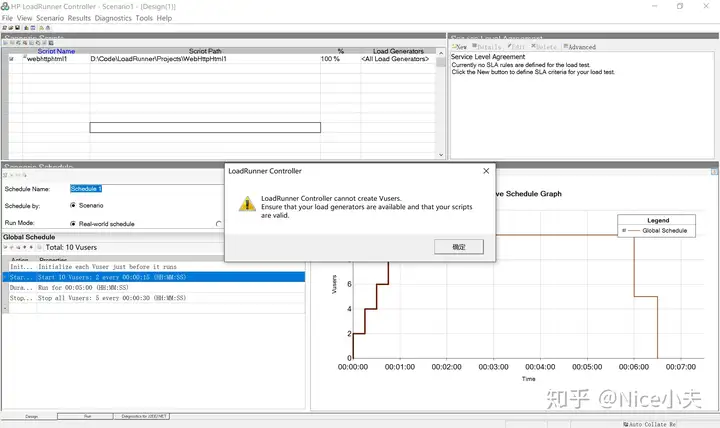
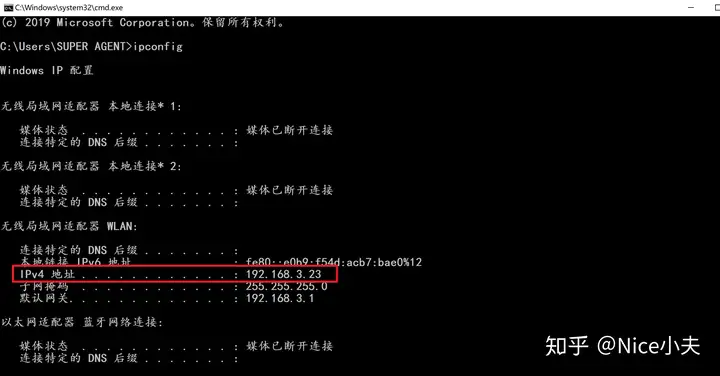
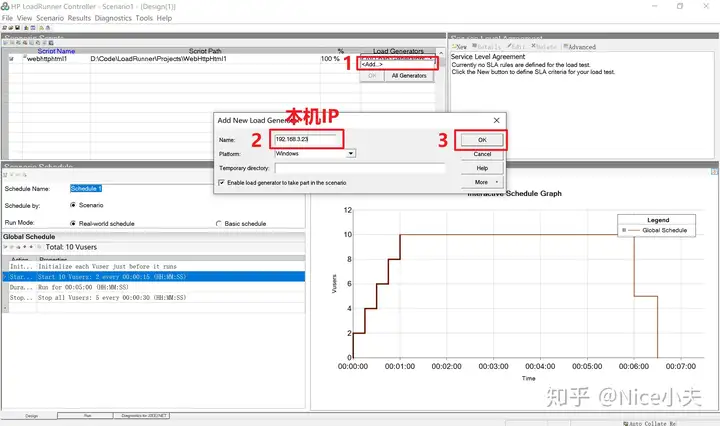
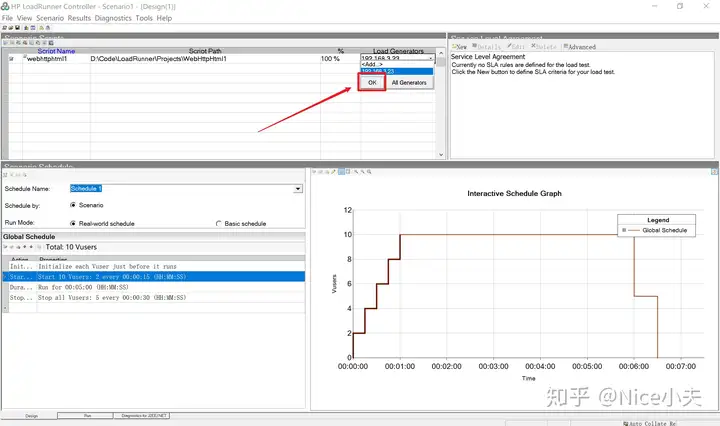
来源: c# Dapper,添加,修改,删除,查询,事务,存储过程,含数据库(从入门到高级)_橙-极纪元的博客-CSDN博客
目录
前言
介绍
重点提示
安装
使用NuGet安装
准备工作
数据库SQL (含存储过程)
模型类
Type.cs
Product.cs
数据库访问层
引入关键库
创建数据库连接
添加 3个方法
1.新增一条数据,不带事务
2.新增一条数据,且,返回自增ID;不带事务
3.新增多条数据,不带事务
修改 2个方法
1.修改一条数据,不带事务
2.修改多条数据,不带事务
删除 2个方法
1.删除一条数据,不带事务
2.删除多条数据,不带事务
查询/Join查询/函数查询/查询In操作/多语句查询/验证类型名是否存在 7个方法
1.查询一条数据
2.普通查询-列表
3.Join查询-列表
4.函数查询 和,平均值,最大值,最小值
5.查询In操作
6.多语句查询
7.验证类型名是否存在
事务 3个方法
1.事务第一种用法;添加一条分类的同时新增一条产品数据
2.事务第二种用法;添加一条分类的同时新增一条产品数据
3.新增(添加)多条数据,带事务
执行存储过程 3个方法
1.查询产品表,根据类型ID 查询出所有产品,且返回产品数量
2.插入新产品的存储过程,产品名存在就不插入
3.获取产品表和产品类型表中的所有数据
sql
前言
介绍
C# Dapper高级编程;
添加方法3个,
修改方法2个,
删除方法2个,
查询方法7个(含Join),
事务方法3个,
存储过程方法3个
重点提示
一、ORM框架执行效率排序EF 7 8 Dapper执行效率 1 2
二、传参
传参有三种方式
第一种:model模型传参 如:User user=new User(); user.name=”小明”
第二种:匿名类型传参 如:var user = new {name=”小明”};
第三种:DynamicParameters 传参 如下:
DynamicParameters paras = new DynamicParameters();
paras.Add(“@name”, “小明”);//输入参数
三、
只有在BeginTransaction(事务)时要求连接是打开的conn.Open()。
而在不使用事务的时候,简单的增删改查可以不用这一句dbConnection.Open()(即conn.Open());
因为Dapper的大部分方法中有dbConnection.Open(),所以不需要每次都打开连接,程序会自己处理。
安装
使用NuGet安装
项目》引用》右键》管理NuGet程序包》左侧出现界面》浏览》输入“Dapper”》选中》左侧有个“安装”》点击安装
在解决方案管理器中点击项目,查看引用,如果有Dapper,说明安装成功。
准备工作
数据库sql (含存储过程)
USE [master]
GO
/****** Object: Database [DBTase] Script Date: 2020/11/20 10:22:57 ******/
CREATE DATABASE [DBTase]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N’DBTase’, FILENAME = N’C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLServer\MSSQL\DATA\DBTase.mdf’ , SIZE = 5120KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N’DBTase_log’, FILENAME = N’C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLServer\MSSQL\DATA\DBTase_log.ldf’ , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%)
GO
ALTER DATABASE [DBTase] SET COMPATIBILITY_LEVEL = 110
GO
IF (1 = FULLTEXTSERVICEPROPERTY(‘IsFullTextInstalled’))
begin
EXEC [DBTase].[dbo].[sp_fulltext_database] @action = ‘enable’
end
GO
ALTER DATABASE [DBTase] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [DBTase] SET ANSI_NULLS OFF
GO
ALTER DATABASE [DBTase] SET ANSI_PADDING OFF
GO
ALTER DATABASE [DBTase] SET ANSI_WARNINGS OFF
GO
ALTER DATABASE [DBTase] SET ARITHABORT OFF
GO
ALTER DATABASE [DBTase] SET AUTO_CLOSE OFF
GO
ALTER DATABASE [DBTase] SET AUTO_CREATE_STATISTICS ON
GO
ALTER DATABASE [DBTase] SET AUTO_SHRINK OFF
GO
ALTER DATABASE [DBTase] SET AUTO_UPDATE_STATISTICS ON
GO
ALTER DATABASE [DBTase] SET CURSOR_CLOSE_ON_COMMIT OFF
GO
ALTER DATABASE [DBTase] SET CURSOR_DEFAULT GLOBAL
