[转载]SQLite 入门教程(四)增删改查,有讲究 – 左洸 – 博客园.
增删改查操作,其中增删改操作被称为数据操作语言 DML,相对来说简单一点。 查操作相对来说复杂一点,涉及到很多子句,
所以这篇先讲增删改操作,以例子为主,后面再讲查操作。
一、插入数据 INSERT INTO 表(列…) VALUES(值…)
根据前面几篇的内容,我们可以很轻送的创建一个数据表,并向其中插入一些数据,不多说,看例子:
myqiao@ubuntu:~/My Documents/db$ sqlite3 test.db
-- Loading resources from /home/myqiao/.sqliterc
SQLite version 3.7.4
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite> .tables
sqlite>
sqlite> CREATE TABLE Teachers(
...> Id integer PRIMARY KEY,
...> Name text NOT NULL,
...> Age integer CHECK(Age>22),
...> Country text DEFAULT 'USA');
sqlite> .tables
Teachers
sqlite>
sqlite> INSERT INTO Teachers VALUES(1,'Alice',25,'CHN');
sqlite> INSERT INTO Teachers VALUES(2,'Bob',25,'BRA');
sqlite> INSERT INTO Teachers(Id,Name,Age,Country) VALUES(3,'Charls',33,'USA');
sqlite> INSERT INTO Teachers(Name,Age) VALUES('Jhon',43);
sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 CHN
2 Bob 25 BRA
3 Charls 33 USA
4 Jhon 43 USA
sqlite>
很简单,创建了一个 Teachers 表并向其中添加了四条数据,设定了一些约束,其中有自动增加的主键、默认值等等。
二、修改数据 UPDATE 表 SET 列 = ‘新值’ 【WHERE 条件语句】
UPDATE 语句用来更新表中的某个列,如果不设定条件,则所有记录的这一列都被更新; 如果设定了条件,则符合条件的记录的这一列被更新, WHERE 子句被用来设定条件,如下例:
sqlite>
sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 CHN
2 Bob 25 BRA
3 Charls 33 USA
4 Jhon 43 USA
sqlite>
sqlite>
sqlite> UPDATE Teachers SET Country='China';
sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 China
2 Bob 25 China
3 Charls 33 China
4 Jhon 43 China
sqlite>
sqlite>
sqlite> UPDATE Teachers SET Country='America' WHERE Id=3;
sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 China
2 Bob 25 China
3 Charls 33 America
4 Jhon 43 China
sqlite>
sqlite>
sqlite> UPDATE Teachers SET Country='India' WHERE Age<30; sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 India
2 Bob 25 India
3 Charls 33 America
4 Jhon 43 China
sqlite>
三、删除数据 DELETE FROM 表 【WHERE 条件语句】
如果设定 WHERE 条件子句,则删除符合条件的数据记录;如果没有设定条件语句,则删除所有记录
sqlite>
sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 India
2 Bob 25 India
3 Charls 33 America
4 Jhon 43 China
sqlite>
sqlite>
sqlite> DELETE FROM Teachers WHERE Age>30;
sqlite> SELECT * FROM Teachers;
Id Name Age Country
---- --------------- --------------- ---------------
1 Alice 25 India
2 Bob 25 India
sqlite>
sqlite>
sqlite> DELETE FROM Teachers;
sqlite> SELECT * FROM Teachers;
sqlite>
四、查找数据 SELECT 列… FROM 表
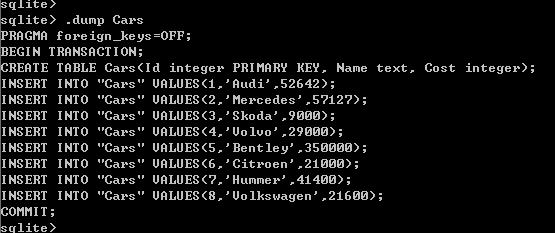
为了后面的练习,需要一些样本数据。 首先将下面的 SQL 语句保存到 data.SQL 文件中
BEGIN TRANSACTION;
CREATE TABLE Cars(Id integer PRIMARY KEY, Name text, Cost integer);
INSERT INTO Cars VALUES(1,'Audi',52642);
