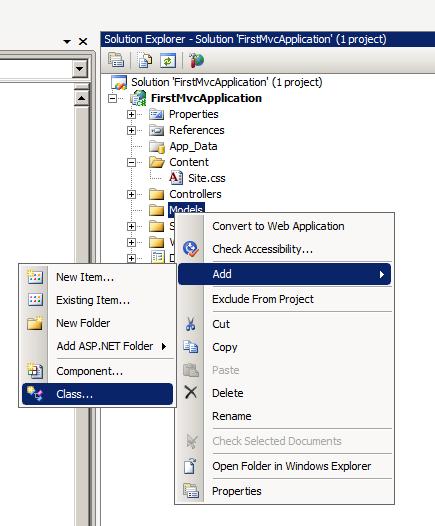
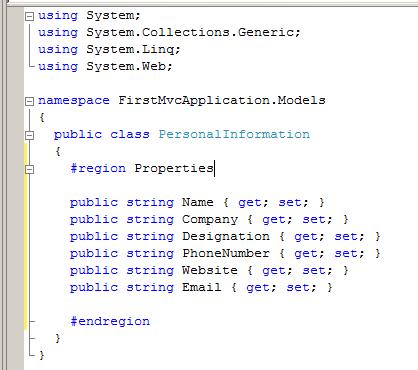
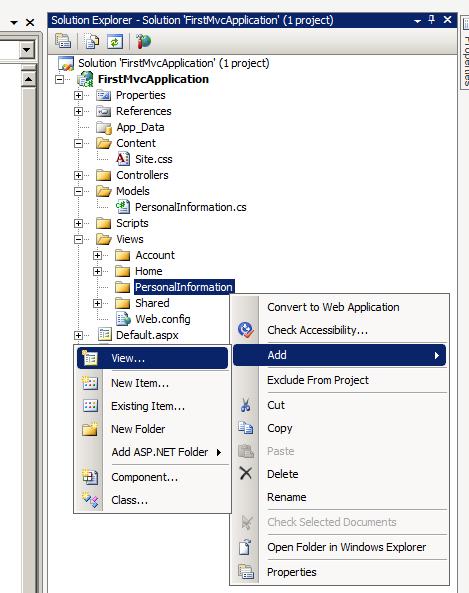
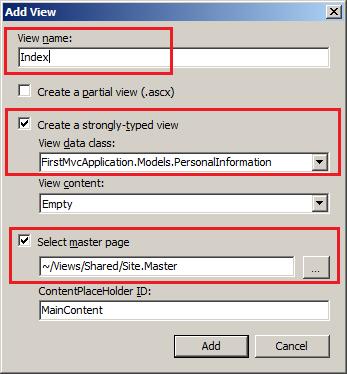
转载:http://www.cnblogs.com/CareySon/archive/2010/01/05/1639825.html
从开发者的角度来看,创建ASP.NET MVC的View是一件很爽的事,因为你可以精确控制最终生成的HTML。具有讽刺意味的是不得不写出每一行HTML代码同时也是ASP.NET MVC的View中让人不爽的地方。让我用我的一个经历来告诉我创建ASP.NET MVC view Helpers背后灵感的由来。由一小部分开发人员(包括我)和一个CSS设计人员(我们叫他Ricky)组成的小组,开始了一个新的ASP.NET MVC的项目,在项目开发过程中;我给页面添加了一些TextBox和一些其他元素,我check-in了我的代码,直到回家我也没再想起过这事。隔夜早 晨,刚上班时我就从CSS设计那里收到一封邮件来通知我我必须按照他的CSS指导方针来写HTML,比如说对于textbox,必须遵循以下规则:
- 每个textbox必须内嵌在li标签中
- 每一个textbox都必须有一个label标签的for属性与之对应
- textbox必须使用input标签并设置type属性为text
对于这些要求我一一照做并修改我的代码符合了后两条规则,但我忘了关于li的 指导方针,我很快更新了页面并提交了我的代码。几天后,项目又推进了很多,Ricky来到我的办公桌前并让我看看我所做的改变。打开页面,他开始一一列举 那些我不遵循它的UI规定的地方,有很多地方我都忽视了因为我甚至不知道这些指导方针的存在.在他指出这些后,我想:一定会有方法可以让我们两个人都如愿 以偿.对于我来说只是需要html标签的id,对于Ricky来说他需要我的HTML符合规范来让他的CSS文件能够选择到合适的html。所以我们引入 了view helper.
