最近很多时候都在用C#的集合类型,发现个问题:什么时候用Dictionary和Hashtable?哪个一个性能上指的是查询的时候更高效呢,于是MSDN上搜了一下,找到了如下文档,大概意思是Hashtable利用一个缓存池来存储被唯一赋予按哈西算法生成的hashcode的值对象,类似与数据库中的索引,查询的时候读取每个对象的hashcode从缓存池中进行查询,最关键的是最后一段,Dictionary也是利用hash算法存储对象的,不过存储非简单类型对象的时候也就是自定的类型和Object类型的对象性能上要比hasttable类型高。
下面引自MSDN:
Hashtable and Dictionary Collection Types
The Hashtable class and the Dictionary<(Of <(TKey, TValue>)>) generic class implement the IDictionary interface. The Dictionary<(Of <(TKey, TValue>)>) generic class also implements the IDictionary<(Of <(TKey, TValue>)>) generic interface. Therefore, each element in these collections is a key-and-value pair.
A Hashtable object consists of buckets that contain the elements of the collection. A bucket is a virtual subgroup of elements within the Hashtable, which makes searching and retrieving easier and faster than in most collections. Each bucket is associated with a hash code, generated using a hash function and based on the key of the element.
A hash function is an algorithm that returns a numeric hash code based on a key. The key is the value of some property of the object being stored. A hash function must always return the same hash code for the same key. It is possible for a hash function to generate the same hash code for two different keys, but a hash function that generates a unique hash code for each unique key results in better performance when retrieving elements from the hash table.
Each object that is used as an element in a Hashtable must be able to generate a hash code for itself using an implementation of the GetHashCode method. However, you can also specify a hash function for all elements in a Hashtable by using a Hashtable constructor that accepts an IHashCodeProvider implementation as one of its parameters.
When an object is added to a Hashtable, it is stored in the bucket that is associated with the hash code that matches the object's hash code. When a value is being searched for in the Hashtable, the hash code is generated for that value, and the bucket associated with that hash code is searched.
For example, a hash function for a string might take the ASCII codes of each character in the string and add them together to generate a hash code. The string “picnic” would have a hash code that is different from the hash code for the string “basket”; therefore, the strings “picnic” and “basket” would be in different buckets. In contrast, “stressed” and “desserts” would have the same hash code and would be in the same bucket.
The Dictionary<(Of <(TKey, TValue>)>) class has the same functionality as the Hashtable class. A Dictionary<(Of <(TKey, TValue>)>) of a specific type (other than Object) has better performance than a Hashtable for value types because the elements of Hashtable are of type Object and, therefore, boxing and unboxing typically occur if storing or retrieving a value type.

[MVC]ASP.NET MVC之AJAX
本文的例子基于ASP.NET MVC Preview 3,并采用了JQuery完成客户端的JavaScript功能。
之前的两篇文章粗粗的对ASP.NET MVC做了介绍。这里强烈推荐一个网站,有兴趣的朋友可以看这里。这是Rob Conery的个人网站,他采用了ASP.NET MVC做了一个Demo, 不仅在codeplex上提供了这个项目的源代码,还提供了15个视频,这些视频的内容包括从项目的构思、到设计、再到实现和重构的一个完整的过程。
ASP.NET Web Form下的AJAX
在传统的Asp.Net下,如果不使用Asp.Net Ajax或者如Ajax.Net此类第三方的框架,就需要一个空白的页面,并且在此页面的Page_Load方法中完成所有的服务器端的操作,通过 Response将数据传回客户端,提交给JavaScript来处理。各人认为,这种方法的一个不好的地方就是一个页面只能完成一项功能,即使这个功能 再简单。
ASP.NET MVC下的AJAX
在ASP.NET MVC中,每一个Request都被route到一个Controller下的Action来处理,即一个Controller Class的一个方法。因此,如果在Action方法中完成业务逻辑,并把需要回传的数据写回到Response中,在客户端再由JavaScript来 处理这些回传的数据,相信也能实现AJAX。基于这个想法,做了一个小小的Demo,实现了asp.net mvc下的ajax。
为了方便起见,客户端JavaScript的功能就通过JQuery来实现了。
页面文件:
1
 <h2>Lunch Tracker List</h2>
<h2>Lunch Tracker List</h2>2
<hr />3
<!–<% using( Html.Form<LunchController>( lc => lc.Search(), FormMethod.Post )) { %>–>4
<form id="UsersForm">5
Choose User:<%= Html.DropDownList("Users", new SelectList(ViewData.Model.Users, "ID", "UserName"), new { id = "userName" })%> <input type="button" id="btnSearchLunch" value="Show All" />6
</form>7
<!–<%} %>–>8
<br />9
<p id="userlunchlist">10
11
</p>12
 <script type="text/javascript">
<script type="text/javascript">

13
 $(document).ready(
$(document).ready(14
function()15
 {
{
16
$("#btnSearchLunch").click(function()17
{18
var userName = $("#userName").val();19
$.get("/Lunch/SearchUserAjax", { name:userName }, function(data)20
{21
$("p#userlunchlist").empty();22
$("p#userlunchlist").append(data);23
$("p#userlunchlist table").show("slow");24
 });
});25
}); 26
}27
 );
);28
</script>其中的$(document).ready(…..)是jQuery下的JavaScript实现,有兴趣的朋友可以看看jQuery官网和中文社区。
在来看一下Controller中的对应的Action方法:
1 public void SearchUserAjax()
2 {
3 string uerid = Request["name"];
4
5 List<UserLunchList> lunchs = (
6 from userlunch in repository.UserLunchLists.ToList()
7 where userlunch.UserID == int.Parse(uerid)
8 select userlunch
9 ).ToList();
10 StringBuilder sb = new StringBuilder();
11 sb.Append("<table id='LunchList' style='display:none'><tr><th>User</th><th>Time</th><th>Price</th></tr>");
12 foreach (UserLunchList lunch in lunchs)
13 {
14 sb.Append("<tr><td>" + lunch.User.UserName + "</td><td>" + lunch.Time.ToShortDateString() + "</td><td>" + lunch.Cost + "</td></tr>");
15 }
16 sb.Append("</table>");
17 Response.ContentType = "text/html";
18 Response.Write(sb.ToString());
19 }
public void SearchUserAjax()2
{3
string uerid = Request["name"];4
5
List<UserLunchList> lunchs = (6
from userlunch in repository.UserLunchLists.ToList()7
where userlunch.UserID == int.Parse(uerid)8
select userlunch9
).ToList();10
StringBuilder sb = new StringBuilder();11
sb.Append("<table id='LunchList' style='display:none'><tr><th>User</th><th>Time</th><th>Price</th></tr>");12
foreach (UserLunchList lunch in lunchs)13
{14
sb.Append("<tr><td>" + lunch.User.UserName + "</td><td>" + lunch.Time.ToShortDateString() + "</td><td>" + lunch.Cost + "</td></tr>");15
}16
sb.Append("</table>");17
Response.ContentType = "text/html";18
Response.Write(sb.ToString());19
}说穿了很简单,就是把想要的数据直接写到Response中就可以了,这里为了方便起见,就是写好了Table的格式。有一个地方需要注意的就是这个语句
Response.ContentType = "text/html" 很重要,它告知JavaScript以何种格式来处理Response中的数据。
核心内容就这么简单,呵呵。
如果觉得写JavaScript代码烦的话,可以使用extension方法,自定一个Html.Form或者其它的控件。
Sample Code
[MVC]推荐一个基于Microsoft ASP.NET MVC Preview 2 的应用示例
园子里介绍Mircosoft MVC的文章已经有不少了,其中还有一些入门的系列示例很不错.
但是如果要使用这个东西开发应用的话,项目结构,代码分布上还有一些细节问题.当然每
个人可以会根据自己的实际开发经验进行分层设计.但我还是比较关注微软工程师们在使用
这个框架开发时的方式和习惯.所幸在MVC的官方链接上有这样一个应用,它就是采用MVC
框架进行架构的,当然还有一组视频从设计,集成测试等方面来介绍使用MVC框架.所以本
人就在这里借花献佛了:)
它的源码下载链接:点击这里
设计和测试视频:点击这里
当然如果这编译和运行这个应用,还需要Unity框架支持
它的installer 下载链接:点击这里
source code 链接: 点击这里
注意:示例应用的MVC版本为Microsoft ASP.NET MVC Preview 2,因为MVC框架更
新速度很快(基本上两三个月就一个版本),所以如果下载是Preview3的话,会在编译时报错.
