在各种手机APP泛滥的现在,背后都有同样泛滥的API接口在支撑,其中鱼龙混杂,直接裸奔的WEB API大量存在,安全性令人堪优
在以前WEB API概念没有很普及的时候,都采用自已定义的接口和结构,对于公开访问的接口,专业点的都会做下安全验证,数据签名之类
反而现在,谁都可以用WEB API估接口,安全性早忘一边了,特别是外包小公司的APP项目,80%都有安全漏洞(面试了大半年APP开发得出的结论)
特在过年之前,整理了下在用的解决方案,本方案解决了
- 数据安全问题
- 标准消息结构
- 接口测试程序
- 接口文档体现
正文
数据结构
对于一个接口,返回的内容除了要返回业务数据外,还得返回处理状态,并且这个状态是在每个接口都得有
所以数据格式都会定义为:
数据头(描述数据信息)
———————————–
数据体(具体数据)
本文定义结构为

/// <summary>
/// 处理结果
/// </summary>
public class DealResult
{
/// <summary>
/// 处理结果
/// </summary>
public bool Result
{
get;
set;
}
/// <summary>
/// 消息
/// </summary>
public string Message
{
get;
set;
}
/// <summary>
/// 关联数据
/// </summary>
public object Data
{
get;
set;
}
}
所有接口都返回此对象,会描述本次请求的状态,和对应的数据,服务端则根据实际情况,返回处理结果和对应的数据
数据安全
开方式接口安全性就不用多说了,解决方法为加密,或数据签名验证,本文方案为进行数据签名
同返回的数据一样,提交到服务器的数据格式也统一约定,定义一个数据头基类
/// <summary>
/// 参数基类
/// </summary>
[Serializable]
public class ParameBase
{
string time = DateTime.Now.ToString("yyyy-MM-dd hh:mm:ss");
/// <summary>
/// 时间 格式 yyyy-MM-dd hh:mm:ss
/// </summary>
public string Time
{
get
{
return time;
}
set
{
time = value;
}
}
/// <summary>
/// 来源网站 = 1, IOS = 2,Android = 3, 微信 = 4
/// </summary>
public int SourceFrom
{
get;
set;
}
/// <summary>
/// 签名
/// </summary>
public string Token
{
get;
set;
}
}
一个登录对象表示为
/// <summary>
/// 登录
/// </summary>
public class Login : ParameBase
{
/// <summary>
/// 用户名
/// </summary>
public string Name
{
get;
set;
}
/// <summary>
/// 密码
/// </summary>
public string Password
{
get;
set;
}
}
数据签名表示为(KEY稍后讲到)
Token=MD5(属性值1+值2….+KEY)
按此对象表示为 MD5(Name+PassWord+Source+Time+KEY)
如果是GET参数怎么办,一样,按参数名计算,同时传递的参数要附带上Source,Time,Token
密钥机制
有的喜欢把密钥放在客户端,或固定密钥,显然都有安全问题,解决方法是动态获取
这就意味着在设计接口时,有一个接口是首先要调用的,让服务器返回密钥,于是就有了登录的概念
过程表示为
登录>返回用户信息和密钥=>存储用户信息和密钥=>使用密钥调用其它接口
这样只有登录者和服务器才知道自已的密钥了
综上所述,数据结构表示为
客户端提交结构为 ParameBase(附带签名信息)
服务端返回结构为 DealResult
登录机制
同网页请求一样,怎么知道多次调用是同一个人呢,这里采用了COOKIE的形式,登录后服务端返回一个COOKIE,客户端再请求时带上这个COOKIE
服务端需要存储这个COOKIE标识,所有的验证处理都会基于此标识来判断用户
有了上面基础,进入项目阶段
WEB API项目
其实用什么项目类型都行,只是WEB API方便了对象结构序列化和传参
默认WEB API路由RESUFUL形式,没有控制器方法,只能按METHOD来定义,很不方便,改成控制器的形式,这样就能用方法名来访问了
更改路由配置为
|
1
2
3
4
5
|
config.Routes.MapHttpRoute(
name: "DefaultApi",
routeTemplate: "api/{controller}/{action}/{id}",
defaults: new { id = RouteParameter.Optional }
);
|
在此文,数据分为请求和返回,以登录返回用户信息为例,登录为请求,用户信息为返回,示例对象结构为
用户对象
/// <summary>
/// 登录返回用户
/// </summary>
public class User
{
/// <summary>
/// 用户编号
/// </summary>
public int Id
{
get;
set;
}
/// <summary>
/// 名称
/// </summary>
public string Name
{
get;
set;
}
/// <summary>
/// 本次登录的KEY
/// </summary>
public string Key
{
get;
set;
}
/// <summary>
/// 本资登录的凭证
/// </summary>
public string Voucher
{
get;
set;
}
}
请求方式
这里只采用了GET,POST两种方式,根据实际情况定义,控制器方法一定需要都标明,不然会出现路由BUG
定义登录方法
 View Code
View Code这里可以看到,创建了两个GUID,一个为用户凭证,一个为用户密钥,放入用户信息返回,同时调用LoginStatusContext.SetLoginStatus保存登录信息
同时使用了AnonymousSign标注,此方法使用默认签名Setting.DefaultKey
定义获取用信息方法
/// <summary>
/// 基本信息
/// </summary>
/// <param name="name">参数name</param>
/// <returns>User</returns>
[HttpGet]
public DealResult GetBasicInfo(string name)
{
var user = new User() { Name = name, Id = CurrentUserId };
return DealResult(true, string.Empty, user);
}
示例控制器完整定义

