插入条记录
发现回显的全部都是 ?????….
乱码….
仔细查看了半天
发现数据库的排序规则是德语…
修改方法:数据库属性->选项->排序规则
设置成 CHINESE_PRC_CI_AI 就可以了

[教程]log4net简明手册
常见面,却不怎么用,究其原因还是觉得太复杂了点。不过,这东西出现次数越来越频繁,也只好写点东西,以备后用。本文仅对 Log4net 的使用做个简要说明,所有涉及到扩展和开发的部分一概忽略。
使用 Log4net,需要熟悉的东东有 Logger、Appender 以及 Layout。Logger 是日志记录器,我们使用其相关方法来完成日志记录;Appender 用于设置日志的存储方式和位置,Logger 的配置中会绑定一个或多个 Appender;Layout 关联具体的 Appender,用于设置日志字符串的格式。
1. Logger
所有的记录器都必须实现 ILog 接口,该接口提供日志记录所需的大量方法。
public interface ILog : ILoggerWrapper
{
void Debug(…);
void Error(…);
void Fatal(…);
void Info(…);
void Warn(…);
bool IsDebugEnabled { get; }
bool IsErrorEnabled { get; }
bool IsFatalEnabled { get; }
bool IsInfoEnabled { get; }
bool IsWarnEnabled { get; }
}
通常情况下,我们通过 LogManager.GetLogger() 来获取一个记录器。LogManager 内部维护一个 hashtable,保存新创建 Logger 引用,下次需要时直接从 hashtable 获取其实例。
ILog log = LogManager.GetLogger(this.GetType());
log.Debug(“aaaaaaaaaaaaaaa”);
所有 Logger 的参数设置都直接或间接继承自 root,其继承关系类似 namespace。比如,名为 “MyLogger.X.Y” 参数设置继承自 “MyLogger.X”。当我们创建 “MyLooger.X.Y” 记录器时,会在配置文件找该名称的记录器设置,如果没找到,则按继承关系向上查找,直到 root。因此,在创建 Logger 时,我们通常使用类型名称做为记录器的名字,缺省情况下,它会使用 root 或某一个父配置,但在需要的时候,我们随时可以为具体的类型添加一个更加 “详细” 的配置。
在创建 Logger 设置时,需要注意 “level” 参数。Log4net 允许我们通过该参数调整日志记录级别,只有高于或等于该级别的日志才会被记录下来。比如在代码调试阶段,我们可能希望记录所有的信息,而在部署阶段,我们只希望记录级别更高的错误信息。这个参数的好处是允许我们在不修改代码的前提下,随时调整记录级别。
(高) OFF > FATAL > ERROR > WARN > INFO > DEBUG > ALL (低)
“appender-ref” 参数用于绑定一个或多个具体的 Appender。
2. Appender / Layout
Log4net 提供了大量的 Appender,最常用的包括 AdoNetAppender、AspNetTraceAppender、ConsoleAppender、FileAppender、 OutputDebugStringAppender。每种 Appender 都有特定一些参数,使用时直接从 《Log4net 手册》的示例中拷贝过去,就OK了。(代码摘自 Log4net 手册)
(1) AspNetTraceAppender
(2) ConsoleAppender
(3) OutputDebugStringAppender
(4) FileAppender
有关 Layout 详细信息,请参考 Log4net 相关文档,本文不做详述。
3. Configuration
Log4net 的配置方式十分灵活,即可以写到应用程序配置文件中,也可以使用独立配置文件。同时它还提供了监测配置文件变化的功能,这样我们随时可以调整配置,而无须重启应用程序。
(1) 使用 app.config / web.config
app.config / web.config
使用代码初始化配置。
log4net.Config.XmlConfigurator.Configure();
(2) 使用自定义配置文件
test.log4net
使用代码初始化配置。
log4net.Config.XmlConfigurator.Configure(new FileInfo(“test.log4net”));
使用 XmlConfigurator.ConfigureAndWatch() 方法除了初始化配置外,还会监测配置文件的变化,一旦发生修改,将自动刷新配置。
(3) XmlConfiguratorAttribute
我们还可以使用 XmlConfiguratorAttribute 代替 XmlConfigurator.Config()/ConfigureAndWatch(),ConfiguratorAttribute 用于定义与 Assembly 相关联的配置文件名。
方式1: 关联到 test.log4net,并监测变化。
[assembly: log4net.Config.XmlConfigurator(ConfigFile=”test.log4net”, Watch=true)]
方式2: 关联到 test.exe.log4net (或 test.dll.log4net,文件名前缀为当前程序集名称),并监测变化。
[assembly: log4net.Config.XmlConfigurator(ConfigFileExtension=”log4net”, Watch=true)]
[教程]log4net配置与应用
log4net 配置与应用
log4net是apache组织开发的日志组件, 同其姐妹log4j一样, 是一个开源项目. 可以以插件的形式应用在你的系统中. 下面仅说明如何应用在web forms项目中. 做为主要的日志输出组件.
1. 首先你应该下载log4net.dll并引入到你的项目References中.
2. 需要修改你的global.asa.cs. 配置application对象启动的时候加载log4net配置. 这一步是不可以缺少的.
protected void Application_Start(Object sender, EventArgs e)
{
log4net.Config.DOMConfigurator.Configure();
}
{
log4net.Config.DOMConfigurator.Configure();
}
3. 可以看到上面的代码没有参数. 可见是载入了缺省配置. 该配置必须设置于web.config中.
在web.cofig根节点 configuration 中加入如下section:
<configSections> <section name="log4net" type="log4net.Config.Log4NetConfigurationSectionHandler, log4net" /> </configSections>
4.该 config section 声明了名为 log4net 的另外一个config section. 后者必须位于web.config根节点 configuration 下: 以下是一个sample:
<log4net debug="false">
<appender name="LogFileAppender" type="log4net.Appender.FileAppender" >
<param name="File" value="XxxxApplication.log.txt" />
<param name="datePattern" value="MM-dd HH:mm" />
<param name="AppendToFile" value="true" />
<layout type="log4net.Layout.PatternLayout">
<param name="ConversionPattern" value="%d [%t] %-5p %c [%x] - %m%n" />
</layout>
</appender>
<appender name="HttpTraceAppender" type="log4net.Appender.ASPNetTraceAppender" >
<layout type="log4net.Layout.PatternLayout">
<param name="ConversionPattern" value="%d [%t] %-5p %c [%x] - %m%n" />
</layout>
</appender>
<appender name="EventLogAppender" type="log4net.Appender.EventLogAppender" >
<layout type="log4net.Layout.PatternLayout">
<param name="ConversionPattern" value="%d [%t] %-5p %c [%x] - %m%n" />
</layout>
</appender>
<appender name="RollingLogFileAppender" type="log4net.Appender.RollingFileAppender">
<param name="File" value="_LogData\Log.txt" />
<param name="AppendToFile" value="true" />
<param name="MaxSizeRollBackups" value="10" />
<param name="MaximumFileSize" value="5MB" />
<param name="RollingStyle" value="Size" />
<param name="StaticLogFileName" value="true" />
<layout type="log4net.Layout.PatternLayout">
<param name="ConversionPattern" value="%d [%t] %-5p %c [%x] - %m%n" />
</layout>
</appender>
<root>
<level value="DEBUG" />
<appender-ref ref="LogFileAppender" />
</root>
</log4net>
5. 以上定义了多个appender. 简单来说, 每一个 appender 都是一种输出介质.
6. root节点指定了选用的 appender. 本例选用了LogFileAppender. (文本文件输出). 在Appender定义中定义了输出的格式. 和目标文本文件所在位置. (起始位置是应用程序根目录. (web.config所在目录).
7. 到目前位置就配置好了log4net. 可以在我们的应用中直接使用了.
8. 以下说明应用方法:
要输出日志, 必须首先得到带有一个别名的logger.
使用以下命令
(C#):
log4net.ILog Logger logger = log4net.LogManager.GetLogger(this.GetType());
(可以直接使用GetType得到当前类名)
之后调用
logger.Info(string message);
logger.Error(string message);
logger.Debug(string message);
即可输出日志.
调试后可查找应用程序根目录下是否已经自动创建XxxxxApplication.log.txt文本文件.以及是否正确输出了日志.
log4net是一个非常完善的日志组件. 有着强大的可配置性. 有助于提高开发效率.
关于log4net的配置. 可参考apache组织的官方文档位于
http://logging.apache.org/log4net
[问题]未将对象引用设置到对象的实例
最近编写程序进行单元测试时发现提示:
“未将对象引用设置到对象的实例”的错误
搜索了一下网上的答案,还是没有好的结果,不过我将提示的string变量进行了赋值,问题解决了,大概是因为没有对变量进行初始化,造成使用时空对象引用的问题。
[原创]翻译:Dropthings.com的Web Portal开发学习笔记
最近一直在研究Dropthings的架构以及源码,先暂且写个日志,后续内容不断更新
准备翻译Dropthings项目架构的作者写的这本书,不过翻译书比看书难度大多了,看书只需要领会精神就行了,但是翻译书就需要措词和表达能力同时需要让读者能够看懂就不是简单的英语水平能力了,希望不要误人子弟,呵呵…..:

数据库文件下载: 点击下载此文件
点击下载此文件
目录:
1.简介:
2.Web Portal和Widgets(部件)架构
整个应用程序有清晰的三层架构组成,分别是UI层、业务逻辑层和数据访问层:
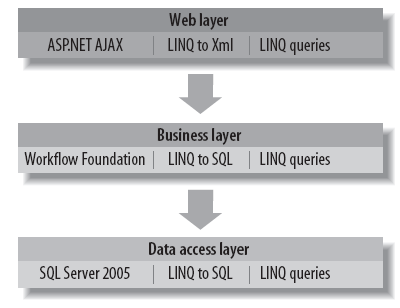
Web表示层:
包含Web页面、Web服务、资源(图片,CSS,JavaScript和resx文件)和配置文件。
业务逻辑层:
提供实体类、业务逻辑和中间层数据缓存
数据访问层:
对数据库和数据源的数据库访问和连接封装成了一个接口。同时实现了对实体类与数据库行的映射的工厂类。
Dropthings使用了.NET3.0和.NET3.5的新功能,Web层使用ASP.NET AJAX的RIA技术、业务逻辑层使用新的WF(WorkFlow)工作流实现复杂的业务逻辑的处理。整体架构使用Linq进行数据持久操作。
C#3.0语言的新特性和Linq使得操作集合、数据库行和XML变得容易。WF使得操作赋值的业务流程变得简单。Linq to SQL 应用在业务逻辑层和数据访问层。尽管简单的增、删、改功能在数据访问层进行了封装,更多的请求要求业务逻辑层的响应速度快。这就是为什么Linq to SQL贯彻整个业务层和数据访问层的原因。
2.Web Portal和Widgets(部件)架构
任何Web Protal的核心是它支持Widgets(部件)并且支持用户自定义起始页面,意思就是用户可以提供自定制的服务,不管是公司的一个部门还是第三方。
书中所说的Defaut.asp就是我们所说的一个ASP.NET实现的用于显示widgets和允许用户添加、删除、移动、自定义并且这些操作不会刷新的主页。应用程序记录下用户自定义的页面的样式。Web Protals允许非注册用户使用添加widgets、编辑、删除、创建页面和设置参数。
一个Dropthings的Widgets就是一个ASP.NET的Web Control。可以是一个用户控件也可以是服务器端控件并且符合ASP.net的生命周期规则。Widgets支持PostBacks、ViewState、Sessions和Caches。唯一不同的地方是所有Widgets都实现了IWidget接口来调用核心框架提供的各种服务。一个自定义的AJAX Control实现了drag-and-drop功能。
每个Widget都包含在框架和容器中,容器(container)提供具有标题、编辑链接、最大、最小化和关闭按钮的标题栏。Widget被加载在标题栏下方的主体部分。事件包括改变标题、编辑链接的click事件、最大、最小和关闭按钮事件调用IWidget接口。
Web Portal实现了异步的请求和异步数据处理,使得用户很少刷新页面。Widgets是一种支持ASP.NET请求机制的控件。因此Dropthings的核心就是Widget,不久你就会感觉到所有Widget都是包含在UpdatePanel中并且全部支持异步请求。虽然你可以不用注册就可以使用自定义Widget,哪怕你在不同的计算机上再次登录也会显示你先前自定义的页面布局。ASP.NET的membership(会员管理)和profile(配置)允许匿名用户有持久状态知道注册用户后进行转换。页面和Widget状态存储在数据库表中。
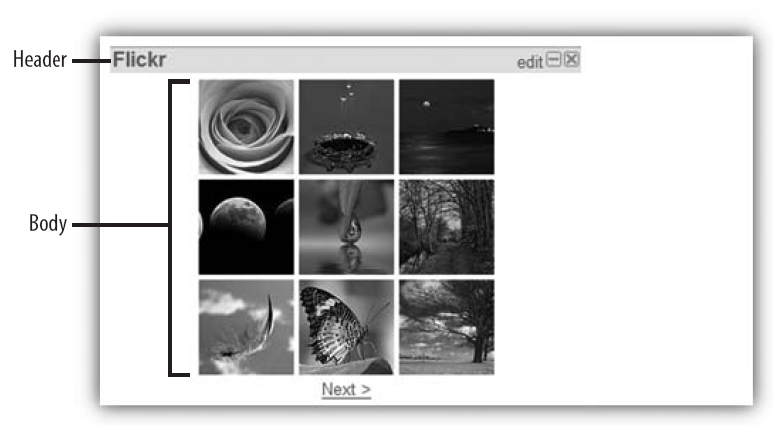
Object Model 对象模型
ASP.NET的membership包含User和Role。如果用户创建了一个或多个页面,每个页面包含一个或多个Widget实例。Widget实例和Widget不同之处类似于面向对象中的类和对象,例如,Flickr图片Widget是一个用于加载Flickr图片的Widget,当一个用户添加它到一个页面后,也就是实例化了一个Widget成为了一个实例。本书中所说的widget实际上都是widget实例。
如图所示:
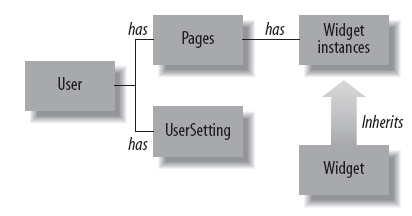
Application Components 应用程序组件
Dropthings使用门面模式来提供一个统一的业务逻辑接口。实现对子系统的访问处理用户、页面、widgets和etc。门面命名为DashboardFacade,结构如图:
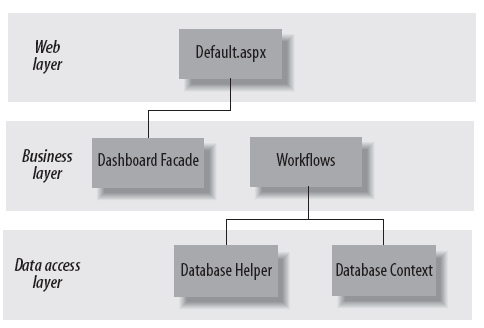
Web层Default.aspx调用DashboardFacade执行添加Tab或Widget、存储Widget状态。DashboardFacade调用具体工作流的操作进行处理。工作流利用Window Workflow Foundation进行实际的处理。每个工作流都包含多个活动(Activities)。每个活动类似于只实现一个功能的类。活动使用DatabaseHelper和DashboardDataContext类操作数据库。DatabaseHelper用于执行通用的数据库操作。DashboardDataContext是用于Linq to SQL的类到数据库表之间的映射。
Data Model 数据模型
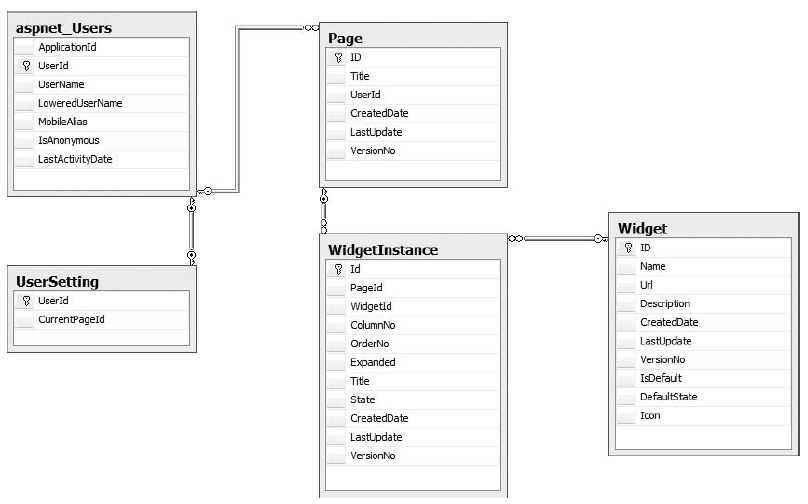
数据模型中应用了ASP.NET的Membership的数据库表aspnet_Users包含所有用户帐户。
具体各表的内容如下:
- aspnet_Users:是ASP.NET的membership默认的表。不过这个表只包含未注册用户信息,注册用户信息存储在aspnet_membership表。图中没有显示,因为它和其他表没什么关系。
- Page:通过UserId与aspnet_users建立主外键关系。
- Widget:存储Widget的详细内容和信息。存储每个widget的标题和是否动态加载。也存储用户第一次访问时创建的默认设置。
- WidgetInstance:通过WidgetId和PageID分别与Page和Widget表建立关系。
- UserSetting:同过UserId与aspnet_Users表建立关系。
具体表的描述如下:
| Table | 列 | 索引类型 | 描述 |
| Page | UserID | Nondusted | 用户页面利用Where UserID=<ID>进行加载 |
| Page | ID | Clusted | 页面的主键,编辑页面用于查询 |
| Widget | ID | Clusted | 部件的主键,当一个部件实例创建后关联到部件ID |
| Widget | IsDefault | Nondusted | 第一次访问,默认部件被创建到页面上。IsDefault设定哪些部件被创建。 |
| WidgetInstance | ID | Clusted | 部件实例的主键,用于更新删除部件实例标示实例。 |
| WidgetInstance | UserID | Nondusted | 用户ID,用于按用户读取部件实例。 |
备注:
- 簇集索引使用的是自增加的整形字段。因为SQL Server本身的数据库文件管理就是基于簇集索引的。如果不选择自动增加的主键当Insert和Delete时候比较麻烦。
- 外键值不是子增加的字段是因为他们不需要增加。
文件结构:
Dropthings是基于C#语言的ASP.NET项目。源码可以从http://www.codeplex.com/dropthings处下载。
Default.aspx:
控制所有Widget的起始页面。
WidgetService.asmx
声明通过起始页面对Widget所有操作的Web Service。
Proxy.asmx
允许Widget引用其他第三方的扩展资源和Web service的接口。
WidgetContainer.ascx
所有Widget的容器,起到核心框架和实际Widget之间的桥梁作用。
所有Widget在Widget文件夹下,每个Widget都是一个Web Control,用到的图片、css、js文件都保存在Widget中的子文件夹下。
Update Panels
UpdatePanel允许整个站点的任何部分都可以进行AJAX异步请求操作。不过,UpdatePanel最重要的是支持拖拽。使用多个UpdatePanel时,多个异步请求同时更新页面会很慢。当你嵌套使用UpdatePanel会更加复杂。所以设计时一定要注意布局。
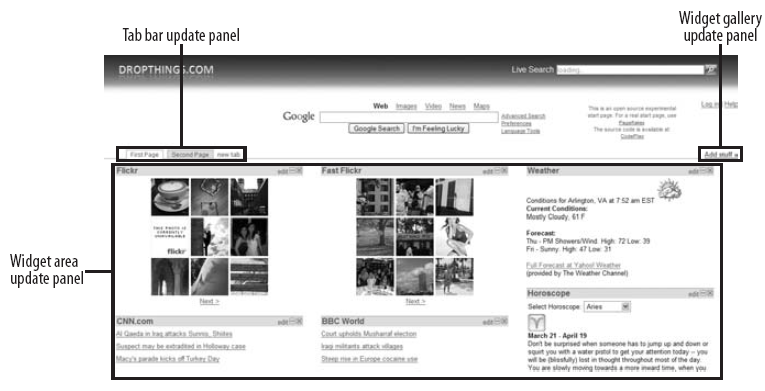
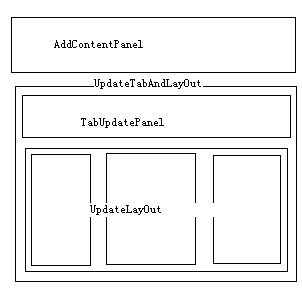
Dropthings中,所有Widget包含在一个UpdatePanel(ID=UpdatePanelLayout)中,因为当用户切换Tab时需要整体加载页面。并且每个Tab创建和修改后的页面都包含在另一个UpdatePanel(ID=TabUpdatePanel),因为Tab可以动态增加。从Widget列表中添加Widget也是一个UpdatePanel(ID=AddContentUpdatePanel)。如图所示。
代码如下:
<!–添加WidgetUpdatePanel–>
<asp:UpdatePanel ID="AddContentUpdatePanel" runat="server" UpdateMode="conditional">
<ContentTemplate>
….略
</ContentTemplate>
</asp:UpdatePanel>
<!–Tab和内容UpdatePanel–>
<asp:UpdatePanel ID="UpdatePanelTabAndLayout" runat="server" UpdateMode="conditional">
<ContentTemplate>
<!–Tab面板 –>
<asp:UpdatePanel ID="TabUpdatePanel" runat="server" UpdateMode="conditional">
<ContentTemplate>
<div id="tabs">
<!– 组件容器UpdatePanel–>
<asp:UpdatePanel ID="UpdatePanelLayout" runat="server" UpdateMode="conditional">
<ContentTemplate>
<!–自定义的三列UpdatePanel –>
<uc3:WidgetPanels ID="WidgetPanelsLayout" runat="server" />
</ContentTemplate>
</asp:UpdatePanel>
</li>
</ul>
</div>
</ContentTemplate>
</asp:UpdatePanel>
</ContentTemplate>
</asp:UpdatePanel>
这样将所有的Widget都放在一个UpdatePanel中的结果是更新或添加Widget时需要更新整体UpdatePanel。当以不更新时要产生大量的异步请求HTML和JavaScript。比较好的解决办法是没列包含一个UpdatePanel,不是整个Widget区域。当你拖拽一个widget跨列时,只是JavaScript进行页面间的处理,不需要更新updatePanel,只需要告诉服务器哪个widget被移动了。服务器端可以像客户端一样计算widget的坐标,这样除了增加和删除修改新的widget需要进行异步请求,其他时候都不要发送请求。

