原贴
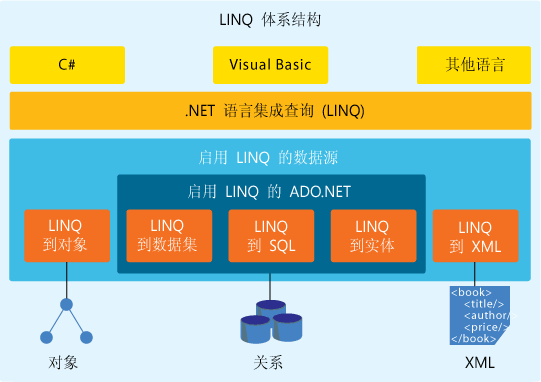
简单地说,LINQ 是支持以类型安全方式查询数据的一系列语言扩展;它将在代号为“Orcas”的下一个版本 Visual Studio 中发布。待查询数据的形式可以是 XML(LINQ 到 XML)、数据库(启用 LINQ 的 ADO.NET,其中包括 LINQ 到 SQL、LINQ 到 Dataset 和 LINQ 到 Entities)和对象 (LINQ 到 Objects) 等。LINQ 体系结构如图 1 所示。
让我们看一些代码。在即将发布的“Orcas”版 C# 中,LINQ 查询可能如下所示:
var overdrawnQuery = from account in db.Accounts
where account.Balance < 0
select new { account.Name, account.Address };
当使用 foreach 遍历此查询的结果时,返回的每个元素都将包含一个余额小于 0 的帐户的名称和地址。
从 以上示例中立即可以看出该语法类似于 SQL。几年前,Anders Hejlsberg(C# 的首席设计师)和 Peter Golde 曾考虑扩展 C# 以更好地集成数据查询。Peter 时任 C# 编译器开发主管,当时正在研究扩展 C# 编译器的可能性,特别是支持可验证 SQL 之类特定于域的语言语法的加载项。另一方面,Anders 则在设想更深入、更特定级别的集成。他当时正在构思一组“序列运算符”,能在实现 IEnumerable 的任何集合以及实现 IQueryable 的远程类型查询上运行。最终,序列运算符的构思获得了大多数支持,并且 Anders 于 2004 年初向比尔·盖茨的 Thinkweek 递交了一份关于本构思的文件。反馈对此给予了充分肯定。在设计初期,简单查询的语法如下所示:
sequence<Customer> locals = customers.where(ZipCode == 98112);
在 此例中,Sequence 是 IEnumerable<T> 的别名;“where”一词是编译器能理解的一种特殊运算符。Where 运算符的实现是一种接受 predicate 委托(即 bool Pred<T>(T item) 形式的委托)的普通 C# 静态方法。本构思的目的是让编辑器具备与运算符有关的特殊知识。这样将允许编译器正确调用静态方法并创建代码,将委托与表达式联系起来。
假设上述示例是 C# 的理想查询语法。在没有任何语言扩展的情况下,该查询在 C# 2.0 中又会是什么样子?
IEnumerable<Customer> locals = EnumerableExtensions.Where(customers,
delegate(Customer c)
{
return c.ZipCode == 98112;
});
这 个代码惊人地冗长,而且更糟糕的是,需要非常仔细地研究才能找到相关的筛选器 (ZipCode == 98112)。这只是一个简单的例子;试想一下,如果使用数个筛选器、投影等,要读懂代码该有多难。冗长的根源在于匿名方法所要求的语法。在理想的查询 中,除了要计算的表达式,表达式不会提出任何要求。随后,编译器将尝试推断上下文;例如,ZipCode 实际上引用了 Customer 上定义的 ZipCode。如何解决这一问题?将特定运算符的知识硬编码到语言中并不能令语言设计团队满意,因此他们开始为匿名方法寻求替代语法。他们要求该语法应 极其简练,但又不必比匿名方法当前所需的编译器要求更多的知识。最终,他们发明了 lambda 表达式。
Lambda 表达式
Lambda 表 达式是一种语言功能,在许多方面类似于匿名方法。事实上,如果 lambda 表达式首先被引入语言,那么就不会有对匿名方法的需要了。这里的基本概念是可以将代码视为数据。在 C# 1.0 中,通常可以将字符串、整数、引用类型等传递给方法,以便方法对那些值进行操作。匿名方法和 lambda 表达式扩展了值的范围,以包含代码块。此概念常见于函数式编程中。
我们再借用以上示例,并用 lambda 表达式替换匿名方法:
IEnumerable<Customer> locals =
EnumerableExtensions.Where(customers, c => c.ZipCode == 91822);
有 几个需要注意的地方。对于初学者而言, lambda 表达式简明扼要的原因有很多。首先,没有使用委托关键字来引入构造。取而代之的是一个新的运算符 =>,通知编译器这不是正则表达式。其次,Customer 类型是从使用中推断出来的。在此例中,Where 方法的签名如下所示:
public static IEnumerable<T> Where<T>(