/// <summary>
/// 帐号操作
/// </summary>
[SignCheckAttribute]
public class AccountController : BaseController
{
/// <summary>
/// 登录
/// </summary>
/// <param name="parame"></param>
/// <returns>User</returns>
[HttpPost]
[AnonymousSign]
public DealResult Login([FromBody] Login parame)
{
if (parame.Password != "123")
{
return DealResult(false, "密码不正确");
}
string key2 = System.Guid.NewGuid().ToString();
string voucher = System.Guid.NewGuid().ToString();
var user = new User() { Name = parame.Name, Id = 1, Key = key2, Voucher = voucher };
var timeDiff = (DateTime.Now - Convert.ToDateTime(parame.Time)).TotalSeconds;//保存客户端和服务端时间差
LoginStatusContext.SetLoginStatus(voucher, user.Id, key2, timeDiff);
CoreHelper.CookieHelper.AddCookies("user", voucher);//存入COOKIE
return DealResult(true, "", user);
}
/// <summary>
/// 基本信息
/// </summary>
/// <param name="name">参数name</param>
/// <returns>User</returns>
[HttpGet]
public DealResult GetBasicInfo(string name)
{
var user = new User() { Name = name, Id = CurrentUserId };
return DealResult(true, string.Empty, user);
}
/// <summary>
/// 测试异常
/// </summary>
/// <returns></returns>
[HttpGet]
public DealResult TestException()
{
int a = 0;
var b = 10 / a;
return DealResult(true);
}
}
此控制器标注了SignCheckAttribute用以进行签名判断
具体实现可看SignCheckAttribute代码
SignCheckAttribute里实现了有
- 数据签名判断
- 签名超时判断
- 用户登录限制
- 签名重复使用处理(一个签名只能使用一次)
- 过期登录用户处理(没有主动退出用户清理)
为了统一处理异常,配置了异常处理
|
1
|
GlobalConfiguration.Configuration.Filters.Add(new ExceptionAttribute());
|
对接口进行测试
大杀器来了,配合此方案放出了对应的测试工具,虽然WEB API有个扩展,但没法对此方案测试
使用此工具能方便按方案要求调用接口,为了方便参数拼接,POST和GET都采用URL参数的形式输入
测试登录/api/account/login
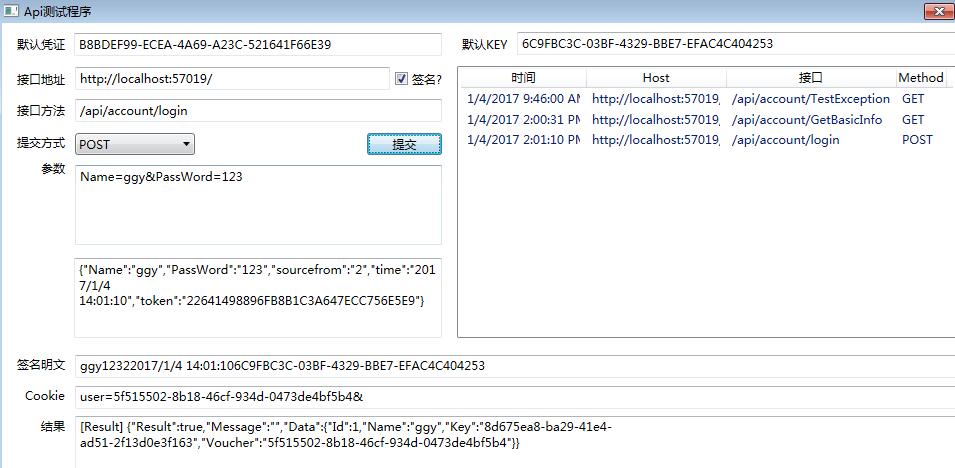
测试获取信息/api/account/GetBasicInfo

