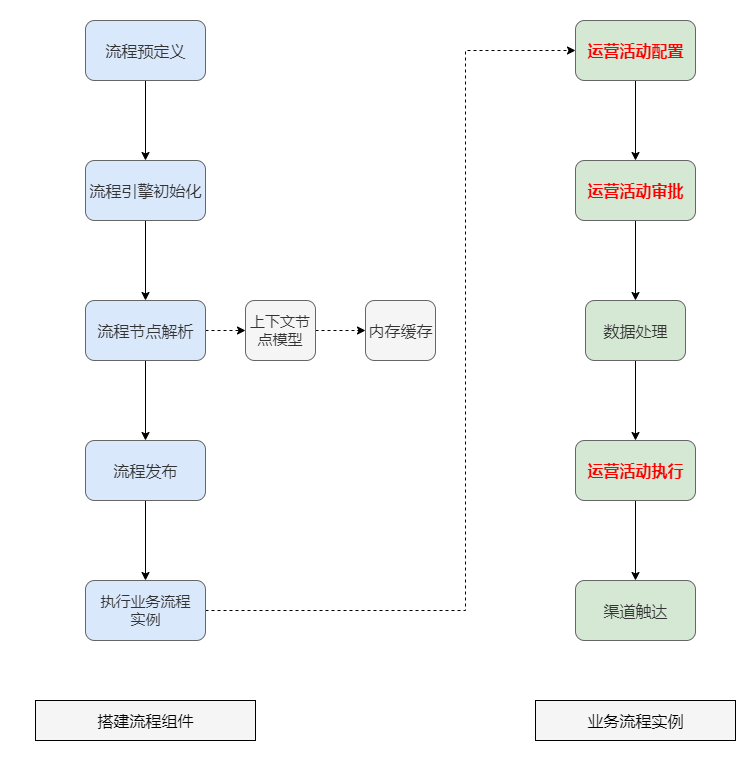
先简单介绍一下营销策略引擎:策略引擎是通过搭建可视化流程组件,定义各个流程节点,自动化执行活动业务流程,从而提供不同运营活动能力。其中核心活动业务流程主要包括三大部分:运营活动配置->运营活动审批->运营活动执行。
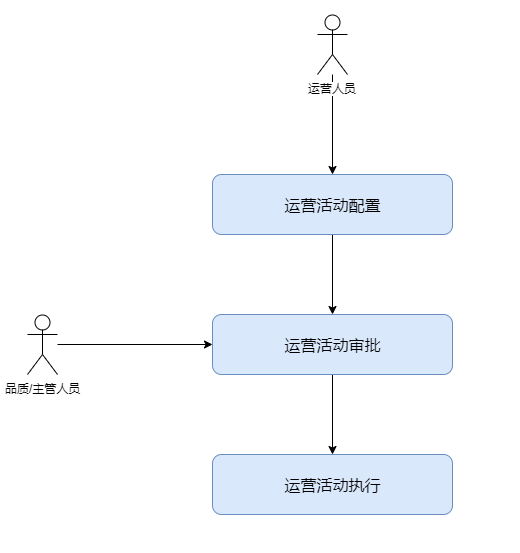
- 运营活动配置:运营人员在系统后台配置运营活动。包括活动名称、活动时间、触发条件、活动用户和具体推送渠道(如短信、微信、push推送等)。
- 运营活动审批:品质/主管人员审批运营活动配置。审批流程涉及了活动审批节点和人员的配置,审批相关的回调操作配置。
- 运营活动执行:系统自动化执行运营活动的过程。即具体的渠道如短信、微信、push等推送活动的任务执行下发流程,包括用户数据准备,数据下发推送和数据效果回收等。
三、设计模式具体应用
3.1 运营活动配置
3.1.1 工厂模式
具体场景
一般情况下,根据不同的用户和活动场景,运营借助数据分析会决策出不同的活动策略,比如需要创建短信推送策略、微信图文推送策略、App Push推送策略等。此时我们可以使用工厂模式,统一管理具体推送策略的创建。
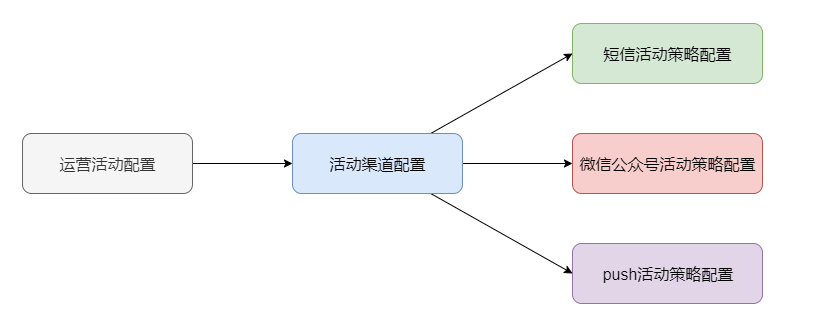
模式分析
在GoF《设计模式:可复用面向对象软件的基础》中:工厂模式被分成了工厂方法和抽象工厂两类,而简单工厂模式(又称静态工厂模式)被看作是工厂方法的一种特例。不过由于简单工厂和工厂方法相对更简单和易于理解,代码可读性也更强,因此在实际项目中更加常用。
其中简单工厂的适用场景:
- a.工厂类负责创建的对象比较少,工厂方法中的创建逻辑简单。
- b.客户端无须关心创建具体对象的细节,仅需知道传入工厂类的类型参数。
而工厂方法的适用场景:
- a.工厂类对象创建逻辑相对复杂,需要将工厂实例化延迟到其具体工厂子类中。
- b.适合需求变更频繁的场景,可以利用不同的工厂实现类支持新的工厂创建方案,更符合开闭原则,扩展性更好。
典型代码示例
public abstract class Product {
public abstract void method();
}
class ProductA extends Product {
@Override
public void method() {
}
}
abstract class Factory<T> {
abstract Product createProduct(Class<T> c);
}
class FactoryA extends Factory{
@Override
Product createProduct(Class c) {
Product product = (Product) Class.forName(c.getName()).newInstance();
return product;
}
}
实际代码
@Component
@Slf4j
public class ActivityStrategyFactory {
public static ActivityStrategy getActivityStrategy(ChannelTypeEnum channelType) {
ChannelTypeStrategyEnum channelTypeStrategyEnum = ChannelTypeStrategyEnum.getByChannelType(channelType);
Assert.notNull(channelTypeStrategyEnum , "指定的渠道类型[channelType=" + channelType + "]不存在");