在我用ASP.NET MVC时我注意到我自己写了很多纯Html,比如div和span,同时伴随使用了很多System.Web.Mvc.HtmlHelper来生成html,比如说一个输入名字的textbox:
<li>
<label for="FirstName">First name</label>
<%= Html.TextBox("FirstName") %>
<%= Html.ValidationMessage("FirstName", "*") %>
</li>
我就想,是不是能有一种方法来将上面的所有代码融合在一起呢。这样不仅让我编程更加轻松,而且再也不用担心Ricky给我设置的条条框框了。理想的情况下会满足以下标准:
- 容易执行
- 重用性好
- 强制执行某些标准(比如Ricky的)
- 和标准的HtmlHelper扩展方法用起来没太大区别
- 容易使用
在我们进入执行这个的细节之前如果你感觉这听起来像又回到了Web Form时代,那就错了。view helper仅仅是在创建HTML的时候起辅助作用,而不是将HTML进行抽象。我关心的只是HTML在页面中的显示效果以及使用JavaScript的 行为更轻松.而不是textbox是否放入li中,当我需要创建一个textbox时,我只需在view中放入如下代码:
<% Html.NewText("FirstName", "First name"); %>
我想声明我仅仅是想将创建HTML延迟到另一个类中。使用View helper我可以轻松做到这一点。首先我们先来看标准的HtmlHelper扩展方法如何做到这一点.
Html helper有两种实现用法,大多数的使用方法都会如下:
<%= Html.TextBox("FirstName") %>
而还有一种用法和声明一个form元素很相似:
<% using (Html.BeginForm()) { %>
<!-- Other elements here-->
<% } %>
上面两种方法的主要区别是Html.TextBox仅仅返回一个string来注入到view中。这也是为什么使用<%=而不是标准的的代码块。而另一种以对象作为返回类型的方法更老练许多,比如,System.Web.Mvc.Html.MvcForm, 这个对象放入using语句.对象被创建时一些HTML就会被注入到view中(严格说:并不是对象创建时,但很接近)还有一些事在对象被回收时将 html注入view(也就是碰到”}”符号时).使用这种方法的好处是可以在using语句之间插入代码。这使它的能力无疑比那些仅仅返回一个字符串注 入页面的方式要强大许多。
所以,我选择第二种方法来实现我的View Helpers.所以HtmlHelper扩展方法会集成IViewObject接口并返回我创建的对象。类图如下:

可以看到,IViewObject实现了System.IDisposable接口。这使实现如前面所提到和Html.BeginForm的使用方法类似所必须的。IViewObject有两个方法,StartView和EndView.这两个方法分别在对象创建时和对象回收时被调用.为了让这些对象的创建更加容易我创建了一个抽象类来处理:执行方法,回收对象和在合适的时候调用EndView方法。类图如下:

上图中的抽象类完整代码如下:
public abstract class AbstractHtmlViewObject : IViewObject
{
private bool mDisposed;
public AbstractHtmlViewObject(ViewRequestContext requestContext, string name)
{
if (requestContext == null)
{ throw new ArgumentNullException("requestContext"); }
ViewRequestContext = requestContext;
Name = name;
}
public IViewRequestContext RequestContext
{
get;
protected set;
}
#region IViewObject Members
public object Attributes { get; set; }
public string Name { get; set; }
public abstract void StartView();
public abstract void EndView();
#endregion
// based on System.Web.Mvc.HtmlHelper.GetModelStateValue
public object GetModelStateValue(string key, Type destinationType)
{
object result = null;
ModelState modelState;
if (ViewRequestContext.HtmlHelper.ViewData.ModelState.TryGetValue(
