来源: Node.js + Web Socket 打造即时聊天程序嗨聊 – 刘哇勇 – 博客园
前端一直是一块充满惊喜的土地,不仅是那些富有创造性的页面,还有那些惊赞的效果及不断推出的新技术。像node.js这样的后端开拓者直接将前端人员的能力扩大到了后端。瞬间就有了一统天下的感觉,来往穿梭于前后端之间代码敲得飞起,从此由前端晋升为’前后端’。

图片来自G+
本文将使用Node.js加web socket协议打造一个网页即时聊天程序,取名为HiChat,中文翻过来就是’嗨聊’,听中文名有点像是专为寂寞单身男女打造的~
其中将会使用到express和socket.io两个包模块,下面会有介绍。
源码&演示
在线演示 (heroku服务器网速略慢且免费套餐是小水管,建议下载代码本地运行)
源码可访问项目的GitHub页面下载
本地运行方法:
- 命令行运行npm install
- 模块下载成功后,运行node server启动服务器
- 打开浏览器访问localhost
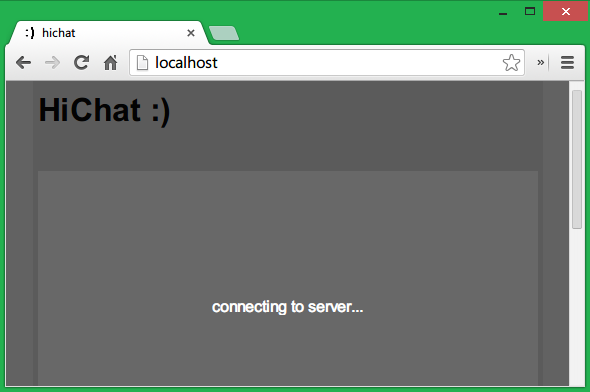
下图为效果预览:
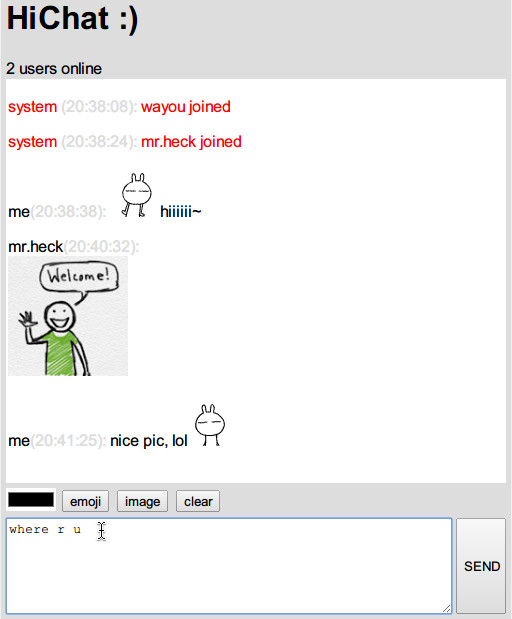
准备工作
本文示例环境为Windows,Linux也就Node的安装与命令行稍有区别,程序实现部分基本与平台无关。
Node相关
- 你需要在本机安装Node.js(废话)
- 多少需要一点Node.js的基础知识,如果还未曾了解过Node.js,这里有一篇不错的入门教程
然后我们就可以开始创建一个简单的HTTP服务器啦。
类似下面非常简单的代码,它创建了一个HTTP服务器并监听系统的80端口。
//node server example
//引入http模块
var http = require('http'),
//创建一个服务器
server = http.createServer(function(req, res) {
res.writeHead(200, {
'Content-Type': 'text/plain'
});
res.write('hello world!');
res.end();
});
//监听80端口
server.listen(80);
console.log('server started');
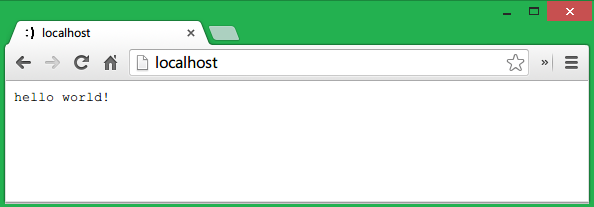
将其保存为一个js文件比如server.js,然后从命令行运行node server或者node server.js,服务器便可启动了,此刻我们可以在浏览器地址栏输入localhost进行访问,也可以输入本机IP127.0.0.1,都不用加端口,因为我们服务器监听的是默认的80端口。当然,如果你机子上面80端口被其他程序占用了,可以选择其他端口比如8080,这样访问的时候需要显示地加上端口号localhost:8080。

Express
首先通过npm进行安装
- 在我们的项目文件夹下打开命令行(tip: 按住Shift同时右击,可以在右键菜单中找到’从此处打开命令行’选项)
- 在命令行中输入 npm install express 回车进行安装
- 然后在server.js中通过require(‘express’)将其引入到项目中进行使用
express是node.js中管理路由响应请求的模块,根据请求的URL返回相应的HTML页面。这里我们使用一个事先写好的静态页面返回给客户端,只需使用express指定要返回的页面的路径即可。如果不用这个包,我们需要将HTML代码与后台JavaScript代码写在一起进行请求的响应,不太方便。
//返回一个简单的HTML内容
server = http.createServer(function(req, res) {
res.writeHead(200, {
'Content-Type': 'text/html' //将返回类型由text/plain改为text/html
});
res.write('<h1>hello world!</h1>'); //返回HTML标签
res.end();
});
在存放上一步创建的server.js文件的地方,我们新建一个文件夹名字为www用来存放我们的网页文件,包括图片以及前端的js文件等。假设已经在www文件夹下写好了一个index.html文件(将在下一步介绍,这一步你可以放一个空的HTML文件),则可以通过以下方式使用express将该页面返回到浏览器。可以看到较最开始,我们的服务器代码简洁了不少。
//使用express模块返回静态页面
var express = require('express'), //引入express模块
app = express(),
server = require('http').createServer(app);
app.use('/', express.static(__dirname + '/www')); //指定静态HTML文件的位置
server.listen(80);

其中有四个按钮,分别是设置字体颜色,发送表情,发送图片和清除记录,将会在下面介绍其实现
socket.io
Node.js中使用socket的一个包。使用它可以很方便地建立服务器到客户端的sockets连接,发送事件与接收特定事件。
同样通过npm进行安装 npm install socket.io 。安装后在node_modules文件夹下新生成了一个socket.io文件夹,其中我们可以找到一个socket.io.js文件。将它引入到HTML页面,这样我们就可以在前端使用socket.io与服务器进行通信了。
<script src="/socket.io/socket.io.js"></script>
同时服务器端的server.js里跟使用express一样,也要通过require(‘socket.io’)将其引入到项目中,这样就可以在服务器端使用socket.io了。
使用socket.io,其前后端句法是一致的,即通过socket.emit()来激发一个事件,通过socket.on()来侦听和处理对应事件。这两个事件通过传递的参数进行通信。具体工作模式可以看下面这个示例。
比如我们在index.html里面有如下JavaScript代码(假设你已经在页面放了一个ID为sendBtn的按钮):
<script type="text/javascript">
var socket=io.connect(),//与服务器进行连接
button=document.getElementById('sendBtn');
button.onclick=function(){
socket.emit('foo', 'hello');//发送一个名为foo的事件,并且传递一个字符串数据‘hello’
}
</script>
上述代码首先建立与服务器的连接,然后得到一个socket实例。之后如果页面上面一个ID为sendBtn的按钮被点击的话,我们就通过这个socket实例发起一个名为foo的事件,同时传递一个hello字符串信息到服务器。
与此同时,我们需要在服务器端写相应的代码来处理这个foo事件并接收传递来的数据。