String strategyName= channelTypeStrategyEnum.getHandlerName();
Assert.notNull(strategyName, "指定的渠道类型[channelType=" + channelType + "未配置策略");
return (ActivityStrategy)SpringContextHolder.getBean(handlerName);
}
public enum ChannelTypeStrategyEnum {
SMS(ChannelTypeEnum.SMS, "smsActivityStrategy"),
WX_NEWS(ChannelTypeEnum.WX, "wxActivityStrategy"),
PUSH(ChannelTypeEnum.PUSH, "pushActivityStrategy"),;
private final ChannelTypeEnum channelTypeEnum;
private final String strategyName;
ChannelTypeStrategyEnum (ChannelTypeEnum channelTypeEnum, String strategyName) {
this.channelTypeEnum = channelTypeEnum;
this.strategyName= strategyName;
}
public String getStrategyName() {
return strategyName;
}
public static ChannelTypeStrategyEnum getByChannelType(ChannelTypeEnum channelTypeEnum) {
for (ChannelTypeStrategyEnum channelTypeStrategyEnum : values()) {
if (channelTypeEnum == channelTypeStrategyEnum.channelTypeEnum) {
return channelTypeStrategyEnum ;
}
}
return null;
}
}
}
实践总结
在实际项目代码中我们采用的是简单工厂模式(静态工厂模式),实现时利用枚举(或者映射配置表)来保存渠道类型与具体策略实现类的映射关系,再结合Spring的单例模式,来进行策略类的创建。
相比于工厂方法模式,在满足业务的前提下,减少了工厂类数量,代码更加简单适用。
3.1.2 模板方法模式
具体场景
在创建不同类型运营活动策略的时候,可以发现除了保存具体活动渠道配置信息不一样之外,创建过程中很多操作流程是相同的:比如保存活动基本配置信息,审计日志上报,创建活动审批工单,创建完成后消息提醒等。
原有实践
@Service
public class SmsActivityStrategy{
public ProcessResult createActivity(ActParam param) {
saveActBaseConfig(param);
createSmsActivity(param);
sendNotification(param);
}
}
@Service
public class PushActivityStrategy{
public ProcessResult createActivity(ActParam param) {
saveActBaseConfig(param);
createChannelActivity(param);
sendNotification(param);
}
}
...
