
来源: 实时开发框架Meteor API解读系列 Meteor.methods – CSDN博客
写在前面的话
- 该系列是零散的。 写到哪个是哪个 不会有个顺序。
- 尽量一篇博客一个API
- 尽量搭配一个代码实例 (因为时间比较零碎不一定能够保证)
- 每篇博文我会标记所使用的Meteor版本,防止因为API变化,导致博客的内容的正确性问题
- 能够看懂官方API就尽量看官方的,官方的才是最准确的。我这里只是提供一个参考
V 0.7.01
本篇文章涉及到的API:Meteor.methods,Meteor.call,Meteor.apply,Meteor.starup
Meteor.methods — Anywhere
关于 Meteor.methods 先看一下官方的简单描述
Defines functions that can be invoked over the network by clients.
大概意思就是 定义一些方法可以被客户端通过网络进行调用。注意下面的解释都是以这一条为基础来解释的。
ps:因为我初次看官方文档就糊涂了。不知道大家注意了没有,官方文档在每个API 后面有个标记,标记api的使用范围是在客户端(Client)使用还是服务端(Server)使用,亦或是同时都可以使用(Anywhere)。
在Meteor.methods后面的标识是Anywhere我的第一反应是服务端通过Meteor.methods定义的方法客户端可以调用,客户端通过Meteor.methods定义的方法服务端可以调用。其实如果稍微思考一下就会知道这样想是错误的。因为客户端有那么多,Meteor怎么知道到底使哪个客户端来执行这个方法呢? 但是这里的Anywhere是什么意思呢?稍后解释。
*强调 该API的作用也可以说它的主要目的是实现: 在服务端定义一组方法,使客户端能够调用。换句话说,通过这个API,客户端可以命令服务端做一些我们允许做的事情。client 端定义的Meteor.methods叫做 'stub'(官方用的是这个单词) ,至于怎么翻译,看个人理解吧。这是下文需要用的一个描述。[我翻译成'存根',理解为 对服务端方法调用的客户端补充动作。]参数:Object
函数Meteor.methods的参数是一个object对象,这个对象里面的属性名就是供客户端调用的函数名,该属性对应的值就是共调用的函数。
例如:
{
"hello":function(){..},
"welcome":function(){..},
"bey":function(){..}
}如下使用:(服务端)
Meteor.methods({
"say":function(name){
//do somthing
console.log("Hello " + name);
return "Hello boy";
} ,
"draw":function(...){
.....
},
.....
});返回值:JSON对象(官方原文是: EJSON-able value)或者一个Meteor.Error对象
Meteor.Error 当后台处理到异常时,应该主动抛出的出错信息。这是一个Meteor自定义的一个异常对象。这个对象与本篇主题不相关,暂不做解释。可能一篇博客介绍它。
在被调用函数的内部 (如say对应函数的内部)存在一个上下对象 this。这个对象组成如下:
{
isSimulation: Boolean,// a boolean value, true if this invocation is a stub.
unblock: Function,//when called, allows the next method from this client to begin running.
userId: String,//the id of the current user.
setUserId: Function//a function that associates the current client with a user.
connection: Object//on the server, the connection this method call was received on.
}根据官方的解释可能不是很i清楚,后面我们通过代码进行测试。
现在Meteor.methods的参数类型,和其中的函数应用已经讲,那么接着讲 如何来调用这些在Server端定义的内容。
有两个方法可以使用
1. Meteor.call
2. Meteor.apply(个人认为:这两个方法的区别有点类似js的call与apply的区别)
Meteor.call — Anywhere
具体形式如下:
Meteor.call("function name",arg1,arg2,..,function(error,result){
//do something
});function nanme 表示 在Meteor.methods中定义的对象的属性名,通过这个属性名来表示调用服务端对应的这个方法。
arg1,arg2,.. 是任意个参数,这个参数将作为服务端函数的参数。
注意这些参数仅为json或者一般数据类型,不能传递包含function对象最后一个是回调函数。如果服务端函数抛出异常则 将赋值给error这个参数。
如果没有异常抛出,则服务端函数的返回值将赋值给result这个参数。
接下来看具体实现和代码。
meteor create api-001 #创建meteor应用
cd api-001 #进入应用目录
rm *.html *.css *.js #删除自动生成的.html,css,js文件
mkdir server #创建server文件夹
mkdir client #创建client文件夹(关于文件夹的作用请参考其他人博客,或官方文档,我暂时还没有写。)
在server文件夹中新建一个js文件,如 main.js 内容如下:
Meteor.methods({
"test":function(){
console.log("Hello I'm Server");
}
});现在代码已经完成了,运行这个工程。
用浏览器(建议使用Chrome,该系列博客都将以此浏览器进行)打开http://localhost:3000 按F12 进入开发者模式 找到console控制台,输入:
Meteor.call("test")这时在meteor启动的命令窗口将看到字符串输出。这就是Meteor.call的使用了。客户端调用服务端的方法。
(这里使用chrome控制台来完成相关测试是为了尽量保持博客的简洁性。同样的语句当然也可以写到客户端的js文件中,然后在html中引用,调用。效果是一样的,但是对于这篇博客来说 代码量就显的繁琐了。关于chrome的开发者模式的使用,请查找资料,或者查看我的博客如果你在看这篇博客时我已经写了的话)最简单的demo已经了解过了,接下来看下它的返回值和参数的传递。
改动一下 main.js:
Meteor.methods({
//这里的参数可以是N个
"test":function(a,b){
console.log(a + " " + b);
//这里使用的返回类型是json对象,当然可以使用基本数据类型,如string,number,bool等
return {
a:a,
b:b,
c:a+b
}
}
});meteor自动重启。同样在chrome控制台输入:
Meteor.call("test",1,2,function(error,result){
//服务端抛出的异常将被这个回调函数的地一个参数接收,也就是error
//当服务端无异常抛出时,error为undefined
if(error){
console.log("服务端异常");
console.log(error);
return;
}
//服务端函数的返回值将被第二个参数接受,也就是result
console.log(result);
});打印结果很明确就是服务端的返回值。
注意,因为Meteor.call可以在Server和Client同时使用,
在Server端运行Meteor.call时,最后一个参数不是回调函数的话,在可能的情况下服务端将同步执行这个方法体)验证代码如下 main.js:
var fs = Npm.require('fs');
Meteor.methods({
"test":function(a){
return a;
}
});
Meteor.startup(function(){
var s = Meteor.call("test",5);
console.log(s);
});
强调!这仅是在Server可以这样用,在Client如果要取到Server的返回值,必须使用回调函数才能获取到。
------------------------------------
现在,下面的这个结论如果不能理解或者对你造成了迷惑请忽略它,因为它的实际作用不大。只是因为API中对它有个简单的提及,那么就用代码代码验证一下。
文档原文:
"On the client, if you do not pass a callback and you are not inside a stub, call will return undefined, and you will have no way to get the return value of the method."
原文就是上面这样了。不知道你思考了没有我上面提及到的这句话伸展:"在Client如果要取到Server的返回值"。 什么伸展呢?因为Meteor.methods在客户端也可以使用,那么如果Client 的Meteor.call调用Client的Meteor.methods中的函数 是不是也需要用回调函数呢? 结论是:不一定需要。
但是根据原文文档(原文没有直接提及,是根据"you do not pass a callback and you are not inside a stub"推断出来的,所以说这个结论实际作用不大),你得满足一个条件才行。条件是:你的Meteor.call必须在stub[前文已经解释过]中。(当然Client 的Metoer.methods本身不能涉及到异步调用。这个和Server端的同步是同样的样要求),而且在sub中使用Method.call 只会调用Client 的Meteor.methods中定义的方法,而Server的Meteor.methods不会执行。
官方文档提到了这个上面的这个情况。原文如下:
"Finally, if you are inside a stub on the client and call another method, the other method is not executed (no RPC is generated, nothing 'real' happens). If that other method has a stub, that stub stands in for the method and is executed."
通过以下代码的运行就能看到:
Server/main.js
Meteor.methods({
hello:function(){
console.log("server");
return 10;
}
});
Client/client.js
Meteor.methods({
hello:function(){
console.log("clent");
return 12;
},
say:function(){
console.log('say');
var hello = Meteor.call("hello");//Server下的hello 不会执行。
console.log(hello);//打印值是12
}
});
Meteor.apply — Anywhere
服务端代码不需要改动,在浏览器控制台输入:
Meteor.apply("test",[1,2],function(errror,result){
if(error){
//do something;
return;
}
// do somthing
console.log(result);
});可以看到 Meteor.apply和Meteor.call 在一般用法 上基本没区别,仅是传递参数的方式不同而已,一个使用参数列表,一个使用参数数组。其实对于大多数 开发过程而言 掌握上述两种的使用已经能够满足开发需要了。因此对无更多要求的人而言,本篇博客可以到此为止。前文提到的 服务端函数 内部的上下文对象的使用 和 关于Meteor.methods的Anywhere 这两个还没解释的地方 可以忽略了。
Meteor.methods的Anywhere
大家细心一点可能发现Meteor.call,Meteor.apply同样是”Anywhere”.