下面是这个产品示例的物理文件截图:)

其实就目前看来MVC还是一个试用性产品,离投入实际应用还待时日.所以园子中观望学
习的多,敢于吃螃蟹的少.不过本人希望到今年年底可以正式应用它来做一些软件.目前也只
能骑毛驴看唱本了:)
[Flex]整合Flex和Java—配置篇
uthor:yongtree
废话就不说了,要想了解Flex的相关内容就请问一下Google,百度吧。切入正题,作为一个Java程序员学习Flex,关心的就是怎样将Flex和Java进行结合交互。带着Java程序员的思维,一开始学习Flex并没有按部就班的学习Flex的基础知识,而是想搞清楚Flex到底怎样和Java交互的。经过了一个周末的研究,终于初见成果,下面就重要的讲解三种配置的两个。
在分享这几种配置之前,先简单的介绍一下需要用到的一些资源。
1、 MyEclipse+Flex插件(官网下载)
2、 Tomcat6.0作为服务器(官网下载)
3、 用BlazeDS(免费)代替LCDS(收费):没钱啊,只能先使用免费的了。从Adobe官方网站上下载下来,将blazeds.war、ds-console.war、samples.war三个文件放在tomcat的webapps目录下。
Flex+Java配置:
第一种:Java工程和Flex工程独立,这种方式也是很多人使用的方式,Flex程序员和Java程序员相互独立的工作,这种方式网上有很多的资料,在这里就不再 赘述了。
第二种:Flex工程加入Java元素
1、 切换到Flex视图,新建Flex project,如下图
|
因为我们是要java和flex结合,所以在服务器选择上我们选择J2EE
|
|
存放java类的源文件,我们的目的就是Flex和java在一个工程里,所以我们这里选择上
|
|
|
说明:Java source folder就是你自己java业务源码存放的根目录,在FB3里,LCDS项目旨在将Java J2ee项目和FlexLcds项目混合。
当然如果你不选择 combined 两个在一起,那么就麻烦些:要么你再单独新建一个Flex项目,而这个项目只写java代码。要么再建一个J2ee工程写java代码,而这个项目只写Flex代码,但最后要把Java编译后的class文件放到这个项目下的webroot\web-inf\classes目录中。即不管怎样,最后发布时,java编译后的class文件必须和lcds部署的项目在一起。
2、 点击Next,配置J2EE服务器,如下图
|
这里我们可以自定义输出路径,一般情况下设置成根目录WebRoot就可以了 |
|
因为我们采用的BlazeDS,所以这里要设置BlazeDS的路径 |
|
|
说明:Target runtime实际上没什么用(后来我删除了配置文件里的对应信息,也没问题),但是不指定就不能继续,如果这里显示的是<none>那么就新建一个Tomcat的runtime,简单的只需要指定tomcat的安装目录即可。
Content folder实际上就是最终编译后的容器目录,因此,BlazeDS的blazeds.war文件将会发布到 该目录 下的web-inf下的flex目录中。同时因为教程采用的是MyEclipse,他默认的就是发布WebRoot里的内容,为了自动化,因此这里改为了WebRoot(这也是java开发的习惯)
Flex WAR file 指的是安装了lcds后的flex.war文件的路径,但是在这里我们采用的是BlazeDS来取代lcds,所以这里设置的是blazeds.war的路径。
Compilation options指定了flex文件的编译方式,选择推荐的在FlexBuilder里编译吧,虽然开发时多耗点时间,但是在发布后不会占用服务器的编译处理时间,对用户来说是有好处的。
Output folder 指的是Flex编译后的swf和html等文件存放的路径,这里改为了WebRoot,意思是发布到根目录就可以了。当然你可以根据你的需要和习惯自行设置其他的路径
3、 点击下一步,采用默认的配置就可以,点击完成,该工程就建立完成。下图为该工程的目录结构
|
Flex编译后发布的文件。我们发布在根目录下 |
|
自动生成的flex的配置文件 |
|
Java源文件夹 |
|
Flex文件的源文件夹 |
|
|
4、 让它变成web工程由MyEclipse发布吧
|
|
|
注意,不要点的太快了,要把这里的对号勾掉,这样就不会覆盖BlazeDS创建的web.xml |
|
|
点击Finish,现在我们的工程的图标变成了J2EE Web 工程了,这意味着,你可以用MyEclipse来发布它或者添加更多容器,比如hibernate、spring等
5、 工程建好以后,你可以通过右键—>属性来进行更多的设置。
|
|
6、 这样一个Flex+Java的工程就建立完成。
7、 编写例子,测试在介绍完第三种方式以后统一介绍。
第三种:由Web project反向加入Flex,也就是Java+Flex
1、 先建立一个web工程:flexweb。(略)
2、 向flexweb工程手工添加Flex需要的元素。
1)首先将BlazeDS需要的jar文件拷到工程的lib目录下。可以将上面建的那个flex工程的lib下的jar文件拷到该工程下的lib目录下。
2)然后要加入Flex BlazeDS需要的配置文件。在WEB-INF下新建一个名为flex的文件夹,然后将我们上面建立的那个firstFlex该文件夹下的四个xml文件拷到该文件夹下。
3)最后,修改web.xml文件,加入Flex的配置。做法一个简单的把上面我们新建的那个flex工程的web.xml的部分代码拷过来。
<context-param>
<param-name>flex.class.path</param-name>
<param-value>/WEB-INF/flex/hotfixes,/WEB-INF/flex/jars</param-value>
</context-param>
<!– Http Flex Session attribute and binding listener support –>
<listener>
<listener-class>flex.messaging.HttpFlexSession</listener-class>
</listener>
<!– MessageBroker Servlet –>
<servlet>
<servlet-name>MessageBrokerServlet</servlet-name>
<display-name>MessageBrokerServlet</display-name>
<servlet-class>flex.messaging.MessageBrokerServlet</servlet-class>
span
- 整合Flex和Java–配置篇.rar (773.6 KB)
- 描述: 整合Flex和java的三种方式
- 下载次数: 21
[Flex]FLEX资源---------手把手实现WebService服务与通讯
FLEX与后台交互的方式不外乎那三 种:HttpService,WebService,remoteObject.虽然从个人的角度我对WebService有些偏见(效率不高),可能因 为我是JAVA程序员,所以更喜爱RO这种专属于JAVA数据传输的高效,但WS带上了SOAP的帽子或许很多时候还是能起到关键作用,最近负责了一个 FLEX AIR项目就完全基于WS,所以也把WS拿出来说说.在FLEX里实现与后台的交互是相当方便的.语法瞧几眼大家都会,
我这里把关键的代码贴一下:
Java代码 
- <?xml version="1.0" encoding="utf-8"?>
- <mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
- <mx:Script>
- <![CDATA[
- import mx.rpc.events.FaultEvent;
- import mx.rpc.events.ResultEvent;
- private function resultHanlder(e:ResultEvent):void{
- msg.text=e.result.toString();
- }
- private function falutHanlder(e:FaultEvent):void{
- msg.text=e.message.toString();
- }
- ]]>
- </mx:Script>
- <mx:WebService wsdl="http://localhost:8080/axis2/services/AccountService?wsdl" id="testService" showBusyCursor="true"
- useProxy="false">
- <mx:operation name="withdraw" result="resultHanlder(event);">
- <mx:request xmlns="">
- <money>
- {parseInt(param.text)}
- </money>
- </mx:request>
- </mx:operation>
- </mx:WebService>
- <mx:TextArea id="msg"/>
- <mx:TextInput id="param"/>
- <mx:Button label="sendMsg" click="testService.withdraw.send();"/>
- </mx:Application>
至于后端如何实现WEBService我有一个不错的文档,照着上面的操作流程图一步步来,相信不会出什么大问题.