IEnumerable<T> items, Func<T, bool> predicate)
编 译器能够推断“c”是指客户,因为 Where 方法的第一个参数是 IEnumerable<Customer>,因此 T 事实上必须是 Customer。利用这种知识,编译器还可验证 Customer 具有一个 ZipCode 成员。最后,没有指定的返回关键字。在语法形式中,返回成员被省略,但这只是为了语法便利。表达式的结果仍将视为返回值。
与匿名方法一样,Lambda 表达式也支持变量捕获。例如,对于在 lambda 表达式主体内包含 lambda 表达式的方法,可以引用其参数或局部变量:
public IEnumerable<Customer> LocalCusts(
IEnumerable<Customer> customers, int zipCode)
{
return EnumerableExtensions.Where(customers,
c => c.ZipCode == zipCode);
}
最后,Lambda 表达式支持更冗长的语法,允许您显式指定类型,以及执行多条语句。例如:
return EnumerableExtensions.Where(customers,
(Customer c) => { int zip = zipCode; return c.ZipCode == zip; });
好消息是,我们向原始文章中提议的理想语法迈进了一大步,并且我们能够利用一个通常能在查询运算符以外发挥作用的语言功能来实现这一目标。让我们再次看一下我们目前所处的阶段:
IEnumerable<Customer> locals =
EnumerableExtensions.Where(customers, c => c.ZipCode == 91822);
这里存在一个明显的问题。客户目前必须了解此 EnumerableExtensions 类,而不是考虑可在 Customer 上执行的操作。另外,在多个运算符的情况下,使用者必须逆转其思维以编写正确的语法。例如:
IEnumerable<string> locals =
EnumerableExtensions.Select(
EnumerableExtensions.Where(customers, c => c.ZipCode == 91822),
c => c.Name);
请注意,Select 属于外部方法,尽管它是在 Where 方法结果的基础上运行的。理想的语法应该更类似以下代码:
sequence<Customer> locals =
customers.where(ZipCode == 98112).select(Name);
因此,是否可利用另一种语言功能来进一步接近实现理想语法呢?
扩展方法
结 果证明,更好的语法将以被称为扩展方法的语言功能形式出现。扩展方法基本上属于可通过实例语法调用的静态方法。上述查询问题的根源是我们试图向 IEnumerable<T> 添加方法。但如果我们要添加运算符,如 Where、Select 等,则所有现有和未来的实现器都必须实现那些方法。尽管那些实现绝大多数都是相同的。在 C# 中共享“接口实现”的唯一方法是使用静态方法,这是我们处理以前使用的 EnumerableExtensions 类的一个成功方法。
假设我们转而将 Where 方法编写为扩展方法。那么,查询可重新编写为:
IEnumerable<Customer> locals =
customers.Where(c => c.ZipCode == 91822);
对于此简单查询,该语法近乎完美。但将 Where 方法编写为扩展方法的真正含义是什么呢?其实非常简单。基本上,因为静态方法的签名发生更改,因此“this”修饰符就被添加到第一个参数:
public static IEnumerable<T> Where<T>(
this IEnumerable<T> items, Func<T, bool> predicate)
此 外,必须在静态类中声明该方法。静态类是一种只能包含静态成员,并在类声明中用静态修饰符表示的类。这就它的全部含义。此声明指示编译器允许在任何实现 IEnumerable<T> 的类型上用与实例方法相同的语法调用 Where。但是,必须能够从当前作用域访问 Where 方法。当包含类型处于作用域内时,方法也在作用域内。因此,可以通过 Using 指令将扩展方法引入作用域。(有关详细信息,请参见侧栏上的“扩展方法”。)
扩展方法
显然,扩展 方法有助于简化我们的查询示例,但除此之外,这些方法是不是一种广泛有用的语言功能呢?事实证明扩展方法有多种用途。其中一个最常见的用途可能是提供共享接口实现。例如,假设您有以下接口:
interface IDog