测试异常处理/api/account/TestException
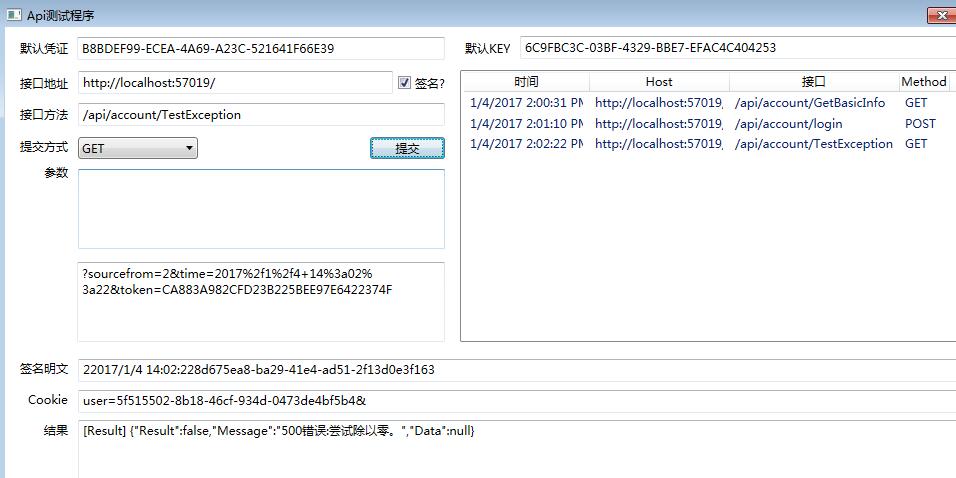
在未登录情况下调用获取信息

