[转载]Attribute(特性),怎么用才更好? – 金色海洋工作室 – 博客园.
前几年:
2008年的某一天,我坐火车去北京。硬卧上铺,一晚上就到北京了。爬到上铺之后发现,旁边上铺有一老兄抱着一个笔记本,一开始还以为是看电影呢,仔细一看才发现——老天呀,居然在写代码!
这老兄也太工作狂了,当时可是晚上九点多了呀。屏幕里的IDE和vs有一点像,但又不是。问过了之后才知道,原来是大名鼎鼎的java(具体叫 啥记不清楚了,好像是j2ee,对java相当的不熟,就是那个意思了)。遇到java高手了,不能错失良机,要问问心中的疑问。
于是我就问他“听说java都在用Hibernate,需要把一些信息记录在XML里?”。
老兄说“是呀,以前都这么用。”
“以前?怎么是以前?”
“因为用XML记录信息不方便。”
“那么现在呢?”
“现在用特性了,把需要的信息放在特性里面。”
……
后面又闲聊了一些。
2008年的事情,对话是记不准确了,大体的意思就是这样,一开始用XML,后来用特性。当时我就觉得,俺们.net程序员怎么总是拾人家的牙恵?
现在:
这几天看到了一些关于特性和实体类的文章,中心思想就是用特性记录一些想要记录的信息,用特性把实体类和XX联系起来。
我们先来看看这一篇,C#基础系列:实现自己的ORM(反射以及Attribute在ORM中的应用)
http://blog.csdn.net/RonoTian/archive/2008/09/08/2900714.aspx
给出的示例如下:


public class Person
{
private string _Name;
private int _Age;
private string _Sex;
[DataFieldAttribute(
“name“, “nvarchar“)]
public string Name
{
get { return this._Name; }
set { this._Name = value; }
}
[DataFieldAttribute(
“age“, “int“)]
public int Age
{
get { return this._Age; }
set { this._Age = value; }
}
[DataFieldAttribute(
“sex“, “nvarchar“)]
public string Sex
{
get { return this._Sex; }
set { this._Sex = value; }
}
}
这里用特性([DataFieldAttribute(“name”, “nvarchar”)])来保存字段名和字段类型,把实体类的属性和字段信息连系了起来。
再来看看这个,手把手教你写ORM(六)
http://www.cnblogs.com/alexander-lee/archive/2007/01/24/hbh-orm-06.html
class tb
{
private string _aaa;
[Param(
“NChar“,10)]
public string aaa
{
get { return _aaa; }
set { _aaa = value; }
}
private string _bbb;
[Param(
“NChar“, 10)]
public string bbb
{
get { return _bbb; }
set { _bbb = value; }
}
}
这里用特性([Param(“NChar”, 10)])来保存字段类型和字段大小,把实体类的属性和字段信息连系了起来。不同的人有不同的习惯,有不同的需求,所以对以特性的定义也就不一样了。
再来看一篇,ASP.NET MVC杂谈之:—步步打造表单验证框架[重排版](1)
http://www.cnblogs.com/leven/archive/2009/03/26/aspnetmvc_validate_01.html
public class Student{
[Range(0, 100, “分数的范围必须在{0}和{1}之间.”)]
public int Source{ get; set; }
}
这里用特性([Range(0, 100, “分数的范围必须在{0}和{1}之间.”)])把属性和验证方式联系了起来。
再看一篇(最后一个了),利用Attribute实现的 MVC动态表单
http://www.cnblogs.com/dozer/archive/2010/08/05/DynamicForm.html
[MetadataType(typeof(MusicMetaData))]
public partial class Music
{ }
public class MusicMetaData
{
[DynamicForm(“Create“, true, “Edit“, false, Order = 3)]
public bool IsDeleted { get; set; }
[DynamicForm(
“Create“, true, “Edit“, false, Order = 1)]
public bool IsExist { get; set; }
[DynamicForm(
“Create“, true, “Edit“, false, Order = 2, Type = 2)]
public string Content { get; set; }
}
这个把属性和添加表单里是否需要,表单里的排序,对应的控件连系了起来。
在18楼的回复里,为了能够应对权限的需求,又增加了“admin = true ,user = false ”来应对。
==============================
好了举了四篇文章里的例子,我们来综合分析一下。如果我觉得他们的做法都挺好,要把他们都吸收进来,那么实体类的定义会变成什么样子呢?