key, out modelState))
{
result = modelState.Value.ConvertTo(destinationType, null);
}
return result;
}
#region IDisposable Members
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (!mDisposed)
{
mDisposed = true;
EndView();
}
}
#endregion
}
如你所见上面AbstractHtmlViewObject对象不仅满足了最上面提到的列表(Ricky那段里),还包含了一些辅助类更容易扩展的东西。 也就是它包含的一个属性:RequestContext,这个属性可以帮助我们很容易创建HTML和扩展方法GetModelStateValue,我们 会在后面详细讲述GetModelStateValue的使用方法。我们会在后面讲述RequestContext的细节,这里我们先看看如何创建我们先 前讨论的那个textbox。
我们已经知道需要创建的textbox有一个文本值与之对应:
- 文本值在label标签中
- 可选的值放在Textbox中
- 可选的验证信息(validation message)
如果上面3个条件都能满足,肯定也能满足我们在part1里的那5个条件.还有一些锦上添花的是可以通过属性来指定textbox是否包裹在li标签内以 及textbox是否是readonly模式.这样我们便能更好的在view page中代码复用。下面的代码包含所有HtmlText(译者按:继承AbstractHtmlViewObject对象,在part1的类图中)对象所有的属性:
private readonly string mLabelText;
private readonly bool mCreateLabel;
private readonly object mValue;
private readonly string mValidationMessage;
private readonly bool mCreateValidationMessage;
private readonly bool mCreateLi;
private readonly bool mReadonly;
public HtmlText(
ViewRequestContext requestContext, string name, string labelText, objec
string validationMessage, bool @readonly, bool createLi, object attribu
: base(requestContext, name)
{
mLabelText = labelText;
mCreateLabel = !string.IsNullOrEmpty(mLabelText);
mValidationMessage = validationMessage;
mCreateValidationMessage = !string.IsNullOrEmpty(validationMessage);
mCreateLi = createLi;
mReadonly = @readonly;
Attributes = attributes;
object valueToAssign = value;
if (valueToAssign == null)
{
// see if the ModelState has a value for this
valueToAssign = GetModelStateValue(name, typeof(string));
}
mValue = valueToAssign;
}
在构造函数中,我们我们存入一系列私有变量中并初始化了会在StartView方法内使用的一个bool类型,除此之外你可以发现这里开始使用 GetModelStateValue方法.目前为止我们先不过多讨论这个方法,这个方法会在后面提到。在参数传入构造器之前我们注意到:
- value参数的类型是object
- object类型的attributes参数被传入
之所以把Value参数定义为object类型是因为这样可以使用户更容易使用并且和ASP.Net MVC Helpers的执行方式保持一致。attributes参数可以被调用者来扩展生成的HTML。比如说,你想将textbox的maxlength属性设置为5,你只需要传入匿名类型”new {maxlength=5}“.input标签会将这个匿名类型转换为HTML属性maxlength=5.这同时也符合Asp.net MVC中HTML Helper现有扩展方法的使用方式.每一个View helper对象都应该支持这种行为以便具有更大的灵活性.在这个类中剩下的两个方法就是从父类继承来的StartView和EndView方法了.