拖拽操作
有两种方法实现拖拽:Free Form 和Columnwise,Protopage 用FreeForm实现的拖拽,这样的应用依赖绝对坐标,widget可以拖拽到任意位置。iGoogle和Live.com 是使用Column-wise实现的拖拽,允许你在列间进行widget的拖拽。Column-wise方式清晰布局widget,大部分web protal都使用这种方式。
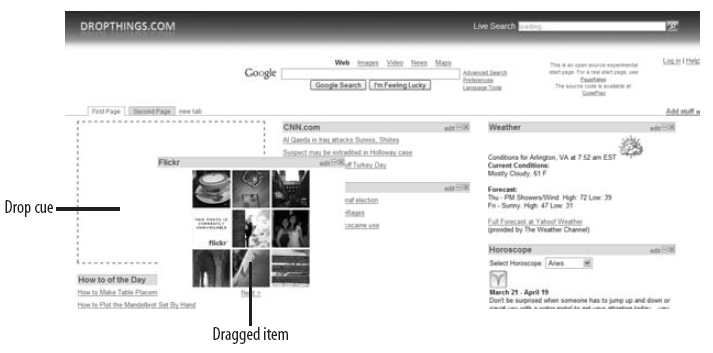
实现多列间的拖拽操作,整个页面被分成三列,每列包含一个ASP.NET的Panel控件。Widget可以添加到任意panel中。拖拽功能是自定义的功能。拖动存在两种方式:一种是本列中的排列顺序拖动,一种是列间的拖动。
如果我们在ASP.NET的AJAX框架中实现IDropTarget接口实现每列的拖拽区,每个widget作为一个IDrogSource在列间拖动。更有意思的是能够记录下widget的坐标值。例如,拖拽一个widget下移,widget会自动向上填充空出的地方。同样你移动一个widget到另一个上方,widget会自动下移到移动的widget下方。这些功能都是类似Extenders的实现的,所以你可以简单的实现一个panel的extender,它将实现类似IDropTarget的功能,并记录坐标。
当拖拽完成我们怎么实现异步存储坐标到服务器呢?当我们拖拽完毕,UI界面进行了更新,但是服务器不知道。任何请求操作都会触发服务器端响应因为需要刷新页面或列。服务器需要异步获得坐标值并存储,但是客户端拖拽完毕后根本体会不到坐标已经发送到服务器。另外一个问题是整个form实现拖拽只基于一个extender。Extenders需要依附于Column Panel并作为一个拖拽目标,也就是widget的拖拽句柄允许widget被拖拽到任何目的。
下面的内容我们将分析如何处理添加widget和起始页面的容器。
使用Widget框架
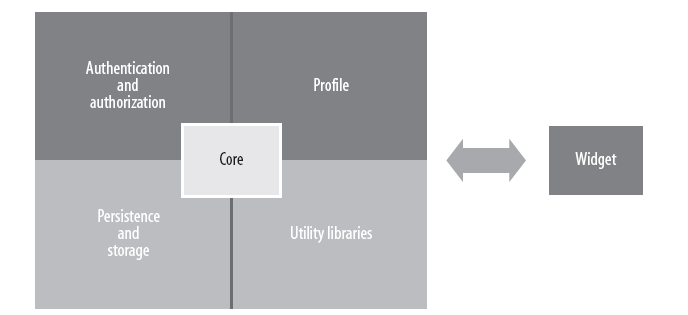
Dropthings使用一个weidget框架提供了widget相关的功能:验证、权限、配置、存储。Widget从这个框架获得这些功能。如图所示。
而且,你不要依赖任何对象就能创建widget。在你本地开发的计算机上不需要整个web portal的源代码就能创建widget。你只需要创建一个ASP.NET2.0的普通站点,创建一个用户控件,让它实现一个标准的请求响应处理,实现一个接口,仅次而已。
不必要担心基于Dropthings框架中的AJAX和javascript。这个框架允许你使用任何ASP.NET2.0的AJAX组件和Ajax Control Toolkit控件。服务器端支持.NET2.0,3.0,3.5利用View state存储临时状态信息。ASP.NET缓存用来缓存widget数据。这种方式比用javascript进行缓存要好得多。
Dropthings框架中使用了ASP.net的membership实现了验证和权限管理。允许widgets加载时获得当前用的配置信息。核心持久化了保存了用户的状态也就是用户的操作,例如对widget的展开、关闭装提以及增加、删除、修改操作。Widget和核心通过一个widget容器进行交互。widget container包含一个widget起到中介的作用。widget container对widget实例提供类似持久化服务和事件响应。page 包含多个wiget container,但是每个widget container只包含一个widget实例。如图
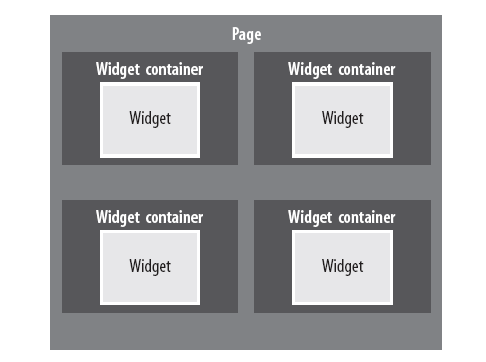
Widget很简单,就是一个标准的web Control,你可以在page_load事件中编写代码。也可以从ASP.net用户控件定义事件。Widgets类似与SharePoint Web Parts,但是比Web Part好的地方是你可以使用ASP.net控件到自定义控件。用户控件用Visual Studio编辑,你不用自定义控件。你也可以创建widget到.ascx文件中,不要编辑成dll或者发布dll到服务器,只需要拷贝ascx文件到web文件夹中。
比如你想显示fickr的照片。可以创建一个web control作为widget来实现。下面的代码实现了当页面加载时调用fickr的service功能:
protected void Page_Load(object sender, EventArgs e)
{
if( !base.IsPostBack )
this.ShowPictures(0);
else
this.ShowPictures(PageIndex);
}
在这个widget中加入linkbutton来用于切换图片,编写linkbutton的onclick时间用来浏览图片,代码如下:
protected void LinkButton1_Click(object sender, EventArgs e)
{
if( this.PageIndex > 0 ) this.PageIndex –;
this.ShowPictures(this.PageIndex);
}
protected void LinkButton2_Click(object sender, EventArgs e)
{
this.PageIndex ++;
this.ShowPictures(this.PageIndex);
}
ASP.NET的页面生命周期类似于普通页面处理。在widget中你可以使用ASP.NET的组件和编写这些组件的事件响应代码。
Container提供了widget容器和框架并且定义了header和body区域。实际上widget是运行时被widget container加载到body区域的。页面上的每个widget都是首先创建一个widget container然后widget container在动态加载widget实例到它的body区域。widget container是框架的一部分,你只需要编写一次。widget开发者不需要编写container因为他们只需要编写widget就行了,container已经定义好了。
widget container是web control当加载页面时候用于动态创建每个widget实例。widget也是一个web control在widget container的Page.LoadControl(.,.)事件中动态加载。实际上widget是被加载到UpdatePanel控件中的。因此,不管什么时候都是widget实例都是发送请求的,widget container没有进行任何请求处理操作。
设计Widget Container
设计好Container的关键问题是如何准确获得UpdatePanels。如何布局ASP.NET到UpatePanel中是个问题。将每个widget container放在一个UpdatePanel中足够处理。但是有个问题就是UpdatePanel中需要动态添加HTML代码。当UpdatePanel更新时将删除现有的HTML代码重新读取ASP.NET组件并重新创建。结果,所有extenders的之前生成的HTML内容将被清除,除非extenders一直在UpatePanel。将extenders放在UpdatePanel中就意味着每次刷新UpdatePanel将初始化并创建一个extenders实例。每次请求处理后UI界面将刷新慢,特别是在页面上使用widget时候。
需要将Header和Body分别放在两个Updatepanel中,这样修改Widget时只刷新Body区域不必刷新Header区域,但是所有的Extender需要加载在Header区域,这样就不必每次都加载Extender来减少处理时间提高响应速度。如图所示。
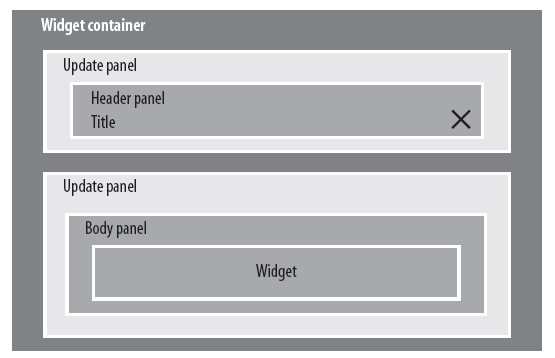
不过,最好是将UpdatePanel包含在HeaderPanel中,只将标题和LinkButton放在UpdatePanel中,这样不用刷新UpdatePanel时(比如单击LinkButton后)重新创建HeaderPanel区域,仅仅需要更新title和LinkButton就可以了.下面的图显示了将HeaderPanel放在UpdatePanel外的设计:

WidgetContainer 实现很简单。Header区只包含标题、最小化、最大化、隐藏按钮和一个body区域用于动
态加载widget。图2.4所示的Dropthings文件结构中所示的WidgetContainer.ascx定义了WidgetContainer
,代码如下:
Example 2-1. The .ascx content for the WidgetContainer
<asp:Panel ID="Widget" CssClass="widget" runat="server">
<asp:Panel id="WidgetHeader" CssClass="widget_header" runat="server">
<asp:UpdatePanel ID="WidgetHeaderUpdatePanel" runat="server"
UpdateMode="Conditional">
<ContentTemplate>
<table class="widget_header_table" cellspacing="0"
cellpadding="0">
<tbody>
<tr>
<td class="widget_title"><asp:LinkButton ID="WidgetTitle"
runat="Server" Text="Widget Title" /></td>
<td class="widget_edit"><asp:LinkButton ID="EditWidget"
runat="Server" Text="edit" OnClick="EditWidget_Click" /></td>
<td class="widget_button"><asp:LinkButton ID="CollapseWidget"
runat="Server" Text="" OnClick="CollapseWidget_Click"
CssClass="widget_min widget_box" />
<asp:LinkButton ID="ExpandWidget" runat="Server" Text=""
CssClass="widget_max widget_box" OnClick="ExpandWidget_Click"/>
</td>
<td class="widget_button"><asp:LinkButton ID="CloseWidget"
runat="Server" Text="" CssClass="widget_close widget_box"
OnClick="CloseWidget_Click" /></td>
</tr>
</tbody>
</table>
</ContentTemplate>
</asp:UpdatePanel>
</asp:Panel>
<asp:UpdatePanel ID="WidgetBodyUpdatePanel" runat="server"
UpdateMode="Conditional" >
<ContentTemplate><asp:Panel ID="WidgetBodyPanel" runat="Server">
</asp:Panel>
</ContentTemplate>
</asp:UpdatePanel>
</asp:Panel>
<cdd:CustomFloatingBehaviorExtender ID="WidgetFloatingBehavior"
DragHandleID="WidgetHeader" TargetControlID="Widget" runat="server" />
整个widgetContainer定义在命名为:Widget的Panel中。首先headerPanel包含Header区域和
WidgetHeaderUpdatePanel的UpdatePanel。它里面包含标题和最小化、最大化的LinkButton用来改变编辑
区域。 WidgetBodyUpdatePanel的UpdatePanel包含一个运行时创建的Widget,并且包含在一个Panel中,
加载widget 是在Page.LoadControl(..)事件中处理的,并添加到Body panel中。
CustomFloatingBehaviorExtender 用于添加widget的Header并且是整个widget支持拖拽。
3.使用ASP.NET AJAX 构建表示层
4.使用.Net3.5构建持久层和业务逻辑层
5.构建客户端Widgets(部件)
6.优化ASP.NET AJAX
7.创建异步,事务和WebService缓存
8.调试和优化服务器端性能
9.优化客户端性能
10.一般部署、发布问题解答
[教程]人工神经网络入门(0) —— 关于人工神经网络的FAQ
今天早上发了一篇关于ANN的文章,给大家演示了一个简单的学习AND运算和OR运算的程序,但是发现大家有很多疑问。
所以通过这篇文章,我希望能对大家的一些常见的疑问给予解答
这里的 训练 一词怎么解释?
学会?
大家通过使用这个程序可以发现:ANN在通过训练以后,可以计算出正确的结果,如1 AND 1 = 1,等等。
如果您阅读了代码会发现,程序中并没有给出如何计算1 AND 1的结果,而是将1,1这两个参数传递给经过训练后ANN,然后由ANN自己计算出结果。
在整个过程中,完全是ANN自己通过一定数量的训练从而达到咱们计算AND运算的结果。
貌似很深奥,不知道能够最终达到甚么效果,实现甚么功能,机器人??
如果您能够深入地了解ANN,最终会达到非常好的效果,特别是做AI这块。
比如RoboCup的仿真机器人比赛中就有应用,
还有一个非常有名的游戏《Bug Brain》,它就是一款通过给一个小虫子设计神经网络而可以在复杂的环境中生存的游戏。有兴趣的朋友可以去了解一下:)
关于这个游戏的玩法和攻略,可以参考http://hi.baidu.com/szk8888/blog/item/eb1d033b282ac7ea14cecb42.html
楼主,你要介绍哪种神经网络?我没看出来。。囧。。。
计划在这一系列文章中,介绍单层和多层(BP)神经网络。
人工神经网络入门(1) —— 单层人工神经网络应用示例 这个属于最简单明了的单层神经网络。介绍一个网络的主要原因就是帮助咱们先有一个感性的认识。
让我们知道ANN是什么,如果使用。
神经网络还真的不是很熟悉,楼主能否解释下这里,我看的不是很懂:
“计算结果”显示为“1.74E-10”,说明 0 AND 0 = 0. 在我的程序中,实际输出的结果只是接近于0,这是正常的。
神经网络计算出来的结果只是近似值。所以你可以在实际的应用中对这个近似值根据实际情况来处理。
你这个学习网络 来运算54 AND 0 结果为什么是1?
经过学习的ANN并不一定能计算出所有有效的输入的结果。
造成这样的原因很多,输入节点的个数,隐含层的层数,激活函数,网络类型,训练集合的选取等等。
而且您的54并不是有效输入,所以说结果不会理想。
[教程]人工神经网络入门(1) —— 单层人工神经网络应用示例
人工神经网络入门(1) —— 单层人工神经网络应用示例
范例程序下载:http://www.cnblogs.com/Files/gpcuster/ANN1.rar
如果您有疑问,可以先参考 FAQ
如果您未找到满意的答案,可以在下面留言:)
1 介绍
还记得在2年前刚刚接触RoboCup的时候,从学长口中听说了ANN(人工神经网络),这个东西可神奇了,他能通过学会从而对一些问题进行足够好处理。就像咱们人一样,可以通过学习,了解新的知识。
但是2年了,一直想学习ANN,但是一直没有成功。原因很多,其中主要的原因是咱们国内的教程中关于这个技术的介绍过于理论化,以至于我们基础差和自学者望而却步。
现在,我希望通过一个简单的示例,让大家先有一个感性的认识,然后再了解一些相应的理论,从而达到更好的学习效果。
2 范例程序的使用和说明
本程序示例2个简单的运算:
1 AND运算: 就是咱们常用的求和运算,如:1 AND 0 = 1
2 or运算: 就是咱们常用的求并运算,如:1 or 0 = 1
启动程序后,你将会看到如下的界面:
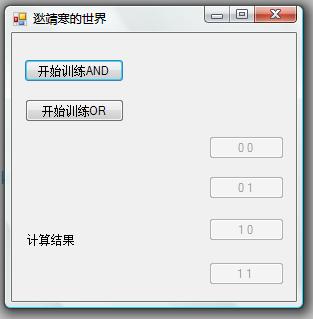
点击“开始训练AND”按钮后,程序就开始训练 AND 运算,并在训练结束后提示咱们。
同时界面变成如下:
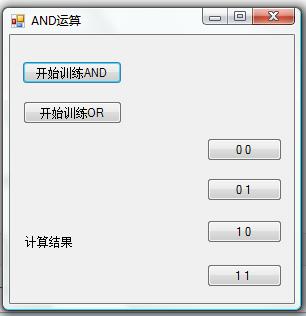
你只需要点击“0 0”按钮,就会在“计算结果”下面显示经过训练以后的ANN计算出来的结果。
如下所示:
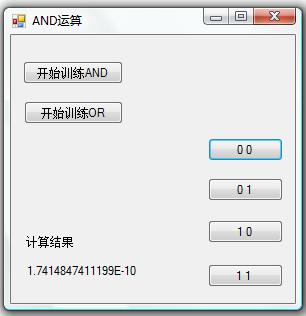
“计算结果”显示为“1.74E-10”,说明 0 AND 0 = 0.
这个结果就是我们想要的。训练成功
其他的按钮使用方法类似:)
3 计算过程
咱们可以参考一下AND计算的总体运行过程:
 //初始化训练集合
//初始化训练集合 TrainSet[] sets = new TrainSet[]{new TrainSet(0, 0, 0), new TrainSet(0, 1, 0),
TrainSet[] sets = new TrainSet[]{new TrainSet(0, 0, 0), new TrainSet(0, 1, 0), 

 new TrainSet(1, 0, 0), new TrainSet(1, 1, 1)}; //构造单层神经网络 2 个输入节点 1个输出节点 NeuralNetwork nn = new NeuralNetwork(2, 1); slnn = new SingleLayerNeuralNetworks(nn, sets); //训练 slnn.Train(); MessageBox.Show("AND运算训练结束"); this.button2.Enabled = true; this.button3.Enabled = true; this.button4.Enabled = true; this.button1.Enabled = true; this.Text = "AND运算";
new TrainSet(1, 0, 0), new TrainSet(1, 1, 1)}; //构造单层神经网络 2 个输入节点 1个输出节点 NeuralNetwork nn = new NeuralNetwork(2, 1); slnn = new SingleLayerNeuralNetworks(nn, sets); //训练 slnn.Train(); MessageBox.Show("AND运算训练结束"); this.button2.Enabled = true; this.button3.Enabled = true; this.button4.Enabled = true; this.button1.Enabled = true; this.Text = "AND运算";
OK,通过上面的代码可以看出,咱们的神经网络有2个输入节点,用于输入AND运算的2个参数。1个输出节点,用于输出AND运算的1个结果。
接下来,咱们的单层神经网络通过一个训练集(有一组输入和相应的希望输出数据)开始训练。训练结束后,咱们就可以用相应的数据对训练结果进行测试了(通过“0 0 ”等按钮)。
4 预告
在下一篇文章中,我将进行ANN基本概率的介绍和本示例实现的原理:)
5 总结
在本文中,咱们介绍了1个基于单层神经网络的简单易懂的程序示例,可以让大家先有一个感性的认识。
[理论]将看板管理应用到敏捷开发
摘要
看板1是丰田生产方式(Toyota Production System,TPS)中用来支持非集中“拉动式”生产控制(non-centralized "pull" production control) 而使用的卡片。作为精益生产的工具,它现在已经应用于世界各地的制造企业之中。如今在敏捷软件开发中,项目的可视化(例如在墙壁上放置任务卡片就是常见的 实践)往往被叫做“软件看板”,或者“任务看板”。我们甚至可以看到一些产品维护团队在类似瀑布过程模型中使用看板系统。那么,看板到底是什么呢?为什么 它会被用于软件开发环境之中呢?
在本文中,我首先解释一下在精益生产中,尤其是TPS中的看板是什么样子的,来理解下这个成熟行业中的实践和法则,并圈定可以应用 于软件开发的概念。其次,我将环顾我们的软件开发项目并指出看板应用的例子。然后,我会分析生产环境中的看板系统与软件开发中的看板系统有何异同,并尝试 提出观点来有效地在软件开发中应用看板系统,其中还介绍了新近在kanbandev2讨论列表中萌芽的“KSSE——持续工程的看板系统(Kanban System for Sustaining Engineering)”运动。最后,我给出TPS的一个全景视图,也就是看板这种工具的原始背景,软件开发仍可从中有所借鉴。
TPS中的看板
在“拉动式”生产系统中,看板是指示移动或者制造零部件的信号装置(通常是放在透明塑料封套中的卡片),它是在丰田生产系统(TPS)中发明和发展起来的。在介绍软件开发中的看板之前,我来详细的介绍下看板最初的用法,也就是TPS中的看板。
看板的目的是通过确保只有当下游工序需要时上游工序才生产零部件,进而最大限度地减少工序(process)之间的在制品(Work-In-Process,WIP)或者库存。“拉动式”是指下游工人从他们的上游工序中领取或者“拉”出所需要的零部件。

