在IIS6下,经常出现w3wp的内存占用不能及时释放,从而导致服务器响应速度很慢。
由于内存释放不及时严重影响到服务器的正常运营,建议采用以下配置,但请考虑自身服务器的使用情况。
可以做以下配置:
1、在IIS中对每个网站进行单独的应用程序池配置。即互相之间不影响。(进程池越多越占用内存,由于访问网站之后往往不会立即释放内存资源。)
2、设置应用程序池的回收时间,默认为1720小时,可以根据情况修改。同时,设置同时运行的w3wp进程数目为1。再设置当内存或者cpu占用超过多少,就自动回收内存 。
3、 设置固定时间加收进程,比如在凌晨1:00至9:00之前访问人数都比较少,影响很少小,可以设定每天在这个时间段内进行内存回收,以减少服务器因为内存 不足带来的影响。设定固定的时间在IIS6中没有限制次数,可以根据实际情况来设定时间比如:晚上12:00,8:00,12:30,6:30等时间段时 间有效的进程池资源回收。
一般来说,这样就可以解决了。但仍然会出现个别网站因为程序问题,不能正确释放。
那么,怎么样才能找到是哪一个网站的?
1、在任务管理器中增加显示pid字段。就可以看到占用内存或者cpu最高的进程pid
2、在命令提示符下运行iisapp -a。注意,第一次运行,会提示没有js支持,点击确定。然后再次运行就可以了。这样就可以看到pid对应的应用程序池
3、到iis中察看该应用程序池对应的网站,就ok了。
Windows Server 2003中的w3wp.exe进程大量占用cpu资源的各种问题解决方法2007-04-
24 14:43这几天服务器总是运行缓慢,远程登录后发现一个w3wp.exe的进程占用了100%
cpu
在Windows Server 2003中对于每一个Web应用,IIS 6.0都用一个独立的w3wp.exe
的实例来运行它。w3wp.exe也称为工作进程(每一个主机头都会有一个)
直接在任务管理器中结束进程是不起作用的,结束后不久它会执行启动,要想结束它可
以在IIS中找到相应的应用程序池停止相应的应用程序池工作。
这些都不是解决办法,它的根本问题是你的那个网站程序有问题,在找到问题以前可以
先打开IIS找到应用程序池先用右键属性中设置“性能”把其中的CPU设成大于60%关闭应
用程序池,把关闭时间和开启时间设短一些比如10秒,这样当您的网站程序大量占用系
统资源时IIS自动快速回收进程并且快速启动进程,您的网站暂时还可以将就着工作。
要解决根本问题还要从程序查起,您可以在IIS中的应用程序池中右键创建多个应用程序
池,然后在每个主机头中的文件家选项的底部将应用程序池对应道刚才建好的应用程序
池,然后一个一个关闭在任务管理器中看看是哪个程序占用的资源较大。
下面是一些网友的相关贴子也许对大家有帮助
朋友的WEB服务器一直运行正常,但这几天CPU占用率一直将近100%,遂去看个究竟。
服务器采用Windows 2003, 网站使用ASP+Access数据库, 查看进程列表发现
w3wp.exe 占用了70%以上的CPU,
查看WEB日志,站点访问量不大,查看TCP连接也不多。用net stop w3svc停掉WEB服
务,CPU占用立即正常,net start w3svc启动WEB后不久现象又出来了。停止所有虚
拟站点,新建一个虚拟站点发现并没有问题,怀疑是站点本身的代码问题。
检查首页代码,大致是如下结构:
粗看一下并没有问题,但就是这段代码造成了w3wp.exe占用大量CPU,难道是死循环?似
乎没有理由。在循环体内加入计数,发现确实是死循环,说明RS.EOF一直为false,加入
如下代码:
if RS.EOF = true then Response.Write "EOF is true"
if RS.EOF = false then Response.Write "EOF is false"
发现输出竟然是EOF is true EOF is false, 说明无法判断RS.EOF的值,
为何如此百思不得其解。检查数据库,发现库中并没有mytable表, 如果该表不存在,
RS.Open "Select * FROM mytable", conn 就会出错,为何没有出错,很