StartView和EndView的定义如下:
public override void StartView()
{
HttpResponseBase httpResponse = RequestContext.HttpResponse;
TagBuilder htmlLiTagBuilder = new TagBuilder("li");
if (mCreateLi)
{
httpResponse.Write(htmlLiTagBuilder.ToString(TagRenderMode.StartTag));
}
// write out label if provided
if (mCreateLabel)
{
TagBuilder labelTag = new TagBuilder("label");
labelTag.Attributes.Add("for", Name);
labelTag.SetInnerText(mLabelText);
httpResponse.Write(labelTag.ToString(TagRenderMode.Normal));
}
string stringValue = string.Empty;
if (this.mValue != null)
{
stringValue = Convert.ToString(this.mValue, CultureInfo.CurrentCulture);
}
if (this.mReadonly)
{
TagBuilder textTag = new TagBuilder("span");
textTag.AddCssClass("readonly-text");
textTag.SetInnerText(
Convert.ToString(this.mValue, CultureInfo.CurrentCulture));
httpResponse.Write(textTag.ToString(TagRenderMode.Normal));
}
else
{
// Use MVC helpers to create the actual text box
httpResponse.Write(RequestContext.HtmlHelper.TextBox(
Name, this.mValue, Attributes));
}
if (this.mCreateLi)
{
httpResponse.Write(htmlLiTagBuilder.ToString(TagRenderMode.EndTag));
}
}
public override void EndView()
{
// Not needed for this element
}
在StartView方法中有很多值得注意的地方,让我们逐个讨论。首先是我们使用System.Web.Mvc.TagBuilder来生成HTML, 而不是直接写HTML标签。TagBuilder只能在Asp.net MVC中使用并且我推荐在生成HTML中必须使用TagBuilder而不是直接写HTML标签,下面是TagBuilder的类图:

下表是TagBuilder中一些方法的说明:
| 名称 |
描述 |
| AddCssClass |
加入css的class名称,如果class已经存在,则后来加入的会和原来的class一起生效 |
| MergeAttribute |
这个方法用于添加或者更新tag的属性,这个方法有一个接受replaceExisting参数的重载,默认情况下已经定义的属性不会被重载。 |
| MergeAttributes |
同上,只是可以在一个方法内添加或更新所有属性. |
| SetInnerText |
设置标签内的文本 |
| ToString |
被重载。用于生成相应的html代码,TagRenderMode枚举类型会控制如何生成HTML标签. |
在上面表格的ToString那行,TagRenderMode枚举用于控制TagBuilder生成HTML标签的方式,TagRenderModel如下所示:
| TagRenderModel |
结果示例 |
| Normal |
<div name=”Sample01”>Some content here</div> |
| StartTag |
<div name=”Sample01”> |
| EndTag |
</div> |
| SelfClosing |
<div name=”Sample01” /> |
| |
|
根据你想创建的HTML标签和你如何使用它,你会发现使用TagRenderModel可以创建出任何你想创建出的HTML.在前面提到的StartView方法内你会发现TagRenderModel被依据不同的条件设置成StartTag,Normal和EndTag等不同的的类型.如果你给InnerHTML属性赋值并用StartTag和EndTag生成它你必须要记住InnerHtml不会被自动生成,你还必须显式的使用InnerHtml属性本身。下面我们来讨论如何创建HtmlHelper扩展方法。
在前面我们说到了创建HtmlText类的方方面面。包括为HtmlText创建的扩展方法.这些扩展方法包括直接被View调用的那些扩展方法。下面代码展示了HtmlText的几种不同的构造函数:
public static class HtmlHelperExtensions
{
#region Textbox
public static IViewObject NewText(
this HtmlHelper htmlHelper, string name)
{
return NewText(htmlHelper, name, null);
}
public static IViewObject NewText(
this HtmlHelper htmlHelper, string name, string labelText)
{
return NewText(htmlHelper, name, labelText, null);
}
public static IViewObject NewText(
this HtmlHelper htmlHelper, string name, string labelText, object value)
{
return NewText(htmlHelper, name, labelText, value, null, false, true, null);
}
public static IViewObject NewText(
this HtmlHelper htmlHelper, string name, string labelText, object value,
string validationMessage, bool @readonly, bool createLi, object attributes)
{
IViewObject viewObject = new HtmlText(
new ViewRequestContext(htmlHelper), name, labelText, value,
validationMessage, @readonly, createLi, attributes);
