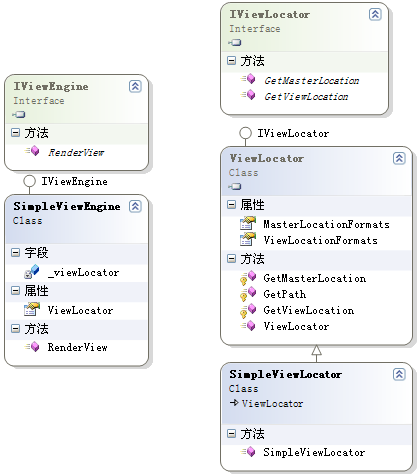
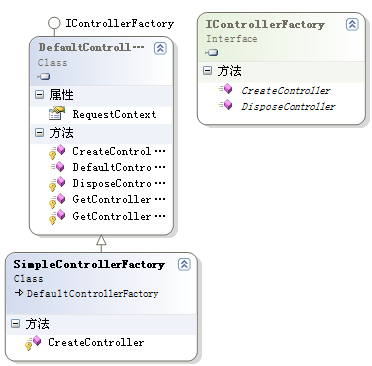
Have you ever seen a presentation of ScottGu about the ASP.NET MVC framework? There is one particular slide that keeps coming back, stating that every step in the ASP.NET MVC life cycle is pluggable. Let's find out if replacing one of these components is actually easy by creating a custom ViewEngine and corresponding view.
Some background
After a route has been determined by the route handler, a Controller is fired up. This Controller sets ViewData, which is afterwards passed into the ViewEngine. In short, the ViewEngine processes the view and provides the view with ViewData from the Controller. Here's the base class:
By default, the ASP.NET MVC framework has a ViewEngine named WebFormsViewEngine. As the name implies, this WebFormsViewEngine is used to render a view which is created using ASP.NET web forms.
The MvcContrib project contains some other ViewEngine implementations like NVelocity, Brail, NHaml, XSLT, …
What we are going to build…
In this blog post, we'll build a custom ViewEngine which will render a page like you see on the right from a view with the following syntax:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns=""http://www.w3.org/1999/xhtml"">http://www.w3.org/1999/xhtml" >
<head>
<title>Custom ViewEngine Demo</title>
</head>
<body>
<h1>{$ViewData.Title}</h1>
<p>{$ViewData.Message}</p>
<p>The following fruit is part of a string array: {$ViewData.FruitStrings[1]}</p>
<p>The following fruit is part of an object array: {$ViewData.FruitObjects[1].Name}</p>
<p>Here's an undefined variable: {$UNDEFINED}</p>
</body>
</html>
Remove /Content/*.* (unless you want to keep the default CSS files)
Add a folder /Code
In order to create a ViewEngine, we will have to do the following:
Create a default IControllerFactory which sets the ViewEngine we will create on each Controller
Edit Global.asax.cs and register the default controller factory
Create a ViewLocator (this one will map a controller + action to a specific file name that contains the view to be rendered)
Create a ViewEngine (the actual purpose of this blog post)
Let's do some coding!
1. Creating and registering the IControllerFactory implementation
Of course, ASP.NET MVC has a default factory which creates a Controller instance for each incoming request. This factory takes care of dependency injection, including Controller initialization and the assignment of a ViewEngine. Since this is a good point of entry to plug our own ViewEngine in, we'll create an inherited version of the DefaultControllerFactory:
publicclass SimpleControllerFactory : DefaultControllerFactory
{ protectedoverride IController CreateController(RequestContext requestContext, string controllerName)
{
Controller controller = (Controller)base.CreateController(requestContext, controllerName);
controller.ViewEngine = new SimpleViewEngine(); // <– will be implemented later in this post return controller;
}
}
In order to make this SimpleControllerFactory the default factory, edit the Global.asax.cs file and add the following line of code in the Application_Start event:
Note that we first locate the view using the ViewLocator, map it to a real path on the server and then render contents directly to the HTTP response. The PrintRenderer class maps {$….} strings in the view to a real variable from ViewData. If you want to see the implementation, please check the download of this example.
Conclusion
Replacing the default ViewEngine with a custom made version is actually quite easy! The most difficult part in creating your own ViewEngine implementation will probably be the parsing of your view. Fortunately, there are some examples around which may be a good source of inspiration (see MvcContrib).
If someone wants to use the code snippets I posted to create their own PHP Smarty, please let me know! Smarty is actually quite handy, and might also be useful in ASP.NET MVC.