GO
ALTER DATABASE [DBTase] SET CONCAT_NULL_YIELDS_NULL OFF
GO
ALTER DATABASE [DBTase] SET NUMERIC_ROUNDABORT OFF
GO
ALTER DATABASE [DBTase] SET QUOTED_IDENTIFIER OFF
GO
ALTER DATABASE [DBTase] SET RECURSIVE_TRIGGERS OFF
GO
ALTER DATABASE [DBTase] SET DISABLE_BROKER
GO
ALTER DATABASE [DBTase] SET AUTO_UPDATE_STATISTICS_ASYNC OFF
GO
ALTER DATABASE [DBTase] SET DATE_CORRELATION_OPTIMIZATION OFF
GO
ALTER DATABASE [DBTase] SET TRUSTWORTHY OFF
GO
ALTER DATABASE [DBTase] SET ALLOW_SNAPSHOT_ISOLATION OFF
GO
ALTER DATABASE [DBTase] SET PARAMETERIZATION SIMPLE
GO
ALTER DATABASE [DBTase] SET READ_COMMITTED_SNAPSHOT OFF
GO
ALTER DATABASE [DBTase] SET HONOR_BROKER_PRIORITY OFF
GO
ALTER DATABASE [DBTase] SET RECOVERY FULL
GO
ALTER DATABASE [DBTase] SET MULTI_USER
GO
ALTER DATABASE [DBTase] SET PAGE_VERIFY CHECKSUM
GO
ALTER DATABASE [DBTase] SET DB_CHAINING OFF
GO
ALTER DATABASE [DBTase] SET FILESTREAM( NON_TRANSACTED_ACCESS = OFF )
GO
ALTER DATABASE [DBTase] SET TARGET_RECOVERY_TIME = 0 SECONDS
GO
EXEC sys.sp_db_vardecimal_storage_format N’DBTase’, N’ON’
GO
USE [DBTase]
GO
/****** Object: StoredProcedure [dbo].[cp_petowner] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[cp_petowner]
AS
select * from product
GO
/****** Object: StoredProcedure [dbo].[cp_petowner_VarCharValue] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
–2.创建一个带参数的存储过程
CREATE PROCEDURE [dbo].[cp_petowner_VarCharValue]
@ownername varchar(50)
AS
DECLARE @ownername2 varchar(50)
set @ownername2=’小米手机’
select *,@ownername as ownername from product where name=@ownername2
GO
/****** Object: StoredProcedure [dbo].[PROC_Product] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
–【存储过程】查询产品表,根据类型ID 查询出所有产品,且返回产品数量
create proc [dbo].[PROC_Product]
@typeID int,
@count int out
as
begin
select @count=COUNT(ID) from Product where TypeID=@typeID;
select * from Product where TypeID=@typeID;
end
GO
/****** Object: StoredProcedure [dbo].[PROC_Product_insert] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
–【存储过程】插入新产品的存储过程,产品名存在就不插入
create proc [dbo].[PROC_Product_insert]
@name nvarchar(50),
@typeID int ,
@count int out
as
begin
declare @c int;
select @c=COUNT(ID) from Product where Name=@name;
if(@c!=0)
set @count =0;
else
begin
insert into Product(name, typeID) values(@name,@typeID);
set @count=1;
end
end
GO
/****** Object: StoredProcedure [dbo].[PROC_TypeAndProduct] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
–【存储过程】获取产品表和产品类型表中的所有数据
create procedure [dbo].[PROC_TypeAndProduct]
as
begin
select TypeID,TypeName from [Type];
select ID,TypeID,Name from Product;
end
GO
/****** Object: Table [dbo].[Product] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Product](
