前言
承玉曾经写过一篇文章构建前端DSL,本文讨论的话题和承玉的差不多,相信大家都知道coffeescript,handlerbars。承玉的DSL和handlerbars类似,我完成的模板语言velocity解析器,和coffeescript类似。在此,与大家分享一些经验,如果你也希望知道coffeescript语法解析如何完成的,那么,本文应该对你有所启示。
说明:本文中主要关注编译器语法分析过程,就语法分析过程而言,解释器和分析器没有区别,所以,请原谅后文中把这两个概念混淆着用了。
让我们回顾一下2010年D2的时候,Hedger介绍了Closure Compiler,老赵的jscex,他们有一个共同点,都是对js进行编译,让js运行更快或者提供一起额外的功能。编译这么一个似乎和 JavaScript没有关系的话题,却逐渐被越来越多的人提起。
本文主要介绍如何用js写一个编译器,这看起来似乎很高级,实际上,编译原理很复杂,写一个编译器却不怎么难,在做这个模板编译之前,我个人对于编 译原理完全不知道的,因为看到coffeescript语法是Jison生成的,然后尝试了一下。写一个编译器,其实就是把一些语法规则翻译成计算机能够 理解的结构,计算机所能理解语法规则有专门的描述语言,Yacc + Lex。IBM上有文章如此描述:
Lex 和 Yacc 是 UNIX 两个非常重要的、功能强大的工具。事实上,如果你熟练掌握Lex 和 Yacc 的话,它们的强大功能使创建 FORTRAN 和 C 的编译器如同儿戏。
Yacc + Lex的一个实现是Bison,09年Zach Carter为了研究编译原理课程,用js完成了Bison的实现Jison, 承玉的kison类似。故事就讲到这里,什么是Yacc,Lex,Bison,Jison,Kison,都不重要,重要的是,这些技术使得我们可以使用简单的方式完成复杂的字符串解析(比如编译)任务。现在我们要来实现一个解释器了,看完就知道这一切了。
Lex & Yacc
Lex和Yacc主要用于解决编译中的第一个问题,源文件从字符串变得有意义(结构化数据)。这个过程,又分为两个步骤:
- 源文件拆分成各种标志(tokens) Lex
- 构造数据结构 Yacc
学习英语的时候,我们都会遇到语法问题,对于陌生的语言,需要知道其语法规则,计算机语法规则与自然语言类似,只是自然语言是与上下文有关的语言,比起计算机语言复杂得多。与上下文无关,其实就是语言的符号意义是确定的。扯远了,举个例子,一个正常的英语句子:
I have a dream. 回到英文课堂,老师会说,句子是由主语+谓语+冠词+宾语构成,这个句子构成的元素是,主语I,谓语have,宾语dream,句号表示句子的结束。这样的一个语法规则,让计算机理解,需要依据上面的两个步骤:
- 识别单词,也就是英语中的主语、谓语和宾语,好吧这些背单词的时候记住就行,标点符号也是词法元素。
- 语法识别,上面的句子对应的语法是:谓语 + 主语 + 冠词 + 宾语 + 问号 => 句子
词法识别和英语学习中背单词一样,计算机通过正则在字符串中匹配词,构成语言的基本结构,这些结构按照一定组合规则构成语法。Yacc所做的,是把 扫描一串字符串,识别其中的词,把词和所描述的语法一一对照,然后能够得到一些结构化的数据,比如上面英语,计算机就能够知道,这是一个完整的句子,三个 主要成分是I、have、dream,至于这个句子什么意思,你应该如何处理,这是编译过程的第二步了。
velocity syntax
上面简单描述了一下原理,现在开始写语法规则分析器吧。写编译器就是把一套语法规则描述清楚,就像翻译一篇说明书。当然,我们首先需要能明白说明书 的意义,本文以velocity模板语言为例,velocity是Java实现的一套模板,是阿里集体后端webx框架的模板语言,语法规则文档,可以大致看下语法,或者点击此处在线尝试vm解释过程。