图1 看板和拉动式生产
图1是看板系统的抽象模型。图中以两个工序,上游工序和下游工序为例,其中上游工序为下游工序供应零部件。为了给最终用户提供产品,这一工序需要生 产零部件并将其流向下游,但是不能生产太多,因为生产过剩被认为是最糟糕的浪费。为了避免生产过剩,上游工序不是将成品零部件“推”给下游工序,反而是下 游工序主动地从上游工序中拉出(拿)零部件。零部件存放的地方叫做“仓库”(或者“超市3”——Taiichi Ohno首 次提出看板的思想,是在他参观了某个美国超市之后,在那里不是由商店售货员而是由顾客自己去获取他们想要的东西)。仓库位于上游工序,作为在制品的“缓冲 区”或者“队列”。当一名来自下游工序的工人——叫做“物料管理员”——来到仓库并拿到新近完成的零部件,同时他也反馈一个生产信号——也就是,下游从上 游中获取东西并在同时通过看板卡将信息推给上游。这是必须的,因为没有来自下游工序的信号上游工序决不会生产零部件。
那么在图1中有两种类型的看板一同工作:
- 领取看板(Withdraw Kanban)——是由物料管理员递交给仓库的购物清单。
- 生产看板(Production Kanban)——指示上游工序为其下游工序生产零部件。
如图1所示,领取看板循环于两道工序之间,而生产看板循环于工序内部,并且两者在仓库内发生交换。让我们稍微仔细的了解下这个交换细节。图2显示了在仓库中是如何进行“看板交换”。

图2 仓库中的看板交换
- 位于下游的物料管理员收到领取零部件的信号。此信号由下游工序定义,为下面两种情况之一:
(a) 由收集到的领取看板的数量触发信号
(b) 由定时时间间隔触发信号
物料管理员带着空托盘(pallet)和收集到的领取看板访问上游仓库,并将他收集的领取看板当作购物清单——其中标明了下游工序需要什么,需要多少。 - 由上游工序完成的零部件用托盘装着,并附上生产看板放入仓库。(这些发生在一个单独的线程中,和(1)是独立的。)
- 物料管理员拿取领取看板(购物清单)中指定的零部件,检查是否与附在零部件上的生产看板相匹配,然后交换两个看板。
- 他将生产看板放入“生产板(Production Board)”中——稍后当看板累计到一定的阀值时,它将直观地触发上游生产。
- 物料管理员将所需的零部件附带着领取看板一同从仓库搬运至下游车间。
你可以看到仓库是由一个单独的线程控制的、位于两个工序之间的队列(queue),它通过看板来交换物品和信息。看板卡上面写明了像零部件号码、名称、数量、托盘类型、仓库位置这样的信息,这样物料管理员拿到卡片就知道去做什么了。
对于看板的运转有着严格的规定——被称作“看板六准则”:
- 客户(下游)工序精确按照看板上指示的数量领取产品。
- 供应者(上游)精确按照看板上指定的数量和顺序生产产品。
- 没有任何产品在看板之外制造或者流动。
- 每件产品每时每刻都要与看板相伴。
- 质量残次和数量有误的产品决不能发往下游工序。
- 谨慎地减少看板的数量来降低库存并揭露问题。
正如我们所了解到的,仓库用作零部件的队列,托盘用作零部件的载体,而看板卡用作客户之所需的信息载体。通过维持“连续流通(continuous flow)”(消除等待带来的浪费)和“最小化在制品(minizing WIP)”(消除生产过剩带来的浪费)之间的平衡,它们共同形成了“拉动式”系统。在超市中也是用同样的机制来把从采购到销售之间的流程中的在制品维持在 “适当”数量,做好这一步是提高商店盈利率的关键。
目前为止,我已经讲述了看板是如何在制造业中工作的。注意以上是对真实看板系统的简化模型。这里没有明确提及的另一件事是看板形象地向每一个工人展示了信息和产品的流程,并激励在现场5(Gemba,指工作场所)的改善4(Kaizen,指工序改进)。改善源于对现场中发生事件的关注。通过看板,每个工人(不是管理人员)都可以看到生产流程,进而有机会发现其中的浪费,并建议改进他们所在的工序。
看板的特性
根据前一节的详细介绍,这里列出了从TPS最初的看板概念中总结的特性和作用。
- 实体的:看板是实体的卡片。可以拿在手中,可以移动,可以放在某些东西上面或者里面。
- 限制在制品数量:看板限制在制品的数量,也就是防止生产过剩。
- 连续流通:它会在仓库耗尽库存之前通知生产的需求。
- 拉动式:下游工序从上游工序中抽取零部件。
- 自导向(Self-Directing):它有要完成的工作的所有信息,能以一种非集中的方式实行生产自治,并且不需要微管理(micro-management)。
- 可视化:堆放或者张贴着的看板直观地展示了当前的状态和进度。
- 信号:看板的可视化状态为下一步的领取操作或者生产操作作出指示。
- 改善(Kaizen):可视化的流程触发并刺激改善。
- 附着的(Attached):看板附在所供给的零部件之上并随其一同移动。
图3为以上9个特性之间的相互影响,它显示了如何将这些组成一个因果效应网络。你从中可以看到看板的两种含义,一是“在维持连续流通的同时限制在制品数量”,而另一种是“改善”。

图3 看板的特性和作用
图表右侧说明了如何在维持连续流通的同时,最大限度地减少在制品。如果仓库中的在制品太少的话,下游工序不得不等待所需的零部件准备就绪,但是在制品还应该保证最小化以防止生产过剩。这样看来这两个目标是相矛盾的,而看板正被看作是解决这个难题的策略。
看板附着于零部件,并且可以被收集和重用,因此看板的数量是固定的。而且看板还可以直观地指示下游工序仅当需要时才获取零部件。这里有两种限定在制品数量的机制。
第一个机制“附着的看板”工作机制同“能量守恒定律”类似。一旦根据产品市场销售的速度和当前工序的内在变化规律确定了看板的数量,那么不管零部件的流入 和流出如何,在制品的数量都被限制为看板数量的一定比例。在任何时候,看板(相当于系统中的“能量”)的最大数量都与在制品的上限保持守恒。在图4中,你 可以看到“系统”指的是上游工序和下游工序之间的库存,也就是“仓库”中的在制品。

图4 限定在制品数量的看板机制
第二个机制——“拉动式”——通过依据下游消耗速度来确定上游工序的生产速度,这种机制也限制了在制品的数量。第一个机制仅仅涉及到在制品的数量,而第二个则涉及到流程——流程的方向和速度。
“方向”——仅由下游工序来驱动生产。
“速度”——通过看板传达下次生产的时机和数量。
通过确保上游工序的生产以下游工序首次衍生订单中的消耗为依据,“拉动式”限制了在制品的数量。通过在仓库中交换看板,将生产控制信息从下游推到上游,这种依赖性便得以实现。
回到图3:图表左侧说明了如何促使工作自导向并促进改善。通过查看张贴在面板上的看板卡,每个人都可以了解到发生了什么事,以及工序运转的健康状 态。改善起始于对现场(Gemba)工作流的观测。放置于面板之上的看板卡直观地帮助工作在没有中央控制管理之下自导向。为了支持改善,这种自治的工序向 外提供其性能数据,并将管理重点从对具体工作的指派或者调度上转移到改善活动。
图3中的箭头最终都指向了三个结果,如其所示,看板的终极目标可以表示为“限制在制品数量”、“连续流通”和“改善”。看板系统在维持“连续流通”的同时“限制在制品数量”。它缓冲由普通变因引起的变化情况,并暴露特殊变因引起的变化情况,以备改善。
软件开发中的看板
现在,让我们将视线回到我们自己的工作领域——软件开发。在敏捷软件开发中,通过在项目工作场所的墙上张贴卡片来呈现和分享项目状态已经成为一种常见的实践。我已经在我的上一篇InfoQ文章《用“看板图”实现敏捷项目的可视化》[Hiranabe07]给出了很多例子。特别是,贴在墙上用来展示当前项目状态的任务卡片有时也被称作“任务看板”或者“软件看板”[Poppendieck03]。图5是Change Vision公司的JUDE6开发团队所用的任务看板。

图5 敏捷看板
在面板上,工程任务用卡片(即时贴)来代表,并通过把卡片贴在在面板中的不同区域来象征任务的状态,这些区域被标注为“ToDo”、“Doing” 和“Done”(标注的名称可能因地而异,比如“进行中(In Progress)”、“已测试(Tested)”、“已验收(Accepted)”、“停滞中(Blocking)”等等。)。这样的看板面板有利于可 视化地通知任务并限制在制品(处理中的任务)数量。不过在这里并没有出现“工序”(上游或者下游),新出现的概念是“迭代”。对于每一次迭代,通过分解用 户故事识别出任务,并且将其张贴在面板的ToDo区域中。
这是一个拉动式系统吗?在制造业中,零部件由上游工序传递至下游工序。而在图5所示的敏捷开发中,并没有看到“移交物”。一个看板卡片对应一个任 务,上面写明了如下信息:任务编号、任务名称、估计时间以及任务领取人的名字。任务有状态,可以是“ToDo”、“Doing”或者“Done”,状态信 息被分享给整个团队。敏捷开发重视在一起工作,并趋向于减少团队内部的移交物。我称此为“敏捷看板”。
图6是另一个看板面板实例,由Yamaha Motor Solution有限公司7所采用。

图6 持续看板(Sustaining Kanban)
在这里,看板系统被用于带有流程的传统瀑布开发模型。项目被分解成“设计”、“开发”、“验证”等连续的工序,而看板卡就在这些工序之间移动。每张 卡片代表需要修改或者添加的系统需求,也代表给下游工序的移交物。注意这不是一个标准的瀑布流程——标准瀑布流程中所有的需求在同一时间内完成“设计”, 而“开发”和“验证”则在另一时间,这将使得所有的卡片作为一个整体进行移动。与标准的瀑布流程不同的是,这个项目中的卡片是一个接一个地移动,就像制造 业中的单件流(one-piece-flow)一样。这里表现的是产品生命周期里稳定的“持续(sustaining)”阶段,处在带有流程的瀑布状态转 换模型的管理之下。在这里,你可以清楚地看到“工作流程”的概念,而不同于敏捷中的“迭代”概念。它比敏捷看板看起来更像工厂中的看板,而且通过制定规则 只允许下游工序移动卡片8,可以使其成为拉动式系统。我称其为“持续看板”,这与稍后章节中讨论的David Anderson的“持续工程的看板系统”是类似的。
图7显示的是另外一个例子——在整个产品开发流程的价值流中使用看板的思想实验(thought experiment)[Poppendieck 07]。