[ID] [int] IDENTITY(1,1) NOT NULL,
[TypeID] [int] NULL,
[Name] [nvarchar](50) NULL,
CONSTRAINT [PK_Product] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
/****** Object: Table [dbo].[Type] Script Date: 2020/11/20 10:22:57 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Type](
[TypeID] [int] IDENTITY(1,1) NOT NULL,
[TypeName] [nvarchar](50) NULL,
CONSTRAINT [PK_Type] PRIMARY KEY CLUSTERED
(
[TypeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[Product] ON
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (1, 1, N’苹果手机’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (3, 1, N’三星手机’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (4, 1, N’华为手机’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (5, 1, N’小米手机’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (7, 2, N’苹果电脑’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (8, 2, N’戴尔电脑’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (9, 3, N’小米手环’)
INSERT [dbo].[Product] ([ID], [TypeID], [Name]) VALUES (10, 3, N’华为手环’)
SET IDENTITY_INSERT [dbo].[Product] OFF
SET IDENTITY_INSERT [dbo].[Type] ON
INSERT [dbo].[Type] ([TypeID], [TypeName]) VALUES (1, N’手机’)
INSERT [dbo].[Type] ([TypeID], [TypeName]) VALUES (2, N’电脑’)
INSERT [dbo].[Type] ([TypeID], [TypeName]) VALUES (3, N’手表’)
SET IDENTITY_INSERT [dbo].[Type] OFF
ALTER TABLE [dbo].[Product] WITH CHECK ADD CONSTRAINT [FK_product_Type] FOREIGN KEY([TypeID])
REFERENCES [dbo].[Type] ([TypeID])
GO
ALTER TABLE [dbo].[Product] CHECK CONSTRAINT [FK_product_Type]
GO
USE [master]
GO
ALTER DATABASE [DBTase] SET READ_WRITE
GO
模型类
Type.cs
/// <summary>
/// 产品类型
/// </summary>
public class Type
{
/// <summary>
/// TypeID
/// </summary>
private int _typeid;
public int TypeID
{
get { return _typeid; }
set { _typeid = value; }
}
/// <summary>
/// TypeName
/// </summary>
private string _typename;
public string TypeName
{
get { return _typename; }
set { _typename = value; }
}
}
Product.cs
/// <summary>
/// 产品
/// </summary>
public class Product
{
/// <summary>
/// ID
/// </summary>
private int _id;
public int ID
{
get { return _id; }
set { _id = value; }
}
/// <summary>
/// TypeID
/// </summary>
private int _typeid;
public int TypeID
{
get { return _typeid; }
set { _typeid = value; }
}
/// <summary>
/// Name
/// </summary>
private string _name;
public string Name
{
get { return _name; }
set { _name = value; }
}
public Type ProductType { get; set; }//做联表查询
}
数据库访问层
引入关键库
using System;
using System.Collections.Generic;
using System.Linq;
using Dapper;
using System.Data;
using System.Data.SqlClient;
创建数据库连接
private static string connStr = “server=.;uid=sa;pwd=sa;database=DBTase”;