有可能捕获的异常被忽略了。
检查包含文件conn.asp, 发现了异常处理代码:
On Error Resume Next
原来问题在此。
On Error Resume Next忽略了查询表时的失败以及后续的错误,造成进入死循环
。
那为何网站本来运行正常,现在却找不到mytable表了呢?仔细检查网站才发现“有‘客
’自远方来”,上传了后门工具、删除了多张数据表,害我忙活了一天。
更多的内容大家还可以到:
http://www.microsoft.com/china/technet/security/guidance/secmod93.mspx
查找更详细的安全设置
windows2003 iis6.0假死问题解决
这几天服务器总是运行缓慢,远程登录后发现一个w3wp.exe的进程占用了100% cpu。
问题的原因最终找到两个:
1.采用的jet 数据库连接方式存在问题:http://support.microsoft.com/?id=838306
补丁下载:
chs:WindowsServer2003-KB838306-x86-chs.exe
enu:WindowsServer2003-KB838306-x86-enu.exe
2.将access数据库扩展名改为asp
下面是我的差错过程和解决方案:
搜索一下发现类似问题还真不少,那个w3wp的进程是iis6.0的应用程序池,网上的说法
有两种,一是因为asp或者ASP.NET代码中含有死循环引起的。但是服务器上这么多网站
,谁知道那个网站出了问题。二是由于上面的jet连接数据库方式的bug引起的,下载
838306的补丁,或者升级到sp1可以解决这个问题,但是打了这个补丁后,有些网站的问
题依然存在。
又去搜索,有人说将每个网站建立独立的应用程序池,应用程序池的安全性帐户设为本
地服务即可。方法如下:
首先新建应用程序池:
然后将网站的应用程序池指向刚才建立的应用程序池:
在建立完所有应用程序池后,统一修改应用程序池的属性:
将应用程序池安全帐户指定为本地服务:
设置完这些之后,问题依然存在,这样一个网站出现问题,不致影响其他网站,但是这
个网站仍然占用大量资源,导致其它网站响应缓慢。不过在任务管理器中出现了每个应
用程序池的进程,因此可以找到具体出问题的进程了。
下面是寻找出错网站的过程:要找到这个网站,必须把有问题的进程跟该网站的应用程
序池联系起来。首先设置任务管理器的查看方式,加入PID的显示:
然后再命令行运行iisapp -a,可以看到PID跟应用程序池的对应关系:
再去iis中看该应用程序池对应的网站,有问题的网站就找到了,剩下的就是这个网站代
码中的问题了。
在某位网站管理员的纠缠不休下,我终于无法忍受,帮他找错误- – 无数次配置iis
,网站程序也换了,该升级的也升级了,问题还是存在,黔驴技穷,把网站下载到本地
看看到底怎么回事。当我试图打开他的数据库的时候,问题出现了:
他的数据库是.asp的扩展名,要先修改为.mdb才能打开,但是当我点击要改名字的时候
,我的电脑没有响应了~!看来问题在这个数据库了。
用命令行rename之后,打开数据库,修复,似乎没有任何问题,但是再改为.asp时,又
出现了刚才的问题。哈~原来是.asp的扩展名在作怪。
但是我试着将其他的数据库改为.asp,没有问题。根本原因不得而知,望知情者告知。
最后,在iis中随便添加了一个isapi对应到mdb,造成mdb无法执行,防止下载,将所有
的.asp的数据库改回.mdb,问题解决
(转)Windows Server 2003中的w3wp.exe进程大量占用cpu资源的各种问题解决方法 1:使用 MicrosoftJet 数据库引擎 Web 应用程序可能停止响应负载,造成假死:
原因:发生此问题是因为 Jet 数据库引擎中存在缺陷。 Microsoft Windows Server 2003 上只会出现此问题。 在 Windows Server 2003, COM+ 更改频率 CoFreeUnusedLibraries 函数被调用。 此更改导致 Jet 驱动程序以初始化频繁。 此行为可能导致死锁条件。
Web 服务器负载时最常出现此问题。
