智能盘点-钢筋数量AI识别-目标检测实践 – 知乎
- 开发笔记
- 2021-08-13
- 152热度
- 0评论
003-智能盘点-钢筋数量AI识别-实践
1 背景
在现如今All in AI的背景中,越来越多的传统行业,开始加快数字化、智能化的进程,
AI养猪、AI养鸡这样接地气的场景,也已经进入到落地、工业化的阶段。
0110日,广联达在DataFountain发布了智能盘点—钢筋数量AI识别比赛
比赛地址
- 在工地现场,对于进场的钢筋车,验收人员需要对车上的钢筋进行现场人工点根,确认数量后钢筋车才能完成进场卸货。目前现场采用人工计数的方式,如图1-1中所示:


- 上述过程繁琐、消耗人力且速度很慢(一般一车钢筋需要半小时,一次进场盘点需数个小时)。针对上述问题,希望通过:
手机拍照->目标检测计数->人工修改少量误检的方式
2 问题
- 精度要求高(High precision requirement)
- 钢筋本身价格较昂贵,且在实际使用中数量很大,误检和漏检都需要人工在大量的标记点中找出,所以需要精度非常高才能保证验收人员的使用体验。需要专门针对此密集目标的检测算法进行优化,另外,还需要处理拍摄角度、光线不完全受控,钢筋存在长短不齐、可能存在遮挡等情况。
- 钢筋尺寸不一(Various dimensions of rebars)
- 钢筋的直径变化范围较大(12-32中间很多种类)且截面形状不规则、颜色不一,拍摄的角度、距离也不完全受控,这也导致传统算法在实际使用的过程中效果很难稳定。