[教程]理解.NET中的数据库连接池
理解.NET中的数据库连接池
 作者 Joydip Kanjilal
作者 Joydip Kanjilal
摘要:
连接池能在程度上提高数据库访问性能。本文讨论到底何为连接池,它如何提高数据库访问性能,以及如何在.NET中创建连接池并增加或移除连接。
导言
连 接数据库是应用程序中耗费大量资源且相对较慢的操作,但它们又是至关紧要的。连接池是已打开的及可重用的数据库连接的一个容器。连接池在所有的数据库连接 都关闭时才从内存中释放。使用连接池最基本的好处是提高应用程序的性能及可伸缩性,而其主要缺点是会有一个或多个数据库连接将一直保持打开状态,即使当前 不在使用。ADO.NET的Data Providers将默认情况下将使用连接池,如果你不想使用连接池,必须在连接字符串中指定 ”Polling=false”。连接池中为你提供了空闲的打开的可重用的数据库连接,而不再需要每次在请求数据库数据时新打开一个数据库连接。当数据库 连接关闭或释放时,将返回到连接池中保持空闲状态直到新的连接请求到来。如果我们有效地使用连接池,打开和关闭数据库将不再很耗费资源。本文讨论连接池的 相关内容以及如何有效的使用连接池来提高应用程序的效率及可伸缩性。
连接池如何工作
连 接池中包含打开的可重用的数据库连接。在同一时刻同一应用程序域中可以有多个连接池,但连接池不可以跨应用程序域共享。注意:一个连接池是通过一个唯一的 连接字符串来创建。连接池是根据第一次请求数据库连接的连接字符串来创建的,当另外一个不同的连接字符串请求数据库连接时,将创建另一个连接池。因此一个 连接字符中对应一个连接池而不是一个数据库对应一个连接池。如以下代码所示
代码1
// 新建一个连接池
SQLConnection SQLConnection = new SqlConnection();
sqlConnection.ConnectionString =
"Server=localhost;Database=test;User ID=joydip;Password=joydip;Trusted_Connection=False";
sqlConnection.Open();
代码2
// 因为连接字符串不同,新建另一个连接池
SqlConnection conn = new SqlConnection();
sqlConnection.ConnectionString =
"Server=localhost;Database=test;User ID=test;Password=test;Trusted_Connection=False";
sqlConnection.Open();
代码3
// 因为连接字符串与代码1相同,不再创建连接池.
SqlConnection conn = new SqlConnection();
sqlConnection.ConnectionString =
"Server=localhost;Database=test;User ID=joydip;Password=joydip;Trusted_Connection=False";
sqlConnection.Open();
当 有新的数据库连接请求到来时,连接池中连接进行了响应而不用创建一个新的数据库连接,也就是说数据库连接可以被重用,而不需要重新新建连接。因此这提高了 应用程序的效率和可伸缩性。当你在应用程序中关闭一个打开的数据库连接时,该连接返回到连接池中等待重新连接直到等待超时。在这个时间内等待同一数据库相 同连接信息的连接请求。如果这个时间内没有连接请求,这个数据库连接将被关闭,并从连接池中移除这个连接实例。
当一个新的连接池创建后,数据库连接被添加到池中,连接池和池中的连接立即可被使用。连接池中将填满连接字个串中指定的最小连接数量的连接。连接池中连接在长时间不活动或超出指定的生存期时将被移除。
连接池由连接池管理器维护。当后续的连接请求到来,连接池管理器在连接池中寻找可用的空闲的连接,如果存在就交给应用程序使用。以下描述了当一个新的连接请求到来时连接管理器如何工作
· 如果有未用连接可用,返回该连接
· 如果池中连接都已用完,创建一个新连接添加到池中
· 如果池中连接已达到最大连接数,请求进入等待队列直到有空闲连接可用
通过连接字符串中传递的参数可以控制连接池。基本的参数包括:
· Connect Timeout
· Min Pool Size
· Max Pool Siz
· Pooling
为了有效的使用连接池,记住数据库操作完成后马上关闭连接,这样连接才能返回连接池中。
提高连接池性能
我 们应该在最晚时刻打开连接并在最早时刻释放连接,即在使用完成后立即释放。数据库连接应该在真正请求数据时才打开,而不应在使用之前就请求连接,这会减少 池中可用连接的数量,因此有害于连接池的操作及应用程序性能。数据库连接应使用完成后立即释放,这能促进连接池更好的使用,因为连接可以返回池中被重新使 用。以下代码展示如何在应用程序中有效地打开和关闭连接
代码4
SqlConnection sqlConnection = new SqlConnection(connectionString);
try
{
sqlConnection.Open();
//Some Code
}
finally
{
sqlConnection.Close();
}
代码4可以使用”using”关键字进一步简化如以下代码所示
代码5
using(SqlConnection sqlConnection = new SqlConnection(connectionString))
{
sqlConnection.Open();
//Some Code
}
注:以上代码5中的”using”关键字将隐含地生成try-finally块
以下列举了更好地使用连接池的几个可参考要点
· 在需要使用时才打开连接,并在完成操作后马上关闭
· 在关闭连接时先关闭相关用户定义的事务
· 确保维持连接池中至少有一个打开的连接
· 在使用集成身份验证的情况下避免使用连接池
连接池可以通过以下途径进行监控
· 使用sp_who或sp_who2存储过程
· 使用SQL Server的Profiler
· 使用性能监视器的性能计数器
参考文献
Tuning Up ADO.NET Connection Pooling in ASP.NET Applications
Connection Pooling for the .NET Framework Data Provider for SQL Server
The .NET Connection Pool Lifeguard
ADO.NET Connection Pooling Explained
结语
连 接池是数据库连接对象的容器,只要其中存在活动的或打开的连接它维持活动状态。当使用一个连接字符串来请求数据库连接时,将分配一个新的连接池。通过在应 用程序中使用相同的连接字符串我们可以提高应用程序的性能和可伸缩性。然而如果我们不正确地使用连接池可能给我们的应用程序带来负效果。MSDN中说“连 接是提高应用程序性能的有力工具,但如果使用不当连接池非但不是有益的而且是害的”。本文讨论了连接池的相关内容以及如何有效的使用连接池来提高应用程序 的效率及可伸缩性。
[教程][Serializable]在C#中的作用-NET 中的对象序列化
简介
序列化是指将对象实例的状态存储到存储媒体的过程。在此过程中,先将对象的公共字段和私有字段以及类的名称(包括类所在的程序集)转换为字节流,然后再把字节流写入数据流。在随后对对象进行反序列化时,将创建出与原对象完全相同的副本。
在面向对象的环境中实现序列化机制时,必须在易用性和灵活性之间进行一些权衡。只要您对此过程有足够的控制能力,就可以使该过程在很大程度上自动进 行。例如,简单的二进制序列化不能满足需要,或者,由于特定原因需要确定类中那些字段需要序列化。以下各部分将探讨 .NET 框架提供的可靠的序列化机制,并着重介绍使您可以根据需要自定义序列化过程的一些重要功能。
持久存储
我们经常需要将对象的字段值保存到磁盘中,并在以后检索此数据。尽管不使用序列化也能完成这项工作,但这种方法通常很繁琐而且容易 出错,并且在需要跟踪对象的层次结构时,会变得越来越复杂。可以想象一下编写包含大量对象的大型业务应用程序的情形,程序员不得不为每一个对象编写代码, 以便将字段和属性保存至磁盘以及从磁盘还原这些字段和属性。序列化提供了轻松实现这个目标的快捷方法。
公共语言运行时 (CLR) 管理对象在内存中的分布,.NET 框架则通过使用反射提供自动的序列化机制。对象序列化后,类的名称、程序集以及类实例的所有数据成员均被写入存储媒体中。对象通常用成员变量来存储对其他 实例的引用。类序列化后,序列化引擎将跟踪所有已序列化的引用对象,以确保同一对象不被序列化多次。.NET 框架所提供的序列化体系结构可以自动正确处理对象图表和循环引用。对对象图表的唯一要求是,由正在进行序列化的对象所引用的所有对象都必须标记为 Serializable(请参阅基本序列化)。否则,当序列化程序试图序列化未标记的对象时将会出现异常。
当反序列化已序列化的类时,将重新创建该类,并自动还原所有数据成员的值。
按值封送
对象仅在创建对象的应用程序域中有效。除非对象是从 MarshalByRefObject 派生得到或标记为 Serializable,否则,任何将对象作为参数传递或将其作为结果返回的尝试都将失败。如果对象标记为 Serializable,则该对象将被自动序列化,并从一个应用程序域传输至另一个应用程序域,然后进行反序列化,从而在第二个应用程序域中产生出该对 象的一个精确副本。此过程通常称为按值封送。
如果对象是从 MarshalByRefObject 派生得到,则从一个应用程序域传递至另一个应用程序域的是对象引用,而不是对象本身。也可以将从 MarshalByRefObject 派生得到的对象标记为 Serializable。远程使用此对象时,负责进行序列化并已预先配置为 SurrogateSelector 的格式化程序将控制序列化过程,并用一个代理替换所有从 MarshalByRefObject 派生得到的对象。如果没有预先配置为 SurrogateSelector,序列化体系结构将遵从下面的标准序列化规则(请参阅序列化过程的步骤)。
