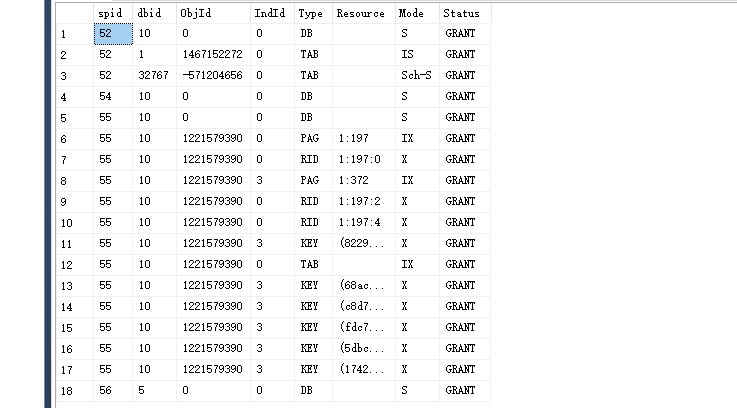
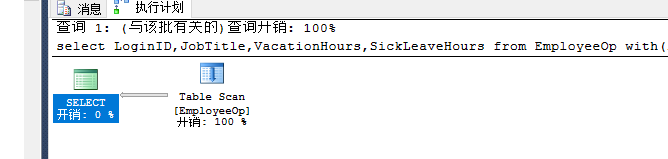
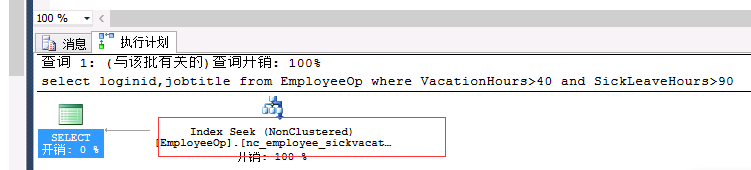
来源: .Net内部缓存System.Web.Caching.Cache 和Redis缓存缓存工厂切换_naileiforever的专栏-CSDN博客_.net cache和redis
有个问题,以前系统采用的是System.Web.Caching.Cache
但是redis缓存的流行
分布式的流行,缓存就被切换了.
但是在redis缓存的环境需要配置,有时候要切换回来.
这时候就弄个缓存工厂切换.
改动小小的地方就ok.
namespace Yestar.Cache.Factory
{
///
/// Zhruanjian
/// 创建人:TD
/// 描 述:缓存工厂类
///
public class CacheFactory
{
///
/// 定义通用的Repository
///
///
public static ICache Cache()
{
return new Cache();
}
}
}
定义缓存抽象类
using System;
namespace Yestar.Cache
{
///
/// Zhruanjian
/// 创建人:TD
/// 描 述:定义缓存接口
///
public interface ICache
{
///
/// 读取缓存
///
///键 ///
T GetCache(string cacheKey) where T : class;
///
/// 写入缓存
///
///对象数据 ///键 void WriteCache(T value, string cacheKey) where T : class;
///
/// 写入缓存
///
///对象数据 ///键 ///到期时间 void WriteCache(T value, string cacheKey, DateTime expireTime) where T : class;
///
/// 移除指定数据缓存
///
///键 void RemoveCache(string cacheKey);
///
/// 移除全部缓存
///
void RemoveCache();
}
}
System.Web.Caching.Cache 缓存继承抽象类using System;
using System.Collections;
using System.Web;
namespace Yestar.Cache
{
///
/// 版 本 6.1
/// Zhruanjian
/// 描 述:缓存操作
///
public class Cache : ICache
{
private static System.Web.Caching.Cache cache = HttpRuntime.Cache;
///
/// 读取缓存
///
///键 ///
public T GetCache(string cacheKey) where T : class
{
if (cache[cacheKey] != null)
{
return (T)cache[cacheKey];
}
return default(T);
}
///
/// 写入缓存
///
///对象数据 ///键 public void WriteCache(T value, string cacheKey) where T : class
{
cache.Insert(cacheKey, value, null, DateTime.Now.AddMinutes(10), System.Web.Caching.Cache.NoSlidingExpiration);
}
///
/// 写入缓存
///
///对象数据 ///键 ///到期时间 public void WriteCache(T value, string cacheKey, DateTime expireTime) where T : class
{
cache.Insert(cacheKey, value, null, expireTime, System.Web.Caching.Cache.NoSlidingExpiration);
}
///
/// 移除指定数据缓存
///
///键 public void RemoveCache(string cacheKey)
{
cache.Remove(cacheKey);
}
///
/// 移除全部缓存
///
public void RemoveCache()
{
IDictionaryEnumerator CacheEnum = cache.GetEnumerator();
while (CacheEnum.MoveNext())
{
cache.Remove(CacheEnum.Key.ToString());
}
}
}
}
RedisCache 缓存类using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using ServiceStack.Redis;
namespace Yestar.Cache.Redis
{
///
/// 版 本 6.1
/// Zhruanjian
/// 描 述:定义缓存接口
///
public class Cache : ICache
{
///
/// 读取缓存
///
///键 ///
public T GetCache(string cacheKey) where T : class
{
return RedisCache.Get(cacheKey);
}
///
/// 写入缓存
///
///对象数据 ///键 public void WriteCache(T value, string cacheKey) where T : class
{
RedisCache.Set(cacheKey, value);
}
///
/// 写入缓存
///
///对象数据 ///键 ///到期时间 public void WriteCache(T value, string cacheKey, DateTime expireTime) where T : class
{
RedisCache.Set(cacheKey, value, expireTime);
}
///
/// 移除指定数据缓存
///
///键 public void RemoveCache(string cacheKey)
{
RedisCache.Remove(cacheKey);
}
///
/// 移除全部缓存
///
public void RemoveCache()
{
RedisCache.RemoveAll();
}
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using ServiceStack.Redis;
namespace Yestar.Cache.Redis
{
///
/// 版 本 6.1
/// Zhruanjian
/// 描 述:定义缓存接口
///
public class RedisCache
{
#region — 连接信息 —
///
/// redis配置文件信息
///
private static RedisConfigInfo redisConfigInfo = RedisConfigInfo.GetConfig();
private static PooledRedisClientManager prcm;
///
/// 静态构造方法,初始化链接池管理对象
///
static RedisCache()
{
CreateManager();
}
///
/// 创建链接池管理对象
///
private static void CreateManager()
{
string[] writeServerList = SplitString(redisConfigInfo.WriteServerList, “,”);