为此,我们在server.js中可以这样写:
//服务器及页面响应部分
var express = require('express'),
app = express(),
server = require('http').createServer(app),
io = require('socket.io').listen(server); //引入socket.io模块并绑定到服务器
app.use('/', express.static(__dirname + '/www'));
server.listen(80);
//socket部分
io.on('connection', function(socket) {
//接收并处理客户端发送的foo事件
socket.on('foo', function(data) {
//将消息输出到控制台
console.log(data);
})
});
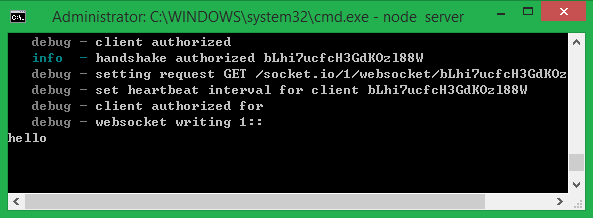
现在Ctrl+C关闭之前启动的服务器,再次输入node server启动服务器运行新代码查看效果,一切正常的话你会在点击了页面的按扭后,在命令行窗口里看到输出的’hello’字符串。
一如之前所说,socket.io在前后端的句法是一致的,所以相反地,从服务器发送事件到客户端,在客户端接收并处理消息也是显而易见的事件了。这里只是简单介绍,具体下面会通过发送聊天消息进一步介绍。
基本页面
有了上面一些基础的了解,下面可以进入聊天程序功能的开发了。
首先我们构建主页面。因为是比较大众化的应用了,界面不用多想,脑海中已经有大致的雏形,它有一个呈现消息的主窗体,还有一个输入消息的文本框,同时需要一个发送消息的按钮,这三个是必备的。
另外就是,这里还准备实现以下四个功能,所以界面上还有设置字体颜色,发送表情,发送图片和清除记录四个按钮。
最后的页面也就是先前截图展示的那们,而代码如下:
www/index.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="author" content="Wayou">
<meta name="description" content="hichat | a simple chat application built with node.js and websocket">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>hichat</title>
<link rel="stylesheet" href="styles/main.css">
<link rel="shortcut icon" href="favicon.ico" type="image/x-icon">
<link rel="icon" href="favicon.ico" type="image/x-icon">
</head>
<body>
<div class="wrapper">
<div class="banner">
<h1>HiChat :)</h1>
<span id="status"></span>
</div>
<div id="historyMsg">
</div>
<div class="controls" >
<div class="items">
<input id="colorStyle" type="color" placeHolder='#000' title="font color" />
<input id="emoji" type="button" value="emoji" title="emoji" />
<label for="sendImage" class="imageLable">
<input type="button" value="image" />
<input id="sendImage" type="file" value="image"/>
</label>
<input id="clearBtn" type="button" value="clear" title="clear screen" />
</div>
<textarea id="messageInput" placeHolder="enter to send"></textarea>
<input id="sendBtn" type="button" value="SEND">
<div id="emojiWrapper">
</div>
</div>
</div>
<div id="loginWrapper">
<p id="info">connecting to server...</p>
<div id="nickWrapper">
<input type="text" placeHolder="nickname" id="nicknameInput" />
<input type="button" value="OK" id="loginBtn" />
</div>
</div>
<script src="/socket.io/socket.io.js"></script>
<script src="scripts/hichat.js"></script>
</body>
</html>
样式文件 www/styles/main.css
html, body {
margin: 0;
background-color: #efefef;
font-family: sans-serif;
}
.wrapper {
width: 500px;
height: 640px;
padding: 5px;
margin: 0 auto;
background-color: #ddd;
}
#loginWrapper {
position: fixed;
top: 0;
right: 0;
bottom: 0;
left: 0;
background-color: rgba(5, 5, 5, .6);
text-align: center;
color: #fff;
display: block;
padding-top: 200px;
}
#nickWrapper {
display: none;
}
.banner {
height: 80px;
width: 100%;
}
.banner p {
float: left;
display: inline-block;
}
.controls {
height: 100px;
margin: 5px 0px;
position: relative;
}
#historyMsg {
height: 400px;
background-color: #fff;
overflow: auto;
padding: 2px;
}
#historyMsg img {
max-width: 99%;
}
.timespan {
color: #ddd;
}
.items {
height: 30px;
}
#colorStyle {
width: 50px;
border: none;
padding: 0;
}
/*custom the file input*/