图7 精益+敏捷看板
假设在一个产品开发流中有客户团队、产品所有人、开发团队和QA团队,他们使用队列传递移交物来协调工作,以使得团队之间能异步工作,并维持工作速 度。每一个“DONE”空间是一个队列,其工作方式就像制造工厂中的“仓库”那样,并且看起来非常像TPS看板系统。同时,它看起来就像每条工序内同步地 使用敏捷看板,而在贯穿各个工序的整个价值流上异步地使用持续看板。我认为看板系统可以扩展至覆盖整个价值流,在这种情况下,它是价值流的一个活生生的视 觉表现。
在这里例子中,通过设定每一个区域的大小可以限制在制品的数量。而为了使其变成拉动式系统,还需要一种机制来使下游工序以某种信号通知上游工序开始 工作。其中一种方法是制定一个规则只允许下游移动DONE区域中的卡片来通知上游。另一种方法是定期召开“迭代会议”,来同步团队和团队之间传递(通讯) 的信息。这两种通讯方式可能对应于我们在第一章节中讨论的零部件领取的两种信号,即领取看板的数量(a)和时间间隔(b)的可视信号。一次迭代中的一组用 户故事对应于迭代中托盘里的零部件,而零部件的数量对应于迭代中的项目“生产率”(昨日天气[Beck00])。我叫它为“精益+敏捷看板”,如下一个例 子展示的那样它可以与“敏捷看板”相结合。
图8中是一个小型的“便携式”看板系统,这是我在CENTRAL COMPUTER SERVICES有限公司的某个项目里发现的。在这个项目中,团队被分为了几个小型子团队(通常是一对人)。整个团队有一个与图7概念相似的工作流,还有 图8所示的小型敏捷看板面板(ToDo、Doing、DONE)。 当一个子团队选取了一个用户故事,他们将其分解到任务并张贴在便携式看板面板上。在这种情况下,看板系统由两个层面组成,在项目层面一张卡片代表一个用户 故事,而在团队(或者结对)层面一张卡片代表一个任务。
他们很喜欢这个便携式小型看板系统,并命名为“看板nano”。

图8 便携式敏捷看板(“看板nano”)
如你所见,将看板的概念应用于软件开发有许多方式。“敏捷看板”用来在团队中分享信息并使工作自导向,但它不支持流程。“持续看板”是另一种类型的 看板,能够让小批量的维护工作在几个状态之间流转。这种结合便是“精益+敏捷看板”,使用“持续看板”贯穿价值流,同时在子流(sub-stream)中 使用“敏捷看板”。
注意,图5中的“敏捷看板”(在当今敏捷项目中随处可见)仅仅可以看到价值流中的一个子流。当你考虑从客户到客户的完整价值流,经常由处于同一流中 的某个团队递交给你需求,而另一个团队则交付你的工作结果给客户。这篇文章的目的之一,就是要设法让看板的应用超越“敏捷看板”,扩大看板在价值流中的应 用范围。
生产与开发
软件开发是不同于生产活动或者制造活动的。软件工程师每次创造的产物都是不同的,而制造业总是周而复始的生产相同的东西。所以直接将两者等同起来是 危险的。可是,让我们研究一下如何在软件开发看板中找到TPS看板中的特性。表1显示了我们在章节1中总结的看板特性在我们已经提及的两种软件看板中是否 仍然有效。

图5所示的敏捷看板例子本身并没有实现“限制在制品的数量”、“连续流通”和“拉动式”特性。敏捷看板更关注于实现任务、“可视化”和“自导向”,以便帮助团队自治并改进其工序。为了使工序连续流通并限制在制品的数量,需要召开“迭代会议”交流信息。
图6中的“持续看板”不仅可以限制在制品的数量,还可以以“单件(one-piece)”和“拉动式”的方式控制流程,而不需要召开迭代会议。在这种方法中,它的关注点是“限制在制品的数量”、“连续流通”和“拉动式”,同时允许团队(或者管理人员)借其改进工序。
回顾一下图3,我将看板的特性和作用分成图9所示的两个关键区域,以便上面提到的两类软件看板概念的用途各得其所。图10显示了生产和开发的频谱 图。生产是成功几率很高(高于99%)的工序,而开发的成功几率要低。当成功几率在50%左右的时候敏捷是理想的开发方法,而当成功几率超过90%的时候 瀑布式则是理想的开发方式(依据Shannon理论,一个具有50%成功几率的项目是最有价值的项目)。通常随着开发进入到支持维护状态,修改缺陷和添加 新功能的成功几率逐步提高。
看板系统的“工序控制焦点(Process Control Focus)”适合在“高于90%”的成功率下工作,而“工序改进焦点(Process Improvement Focus)”既适合在50%成功率也适合在90%成功率下工作。
值得注意的是,敏捷方法在产品维护状态(sustaining mode )下仍能工作良好,同样看板的“工序改进焦点”特性也在维护状态下工作良好。

图9 看板的特性和作用(2)

图10 使用看板的方法频谱
KSSE——持续工程的看板系统
接下来,我介绍最近出现的一种软件开发精益应用。Agile2007会议时,我参加了David Anderson主持的关于软件看板的一个会中会(Conference-Within-A-Conference,CWAC)。他在 Corbis.com管理着一个“维护状态(maintenance mode)”类型的看板系统,并发表了一篇相关论文——持续工程的看板系统[Anderson 07]。他的方法首先关注于看板的“限制在制品数量”特性——就像在图4所示的抽象图表那样——也关注“自导向”特性以使得团队自组织,减少自上而下的 (top-down)管理。然后,通过看板观察流程,找出整个工序流中的驻点(stagnation point)并调整人力资源,也就是在工序间调动成员。这意味着他的方法,像图3表现的那样,涵盖了看板特性中从“限制在制品数量”、“自导向”到“改 善”。
会议之后,Anderson启动了一个看板开发邮件列表2,这里已经成为将看板应用于软件开发的一个新兴知识创新讨论社区,名为“KSSE”——持续工程的看板系统,读作Kiss-ee ;-)。Aaron Sanders还着手创建关于看板的知识体系,并已经开始构建KSSE词汇表。
KSSE对于通过队列在工序间传递移交物、连续相接的多个工序运作良好。请注意KSSE不一定需要纳入“迭代”的概念。使用KSSE的方式,我看到了另一种缩放(scaling)敏捷的可能性方式并且好过“scrum of scrums”。[Ladas07]
创造价值流
当通过看板从敏捷放大到精益时,一张看板卡应该代表什么东西呢?
在敏捷看板系统中,一个卡片是一个从“用户故事”中分解出来的“任务”。在开发团队中,它作为工作的一个基本单元执行,因为团队中每个人都能明白 它的意思。但是,在看板系统中它贯穿了价值流中的多个工序(多个团队),在其中流转之物应该带有客户认可的价值。既然这样,看板卡片就不是对应于“工作 (work)”而是对应于“功能(feature)”,并且它不是WBS(任务分解结构,work breakdown structure)的组成部分,而是FBS(功能分解结构,feature breakdown structure)的组成部分。因此团队中的每个人,甚至是客户,都能够理解看板的含义和流转之物的价值。Jim Highsmith 在《敏捷项目管理(Agile Project Management)》[Highsmith04]书中所概述的原理也将FBS定位高于WBS。
“用户故事”,“Backlog事项”或者“用例”都被抽象为“MMF”(最小可市场化功能,minimum marketable features),用来明确地声明流转之物具有客户价值。于是精益开发就可以说成“使得MMF快速流过整个价值流。”
图5中“敏捷看板”的例子是一个工作的分解,它在团队内部工作良好。图6中“持续看板”的例子是一个功能的分解并且一张卡片代表一个MMF。图7中“精益+敏捷看板”的例子与图8一起展示了上级功能分解和下级工作分解的结合。
一旦建立起工作流程,五个“精益思想”[Womack1996]的核心概念就可直接应用于整个工序。精益工序的管理可以简单地遵循以下原则。
- 从客户的角度定义价值——确定和分类MMF
- 明确价值流并消除浪费——找出驻点(停滞的任务)
- 在客户的拉动下创造价值流——制定看板的拉动规则
- 关注员工并给予一定的权力——授权给在现场的团队
- 追求完美的持续改善——反省和改善
TPS全景视图
以下内容相当于附录,我在这一部分分享从TPS中学到,并发现可以适用于软件开发的知识。Mary和Tom Poppendieck已经发现有效的软件开发方式和精益或者TPS方法有着很多的相同点——不是在实践层面,而是在原理层面上 [Poppendieck03, 07]。让我们从更高的角度回过头来再看下TPS中的看板。
读者很容易假定看板是整个TPS的中心,但其实并不是。图11展示了TPS的概念结构,有时也叫做“TPS之屋(TPS House)”。它有好几种版本,图11是基于Toshiko Narusawa和John Shook的版本[Narusawa06]。在TPS中,看板仅仅是“拉动式系统”实现准时制(Just-In-Time9)的一种方法。准时制可以解释为“仅在需要的时候生产和交付所需要的东西,并且仅完成需要的数量”。它直接瞄准的是客户的需要:“尽快以最低的价格提供最高质量的产品。”注意,准时制是TPS的两大支柱之一,另一个是Jidoka10(译 注:写作“自动化/自働化”,但其含义与对应于Automation的中文的“自动化”不同,详见注释)。制造业中的“Jidoka”即自动停机 (Autonomation)与软件开发中的测试驱动开发类似。Mary和Tom Poppendieck把Jidoka解释为“停止流水线文化(Stop the Line Culture)”。丰田工厂的工人真正地可以停止流水线而不是把次品推到下一个工序——它不仅是一种规定,也是丰田公司的一种文化,它的萌芽可以追溯到 (丰田集团创始人)丰田佐吉时期。