- 边界难以区分(Indistinguishable boundaries )
- 一辆钢筋车一次会运输很多捆钢筋(如图1-3),如果直接全部处理会存在边缘角度差、遮挡等问题效果不好,目前在用单捆处理+最后合计的流程,这样的处理过程就会需要对捆间进行分割或者对最终结果进行去重,难度较大。
看看实际的场景图片:


希望的结果是这样的,告诉有多少根、并且标记位置供人工验证

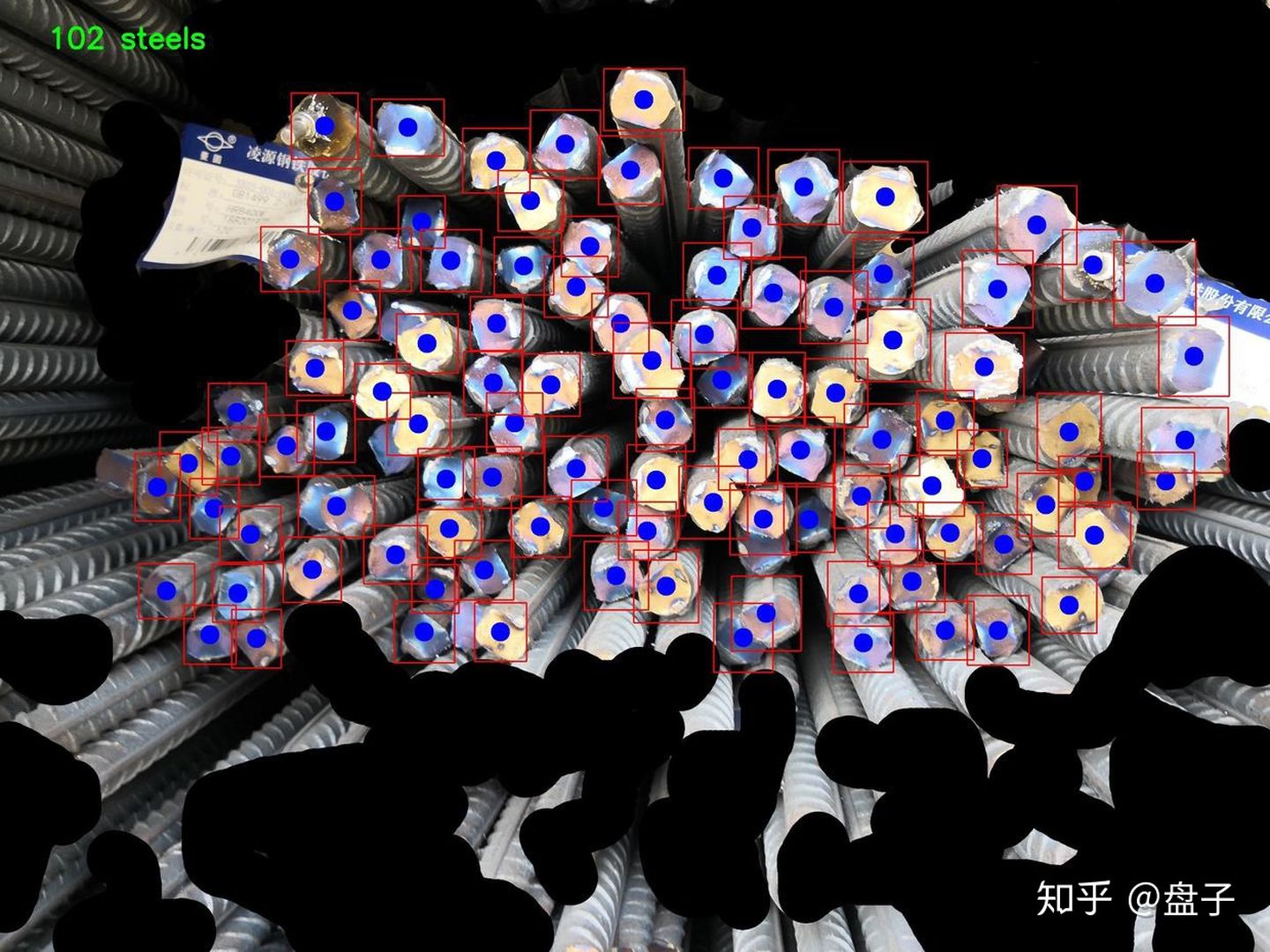
3 分析
AI数钢筋这个问题是一个 object detection 问题,相比于多分类,这里是一个密集型小物体单分类定位问题。
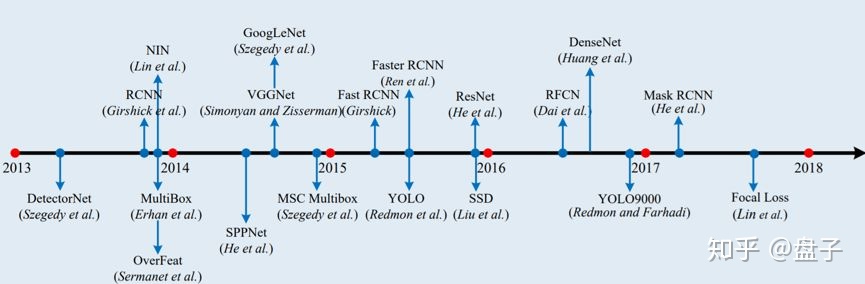
目标检测流派,常被分为双阶段检测 和 单阶段检测
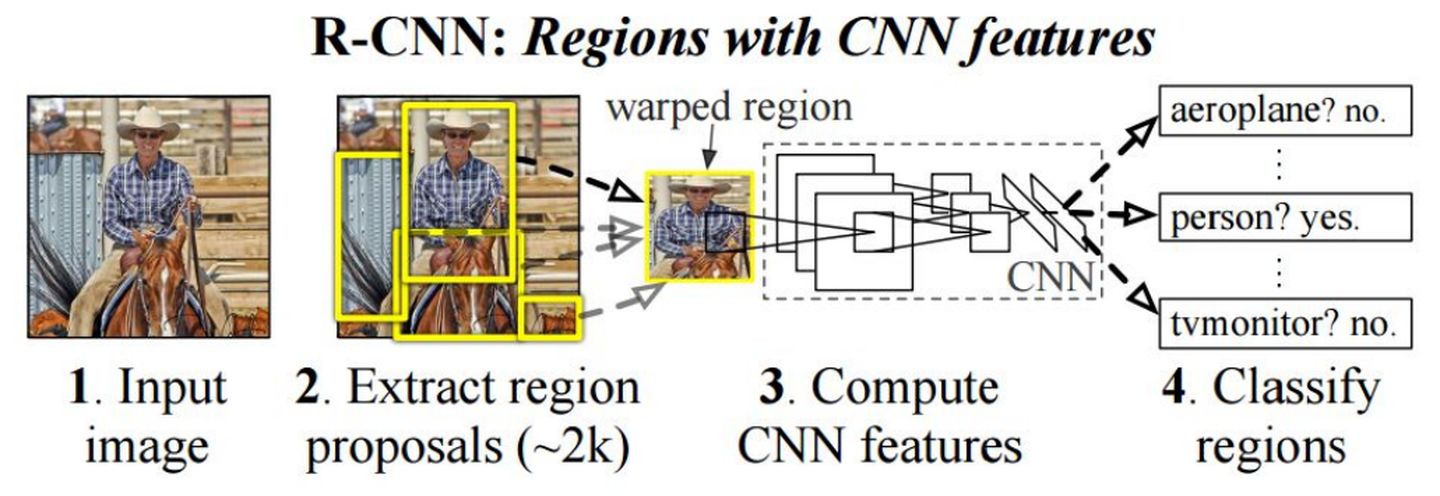
- 双阶段检测、始于2014年 大神RBG 的
Rcnn,后续Fast-Rcnn(2015)Faster R-CNN (2016)是对其的进一步优化。
https://arxiv.org/abs/1311.2524
论文 2014年 RBG大神
- 方法流程(Faster Rcnn):
- 1 通过conv layers 卷积层 获取图像特征信息 feature maps 77512 (VGG为例)