基本序列化
要使一个类可序列化,最简单的方法是使用 Serializable 属性对它进行标记,如下所示:
[Serializable]
public class MyObject {
public int n1 = 0;
public int n2 = 0;
public String str = null;
}
以下代码片段说明了如何将此类的一个实例序列化为一个文件:
MyObject obj = new MyObject();
obj.n1 = 1;
obj.n2 = 24;
obj.str = "一些字符串";
IFormatter formatter = new BinaryFormatter();
Stream stream = new FileStream("MyFile.bin", FileMode.Create,
FileAccess.Write, FileShare.None);
formatter.Serialize(stream, obj);
stream.Close();
本 例使用二进制格式化程序进行序列化。您只需创建一个要使用的流和格式化程序的实例,然后调用格式化程序的 Serialize 方法。流和要序列化的对象实例作为参数提供给此调用。类中的所有成员变量(甚至标记为 private 的变量)都将被序列化,但这一点在本例中未明确体现出来。在这一点上,二进制序列化不同于只序列化公共字段的 XML 序列化程序。
将对象还原到它以前的状态也非常容易。首先,创建格式化程序和流以进行读取,然后让格式化程序对对象进行反序列化。以下代码片段说明了如何进行此操作。
IFormatter formatter = new BinaryFormatter();
Stream stream = new FileStream("MyFile.bin", FileMode.Open,
FileAccess.Read, FileShare.Read);
MyObject obj = (MyObject) formatter.Deserialize(fromStream);
stream.Close();
// 下面是证明
Console.WriteLine("n1: {0}", obj.n1);
Console.WriteLine("n2: {0}", obj.n2);
Console.WriteLine("str: {0}", obj.str);
上 面所使用的 BinaryFormatter 效率很高,能生成非常紧凑的字节流。所有使用此格式化程序序列化的对象也可使用它进行反序列化,对于序列化将在 .NET 平台上进行反序列化的对象,此格式化程序无疑是一个理想工具。需要注意的是,对对象进行反序列化时并不调用构造函数。对反序列化添加这项约束,是出于性能 方面的考虑。但是,这违反了对象编写者通常采用的一些运行时约定,因此,开发人员在将对象标记为可序列化时,应确保考虑了这一特殊约定。
如果要求具有可移植性,请使用 SoapFormatter。所要做的更改只是将以上代码中的格式化程序换成 SoapFormatter,而 Serialize 和 Deserialize 调用不变。对于上面使用的示例,该格式化程序将生成以下结果。
<SOAP-ENV:Envelope
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:SOAP- ENC=http://schemas.xmlsoap.org/soap/encoding/
xmlns:SOAP- ENV=http://schemas.xmlsoap.org/soap/envelope/
SOAP-ENV:encodingStyle=
"http://schemas.microsoft.com/soap/encoding/clr/1.0
http://schemas.xmlsoap.org/soap/encoding/"
xmlns:a1="http://schemas.microsoft.com/clr/assem/ToFile">
<SOAP-ENV:Body>
<a1:MyObject id="ref-1">
<n1>1</n1>
<n2>24</n2>
<str id="ref-3">一些字符串</str>
</a1:MyObject>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
需 要注意的是,无法继承 Serializable 属性。如果从 MyObject 派生出一个新的类,则这个新的类也必须使用该属性进行标记,否则将无法序列化。例如,如果试图序列化以下类实例,将会显示一个 SerializationException,说明 MyStuff 类型未标记为可序列化。
public class MyStuff : MyObject
{
public int n3;
}
使用序列化属性非常方便,但是它存在上述的一些限制。有关何时标记类以进行序列化(因为类编译后就无法再序列化),请参考有关说明(请参阅下面的序列化规则)。
选择性序列化
类通常包含不应被序列化的字段。例如,假设某个类用一个成员变量来存储线程 ID。当此类被反序列化时,序列化此类时所存储的 ID 对应的线程可能不再运行,所以对这个值进行序列化没有意义。可以通过使用 NonSerialized 属性标记成员变量来防止它们被序列化,如下所示:
[Serializable]
public class MyObject
{
public int n1;
[NonSerialized] public int n2;
public String str;
}
自定义序列化
可 以通过在对象上实现 ISerializable 接口来自定义序列化过程。这一功能在反序列化后成员变量的值失效时尤其有用,但是需要为变量提供值以重建对象的完整状态。要实现 ISerializable,需要实现 GetObjectData 方法以及一个特殊的构造函数,在反序列化对象时要用到此构造函数。以下代码示例说明了如何在前一部分中提到的 MyObject 类上实现 ISerializable。
[Serializable]
public class MyObject : ISerializable
{
public int n1;
public int n2;
public String str;
public MyObject()
{
}
protected MyObject(SerializationInfo info, StreamingContext context)
{
n1 = info.GetInt32("i");
n2 = info.GetInt32("j");
str = info.GetString("k");
}
public virtual void GetObjectData(SerializationInfo info,
StreamingContext context)
{
info.AddValue("i", n1);
info.AddValue("j", n2);
info.AddValue("k", str);
}
}
在 序列化过程中调用 GetObjectData 时,需要填充方法调用中提供的 SerializationInfo 对象。只需按名称/值对的形式添加将要序列化的变量。其名称可以是任何文本。只要已序列化的数据足以在反序列化过程中还原对象,便可以自由选择添加至 SerializationInfo 的成员变量。如果基对象实现了 ISerializable,则派生类应调用其基对象的 GetObjectData 方法。
需要强调的是,将 ISerializable 添加至某个类时,需要同时实现 GetObjectData 以及特殊的构造函数。如果缺少 GetObjectData,编译器将发出警告。但是,由于无法强制实现构造函数,所以,缺少构造函数时不会发出警告。如果在没有构造函数的情况下尝试反 序列化某个类,将会出现异常。在消除潜在安全性和版本控制问题等方面,当前设计优于 SetObjectData 方法。例如,如果将 SetObjectData 方法定义为某个接口的一部分,则此方法必须是公共方法,这使得用户不得不编写代码来防止多次调用 SetObjectData 方法。可以想象,如果某个对象正在执行某些操作,而某个恶意应用程序却调用此对象的 SetObjectData 方法,将会引起一些潜在的麻烦。
在反序列化过程中,使用出于此目的而提供的构造函数将 SerializationInfo 传递给类。对象反序列化时,对构造函数的任何可见性约束都将被忽略,因此,可以将类标记为 public、protected、internal 或 private。一个不错的办法是,在类未封装的情况下,将构造函数标记为 protect。如果类已封装,则应标记为 private。要还原对象的状态,只需使用序列化时采用的名称,从 SerializationInfo 中检索变量的值。如果基类实现了 ISerializable,则应调用基类的构造函数,以使基础对象可以还原其变量。
如果从实现了 ISerializable 的类派生出一个新的类,则只要新的类中含有任何需要序列化的变量,就必须同时实现构造函数以及 GetObjectData 方法。以下代码片段显示了如何使用上文所示的 MyObject 类来完成此操作。
[Serializable]
public class ObjectTwo : MyObject
{
public int num;
public ObjectTwo() : base()
{
}
protected ObjectTwo(SerializationInfo si, StreamingContext context) :
base(si,context)
{
num = si.GetInt32("num");
}
public override void GetObjectData(SerializationInfo si,
StreamingContext context)
{
base.GetObjectData(si,context);
si.AddValue("num", num);
}
}