viewObject.StartView();
return viewObject;
}
#endregion
//NOTE: SOME CONTENT OMITTED FROM THIS SNIPPET
}
NewText方法有四个不同版本的重载,这些重载都属于 System.Web.Mvc.HtmlHelper的扩展方法,只有最后一个方法用于真正的起作用,而其他的方法都是这个方法的封装以便让用户使用起来 更简单.上面的代码中HtmlText对象通过传入适当的参数来初始化,而view是通过StartView方法来初始化,在StartView中被调用 的HtmlText会返回合适的对象动态的将Html注入View.现在让我们来看看如何在view中使用这些方法。
前面我们已经创建了在View中可使用的HtmlText对象,现在就可以使用了。在前面我们提到,如果想要创建一个textbox来满足Ricky的标准,我必须写如下代码:
<li>
<label for="FirstName">First name</label>
<%= Html.TextBox("FirstName") %>
<%= Html.ValidationMessage("FirstName", "*") %>
</li>
现在通过使用HtmlHelper,我们可以把代码简化如下:
<% Html.NewText("FirstName", "First name"); %>
上面两种方法所生成的Html是完全相同的,我们实现了前面设定的目标。从今往后就可以使用这个Helper来简化Asp.net MVC view的开发了。上面代码中并没有用到EndView方法.下面我们来研究一个更复杂一些的HTML的构造—radio button,看是如何实现的
使用Asp.net MVC来创建一组radio button,代码一般如下:
<li>
<div class="option-group" id="GenderContainer">
<label for="Gender">Gender</label>
<% foreach (SelectListItem item in Model.GenderList)
{ %>
<%= Html.RadioButton(item.Text, item.Value)%>
<span><%= item.Text%></span>
<% } %>
</div>
</li>
上面代码是从AddContactClass.aspx view中节选的,所有代码可以从这篇文章的网站下载,上面代码中ContactController通过Model.GenderList属性来集中返回代码:
public ActionResult AddContactClassic()
{
AddContactModel addModel = InternalGetInitialAddModel();
return View(addModel);
}
private AddContactModel InternalGetInitialAddModel()
{
string maleString = Gender.Male.ToString();
string femaleString = Gender.Female.ToString();
IList<SelectListItem> genderRadioButtons = new List<SelectListItem>()
{
new SelectListItem { Text = maleString, Value = maleString },
new SelectListItem { Text = femaleString, Value = femaleString }
};
AddContactModel model = new AddContactModel { GenderList = genderRadioButtons };
return model;
}
生成的HTML效果图如下:

在上面创建radio button的代码中有很多掩盖了元素真实意图(译者按:比如说为什么我们这么写HTML,是为了满足Ricky的标准吗?)的部分,比如说:外层的 div和内层的span是为了label而包裹文本.而如果我们需要一组radio button时只需要声明一下并指定相关的值那不是更爽吗?下面我们创建HtmlRadioButtonGroup view helper,它可以满足我们只声明并指定相关值就能创建出相应的html,使用HtmlRadioButtonGroup,我们可以将前面的radio button精简如下:
<% Html.NewRadioButtonGroup("Gender", Model.GenderList); %>
上面代码中,我们可以从更高的视角来创建Html,清楚的这段代码的作用而不是关注Html的细节。下面来创建一个替我们生成HTML的helper,也就是为:HtmlRadioButtonGroup类,下面代码展示了这个类唯一的构造函数和它的字段:
private readonly List<SelectListItem> mSelectList;
private readonly bool mCreateLi;
public HtmlRadioButtonGroup(
ViewRequestContext requestContext, string name,
IEnumerable<SelectListItem> selectList, bool createLi, object attributes)
: base(requestContext, name)
{
mSelectList = new List<SelectListItem>();
if (selectList != null)
{
mSelectList.AddRange(selectList);
}
mCreateLi = createLi;
Attributes = attributes;
}
看上去是不是和我们先前的HtmlText对象的构造器很像?它的构造函数为通过传参的方式将RequestContext变得可用。并且通过构造 函数为所有的字段进行初始化,这也意味着这个类是在StartView方法中(译者按:因为RequestContext方法在StartView中可以 传入)的,下面代码是StartView的完全版本:
public override void StartView()
{
HttpResponseBase httpResponse = RequestContext.HttpResponse;
TagBuilder liTagBuilder = new TagBuilder("li");
if (mCreateLi)
{
httpResponse.Write(liTagBuilder.ToString(TagRenderMode.StartTag));
}
TagBuilder divTag = new TagBuilder("div");
divTag.AddCssClass("option-group");
divTag.MergeAttribute("name", Name);