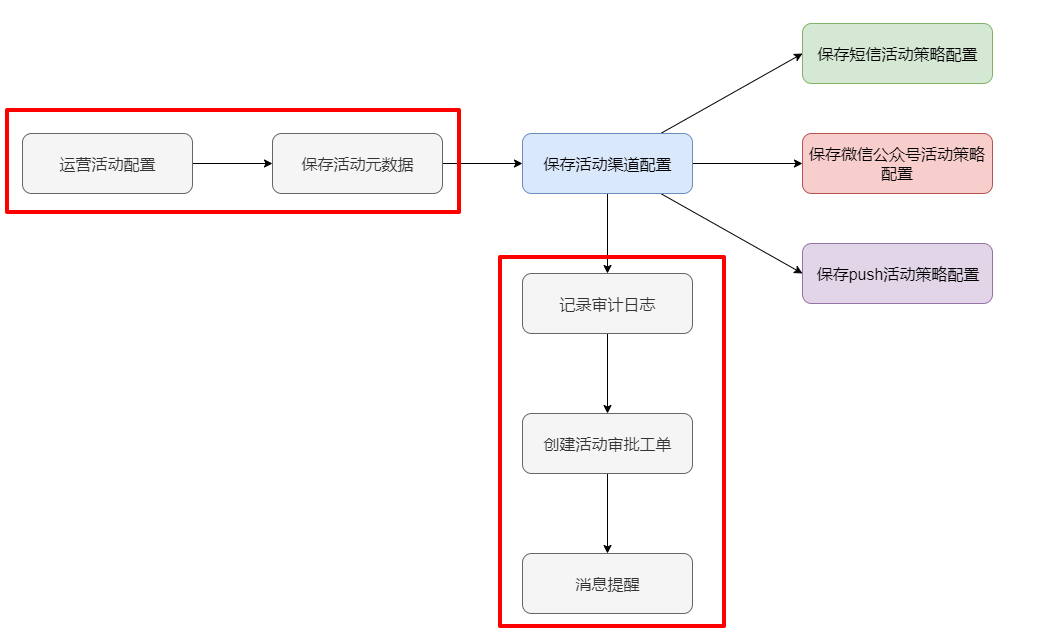
对于每种活动策略而言,这些操作都是必需的且操作流程都是固定的,所以可以将这些操作提取成公用的流程,此时就考虑到了模板方法模式。
模式分析
在GoF《设计模式:可复用面向对象软件的基础》:模板方法模式是在一个方法中定义一个算法骨架,并将某些步骤推迟到其子类中实现。模板方法模式允许子类在不改变算法结构的情况下重新定义算法的某些步骤。
上面所指的“算法”,可以理解为业务逻辑,而‘’算法骨架“即是模板,包含‘’算法骨架“的方法就是模板方法,这也是模板方法模式名称的来源。
模板方法模式适用场景:业务逻辑由确定的步骤组成,这些步骤的顺序要是固定不变的,不同的具体业务之间某些方法或者实现可以有所不同。
实现时一般通过抽象类来定义一个逻辑模板和框架,然后将无法确定的部分抽象成抽象方法交由子类来实现,调用逻辑仍在抽象类中完成。
典型代码示例
public abstract class AbstractTemplate {
protected abstract void doStep1();
protected abstract void doStep2();
public void templateMethod(){
this.doStep1();
......
this.doStep2();
}
}
public class ConcreteClass1 extends AbstractTemplate {
protected void doStep1()
{
}
protected void doStep2()
{
}
}
public class ConcreteClass2 extends AbstractTemplate {
protected void doStep1()
{
}
protected void doStep2()
{
}
}
public class Client {
public static void main(String[] args)
{
AbstractTemplate class1=new ConcreteClass1();
AbstractTemplate class2=new ConcreteClass2();
class1.templateMethod();
class2.templateMethod();
}
}
实际代码
@Slf4j
public abstract class AbstractActivityTemplate{
protected abstract ProcessResult createChannelActivity(ActParam param);
public ProcessResult createActivity(ActParam param) {
saveActBaseConfig(param);
createChannelActivity(param);
}
}
@Service
public class SmsActivityStrategy extends AbstractActivityTemplate{
public ProcessResult createChannelActivity(ActParam param) {
createSmsActivity(param);
}
}