.imageLable {
position: relative;
}
#sendImage {
position: absolute;
width: 52px;
left: 0;
opacity: 0;
overflow: hidden;
}
/*end custom file input*/
#messageInput {
width: 440px;
max-width: 440px;
height: 90px;
max-height: 90px;
}
#sendBtn {
width: 50px;
height: 96px;
float: right;
}
#emojiWrapper {
display: none;
width: 500px;
bottom: 105px;
position: absolute;
background-color: #aaa;
box-shadow: 0 0 10px #555;
}
#emojiWrapper img {
margin: 2px;
padding: 2px;
width: 25px;
height: 25px;
}
#emojiWrapper img:hover {
background-color: blue;
}
.emoji{
display: inline;
}
footer {
text-align: center;
}
为了让项目有一个良好的目录结构便于管理,这里在www文件夹下又新建了一个styles文件夹存放样式文件main.css,然后新建一个scripts文件夹存放前端需要使用的js文件比如hichat.js(我们前端所有的js代码会放在这个文件中),而我们的服务器js文件server.js位置不变还是放在最外层。
同时再新建一个content文件夹用于存放其他资源比如图片等,其中content文件夹里再建一个emoji文件夹用于存入表情gif图,后面会用到。最后我们项目的目录结构应该是这样的了:
├─node_modules
└─www
├─content
│ └─emoji
├─scripts
└─styles
此刻打开页面你看到的是一个淡黑色的遮罩层,而接下来我们要实现的是用户昵称的输入与服务器登入。这个遮罩层用于显示连接到服务器的状态信息,而当连接完成之后,会出现一个输入框用于昵称输入。
上面HTML代码里已经看到,我们将www/scripts/hichat.js文件已经引入到页面了,下面开始写一些基本的前端js开始实现连接功能。
定义一个全局变量用于我们整个程序的开发HiChat,同时使用window.onload在页面准备好之后实例化HiChat,调用其init方法运行我们的程序。
www/scripts/Hichat.js
window.onload = function() {
//实例并初始化我们的hichat程序
var hichat = new HiChat();
hichat.init();
};
//定义我们的hichat类
var HiChat = function() {
this.socket = null;
};
//向原型添加业务方法
HiChat.prototype = {
init: function() {//此方法初始化程序
var that = this;
//建立到服务器的socket连接
this.socket = io.connect();
//监听socket的connect事件,此事件表示连接已经建立
this.socket.on('connect', function() {
//连接到服务器后,显示昵称输入框
document.getElementById('info').textContent = 'get yourself a nickname :)';
document.getElementById('nickWrapper').style.display = 'block';
document.getElementById('nicknameInput').focus();
});
}
};
上面的代码定义了整个程序需要使用的类HiChat,之后我们处理消息显示消息等所有业务逻辑均写在这个类里面。
首先定义了一个程序的初始化方法,这里面初始化socket,监听连接事件,一旦连接到服务器,便显示昵称输入框。当用户输入昵称后,便可以在服务器后台接收到然后进行下一步的处理了。
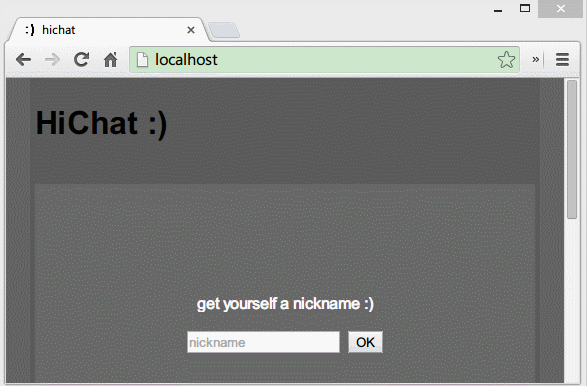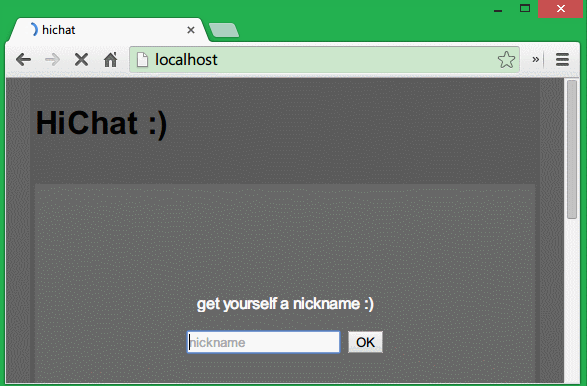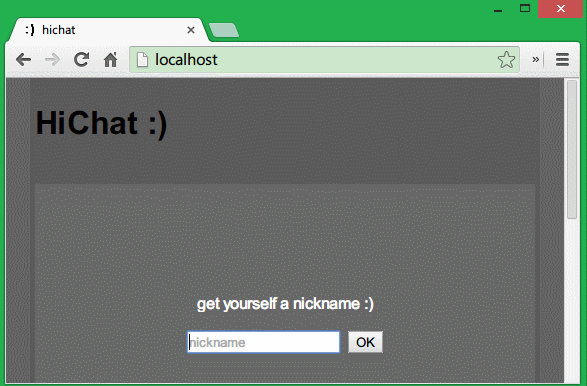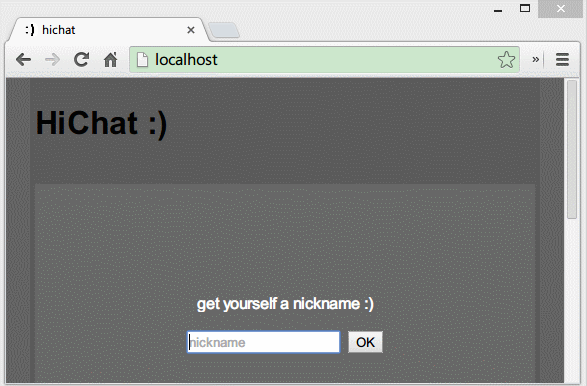
设置昵称
我们要求连接的用户需要首先设置一个昵称,且这个昵称还要唯一,也就是不能与别人同名。一是方便用户区分,二是为了统计在线人数,同时也方便维护一个保存所有用户昵称的数组。
为此在后台server.js中,我们创建一个名叫users的全局数组变量,当一个用户设置好昵称发送到服务器的时候,将昵称压入users数组。同时注意,如果用户断线离开了,也要相应地从users数组中移除以保证数据的正确性。
在前台,输入昵称点击OK提交后,我们需要发起一个设置昵称的事件以便服务器侦听到。将以下代码添加到之前的init方法中。
www/scripts/hichat.js
//昵称设置的确定按钮
document.getElementById('loginBtn').addEventListener('click', function() {
var nickName = document.getElementById('nicknameInput').value;
//检查昵称输入框是否为空
if (nickName.trim().length != 0) {
//不为空,则发起一个login事件并将输入的昵称发送到服务器
that.socket.emit('login', nickName);
} else {
//否则输入框获得焦点
document.getElementById('nicknameInput').focus();
};
}, false);
server.js
//服务器及页面部分
var express = require('express'),
app = express(),
server = require('http').createServer(app),
io = require('socket.io').listen(server),
users=[];//保存所有在线用户的昵称
app.use('/', express.static(__dirname + '/www'));
server.listen(80);
//socket部分
io.on('connection', function(socket) {
//昵称设置
socket.on('login', function(nickname) {
if (users.indexOf(nickname) > -1) {
socket.emit('nickExisted');
} else {