- 2 RPN层 (softmax) 判断anchors属于foreground或者background 利用bounding box regression修正anchors获得精确的proposals
- 3 Roi Pooling 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别
- 4 Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
- 单阶段检测、始于2016年的 Joseph Redmon ,之后的
YOLO9000YOLOV3是对其的进一步优化
https://arxiv.org/abs/1506.02640
2016年 Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
You Only Look Once
YOLO家族区别于两阶段的RCNN家族,取消了RPN层,将proposal和detection放在一级完成。
4 实践
1 双阶段Faster Rcnn
- 坑1 :
在Faster-Rcnn论文和众多开源项目中,都会使用这样的一组anchors,尺度,在600*800 的标准输入中,最小的也是,128*128 像素,实际在当前场景下,尺度会更小,应该使用更小的anchors来 增加RPN层正样本的命中率和训练收敛速度。
[128, 256, 512]
[1:1,1:2,2:1]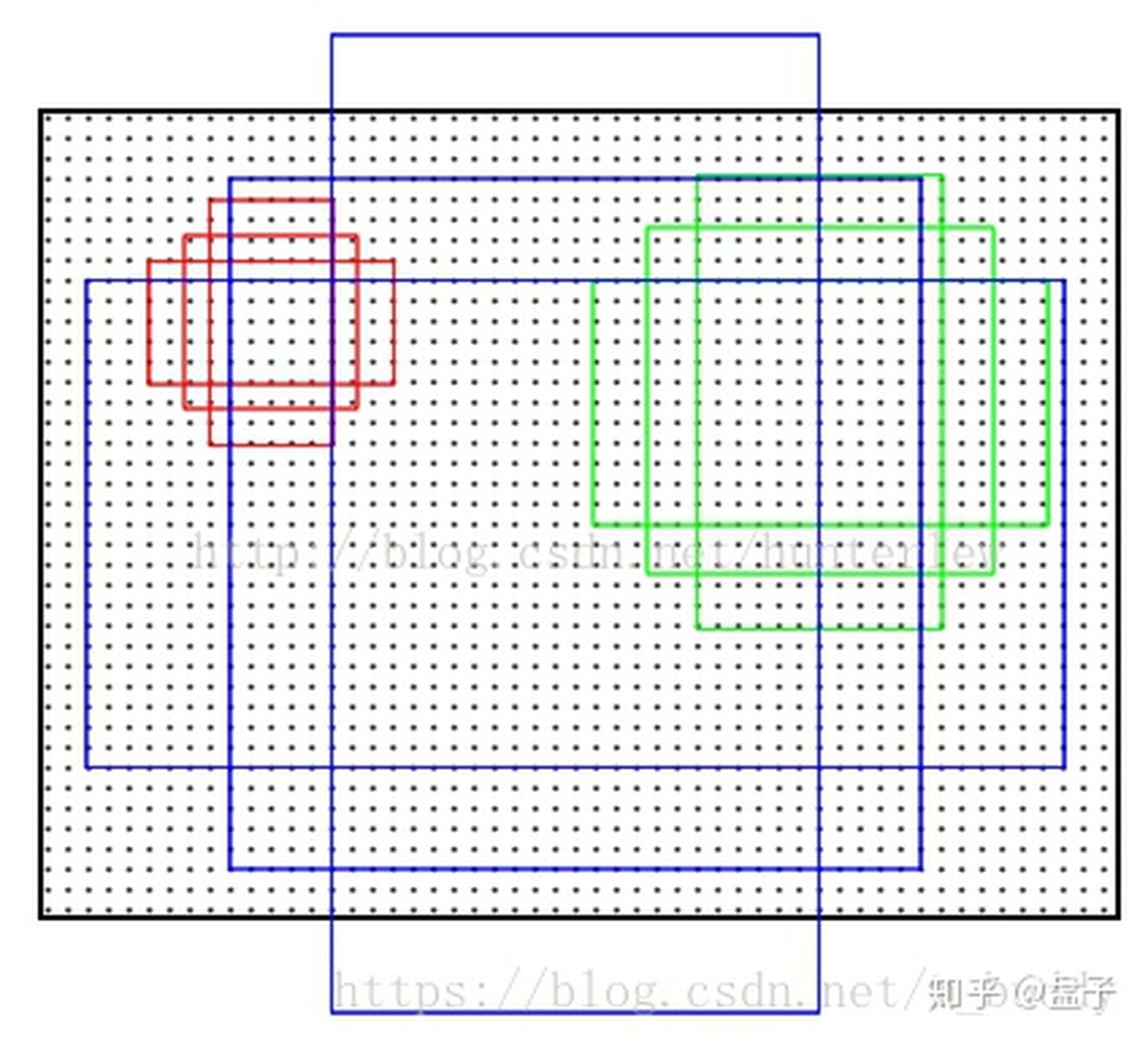
- 坑2 :
在Roi Pooling层前,提取RPN层正负样本,模式是256个(128正,128负),当正样本少于128时,增加负样本个数。当在当前场景中,ground truth 个数最多都有300个左右,适当增加样本采样会更利于训练。
- 坑3 :
增加num_rois个数,确保检出率。
如下是在250张训练数据下,10轮训练的结果,框定位置不够准确,密集区存在漏检。更重要的是,在
Tesla V100下 一轮training的时间是 50-70min。测一轮,一天就过去了。


2 单阶段YOLO
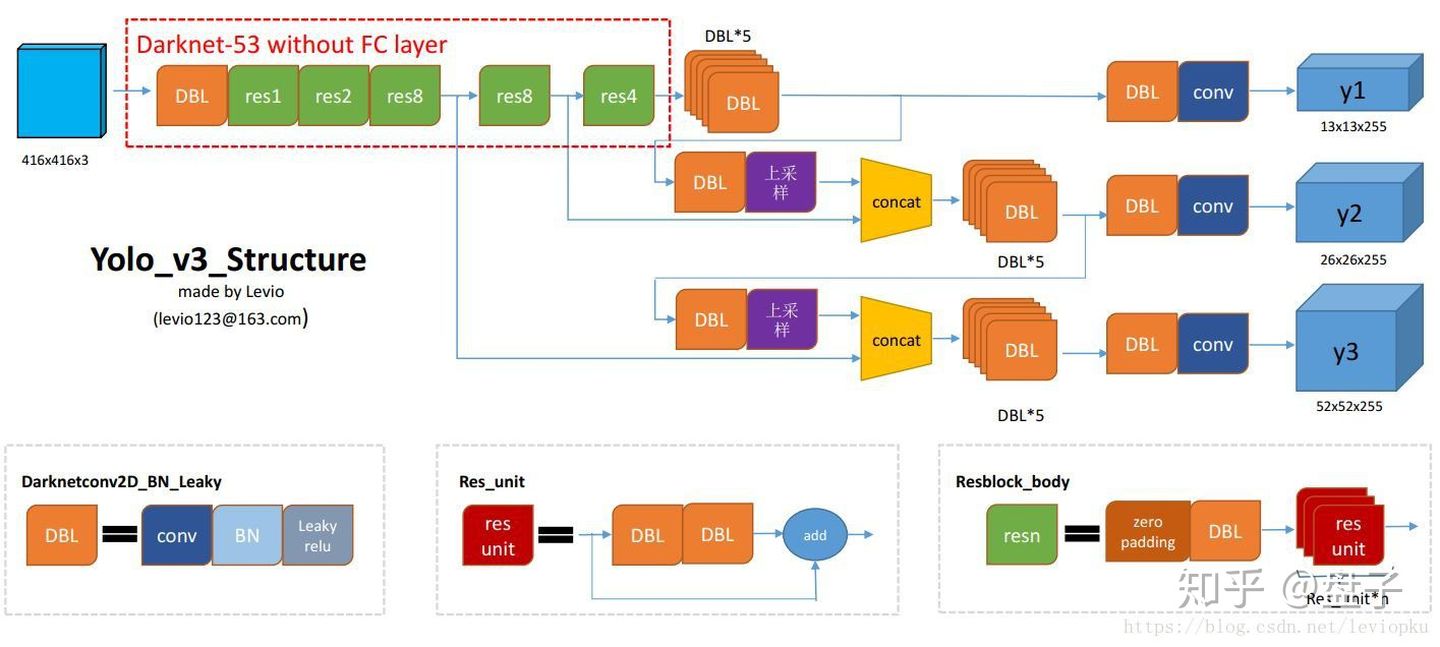
YOLO被称为是目标检测工程化的首选模型。在YOLOv1/2 中 小尺度密集物体的定位效果差,常被诟病,在2018年新出的YOLOv3中,有了很大的改进。
- yolo3 使用 借鉴resnet的darknet网络作为backbone,多尺度的引入,使得模型的感受野更大,
- 在默认模型中,yolov3 输出 13 26 52 三个尺度的特征信息。


- 在416*416尺度下,最小可以感受 8*8 像素的的信息 ,恢复到本场景2000*2000 差不多是40*40 像素,基本满足。