INSERT INTO Cars VALUES(2,'Mercedes',57127);
INSERT INTO Cars VALUES(3,'Skoda',9000);
INSERT INTO Cars VALUES(4,'Volvo',29000);
INSERT INTO Cars VALUES(5,'Bentley',350000);
INSERT INTO Cars VALUES(6,'Citroen',21000);
INSERT INTO Cars VALUES(7,'Hummer',41400);
INSERT INTO Cars VALUES(8,'Volkswagen',21600);
COMMIT;
BEGIN TRANSACTION;
CREATE TABLE Orders(Id integer PRIMARY KEY, OrderPrice integer CHECK(OrderPrice>0),
Customer text);
INSERT INTO Orders(OrderPrice, Customer) VALUES(1200, "Williamson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(200, "Robertson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(40, "Robertson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(1640, "Smith");
INSERT INTO Orders(OrderPrice, Customer) VALUES(100, "Robertson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(50, "Williamson");
INSERT INTO Orders(OrderPrice, Customer) VALUES(150, "Smith");
INSERT INTO Orders(OrderPrice, Customer) VALUES(250, "Smith");
INSERT INTO Orders(OrderPrice, Customer) VALUES(840, "Brown");
INSERT INTO Orders(OrderPrice, Customer) VALUES(440, "Black");
INSERT INTO Orders(OrderPrice, Customer) VALUES(20, "Brown");
COMMIT;
然后在在终端执行命令 .read data.SQL,将数据导入到数据库中
sqlite>
sqlite> .tables
Friends
sqlite> .read data.sql
sqlite> .tables
Cars Orders Teachers
sqlite>
可以看到,Cars 表和 Orders 表已经导入到数据库中,现在可以查询了
sqlite>
sqlite> SELECT * FROM Cars;
Id Name Cost
---- --------------- ---------------
1 Audi 52642
2 Mercedes 57127
3 Skoda 9000
4 Volvo 29000
5 Bentley 350000
6 Citroen 21000
7 Hummer 41400
8 Volkswagen 21600
sqlite> SELECT * FROM Orders;
Id OrderPrice Customer
---- --------------- ---------------
1 1200 Williamson
2 200 Robertson
3 40 Robertson
4 1640 Smith
5 100 Robertson
6 50 Williamson
7 150 Smith
8 250 Smith
9 840 Brown
10 440 Black
11 20 Brown
sqlite>
五、 限制返回数量 SELECT 列… FROM 表 LIMIT 数量 OFFSET 位置
有时候数据库中的数据太多,全部返回可不行,可以限制返回的数量,还可以设定返回的起始位置,如下:
sqlite>
sqlite> SELECT * FROM Cars LIMIT 4;
Id Name Cost
---- --------------- ---------------
1 Audi 52642
2 Mercedes 57127
3 Skoda 9000
4 Volvo 29000
sqlite>
sqlite> SELECT * FROM Cars LIMIT 4 OFFSET 2;
Id Name Cost
---- --------------- ---------------
3 Skoda 9000
4 Volvo 29000
5 Bentley 350000
6 Citroen 21000
sqlite>
六、 别名 SELECT 列 AS 别名,列 AS 别名 FROM
我们可以给返回数据集中的某些列起一个比较直观的名字,比如把 Cost 改为”Price Of Car”
sqlite>
sqlite> SELECT Name , Cost AS 'Price Of Car' FROM Cars;
Name Price Of Car
---- ---------------
Audi 52642
Merc 57127
Skod 9000
Volv 29000
Bent 350000
Citr 21000
Humm 41400
Volk 21600
sqlite>
七、 条件查询 SELECT 列 FROM 表 【WHERE 条件语句】
