原著:Sadaf Alvi
翻译:Abbey
原文出处 Attributes in C#, CodeProject
 摘要
摘要
在这篇指南里,我们将会看到如何自己创建属性(Attribute),并将其用到不同的程序实体(Entity)上,在程序运行时获取属性信息。
译注
MSDN将 Attribute 与 Property 均译作“属性”。我真不知道该怎么译了,就将 Property 译作“数据属性”吧。
介绍
属性(Attribute)是一种新型的声明信息。我们可以使用属性来定义设计时的信息(比如帮助文件、文档的链接),以及运行时的信息(比如将一个 类的域与一个XML的域相关联)。我们也可以用属性来创建“自描述”的组件(可以提供该组件的描述信息)。在这篇指南里,我们将会看到如何自己创建属性 (Attribute),并将其用到不同的程序实体(Entity)上,并在程序运行时获取属性信息。
属性的概念
MSDN(ms-help://MS.MSDNQTR.2002APR.1033/csspec/html/vclrfcsharpspec_17_2.htm)里是这样定义的:属性是一个声明的附加声明。
使用预定义的属性
C#已经预定义了一小组的属性供我们使用。在学习如何创建一个自定义的属性前,我们先通过一段代码来看看怎么使用这些预定义的属性吧。
using System;
public class AnyClass
{
[Obsolete("别用Old这个老方法了,请用New方法", true)]
static void Old( ) { }
static void New( ) { }
public static void Main( )
{
Old( );
}
}
在这个例子里我们使用了Obsolete(“陈旧的”)属性,它会将其所修饰的程序实体(类、方法、数据成员等)说明为已废弃不用的。第一个参数—一 个字符串说明这个实体为何被废弃、由谁代替。实际上这个字符串的内容你想写什么都可以。第二个参数则告诉编译器将用户对此实体的调用视作一个编译错误。这 个参数的缺省值为false,表示编译器仅将用户对其的调用视作警告。编译上面这段代码时,我们将会得到一个编译错误(译注:注意编译错误后附的提示了 吗?):
AnyClass.Old() is obsolete:“别用Old这个老方法了,请用New方法”
开发自定义的属性
现在开始开发我们自己的属性吧。这儿有一个小窍门:从C#定义的System.Attribute类派生我们的属性类(从抽象基类 System.Attribute直接或间接地派生一个类,该派生类都是一个属性类。一个属性类的声明就定义了一种新的属性类型),然后得到了这样一个声 明:
using System;
public class HelpAttribute : Attribute
{
}
不管你相不相信,我们已经创建了一个自定义的属性。我们可以象这样用它修饰任何的类:
[Help()]
public class AnyClass
{
}
注意:
在 属性类名与后缀Attribute间存在一个自动的编译转换。因此当我们用一个属性去修饰一个程序实体时,不需要给出Attribute这个后缀。编译器 首先会在System.Attribute的所有派生类中进行匹配,如果没有找到匹配属性,它就将属性名加上Attribute后缀名后再进行匹配。
目前我们的这个属性还没什么用,让我们加点内容吧。在这个示例里,我们为自定义的属性类添加了一个数据属性Description(Property),我们将在本文的最后演示如何在运行时查询这些信息。
using System;
public class HelpAttribute : Attribute
{
public HelpAttribute(String Descrition_in)
{
this.description = Description_in;
}
protected String description;
public String Description
{
get
{
return this.description;
}
}
}
[Help("这是个什么也不做的类")]
public class AnyClass
{
}
定义/控制自定义属性的使用
AttributeUsage 类是另一个预定义的属性类,以帮助我们控制自定义属性的使用。亦即我们可以定义自定义属性类的属性。这个类描述了如何使用自定义的属性类。AttributeUsage有三个数据属性可用以修饰我们的自定义的属性:
|
ValidOn |
定义了自定义属性在哪些程序实体上可被使用。这个可使用实体的列表可通过AttributeTargets枚举类型的OR操作进行设置 |
| AllowMultiple | 定义了是否可在同一个程序实体上同时使用多个属性进行修饰 |
| Inherited | 定义了自定义属性的修饰是否可由被修饰类的派生类继承 |
让我们做点具体的吧。我们将会用一个AttributeUsage属性修饰我们的属性类,以控制其作用范围:
using System;
[AttributeUsage(AttributeTargets.Class), AllowMultiple = false, Inherited = false ]
public class HelpAttribute : Attribute
{
public HelpAttribute(String Description_in)
{
this.description = Description_in;
}
protected String description;
public String Description
{
get
{
return this.description;
}
}
}
先看看AttributeTargets.Class,说明了我们的Help属性只能用以修饰类,下面的这段代码将会导致一个编译错误(“属性 Help不能用在这样的声明上,它只能用在类的声明上”),因为我们用Help属性去修饰方法AnyMethod()了:
[Help("this is a do-nothing class")]
public class AnyClass
{
[Help("this is a do-nothing method")] //error
public void AnyMethod()
{
}
}
编译错误:
AnyClass.cs: Attribute ''Help'' is not valid on this declaration type. It is valid on ''class'' declarations only.
