转载:http://www.codeproject.com/KB/aspnet/memcached_aspnet.aspx
Introduction
Currently I am working on a web-based project that will be hosted in a web farm. Among the several issues, we faced the issue of having a distributed cache. As we know the current cache in ASP.NET is an in-process cache and can't be used in a web farm. After doing some research found a few solutions on the web but at the end all of them had scalability issues. We found a few third party implementations but they were quite expensive. Then I came across memcahced implemented by Danga Interactive. This is a high performance distributed memory cache initially implemented for http://www.LiveJournal.com. The original implementation runs on *nix system. Luckily there is win32 port available at http://jehiah.cz/projects/memcached-win32/ for those who want to run it in a windows environment. For more detail on the working of Memcached, please read the following article http://www.linuxjournal.com/article/7451.
There is a C# client for memcached available and can be downloaded from the following location https://sourceforge.net/projects/memcacheddotnet/. For coding this provider, I have used the clientlib 1.1.5.
Using the code
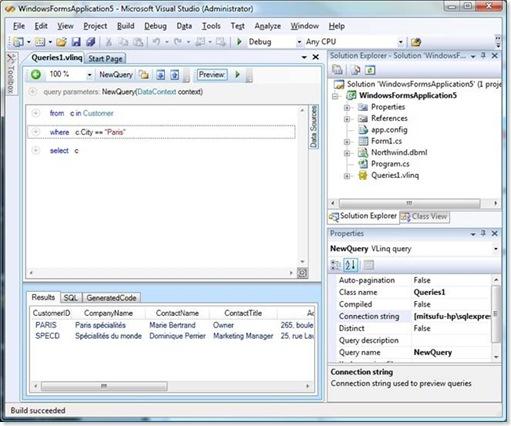
Following is the interface for the Cached Provider.
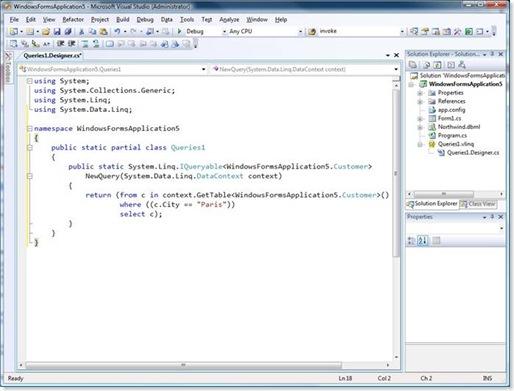
public abstract class CacheProvider : ProviderBase
{
// Currently returns -1 as this property is not implemented
public abstract long Count { get;}
// Returns the server names with port in the memcached cluster
public abstract string[] Servers { get;}
// Default expiration time in milli seconds
public abstract long DefaultExpireTime { get;set;}
// Adds object to the cache for the max amount of time
public abstract bool Add(string strKey, object objValue);
// Adds object to the cache for Default Expire time if bDefaultExpire
// is set to true otherwise for max amount of time
public abstract bool Add(string strKey, object objValue,bool bDefaultExpire);
// Add objects for specified about of time. Time is specified in milli seconds
public abstract bool Add(string strKey, object objValue, long lNumofMilliSeconds);
// Return the object from memcached based on the key otherwise
// just returns null
public abstract object Get(string strKey);
// Clears everything from the cache on all servers
public abstract bool RemoveAll();
// Removes the an object from cache
public abstract object Remove(string strKey);
// Release resources and performs clean up
public abstract void Shutdown();
// Checks if the key exists in memory
public abstract bool KeyExists(string strKey);
// Return all servers stats
public abstract Hashtable GetStats();
}
Following is how to configure Cache Provider in a web.config or app.config file
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
<section name="cacheProvider" type="CacheProvider.CacheProviderSection, CacheProvider"
allowDefinition="MachineToApplication" restartOnExternalChanges="true"/>
</configSections>
<cacheProvider defaultProvider="MemcachedCacheProvider">
<providers>
<add name="MemcachedCacheProvider" type="CacheProvider.MemcachedCacheProvider,CacheProvider"
servers="127.0.0.1:11211" socketConnectTimeout="1000" socketTimeout="1000"/>
<!�To add more servers use comma to separate servernames and ports
eg. servers="127.0.0.1:11211,192.168.0.111:11211"
-->
</providers>
</cacheProvider>
</configuration>
Following parameters can be specified for initializing the cache provider
socketConnectTimeout� Timeout for Socket connection with memcached serverssocketTimeout� Timeout for Socket read-write operationsdefaultExpireTime� Default expire time in milliseconds
To use Cache Provider in a project add a reference to the CacheProvider.dll and access the methods using DistCache static class. When creating keys for storing data, avoid using spaces in keys e.g. "My Key". This is an issue with C# memcached client. To close the provider gracefully please add a call to DistCache.Shutdown() in Global.asax file's Application_End event.
Update Dec 24, 2007
To report any issues and enhancements please go to the following link http://www.codeplex.com/memcachedproviders. I have started working on the Session State Provider for Memcached. I will be releasing it very soon on codeplex.com.
Update Dec 31, 2007I have released Session State Provider for memcached. Please go to the following link to download
http://www.codeplex.com/memcachedproviders
References
- http://www.danga.com/memcached/
- http://jehiah.cz/projects/memcached-win32/
- https://sourceforge.net/project/showfiles.php?group_id=152153
- Sample Project Provider by Memcached C# client 1.1.5
- http://www.infoq.com/news/2007/07/memcached
- http://msdn2.microsoft.com/en-US/library/aa479038.aspx
- http://www.linuxjournal.com/article/7451
License
This article, along with any associated source code and files, is licensed under The Apache License, Version 2.0
About the Author
| Fahad Azeem Member |
My name is Fahad Azeem. I am interested in distributed software development. Currently I am working for a software consulting company in Chicago which developes software in .NET platform. My Blog: http://fahadaz.blogspot.com
|
 United States
United States






 本地免费下载
本地免费下载




 }
}