{
// Barks for 2 seconds
void Bark();
void Bark(int seconds);
}
此接口要求每个实现器都应编写适用于两种重载的实现。有了“Orcas”版 C#,接口变得很简单:
interface IDog
{
void Bark(int seconds);
}
扩展方法可添加到另一个类:
static class DogExtensions
{
// Barks for 2 seconds
public static void Bark(this IDog dog)
{
dog.Bark(2);
}
}
接口实现器现在只需实现单一方法,但接口客户端却可以自由调用任一重载。
我们现在拥有了用于编写筛选子句的非常接近理想的语法,但“Orcas”版 C# 仅限于此吗?并不全然。让我们对示例稍作扩展,相对于整个客户对象,我们只投影出客户名称。如我前面所述,理想的语法应采用如下形式:
sequence<string> locals =
customers.where(ZipCode == 98112).select(Name);
仅用我们讨论过的语言扩展,即 lambda 表达式和扩展方法,此代码可重新编写为如下所示:
IEnumerable<string> locals =
customers.Where(c => c.ZipCode == 91822).Select(c => c.Name);
请注意,此查询的返回类型不同,它是 IEnumerable<string> 而不是 IEnumerable<Customer>。这是因为我们仅从 select 语句中返回客户名称。
当投影只是单一字段时,该方法确实很有效。但是,假设我们不仅要返回客户的名称,还要返回客户的地址。理想的语法则应如下所示:
locals = customers.where(ZipCode == 98112).select(Name, Address);
匿名类型
如果我们想继续使用我们现有的语法来返回名称和地址,我们很快便会面临问题,即不存在仅包含 Name 和 Address 的类型。虽然我们仍然可以编写此查询,但是必须引入该类型:
class CustomerTuple
{
public string Name;
public string Address;
public CustomerTuple(string name, string address)
{
this.Name = name;
this.Address = address;
}
}
然后我们才能使用该类型,即此处的 CustomerTuple,以生成我们查询的结果。
IEnumerable<CustomerTuple> locals =
customers.Where(c => c.ZipCode == 91822)
.Select(c => new CustomerTuple(c.Name, c.Address));
那 确实像许多用于投影出字段子集的样板代码。而且还往往不清楚如何命名此种类型。CustomerTuple 确实是个好名称吗?如果投影出 Name 和 Age 又该如何命名?那也可以叫做 CustomerTuple。因此,问题在于我们拥有样板代码,而且似乎无法为我们创建的类型找到任何恰当的名称。此外,还可能需要许多不同的类型,如何 管理这些类型很快便可能成为一个棘手的问题。
这正是匿名类型要解决的问题。此功能主要允许在无需指定名称的情况下创建结构化类型。如果我们使用匿名类型重新编写上述查询,其代码如下所示:
locals = customers.Where(c => c.ZipCode == 91822)
.Select(c => new { c.Name, c.Address });
此代码会隐式创建一个具有 Name 和 Address 字段的类型:
class
{
public string Name;
public string Address;
}
此类型不能通过名称引用,因为它没有名称。创建匿名类型时,可显式声明字段的名称。例如,如果正在创建的字段派生于一条复杂的表达式,或纯粹不需要名称,就可以更改名称:
locals = customers.Where(c => c.ZipCode == 91822)
.Select(c => new { FullName = c.FirstName + “ “ + c.LastName,
HomeAddress = c.Address });
在此情形下,生成的类型具有名为 FullName 和 HomeAddress 的字段。
这样我们又向理想世界前进了一步,但仍存在一个问题。您将发现,我在任何使用匿名类型的地方都策略性地省略了局部变量的类型。显然我们不能声明匿名类型的名称,那我们如何使用它们?