当然我们可以AttributeTargets.All来允许Help属性修饰任何类型的程序实体。AttributeTargets可能的值包括:
- Assembly,
- Module,
- Class,
- Struct,
- Enum,
- Constructor,
- Method,
- Property,
- Field,
- Event,
- Interface,
- Parameter,
- Delegate,
- All = Assembly | Module | Class | Struct | Enum | Constructor | Method | Property | Field | Event | Interface | Parameter | Delegate,
- ClassMembers = Class | Struct | Enum | Constructor | Method | Property | Field | Event | Delegate | Interface )
接下来,该看看AllowMultiple = false这句了:它确定了不能象下面这样,在同一实体上同时使用多个同种属性进行修饰:
[Help("this is a do-nothing class")]
[Help("it contains a do-nothing method")]
public class AnyClass
{
[Help("this is a do-nothing method")] //这也是错误的,因为Help属性只能修饰类
public void AnyMethod()
{
}
}
编译错误:
AnyClass.cs: Duplicate ''Help'' attribute
我们再来谈谈AttributeUsage的最后一个数据属性Inherited:定义了自定义属性的修饰是否可由被修饰类的派生类继承。基于下示代码表示的继承关系,让我们看看会发生什么吧:
[Help("BaseClass")]
public class Base
{
}
public class Derive : Base
{
}
我们选择了AttributeUsage的四种组合:
- [AttributeUsage(AttributeTargets.Class, AllowMultiple = false, Inherited = false ]
- [AttributeUsage(AttributeTargets.Class, AllowMultiple = true, Inherited = false ]
- [AttributeUsage(AttributeTargets.Class, AllowMultiple = false, Inherited = true ]
- [AttributeUsage(AttributeTargets.Class, AllowMultiple = true, Inherited = true ]
对应上述组合的结果:
- 如果我们查询(稍后我们会看见如何在运行时查询一个类的属性信息。)这个Derive类的Help属性时,会因其未从基类继承该属性而一无所获。
- 因为同样的原因,得到与结果一同样的结果。
- 为了解释这后面的两种情况,我们把同样的属性也用在这个Derive派生类上,代码修改如下:
- 我们的查询会同时得到其类Base与派生类Dervie的Help属性信息,因为继承与多重修饰均被允许。
[Help("BaseClass")]
public class Base
{
}
[Help("DeriveClass")]
public class Derive : Base
{
}
注意:
AttributeUsage只能用于System.Attribute的派生类,且该派生类的AllowMultiple与Inherited都为false。
定位参数与命名参数
定位参数是属性类构造子(Constructor)的参数。它们是每次使用该属性修饰某个程序实体时都必须提供值的参数。相对的,命名参数则是可选参 数,它也不是属性类构造子的参数。为了详细解释它们的含义,让我们给Help属性类加点内容,然后看看下面的示例:
[AttributeUsage(AttributeTargets.Class, AllowMultiple = false, Inherited = false)]
public class HelpAttribute : Attribute
{
public HelpAttribute(String Description_in)
{
this.description = Description_in;
this.verion = "No Version is defined for this class";
}
protected String description;
public String Description
{
get
{
return this.description;
}
}
protected String version;
public String Version
{
get
{
return this.version;