public class Person
{
private string _Name;
private int _Age;
private string _Sex;
[DataFieldAttribute(
“name“, “nvarchar“)]
[Param( “nvarchar“, 10)]
[Range(??, “必须填写姓名!”)]
[DynamicForm(“Create“, true, “Edit“, true, Order = 1)]
public string Name
{
get { return this._Name; }
set { this._Name = value; }
}
[DataFieldAttribute(
“age“, “int“)]
[Param(“age“, 4)]
[Range(0, 130, “年龄的范围必须在{0}和{1}之间.”)]
[DynamicForm(“Create“, true, “Edit“, true, Order = 2)]
public int Age
{
get { return this._Age; }
set { this._Age = value; }
}
[DataFieldAttribute(
“sex“, “nvarchar“)]
[Param(“sex“, 1)]
[Range(??, “男或者女”)]
[DynamicForm(“Create“, true, “Edit“, true, Order = 3)]
public string Sex
{
get { return this._Sex; }
set { this._Sex = value; }
}
}
不知道大家对于这样的实体类是不是能够接受?我是接受不了,呵呵。这是有原因的,不是说我不喜欢就不愿意接受,也不是说我是老顽固。
我觉得这么做设计违反了三个原则:最少获知、依赖倒置、单一职责。(在13楼也回复了)
原则不是挂在嘴边上的,是需要在实际里应用的!
1、最少获知:
实体类和字段信息、控件、表单、验证作对应,那么应该知道什么呢?
需要知道字段名、字段大小、字段类型,或者是添加表单是否需要,序号是多少;或者用什么规则来验证?
要知道的也太多了吧。需要什么信息,就增加一个Attribute来保存,是挺简单,但是越积越多,怎么维护呀?
这样就造成了一个问题,Attribute会越来越多,多了就不好维护。Attribute的增加或者改动,就意味着,实体类结构的变化,就是说你要修改你的代码了。
就其原因:违反了最少获知原则。知道的太多了,会累坏的。
2、依赖倒置:
就是要依赖抽象,而不是依赖具体实现。
把具体的信息放在Attribute里面保存,存放的就是一个具体的实现,而不是抽象。Attribute的种类是依据字段名、字段类型,或者是添加表单、修改表单这类的具体的东东,也不是针对抽象来做的。
记录的又是“name”,“nvarchar”,“10”这样的具体的信息,那么就更是具体,离抽象又远了一步。
3、单一职责:
字段名称有变化了,要修改实体类的定义(Attribute也算吧),Create里面要不要显示,需要改的实体类;序号变了,还要改;验证方式变了,还要改。
有一点风吹草动就要改实体类的定义,累不累呢?
============================
如何解决?
说了这么多,都是发现问题,提出问题。估计好多人也都能发现这些,这说这些没有什么意义,我是最反感只提出问题而不解决问题的人,所以我这里要提出我的解决问题的方法。
我不敢保证我的方法就是好方法,但是至少有一个方法,至少是我觉得还可以的方法。
我的做法是,定义一个“字段编号”,比如1000010,前四位是表编号,后三位是字段序号。
这个编号是不能修改的,确定下来就不能再变了。
那么他有什么用处呢?