string[] readServerList = SplitString(redisConfigInfo.ReadServerList, “,”);
prcm = new PooledRedisClientManager(readServerList, writeServerList,
new RedisClientManagerConfig
{
MaxWritePoolSize = redisConfigInfo.MaxWritePoolSize,
MaxReadPoolSize = redisConfigInfo.MaxReadPoolSize,
AutoStart = redisConfigInfo.AutoStart,
});
}
private static string[] SplitString(string strSource, string split)
{
return strSource.Split(split.ToArray());
}
#endregion
#region — Item —
///
/// 设置单体
///
///
////////////
public static bool Set(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.Set(key, t);
}
}
///
/// 设置单体
///
///
////////////
public static bool Set(string key, T t, TimeSpan timeSpan)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.Set(key, t, timeSpan);
}
}
///
/// 设置单体
///
///
////////////
public static bool Set(string key, T t, DateTime dateTime)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.Set(key, t, dateTime);
}
}
///
/// 获取单体
///
///
//////
public static T Get(string key) where T : class
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.Get(key);
}
}
///
/// 移除单体
///
///public static bool Remove(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.Remove(key);
}
}
///
/// 清空所有缓存
///
public static void RemoveAll()
{
using (IRedisClient redis = prcm.GetClient())
{
redis.FlushAll();
}
}
#endregion
#region — List —
public static void List_Add(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
var redisTypedClient = redis.As();
redisTypedClient.AddItemToList(redisTypedClient.Lists[key], t);
}
}
public static bool List_Remove(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
var redisTypedClient = redis.As();
return redisTypedClient.RemoveItemFromList(redisTypedClient.Lists[key], t) > 0;
}
}
public static void List_RemoveAll(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
var redisTypedClient = redis.As();
redisTypedClient.Lists[key].RemoveAll();
}
}
public static long List_Count(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.GetListCount(key);
}
}
public static List List_GetRange(string key, int start, int count)
{
using (IRedisClient redis = prcm.GetClient())
{
var c = redis.As();
return c.Lists[key].GetRange(start, start + count – 1);
}
}
public static List List_GetList(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
var c = redis.As();
return c.Lists[key].GetRange(0, c.Lists[key].Count);
}
}
public static List List_GetList(string key, int pageIndex, int pageSize)
{
int start = pageSize * (pageIndex – 1);
return List_GetRange(key, start, pageSize);
}
///
/// 设置缓存过期
///
//////public static void List_SetExpire(string key, DateTime datetime)
{
using (IRedisClient redis = prcm.GetClient())
{
redis.ExpireEntryAt(key, datetime);
}
}
#endregion
#region — Set —
public static void Set_Add(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
var redisTypedClient = redis.As();
redisTypedClient.Sets[key].Add(t);
}
}
public static bool Set_Contains(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
var redisTypedClient = redis.As();
return redisTypedClient.Sets[key].Contains(t);
}
}
public static bool Set_Remove(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
var redisTypedClient = redis.As();
return redisTypedClient.Sets[key].Remove(t);
}
}
#endregion
#region — Hash —
///
/// 判断某个数据是否已经被缓存
///
///
/////////
public static bool Hash_Exist(string key, string dataKey)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.HashContainsEntry(key, dataKey);
}
}
///
/// 存储数据到hash表