if (Attributes != null)
{
divTag.MergeAttributes(new RouteValueDictionary(Attributes));
}
TagBuilder labelTag = new TagBuilder("label");
labelTag.MergeAttribute("for", Name);
labelTag.SetInnerText(Name);
httpResponse.Write(labelTag.ToString(TagRenderMode.Normal));
httpResponse.Write(divTag.ToString(TagRenderMode.StartTag));
// Write out the radio buttons, let the MVC Helper do the hard work here
foreach (SelectListItem item in this.mSelectList)
{
string text = !string.IsNullOrEmpty(item.Text)
? item.Text
: item.Value;
httpResponse.Write(RequestContext.HtmlHelper.RadioButton(
Name, item.Value, item.Selected));
// Note: Because we are using HtmlHelper.RadioButton the <input>
// elements will have duplicate ids
// See: http://forums.asp.net/t/1363177.aspx
// In order to avoid this we could do this ourselves here
TagBuilder spanTag = new TagBuilder("span");
spanTag.SetInnerText(text);
httpResponse.Write(spanTag.ToString(TagRenderMode.Normal));
}
httpResponse.Write(divTag.ToString(TagRenderMode.EndTag));
if (this.mCreateLi)
{
httpResponse.Write(liTagBuilder.ToString(TagRenderMode.EndTag));
}
}
这里的想法和HtmlText类如初一撤,那就是:所有的HTML代码都在StartView方法中生成。因此这里StartView方法创建了一 些HTML tag,并遍历mSelectList中的元素并通过Asp.net MVC自带的RadioButton扩展方法为每一个元素生成一个RadioButton。在重用这些方法时最好先重写这些方法(译者按:看上面代码注 释)。
从上面代码中的注释可以看出,使用HtmlHelper.RadioButton扩展方法有一个明显的bug,就是id和name用的是同一个值, 这里因为name属性本来就应该为RadioButton设置成相同的这样他们便可以逻辑上连成一组,但是id属性是每个元素唯一拥有,这里解决这个 bug的方法是不用这个方法,但在这里为了简单起见我们先使用这个方法.上面创建的两个Html helper对象都没有用到EndView方法,你可以已经开怀疑这个方法为什么存在,在接下来的HtmlFieldSet的Helper我会给你展示 EndView的用途
接上文..前面我们已经创建好了HtmlFieldSet,现在,为了让HtmlHelper的扩展方法可以使用这个类,还需要创建一个方法:NewHtmlFieldSet
public static IViewObject NewHtmlFieldSet(
this HtmlHelper htmlhelper, string name, string title, object attributes)
{
IViewObject viewObject = new HtmlFieldSet(
new ViewRequestContext(htmlhelper), name, title, attributes);
viewObject.StartView();
return viewObject;
}
这个方法的实现和前面所提到的那些没有上面不同,都是传入相应参数并返回view object,在View被初始化时返回这个对象,View首先在初始化时使用返回的View object,更确切点说,返回的IViewObject会在using语句中被view使用,例子如下:
<% using (Html.NewHtmlFieldset("FieldsetName", "My Fieldset", null))
{ %>
<li>
<label for="FirstName">FirstName</label>
<span id="FirstName"><%= Html.Encode(Model.FirstName) %></span>
</li>
<% } %>
对应生成的HTML代码如下:
<fieldset name="FieldsetName">
<legend>My Fieldset</legend>
<ol>
<li>
<label for="FirstName">FirstName</label>
<span id="FirstName">Sayed</span>
</li>
</ol>
</fieldset>
EndView方法输出了最后的三个结尾标签(</li>,</ol>,</fieldset>),达到了我 们的预期,现在就可以使用view helper来创建fieldset以及包含在内的legend,以便达到更好的可理解和可维护性。下面来看view helper是如何简化view的开发的。
这篇文章中附带的示例代码时全功能版本,每一个页面都有两个版本-使用view helper和不使用view helper.不适用view helper的版本全部手动创建HTML,而使用view helper的版本包括了我们先前创建的3个view helper,让我们来进行简单的比较,从源码中找到AddContactClassic.aspx
<%@ Page Title="" Language="C#" MasterPageFile="~/Views/Shared/Site.Master"
Inherits="System.Web.Mvc.ViewPage<Sedodream.Web.ViewHelper.Models.AddContactModel>"
%>
<%@ Import Namespace="Sedodream.Web.Common.Contact" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent" runat="server">
Add Contact Classic
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent" runat="server">