socket.userIndex = users.length;
socket.nickname = nickname;
users.push(nickname);
socket.emit('loginSuccess');
io.sockets.emit('system', nickname); //向所有连接到服务器的客户端发送当前登陆用户的昵称
};
});
});
需要解释一下的是,在connection事件的回调函数中,socket表示的是当前连接到服务器的那个客户端。所以代码socket.emit(‘foo’)则只有自己收得到这个事件,而socket.broadcast.emit(‘foo’)则表示向除自己外的所有人发送该事件,另外,上面代码中,io表示服务器整个socket连接,所以代码io.sockets.emit(‘foo’)表示所有人都可以收到该事件。
上面代码先判断接收到的昵称是否已经存在在users中,如果存在,则向自己发送一个nickExisted事件,在前端接收到这个事件后我们显示一条信息通知用户。
将下面代码添加到hichat.js的inti方法中。
www/scripts/hichat.js
this.socket.on('nickExisted', function() {
document.getElementById('info').textContent = '!nickname is taken, choose another pls'; //显示昵称被占用的提示
});
如果昵称没有被其他用户占用,则将这个昵称压入users数组,同时将其作为一个属性存到当前socket变量中,并且将这个用户在数组中的索引(因为是数组最后一个元素,所以索引就是数组的长度users.length)也作为属性保存到socket中,后面会用到。最后向自己发送一个loginSuccess事件,通知前端登陆成功,前端接收到这个成功消息后将灰色遮罩层移除显示聊天界面。
将下面代码添加到hichat.js的inti方法中。
www/scripts/hichat.js
this.socket.on('loginSuccess', function() {
document.title = 'hichat | ' + document.getElementById('nicknameInput').value;
document.getElementById('loginWrapper').style.display = 'none';//隐藏遮罩层显聊天界面
document.getElementById('messageInput').focus();//让消息输入框获得焦点
});
在线统计
这里实现显示在线用户数及在聊天主界面中以系统身份显示用户连接离开等信息。
上面server.js中除了loginSuccess事件,后面还有一句代码,通过io.sockets.emit 向所有用户发送了一个system事件,传递了刚登入用户的昵称,所有人接收到这个事件后,会在聊天窗口显示一条系统消息’某某加入了聊天室’。同时考虑到在前端我们无法得知用户是进入还是离开,所以在这个system事件里我们多传递一个数据来表明用户是进入还是离开。
将server.js中login事件更改如下:
server.js
socket.on('login', function(nickname) {
if (users.indexOf(nickname) > -1) {
socket.emit('nickExisted');
} else {
socket.userIndex = users.length;
socket.nickname = nickname;
users.push(nickname);
socket.emit('loginSuccess');
io.sockets.emit('system', nickname, users.length, 'login');
};
});
较之前,多传递了一个login字符串。
同时再添加一个用户离开的事件,这个可能通过socket.io自带的disconnect事件完成,当一个用户断开连接,disconnect事件就会触发。在这个事件中,做两件事情,一是将用户从users数组中删除,一是发送一个system事件通知所有人’某某离开了聊天室’。
将以下代码添加到server.js中connection的回调函数中。
server.js
//断开连接的事件
socket.on('disconnect', function() {
//将断开连接的用户从users中删除
users.splice(socket.userIndex, 1);
//通知除自己以外的所有人
socket.broadcast.emit('system', socket.nickname, users.length, 'logout');
});
上面代码通过JavaScript数组的splice方法将当前断开连接的用户从users数组中删除,这里我们看到之前保存的用户索引被使用了。同时发送和用户连接时一样的system事件通知所有人’某某离开了’,为了让前端知道是离开事件,所以发送了一个’logout’字符串。
下面开始前端的实现,也就是接收system事件。
在hichat.js中,将以下代码添加到init方法中。
www/scripts/hichat.js
this.socket.on('system', function(nickName, userCount, type) {
//判断用户是连接还是离开以显示不同的信息
var msg = nickName + (type == 'login' ? ' joined' : ' left');
var p = document.createElement('p');
p.textContent = msg;
document.getElementById('historyMsg').appendChild(p);
//将在线人数显示到页面顶部
document.getElementById('status').textContent = userCount + (userCount > 1 ? ' users' : ' user') + ' online';
});
现在运行程序,打开多个浏览器标签,然后登陆离开,你就可以看到相应的系统提示消息了。
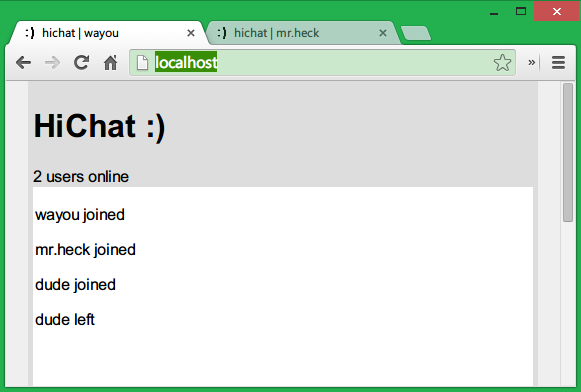
发送消息
用户连接以及断开我们需要显示系统消息,用户还要频繁的发送聊天消息,所以可以考虑将消息显示到页面这个功能单独写一个函数方便我们调用。为此我们向HiChat类中添加一个_displayNewMsg的方法,它接收要显示的消息,消息来自谁,以及一个颜色共三个参数。因为我们想系统消息区别于普通用户的消息,所以增加一个颜色参数。同时这个参数也方便我们之后实现让用户自定义文本颜色做准备。
将以下代码添加到的我的HiChat类当中。
www/scripts/hichat.js
//向原型添加业务方法
HiChat.prototype = {
init: function() { //此方法初始化程序
//...