切记要在反序列化构造函数中调用基类,否则,将永远不会调用基类上的构造函数,并且在反序列化后也无法构建完整的对象。
对象被彻底重新构建,但是在反系列化过程中调用方法可能会带来不良的副作用,因为被调用的方法可能引用了在调用时尚未反序列化的对象引用。如果正在 进行反序列化的类实现了 IDeserializationCallback,则反序列化整个对象图表后,将自动调用 OnSerialization 方法。此时,引用的所有子对象均已完全还原。有些类不使用上述事件侦听器,很难对它们进行反序列化,散列表便是一个典型的例子。在反序列化过程中检索关键 字/值对非常容易,但是,由于无法保证从散列表派生出的类已反序列化,所以把这些对象添加回散列表时会出现一些问题。因此,建议目前不要在散列表上调用方 法。
序列化过程的步骤
在格式化程序上调用 Serialize 方法时,对象序列化按照以下规则进行:
检查格式化程序是否有代理选取器。如果有,检查代理选取器是否处理指定类型的对象。如果选取器处理此对象类型,将在代理选取器上调用 ISerializable.GetObjectData。
如果没有代理选取器或有却不处理此类型,将检查是否使用 Serializable 属性对对象进行标记。如果未标记,将会引发 SerializationException。
如果对象已被正确标记,将检查对象是否实现了 ISerializable。如果已实现,将在对象上调用 GetObjectData。
如果对象未实现 Serializable,将使用默认的序列化策略,对所有未标记为 NonSerialized 的字段都进行序列化。
版本控制
.NET 框架支持版本控制和并排执行,并且,如果类的接口保持一致,所有类均可跨版本工作。由于序列化涉及的是成员变量而非接口,所以,在向要跨版本序列化的类中 添加成员变量,或从中删除变量时,应谨慎行事。特别是对于未实现 ISerializable 的类更应如此。若当前版本的状态发生了任何变化(例如添加成员变量、更改变量类型或更改变量名称),都意味着如果同一类型的现有对象是使用早期版本进行序 列化的,则无法成功对它们进行反序列化。
如果对象的状态需要在不同版本间发生改变,类的作者可以有两种选择:
实现 ISerializable。这使您可以精确地控制序列化和反序列化过程,在反序列化过程中正确地添加和解释未来状态。
使用 NonSerialized 属性标记不重要的成员变量。仅当预计类在不同版本间的变化较小时,才可使用这个选项。例如,把一个新变量添加至类的较高版本后,可以将该变量标记为 NonSerialized,以确保该类与早期版本保持兼容。
序列化规则
由 于类编译后便无法序列化,所以在设计新类时应考虑序列化。需要考虑的问题有:是否必须跨应用程序域来发送此类?是否要远程使用此类?用户将如何使用此类? 也许他们会从我的类中派生出一个需要序列化的新类。只要有这种可能性,就应将类标记为可序列化。除下列情况以外,最好将所有类都标记为可序列化:
所有的类都永远也不会跨越应用程序域。如果某个类不要求序列化但需要跨越应用程序域,请从 MarshalByRefObject 派生此类。
类存储仅适用于其当前实例的特殊指针。例如,如果某个类包含非受控的内存或文件句柄,请确保将这些字段标记为 NonSerialized 或根本不序列化此类。
某些数据成员包含敏感信息。在这种情况下,建议实现 ISerializable 并仅序列化所要求的字段。
[教程]Membership扩展
| 转]用好VS2005之扩展membership服务 |
|
ASP.NET 2.0中新增的最佳功能之一是新的成员身份服务,它提供了用于创建和管理用户帐户的易于使用的API
ASP.NET 2.0中新增的最佳功能之一是新的成员身份服务,它提供了用于创建和管理用户帐户的易于使用的API。ASP.NET 1.x大规模引入了窗体身份验证,但仍然要求您编写相当数量的代码来执行实际操作中的窗体身份验证。成员身份服务填补了ASP.NET 1.x窗体身份验证服务的不足,并且使实现窗体身份验证变得比以前简单得多。
成员身份API 通过两个新的类公开:Membership和MembershipUser。前者包含了用于创建用户、验证用户以及完成其他工作的静态方法。 MembershipUser代表单个用户,它包含了用于检索和更改密码、获取上次登录日期以及完成类似工作的方法和属性。通过这两个新的类,我们可以不 用写一行代码,方便得完成对用户的管理。 但是在实际开发过程中,绝对不能满足我们日常开发的需要。经过日常项目的开发和网络上资料的搜索,现将其一一列出:
微软给我们提供了一个Aspnet_regsql的命令来修改默认数据库。打开 Visual Studio 2005 命令提示,输入aspnet_regsql,按照提示一步一步进行即可。
此时打开数据库,可以发现多处来了一系列"aspnet_"开头的存储过程,这就是我们使用membership所必需的存储过程。
此时打开IIS,[属性] →[ASP.NET] →[编辑配置]:
[常规],连接参数LocalSQLServer按照普通的sql连接字符串格式。
[身份验证],模式为Forms,管理提供程序的minRequiredNonalphanumericCharacters为0,这时就可以去掉默认变态的必需需要输入字母,数字等组合的密码安全了。此步也可修改密码最低长度和最大长度等等。
经过此步骤,系统会自动在web.config中配置好了我们所需的规则。很方便,修改web.config以后都可以通过这种图形化工具来了。
二、由于自带的login控件和membership类,只提供了简单的用户信息录入,不能满足我们项目的需要。例如:我们要用户注册的时候同时输入 QQ号码,电话号码,家庭地址。那么默认的是没有办法解决的。我这里给出两种解决方案。我分别用在了不同的项目中。优缺点大家自行判断。
1、使用profile。此类方法网上教程已经很多。不在出重复叙述,免去赚稿费的嫌疑:)。这里只是给出网上没有的部分说明。
由于membership只能列出来指定组的用户名,而不能列出其他的详细信息,我们实际使用中,往往需要对组中的其它信息进行同时修改。我采用的是自行构造datatable的方法。见代码: public static DataTable listuser(string userRoles)//列出指定组的用户信息
{ string[] users = Roles.GetUsersInRole(userRoles); //列出指定组下的用户 DataTable dt = new DataTable(); dt.Columns.Add("username", System.Type.GetType("System.String")); dt.Columns.Add("QQ", System.Type.GetType("System.String")); dt.Columns.Add("phone", System.Type.GetType("System.String")); dt.Columns.Add("address", System.Type.GetType("System.String")); dt.Columns.Add("email", System.Type.GetType("System.String")); //以上构造一个数据表 foreach (string i in users) { DataRow dr = dt.NewRow(); MembershipUser mu = Membership.GetUser(i); 得到用户基本信息 ProfileCommon p = Profile.GetProfile(i); //得到用户的profile信息 dr[0] = mu. username; dr[1] = p. QQ; //profile是强类型,可以很方便的通过感知来添加。 dr[2] = p. phone; dr[3] = p. address; dr[4] = mu. email; dt.Rows.Add(dr); dt.AcceptChanges(); } return dt; } public static void deleteuser(string username)/删除指定用户 { Membership.DeleteUser(username); //系统会自动删除profile下的指定用户的信息 } public static void updateuser(string username)/更新指定用户 { ProfileCommon p = Profile.GetProfile(i); //得到用户的profile信息 p. phone="电话"; p. address="地址; p. QQ="QQ号码"; p.Save(); //保存所作修改。 } 2、自定义一个membershipinfo表格,同membership系统标关联起来。自己编写SQL语句来进行查询,修改等功能。
列出指定组的用户
select * from aspnet_membership inner join aspnet_users on aspnet_membership.userid=aspnet_users.userid left join memberinfo on aspnet_membership.userid=memberinfo.userid where aspnet_membership.userid=(select userid from aspnet_usersinroles inner join aspnet_roles on aspnet_usersinroles.roleid=aspnet_roles.roleid where rolename='admin') 删除、修改等功能比较简单,这里就不作叙述。可以采用membership的createuser方法建立,然后再用sql语句写入memberinfo表。 对于建立用户,我们可以采取扩展CreateUserWizard控件,或者自行写登陆界面。
1、采取扩展CreateUserWizard控件,我们可以使用它的模版列,此时需要注意的是:用户名,密码,提示问题,提示问题答案,Email, 他们的ID一定要分别是username,Password,Question,Answer,Email否则会出错,而且此时验证控件均不能使用。怀疑 是IDE的一个Bug。