补丁下载:
chs:WindowsServer2003-KB838306-x86-chs.exe
enu:WindowsServer2003-KB838306-x86-enu.exe
在IIS6下,经常出现w3wp.exe的内存及CPU占用不能及时释放,从而导致服务器响应速度很慢。
解决内存占用过多,可以做以下配置:
1、在IIS中对每个网站进行单独的应用程序池配置。即互相之间不影响。
2、设置应用程序池的回收时间,默认为1720小时,可以根据情况修改。再设置当内存占用超过多少(如500M),就自动回收内存。
解决CPU占用过多:
1、在IIS中对每个网站进行单独的应用程序池配置。即互相之间不影响。
2、设置应用程序池的CPU监视,不超过25%(服务器为4CPU),每分钟刷新,超过限制时关闭。
根据w3wp取得是那个一个应用程序池:
1、在任务管理器中增加显示pid字段。就可以看到占用内存或者cpu最高的进程pid
2、在命令提示符下运行iisapp -a。注意,第一次运行,会提示没有js支持,点击确定。然后再次运行就可以了。这样就可以看到pid对应的应用程序池。(iisapp实际上是存放在 C:\windows\system32目录下的一个VBS脚本,全名为iisapp.vbs,如果你和我一样,也禁止了Vbs默认关联程序,那么就需要 手动到该目录,先择打开方式,然后选“Microsoft (r) Windows Based Script Host”来执行,就可以得到PID与应用程序池的对应关系。)
3、到iis中察看该应用程序池对应的网站,就ok了,做出上面的内存或CPU方面的限制,或检查程序有无死循环之类的问题。
QUOTE:
环境:win2003server+IIs+ASP+MSSQL
现象:每隔一段时间(不定,有时几分钟,有时半小时)出现一次网站打开非常缓慢,甚至有时会出现超时打不开站点,此时查看服务器端的进程,CPU占用率达到100%,其中w3wp占用70~80%,SQL占用20~30%。所有服务器端的操作也变得缓慢。
初 期解决方法:每次现象出现时,立即登录服务器直接结束w3wp进程或重启IIS服务,平均每天约十次操作,由于服务器存放于远程机房,所有操作都是远程控 制进行,有时会因此出现远程无法连接登录的情况,只能通过电话通知机房管理人员重启服务器解决,此过程导致用户抱怨不断。
经过网上查阅资料,发现此类现象多数由于网页代码不合理所致,以下情况会导致此类现象发生:
1、代码中多处使用application、seesion等服务器缓存,导致服务器资料过度占用;
2、代码有不合理语法,死循环等;
3、数据库损坏,尤其是ACCESS数据库;
4、装过多第三方软件或插件,与IIS或网页功能代码冲突。
第一阶段排查:根据查阅到的参考资料逐项分析
1、服务器上所有站点代码均为公司设计人员自行编写,可证实并无过多调用服务器缓存语法(排除)
2、代码是否存在不合理语法(不确定)
3、根据情况来看,IIS进程占用率升高时,SQL占用率同时升高,应为SQL数据库的站点,根据现象判断,库或表应该正常,估计是数据方面可能有误;(不确定)
4、服务器端除了基本的系统服务,防杀毒及网站运作必备服务之外,并无多余第三方软件,机率不大(排除)。
经过以上分析判断,将不确定项连起来得出的结论是:某个采用了SQL数据库的网站网页代码存在不合理语法,导致IIS和SQL进程CPU占用率过高。
第二阶段排查:
确定范围,接着继续把范围缩小。
由于服务器上采用SQL数据库的站点并不多,便于建立独立进程ID来观察,将所有采用SQL数据库的站点在IIS管理器中分别建立独立的应用程序池,然后 通过CMD界面输入:iisapp -a 命今查看并记录下各IIS池的进程ID号,通过多次现象重现时的观察,有个IIS进程ID是导致此次问题的罪魁祸首。
2003服务器用.net程序,w3wp老占cpu资源!怎么办?
w3wp.exe狂占内存的问题解决方案!
问:
好的ASP.NET程序,放在一台服务器上,客户端连接使用一段时间后,在服务器上打开任务管理器一看,发现有很多w3wp.exe,占用内存很大,达到1g,请问为什么会这样?有什么办法可以避免这种情况呢?