图11 TPS概念结构
准时制由以下三部分元素构成,“节拍时间(Takt time)”、“连续流通”和“拉动式系统”。
- 节拍时间基于销售率制定产品生产率。
- 连续流通与节拍时间相匹配,无停滞地在工序中生产部件。
- 拉动式系统在工序之间移动零部件并通知生产,同时限制库存数量。
也应该注意到两个支柱依赖于改善和人。丰田一年生产近千万辆汽车,同时,他们通过在现场(也就是车间)中近1百万次的改善来完善他们的工序。形象化地表示出团队正在做些什么,总是改善的出发点。
结论
文中,我分析了看板在制造业的实施,接着列出了看板的特性。看板系统用以达到以下目标:
- 更优的工序控制——在限制在制品数量的同时保持连续流通
- 更优的工序改进——使流程可视化并且激励改善
“敏捷看板”专注于#2,而“持续看板”专注于#1。我提出将两者结合,来拓展可视化和“拉动式系统”到整个价值流,以使得整个生产精益化。
感谢
Tom Poppendieck与Mary对本文进行了通篇审校,并给出了许多见解和建议,在此我表示非常感谢。感谢Yamaha Motor Solution有限公司总裁Yasuharu Terai以及Ryuichi Sato允许本文中使用其看板系统的图片。另外David Anderson也参与了本文的审校工作并且提出了一个更好的看板抽象层次来推进KSSE的发展。KSSE概念最初来源于Kanbandev Yahoo团队的讨论。最后感谢Deborah Hartmann的最后校订工作,使得我的表达更清晰。
关于作者
Kenji HIRANABE是日本Change Vision公司的CEO。他是JUDE(一个集成了ERD、DFD和Mind Map的UML编辑器)和TRICHORD 11(一 个集成了Burndown图表和Parking Lots图的敏捷项目管理看板系统)的创始人。他还把《Lean Software Development》、《XP Installed》、《Agile Project Management》以及其他XP/Agile书籍翻译成日文。Kenji把软件开发看作是一种沟通游戏,并一直在寻求提高软件开发的生产效率、合作程 度以及乐趣的途径。
参考文献
TPS
- [Ohno78] Taiichi Ohno, "Toyota Seisan Houshiki", 1978 (English: "Toyota Production System", 1988). The bible of TPS. This is a MUST book for lean practicioners.
- [Narusawa06] Toshiko Narusawa, John Shook, "Eigo de Kaizen, Toyota seisan houshiki", 2007(Japanese and English). Recently published English/Japanese parallel translation of TPS.
- [Ishii05] Masamitsu Ishii, "Toyota no moto-koujousekininnsha ga oshieru nyuumon Toyota seisan houshiki", 2005. Includes a version of TSP concept structure.
- [Monden06] Yasuhiro Kadota, "Toyota Production System", 2006(English: "Toyota Production System 3rd", 1998). The bible of implementation of TPS. I studied Kanban discussion in section 1 from this book.
敏捷和精益的主流文献
- [Reeves92] Jack W. Reeves, "What is Software Design?" C++ Journal, 1992. My favorite article about Software Design.
- [Kent00] Kent Beck and Martin Fowler, "Planning Extreme Programming", 2000, Addison-Wesley. About planning of release and iteration. Yesterdays weather and project Velocity idea first explained in detail in the book.
- [Poppendieck03] Mary and Tom Poppendieck, "Lean Software Development", 2003 Addison-Wesley. The first classic of drawing lines between TPS and software development.
- [Highsmith04] Jim Highsmith, "Agile Project Management", 2004, Addison-Wesley. Feature breakdown structure is introduced as a practice of APM.
- [Poppendieck07] Mary and Tom Poppendieck, "Implementing Lean Software Development", 2006 Addison-Wesley. Explains Kanban in lean and how it works as a pull process mechanism.
- [Cockburn06] Alistair Cockburn, What engineering has in common with manufacturing and why it matters" 2006. Alistair has another discussion of viewing unvalidated decision as WIP in software engineering process.
最近出现的看板概念
- [Hiranabe07] Kenji Hiranabe, "Visualizing Agile Projects using Kanban", http://www.infoq.com/articles/agile-kanban-boards. A Colletion of visualization methods and Kanban in Agile development workplace
- [Anderson07] David Anderson, "A Kanban System for Sustaining Engineering on Software Systems", http://www.agilemanagement.net/Articles/Papers/AKanbanSystemforSustainin.html. His experience in Corbis.com with a Kanban system
- [Sanders07] Aaron Sanders, "Kanban Ground Rules Example for a Specific Team Kanban System for Software Engineering – KSSE", http://aaron.sanders.name/kanban/kanban-ground-rules-example-for-a-specific-team. Also creating a body of knowledge of KSSE.
- [Ladas07] Corey Ladas, "Lean scales differently than Agile", http://leansoftwareengineering.com/2007/09/03/lean-scales-differently-than-agile. Kanban can be another possible way of scaling agile in a lean and flat way, unlike "scrum of scrum".
1关于看板的更多信息http://en.wikipedia.org/wiki/Kanban
2关于kanbandev的更多信息http://finance.groups.yahoo.com/group/kanbandev
3关于Taiichi Ohno的更多信息http://en.wikipedia.org/wiki/Taiichi_Ohno
4关于改善的更多信息http://en.wikipedia.org/wiki/Kaizen
5关于现场的更多信息http://en.wikipedia.org/wiki/Gemba
6JUDE是一个集成了UML、ERD、DFD和Mind Map的可视化软件编辑器。点击http://jude.change-vision.com/了解更多信息。
7Yamaha Motors有硬件产品生产线,因此他们的软件团队有很好的条件从工厂中学习精益思想。在我参观他们公司的时候,看到了许多用于软件项目可视化的 “XFDs”(极限反馈装置,extreme feedback devices),这与他们工厂中的可视化管理系统——“行灯(Andon)”是类似的。
8虽然无关紧要,但知道那些红盒子(工序)表示是由中国外包生产的也很有趣。
9关于准时制的更多信息http://www.toyota.co.jp/en/vision/production_system/just.html
10关于Jidoka的更多信息http://www.toyota.co.jp/en/vision/production_system/jidoka.html
11关于TRICHORD的更多信息http://trichord.change-vision.com/
查看英文原文:Kanban Applied to Software Development: from Agile to Lean
[教程]Linq to SQL 基础教程
Contents
- Introduction
- Background
- What is LINQ to SQL
- How to Use LINQ to SQL
- Enhanced Features
- Points of Interest
- Other LINQs
Introduction
This article demonstrates what LINQ to SQL is and how to use its basic functionality. I found this new feature amazing because it really simplifies a developer's Debugging work and offers many new ways of coding applications.
Background
For this article, I have used the Northwind database sample from Microsoft. The database is included in the ZIP file or can be found on the Microsoft website.
What is LINQ to SQL
The LINQ Project is a codename for a set of extensions to the .NET Framework that encompasses language-integrated query, set and transform operations. It extends C# and Visual Basic with native language syntax for queries. It also provides class libraries to take advantage of these capabilities. For more general details, refer to the Microsoft LINQ Project page.
LINQ to SQL is a new system which allows you to easily map tables, views and stored procedures from your SQL server. Moreover, LINQ to SQL helps developers in mapping and requesting a database with its simple and SQL-like language. It is not the ADO.NET replacement, but more an extension that provides new features.