添加 3个方法
1.新增一条数据,不带事务
/// <summary>
/// 新增一条数据,不带事务
/// </summary>
public static void Add()
{
string sql = @”insert into Type(TypeName) values(@TypeName)”;
Type productType = new Type()
{
TypeName = “测试类型2020-11-19”
};
using (SqlConnection conn = new SqlConnection(connStr))
{
int result = conn.Execute(sql, productType);
if (result > 0)
{
Console.WriteLine(“新增一条数据成功!”);
}
}
}
2.新增一条数据,且,返回自增ID;不带事务
/// <summary>
/// 新增一条数据,且,返回自增ID;不带事务
/// </summary>
public static void AddGetID()
{
/*
在高并发的环境中 可能得到的@@identity会不是你想要的结果
你在新增,别人也可能也在新增 。你获取的时候就是 获取到最后插入的那条记录的ID.
所以 我们要修改一下
SELECT @@identity
修改为
SELECT SCOPE_IDENTITY();
*/
string sql = @”insert into Type(TypeName) values(@TypeName);SELECT SCOPE_IDENTITY();”;
Type productType = new Type()
{
TypeName = “新增一条数据,且,返回自增ID;不带事务”
};
using (SqlConnection conn = new SqlConnection(connStr))
{
//获取新加的ID
int id = Convert.ToInt32(conn.ExecuteScalar(sql, productType));
if (id > 0)
{
Console.WriteLine(“新增一条数据,且,返回自增ID;不带事务”);
Console.WriteLine($”新增ID为:{id}”);
}
}
}
3.新增多条数据,不带事务
/// <summary>
/// 新增多条数据,不带事务
/// </summary>
public static void AddList()
{
string sql = @”insert into Type(TypeName) values(@TypeName)”;
List<Type> productTypeList = new List<Type>
{
new Type(){ TypeName = “1测试类型2020-11-19”},
new Type(){ TypeName = “2测试类型2020-11-19”},
new Type(){ TypeName = “3测试类型2020-11-19”},
new Type(){ TypeName = “4测试类型2020-11-19”},
new Type(){ TypeName = “5测试类型2020-11-19”},
new Type(){ TypeName = “6测试类型2020-11-19”}
};
using (SqlConnection conn = new SqlConnection(connStr))
{
int result = conn.Execute(sql, productTypeList);
if (result > 0)
{
Console.WriteLine(“新增多条数据,不带事务–添加成功!”);
}
}
}
修改 2个方法
1.修改一条数据,不带事务
/// <summary>
/// 修改一条数据,不带事务
/// </summary>
public static void Update()
{
string sql = @”update Type set TypeName=@TypeName where TypeID=@TypeID”;
Type productType = new Type()
{
TypeID = 5,
TypeName = “Update测试类型2020-11-19”
};
using (SqlConnection conn = new SqlConnection(connStr))
{
int result = conn.Execute(sql, productType);
if (result > 0)
{
Console.WriteLine(“修改一条数据成功!”);
}
}
}
2.修改多条数据,不带事务
/// <summary>
/// 修改多条数据,不带事务
/// </summary>
public static void UpdateList()
{
string sql = @”update Type set TypeName=@TypeName where TypeID=@TypeID”;
List<Type> productTypeList = new List<Type>
{
new Type(){ TypeID=6, TypeName = “1Update测试类型2020-11-19”},
new Type(){ TypeID=7, TypeName = “2Update测试类型2020-11-19”},
new Type(){ TypeID=8, TypeName = “3Update测试类型2020-11-19”},
new Type(){ TypeID=9, TypeName = “4Update测试类型2020-11-19”},
new Type(){ TypeID=10,TypeName = “5Update测试类型2020-11-19”},
new Type(){ TypeID=11,TypeName = “6Update测试类型2020-11-19”}
