
摘要
本文将对“MVC公告发布系统”的发布公告功能添加日志功能和异常处理功能,借此来讨论ASP.NET MVC中拦截器的使用方法。
一个小难题
我们继续完善“MVC公告发布系统”,这次,我们的需求是对公告发布功能添加日志记录能力,即在发布公告前,记录一次,在公告发布成功后,再记录一次。然后还要使得其具备异常处理,即当业务组件出现问题时,跳转到相应的错误页面并显示相应提示。
有人可能笑了,这有什么难的,在DoRelease这个Action的开始和结束处各加入相应日志功能不久结了。异常处理更不在话下,直接try…catch搞定。
没错,以上方法确实行得通,但是存在以下两点问题:
1.代码重复问题。很多日志处理代码和异常处理代码是很相似的,这样就导致了各个Action中存在大量重复代码。
2.职责被破坏。不要忘了,我们的Controller仅仅是控制器,它应该只负责表示逻辑,而不应该被一大堆日志处理代码和try…catch块包围。我们要的Action,应该是干净的、工整的、仅包含表示逻辑的Action。
以上两点,造成了我们系统中的坏味代码。那么,怎么解决这个问题呢?
从厨师到AOP
先来想象一个场景:饭店里的高级厨师怎么工作?我们知道,他不用洗菜切菜、不用端着盘子送菜、如果发现手里牛肉变质了他更不用拿着牛肉去找肉店老板理论,他的工作很单一:炒菜。
当原料送来后,有专门的顺菜切菜工进行洗菜、切菜,然后把处理好的菜送给厨师,厨师只管下锅炒,炒完了送菜自然也不必关心,因为有专门的服务员负责这事。如果发现牛肉变质了,它只管说一声,自然有相应的人处理这事。
这个场景就是典型的AOP(面向切面编程)。厨师可以看成是业务组件,它有个方法就是“炒菜”,但是炒菜前要切菜,炒完了要有人送菜,可这不是厨师该关心 的事啊!于是我们的切菜工和服务员就相当于拦截器,其中切菜工在炒菜前拦截,进行切菜,服务员在炒菜后拦截,负责送菜。当然,我们还有个异常拦截器:处理 问题的人,就是那个当厨师发现肉变质了喊一声,就来处理的人。
基于这个场景,我们看看这样有什么好处。首先是厨师职责单一了,他可以专注于自己的工作:炒菜,而不必理会不该自己关心的问题。而且“拦截器们”可以复用 的,例如一个抠门的老板完全可以找3个厨师但是只招一名服务员,反正一名服务员就可以给三名厨师端菜,这样,拦截器的复用使得代码重复不见了!
回来
好的,现在回到我们的“MVC公告发布系统”。相信看了上面的场景,你的灵感一定来了:对啊,Action不就是厨师吗,如果我们可以将日志功能做成拦截 器,在DoRelease执行前先拦截一次完成记录日志功能,DoRelease执行后再拦截一次记录一次日志。最好还有个拦截器,在Action发生异 常的时候可以拦截处理(就像上文处理变质牛肉的人),不就搞定了吗。
可是要怎么实现拦截Action呢?真是幸运之极,ASP.NET MVC框架中内置了这种机制!哈哈,我们赶快来做吧!
