一个Url请求经过了Routing处理后会调用Controller的Action方法. 中间的过程是怎样的? Action方法中返回ActionResult对象后,如何到达View的? 本文将讲解Controller的基本用法, 深入分析Controller的运行机制, 并且提供了创建所有类型Action的代码. 值得学习ASP.NET MVC时参考.
在上一篇文章中, 我已经学会了如何使用Routing获取Controller和Action, 随后的程序会调用Controller中的Action方法.
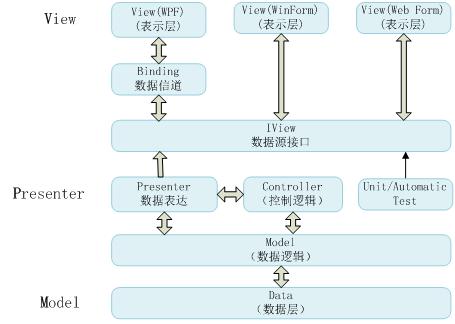
每个Action方法都要返回一个ActionResult对象. 一个Action会将数据传递给View,如图:
Controller负责将获取Model数据并将Model传递给View对象.通知View对象显示.
ActionResult类包括ExecuteResult方法, 当ActionResult对象返回后会执行此方法.
通过对MVC源代码的分析,我们了解到Controller对象的职责是传递数据,获取View对象(实现了IView接口的类),通知View对象显示.
View对象的作用是显示.虽然显示的方法RenderView()是由Controller调用的,但是Controller仅仅是一个"指挥官"的作用, 具体的显示逻辑仍然在View对象中.
需 要注意IView接口与具体的ViewPage之间的联系.在Controller和View之间还存在着IView对象.对于ASP.NET程序提供了 WebFormView对象实现了IView接口.WebFormView负责根据虚拟目录获取具体的Page类,然后调用 Page.RenderView().
通过上面的流程,我们知道了ActionResult对象在整个流程中的作用.ActionResult是一个抽象类, 在Action中返回的都是其派生类.下面是我整理的RC2版本中提供的ActionResult派生类:
下面我将列举各个ActionResult的实例.
在文章最后提供有完整实例代码下载.
六.Controller 深入分析
在研究Controller/Action的流程过程中, 发现了ASP.NET MVC一些问题.
1.Routing组件与MVC框架的结合
Routing组件和ASP.NET MVC并不是一个项目, 在ASP.NET MVC中仅仅是使用了Routing组件, 在源代码中是通过dll的方式引用的.Routing组件已经包含在.net framework 3.5 sp1中了.而ASP.NET MVC还未出正式版.
那么ASP.NET MVC是如何应用Routing组件的呢?
Routing组件获取了Url中的数据后, 会将数据保存在一个 RouteData 对象中.并将请求传递给一个实现了IRouteHandler接口的对象. 在Asp.net MVC中提供的MvcRouteHandler类实现了此接口, Routing 将请求传递给MvcRouteHandler的GetHttpHandler方法.下面是源代码:
IRouteHandler接口:
public interface IRouteHandler
{
IHttpHandler GetHttpHandler(RequestContext requestContext);
}
MvcRouteHandler类:
public class MvcRouteHandler : IRouteHandler {
protected virtual IHttpHandler GetHttpHandler(RequestContext requestContext) {
return new MvcHandler(requestContext);
}
#region IRouteHandler Members
IHttpHandler IRouteHandler.GetHttpHandler(RequestContext requestContext) {
return GetHttpHandler(requestContext);
}
#endregion
}
曾经我认为IRouteHandler是多余的, 用IHttpHandler就够了. 现在知道了为何要定义这个接口. 主要是为了传递RouteData对象.GetHttpHandler方法需要一个RequestContext 对象.RequestContext 是 System.Web.Routing程序集中的类, 里面除了处理请求需要的HttpContextBase对象,还包括了一个RouteData对象.