}
//即便我们不想我们的属性用户设置Version这个数据属性,我们也不得不提供set方法
set
{
this.verion = value;
}
}
}
[Help("This is Class1")]
public class Class1
{
}
[Help("This is Class2", Version = "1.0")]
public class Class2
{
}
[Help("This is Class3", Version = "2.0",
Description = "This is do-nothing class")]
public class Class3
{
}
我们查询Class1的Help属性信息时,会得到下列结果:
Help.Description : This is Class1 Help.Version :No Version is defined for this class
如果我们不定义Version数据属性的值,那么构造子函数体内所赋的缺省值将会使用。如果也没有,那么该数据属性对应的数据类型的缺省值将被使用(比如int类型的缺省值为0)。查询Class2将会得到这样的结果:
Help.Description : This is Class2 Help.Version : 1.0
请不要为了可选的参数而提供多个构造子的重载版本,而应该将它们定义成命名参数。我们之所以称其为“命名的”,是我们为了能在构造子里给 它们赋值,不得不用一个个的标识符定义和访问它们。比如在第二个类中Help属性的使用[Help("This is Class2", Version = "1.0")] 你瞧,AttributeUsage的ValidOn参数就是一个定位参数,而Inherited与AllowMultiple则是命名参数。 注意:在属性类的构造子中给命名参数赋值,我们必须为它提供一个相应的set方法,否则会导致这样的编译错误(Version不能是一个只读的数据属 性):
''Version'' : Named attribute argument can''t be a read only property
当我们查询Class3的Help属性信息时会发生什么呢?会这样-因上述的原因导致编译错误(Description不能是只读的数据属性):
''Desciption'' : Named attribute argument can''t be a read only property
所以还是给Description添加一个set方法吧。这样会得到正确的输出结果:
This is do-nothing class Help.Version : 2.0
这是因为构造子利用定位参数构造一个属性时,它会调用所有命名参数的set方法。构造子里的赋值行为实际均由各命名参数对应的数据属性的set方法完成,被其覆写(Override)了。
参数类型
一个属性类的参数可使用的数据类型限于:
- bool
- byte
- char
- double
- float
- int
- long
- short
- string
- System.Type
- object
- 枚举类型以及上述数据类型的一维数组
属性标识
让我们想象一下,怎么才能把我们的Help属性用到一个完整的程序集(assembly)上?首先要面对的问题是该把Help属性放在哪儿,以便让编 译器识别出它是属于一个程序集的?再考虑另一种情况:我们想把一个属性用在某个方法的返回类型上时,编译器如何才能确定我们把它用在了返回类型而不是这个 方法本身之上?要解决这么多含糊的问题,我们需要属性标识。借助属性标识的帮助,我们可以明确地告诉程序集我们希望把属性放在哪儿。比如:
[assembly: Help("this a do-nothing assembly")]
这个Help属性前的assembly标识符显式地告诉了编译器,当前这个Help属性用于整个程序集。可用的标识符包括:
- assembly
- module
- type
- method
- property
- event
- field
- param
- return
在运行时查询属性
我们已经知道了如何创建属性并如何在程序中使用它们。现在该学习我们所建属性类的用户如何才能在运行时查询该属性类的信息了。要查询一个程序实体的所有属性信息,我们得使用反射(reflection)-在运行时发现类型信息的一种功能。
我们可以直接使用.NET Framework提供的反射Reflection API来枚举一个完整程序集的所有元数据(metadata),并产生该程序集所有类、类型、方法的列表。还记得之前的Help属性和AnyClass类吗?
using System;
using System.Reflection;
using System.Diagnostics;
//attaching Help attribute to entire assembly
[assembly : Help("This Assembly demonstrates custom attributes creation and their run-time query.")]