};
using (SqlConnection conn = new SqlConnection(connStr))
{
int result = conn.Execute(sql, productTypeList);
if (result > 0)
{
Console.WriteLine(“修改多条数据成功!”);
}
}
}
删除 2个方法
1.删除一条数据,不带事务
/// <summary>
/// 删除一条数据,不带事务
/// </summary>
public static void Delete()
{
string sql = @”delete Type where TypeID=@TypeID”;
Type productType = new Type();
productType.TypeID = 11;
using (SqlConnection conn = new SqlConnection(connStr))
{
//添加、删除、修改 Execute 存储过程
//update
int result = conn.Execute(sql, productType);
if (result > 0)
{
Console.WriteLine(“删除一条数据成功!”);
}
}
}
2.删除多条数据,不带事务
/// <summary>
/// 删除多条数据,不带事务
/// </summary>
public static void DeleteList()
{
string sql = @”delete Type where TypeID=@TypeID”;
List<Type> productTypeList = new List<Type>
{
new Type(){ TypeID=9},
new Type(){ TypeID=10}
};
using (SqlConnection conn = new SqlConnection(connStr))
{
//添加、删除、修改 Execute 存储过程
//update
int result = conn.Execute(sql, productTypeList);
if (result > 0)
{
Console.WriteLine(“删除多条数据成功!”);
}
}
}
查询/Join查询/函数查询/查询In操作/多语句查询/验证类型名是否存在 7个方法
1.查询一条数据
/// <summary>
/// 查询一条数据
/// </summary>
public static void GetModel()
{
Console.WriteLine(“******查询一条数据******”);
string sql = @”select * from Type where TypeID=@TypeID”;
Type productType = new Type();
productType.TypeID = 6;
using (SqlConnection conn = new SqlConnection(connStr))
{
Type _type = conn.Query<Type>(sql, productType).Single();
Console.WriteLine($”[ID:{_type.TypeID}]Name:{_type.TypeName}”);
}
}
2.普通查询-列表
/// <summary>
/// 普通查询-列表
/// ProductSelect产品查询
/// </summary>
public static void ProductSelect()
{
Console.WriteLine(“******普通查询-列表******”);
string sql = “select * from product”;
using (SqlConnection conn = new SqlConnection(connStr))
{
List<Product> productsList = conn.Query<Product>(sql).ToList();
Console.WriteLine(“//ProductSelect查询//”);
foreach (var item in productsList)
{
Console.WriteLine($”ID:{item.ID}\nName:{item.Name}”);
}
}
}
3.Join查询-列表
/// <summary>
/// Join查询-列表
/// ProductJoinTypeSelect产品带产品类型名称查询
/// </summary>
public static void ProductJoinTypeSelect()
{
Console.WriteLine(“******Join查询-列表******”);
string sql = @”select * from product p
left join type t
on (p.TypeID=t.TypeID)”;
using (SqlConnection conn = new SqlConnection(connStr))
{
var productsList = conn.Query<Product, Type, Product>
(sql, (product, type) =>
{
product.ProductType = type;//关联表
return product;
}, splitOn: “typeid”//建立关系的字段
).ToList();
Console.WriteLine(“//ProductJoinTypeSelect查询//”);
foreach (var item in productsList)
{
Console.WriteLine($”ID:{item.ID}\nName:{item.Name}\nTypeName:{item.ProductType.TypeName}”);
}
}
}
4.函数查询 和,平均值,最大值,最小值
/// <summary>
/// 函数查询 和,平均值,最大值,最小值