},
_displayNewMsg: function(user, msg, color) {
var container = document.getElementById('historyMsg'),
msgToDisplay = document.createElement('p'),
date = new Date().toTimeString().substr(0, 8);
msgToDisplay.style.color = color || '#000';
msgToDisplay.innerHTML = user + '<span class="timespan">(' + date + '): </span>' + msg;
container.appendChild(msgToDisplay);
container.scrollTop = container.scrollHeight;
}
};
在_displayNewMsg方法中,我们还向消息添加了一个日期。我们也判断了该方法在调用时有没有传递颜色参数,没有传递颜色的话默认使用#000即黑色。
同时修改我们在system事件中显示系统消息的代码,让它调用这个_displayNewMsg方法。
www/scripts/hichat.js
this.socket.on('system', function(nickName, userCount, type) {
var msg = nickName + (type == 'login' ? ' joined' : ' left');
//指定系统消息显示为红色
that._displayNewMsg('system ', msg, 'red');
document.getElementById('status').textContent = userCount + (userCount > 1 ? ' users' : ' user') + ' online';
});
现在的效果如下:
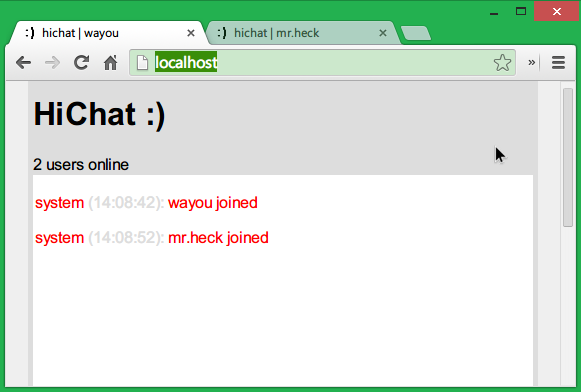
有了这个显示消息的方法后,下面就开始实现用户之间的聊天功能了。
做法也很简单,如果你掌握了上面所描述的emit发送事件,on接收事件,那么用户聊天消息的发送接收也就轻车熟路了。
首先为页面的发送按钮写一个click事件处理程序,我们通过addEventListner来监听这个click事件,当用户点击发送的时候,先检查输入框是否为空,如果不为空,则向服务器发送postMsg事件,将用户输入的聊天文本发送到服务器,由服务器接收并分发到除自己外的所有用户。
将以下代码添加到hichat.js的inti方法中。
www/scripts/hichat.js
document.getElementById('sendBtn').addEventListener('click', function() {
var messageInput = document.getElementById('messageInput'),
msg = messageInput.value;
messageInput.value = '';
messageInput.focus();
if (msg.trim().length != 0) {
that.socket.emit('postMsg', msg); //把消息发送到服务器
that._displayNewMsg('me', msg); //把自己的消息显示到自己的窗口中
};
}, false);
在server.js中添加代码以接收postMsg事件。
server.js
io.on('connection', function(socket) {
//其他代码。。。
//接收新消息
socket.on('postMsg', function(msg) {
//将消息发送到除自己外的所有用户
socket.broadcast.emit('newMsg', socket.nickname, msg);
});
});
然后在客户端接收服务器发送的newMsg事件,并将聊天消息显示到页面。
将以下代码显示添加到hichat.js的init方法中了。
this.socket.on('newMsg', function(user, msg) {
that._displayNewMsg(user, msg);
});
运行程序,现在可以发送聊天消息了。

发送图片
上面已经实现了基本的聊天功能了,进一步,如果我们还想让用户可以发送图片,那程序便更加完美了。
图片不同于文字,但通过将图片转化为字符串形式后,便可以像发送普通文本消息一样发送图片了,只是在显示的时候将它还原为图片。
在这之前,我们已经将图片按钮在页面放好了,其实是一个文件类型的input,下面只需在它身上做功夫便可。
用户点击图片按钮后,弹出文件选择窗口供用户选择图片。之后我们可以在JavaScript代码中使用FileReader来将图片读取为base64格式的字符串形式进行发送。而base64格式的图片直接可以指定为图片的src,这样就可以将图片用img标签显示在页面了。
为此我们监听图片按钮的change事件,一但用户选择了图片,便显示到自己的屏幕上同时读取为文本发送到服务器。
将以下代码添加到hichat.js的init方法中。
www/scripts/hichat.js
document.getElementById('sendImage').addEventListener('change', function() {
//检查是否有文件被选中
if (this.files.length != 0) {
//获取文件并用FileReader进行读取
var file = this.files[0],
reader = new FileReader();
if (!reader) {
that._displayNewMsg('system', '!your browser doesn\'t support fileReader', 'red');
this.value = '';
return;
};
reader.onload = function(e) {
//读取成功,显示到页面并发送到服务器
this.value = '';
that.socket.emit('img', e.target.result);
that._displayImage('me', e.target.result);
};
reader.readAsDataURL(file);
};
}, false);
上面图片读取成功后,调用_displayNImage方法将图片显示在自己的屏幕同时向服务器发送了一个img事件,在server.js中,我们通过这个事件来接收并分发图片到每个用户。同时也意味着我们还要在前端写相应的代码来接收。
这个_displayNImage还没有实现,将会在下面介绍。
将以下代码添加到server.js的socket回调函数中。
server.js
//接收用户发来的图片
socket.on('img', function(imgData) {
//通过一个newImg事件分发到除自己外的每个用户
socket.broadcast.emit('newImg', socket.nickname, imgData);
});
同时向hichat.js的init方法添加以下代码以接收显示图片。
this.socket.on('newImg', function(user, img) {
that._displayImage(user, img);
});
有个问题就是如果图片过大,会破坏整个窗口的布局,或者会出现水平滚动条,所以我们对图片进行样式上的设置让它最多只能以聊天窗口的99%宽度来显示,这样过大的图片就会自己缩小了。
#historyMsg img {
max-width: 99%;
}