And yes, it has been a lot of reading, but I did not forget. Download the example code from this blog post: CustomViewEngine.zip (213.17 kb)
ASP.NET MVC为我们提供了一个默认的视图引擎,这个视图引擎叫做:WebFormsViewEngine. 从名字就可以看出,这个视图引擎是使用ASP.NET web forms来呈现的。在这里,我们要实现的视图引擎所使用的模板用HTML文件吧,简单的模板示例代码如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><htmlxmlns=""http://www.w3.org/1999/xhtml"">http://www.w3.org/1999/xhtml" >
<head><title>自定义视图引擎示例</title></head><body><h1>{$ViewData.Title}</h1><p>{$ViewData.Message}</p><p>The following fruit is part of a string array: {$ViewData.FruitStrings[1]}</p><p>The following fruit is part of an object array: {$ViewData.FruitObjects[1].Name}</p><p>Here's an undefined variable: {$UNDEFINED}</p></body></html>
注3:不过,如果程序中多次复用单个NativeOverlapped对象的话,这个方法的性能会略微好于 QueueUserWorkItem,据说WCF中便使用了这种方式——微软内部总有那么些技巧是我们不知如何使用的,例如老赵记得之前查看 ASP.NET AJAX源代码的时候,在MSDN中不小心发现一个接口描述大意是“预留方法,请不要在外部使用”。对此,我们又能有什么办法呢?
A LRU Cache is a key-value based data container that is constrained by size and/or age, removing the least recently used objects first. This algorithm requires keeping track of the most recent time each object is accessed, which can be expensive to ensure the algorithm always discards the least recently used item.
Other LRU Algorithms
Most LRU Caching algorithms consist of two parts: a dictionary and a list. The dictionary guarantees quick access to your data, and the list, ordered by age of the objects, controls the lifespan of objects and determines which objects are to be removed first.
A simple LRU Cache implementation uses a doubly linked list; adding new items to the head, removing items from the tail, and moving any existing items to the head when referenced (touched). This algorithm is good for single threaded applications but becomes very slow in a multi-threaded environment. In a multi-threaded app, every time the linked list is modified, it must be locked. This requires thread locks on insert, read, and delete operations, causing the slowness.
Another algorithm is to mark each item’s age with a timestamp (DateTime or incremented Integer) value when touched. When the cache becomes full, the list of items must be sorted and truncated. This keeps insert and read operations very fast because no locks are required, but makes delete painfully slow (normally O(N * log N), for sorting).
Overview
The algorithm I choose, divides items into time slices I call AgeBags. Items are added to the current AgeBag until the bag becomes full or the designated time span expires, then that AgeBag is closed and the next AgeBag becomes current. Items that are touched are marked with an index of the current bag. When the cache gets too full/old, the oldest AgeBag is emptied, moving any nodes that have been touched to the correct AgeBag and removing the rest of the nodes in the bag. This allows reads to be performed without locking, and makes deletes much faster because only items that are in the oldest AgeBag are ever moved and no real sorting is ever performed.
In this system, even though the exact order of items is not maintained, this is still a true LRU Cache because everything that remains in the oldest bag (after moves are made for the touched items) is removed at the same time. Therefore, no item remains in the cache that is older than the removed items.
My implementation of LRUCache contains two distinct sections which are coded as subclasses. The LifespanMgr class tracks the item usage and determines which items to remove when the cache gets full/old. The Index class provides Dictionary key/value access to all objects stored in the cache. The Index has delegates to calculate the key of any item added to the cache, and to load an item by key/value from an external source.
Instead of storing item nodes in the Index, the Index holds WeakReference objects that point at the item nodes. By doing this, the Index does not prevent items from being garbage collected. This also allows old items to be removed from the AgeBag without having to remove the items from the index. Once a Node is removed from the LifespanMgr, it becomes eligible for garbage collection. The Node is not removed from the Indexes immediately. If an Index retrieves the node prior to garbage collection, it is reinserted into the current AgeBag’s node list. If it has already been garbage collected, a new object gets loaded. If the Index size exceeds twice the cache’s capacity, the Index is cleared and rebuilt.
Locking
Before I get into the code, I should provide a brief explanation of all the locking mechanisms used by the LRUCache:
The first and simplest is the Interlocked class which ensures that increment and decrement operations occur without context switching. This is all that is required to make increment and decrement operations thread safe, and is much faster than other locking methods.
The next locking mechanism is the Monitor class. This class is called whenever you use the C#lock keyword. One method of note is Monitor.TryEnter(obj), which immediately returns a bool specifying if a lock was acquired. Unlike the standard Enter() method, after the first thread gets the lock, all other threads will skip the operation instead of waiting for the first thread to complete. This is good for cases where speed is more important than the action being locked. It is also ideal for cases when the locked code only needs to be performed by one thread.