/// </summary>
public static void GetFunction()
{
Console.WriteLine(“******函数查询,和,平均值,最大值,最小值******”);
string sql = @”select * from Type”;//ORM框架执行效率排序EF 7 8 Dapper执行效率 1 2
using (SqlConnection conn = new SqlConnection(connStr))
{
List<Type> productTypeList = conn.Query<Type>(sql).ToList();
int count = productTypeList.Count();//获取记录条数
Console.WriteLine($”记录条数:{count}”);
var sum = productTypeList.Sum(p => p.TypeID);
var avg = productTypeList.Average(p => p.TypeID);
var max = productTypeList.Max(p => p.TypeID);
var min = productTypeList.Min(p => p.TypeID);
Console.WriteLine($”和 Sum:{sum}”);
Console.WriteLine($”平均值 Average:{avg}”);
Console.WriteLine($”最大值 Max:{max}”);
Console.WriteLine($”最小值 Min:{min}”);
foreach (Type t in productTypeList)
{
Console.WriteLine($”{t.TypeID}-{t.TypeName}”);
}
}
}
5.查询In操作
/// <summary>
/// 查询In操作
/// </summary>
public static void GetIn()
{
Console.WriteLine(“******查询In操作******”);
string sql = “select * from product where ID in @ids”;
int[] ids = {1,2,3,4,5};
using (SqlConnection conn = new SqlConnection(connStr))
{
List<Product> productsList = conn.Query<Product>(sql,new { ids= ids }).ToList();
foreach (var item in productsList)
{
Console.WriteLine($”ID:{item.ID}\nName:{item.Name}”);
}
}
}
6.多语句查询
/// <summary>
/// 多语句查询
/// </summary>
public static void GetMultiple()
{
Console.WriteLine(“******多语句查询******”);
string sql = “SELECT TypeID, TypeName FROM [Type];SELECT ID, TypeID, Name FROM Product”;
using (SqlConnection conn = new SqlConnection(connStr))
{
Dapper.SqlMapper.GridReader multiReader = conn.QueryMultiple(sql);
//注意:由于首先查出是Type,其次是Product,那么你在执行下面代码的时候顺序必须和sql语句顺序一致
IEnumerable<Type> typeList = multiReader.Read<Type>();
IEnumerable<Product> productList = multiReader.Read<Product>();
Console.WriteLine(“//多语句查询-类型信息”);
foreach (var item in typeList)
{
Console.WriteLine($”ID:{item.TypeID}\nName:{item.TypeName}”);
}
Console.WriteLine(“//多语句查询-产品信息”);
foreach (var item in productList)
{
Console.WriteLine($”ID:{item.ID}\nName:{item.Name}”);
}
}
}
7.验证类型名是否存在
/// <summary>
/// 验证类型名是否存在
/// </summary>
/// <param name=”name”>类型名</param>
/// <returns></returns>
public static bool Check(string name)
{
string sql = “select count(TypeName) from Type where TypeName=@TypeName”;
using (SqlConnection conn = new SqlConnection(connStr))
{
var number = conn.QueryFirst<int>(sql, new { TypeName = name });
if (number > 0)
{
return true;
}
return false;
}
}
事务 3个方法
1.事务第一种用法;添加一条分类的同时新增一条产品数据
/// <summary>
/// 事务第一种用法;添加一条分类的同时新增一条产品数据
/// </summary>
public static void ExecuteTranscationOne()
{
/*
在高并发的环境中 可能得到的@@identity会不是你想要的结果
你在新增,别人也可能也在新增 。你获取的时候就是 获取到最后插入的那条记录的ID.