如下所示,我们定义好的样式应当是:
<WizardSteps>
<asp:CreateUserWizardStep runat="server"> 自定义代码部分<ContentTemplate> </ContentTemplate> </asp:CreateUserWizardStep> </WizardSteps> 代码部分: protected void CreateUserWizard1_CreatedUser(object sender, EventArgs e) { //由于系统会自动给们建立基本的信息表,所以我们只需要对profile或者membershipinfo标进行修改即可。 Roles.AddUserToRole(CreateUserWizard1.UserName, "shop"); //添加用户到相应的组 ProfileCommon p = (ProfileCommon)ProfileCommon.Create(CreateUserWizard1.UserName, true); p. QQ = ((TextBox)CreateUserWizard1.CreateUserStep.ContentTemplateContainer.FindControl("QQ")).Text.Trim(); p.address= ((TextBox)CreateUserWizard1.CreateUserStep.ContentTemplateContainer.FindControl("address")).Text.Trim(); p.phone = ((TextBox)CreateUserWizard1.CreateUserStep.ContentTemplateContainer.FindControl("phone")).Text.Trim(); p.Save();//保存所作修改 } 2、采取自己写UI,个人推荐使用这种方法。灵活性比较大,而且可以使用2005强大的验证控件。
页面部分比较简单略过不再陈述。下面详细介绍一下代码部分。
此时我们需要使用membership的CreateUser()方法。语法我们就不再介绍。他会根据建立用户的结果返回成一个 MembershipCreateStatus枚举类,它详细的包含了所有建立用户不成功的错误信息。我们只需要根据他的值,就可以返回给界面相应的提 示,如:用户名已经存在,电子邮件已经存在等等。
对于自定义用户信息部分我们仍然可以采取profile或者自定义membershipinfo表的方法。
列出profile建立用户的方法。SQL语句比较简单,略过不写。
protected void Button1_Click(object sender, EventArgs e)
{ MembershipCreateStatus status; MembershipUser newUser = Membership.CreateUser(username.Text.Trim(), Password.Text.Trim(), Email.Text.Trim(), Question.Text.Trim(), Answer.Text.Trim(), true, out status); //使用membership建立用户,并把建立结果返回给MembershipCreateStatus if (newUser == null)//没有新用户,则意味着出错。
{ GetErrorMessage(status); //调用GetErrorMessage函数,返回详细错误信息 } else { Roles.AddUserToRole(newUser.UserName, "jiancai"); //添加用户到相应组 ProfileCommon p = (ProfileCommon)ProfileCommon.Create(newUser.UserName, true); p.QQ = QQ.Text.Trim(); p.address= address.Text.Trim(); p.phone= phone.Text.Trim(); p.Save(); } } public void GetErrorMessage(MembershipCreateStatus status) { switch (status) { case MembershipCreateStatus.DuplicateUserName: DisplayAlert("当前用户已经存在,请重新选择"); break; //其余各种错误信息,请查看MSDN的MembershipCreateStatus枚举类。 default: DisplayAlert("注册00000000用户失败,请检查您的用户名,密码等信息"); break; } } 个人见解:采取profile的方法,比较方便,由于profile 是强类型,可以通过智能感知功能减少代码的输入量。采取自定义数据表的方法,需要输入大量的sql语句,但是查询速度比较快,性能比较强,由于 Roles.GetUsersInRole()方法无法分页读取数据,只能一次性读出来所有数据,而自写SQL 语句可以很方便的根分页结合起来。随着用户量的增多,故不推荐profile方法。
三、密码问题。
个人觉得密码是一个比较头疼的问题。我们在实际开发中总是需要admin组有对用户进行密码修改的权限。Membership提供的修改密码方法只能在 已经知道密码提示答案的时候才能修改。而admin组根本不可能知道用户的密码提示答案的。这里有点好笑。难道是中西方文化差异?
列出个人对membership密码研究的一些心得。
大家都知道machine.config和web.config,如果两者发生冲突,那么以web.config优先。
默认状态下,membership是采用SHA1的方法进行加密,然后采取一种机制,与passwordsalt进行再次加密,最后形成数据库中显示的密码。可见随着MD5加密的破解,微软对密码的安全也煞费苦心。
有的朋友不喜欢默认的SHA1加密形式,我们只需要在web.config中设置以下代码来覆盖machine.config中对密码的设置就好了:
<machineKey
validationKey="AutoGenerate,IsolateApps" decryptionKey="AutoGenerate,IsolateApps" decryption="Auto" validation="MD5/SHA1/Clear" /> 其中:
Clear – 密码以明文形式存储。用户密码可与此值直接比较,而不需要进行进一步的转换。
MD5 -使用消息摘要 5 (MD5) 哈希摘要存储密码。为了验证凭据,将使用 MD5 算法对用户密码进行哈希运算并将计算出来的值与存储的值进行比较。使用此值时,从不存储或比较明文密码。此算法的性能比 SHA1 好。
SHA1 -使用 SHA1 哈希摘要存储密码。为了验证凭据,将使用 SHA1 算法对用户密码进行哈希运算并将计算出来的值与存储的值进行比较。从不存储明文密码。使用该算法可以获得比 MD5 算法高的安全性。
然而虽然MembershipUser提供了GetPassword 方法,但是这是后只有在加密形式设置成Clear,即密码在数据库中以明码的形式存在,才能得到密码。而ChangePassword必须要提供旧密码或 者密码提示答案才可以修改。对用户管理造成了很大的不便。找了许多资料无解。顺便提带一下:微软的membership机制起源于csblog,并进行了 一定的修改。
Csblog对密码的策略:首先对用户输入的密码进行加密(SHA1或者MD5),然后根据系统自动生成的密匙再次对加密后的密码进行DES加密。不过我按照csblog 的方法进行加密的时候,形式相同,密码却不同,目前正在演就中。也欢迎大家共同讨论。
如果passwordsalt和password固定,那么用户密码肯定一定。所以目前我采取的一个方法就是给用户重新设置成固定密码的功能。
首先取得已知用户密码的passwordsalt和password,然后替换相应用户的passwordsalt和password字段。这时,用户的密码就已经恢复成已知的密码了。
不可否认,membership给我们开发中创造了很大的便利,其方便的Roles功能,对于我们进行权限管理的时候提供了很好的解决方案。2005许 多功能均进化自csblog这优秀的开源项目,有兴趣者可以研究csblog,以进一步的了解membership的运作机制。限于篇幅,MSDN上边有 做介绍的我就不再重复叙述。只介绍MSDN上没有列出的技巧跟我在项目开发中的一些心得。 ASP.NET 2.0为使用窗体身份验证的Web站点提供了重要的安全性优势。通过提供用户配置文件储备库以及对角色的支持,窗体身份验证将走出ASP.NET内行的视 野,而得以更广泛地实现。
|
[教程]WebClient研究
WebClient
Mircsoft在dotnet1.1框架下提供的向 URI 标识的资源发送数据和从 URI 标识的资源接收数据的公共方法。
通过这个类,大家可以在脱离浏览器的基础上模拟浏览器对互联网上的资源的访问和发送信息。
WebClient类不能被继承,在dotnet1.1框架中已经为我们提供了WebRequest和WebResponse两个强大的类来
处理向URI标示的资源和获取数据了。然后,不足的是利用WebRequest和WebResponse时设置过于复杂。
使用起来颇为费劲。于是乎有了现在的WebClient,WebClient其实可以理解为对WebRequest和WebResponse等
协作的封装。它使人们使用起来更加简单方便,然后它也有先天不足的地方。那就是缺少对cookies/session的
支持,用户无法对是否自动url转向的控制,还有就是缺少对代理服务器的支持。关于session/url转向控制/代理
服务器的使用我将在以后关于WebRequest/WebResponse的话题里面向大家介绍。下面先给大家简单介绍一
下WebClinet类。
类名:WebClient
命名空间System.Net.WebClient