隐式类型化部变量
还有另一种语言功能被称为隐式类型化局部变量(或简称为 var),它负责指示编译器推断局部变量的类型。例如:
var integer = 1;
在此例中,整数具有 int 类型。请务必明白,这仍然是强类型。在动态语言中,整数的类型可在以后更改。为说明这一点,以下代码不会成功编译:
var integer = 1;
integer = “hello”;
C# 编译器将报告第二行的错误,表明无法将字符串隐式转换为 int。
在上述查询示例中,我们现在可以编写完整的赋值,如下所示:
var locals =
customers
.Where(c => c.ZipCode == 91822)
.Select(c => new { FullName = c.FirstName + “ “ + c.LastName,
HomeAddress = c.Address });
局部变量的类型最终成为 IEnumerable<?>,其中“?”是无法编写的类型的名称(因为它是匿名的)。
隐式类型化局部变量只是:方法内部的局部变量。它们无法超出方法、属性、索引器或其他块的边界,因为该类型无法显式声明,而且“var”对于字段或参数类型而言是非法的。
事实证明,隐式类型化局部变量在查询的环境之外非常便利。例如,它有助于简化复杂的通用实例化:
var customerListLookup = new Dictionary<string, List<Customer>>();
现在我们的查询取得了良好进展;我们已经接近理想的语法,而且我们是用通用语言功能来达成的。
有趣的是,我们发现,随着越来越多的人使用过此语法,经常会出现允许投影超越方法边界的需求。如我们以前所看到的,这是可能的,只要从 Select 内部调用对象的构造函数来构建对象即可。但是,如果没有用来准确接受您需要设置的值的构造函数,会发生什么呢?
对象初始值
为解决这一问题,即将发布的“Orcas”版本提供了一种被称为对象初始值的 C# 语言功能。对象初始值主要允许在单一表达式中为多个属性或字段赋值。例如,创建对象的常见模式是:
Customer customer = new Customer();
customer.Name = “Roger”;
customer.Address = “1 Wilco Way”;
此时,Customer 没有可以接受名称和地址的构造函数;但是存在两个属性,即 Name 和 Address,当创建实例后即可设置它们。对象初始值允许使用以下语法创建相同的结果:
Customer customer = new Customer()
{ Name = “Roger”, Address = “1 Wilco Way” };
在我们前面的 CustomerTuple 示例中,我们通过调用其构造函数创建了 CustomerTuple 类。我们也可以通过对象初始值获得同样的结果:
var locals =
customers
.Where(c => c.ZipCode == 91822)
.Select(c =>
new CustomerTuple { Name = c.Name, Address = c.Address });
请注意,对象初始值允许省略构造函数的括号。此外,字段和可设置的属性均可在对象初始值的主体内部进行赋值。
我们现在已经拥有在 C# 中创建查询的简洁语法。尽管如此,我们还有一种可扩展途径,可通过扩展方法以及一组本身非常有用的语言功能来添加新的运算符(Distinct、OrderBy、Sum 等)。
语 言设计团队现在有了数种可赖以获得反馈的原型。因此,我们与许多富于 C# 和 SQL 经验的参与者组织了一项可用性研究。几乎所有反馈都是肯定的,但明显疏忽了某些东西。具体而言,开发人员难以应用他们的 SQL 知识,因为我们认为理想的语法与他们擅长领域的专门技术并不很符合。
查询表达式
于是,语言设计团队设计了一种与 SQL 更为相近的语法,称为查询表达式。例如,针对我们的示例的查询表达式可如下所示:
var locals = from c in customers
where c.ZipCode == 91822
select new { FullName = c.FirstName + “ “ +
c.LastName, HomeAddress = c.Address };
查询表达式是基于上述语言功能构建而成。它们在语法上,完全转换为我们已经看到的基础语法。例如,上述查询可直接转换为:
var locals =
customers
.Where(c => c.ZipCode == 91822)
.Select(c => new { FullName = c.FirstName + “ “ + c.LastName,
HomeAddress = c.Address });
查 询表达式支持许多不同的“子句”,如 from、where、select、orderby、group by、let 和 join。这些子句先转换为对等的运算符调用,后者进而通过扩展方法实现。如果查询语法不支持必要运算符的子句,则查询子句和实现运算符的扩展方法之间的 紧密关系很便于将两者结合。例如:
var locals = (from c in customers
where c.ZipCode == 91822
select new { FullName = c.FirstName + “ “ +
c.LastName, HomeAddress = c.Address})
.Count();
在本例中,查询现在返回在 91822 ZIP Code 区居住的客户人数。
通 过该种方法,我们已经设法在结束时达到了开始时的目标(我对这一点始终觉得非常满意)。下一版本的 C# 的语法历经数年时间的发展,尝试了许多新的语言功能,才最终到达近乎于 2004 年冬提议的原始语法的境界。查询表达式的加入以 C# 即将发布的版本的其他语言功能为基础,并促使许多查询情况更便于具有 SQL 背景的开发人员阅读和理解。