(其他渠道活动类似,此处省略)
public class Client {
public static void main(String[] args)
{
AbstractActivityTemplate smsActivityStrategy=new SmsActivityStrategy();
AbstractActivityTemplate pushActivityStrategy=new PushActivityStrategy();
ActParam param = new ActParam();
smsActivityStrategy.createActivity(param);
pushActivityStrategy.createActivity(param);
}
}
实践总结
模板方法模式有两大作用:复用和扩展。复用是指所有的子类可以复用父类中提供的模板方法的代码。扩展是指框架通过模板模式提供功能扩展点,让用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能。
模板方法非常适用于有通用业务逻辑处理流程,同时又在具体流程上存在一定差异的场景,可以通过将流程骨架抽取到模板类中,将可变的差异点设置为抽象方法,达到封装不变部分,扩展可变部分的目的。
3.1.3 策略模式
具体场景
上述我们通过模板方法模式抽取出了公共流程骨架,但这里还存在一个问题:调用类仍需要明确知道具体实现类是哪个,实例化后才可进行调用。也就是每一次增加新的渠道活动时,调用方都必须修改调用逻辑,添加新的活动实现类的初始化调用,显然不利用业务的扩展性。
在创建运营活动过程中,不同类型的活动会对应着不同的创建流程,调用方只需要根据渠道类型来进行区分,而无需理会其中具体的业务逻辑。此时策略模式是一个比较好的选择。
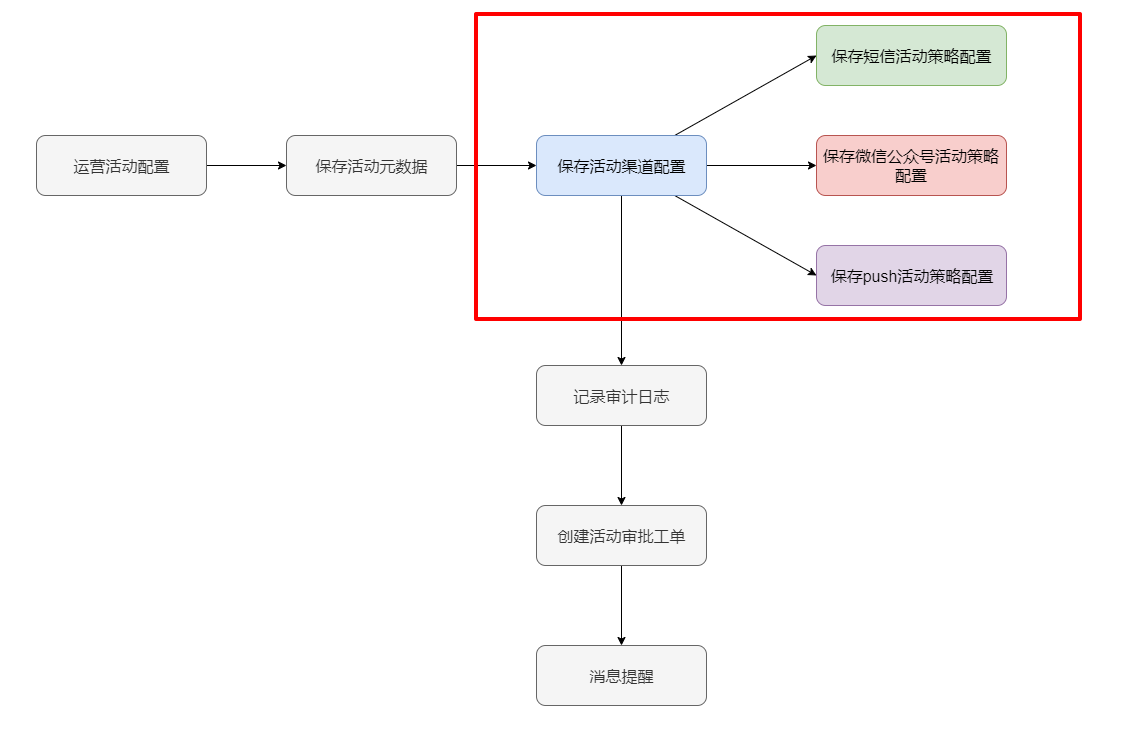
模式分析
在GoF《设计模式:可复用面向对象软件的基础》中:策略模式定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的调用方。
典型代码示例
public interface Strategy {
void doStrategy();
}
public class StrategyA implements Strategy{
@Override
public void doStrategy() {
}
}
public class Context {
private Strategy strategy = null;
public Context(Strategy strategy) {
this.strategy = strategy;
}
public void doStrategy() {
strategy.doStrategy();
}
}
实际代码
public interface ActivityStrategy {
void createActivity(ActParam param);
}
@Slf4j
public abstract class AbstractActivityTemplate implements ActivityStrategy {
protected abstract ProcessResult createChannelActivity(ActParam param);