RequestContext类:
public class RequestContext
{
public RequestContext(HttpContextBase httpContext, RouteData routeData);
public HttpContextBase HttpContext { get; }
public RouteData RouteData { get; }
}
Routing组件在Web.Config中注册了一个HttpModule: System.Web.Routing.UrlRoutingModule, 而不是HttpHandler:
<add name="UrlRoutingModule" type="System.Web.Routing.UrlRoutingModule, System.Web.Routing, Version=3.5.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/>
可惜看不到这个类的源代码. 所有请求最后都是要传递给IHttpHandler对象处理, 主要的工作是编译页面, 所以我猜测这个Module将请求截获后通过IRouteHandler接口对象获取一个HttpHandler, 然后将处理移交给获取到的HttpHandler.
ASP.NET MVC 中实现了IHttpHandler接口的类是MvcHandler, MvcRouteHandler.GetHttpHandler方法就是返回一个MvcHandler对象. MvcHandler类的构造函数需要传入一个RequestContext对象. 实现的IHttpHandler接口方法处理过程中都需要依赖这个对象.
但是微软在这里的处理有一些不足. MvcHandler虽然实现了IHttpHandler接口但是不能被当作IHttpHandler接口使用. 因为IHttpHandler中没有定义RequestContext属性, 如果一个MvcHandler对象此属性没有赋值则会出错, 也没有将默认的无参数构造函数设置为private, 所以理论上可以很随意的实例化一个MvcHandler而不为其RequestContext属性赋值.
IRouteHandler想实现的语意是: 返回一个具有RequestContext属性的IHttpHandler对象.
但是最后的实现结果是: 提供"返回IHttpHandler对象"的方法, 此方法接收RequestContext对象参数.
还需要注意ControllerContext类. 在Controller的处理过程中使用此对象作为保存上下文数据的容器.下面是这几个类的包含关系:

可以看到在ControllerContext中包含了RequestContext对象,但是又将RequestContext对象中的两个属性 提取到自己的类中.如果仅仅是为了使用方便而这么做, 个人认为不是一个好的设计.数据对象的存储职责也应该明确,使用ControllerContext.RequestContext.RouteData 的方式更容易被人理解.
PS:这种方式类似于方法内联.对于属性JIT为了效率会帮助我们做内联.而仅仅是为了使用方便.
2.IView 与 View对象的关系
所以从系统的角度上看, 实现了IView接口的对象才是View.
但是从实现效果上看, 具体的aspx或者ascx页面才是View.
当第一次看到IView接口时我认为它应该是"View角色"需要实现的接口. 但是结果并不是这样.
在我们的系统中View对象应该是aspx或者ascx文件. 而且并不是所有的ActionResult都需要找到aspx或者ascx文件, 事实上只有PartialViewResult 和 ViewResult 才会去寻找View对象.其他的ActionResult要么是返回文件, 要么是跳转等等.
那么两者的关系到底是怎样的? 其实其中的过程需要牵扯到这几个接口和类:
IViewEngine, ViewEngineResult, ViewEngineCollection
ViewEngine是View引擎, ViewEngineCollection是一个引擎集合,里面保存了各种寻找View的引擎.但是在目前的源代码中只有 WebFormViewEngine : VirtualPathProviderViewEngine : IViewEngine
这一系列WebForm使用的引擎.引擎的作用有两个:
1.寻找Page/用户控件的路径
2.根据路径创建IView对象.也就是根据页面的物理文件创建IView接口对象.
而且目前实现了IView接口的对象也只有一个:
WebFormView
WebFormViewEngine 根据页面路径, 将一个页面地址转化为一个WebFormView对象,也就是一个IView接口对象.
至此IView接口和Page页面类仍然没有任何关系, IView对象只是保存了页面的物理路径.
接着在IView的Render事件中,根据物理路径创建了一个页面的object实例,注意看这一段代码:
object viewInstance = BuildManager.CreateInstanceFromVirtualPath(ViewPath, typeof(object));
if (viewInstance == null) {
throw new InvalidOperationException(
String.Format(
CultureInfo.CurrentUICulture,
MvcResources.WebFormViewEngine_ViewCouldNotBeCreated,
ViewPath));
}
ViewPage viewPage = viewInstance as ViewPage;
if (viewPage != null) {
RenderViewPage(viewContext, viewPage);
return;
}
ViewUserControl viewUserControl = viewInstance as ViewUserControl;
if (viewUserControl != null) {
RenderViewUserControl(viewContext, viewUserControl);
return;
}
viewInstance 就是通过物理路径创建的页面对象.但是他的类型是object, 而且程序尝试将其分别转化为ViewPage对象和ViewUserControl对象.