vm(velocity简称)语法规则很简单,大概开5分钟就能学会,vm虽然简单,但是也是一套比较基本的计算机语言的实现了,对比下,英语我们学习了10年,还没能学好,vm只需要5分钟,自然语言的复杂度,比起计算机语言实在不是一个数量级。
#set( $foo = "Velocity" ) Hello $foo World! vm语法分为两部分,第一部分是vm语法内容,另一部分是字符串,模板语言都是如此,字符串部分无需考虑,原样输出即可,vm语法主要是前者结构分析。上面的vm输出Hello Velocity World!。语法部分,主要分为两部分References和Directives。
References 和 Literal
References是vm中变量,解析时References输出为变量对应的值,模板语言最基本的功能也就是变量替换,vm同样如此,只是vm 还有一些其他复杂的功能。Literal和js里面的字面量一直,是vm里面的基本数据结构。vm是一个模板语言,变量的值可以来自外部,而且是主要数据 来源,References和Literal这两者构成了vm语法的基本数据。
References基本形式是$foo,或者加一些修饰符$!{foo}。复杂形式是,变量+属性,支持的属性方式有三种:
- Properties 最普通的属性
$foo.bar - Methods 方法
$foo.bar(),因为方法是有参数的,参数由References和Literal构成 - Index 索引
$foo['bar'],index可以是字符串,也可以是变量References
上面三种方式和js的对象属性查找方式一样,因为存在Methods和Index,方法和Index本身又可以包含References,引用的组 成部分可以是引用。这样式描述形成了递归,语法一般都是通过递归的形式来相互包含。引用(References)里包含自身,这如果使用普通的字符串匹 配,逻辑上会有些晕。
Literal是基本的数据结构,分为字符串、map(js中的对象)、数字、数组。map的值由Literal 或者References构成,数组元素同样,字符串和数组相对简单,可以直接从源文件中匹配得到。到此,应该大致明白编译的复杂了吧,就这些基本的数据 结构相互包含,要理清其中结构,还是很麻烦的吧,虽然我们可以一眼就知道这些结构,如何让计算机明白,就不那么容易了。不过,通过yacc,我们只需要描 述清楚这些结构就行,怎么理清其中关系,Jison会自动处理的。
Directives
前面引用和字面量部分,是vm中关系最复杂的结构了,Directives是一些指令,包括逻辑结构和循环,模块之间引用加载等运算。这些结构比较好搞定,一般都是各自不相干,不像上面,相互引用,纠缠不清。vm解析,最复杂的还是在于引用的确定。
Directives分为单行指令和多行指令,单行指令作用范围是一句,比如#set、#parse,多行指令主要是#macro,#foreach,if|else|elseif,这些都是通过#end来结束,这样的区分可以在语法分析阶段完成,也可以在后期处理。
语法分析
本文有些长,已经开始靠近目标了。上面描述语法的过程,是非常重要的,使用yacc描述语法规则,就是对输入源分类的过程。经过上面的分析,yacc的已经差不多构思好了,接下来把规则用yacc语法写下来就好。
在写yacc描述之前,需要做一件是,lex词法分析。词法分析就是要找到上面说的References、Literal、Directives的基本元素。新建一个文件velocity.l,开始写lex描述。
References
从References开始,vm里面引用的最主要的特征是符号$,首先假设有一个vm字符串:
hello $foo world 其中,$foo是References,很明显References是美元符号开头,$后面跟字母,这里需要引入状态码的概念,因为$后面的字母的意义和$前面的字母意义是不一样的,那么当扫描到$以后,可说我们处于不同的状态,区分好状态,就可以专心处理之和vm语法,否则同样的一个字符,意义就不一样。这个状态,我们用mu表示,状态吗可以随意命名,使用mu,是有渊源的,handlerbars的lex文件因为继承了Mustache语法,mu表示Mustache语法开始,我参考了handlerbars,所以用mu。
velocity.l写下:
%x mu %% [^#]*?/"$" { this.begin("mu"); if(yytext) return 'CONTENT'; } <mu>"$!" { return 'DOLLAR'; } <mu>"$" { return 'DOLLAR'; } <INITIAL><<EOF>> { return 'EOF'; } %x声明有的状态码,状态码和字符串或者正则表达式组合成一个特征,比如<mu>"$",双引号表示字符串,这个特征描述表示,mu状态下,遇到$,返回DOLLAR。我们用DOLLAR描述$,至于为什么我们要给$一 个名字,再次回到英语中,我们会把单词分为名词、动词,各种分类,语法规则不会直接处理某个特定的词如何组合,而是规定某一类词的组合规则,比如,最普通 的句子,主语+谓语+宾语,主语一般是名词,谓语是动词,宾语也是名词,这样描述要简单得多,lex词法分析是给字符做最小粒度的分类,最终,一个vm输 入源码,可以归纳到一个分类里,符合英语语法的字符串,我们统称为英语。
特征都使用全大写字母,这是一种约定,因为在yacc描述中,语法规则名都用小写。%%后面第一行,[^#]*?/"$",这是一个正则表达式,正则分为两个部分,第一部分 [^#]*?匹配所有不是符号#的字符,后面一部分"$",中间反斜杠分割,是一个向后断言,匹配美元符号前面所有不是符号#的字符,也就是遇到没有符号的时候,后面通过 this.begin开始状态mu。这里使用到yytext,就是前面正则所匹配到的内容,有个细节,这个匹配去除了#,因为#是另一种状态Directives的开始,这里暂时只讨论引用识别。最后一行,表示结束返回,这个无需理解。
引用的最基本形式,$ + 字母,美元符号识别了,接下来识别后面的字母,使用正则表达式
<mu>[a-zA-Z][a-zA-Z0-9_]* { return 'ID'; } 如此,我们可以用这两条规则,开始写第一条yacc语法规则了:
reference : DOLLAR ID { $$ = {type: "references", id: $2} } ; 上面描述的是reference,由lex中返回的DOLLAR和ID组合成为一个reference,大括号里面写的是js代码,用于构造结构化数据,需要什么样的数据可以自己随便搞,$$表示返回结果, $1是DOLLAR词对应的字符串,也就是$,$2表示第二个词,也就是ID。复杂的reference可以继续写:
reference : DOLLAR ID | DOLLAR ID attributes ; attributes : attribute | attributes attribute ; attribute : method | index | property ; property : DOT ID ; index : BRACKET literal CLOSE_BRACKET | BRACKET reference CLOSE_BRACKET ; reference在原来的基础下,增加了attributes,attributes是由一个或者多个属性组成,在yacc中,使用attributes attribute来描述多个属性的情况,规则直接包含自身的情况还是非常常见的。attribute由 method,index,property 组成,继续拆分,index是两个中括号加一个literal或者 reference 组成,我们可以继续对literal进行分类,同样的描述。我们回到了上面对vm 语法描述的那个分类过程只不过,现在我们使用yacc的语法描述,前面使用的是自然语言。