实现拦截器
在ASP.NET MVC中,有三种拦截器:Action拦截器、Result拦截器和Exception拦截器。我要用到第一种和第三种。其实所谓的ASP.NET MVC拦截器,也没什么神秘的,就是一个普通的类而已。只不过需要继承FilterAttribute基类,Action拦截器还要实现IActionFilter接口,而Exception拦截器需要实现IExceptionFilter接口。
我们先来看实现:让我们在Controllers目录下新建一个Filters目录,然后在Filters下新建两个类,一个叫LoggerFilter一个叫ExceptionFilter。首先是LoggerFilter的代码。
LoggerFilter.cs:
 using System;
using System;2
using System.Collections.Generic;3
using System.Linq;4
using System.Web;5
using System.Web.Mvc;6
using System.Web.Mvc.Ajax;7
8
namespace MVCDemo.Controllers.Filters9
 {
{

10
 public class LoggerFilter : FilterAttribute, IActionFilter
public class LoggerFilter : FilterAttribute, IActionFilter11
 {
{
12
void IActionFilter.OnActionExecuting(ActionExecutingContext filterContext)13
{14
filterContext.Controller.ViewData["ExecutingLogger"] = "正要添加公告,已以写入日志!时间:" + DateTime.Now; 15
 }
}16
17
void IActionFilter.OnActionExecuted(ActionExecutedContext filterContext)18
{19
filterContext.Controller.ViewData["ExecutedLogger"] = "公告添加完成,已以写入日志!时间:" + DateTime.Now;20
}21
}22
 }
}
可以看到,这个类继承了FilterAttribute并实现了IActionFilter。其中关键是IActionFilter,它有两个方 法,OnActionExecuting在被拦截Action前执行,OnActionExecuted在被拦截Action后执行。两个方法都有一个参 数,虽然类型不同,但其实都是一个作用:被拦截Action的上下文。
这个地方我得解释一下,你拦截器拦截了Action,在做处理时难免要用到被拦截Action相关的东西,例如在我们的例子中,就需要想被拦截 Action所在Controller的ViewData中添加内容,所以,拦截器方法有一个参数表示被拦截Action的上下文是顺理成章的事。
下面再看ExceptionFilter这个拦截器,它是在Action出现异常时发挥作用的。
ExceptionFilter.cs:
using System;2
using System.Collections.Generic;3
using System.Linq;4
using System.Web;5
using System.Web.Mvc;6
using System.Web.Mvc.Ajax;7
8
namespace MVCDemo.Controllers.Filters9
{10
public class ExceptionFilter : FilterAttribute,IExceptionFilter11
{12
void IExceptionFilter.OnException(ExceptionContext filterContext)13
{14
filterContext.Controller.ViewData["ErrorMessage"] = filterContext.Exception.Message;15
filterContext.Result = new ViewResult()16
{17
ViewName = "Error",18
ViewData = filterContext.Controller.ViewData,19
};20
filterContext.ExceptionHandled = true;21
}22
}23
}
异常拦截器一样需要继承FilterAttribute,但是不要实现IActionFilter,而是要实现IExceptionFilter接口,这 个接口只有一个方法:OnException,顾名思义,当然是发生异常时被调用了。我们看看我让它做了什么:首先将异常信息 (ExceptionContext一样也是上下文,而其成员的Exception就是一个Exception类型的实例,就是被抛出的异常)记录到 ViewData相应的键值里,然后我们要呈现Error这个视图。
注意!这里已经不是Controller里了,而是另一个类,所以当然不能调用View方法返回ViewResult实例了。我们只好新建一个ViewResult实例,并将其视图名设为Error,将上下文中的DataView传过去。
最后那行filterContext.ExcepitonHandled = true;很重要,这行的意思是告诉系统,异常已经处理,不要再次处理了。
应用拦截器
好了,拦截器建立完了,要怎么应用到相应的Action上呢?如果你使用过Spring,你一定对其AOP是实现之麻烦深有感触,如果你和我一样讨厌写各 种XML的话,你真是太幸福了。因为在ASP.NET MVC中,应用拦截器简直是轻松加愉快。只要将拦截器当做Attribute写在要应用此拦截器的Action上就行了。看代码。
AnnounceController.cs:
using System;2
using System.Collections.Generic;3
using System.Linq;4
using System.Web;5
using System.Web.Mvc;6
using System.Web.Mvc.Ajax;7
using MVCDemo.Models;8
using MVCDemo.Models.Interfaces;9
using MVCDemo.Models.Entities;10
using MVCDemo.Controllers.Filters;11
12
namespace MVCDemo.Controllers13
{14
public class AnnounceController : Controller15
{16
public ActionResult Release()17