一般的条件语句都是大于、小于、等于之类的,这里有几个特别的条件语句
LIKE
- LIKE 用通配符匹配字符串
- 下划线 _ 匹配一个字符串
- 百分号 % 匹配多个字符串
- LIKE 匹配字符串时不区分大小写
sqlite>
sqlite> SELECT * FROM Cars WHERE Name Like '____';
Id Name Cost
---- --------------- ---------------
1 Audi 52642
sqlite>
sqlite> SELECT * FROM Cars WHERE Name Like '%en';
Id Name Cost
---- --------------- ---------------
6 Citroen 21000
8 Volkswagen 21600
sqlite>
sqlite> SELECT * FROM Cars WHERE Name Like '%EN';
Id Name Cost
---- --------------- ---------------
6 Citroen 21000
8 Volkswagen 21600
sqlite>
GLOB
- GLOB 用通配符匹配字符串
- 下划线 ? 匹配一个字符串
- 百分号 * 匹配多个字符串
- LIKE 匹配字符串时,区分大小写
BETWEEN 值1 AND 值2
返回两个值之间的数据集合。下面的语句查询价格在 20000 到 55000 之间的车,都是好车啊。
sqlite>
sqlite> SELECT * FROM Cars WHERE Cost BETWEEN 20000 AND 55000;
Id Name Cost
---- --------------- ---------------
1 Audi 52642
4 Volvo 29000
6 Citroen 21000
7 Hummer 41400
8 Volkswagen 21600
sqlite>
IN (集合)
对应列的值必须在集合中。下面的语句查找奥迪和悍马的价格。
sqlite>
sqlite> SELECT * FROM Cars WHERE Name IN ('Audi','Hummer');
Id Name Cost
---- --------------- ---------------
1 Audi 52642
7 Hummer 41400
sqlite>
八、 排序 ORDER BY 列 ASC (DESC)
指定某个列进行排序,ASC 为升序,DESC 为降序。下面的语句查询汽车品牌和价格,并以价格排序
sqlite>
sqlite> SELECT Name, Cost FROM Cars ORDER BY Cost DESC;
Name Cost
---- ---------------
Bent 350000
Merc 57127
Audi 52642
Humm 41400
Volv 29000
Volk 21600
Citr 21000
Skod 9000
sqlite>
九、 区分 DISTINCT 列
有一些字段的值可能会出现重复,比如订单表中,一个客户可能会有好几份订单,因此客户的名字会重复出现。
到底有哪些客户下了订单呢?下面的语句将客户名字区分出来。
sqlite>
sqlite> Select * FROM Orders;
Id OrderPrice Customer
---- --------------- ---------------
1 1200 Williamson
2 200 Robertson
3 40 Robertson
4 1640 Smith
5 100 Robertson
6 50 Williamson
7 150 Smith
8 250 Smith
9 840 Brown
10 440 Black
11 20 Brown
sqlite>
sqlite> SELECT DISTINCT Customer FROM ORDERS;
Customer
---------------
Black
Brown
Robertson
Smith
Williamson
sqlite>
十、 分组 GROUP BY 列
分组和前面的区分有一点类似。区分仅仅是为了去掉重复项,而分组是为了对各类不同项进行统计计算。
比如上面的例子,我们区分出 5 个客户,这 5 个客户一共下了 11 个订单,说明很多客户都下了不止一个订单。
下面的语句统计每个客户在订单上总共花费了多少钱。
sqlite>
sqlite> SELECT sum(OrderPrice) AS Total, Customer FROM Orders GROUP BY Customer;
Total Customer
--------------- ---------------
440 Black
860 Brown
340 Robertson
2040 Smith
1250 Williamson
sqlite>
这里 Sum 是 SQLite 内置的统计函数,在这个例子中用来求每个顾客的订单价格的和。
统计结果也可以设定返回条件,但是不能用 WHERE 子句,而是用 HAVING 子句,如下例,返回订单总额大于 1000 的顾客。
sqlite>
sqlite> SELECT sum(OrderPrice) AS Total, Customer FROM Orders
...> GROUP BY Customer HAVING sum(OrderPrice)>1000;
Total Customer
--------------- ---------------
2040 Smith
1250 Williamson
sqlite>
十一、 逻辑运算符
有的查询涉及的条件语句很复杂,是有好几个条件语句经过逻辑运算得来的,一共有三种逻辑运算符:
一般稍微了解点编程知识的应该都没问题。