先解释一下Server的call,apply和Client的call,apply的区别。
区别很简单:
Server:
仅能调用服务端的Meteor.methods中定义的函数
Client:
同时调用服务端和客户端的Meteor.methods中定义的函数。这个涉及到了Meteor.methods的Anywhere了。具体请往下看。因为前面已经介绍了methods,call,apply的简单用法了。那么下面的代码就尽量简化不再描述这些了。
首先修改server的main.js。内容如下:
Meteor.methods({
"test":function(a){
console.log("server");
return a+1;
}
});
//Meteor加载完所有文件后将执行这个方法。具体使用请参考官方文档,比较简单。
Meteor.startup(function(){
//然meteor启动后执行test方法
Meteor.call("test",1,function(err,result){
console.log(result);
});
});另外,最开始的时候就新建了一个client文件,在该文件夹下 新建一个js文件,如client.js
内容如下:
Meteor.methods({
"test":function(a){
console.log("Client");
return a+"aaa";
}
});代码基本就这样 然后重新运行meteor.
可以看到在Meteor.startup调用的Meteor.call只执行了Server下定义的test函数。
接着打开Chrome的控制台,输入:
Meteor.call("test",1,function(err,result){
console.log(result);
});可以发现,客户端Meteor.methods和服务端Meteor.methods定义的test方法都执行了。而且在这个call函数的里回调函数的返回值 是服务端test的返回值,客户端test函数的返回值自动被舍弃了。
如果Client和Server同时定义了Meteor.methods 函数,在进行调用时,server 执行Meteor.call或Meteor.apply 只会使Server端的Meteor.methods中定义的函数执行
,而Client端执行的call和apply 会同调用客户端和服务端中Meteor.methods定义的函数。
且返回值都是以Server端的函数返回值,客户端的返回值将自动舍弃。其实这个结论自己多写几个代码就能够了解。到这里 Meteor.methods的Anywhere不用再解释,应该也明白了。
Meteor.methods中函数的上下文对象 this
this中包含五个属性如下 (这些当需要用到时,能够想起有怎么个属性存在就可以了。到时候会自动知道该怎么使用)
{
isSimulation: Boolean,// a boolean value, true if this invocation is a stub.
unblock: Function,//when called, allows the next method from this client to begin running.
userId: String,//the id of the current user.
setUserId: Function//a function that associates the current client with a user.
connection: Object//on the server, the connection this method call was received on.
}this.userId
调用这个函数的用户的id ,类型:string。如果用户没有登录,值为null。 该属性在 Server的Meteor.methods和Client的Meteor.methods都存在。用官方的描述就是Anywhere。 这个属性依赖Meteor的accounts 模块。这里不赘述。this.setUseId类型:Function,该setUerId函数的接收一个字符串或者null。使用范围:Server设置当前链接的 用户。也就是说可以改变登录用户,或者使用户登录[如果this.userId为null],注销登录用户[this.setUserId(null)] .同样需要 Meteor的accounts模块的支持。this.isSimulation类型:Boolean 。使用范围:Anywhere
这个属性 我解释不好(如有好的理解请在博客下方留言),官方的解释是这样的:
Access inside a method invocation. Boolean value, true if this invocation is a stub.[我理解意思是在Client的Meteor.methods中该值为true,Server中为false]。而且经过代码如下代码测试貌似和我理解的意思差不多 :
1. Server的call 或apply调用时,在Server的Meteor.methods中```isSimulation```为false
2. Client的call或apply调用时,
在Server的Meteor.methods中```isSimulation```为false,
在Client的Meteor.methods中```isSimulation```为true测试代码:
client.js:
Meteor.methods({
"test":function(a){
console.log("Client");
console.log(this.isSimulation); //false
return a+"aaa";
}
});main.js:
Meteor.methods({
"test":function(a){
console.log("server");
console.log(this.isSimulation);//true
return a+1;
}
});
Meteor.startup(function(){
Meteor.call("test",1,function(err,result){
console.log(result);
});
});4 this.unblock()
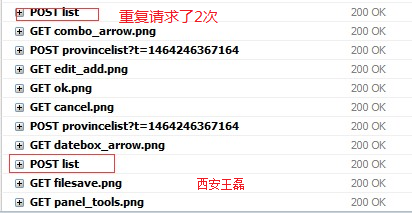
解释这个之前,我刚才得到了一个结论,一直没有注意到(没有使用过this.unblick()也没注意过它是否是阻塞的,写博客确实也是一种自我学习过程,当然这是题外话了。)的结论。默认情况下在Client调用Server端的函数这种过程是阻塞式的。意识就是说,如果有多个客户端同时调用test这个函数,而test这个函数的执行需要耗费一段,那么这个调用会进行排队依次执行。而就是只要当前面N次调用都完成以后,后面的调用才会进行。可以经过一下代码验证:
清空client.js的内容,不需要。 然后main.js的内容是:
var fs = Npm.require('fs');
Meteor.methods({
"test":function(a){
if(a==1){
//这里我通过多次读写文件的时间耗费进行阻塞
//,注意文件大小最好是在10M-40M之间,太小的文件,或者一般的计算可能执行速度太快看不到效果
for(var i=0;i<20;i++){
var data = fs.readFileSync("/home/ec/download/NVIDIA");
fs.writeFileSync("/home/ec/download/test/NVIDIA"+i, data);
}
}
console.log(a);
}
});在单个浏览器端,或者同时多个浏览器运行:(把命令写在一行)