{18
ICategoryService cServ = ServiceBuilder.BuildCategoryService();19
List<CategoryInfo> categories = cServ.GetAll();20
ViewData["Categories"] = new SelectList(categories, "ID", "Name");21
return View("Release");22
}23
24
[LoggerFilter()]25
[ExceptionFilter()]26
public ActionResult DoRelease()27
{28
AnnounceInfo announce = new AnnounceInfo()29
{30
ID = 1,31
Title = Request.Form["Title"],32
Category = Int32.Parse(Request.Form["Category"]),33
Content = Request.Form["Content"],34
};35
36
IAnnounceService aServ = ServiceBuilder.BuildAnnounceService();37
aServ.Release(announce);38
39
ViewData["Announce"] = announce;40
41
System.Threading.Thread.Sleep(2000);42
ViewData["Time"] = DateTime.Now;43
System.Threading.Thread.Sleep(2000);44
45
return View("ReleaseSucceed");46
}47
}48
}
看到没有,只要在DoRelease上写这么两个Attribute,一切就完成了,至于什么时候该调用什么拦截器,都是框架帮你完成了。注意一点,为了 让我们看出拦截器的时序,我们在DoRelease中加了一点东西,就是加了一个ViewData["Time"],里面记录了执行此Action的时 间,因为日志拦截器在前后都会记录时间,我们通过比较时间就可以看出执行顺序了。至于那两个Sleep则是让效果更明显的,这行代码的意思是让程序在这里 延迟2秒。
要执行这个程序,我们还要改一下ReleaseSucceed.aspx视图,其实就是加几个地方显示ViewData里相应的数据。
ReleaseSucceed.aspx:
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="ReleaseSucceed.aspx.cs" Inherits="MVCDemo.Views.Announce.ReleaseSucceed" %>2
<%@ Import Namespace="MVCDemo.Models.Entities" %>3
4
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">5
6
<html xmlns="http://www.w3.org/1999/xhtml" >7
<head runat="server">8
<title></title>9
</head>10
<body>11
<% AnnounceInfo announce = ViewData["Announce"] as AnnounceInfo; %>12
<div>13
<h1>MVC公告发布系统——发布公告成功</h1>14
<dl>15
<dt>ID:</dt>16
<dd><%= announce.ID %></dd>17
<dt>标题:</dt>18
<dd><%= announce.Title %></dd>19
<dt>类别ID:</dt>20
<dd><%= announce.Category %></dd>21
<dt>内容:</dt>22
<dd><%= announce.Content %></dd>23
<dt>发布时间:</dt>24
<dd><%= ViewData["Time"] %></dd>25
</dl>26
<p><%= ViewData["ExecutingLogger"] %></p>27
<p><%= ViewData["ExecutedLogger"] %></p>28
</div>29
</body>30
</html>
现在可以提交一则公告看结果了:

下面我们来看看异常拦截器的效果。要触发异常拦截器,首先要抛出一个异常,所以,我们在业务逻辑组件做点手脚。将MockAnnounceServices的Release方法改成如下:
/// <summary>2
/// 发布公告3
/// </summary>4
/// <param name="announce"></param>5
public void Release(AnnounceInfo announce)6
{7
throw new Exception("发布公告失败了!原因?没有原因!我是业务组件,我说失败就失败!");8
return;9
} 另外,我们还要实现一个Error.aspx视图,这是在异常拦截器中定义的错误视图。我们将它新建在Views/Shared下就可以了。顺便说一下, 共用的视图一般放在Shared下,因为ASP.NET MVC的视图寻找机理是当与Controller同名目录下不存在时,就到Shared下看看有没有此视图。
Error.aspx:
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="Error.aspx.cs" Inherits="MVCDemo.Views.Shared.Error" %>2
3
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">4
5
<html xmlns="http://www.w3.org/1999/xhtml" >6
<head runat="server">7
<title></title>8
</head>9
<body>10
<div>11
<h1>系统发生异常</h1>12
<%= ViewData["ErrorMessage"] %>13
</div>14
</body>15
</html>好了,现在我们再提交新公告,会返回如下结果:
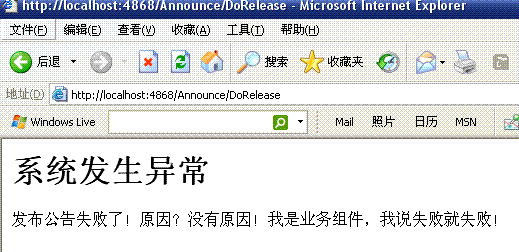
我们再回过头看看,使用了拦截器后,代码是不是很清晰呢。
小结
通过本文,朋友们应该可以掌握拦截器的基本使用以及使用它在表示层实现AOP了。下一篇作为本系列的终结篇,将对ASP.NET MVC做一个全面的讨论,并与Web Form模型进行一个比较,使朋友们看清其优势、劣势,从而更好的学习使用这个框架。