公共构造函数
| WebClient 构造函数 | 初始化 WebClient 类的新实例。 |
公共属性
| BaseAddress | 获取或设置 WebClient 发出请求的基 URI。 |
| Container(从 Component 继承) | 获取 IContainer,它包含 Component。 |
| Credentials | 获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 |
| Headers | 获取或设置与请求关联的标头名称/值对集合。 |
| QueryString | 获取或设置与请求关联的查询名称/值对集合。 |
| ResponseHeaders | 获取与响应关联的标头名称/值对集合。 |
| Site(从 Component 继承) | 获取或设置 Component 的 ISite。 |
公共方法
| CreateObjRef(从 MarshalByRefObject 继承) | 创建一个对象,该对象包含生成用于与远程对象进行通讯的代理所需的全部相关信息。 |
| Dispose(从 Component 继承) | 已重载。释放由 Component 占用的资源。 |
| DownloadData | 从具有指定 URI 的资源下载数据。 |
| DownloadFile | 从具有指定 URI 的资源将数据下载到本地文件。 |
| Equals(从 Object 继承) | 已重载。确定两个 Object 实例是否相等。 |
| GetHashCode(从 Object 继承) | 用作特定类型的哈希函数,适合在哈希算法和数据结构(如哈希表)中使用。 |
| GetLifetimeService(从 MarshalByRefObject 继承) | 检索控制此实例的生存期策略的当前生存期服务对象。 |
| GetType(从 Object 继承) | 获取当前实例的 Type。 |
| InitializeLifetimeService(从 MarshalByRefObject 继承) | 获取控制此实例的生存期策略的生存期服务对象。 |
| OpenRead | 为从具有指定 URI 的资源下载的数据打开一个可读的流。 |
| OpenWrite | 已重载。打开一个流以将数据写入具有指定 URI 的资源。 |
| ToString(从 Object 继承) | 返回表示当前 Object 的 String。 |
| UploadData | 已重载。将数据缓冲区上载到具有指定 URI 的资源。 |
| UploadFile | 已重载。将本地文件上载到具有指定 URI 的资源。 |
| UploadValues | 已重载。将名称/值集合上载到具有指定 URI 的资源。 |
从上表中我们可以看到WebClient提供四种将数据上载到资源的方法:
- OpenWrite 返回一个用于将数据发送到资源的 Stream。
- UploadData 将字节数组发送到资源并返回包含任何响应的字节数组。
- UploadFile 将本地文件发送到资源并返回包含任何响应的字节数组。
- UploadValues 将 NameValueCollection 发送到资源并返回包含任何响应的字节数组。
另外WebClient还提供三种从资源下载数据的方法:
- DownloadData 从资源下载数据并返回字节数组。
- DownloadFile 从资源将数据下载到本地文件。
- OpenRead 从资源以 Stream 的形式返回数据。
下面我们将通过一个简单的应用程序来测试WebClient的最简单用法作为本小节的结束让大家对WebClient有个初步的认识
例子1:利用WebClient实现对博客园首页的访问
首先我们用HttpLook对这次访问进行分析,为了方便分析我特别将浏览器对图片的访问去掉 让我们能看到更简便的分析结果
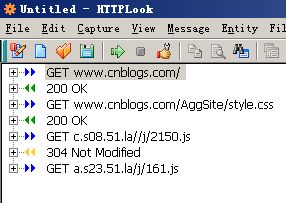
我们可以看到整个过程中我们发起了4次资源请求,其中第一次是对博客园首页进行访问
第二次访问的是样式表文件,第三和四次访问的是js脚本。
我们点击第一项可以看见关于这次资源访问的http头部信息,所谓http头部就是我们不能看见的浏览器和远程服务器传递的一些不可见元素。
1 GET / HTTP/1.1
GET / HTTP/1.1
2Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*
3Accept-Language: zh-cn
4UA-CPU: x86
5Accept-Encoding: gzip, deflate
6User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
7Host: www.cnblogs.com
8Connection: Keep-Alive
9Cookie: .DottextCookie=(隐藏)
GET / HTTP/1.12
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*3
Accept-Language: zh-cn4
UA-CPU: x865
Accept-Encoding: gzip, deflate6
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)7
Host: www.cnblogs.com8
Connection: Keep-Alive9
Cookie: .DottextCookie=(隐藏) 这些http信息包含了浏览器访问的过程。其中
第一行:请求地址的相对路径和使用协议 相对路径为/ 协议采用http1.1
第二行:表示我们请求的资源种类。
第三行:我们的语言是简体中文。
第四行:我们使用的cup结构。这个http头在一般的网页中并不过见。估计是博客园的一次调查??
第五行:标示采用gzip方式压缩html编码进行传递。只有一些浏览器支持的gzip解压缩时采用这种方式传递文本。由于我们
要写的程序不具备gzi解压缩的能力 所以我们不考虑使用这种方式发送请求。
第六行:浏览器说明
第七行:当前主机地址
第八行:连接请求状态
第九行:cookies信息
我在新建的应用程序里面利用WebClient来实现这了一过程。
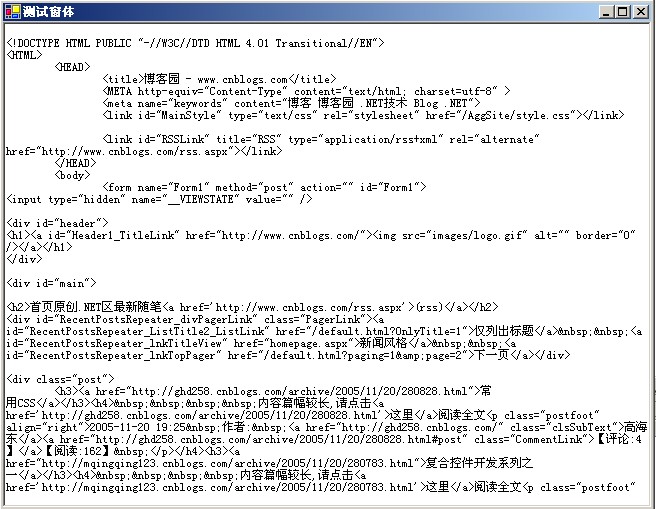
下面我将就关键实现做一些解释
1WebClient _client=new WebClient();
2 _client.BaseAddress="http://www.cnblogs.com";
3 _client.Headers.Add("Accept","image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*");
4 _client.Headers.Add("Accept-Language","zh-cn");
5 _client.Headers.Add("UA-CPU","x86");
6 //_client.Headers.Add("Accept-Encoding","gzip, deflate");
7 _client.Headers.Add("User-Agent","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)");
8 System.IO.Stream objStream=_client.OpenRead("/");
9 System.IO.StreamReader _read=new System.IO.StreamReader(objStream,System.Text.Encoding.UTF8);
10 textBox1.Text=_read.ReadToEnd();
WebClient _client=new WebClient();2
_client.BaseAddress="http://www.cnblogs.com";3
_client.Headers.Add("Accept","image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*");4
_client.Headers.Add("Accept-Language","zh-cn");5
_client.Headers.Add("UA-CPU","x86");6
//_client.Headers.Add("Accept-Encoding","gzip, deflate");7
_client.Headers.Add("User-Agent","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)");8
System.IO.Stream objStream=_client.OpenRead("/");9
System.IO.StreamReader _read=new System.IO.StreamReader(objStream,System.Text.Encoding.UTF8);10
textBox1.Text=_read.ReadToEnd(); 第一行:新建一个WebClient 实例_client
第二行~第七行:将上边捕捉到的Http头部放入到_client实例,注意第六行的被注释掉了。因为我们的程序无法进行gzip解码所以如果这样请求
获得的资源可能无法解码。当然我们可以给程序加入gzip处理的模块 那是题外话了。
第八行:利用_client.OpenRead(string URI)的方法获取网上资源的Stream
第九行:利用StreamReader将Stream用我们需要的编码方法去解析。这里使用了UTF8。对应不同的网站可以使用Default等不同的解码方法。
第十行:将我们解码后的内容放到textBox1里面显示出来
好了 大致关于WebClient的介绍就到这里了。以后将为大家陆续介绍WebClient的各种属性和方法。
利用WebClient做个资源小偷其实是很简单的,所以大家一定要防盗链阿!!!
