
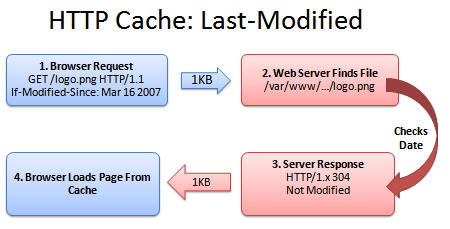
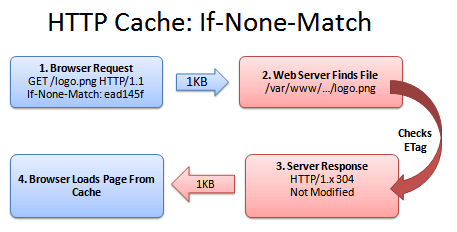
[转载]CSS Sprites – senly – 博客园.
CSS Sprites
CSS Sprites
原理
我们知道,自CSS革命以降,HTML倾向于语义化,在一般情况下不再在标记里写装饰性的内容而是把呈现的任务交给了CSS。GUI是缤纷多彩的, 少不了各种漂亮的图来装点。新时代的生产方式是,在HTML布满各种各样的钩子(hook),然后交由CSS来处理。在需要用到图片的时候,现阶段是通过 CSS属性background-image组合background-repeat, background-position等来实现(题外话:为何我提现阶段,因为未来浏览器若支持content则又新增另外的实现方法)。我们的主角是,你一定猜到了,就是background-position。通过调整background-position的数值,背景图片就能以不同的面貌出现在你眼前。其实图片整体面貌没有变,由于图片位置的改变,你看到只该看到的而已。就好比手表上的日期,你今天看到是21,明天看到是22,是因为它的position往上跳了一格。所以你也大概了解到,CSS Sprites一般只能使用到固定大小的盒子(box)里,这样才能够遮挡住不应该看到的部分。
我们使用YUI的sprite.png举个例子,假如我们有这么一段代码,max代表最大化,min代表最小化,我们需要给它们配上相应的漂亮图片(这样我们的网站才能够吸引人,才可以卖钱,才可以到佛罗里达晒太阳:D):
<div class="max">最大化</div>
<div class="min">最小化</div>这两个class都使用同一个图片:
.min, .max {
width:16px;
height:16px;
background-image:url(http://developer.yahoo.com/yui/build/assets/skins/sam/sprite.png);
background-repeat: no-repeat; /*我们并不想让它平铺*/
text-indent:-999em; /*隐藏文本的一种方法*/
}效果如下:
我们看到一团灰,没错,因为我们还没有指定background-position,默认为 0 0,可以看下sprite.png, 处于这个位置正是灰块。好了,我们要找到代表最大化的加号和代表最小化的减号的位置找出来。经过测量,最大化按钮位于Y轴的350px处,最小化按钮位于 Y轴400px处。想一想我们如何才能让它们能够显示出来呢,明显,要向上提升sprite.png,得到代码如下:
.max {
background-position: 0 -350px;
}
.min {
background-position: 0 -400px;
}耶,我们成功了:
(注意:为了举例的方便,本例子直接在HTML内置样式,切勿在实践中的非特殊情况使用这种方式)。
优点
我们从前面了解到,CSS Sprites为什么突然跑火,跟能够提升网站性能有关。显而易见,这是它的巨大优点之一。普通制作方式下的大量图片,现在合并成一个图片,大大减少了HTTP的连接数。HTTP连接数对网站的加载性能有重要影响。
缺点
至于可维护性,这是一般双刃剑。可能有人喜欢,有人不喜欢,因为每次的图片改动都得往这个图片删除或添加内容,显得稍微繁琐。而且算图片的位置(尤其是这种上千px的图)也是一件颇为不爽的事情。当然,在性能的口号下,这些都是可以克服的。
由于图片的位置需要固定为某个绝对数值,这就失去了诸如center之类的灵活性。
前面我们也提到了,必须限制盒子的大小才能使用CSS Sprites,否则可能会出现出现干扰图片的情况。这就是说,在一些需要非单向的平铺背景和需要网页缩放的情况下,CSS Sprites并不合适。YUI的解决方式是,加大图片之间的距离,这样可以保持有限度的缩放。
总结
性能压倒一切。CSS Sprites是值得推广的一种技术。尤其适宜用于FIR,比如固定大小的icon替换。为保持兼容性,图片中的各个部分保持一定的距离是一种不错的做法。
推荐阅读:
- CSS Sprites: Image Slicing’s Kiss of Death
- 14 Rules for Faster-Loading Web Sites
- High Performance Web Sites
更新:有网友问到IE6不支持png的问题。其实真相是,IE6不支持的是半透明(alpha transparency)的png,对于全透明的png, IE6并不存在问题。因此,在实践中,不涉及到半透明而需要透明背景的图片,其实都可以使用png, 这是很安全的。













{kind=link}
{kind=link}