@Override
public ProcessResult createActivity(ActParam param) {
saveActBaseConfig(param);
createChannelActivity(param);
}
}
@Component
public class SmsChannelActivityStrategy extends AbstractActivityTemplate {
@Override
public void createChannelActivity(ActParam param) {
}
}
(其他渠道活动类似,此处省略)
@Slf4j
@Component
public class ActivityContext {
@Resource
private ActivityStrategyFactory activityStrategyFactory ;
public void create(ActParam param) {
ActivityStrategy strategy = activityStrategyFactory.getActivityStrategy(param.ChannelType);
strategy.createActivity(param);
}
}
实际编码过程中,我们加入了ChannelActivityStrategy作为渠道活动创建策略接口,并用模板类AbstractActivityTemplate实现该接口,同时结合工厂模式创建具体策略,至此将三种模式结合了起来。
实践总结
策略模式在项目开发过程中经常用于消除复杂的if else复杂逻辑,后续如果有新的渠道活动时,只需要新增对应渠道的活动创建逻辑即可,可以十分便捷地对系统业务进行扩展。
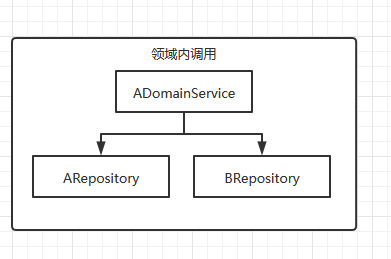
在项目实践过程,经常会将工厂模式、模板方法模式和策略模式一起结合使用。模板方法模式进行业务流程公共骨架的抽取,策略模式进行具体子流程策略的实现和调用的封装,而工厂模式可以进行子流程策略的创建。
多种模式的结合使用可以充分发挥出各个模式的优势,达到真正提升系统设计扩展性的目的。
3.2 运营活动执行
3.2.1 状态模式
具体场景
在运营活动的执行过程中,会涉及活动状态的变更,以及变更前的条件检测和变更后的操作处理。与之相对应地,我们很容易就会想到状态模式。

模式分析
在 GoF 经典的《设计模式:可复用面向对象软件的基础》中:状态模式允许一个对象在其内部状态改变的时候改变其行为。
状态模式的作用就是分离状态的行为,通过维护状态的变化,来调用不同状态对应的不同功能。它们的关系可以描述为:状态决定行为。由于状态是在运行期被改变的,因此行为也会在运行期随着状态的改变而改变。
典型代码示例
interface State {
void handle()
}
public class ConcreteStateA implements State {
@Override
public void handle() {
}
}
public class ConcreteStateB implements State {
@Override
public void handle() {
}
}
public class Context {