[教程]使用Forms Authentication实现用户注册、登录 (一)基础知识
本文示例代码:http://www.codeplex.com/a/Release/ProjectReleases.aspx?ReleaseId=9518
前言
本来使用Forms Authentication进行用户验证的方式是最常见的,但系统地阐明其方法的文章并不多见,网上更多的文章都是介绍其中某一部分的使用方法或实现原理,而更多的朋友则发文询问如何从头到尾完整第实现用户的注册、登录。因此,Anders Liu在这一系列文章中计划通过一个实际的例子,介绍如何基于Forms Authentication实现:
l 用户注册(包括密码的加密存储)
l 用户登录(包括密码的验证、设置安全Cookie)
l 用户实体替换(使用自己的类型作为HttpContext.User的类型)
有关Forms Authentication的原理等内容不属于本文的讨论范畴,大家可以通过在Google等搜索引擎中输入“Forms Authentication”、“Forms身份验证”、“窗体身份验证”等关键词来查看更多资源。本文仅从实用的角度介绍如何使用这一技术。
不使用Membership
本文介绍的实现方式不依赖ASP.NET 2.0提供的Membership功能。这主要是因为,如果使用Membership,就必须用aspnet_regSQL.exe实用工具配置数据库,否则就得自己写自定义的MembershipProvider。
如果用aspnet_regSQL.exe配置数据库,就会导致数据库中出现很多我们实际并不需要的表或字段。此外更重要的是,默认的SQLMembershipProvider给很多数据表添加了ApplicationID列,其初衷可能是希望可以将多个应用程序的用户全部放在一个库里,但又能彼此隔离。但实际情况是,每个应用程序都在其自身的数据库中保存用户数据。因此,引入这个ApplicationID无端地在每次查找用户时增加了额外的条件。
另一方面,如果考虑自己实现一个MembershipProvider,因为工作量巨大,有点得不偿失。
但是,如果不使用Membership,也就无法享受ASP.NET 2.0中新增的Login等控件的便利了。
与Forms Authentication相关的配置
在web.config文件中,<system.web>/<authentication>配置节用于对验证进行配置。为<authentication>节点提供mode="Forms"属性可以启用Forms Authentication。一个典型的<authentication>配置节如下所示:
<authentication mode="Forms">
<forms
name=".ASPXAUTH"
loginUrl="login.aspx"
defaultUrl="default.aspx"
protection="All"
timeout="30"
path="/"
requireSSL="false"
slidingExpiration="false"
enableCrossAppRedirects="false"
cookieless="UseDeviceProfile"
domain=""
/>
</authentication>
以上代码使用的均是默认设置,换言之,如果你的哪项配置属性与上述代码一致,则可以省略该属性例如<forms name="MyAppAuth" />。下面依次介绍一下各种属性:
l name——Cookie的名字。Forms Authentication可能会在验证后将用户凭证放在Cookie中,name属性决定了该Cookie的名字。通过FormsAuthentication.FormsCookieName属性可以得到该配置值(稍后介绍FromsAuthentication类)。
l loginUrl——登录页的URL。通过FormsAuthentication.LoginUrl属性可以得到该配置值。当调用FormsAuthentication.RedirectToLoginPage()方法时,客户端请求将被重定向到该属性所指定的页面。loginUrl的默认值为“login.aspx”,这表明即便不提供该属性值,ASP.NET也会尝试到站点根目录下寻找名为login.aspx的页面。
l defaultUrl——默认页的URL。通过FormsAuthentication.DefaultUrl属性得到该配置值。
l protection——Cookie的保护模式,可取值包括All(同时进行加密和数据验证)、Encryption(仅加密)、Validation(仅进行数据验证)和None。为了安全,该属性通常从不设置为None。
l timeout——Cookie的过期时间。
l path——Cookie的路径。可以通过FormsAuthentication.FormsCookiePath属性得到该配置值。
l requireSSL——在进行Forms Authentication时,与服务器交互是否要求使用SSL。可以通过FormsAuthentication.RequireSSL属性得到该配置值。
l slidingExpiration——是否启用“弹性过期时间”,如果该属性设置为false,从首次验证之后过timeout时间后Cookie即过期;如果该属性为true,则从上次请求该开始过timeout时间才过期,这意味着,在首次验证后,如果保证每timeout时间内至少发送一个请求,则Cookie将永远不会过期。通过FormsAuthentication.SlidingExpiration属性可以得到该配置值。
l enableCrossAppRedirects——是否可以将以进行了身份验证的用户重定向到其他应用程序中。通过FormsAuthentication.EnableCrossAppRedirects属性可以得到该配置值。为了安全考虑,通常总是将该属性设置为false。
l cookieless——定义是否使用Cookie以及Cookie的行为。Forms Authentication可以采用两种方式在会话中保存用户凭据信息,一种是使用Cookie,即将用户凭据记录到Cookie中,每次发送请求时浏览器都会将该Cookie提供给服务器。另一种方式是使用URI,即将用户凭据当作URL中额外的查询字符串传递给服务器。该属性有四种取值——UseCookies(无论何时都使用Cookie)、UseUri(从不使用Cookie,仅使用URI)、AutoDetect(检测设备和浏览器,只有当设备支持Cookie并且在浏览器中启用了Cookie时才使用Cookie)和UseDeviceProfile(只检测设备,只要设备支持Cookie不管浏览器是否支持,都是用Cookie)。通过FormsAuthentication.CookieMode属性可以得到该配置值。通过FormsAuthentication.CookiesSupported属性可以得到对于当前请求是否使用Cookie传递用户凭证。
l domain——Cookie的域。通过FormsAuthentication.CookieDomain属性可以得到该配置值。
以上针对<system.web>/<authentication>/<forms>节点的介绍非常简略,基本上是Anders Liu个人对于文档进行的额外说明。有关<forms>节点的更多说明,请参见MSDN文档(http://msdn2.microsoft.com/zh-cn/library/1d3t3c61(VS.85).aspx)。
FormsAuthentication类
FormsAuthentication类用于辅助我们完成窗体验证,并进一步完成用户登录等功能。该类位于system.web.dll程序集的System.Web.Security命名空间中。通常在Web站点项目中可以直接使用这个类,如果是在类库项目中使用这个类,请确保引用了system.web.dll。
前一节已经介绍了FormsAuthentication类的所有属性。这一节将介绍该类少数几个常用的方法。
RedirectToLoginPage方法用于从任何页面重定向到登录页,该方法有两种重载方式:
public static void RedirectToLoginPage ()
public static void RedirectToLoginPage (string extraQueryString)
两种方式均会使浏览器重定向到登录页(登录页的URL由<forms>节点的loginUrl属性指出)。第二种重载方式还能够提供额外的查询字符串。
RedirectToLoginPage通常在任何非登录页的页面中调用。该方法除了进行重定向之外,还会向URL中附加一个ReturnUrl参数,该参数即为调用该方法时所在的页面的URL地址。这是为了方便登录后能够自动回到登录前所在的页面。
RedirectFromLoginPage方法用于从登录页跳转回登录前页面。这个“登录前”页面即由访问登录页时提供的ReturnUrl参数指定。如果没有提供ReturnUrl参数(例如,不是使用RedirectToLoginPage方法而是用其他手段重定向到或直接访问登录页时),则该方法会自动跳转到由<forms>节点的defaultUrl属性所指定的默认页。
此外,如果<forms>节点的enableCrossAppRedirects属性被设置为false,ReturnUrl参数所指定的路径必须是当前Web应用程序中的路径,否则(如提供其他站点下的路径)也将返回到默认页。
RedirectFromLoginPage方法有两种重载形式:
public static void RedirectFromLoginPage (string userName, bool createPersistentCookie)
public static void RedirectFromLoginPage (string userName, bool createPersistentCookie, string strCookiePath)
userName参数表示用户的标识(如用户名、用户ID等);createPersistentCookie参数表示是否“记住我”;strCookiePath参数表示Cookie路径。
RedirectFromLoginPage方法除了完成重定向之外,还会将经过加密(是否加密取决于<forms>节点的protection属性)的用户凭据存放到Cookie或Uri中。在后续访问中,只要Cookie没有过期,则将可以通过HttpContext.User.Identity.Name属性得到这里传入的userName属性。
此外,FormsAuthentication还有一个SignOut方法,用于完成用户注销。其原理是从Cookie或Uri中移除用户凭据。
小结
好了,至此所需要掌握的基础知识就齐备了,接下来我们将实现用户注册、登录等功能。