接口文档
接口结构文档一直是很让人头疼的事,手写更改了又得维护,版本不一样还麻烦,自动生成最好了,同样WEB API 带扩展没法表示此结构详细
大杀器2号来了,按代码注释动态生成接口文档,文档格式与控制器保持一致
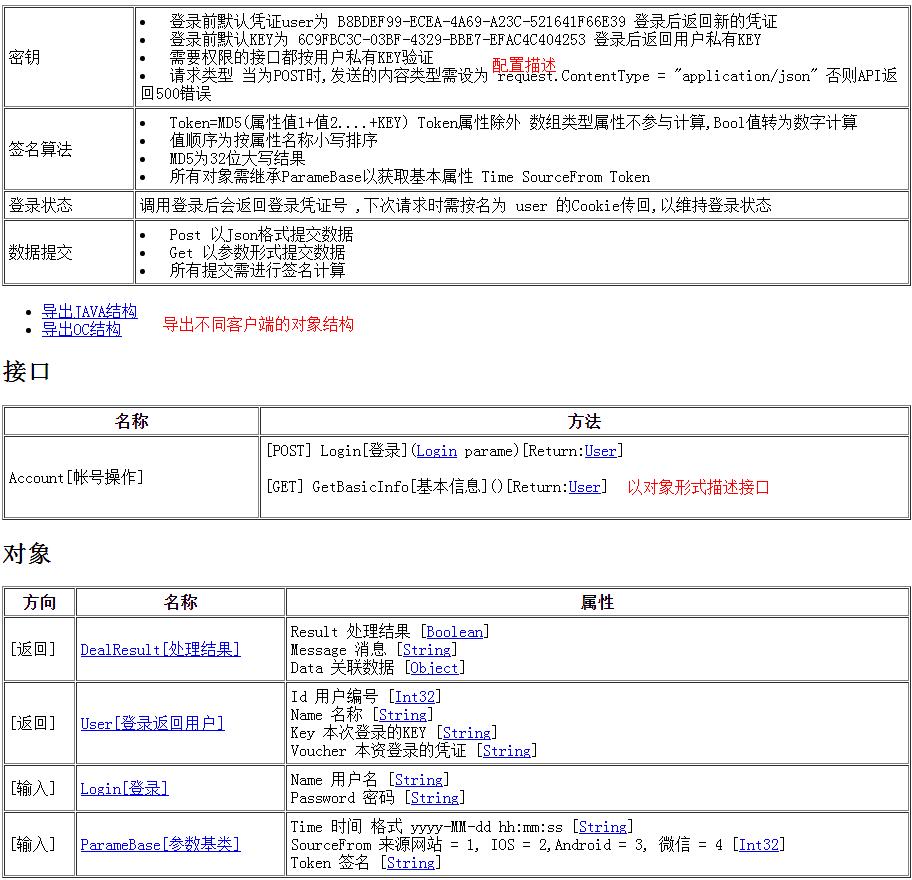
Home控制器代码实现
public ActionResult Index(SummaryAnalysis.ExportType exportType = SummaryAnalysis.ExportType.NONE)
{
if (exportType != SummaryAnalysis.ExportType.NONE)
{
var str = SummaryAnalysis.Load(exportType);
return File(str, "application/octet-stream", "Model_" + exportType + ".zip");
}
else
{
if (string.IsNullOrEmpty(outPut))
{
outPut = SummaryAnalysis.Load(exportType);
}
ViewBag.OutPut = outPut;
return View();
}
}
}
在见过的开发文档,我觉得这是最好的展现形式了,还有锚点,快速定位到对象结构,并且与源代码保持一致
附WEB API 自带文档生成区别
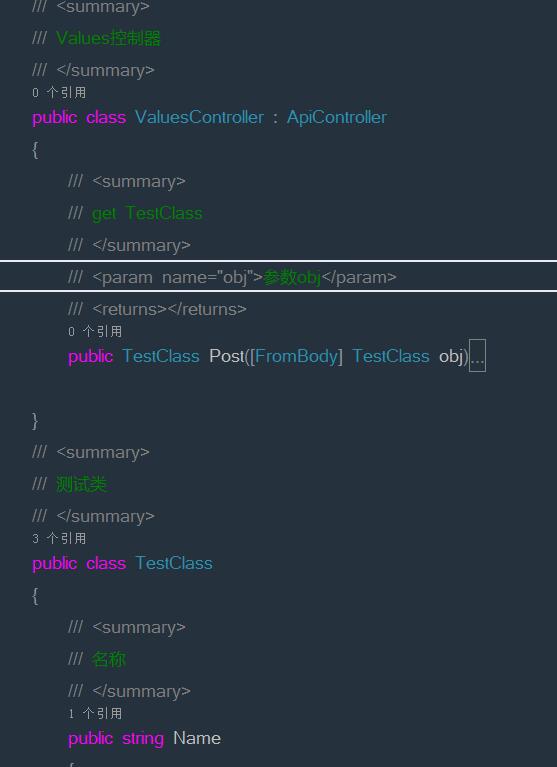

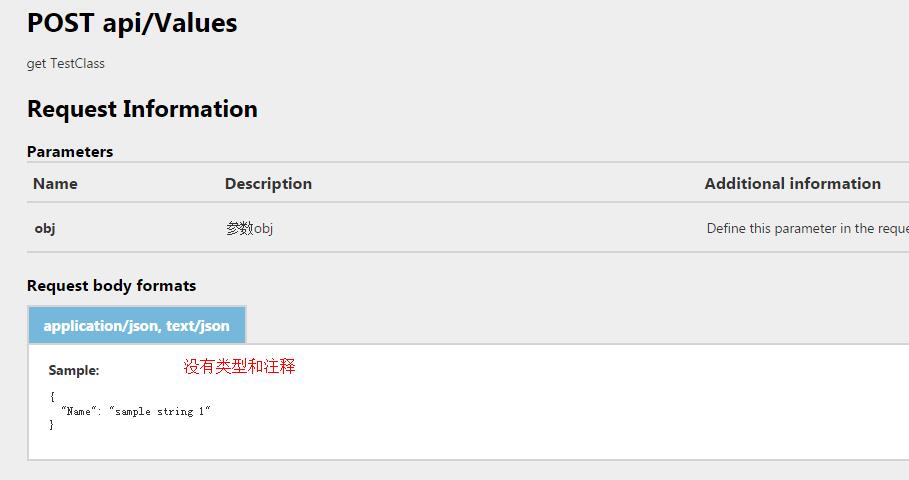
附上项目源码
http://pan.baidu.com/s/1c2rDacK
项目结构:
———-WPF测试程序
———-接口示例
虽然跟CRL快速开发框架无关,但还是加上CRL的名,好文要顶!




 using System;
using System;
 public partial class _Default : System.Web.UI.Page
public partial class _Default : System.Web.UI.Page
 }
}

 }
}