//our custom attribute class
public class HelpAttribute : Attribute
{
public HelpAttribute(String Description_in)
{
this.description = Description_in;
}
protected String description;
public String Description
{
get
{
return this.deescription;
}
}
}
//attaching Help attribute to our AnyClass
[HelpString("This is a do-nothing Class.")]
public class AnyClass
{
//attaching Help attribute to our AnyMethod
[Help("This is a do-nothing Method.")]
public void AnyMethod()
{
}
//attaching Help attribute to our AnyInt Field
[Help("This is any Integer.")]
public int AnyInt;
}
class QueryApp
{
public static void Main()
{
}
}
我们将在接下来的两节里在我们的Main方法里加入属性查询的代码。
查询程序集的属性
在接下来的代码片段里,我们获取当前进程的名字,并使用Assembly类的LoadFrom方法装载程序集。然后我们使用 GetCustomAttributes方法获取当前程序集的所有自定义属性。接下来的foreach语句又遍历所有的属性对象,并试着将这些属性转化为 Help属性(使用as关键字进行转换,如果转换失败,将会返回一个空值而不是触发一个异常)。再后的一条语句是指如果转换成功,则显示Help属性的所 有数据属性信息。
class QueryApp
{
public static void Main()
{
HelpAttribute HelpAttr;
//Querying Assembly Attributes
String assemblyName;
Process p = Process.GetCurrentProcess();
assemblyName = p.ProcessName + ".exe";
Assembly a = Assembly.LoadFrom(assemblyName);
foreach (Attribute attr in a.GetCustomAttributes(true))
{
HelpAttr = attr as HelpAttribute;
if (null != HelpAttr)
{
Console.WriteLine("Description of {0}:\n{1}", assemblyName,HelpAttr.Description);
}
}
}
}
程序的输出结果:
Description of QueryAttribute.exe: This Assembly demonstrates custom attributes creation and their run-time query. Press any key to continue
查询类、方法和域的属性
在下面的代码片段里,和上面的代码不同的只是Main方法的第一条语句变成了:
Type type = typeof(AnyClass);
它使用typeof操作符返回AnyClass对应的Type对象。其余的代码也类似上述的代码,我想不需要再做解释了吧。要查询方法和域的属性,我们首先要获得当前类中所有方法和类,然后再用类似于查询类的属性的方法来查询与之对应的属性。
class QueryApp
{
public static void Main()
{
Type type = typeof(AnyClass);
HelpAttribute HelpAttr;
//Querying Class Attributes
foreach (Attribute attr in type.GetCustomAttributes(true))
{
HelpAttr = attr as HelpAttribute;
if (null != HelpAttr)
{
Console.WriteLine("Description of AnyClass:\n{0}",
HelpAttr.Description);
}
}
//Querying Class-Method Attributes
foreach(MethodInfo method in type.GetMethods())
{
foreach (Attribute attr in method.GetCustomAttributes(true))
{
HelpAttr = attr as HelpAttribute;
if (null != HelpAttr)
{
Console.WriteLine("Description of {0}:\n{1}",
method.Name,
HelpAttr.Description);
}
}
}
//Querying Class-Field (only public) Attributes
foreach(FieldInfo field in type.GetFields())
{
foreach (Attribute attr in field.GetCustomAttributes(true))
{
HelpAttr= attr as HelpAttribute;
if (null != HelpAttr)
{
Console.WriteLine("Description of {0}:\n{1}",
field.Name,HelpAttr.Description);
}
}
}
}
}
下面是程序输出:
Description of AnyClass: This is a do-nothing Class. Description of AnyMethod: This is a do-nothing Method. Description of AnyInt: This is any Integer. Press any key to continue
关于作者
Sadaf Alvi,卡拉奇大学的自然科学学士,主页http://www24.brinkster.com/salvee



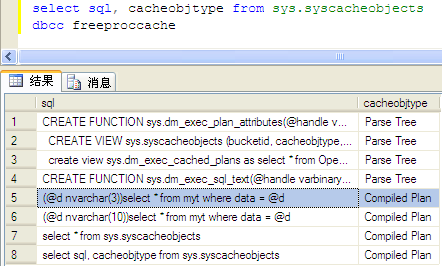
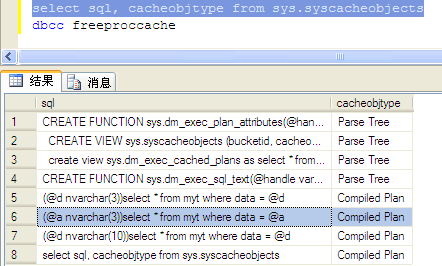
 declare @
declare @