private State state;
public void setState(State state) {
this.state = state;
}
public void request() {
state.handle();
}
}
public class Client {
public static void main(String[] args){
State state = new ConcreteStateB();
Context context = new Context();
context.setState(state);
context.request();
}
}
实践总结
在实际软件项目开发中,业务状态不多且状态转移简单的场景, 可使用状态模式来实现;但如果是涉及的业务流程状态转移繁杂时,使用状态模式会引入非常多的状态类和方法,当状态逻辑有变更时,代码也会变得难以维护,此时使用状态模式并不十分适合。
而当流程状态繁多,事件校验和触发执行动作包含的业务逻辑比较复杂时,如何去实现呢?
这里我们必须停下来思考:使用设计模式只是解决实际问题的一种手段,但设计模式不是一把“万能的”锤子,需要清楚地了解到它的优势和不足。而这种问题场景下,业界已经有一个更通用的方案——有限状态机,通过更高层的封装,提供给业务更便捷的应用。
3.2.2 状态模式的应用——有限状态机
有限状态机(Finite-State Machine , 缩写:FSM),业界简称状态机。它亦是由事件、状态、动作 三大部分组成,三者的关系是:事件触发状态的转移,状态的转移触发后续动作的执行。状态机可以基于传统的状态模式硬编码来实现,也可以通过数据库/文件配置或者DSL的方式来保存状态及转移配置来实现(推荐)。
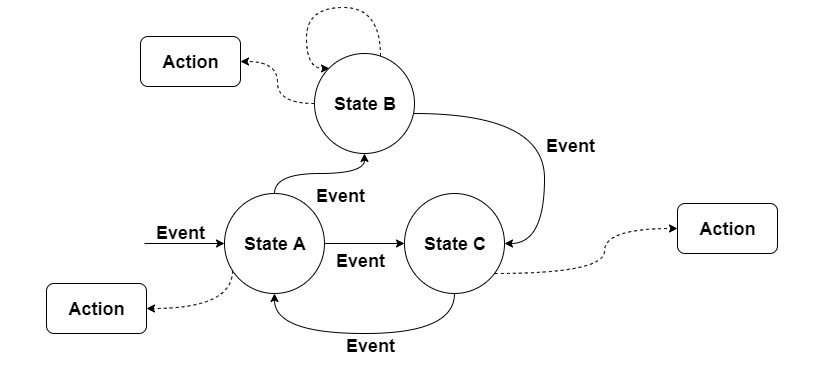
业界中也已涌现出了不少开源状态机的框架,比较常用的有Spring-statemachine(Spring官方提供) 、squirrel statemachine和阿里开源的cola-statemachine。
实际应用
在实际项目开发中,我们针对自身业务的特点:业务流程状态多,但是事件触发和状态变更动作相对简单,故而选择了无状态、更加轻量级的解决方案——基于开源的状态机实现思想进行开发。(关于状态机的实现和使用选型会在后续的文章中做进一步的分析,感兴趣的童鞋可以访问官网先做了解)。
实践代码
public class StatusMachineEngine {
private StatusMachineEngine() {
}
private static final Map<OrderTypeEnum, String> STATUS_MACHINE_MAP = new HashMap();
static {
STATUS_MACHINE_MAP.put(ChannelTypeEnum.SMS, "smsStateMachine");
STATUS_MACHINE_MAP.put(ChannelTypeEnum.PUSH, "pushStateMachine");
}
public static String getMachineEngine(ChannelTypeEnum channelTypeEnum) {
return STATUS_MACHINE_MAP.get(channelTypeEnum);