但考虑到缩小后的图片有可能失真,用户看不清,我们需要提供一个方法让用户可以查看原尺寸大小的图片,所以将图片用一个链接进行包裹,当点击图片的时候我们打开一个新的窗口页面,并将图片按原始大小呈现到这个新页面中让用户查看。
所以最后我们实现的_displayNImage方法应该是这样的。
将以下代码添加到hichat.js的HiChat类中。
www/scripts/hichat.js
_displayImage: function(user, imgData, color) {
var container = document.getElementById('historyMsg'),
msgToDisplay = document.createElement('p'),
date = new Date().toTimeString().substr(0, 8);
msgToDisplay.style.color = color || '#000';
msgToDisplay.innerHTML = user + '<span class="timespan">(' + date + '): </span> <br/>' + '<a href="' + imgData + '" target="_blank"><img src="' + imgData + '"/></a>';
container.appendChild(msgToDisplay);
container.scrollTop = container.scrollHeight;
}
再次启动服务器打开程序,我们可以发送图片了。
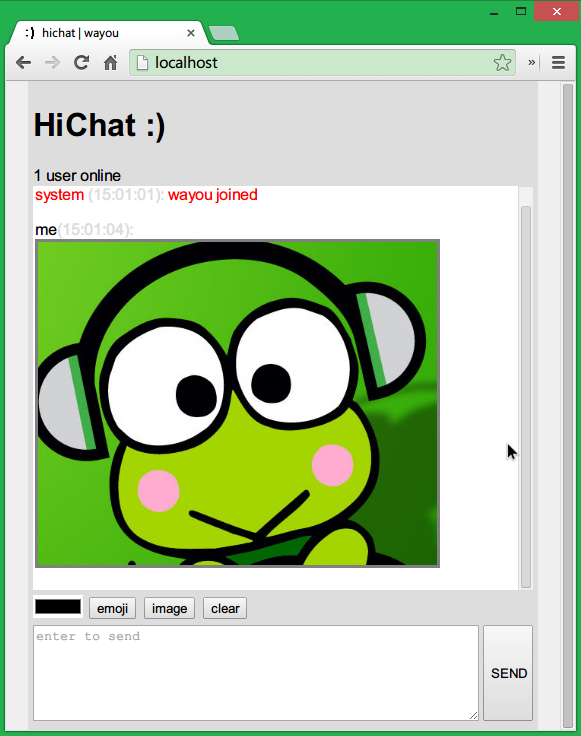
发送表情
文字总是很难表达出说话时的面部表情的,于是表情就诞生了。
前面已经介绍过如何发送图片了,严格来说,表情也是图片,但它有特殊之处,因为表情可以穿插在文字中一并发送,所以就不能像处理图片那样来处理表情了。
根据以往的经验,其他聊天程序是把表情转为符号,比如我想发笑脸,并且规定’:)’这个符号代码笑脸表情,然后数据传输过程中其实转输的是一个冒号加右括号的组合,当每个客户端接收到消息后,从文字当中将这些表情符号提取出来,再用gif图片替换,这样呈现到页面我们就 看到了表情加文字的混排了。
你好,王尼玛[emoji:23]——>你好,王尼玛
上面形象地展示了我们程序中表情的使用,可以看出我规定了一种格式来代表表情,[emoji:xx],中括号括起来然后’emoji’加个冒号,后面跟一个数字,这个数字表示某个gif图片的编号。程序中,如果我们点击表情按扭,然后呈现所有可用的表情图片,当用户选择一个表情后,生成对应的代码插入到当前待发送的文字消息中。发出去后,每个人接收到的也是代码形式的消息,只是在将消息显示到页面前,我们将表情代码提取出来,获取图片编号,然后用相应的图片替换。
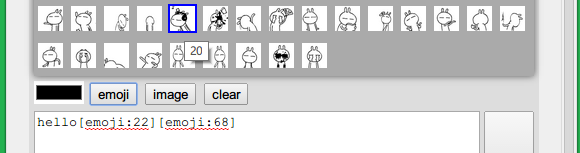
首先得将所有可用的表情图片显示到一个小窗口,这个窗口会在点击了表情按钮后显示如下图,在HTML代码中已经添加好了这个窗口了,下面只需实现代码部分。
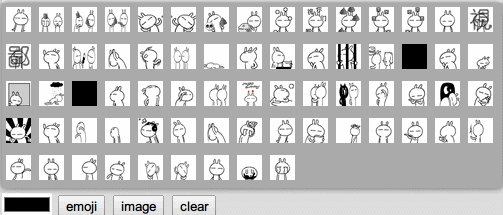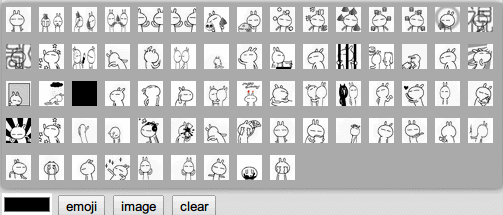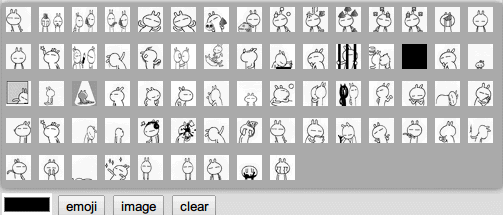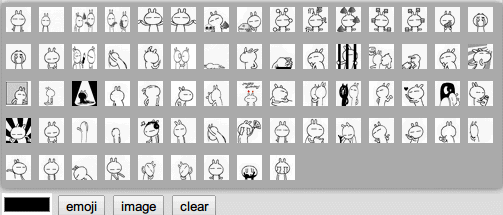
我们使用兔斯基作为我们聊天程序的表情包。可以看到,有很多张gif图,如果手动编写的话,要花一些功夫,不断地写<img src=’xx.gif’/>,所以考虑将这个工作交给代码来自动完成,写一个方法来初始化所有表情。
为此将以下代码添加到HiChat类中,并在init方法中调用这个方法。
www/scripts/hichat.js
_initialEmoji: function() {
var emojiContainer = document.getElementById('emojiWrapper'),
docFragment = document.createDocumentFragment();
for (var i = 69; i > 0; i--) {
var emojiItem = document.createElement('img');
emojiItem.src = '../content/emoji/' + i + '.gif';
emojiItem.title = i;
docFragment.appendChild(emojiItem);
};
emojiContainer.appendChild(docFragment);
}
同时将以下代码添加到hichat.js的init方法中。
www/scripts/hichat.js
this._initialEmoji();
document.getElementById('emoji').addEventListener('click', function(e) {
var emojiwrapper = document.getElementById('emojiWrapper');
emojiwrapper.style.display = 'block';
e.stopPropagation();
}, false);
document.body.addEventListener('click', function(e) {
var emojiwrapper = document.getElementById('emojiWrapper');
if (e.target != emojiwrapper) {
emojiwrapper.style.display = 'none';
};
});
上面向页面添加了两个单击事件,一是表情按钮单击显示表情窗口,二是点击页面其他地方关闭表情窗口。
现在要做的就是,具体到某个表情被选中后,需要获取被选中的表情,然后转换为相应的表情代码插入到消息框中。
为此我们再写一个这些图片的click事件处理程序。将以下代码添加到hichat.js的inti方法中。
www/scripts/hichat.js
document.getElementById('emojiWrapper').addEventListener('click', function(e) {
//获取被点击的表情
var target = e.target;
if (target.nodeName.toLowerCase() == 'img') {
var messageInput = document.getElementById('messageInput');
messageInput.focus();
messageInput.value = messageInput.value + '[emoji:' + target.title + ']';
};
}, false);
现在表情选中后,消息输入框中可以得到相应的代码了。
之后的发送也普通消息发送没区别,因为之前已经实现了文本消息的发送了,所以这里不用再实现什么,只是需要更改一下之前我们用来显示消息的代码,首先判断消息文本中是否含有表情符号,如果有,则转换为图片,最后再显示到页面。
为此我们写一个方法接收文本消息为参数,用正则搜索其中的表情符号,将其替换为img标签,最后返回处理好的文本消息。
将以下代码添加到HiChat类中。
www/scripts/hichat.js
_showEmoji: function(msg) {
var match, result = msg,
reg = /\[emoji:\d+\]/g,
emojiIndex,
totalEmojiNum = document.getElementById('emojiWrapper').children.length;