- 根据K-Means修改先验框,加速模型收敛。(如果用图像增强套路,增强后再进行K-Means更佳)
- 超参数调整,
最大检出框,IOU,SCORE-THRESH,这需要更多的尝试


在提交结果到比赛后台时,发现F1 Score 比感受得分低,通过对训练数据predict结果,评价发现,主要原因是官方IOU设置问题,比赛要求IOU>0.7为真;这是一个较为严格的标准(更多比赛在0.5)。比如在测试时发现,在IOU=0.5 时模型mAP=95.81% (P=0.99 R=0.97)时,IOU=0.7时 mAP=83.1%。
- 所以下面,还需要进一步提高标定框的精度。
- 1 提高训练ignore_thresh值,该值是确定anchor定框,和真实框在何种阈值下,为正样本的阈值。既然比赛要求是0.7 ,该参数也应该提高。
- 2 增大input size 默认size为416*416 理论已经满足需求,但是适当提高input size 会有助于提高文本框标定精度。
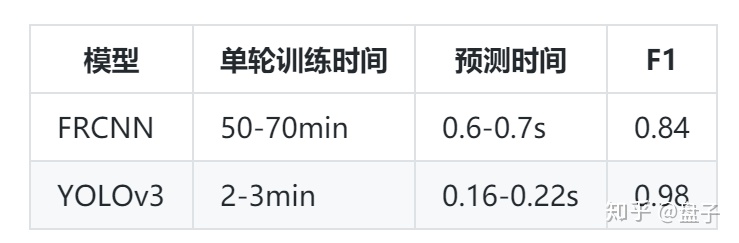
5 对比
1 评价标准
- 官方提供了常规的F1指标

2 对比
比较上述两种方法:

- PS:
- 如上对比,仅仅是当前测试结果,理论上FRCNN RFCN等两阶方法可以更好,谁让它训练时间太长...
- YOLO的评分同样可以更好,实际是现在的NO1 已经是无限接近0.99的成绩... 膜拜