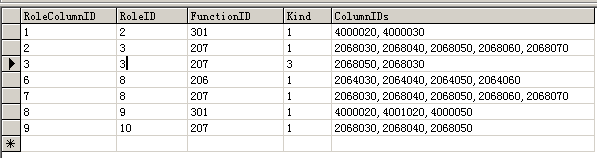
字段编号没有含义,但是却可以代表很多,比如可以代表字段名、字段大小、字段类型(图1),可以表示表单需要哪些字段(图2,建立视图),可以代表验证方式(图3,建立视图),也可以代表权限(图4,建立视图)……
字段编号什么都可以代表,因为他就是一个编号。他是一个抽象的,本身并没有什么意义,但是却可以代表很多。
有了这个字段编号,实体类就好办了,只需要一个Attribute来保存这个字段编号就可以了,以后有任何的扩展需求,也不需要增加或者改动Attribute的数量和定义。
这样,实体类的定义就变成了
public class Person
{
private string _Name;
private int _Age;
private string _Sex;
[ColumnID(
2000020)]
public string Name
{
get { return this._Name; }
set { this._Name = value; }
}
[ColumnID(
2000040)]
public int Age
{
get { return this._Age; }
set { this._Age = value; }
}
[ColumnID(
2000030)]
public string Sex
{
get { return this._Sex; }
set { this._Sex = value; }
}
}
简洁多了吧。什么?你问,这个特性不易读看不出来是什么不好。这个嘛,属性名称是给程序员看的,而特性是给程序看的,只要不写错就可以。
符合三个规则:
最小获知,只需要知道字段编号。
依赖倒置,依赖字段编号,而不是具体的信息。
单一职责,字段名可以变化,字段大小也可以变,验证方式也可以变,只要字段编号不变,那么就不需要改实体类。
===========================================
图1
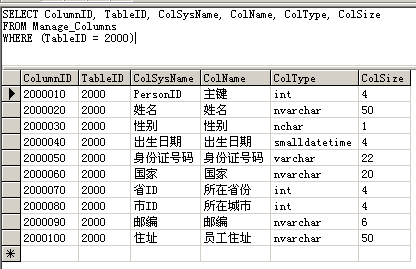
图2,这是一个视图
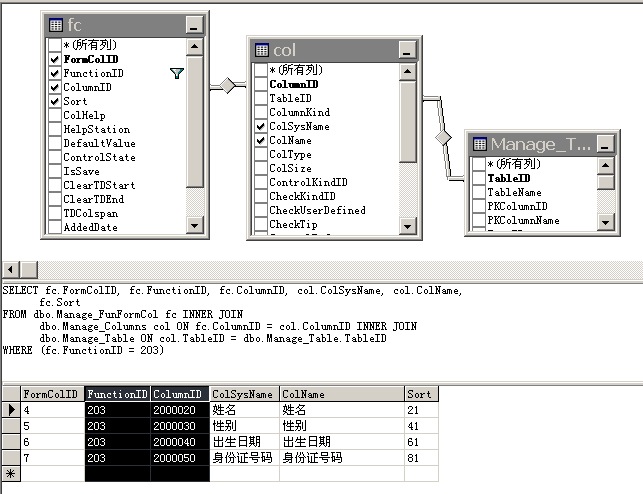
图3,这个也是视图,其实和上面的是一个视图,只是显示的字段不同
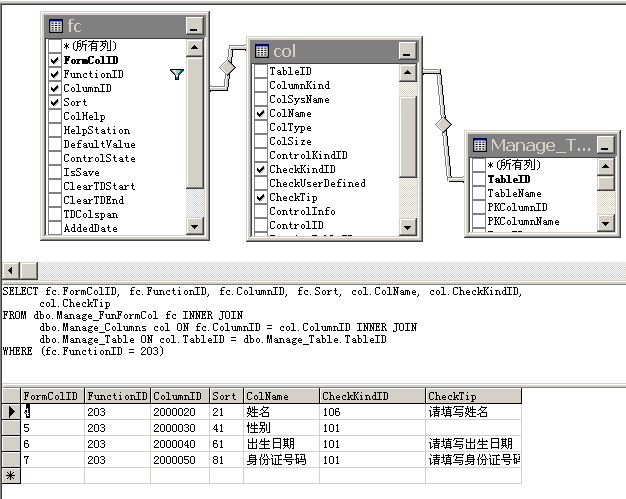
图4,这是一个表里的记录,角色、功能节点与字段编号的关系。