解析过程
上面讲了那么多,现在来总结一下Jison解析一个字符串的过程。用一张图表示吧:
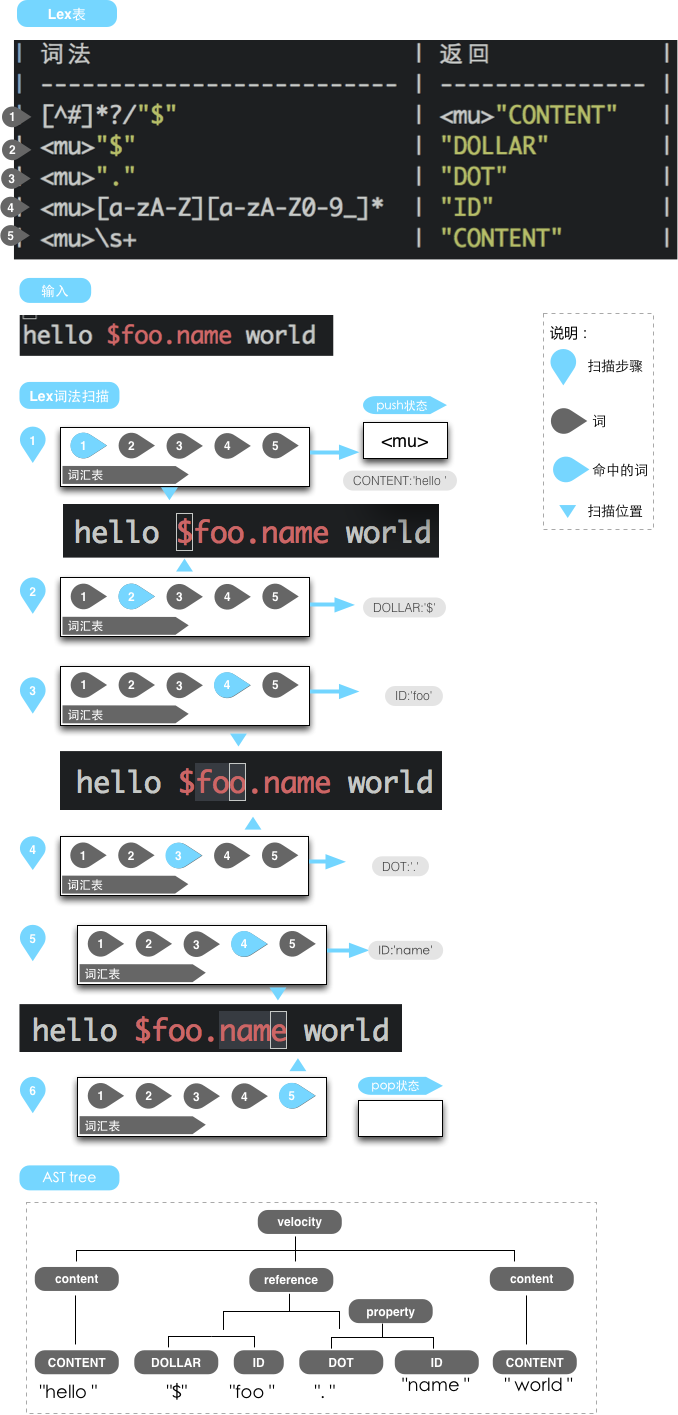
词汇分析过程就是上面所描述的了,一个lex文件,构成一个词汇表,通过从左到右的扫描输入源,依次匹配词汇表里面定义的模式,然后构成一个个词 汇。得到词汇之后,那什么是语法呢,还记得英语语法吗?在计算机里面,语法就是上面所描述的,词汇的组合,规定了词汇的组合形式,比如DOLLAR ID组成一个reference,写yacc语法规则就是不断的对语法进行分类,直到所有的分类最底层都是lex中的词汇,然后语法规则也就ok了。程序会自动根据yacc文件所有定义的规则,分析得到输入源对应的数据结构。
velocity最终的语法描述在这里。
状态码
上面简要描述了yacc和lex工作原理过程,实际中,还是会遇到一些有意思的问题。在写vm解析器的时候,最麻烦的事情是,如何保证括号和中括号的匹配,首先看一段vm字符串:
$foo.bar($foo.name("foo")[1]) $foo.bar([)] 经过分析,我发现括号匹配的一个特点是,括号的闭合状态下,它的前一个状态肯定是括号开始,中括号同样如此。因此,我在velocity.l中再引入两种状态,i, c,分别表示括号开始和中括号开始,在匹配到括号或者中括号结束的时候,判断前面的一个状态是否是符号的开始,这样,就能保证括号和中括号的配对。
在lex词汇分析中,状态码是一个堆栈,这个堆栈通过this.begin开始一个状态,this.popStat退出一个状态,词汇可以是多种状态和正则表达式进行组合,状态的开始和结束,需要自己控制,否则可能会有问题。
解析最终得到一个对象,这个对象的构造是根据velocity.yy而生成的。如何选择合适的数据结构,这个是很很重要的,后面的语法树解释过程, 完全取决于解析器所返回的语法树。在velocity的语法树,最终得到的是一个一维数组,数组的元素分为字符串和对象两种,如果是对象,那么是vm语法 需要进行分析解释的。
语法树解释
得到输入源语法结构之后的工作,相对而言就容易了,这其中会涉及到两个点,我个人觉得比较有意思的。第一个是局部变量,在vm语法中,有一个指令#macro,这个是vm的函数定义,由函数,自然有形参和实参,在函数执行过程中,形参是局部变量,只在函数解析过程中有效,#foreach也会形成一个局部变量,在foreach中有一个内部变量$foreach.index, $foreach.count, $foreach.hasNext这样的局部变量。
局部变量的实现,可以参考lex语法分析过程,在语法树解释过程中,增加一个状态码,当进入一个foreach或者macro的时候,生成一个全局 唯一的条件id,并且在状态中压入当前的条件id,当foreach和macro运行结束后,推出一个状态。foreach和macro控制状态,同时构 造一个数据空间,贮存临时变量,在vm解析过程中,所有的变量查找和设置,都是通过同样的一个函数。当一个变量查询时,检测到存在状态时,首先依次根据状 态码,找到对应状态下的局部变量,如果需要查询的变量在局部环境中找到,那么返回局部对象对应的值,如果是这是值,同样如此。这样的实现和js所中的函数 执行上下文有点类似,可以继续想象一下如何实现避包,实现避包其实只需要在一个函数中返回一个函数,这样的语法在vm中没有,不过如果真的可以返回一个函 数,那么只需要在这个函数和当前函数执行所对应的状态放在一起,并且不释放状态对象的局部变量,那么避包也就有了。
结束
本文到此要结束了,不知道是否有说明白,具体实现细节可以参考velocity.js源码。