
本示例演示了在ASP.NET MVC中进行基于URL的权限控制,由于是基于URL进行控制的,所以只能精确到页。这种权限控制的优点是可以在已有的项目上改动极少的代码来增加权限控 制功能,和项目本身的耦合度低,并且实现起来也比较简单。缺点是权限控制不够精确,不能具体到某一具体的按钮或者某一功能。
在数据库中新建2个表。PermissionItem表用于保存权限ID和页面路径的关系,一个权限ID可以有多个页面,一般同一个权限ID下的页面是为了实现同一个功能。PermissionList表用于保存用户所具有的权限。
USE [UrlAuthorize]
GO
/****** Object: Table [dbo].[PermissionList] Script Date: 07/07/2009 00:07:10 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
Create TABLE [dbo].[PermissionList](
[ID] [int] IDENTITY(1,1) NOT NULL,
[PermissionID] [int] NOT NULL,
[UserID] [int] NOT NULL,
CONSTRAINT [PK_PermissionList] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET IDENTITY_Insert [dbo].[PermissionList] ON
Insert [dbo].[PermissionList] ([ID], [PermissionID], [UserID]) VALUES (1, 2, 1)
Insert [dbo].[PermissionList] ([ID], [PermissionID], [UserID]) VALUES (2, 3, 1)
SET IDENTITY_Insert [dbo].[PermissionList] OFF
/****** Object: Table [dbo].[PermissionItem] Script Date: 07/07/2009 00:07:10 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
Create TABLE [dbo].[PermissionItem](
[ID] [int] IDENTITY(1,1) NOT NULL,
[PermissionID] [int] NOT NULL,
[Name] [nvarchar](50) NOT NULL,
[Route] [varchar](100) NOT NULL,
CONSTRAINT [PK_PermissionItem] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
SET IDENTITY_Insert [dbo].[PermissionItem] ON
Insert [dbo].[PermissionItem] ([ID], [PermissionID], [Name], [Route]) VALUES (1, 1, N'测试页1', N'/Test/Page1')
Insert [dbo].[PermissionItem] ([ID], [PermissionID], [Name], [Route]) VALUES (2, 2, N'测试页2', N'/Test/Page2')
Insert [dbo].[PermissionItem] ([ID], [PermissionID], [Name], [Route]) VALUES (3, 3, N'测试页3', N'/Test/Page3')
Insert [dbo].[PermissionItem] ([ID], [PermissionID], [Name], [Route]) VALUES (5, 1, N'测试页4', N'/Test/Page4')
Insert [dbo].[PermissionItem] ([ID], [PermissionID], [Name], [Route]) VALUES (6, 2, N'测试页5', N'/Test/Page5')
SET IDENTITY_Insert [dbo].[PermissionItem] OFF
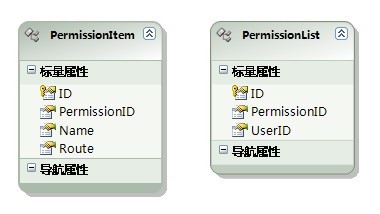
数据库中的示例表示Page1和Page4同属于权限1,Page2和Page5同属于权限2,Page3属于权限3。用户ID为1的用户具有权限2和3。
在ASP.NET MVC项目中新建一个AccountHelper类,这是一个辅助类。GetPermissionItems方法用于获取权限ID和页面路径的对应关系。 这是全局的,并且每个用户在访问页面时都会用到这些信息,所以存入Cache中。数据库的相关操作这里使用的是ADO.NET Entity Framework。
 /// <summary>
/// <summary>
2
 /// 获取权限项
/// 获取权限项3
/// </summary>4
 /// <returns>权限项列表</returns>
/// <returns>权限项列表</returns>5
 public static List<PermissionItem> GetPermissionItems()
public static List<PermissionItem> GetPermissionItems()6
{
7
// 如果缓存中已经存在权限列表信息,则直接从缓存中读取。8
if (HttpContext.Current.Cache["PermissionItems"] == null)9
 {
{
10
// 如果缓存中没有权限列表信息,则从数据库获取并写入缓存11
UrlAuthorizeEntities db = new UrlAuthorizeEntities();12
var items = db.PermissionItem.Where(c => c.PermissionID > 0).ToList();13
HttpContext.Current.Cache["PermissionItems"] = items;14
 }
}15
16
// 这个缓存中保存了所有需要进行权限控制的页面所对应的权限ID17
return (List<PermissionItem>)HttpContext.Current.Cache["PermissionItems"];18
}19
GetUserPermission方法是将用户所具有的权限ID保存到一个一维Int32数组中。这个信息每个用户是不同的,但是会经常使用到,所以存入Session。
/// <summary>2
/// 获取用户权限3
/// </summary>4
/// <param name="userID">用户ID</param>5
/// <returns>用户权限数组</returns>6
public static Int32[] GetUserPermission(int userID)7
{8
// 如果缓存中已经存在权限列表信息,则直接从缓存中读取。9
if (HttpContext.Current.Session["Permission"] == null)10
{11
// 从数据库获取用户权限并将权限ID放到int数组并存入Session12
UrlAuthorizeEntities db = new UrlAuthorizeEntities();13
var permissions = db.PermissionList.Where(c => c.UserID == userID).Select(c=>c.PermissionID).ToArray();14
HttpContext.Current.Session["Permission"] = permissions;15
}16
return (Int32[])HttpContext.Current.Session["Permission"];17
}18
再新建一个UrlAuthorizeAttribute类,继承自AuthorizeAttribute,这是一个Filter。我们重写它的OnAuthorization方法,以在ASP.NET页生命周期身份验证阶段执行它。
/// <summary>2
/// 重写OnAuthorization3
/// </summary>4
/// <param name="filterContext"></param>5
public override void OnAuthorization(AuthorizationContext filterContext)6
{7
// 获取权限项列表8
List<PermissionItem> pItems = AccountHelper.GetPermissionItems();9
10
// 获取当前访问页面对应的权限ID。如果item为空则表示当前页面没有权限控制信息,不需要进行权限控制11
var item = pItems.FirstOrDefault(c => c.Route == filterContext.HttpContext.Request.Path);12
13
if (item != null)14
{15
if (Array.IndexOf<Int32>(AccountHelper.GetUserPermission(int.Parse(filterContext.HttpContext.Session["UserID"].ToString())), item.PermissionID) == –1)16
{17
// 提示权限不够,也可以跳转到其他页面18
filterContext.HttpContext.Response.Write("没有权限访问该页面");19
filterContext.HttpContext.Response.End();20
}21
}22
else23
{24
// 如果权限项列表中不存在当前页面对应的权限ID则所有用户都不允许访问,直接提示无权访问。***注1***25
filterContext.HttpContext.Response.Write("没有权限访问该页面");26
filterContext.HttpContext.Response.End();27
}28
}29
至此,主要的工作都已经完成了的。接下来我们只需要在需要进行权限控制的Action或Controller前加上[UrlAuthorize], 这些Action或Controller中的所有Actions就会自动被UrlAuthorize这个Filter进行处理。如果某一个Action被 标上了[UrlAuthorize],而数据库中又不存在该页面对应的权限ID,那么根据示例的代码,所有用户都将无法访问这个页面,如果需要更改这个设 置,可以修改上面“注1”下面的2行代码。







