}
public static void fire(ChannelTypeEnum channelTypeEnum, String status, EventType eventType, Context context) {
StateMachine orderStateMachine = StateMachineFactory.get(STATUS_MACHINE_MAP.get(channelTypeEnum));
orderStateMachine.fireEvent(status, eventType, context);
}
@Component
public class SmsStateMachine implements ApplicationListener<ContextRefreshedEvent> {
@Autowired
private StatusAction smsStatusAction;
@Autowired
private StatusCondition smsStatusCondition;
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
StateMachineBuilder<String, EventType, Context> builder = StateMachineBuilderFactory.create();
builder.externalTransition()
.from(INIT)
.to(NOT_START)
.on(EventType.TIME_BEGIN)
.when(smsStatusAction.checkNotifyCondition())
.perform(smsStatusAction.doNotifyAction());
builder.externalTransition()
.from(NOT_START)
.to(DATA_PREPARING)
.on(EventType.CAL_DATA)
.when(smsStatusCondition.doNotifyAction())
.perform(smsStatusAction.doNotifyAction());
builder.externalTransition()
.from(DATA_PREPARING)
.to(DATA_PREPARED)
.on(EventType.PREPARED_DATA)
.when(smsStatusCondition.doNotifyAction())
.perform(smsStatusAction.doNotifyAction());
...(省略其他状态)
builder.build(StatusMachineEngine.getMachineEngine(ChannelTypeEnum.SMS));
}
public class Client {
public static void main(String[] args){
Context context = new Context(...);
StatusMachineEngine.fire(ChannelTypeEnum.SMS, INIT, EventType.SUBMIT, context);
}
}