while (match = reg.exec(msg)) {
emojiIndex = match[0].slice(7, -1);
if (emojiIndex > totalEmojiNum) {
result = result.replace(match[0], '[X]');
} else {
result = result.replace(match[0], '<img class="emoji" src="../content/emoji/' + emojiIndex + '.gif" />');
};
};
return result;
}
现在去修改之前我们显示消息的_displayNewMsg方法,让它在显示消息之前调用这个_showEmoji方法。
_displayNewMsg: function(user, msg, color) {
var container = document.getElementById('historyMsg'),
msgToDisplay = document.createElement('p'),
date = new Date().toTimeString().substr(0, 8),
//将消息中的表情转换为图片
msg = this._showEmoji(msg);
msgToDisplay.style.color = color || '#000';
msgToDisplay.innerHTML = user + '<span class="timespan">(' + date + '): </span>' + msg;
container.appendChild(msgToDisplay);
container.scrollTop = container.scrollHeight;
}
下面是实现后的效果:
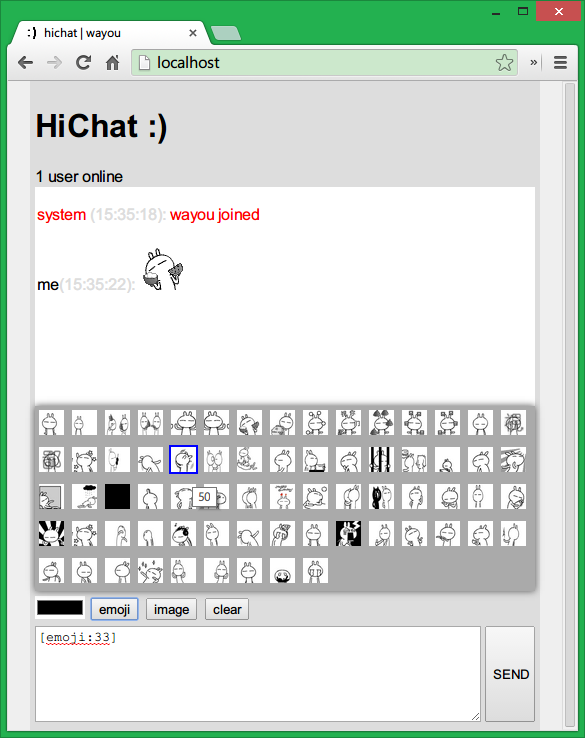
主要功能已经完成得差不多了,为了让程序更加人性与美观,可以加入一个修改文字颜色的功能,以及键盘快捷键操作的支持,这也是一般聊天程序都有的功能,回车即可以发送消息。
文字颜色
万幸,HTML5新增了一个专门用于颜色选取的input标签,并且Chrome对它的支持非常之赞,直接弹出系统的颜色拾取窗口。
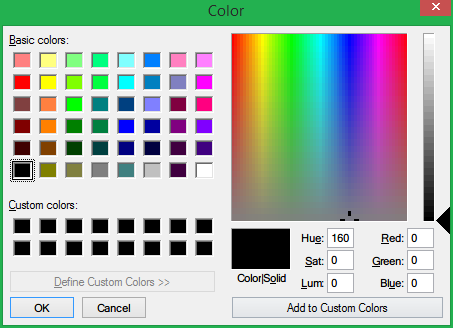
IE及FF中均是一个普通的文本框,不过不影响使用,只是用户只能通过输入具体的颜色值来进行颜色设置,没有Chrome里面那么方便也直观。
之前我们的_displayNewMsg方法可以接收一个color参数,现在要做的就是每次发送消息到服务器的时候,多加一个color参数就可以了,同时,在显示消息时调用_displayNewMsg的时候将这个color传递过去。
下面是修改hichat.js中消息发送按钮代码的示例:
document.getElementById('sendBtn').addEventListener('click', function() {
var messageInput = document.getElementById('messageInput'),
msg = messageInput.value,
//获取颜色值
color = document.getElementById('colorStyle').value;
messageInput.value = '';
messageInput.focus();
if (msg.trim().length != 0) {
//显示和发送时带上颜色值参数
that.socket.emit('postMsg', msg, color);
that._displayNewMsg('me', msg, color);
};
}, false);
同时修改hichat.js中接收消息的代码,让它接收颜色值
this.socket.on('newMsg', function(user, msg, color) {
that._displayNewMsg(user, msg, color);
});
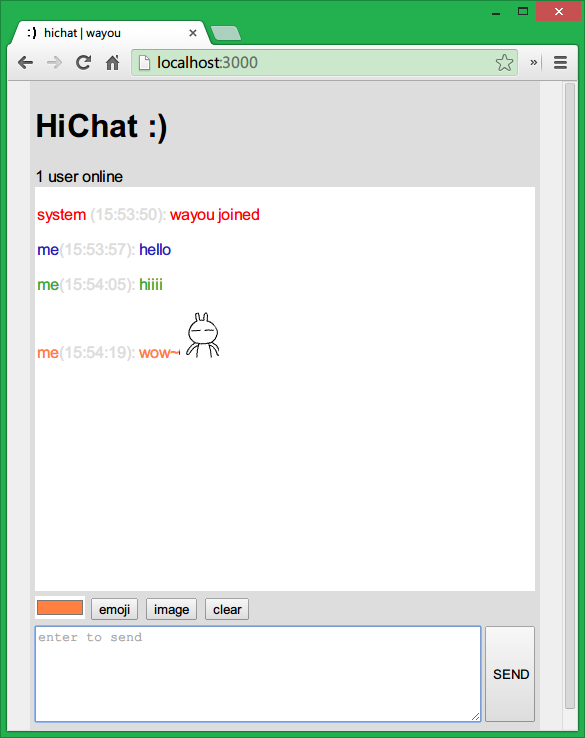
这只是展示了发送按钮的修改,改动非常小,只是每次消息发送时获取一下颜色值,同时emit事件到服务器的时候也带上这个颜色值,这样前端在显示时就可以根据这个颜色值为每个不两只用户显示他们自己设置的颜色了。剩下的就是按相同的做法把发送图片时也加上颜色,这里省略。
最后效果:
按键操作
将以下代码添加到hichat.js的inti方法中,这样在输入昵称后,按回车键就可以登陆,进入聊天界面后,回车键可以发送消息。
document.getElementById('nicknameInput').addEventListener('keyup', function(e) {
if (e.keyCode == 13) {
var nickName = document.getElementById('nicknameInput').value;
if (nickName.trim().length != 0) {
that.socket.emit('login', nickName);
};
};
}, false);
document.getElementById('messageInput').addEventListener('keyup', function(e) {
var messageInput = document.getElementById('messageInput'),
msg = messageInput.value,
color = document.getElementById('colorStyle').value;
if (e.keyCode == 13 && msg.trim().length != 0) {
messageInput.value = '';
that.socket.emit('postMsg', msg, color);
that._displayNewMsg('me', msg, color);
};
}, false);
部署上线
最后一步,当然就是将我们的辛勤结晶部署到实际的站点。这应该是最激动人心也是如释重负的一刻。但在这之前,让我们先添加一个node.js程序通用的package.json文件,该文件里面可以指定我们的程序使用了哪些模块,这样别人在获取到代码后,只需通过npm install命令就可以自己下载安装程序中需要的模块了,而不用我们把模块随源码一起发布。
添加package.json文件
将以下代码保存为package.json保存到跟server.js相同的位置。
{
"name": "hichat",
"description": "a realtime chat web application",
"version": "0.4.0",
"main": "server.js",
"dependencies": {
"express": "3.4.x",
"socket.io": "0.9.x"
},
"engines": {
"node": "0.10.x",
"npm": "1.2.x"
}
}
云服务选择与部署
首先我们得选择一个支持Node.js同时又支持web socket协议的云服务器。因为只是用于测试,空间内存限制什么的都无所谓,只要免费就行。Node.js在GitHub的Wiki页面上列出了众多支持Node.js环境的云服务器,选来选去满足条件的只有heroku。
如果你之前到heroku部署过相关Node程序的话,一定知道其麻烦之处,并且出错了非常不容易调试。不过当我在写这篇博客的时候,我发现了一个利器codeship,将它与你的github绑定之后,你每次提交了新的代码它会自动部署到heroku上面。什么都不用做!