How to Use LINQ to SQL
Create a New C# Project
In this section I'll show you how to use LINQ to SQL from the start, at project creation.
- Create a new Windows form application with Visual C# 2008.
- Make a new "Data Connection" with the SQL Server 2005 northwind.mdf file.
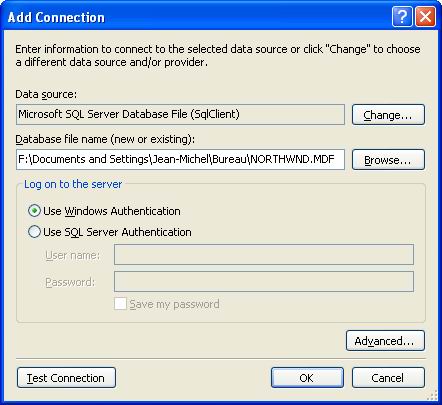
- Add a new item to your project and choose "LINQ to SQL Classes." Name it NorthwindDataClasses.dbml. This new DBML file will contain the mapping of SQL Server tables into C# classes.
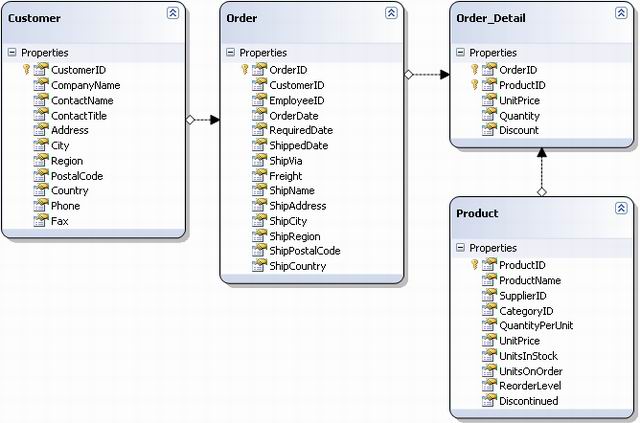
The Object Relational Designer is a design surface that maps a database table into a C# class. To do that, just drag and drop tables from the database explorer into the designer. The designer automatically displays the tables in a UML way and represents the relationship between them. For example, I have dragged and dropped the four tables Customers, order, order_Detail and Product, as shown below:
In NorthwindDataClasses.designer.cs (under NorthwindDataClasses.dbml from the project explorer), you will find definitions for all classes corresponding to tables like this:
| SQL | LINQ to SQL O/R Designer |
| Table name | Class name |
| Columns | Attributes |
| Relations | EntitySet and EntityRef |
| Stored procedures | Methods |
[Table(Name="dbo.Customers")]
public partial class Customer : INotifyPropertyChanging, INotifyPropertyChanged
{
private static PropertyChangingEventArgs emptyChangingEventArgs =
new PropertyChangingEventArgs(String.Empty);
private string _CustomerID;
private string _CompanyName;
private string _ContactName;
private string _ContactTitle;
private string _Address;
private string _City;
private string _Region;
private string _PostalCode;
private string _Country;
private string _Phone;
private string _Fax;
private EntitySet<Order> _Orders;
//..............
}
Understanding DataContext
dataContext is a class that gives direct access to C# classes, database connections, etc. This class is generated when the designer is saved. For a file named NorthwindDataClasses.dbml, the class NorthwindDataClassesDataContext is automatically generated. It contains the definition of tables and stored procedures.
Understanding the var Keyword
This keyword is used when you do not know the type of the variable. Visual Studio 2008 automatically chooses the appropriate type of data and so does IntelliSense!
Examples:
var anInteger = 5;
var aString = "a string";
var unknown_type = new MyClass();
Querying the Database
Once the database is modeled through the designer, it can easily be used to make queries.
Query the Customers from Database
//creating the datacontext instance
NorthwindDataClassesDataContext dc = new NorthwindDataClassesDataContext();
//Sample 1 : query all customers
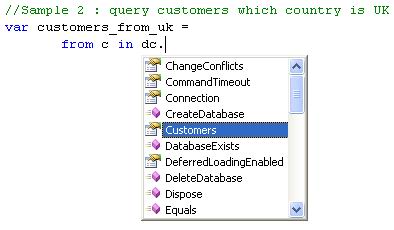
var customers =
from c in dc.Customers
select c;
//display query result in a dataGridView
dataGridResult.DataSource = customers.ToList();
Query the Customers with a Simple Statement
//Sample 2 : query customers which country is UK
//constructing the query
var customers_from_uk =
from c in dc.Customers
where c.Country == "UK"
select c;
Query Specified Columns Only, Returning a Collection of a Specified Class
Use a very simple class definition.
public class CMyClassTwoStrings
{
public CMyClassTwoStrings(string name, string country)
{
m_name = name;
m_country = country;
}
public string m_name;
public string m_country;
}
For example:
//Sample 4a : query customers(name and country) which contact name starts with a 'A'
//using specific class
var customers_name_starts_a_2col_in_specific_class =
from c in dc.Customers
where c.ContactName.StartsWith("A")
select new CMyClassTwoStrings (c.ContactName, c.Country );
//using the returned collection (using foreach in
//console output to really see the differences with the dataGridView way.)
foreach (CMyClassTwoStrings a in customers_name_starts_a_2col_in_specific_class)
Console.WriteLine(a.m_name + " " + a.m_country);
Query Specified Columns Only, Returning a Collection of an Undefined Class
//Sample 4b : query customers(name and country) which contact name starts with a 'A'
//using anonymous class
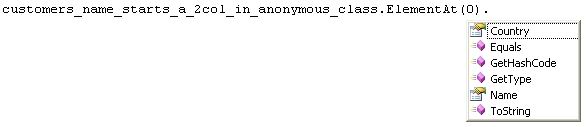
var customers_name_starts_a_2col_in_anonymous_class =
from c in dc.Customers
where c.ContactName.StartsWith("A")
select new {
Name = c.ContactName, //naming the column Name
Country = c.Country //naming the column Country
};
foreach (var a in customers_name_starts_a_2col_in_anonymous_class)
Console.WriteLine(a.Name + " " + a.Country);
This example demonstrates how to use an anonymous class that is (in this example) composed of two strings. The aim of this feature is to create a new class for temporary storage that the developer does not want (or need) to declare. It may be useful in some cases where the declaration of class is used only for storage.
For example, in the sample 4a, the class CMyClassTwoStrings is used only to create the interface between the query engine and the output in the console. It is not used anywhere else and is a loss of time. This new way of writing enables the developer to create temporary classes with an unlimited number of attributes of any type. Every attribute is named, either by specifying the name with Name = c.ContactName or by leaving the attribute without, i.e. Name =. IntelliSense also works with anonymous classes!
Query Multiple Tables
//Sample 5 : query customers and products
//(it makes a cross product it do not represent anything else than a query
var customers_and_product =
from c in dc.Customers
from p in dc.Products
where c.ContactName.StartsWith("A") && p.ProductName.StartsWith("P")
select new { Name = c.ContactName, Product = p.ProductName };
The resulting collection is the cross product between all contact names starting with "A" and all products starting with "P."
Query with Tables Joined
//Sample 6 : query customers and orders
var customers_and_orders =
from c in dc.Customers
from p in dc.Orders
where c.CustomerID == p.CustomerID
select new { c.ContactName, p.OrderID};
This example demonstrates how to specify the relation between tables' joins on an attribute.
Query with Tables Joined through entityref
//Sample 7 : query customers and orders with entityref
var customers_and_orders_entityref =
from or in dc.Orders
select new {
Name = or.Customer.ContactName,
orderId = or.OrderID,
orderDate = or.OrderDate
};
In this example, the entityref property is used. The class orders have an attribute named Customer that refers to the customer who realizes the order. It is just a pointer to one instance of the class Customer. This attribute gives us direct access to customer properties. The advantage of this feature is that the developer does not need to know exactly how tables are joined and access to attached data is immediate.
Query in the Old Way: with SQL as String
As you may want to execute SQL that is not yet supported by LINQ to SQL, a way to execute SQL queries in the old way is available.
//Sample 8 : execute SQL queries
dc.ExecuteCommand("Update Customers SET PostalCode='05024' where CustomerId='ALFKI' ");
Insert, Update and Delete Rows from Database
LINQ to SQL provides a new way of managing data into database. The three SQL statements Insert, Delete and Update are implemented, but using them is not visible.
Update Statement
//Sample 9 : updating data
var customers_in_paris =
from c in dc.Customers
where c.City.StartsWith("Paris")
select c;
foreach (var cust in customers_in_paris)
cust.City = "PARIS";
//modification to database are applied when SubmitChanges is called.
dc.SubmitChanges();
To make modifications to a database, just modify any relevant object properties and call the method SubmitChanges().
Insert Statement
To insert a new entry into the database, you just have to create an instance of a C# class and Attach it to the associated table.
//Sample 10 : inserting data
Product newProduct = new Product();
newProduct.ProductName = "RC helicopter";
dc.Products.Attach(newProduct);
dc.SubmitChanges();
Delete Statement
Deleting data is quite easy. When requesting your database, give a collection of data. Then just call DeleteOnSubmit (or DeleteAllOnSubmit) to delete the specified items.
//Sample 11 : deleting data
var products_to_delete =
from p in dc.Products
where p.ProductName.Contains("helicopter")
select p;
dc.Products.DeleteAllOnSubmit(products_to_delete);
dc.SubmitChanges();
IntelliSense
IntelliSense works into the query definition and can increase developer productivity. It's very interesting because it pops up on DataContext, tables and attributes. In this first example, IntelliSense shows the list of tables mapped from the database, the connection instance and a lot of other properties.
For a table, the list contains all of its columns:
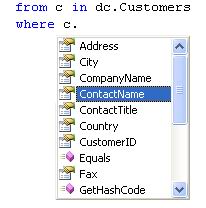
For an attribute, it will display methods and properties depending on the type (string, integer, etc).
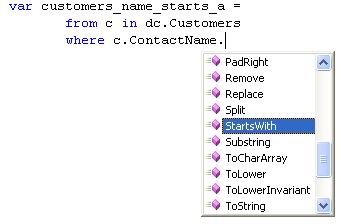
Order of Operations
To use LINQ to SQL, a developer must know exactly when a query is executed. Indeed, LINQ to SQL is very powerful because the query is executed when it's required, but not at definition! In the first sample, we have this code:
///constructing the query
var customers =
from c in dc.Customers
select c;
The query is not yet executed; it is just compiled and analysed. In fact, the query is run when the code makes an access to the customer variable, like here:
//display query result in a dataGridView
dataGridResult.DataSource = customers.ToList();
Enhanced Features
Other LINQ to SQL Options
LINQ to SQL supports deferred loading options. This functionality allows a user to modify query engine behaviour when retrieving data. One of them is the deferred loading that will load all the data of a query. As an example, a query on the order table gives you entry to the customer properties by entityref. If Datacontext.DeferredLoadingEnabled is set at true (default) then the Customer attribute will be loaded when an access to the order entry is made. Otherwise (when at false), it is not loaded. This option helps a developer when optimizing requests, data size and time for querying. There is a good example about that here.
Manage Conflicts
When the function SubmitChanges() is executed, it starts by verifying if there is no conflict that occurs by an external modification. For a server/client application, the application must take conflicts into account in case multiple clients access the database at the same time. To implement conflict resolution, SubmitChanges() generates a System.Data.LINQ.ChangeConflictException exception. The DataContext instance gives details about conflicts to know why exactly they throw. I wrote a basic conflict resolution, but I will not give the full details of all other possibilities because I think it should be an entire article.
try{
//query the database
var customers_in_paris_conflict =
from c in dc.Customers
where c.City.StartsWith("Paris")
select c;
foreach (var cust in customers_in_paris_conflict)
cust.City = "PARIS";
//Make a breakpoint here and modify one customer entry
//(where City is Paris) manually (with VS for example)
//When external update is done, go on and SubmitChanges should throw.
dc.SubmitChanges();
}
catch (System.Data.LINQ.ChangeConflictException)
{
//dc.ChangeConflicts contains the list of all conflicts
foreach (ObjectChangeConflict prob in dc.ChangeConflicts)
{
//there are many ways in resolving conflicts,
//see the RefreshMode enumeration for details
prob.Resolve(RefreshMode.KeepChanges);
}
}
If you want more details about conflict resolution, I suggest you to refer to this page (in VB).
Points of Interest
As a conclusion to this article, I summarize the important points of LINQ to SQL:
- LINQ to SQL is a query language
- Query syntax is verified at build (not at runtime like old SQL queries)
- IntelliSense works with all objects of LINQ to SQL
- Making queries is quite easy (select, insert, update and delete)
- Manage tables' PK/FK relationships
- Databases are automatically mapped to C# classes and queries return a collection of C# class instances
- Conflict detection and resolution
Other LINQs 😉
- Microsoft LINQ Project page
- Microsoft Database sample Northwind
- Blog about LINQ to SQL for advanced users with many examples and details
- Deferred loading
- Microsoft webcasts (French)
[代码]全国哀悼日 网站灰黑色CSS滤镜代码
根据国务院文件,5.19-5.21为全国哀悼日,在此期间,全国和各驻外机构下半旗志哀,停止公共娱乐活动,外交部和我国驻外使领馆设立吊唁簿。5月 19日14时28分起,全国人民默哀3分钟,届时汽车、火车、舰船鸣笛,防空警报鸣响。 Admin5与很多草根网站都将整站换成素装。并建议中国所有站点更换为素装。 国务院决定5月19日至21日为全国哀悼日 http://www.admin5.com/article/20080518/85035.shtml
为方便站点哀悼,特提供css滤镜代码,以表哀悼。以下为全站CSS代码。
| html { filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=1); } |
使用方法:这段代码可以变网页为黑白,将代码加到CSS最顶端就可以实现素装。建议全国站长动起来。为在地震中遇难的同胞哀悼。
如果网站没有使用CSS,可以在网页/模板的HTML代码<head>和</head> 之间插入:
| <style> html{filter:progid:DXImageTransform.Microsoft.BasicImage(grayscale=1);} </style> |
有一些站长的网站可能使用这个css 不能生效,是因为网站没有使用最新的网页标准协议
| <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> |
请将网页最头部的<html>替换为以上代码。
有一些网站FLASH动画的颜色不能被CSS滤镜控制,可以在FLASH代码的<object …>和</object>之间插入:
| <param value="false" name="menu"/> <param value="opaque" name="wmode"/> |
最简单的把页面变成灰色的代码是在head 之间加
| <style type="text/css"> html { FILTER: gray } </style> |
一般的discuz论坛在 你的控制css 文件下修改
/images/header/header.css 这个文件,点源码即可看到 参考 http://bbs.admin5.com
另在哀悼日或遇难的新闻,所有专题和主题 图片上不能使用红色标题。