所以 我们要修改一下
SELECT @@identity
修改为
SELECT SCOPE_IDENTITY();
*/
string TypeSql = @”insert into Type(TypeName) values(@TypeName);
SELECT SCOPE_IDENTITY();”;
string ProduxtSql = @”insert into Product(TypeID,Name)
values(@TypeID,@Name)”;
Type type = new Type()
{
TypeName = “新的分类1”
};
Product product = new Product()
{
TypeID = 0,
Name = “新的产品1”
};
using (SqlConnection conn = new SqlConnection(connStr))//打开数据库方式交给框架执行
{
SqlTransaction trans = null;
try
{
conn.Open();//手动打开数据库链接//在dapper中使用事务,需要手动打开连接
//程序事务,建立在某个连接对象上
//开始事务
trans = conn.BeginTransaction();//连接对象开启事务
int typeID = Convert.ToInt32(conn.ExecuteScalar(TypeSql, type, trans));
product.TypeID = typeID;
int result2 = conn.Execute(ProduxtSql, product, trans);
//提交事务(持久化数据)
trans.Commit();
if (result2 > 0)
Console.WriteLine(“事务1:添加一条数据成功”);
else
Console.WriteLine(“事务1:添加一条数据【失败】”);
}
catch (Exception ex)
{
//事务回滚
trans.Rollback();
Console.WriteLine(ex.Message);
}
}
}
2.事务第二种用法;添加一条分类的同时新增一条产品数据
/// <summary>
/// 事务第二种用法;添加一条分类的同时新增一条产品数据
/// </summary>
public static void ExecuteTranscationTwo()
{
/*
在高并发的环境中 可能得到的@@identity会不是你想要的结果
你在新增,别人也可能也在新增 。你获取的时候就是 获取到最后插入的那条记录的ID.
所以 我们要修改一下
SELECT @@identity
修改为
SELECT SCOPE_IDENTITY();
*/
string TypeSql = @”insert into Type(TypeName) values(@TypeName);
SELECT SCOPE_IDENTITY();”;
string ProduxtSql = @”insert into Product(TypeID,Name)
values(@TypeID,@Name)”;
Type type = new Type()
{
TypeName = “新的分类:事务2”
};
Product product = new Product()
{
TypeID = 0,
Name = “新的产品:事务2”
};
using (SqlConnection conn = new SqlConnection(connStr))//打开数据库方式交给框架执行
{
conn.Open();//在dapper中使用事务,需要手动打开连接
// 连接对象开启事务
//开始事务
using (SqlTransaction trans = conn.BeginTransaction())
{
try
{
//获取新加类型ID
int typeID = Convert.ToInt32(conn.ExecuteScalar(TypeSql, type, trans));
//把新的类型ID 给产品
product.TypeID = typeID;
int result2 = conn.Execute(ProduxtSql, product, trans);
//提交事务(持久化数据)
trans.Commit();
if (result2 > 0)
Console.WriteLine(“事务2:添加一条数据成功”);
else
Console.WriteLine(“事务2:添加一条数据【失败】”);
}
catch (Exception ex)
{
//事务回滚
trans.Rollback();
Console.WriteLine(ex.Message);
}
}
}
}
3.新增(添加)多条数据,带事务
/// <summary>
/// 新增多条数据,带事务
/// </summary>
public static void ExecAddList()
{
string sql = @”insert into Type(TypeID,TypeName) values(@TypeID,@TypeName)”;
List<Type> productTypeList = new List<Type>
{
new Type(){ TypeID=1, TypeName = “Exec1测试类型2020-11-20”},
new Type(){ TypeName = “Exec2测试类型2020-11-20”},
new Type(){ TypeName = “Exec3测试类型2020-11-20”},
new Type(){ TypeName = “Exec4测试类型2020-11-20”},
new Type(){ TypeName = “Exec5测试类型2020-11-20”},
new Type(){ TypeName = “Exec6测试类型2020-11-20″}
};
using (SqlConnection conn = new SqlConnection(connStr))
{
conn.Open();//在dapper中使用事务,需要手动打开连接
// 连接对象开启事务
//开始事务
using (SqlTransaction trans = conn.BeginTransaction())
{
try
{
int result = conn.Execute(sql, productTypeList, trans);
//提交事务(持久化数据)
trans.Commit();
if (result > 0)
{
Console.WriteLine($”新增多条数据,带事务–添加{result}条成功!”);
}
}
catch (Exception ex)
{
//事务回滚
trans.Rollback();