///
///
/////////
public static bool Hash_Set(string key, string dataKey, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
string value = ServiceStack.Text.JsonSerializer.SerializeToString(t);
return redis.SetEntryInHash(key, dataKey, value);
}
}
///
/// 移除hash中的某值
///
///
/////////
public static bool Hash_Remove(string key, string dataKey)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.RemoveEntryFromHash(key, dataKey);
}
}
///
/// 移除整个hash
///
///
/////////
public static bool Hash_Remove(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.Remove(key);
}
}
///
/// 从hash表获取数据
///
///
/////////
public static T Hash_Get(string key, string dataKey)
{
using (IRedisClient redis = prcm.GetClient())
{
string value = redis.GetValueFromHash(key, dataKey);
return ServiceStack.Text.JsonSerializer.DeserializeFromString(value);
}
}
///
/// 获取整个hash的数据
///
///
//////
public static List Hash_GetAll(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
var list = redis.GetHashValues(key);
if (list != null && list.Count > 0)
{
List result = new List();
foreach (var item in list)
{
var value = ServiceStack.Text.JsonSerializer.DeserializeFromString(item);
result.Add(value);
}
return result;
}
return null;
}
}
///
/// 设置缓存过期
///
//////public static void Hash_SetExpire(string key, DateTime datetime)
{
using (IRedisClient redis = prcm.GetClient())
{
redis.ExpireEntryAt(key, datetime);
}
}
#endregion
#region — SortedSet —
///
/// 添加数据到 SortedSet
///
///
/////////public static bool SortedSet_Add(string key, T t, double score)
{
using (IRedisClient redis = prcm.GetClient())
{
string value = ServiceStack.Text.JsonSerializer.SerializeToString(t);
return redis.AddItemToSortedSet(key, value, score);
}
}
///
/// 移除数据从SortedSet
///
///
/////////
public static bool SortedSet_Remove(string key, T t)
{
using (IRedisClient redis = prcm.GetClient())
{
string value = ServiceStack.Text.JsonSerializer.SerializeToString(t);
return redis.RemoveItemFromSortedSet(key, value);
}
}
///
/// 修剪SortedSet
///
//////保留的条数 ///
public static long SortedSet_Trim(string key, int size)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.RemoveRangeFromSortedSet(key, size, 9999999);
}
}
///
/// 获取SortedSet的长度
///
//////
public static long SortedSet_Count(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
return redis.GetSortedSetCount(key);
}
}
///
/// 获取SortedSet的分页数据
///
///
////////////
public static List SortedSet_GetList(string key, int pageIndex, int pageSize)
{
using (IRedisClient redis = prcm.GetClient())
{
var list = redis.GetRangeFromSortedSet(key, (pageIndex – 1) * pageSize, pageIndex * pageSize – 1);
if (list != null && list.Count > 0)
{
List result = new List();
foreach (var item in list)
{
var data = ServiceStack.Text.JsonSerializer.DeserializeFromString(item);
result.Add(data);
}
return result;
}
}
return null;
}
///
/// 获取SortedSet的全部数据
///
///
////////////
public static List SortedSet_GetListALL(string key)
{
using (IRedisClient redis = prcm.GetClient())
{
var list = redis.GetRangeFromSortedSet(key, 0, 9999999);
if (list != null && list.Count > 0)
{
List result = new List();
foreach (var item in list)
{
var data = ServiceStack.Text.JsonSerializer.DeserializeFromString(item);
result.Add(data);
}
return result;
}
}
return null;
}
///
/// 设置缓存过期
///
//////public static void SortedSet_SetExpire(string key, DateTime datetime)
{
using (IRedisClient redis = prcm.GetClient())
{
redis.ExpireEntryAt(key, datetime);
}
}
#endregion
}
}
看起来是不是差不多了,然后redis缓存配置,配置不是大功告成.