Meteor.call("test",1); Meteor.call("test",2);这样就可以看到阻塞的效果。[我猜大概这样是为了实现类似资源锁之类操作]
那么现在,我们不想它阻塞在这里也是很容易做的。没错!就是在函数的第一行执行:
(这里貌似存在一个bug 这个this.unblock()没有起作用 ,具体原因可参考 详情 和 解决方法)
this.unblock();这是main.js内容如下:(参考解决过后的代码)
var fs = Npm.require('fs');
var readFile = Meteor._wrapAsync(fs.readFile.bind(fs));
var writeFile = Meteor._wrapAsync(fs.writeFile.bind(fs));
Meteor.methods({
"test":function(a){
this.unblock();
if(a==1){
//这里我通过多次读写文件的时间耗费进行阻塞
//,注意文件大小最好是在10M-40M之间,太小的文件,或者一般的计算可能执行速度太快看不到效果
var data = readFile("/home/ec/download/NVIDIA");
for(var i=0;i<5;i++){
writeFile("/home/ec/download/test/NVIDIA"+i, data);
console.log(a+"-"+i);
}
}
console.log(a);
return a;
}
});好了,this.unblock()的使用是这篇博客多耗费了2天时间。总算跳过去了。现在就剩最后一个点了。
this.connection Server
这是一个Connection对象,具体可以参考Server connections和这个部分的Meteor.onConnection(callback) 此属性不再本篇博客的讨论范围内。既然不讨论,那么就抄个官方文档的解释放在这里吧。
Access inside a method invocation. The connection this method was received on. null if the method is not associated with a connection, eg. a server initiated method call.
其中一个表达的大概意思是 如果没有通过http(非Client-Server或DDP)而是直接在Server中来调用这个methods里面的方法,那么connection是一个null。
本篇博客结束了。
对了最后其实还落下了一点点。那就是关于Meteor.apply(name, params [, options] [, asyncCallback])第三个可选参数options的解释了。
应该比较好理解 。同样贴上一个官方文档。
Options #仅在client端才有此参数
wait Boolean
(Client only) If true, don’t send this method until all previous method calls have completed, and don’t send any subsequent method calls until this one is completed.
onResultReceived Function
解释:如果为true,除非前面的方法调用都已经完成回调了,才会开始执行本次的函数调用。并且在本次函数调用完成之前 不会在执行其他任何的函数调用了。
(Client only) This callback is invoked with the error or result of the method (just like asyncCallback) as soon as the error or result is available. The local cache may not yet reflect the writes performed by the method.
这个的验证代码可以自己尝试写一下。就当是思考题吧。
转载请注明出处。谢谢!


















![clipboard[1]](http://images.cnitblog.com/blog/73542/201403/191211195214505.png "clipboard[1]")
![clipboard[2]](http://images.cnitblog.com/blog/73542/201403/191211205688617.png "clipboard[2]")
![clipboard[3]](http://images.cnitblog.com/blog/73542/201403/191211247567872.png "clipboard[3]")
![clipboard[4]](http://images.cnitblog.com/blog/73542/201403/191211259746400.png "clipboard[4]")
![clipboard[5]](http://images.cnitblog.com/blog/73542/201403/191211267403299.png "clipboard[5]")
![clipboard[6]](http://images.cnitblog.com/blog/73542/201403/191211275842641.png "clipboard[6]")
![clipboard[7]](http://images.cnitblog.com/blog/73542/201403/191211287243427.png "clipboard[7]")
![clipboard[8]](http://images.cnitblog.com/blog/73542/201403/191211304126410.png "clipboard[8]")
![clipboard[9]](http://images.cnitblog.com/blog/73542/201403/191211321461082.png "clipboard[9]")
![clipboard[10]](http://images.cnitblog.com/blog/73542/201403/191211336778580.png "clipboard[10]")
![clipboard[11]](http://images.cnitblog.com/blog/73542/201403/191211381624576.png "clipboard[11]")
![clipboard[12]](http://images.cnitblog.com/blog/73542/201403/191211404128688.png "clipboard[12]")
![clipboard[13]](http://images.cnitblog.com/blog/73542/201403/191211429129258.png "clipboard[13]")
![clipboard[14]](http://images.cnitblog.com/blog/73542/201403/191211447241672.png "clipboard[14]")
![clipboard[15]](http://images.cnitblog.com/blog/73542/201403/191211471311270.png "clipboard[15]")
![clipboard[16]](http://images.cnitblog.com/blog/73542/201403/191211490689710.png "clipboard[16]")