Console.WriteLine(ex.Message);
}
}
}
}
执行存储过程 3个方法
1.查询产品表,根据类型ID 查询出所有产品,且返回产品数量
/// <summary>
/// 查询产品表,根据类型ID 查询出所有产品,且返回产品数量
/// </summary>
public static void PROC_Product_CountAndList()
{
using (SqlConnection conn = new SqlConnection(connStr))//打开数据库方式交给框架执行
{
//参数
DynamicParameters paras = new DynamicParameters();
paras.Add(“@typeID”, 1);//输入参数
paras.Add(“@count”, 0, DbType.Int32, ParameterDirection.Output);//输出参数
List<Product> productList = conn.Query<Product>(“PROC_Product”, paras, commandType: CommandType.StoredProcedure).ToList();//sql 存储过程
int count = paras.Get<int>(“@count”);//获取输出参数
Console.WriteLine($”共计:{count}”);
foreach (Product product in productList)
{
Console.WriteLine($”ID:{product.ID} – Name:{product.Name} – TypeID:{product.TypeID}”);
}
}
}
sql
–【存储过程】查询产品表,根据类型ID 查询出所有产品,且返回产品数量
create proc PROC_Product
@typeID int,
@count int out
as
begin
select @count=COUNT(ID) from Product where TypeID=@typeID;
select * from Product where TypeID=@typeID;
end
GO
–查询
DECLARE @count int
EXEC PROC_Product 1,@count OUTPUT
select @count
2.插入新产品的存储过程,产品名存在就不插入
/// <summary>
/// 插入新产品的存储过程,产品名存在就不插入
/// 参考:https://www.cnblogs.com/wyy1234/p/9078859.html
/// </summary>
public static void PROC_Product_insert()
{
using (SqlConnection conn = new SqlConnection(connStr))//打开数据库方式交给框架执行
{
//参数
DynamicParameters paras = new DynamicParameters();
paras.Add(“@name”, “苹果3”);//输入参数
paras.Add(“@typeID”, 1);//输入参数
paras.Add(“@count”, 0, DbType.Int32, ParameterDirection.Output);//输出参数
var result = conn.Query<Product>(“PROC_Product_insert”, paras, commandType: CommandType.StoredProcedure).ToList();//sql 存储过程
int count = paras.Get<int>(“@count”);//获取输出参数
Console.WriteLine($”插入:{count}条”);
}
}
sql
GO
–【存储过程】插入新产品的存储过程,产品名存在就不插入
create proc PROC_Product_insert
@name nvarchar(50),
@typeID int ,
@count int out
as
begin
declare @c int;
select @c=COUNT(ID) from Product where Name=@name;
if(@c!=0)
set @count =0;
else
begin
insert into Product(name, typeID) values(@name,@typeID);
set @count=1;
end
end
GO
–查询
DECLARE @count int
EXEC PROC_Product_insert “苹果手机2”,1,@count OUTPUT
select @count
3.获取产品表和产品类型表中的所有数据
/// <summary>
/// 获取产品表和产品类型表中的所有数据
/// 参考:https://www.cnblogs.com/wyy1234/p/9078859.html
/// </summary>
public static void PROC_TypeAndProduct()
{
using (SqlConnection conn = new SqlConnection(connStr))//打开数据库方式交给框架执行
{
//获取多个结果集
Dapper.SqlMapper.GridReader res = conn.QueryMultiple(“PROC_TypeAndProduct”, commandType: CommandType.StoredProcedure);
//注意:如果存储过程首先查出是Type,其次是Product,那么你在执行下面代码的时候顺序必须和存储过程查询顺序一致
//read方法获取Type和Product
IEnumerable<Type> typeList = res.Read<Type>();
IEnumerable<Product> productList = res.Read<Product>();
}
}
sql
GO
–【存储过程】获取产品表和产品类型表中的所有数据
create procedure PROC_TypeAndProduct
as
begin
select TypeID,TypeName from [Type];
select ID,TypeID,Name from Product;
end
–查询
EXEC PROC_TypeAndProduct
————————————————
版权声明:本文为CSDN博主「橙-极纪元」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cplvfx/article/details/109849118