}
通过预定义状态转换流程的方式,实现ApplicationListener接口,在应用启动时将事件、状态转移条件和触发操作的流程加载到状态机工作内存中,由事件触发驱动状态机进行自动流转。
实践总结
实际场景中,不必强行套用设计模式,而是应当充分结合业务的特点,同时针对设计模式的优劣势,进行更加合适的选型或者进一步扩展。
3.3 自动化运营活动审批
3.3.1 设计模式的综合应用——工作流引擎
具体场景
为了做好品质和风险管控,活动创建需要加入审批环节,把控运营活动的发布执行,同时对于不同类型的运营活动,可能涉及的业务领域和部门各不相同,审批管控人员也不一样,需要配置相对应的审批关系。
此时需要做到:
- a.审批流程全配置化,易修改和添加;
- b.业务流程节点可自由编排,组件公用化;
- c.流程数据持久化,审批过程数据需要进行操作监控。
针对这方面的需求,业界有一套通用的业务工具——工作流引擎。工作流引擎显然并不属于具体某一种设计模式的实现,它是涵盖了多种设计模式的组件应用。
不仅仅是审批功能,其实前面自动化营销流程引擎设计也同样是使用工作流引擎搭建流程组件:
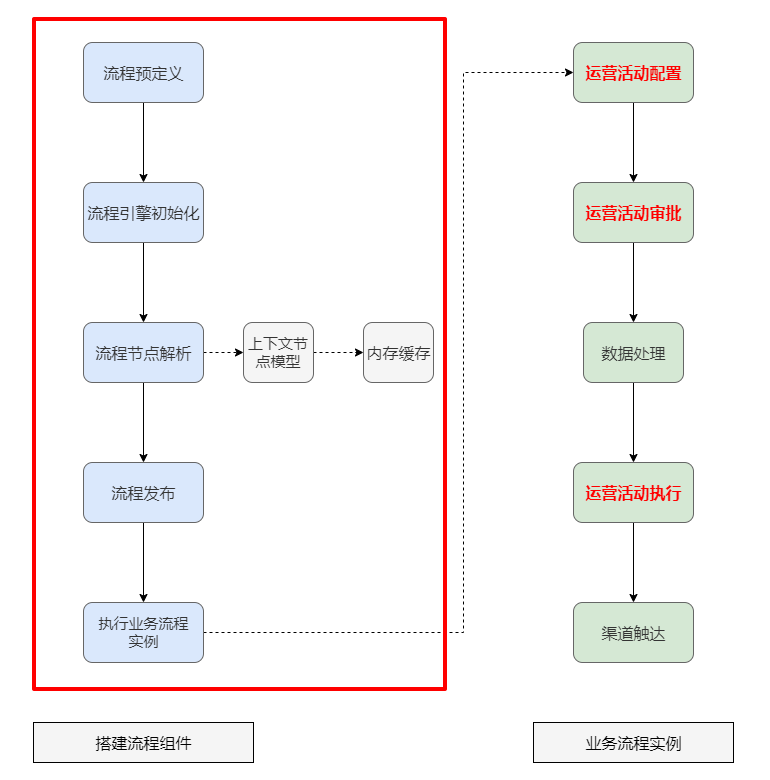
状态机 VS 工作流引擎
工作流引擎和状态机似乎存在非常多的相似之处,都可以通过定义流程的节点、转移条件和相应触发的操作来完成业务流程。如果只从适用场景的复杂性上看,状态机更适用于单维度的业务问题,能够清晰地描绘出所有可能的状态以及导致转换的事件,更加灵活轻便;而工作流引擎则更适合业务流程管理,解决如大型CRM复杂度更高的流程自动化问题,可以改善整体业务流程的效率。
在业界的工作流引擎中,比较著名的有Activiti和JBPM等。(关于状态机和工作流引擎的对比、开源工作流引擎的具体介绍和选型,以及如何自行开发构建一款基本的工作流引擎组件,同样是会在后续的文章中做进一步分析,本文由于主题和篇幅的原因暂不做详细介绍。)
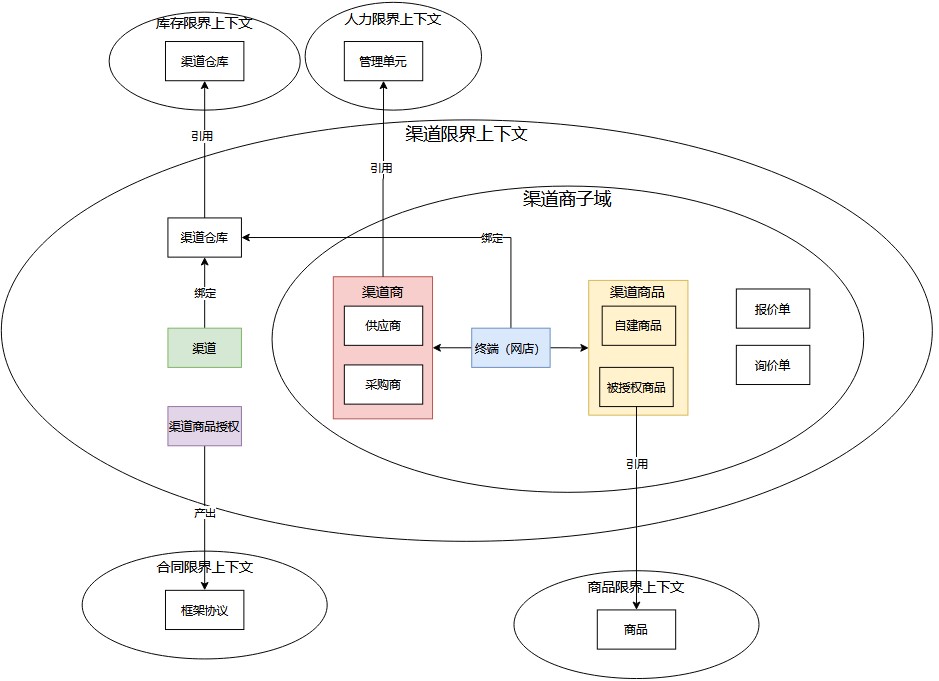
在实际开发过程中,我们是基于开源的Activiti工作流引擎自研了一套简易版的工作流引擎,精简了许多相关的配置,只留下了核心流程操作和数据记录。
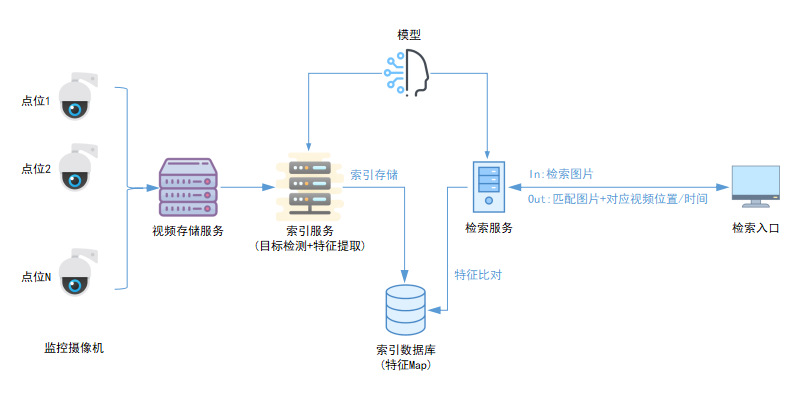
工作流引擎流程图:
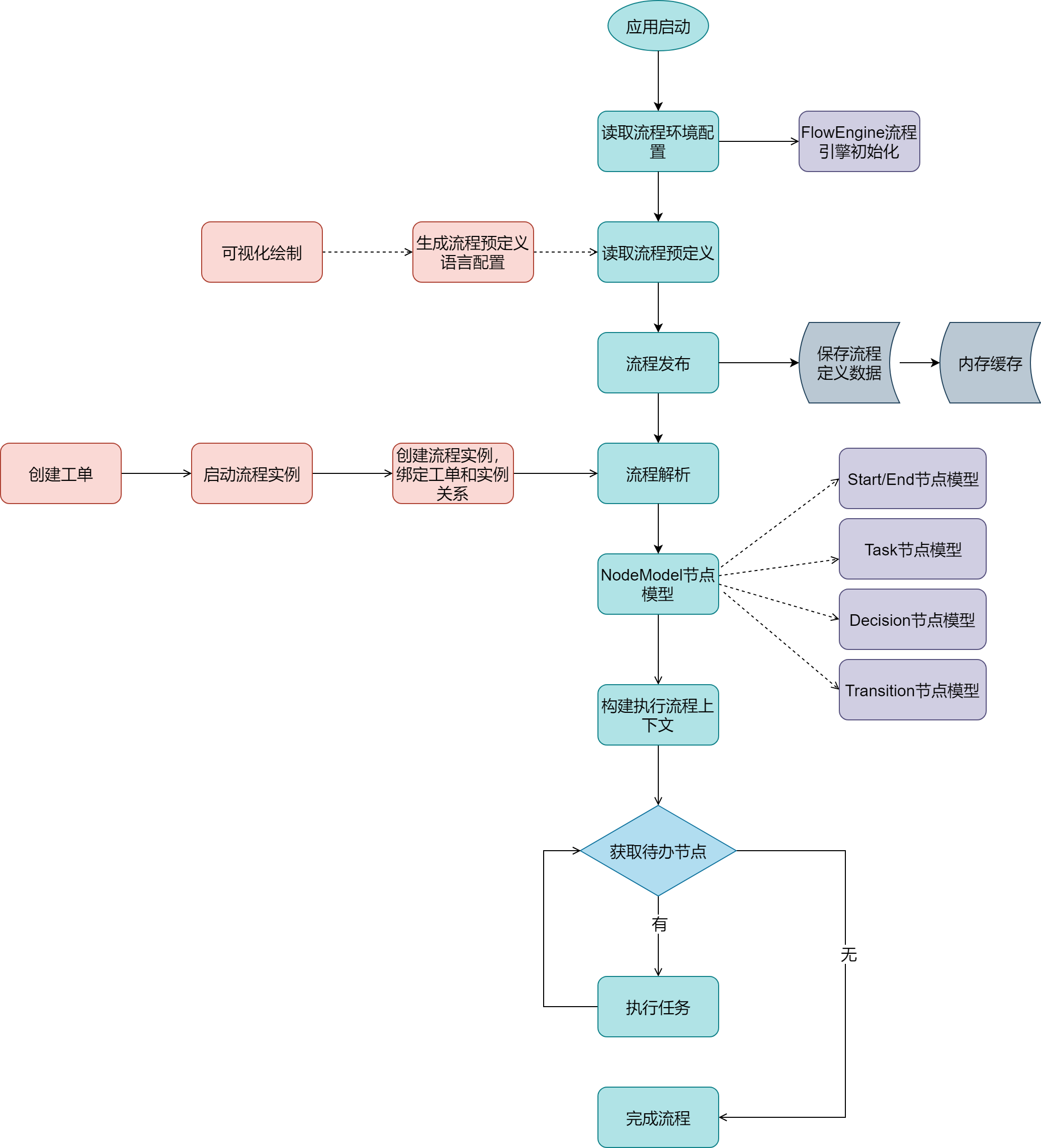
实践总结
工作流引擎是涵盖了多种设计模式的应用组件,只有在复杂多变的业务场景中才需要应用,需要结合业务进行仔细评估。在合适的场景使用合适的解决方案,遵循系统架构设计的简单、合适、可演化原则,不过度设计。
四、总结
本文基于自动化营销的业务实践,分析介绍了工厂方法模式、模板方法模式、策略模式以及状态模式这四种模式在项目开发中的具体实现过程。也在单纯的模式之外介绍了状态机和工作流引擎这些涵盖了多种设计模式系统组件,并分享了过程中的选择和思考。
面对业务复杂多变的需求,需要时刻关注系统设计的复用性和可扩展性,而设计原则和设计模式可以在系统设计实现时给予我们方向性的指导,同时更需要根据实际业务场景进行合理的选择,合适的变通,不断完善自己的方法论。
后续我们将带来系列专题文章的其他内容,每一篇文章都会对里面的技术实践进行详尽解析,敬请期待。
作者:vivo互联网服务器团队-Chen Wangrong