Collapse
if(Monitor.TryEnter(obj))
try {
//do something if lock is not busy
}
finally {
Monitor.Exit(obj);
}
The last locking mechanism used is ReaderWriterLock. At any given time, it allows either concurrent read access for multiple threads, or write access for a single thread. A ReaderWriterLock provides better throughput than Monitor because of its concurrent read access. Because using ReaderWriter locks can get a little tricky, I use a wrapper class that simplifies locking a provided delegate.
Code Review
Because the LifespanMgr is the most interesting part of the code, I will spend most of the remaining article discussing it; however, the code is highly commented so you shouldn’t have any trouble following the rest of the code.
Collapse
publicvoid Touch()
{
if( _value != null && ageBag != _mgr._currentBag )
{
if( ageBag == null )
lock( _mgr )
if( ageBag == null )
{
// if node.AgeBag==null then the object is not// currently managed by LifespanMgr so add it
next = _mgr._currentBag.first;
_mgr._currentBag.first = this;
Interlocked.Increment( ref _mgr._owner._curCount );
}
ageBag = _mgr._currentBag;
Interlocked.Increment( ref _mgr._currentSize );
}
_mgr.CheckValid();
}
Each time an indexed item is added or referenced, LifespanMgr.Node.Touch() is called which (re)inserts the node if needed, and points the node's ageBag variable at the current AgeBag. Also, in the touch method, LifespanMgr.CheckValid() is called.
Collapse
publicvoid CheckValid()
{
DateTime now = DateTime.Now;
// if lock is currently held then skip and let next Touch perform cleanup.if( (_currentSize > _bagItemLimit || now > _nextValidCheck)
&& Monitor.TryEnter( this ) )
try
{
if( (_currentSize > _bagItemLimit || now > _nextValidCheck) )
{
// if cache is no longer valid throw contents// away and start over, else cleanup old itemsif( _current > 1000000 || (_owner._isValid != null
&& !_owner._isValid()) )
_owner.Clear();
else
CleanUp( now );
}
}
finally
{
Monitor.Exit( this );
}
}
CheckValid only performs an action if the AgeBag gets full or the designated time span expires. When either of those cases are met, an optional IsValid() delegate is called which checks the health of the overall cache. If the cache is invalid or out of date, all items in the cache are removed and items will be reloaded the next time an index accesses them. If IsValid returns true, the LifespanMgr.Cleanup() method is called.
Collapse
publicvoid CleanUp( DateTime now )
{
if( _current != _oldest )
lock( this )
{
//calculate how many items should be removed
DateTime maxAge = now.Subtract( _maxAge );
DateTime minAge = now.Subtract( _minAge );
int itemsToRemove = _owner._curCount - _owner._capacity;
AgeBag bag = _bags[_oldest % _size];
while( _current != _oldest && (_current-_oldest>_size - 5
|| bag.startTime < maxAge || (itemsToRemove > 0
&& bag.stopTime > minAge)) )
{
// cache is still too big / old so remove oldest bag
Node node = bag.first;
bag.first = null;
while( node != null )
{
Node next = node.next;
node.next = null;
if( node.Value != null && node.ageBag != null )
if( node.ageBag == bag )
{
// item has not been touched since bag was// closed, so remove it from LifespanMgr
++itemsToRemove;
node.ageBag = null;
Interlocked.Decrement( ref _owner._curCount );
}
else
{
// item has been touched and should// be moved to correct age bag now
node.next = node.ageBag.first;
node.ageBag.first = node;
}
node = next;
}
// increment oldest bag
bag = _bags[(++_oldest) % _size];
}
OpenCurrentBag( now, ++_current );
CheckIndexValid();
}
}
Cleanup does the grunt work of moving touched items out of the last bag and deleting the rest. It also calls CheckIndexValid() to see if indexes need to be recreated, and OpenCurrentBag() which sets up the next current AgeBag.
Usage
The UserCache.cs file contains an example of how the cache can be used:
Brian Agnes has been professionally programming for 15 years using a variety of languages. Brian started using C# in 2002 and is a MCAD charter member.
Brian is currently living in Denver Colorado and working as a Senior Developer for NewsGator.com (a leader in RSS aggregation).
Brian has been a regular presenter at local INETA dot net user groups.








 Replacing the default ViewEngine with a custom made version is actually quite easy! The most difficult part in creating your own ViewEngine implementation will probably be the parsing of your view. Fortunately, there are some examples around which may be a good source of inspiration (see
Replacing the default ViewEngine with a custom made version is actually quite easy! The most difficult part in creating your own ViewEngine implementation will probably be the parsing of your view. Fortunately, there are some examples around which may be a good source of inspiration (see