<h2>Add Contact Classic</h2>
<%= Html.ValidationSummary("Errors exist") %>
<ol> <li>
<span class="success-message"><%= ViewData["SuccessMessage"]%></span>
</li>
</ol>
<% using (Html.BeginForm())
{ %>
<fieldset>
<legend>Account Information</legend>
<ol>
<li>
<label for="FirstName">First name</label>
<%= Html.TextBox("FirstName") %>
<%= Html.ValidationMessage("FirstName", "*") %>
</li>
<li>
<label for="LastName">Last name</label>
<%= Html.TextBox("LastName") %>
<%= Html.ValidationMessage("LastName", "*") %>
</li>
<li>
<label for="Email">Email</label>
<%= Html.TextBox("Email")%>
<%= Html.ValidationMessage("Email", "*")%>
</li>
<li>
<label for="Phone">Phone</label>
<%= Html.TextBox("Phone")%>
<%= Html.ValidationMessage("Phone", "*")%>
</li>
<li>
<div class="option-group" id="GenderContainer">
<label for="Gender">Gender</label>
<% foreach (SelectListItem item in Model.GenderList)
{ %>
<%= Html.RadioButton(item.Text, item.Value)%>
<span><%= item.Text%></span>
<% } %>
</div>
</li>
<li>
<input type="submit" value="Add contact" />
</li>
</ol>
</fieldset>
<% } %>
</asp:Content>
上面代码尽管简单,但仍然包含多达59行代码,而且看起来十分丑陋,下面的版本是使用我们自定义的view helper,让我们来看看包含在AddContactNew.aspx内的新版本:
<%@ Page
Inherits="System.Web.Mvc.ViewPage<Sedodream.Web.ViewHelper.Models.AddContactModel>"
Language="C#" MasterPageFile="~/Views/Shared/Site.Master" Title="" %>
<%@ Import Namespace="Sedodream.Web.Common.View" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent" runat="server">
Add Contact New
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent" runat="server">
<h2>Add Contact New</h2>
<%= Html.ValidationSummary("Errors exist") %>
<ol>
<li>
<span class="success-message"><%= Model.SuccessMessage %></span>
</li>
</ol>
<% using (Html.BeginForm())
{ %>
<fieldset>
<legend>Account Information</legend>
<ol>
<% Html.NewText("FirstName", "First name"); %>
<% Html.NewText("LastName", "Last name"); %>
<% Html.NewText("Email", "Email"); %>
<% Html.NewText("Phone", "Phone"); %>
<% Html.NewRadioButtonGroup("Gender", Model.GenderList); %>
<li>
<input type="submit" value="Add contact" />
</li>
</ol>
</fieldset>
<% } %>
</asp:Content>
使用view helper的版本html大大减少(只有39行)而且更容易理解,这里需要注意view引入了Sedodream.Web.Common.View命名 空间,这使view helper扩展方法所必须的.Sedodream.Web.Common.View命名空间包含在另一个程序集中,这样更方便你在整个小组内进行分发, 使用View helper所带来的可理解性只是使用它所带来好处的其中之一,它还会带来以下好处:
- View更清爽,更容易理解
- 小组内遵循某些标准更容易
- 在修改时需要改变的地方更少
- 可利用回传的model state辅助生成代码
在前面我们提到了GetModelStateValue方法的使用。这个方法用于给HTML元素赋上它自己从View里回传的值,而在view helper内可以给生成的html元素赋值.下面代码片段是System.Web.Mvc.Html.InputExtensions源文件中的一部 分,这里用来展示GetModelStateValue的用法:
case InputType.Radio:
if (!usedModelState) {
string modelStateValue = htmlHelper.GetModelStateValue(
name, typeof(string)) as string;
if (modelStateValue != null) {
isChecked = String.Equals(
modelStateValue, valueParameter, StringComparison.Ordinal);
usedModelState = true;
}
}
上面代码先检查model state来看radio button是否被创建,如果radio button已经存在就可以查看radio button是否已经被选中,当你创建自定义view helper时,你最好也在合适的地方支持类似(可以获取当前html的元素)的功能。前面的HtmlText view helper已经说明了这一点。
文章到此已经将创建自定义view helper的方方面面都讲到了。
原文链接:http://mvcviewhelpers.codeplex.com/
translated by CareySon