我想很多人都看到了这里的设计不足.现在我们只能"约定": 所有的MVC中的页面对象都必须继承自ViewPage或者ViewUserControl类, 否则程序就会出错.产生这种不足的原因就是IView接口和ViewPage没有任何的耦合性, 完全是硬编码进去的.
为什么不让页面直接实现IView接口? 然后尝试将页面转化为IView接口对象, 而不是ViewPage, 这样才是好的设计. 其实微软知道什么是好的设计, 我猜测他们遇到的困难是Page对象和IView接口的冲突. 因为两者都需要Render. 如果在IView中定义自己的Render名称, 那就意味着ASP.NET MVC开发小组要自己处理页面的显示逻辑, 而现在ASP.NET WebForm模式下面的页面显示引擎又不能复用, 重新开发自己的一套显示引擎成本又太大, 才出此下策.
以上只是猜测.这种设计的缺陷虽然可以接受, 但是真的是让我好几天陷入了看不懂代码的痛苦之中.还好, 现在可以解脱了.
七.如何在MVC项目中使用MVC源代码项目
另外在为了跟踪实现过程, 我将ASP.NET MVC的源代码项目添加到了实例项目中, 其中有一些需要注意的地方:
1. 将实例项目中的System.Web.Mvc引用删除, 改成项目引用.
2. 需要在Web.Config中注释掉程序集引用:
<compilation debug="true">
<assemblies>
<add assembly="System.Core, Version=3.5.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089"/>
<add assembly="System.Web.Extensions, Version=3.5.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/>
<add assembly="System.Web.Abstractions, Version=3.5.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/>
<add assembly="System.Web.Routing, Version=3.5.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/>
<!-- <add assembly="System.Web.Mvc, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/>-->
<add assembly="System.Data.DataSetExtensions, Version=3.5.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089"/>
<add assembly="System.Xml.Linq, Version=3.5.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089"/>
<add assembly="System.Data.Linq, Version=3.5.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089"/>
</assemblies>
</compilation>
注释掉的程序集存在于GAC中, 但是我们现在不希望使用GAC中的程序集, 而是引用项目.
3. 将View目录下的Web.Config中的所有System.Web.Mvc相关的 PublicKeyToken 都修改为 null:
<pages
validateRequest="false"
pageParserFilterType="System.Web.Mvc.ViewTypeParserFilter, System.Web.Mvc, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null"
pageBaseType="System.Web.Mvc.ViewPage, System.Web.Mvc, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null"
userControlBaseType="System.Web.Mvc.ViewUserControl, System.Web.Mvc, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null">
<controls>
<add assembly="System.Web.Mvc, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null" namespace="System.Web.Mvc" tagPrefix="mvc" />
</controls>
</pages>
八.总结
首先很抱歉在本系列文章开篇时承诺的每日一篇仅仅坚持了2天.具体原因就不解释了.这篇文章的出炉历时半个月, 并且经历了ASP.NET MVC版本从RC到RC2的演变. 在查看MVC源代码上花费了大量的时间, 希望付出的努力能够为大家研究学习ASP.NET MVC带来帮助. 我也会把这一系列的文章写完, 关于ASP.NET MVC还有太多的地方没有学习.
实例源代码下载地址:
http://files.cnblogs.com/zhangziqiu/Asp.net-MVC-3-Demo.rar


做人、做事,做架构师——架构师能力模型解析 - oliwen - oliwen")
做人、做事,做架构师——架构师能力模型解析 - oliwen - oliwen")
做人、做事,做架构师——架构师能力模型解析 - oliwen - oliwen")









 nc
nc  }
}