代码更新,环境设置,编译部署,全部自动搞定,并且提供了详细的log信息及各步骤的状态信息。使用方法也是很简单,注册后按提示,两三步搞定,鉴于本文已经够长了,应该创纪录了,这里就不多说了。
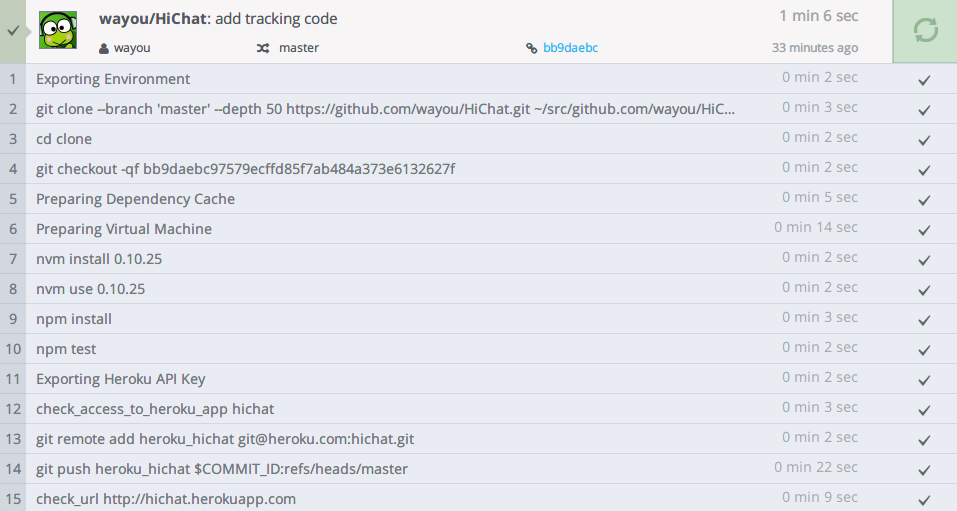
已知问题
部署测试后,发现一些本地未出现的问题,主要有以下几点:
- 首次连接过慢,有时会失败出现503错误,这个查了下heroku文档,官方表示程序首次接入时受资源限制确实会很慢的,这就是用免费套餐注定被鄙视的结果,不过用于线上测试这点还是能够忍受的
- 发送表情时,Chrome会向服务器重新请求已经下载到客户端的gif图片,而IE和FF都无此问题,导致在Chrome里表情会有延迟,进而出现聊天主信息窗口滚动也不及时的现象
- 用户未活动一定时间后会与服务器失连,socket自动断开,不知道是socket.io内部机制还是又是heroku捣鬼
总结展望
经过上面一番折腾,一个基本的聊天程序便打造完毕。可以完善的地方还有许多,比如利用CSS3的动画,完全可以制作出窗口抖动功能的。听起来很不错是吧。同时利用HTML5的Audio API,要实现类似微信的语音消息也不是不可能的,够震撼吧。甚至还有Geolocaiton API我们就可以联想到实现同城功能,利用Webcam可以打造出视频对聊,但这方面WebRTC已经做得很出色了。
PS:做程序员之前有两个想法,一是写个播放器,一是写个聊天程序,现在圆满了。
REFERENCE
Feel free to repost but keep the link to this page please!







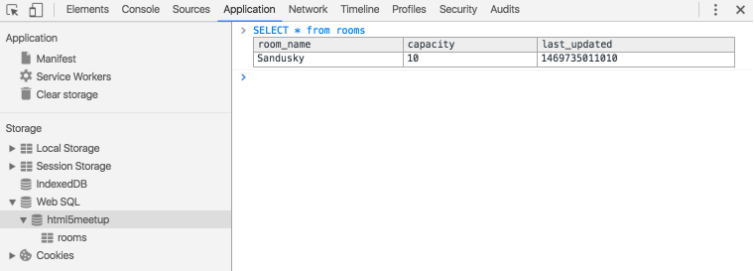
 ) 可以更新数据库。
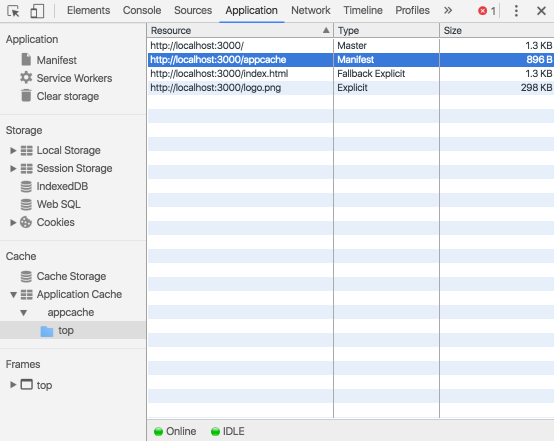
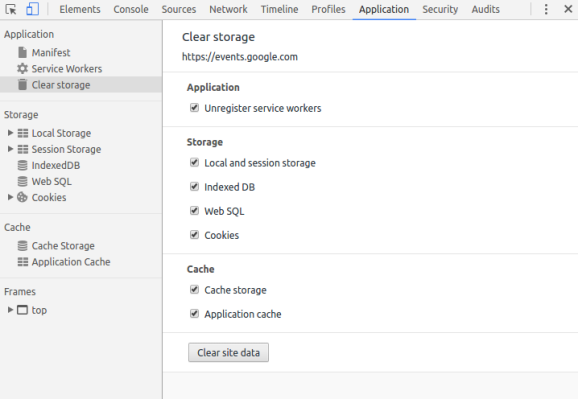
) 可以更新数据库。 ) 可以删除数据库中的所有数据。 从 Clear storage 窗格中,点击一次按钮注销服务工作线程并移除其他存储与缓存也可以实现此目标。
) 可以删除数据库中的所有数据。 从 Clear storage 窗格中,点击一次按钮注销服务工作线程并移除其他存储与缓存也可以实现此目标。