答:这主要是你的ASP.NET 开发的程序有 内存泄漏;对于 非托管资源,一定要注意 释放。
-==================================
问:我的具体情况是这样的:
服务器配置 至强2.8G 内存512M SCSI硬盘 2块 (软镜像)
系统 windows 2003
现在挂了一个asp.net开发的网站 访问量不大 但是出现一个 问题就是
每当服务器运行2-3天后 访问网站就特别慢 重启动服务器后就 正常了
查看进程使用内存的情况 发现w3wp.exe 和sqlservr.exe 进程 占用内存
相当大 达到了170多M( 每个) 物理可用内存几乎用光
(服务器重启动时 占用的内存很小才40多M 每个)
以前网站挂在一个虚拟机上 数据库是分开挂的 从没出现这种情况
后来 原版移植到新服务器上就 出现这样的问题~~
还个一问题就是 我在SQL企业管理器中查看SQL进程 发现有很多是 。net 引起的进程是sleeping 但是却占用了内存~ 无法释放
搞了很久了 一直都没解决
求救~~请高手 指教~~ 万分感谢~~~~~
答:IIS服务管理器—-》应用程序池—-》添加你的应用,并设置最大内存,当程序达到最大内存后其会自动重启。
我的问题跟你一样,不过我的内存是2G的,访问量比较高,一般是差不多运行24小时后就得重启,内存没耗完,W3WP进程占到一百八九十兆,SQL占了二百多兆时,就得重启,不然整个站点就当在那边….55555555,搞了快半个月了还是不行,痛苦啊
w3wp.exe 就是你的ASP.NET应用宿主,如果你使用了大量的Session、Cache等资源,并且Session超市时间很长,那么内存占用量就比较大。应用 池是为增加性能而设的一个特性,但是也消耗很大的内存。另外关掉Windows Server 2003里的大多数Service(那个不用都可以关掉),也可以节省一部分内存
1.怀疑在程序中应用的CACHE,
2.CACHE中有大量的数据
3.频繁刷新CACHE
4.没有设计好CACHE的方式
你的问题我以前也遇见过,我以前是用的Session,后我全部改成cook之后就好多了,应该是你的Session或是你的CACHE有问题(CACHE不太懂,但多多少应该是有的)
跟踪下SQL的调用记录,在每次往CACHE或SESSION写入大量数据时记录一下时间,看是否太过频繁
1.在win2003里asp.net的进程就是w3wp.exe
2.512M 内存个人用是够用了,但是放在服务器上就有点不够用了,尤其是win2003 + asp.net +sql server 。尤其是sql server 他是很吃内存的,如果不控制的话,他会占光所有的物理内存(只剩下几十M 倒 100M 吧)。win2003 本身就要占用150M左右。也就剩不下什么了。
3.优化asp.net程序,就向楼上的说的那样,少用或不用session cache application之类的东西,再有就是是不是有翻页的地方,翻页处理不好也是会占很多内存的。
4.限制sql的内存。企业管理器——SQL的属性(一般是local)——“内存”标签
在这里看内存的设置,把最大值改成100M吧。
第四条是最快的方法,可以试一试。
我的一个自开发OA系统也存在这样的问题。
总结上面,大概原因是因为 session 和 cache 的不合理使用造成的。
我的应用程序中,确实用了很多的Session 和 Cache,
在 MSDN 中找到 了 “动态内存分配”这一篇,今天就试看看,是否有效。
希望有经验的朋友多给些信息,大家也好总结下出现类似错误的原因,谢谢!!
不知道你是什么网站。按理说是不会占用这么大的。如上你用了cache存放了超额的内容。当然。象session这种是不太可能占用这么大的了,或用了 application 类似的一些有超长时间或永久保持性的对象来保存大量数据。如利用单例保存数据这些都有可能造成使用大量的内存。
建义2003系统安装至少1G内存。
w3wp.exe是2003下的一个iis进程,至于楼主说的sql占用内存,那有可能是因为你的sql没有设置占用内存上限
-==================================
w3wp.exe进程狂占内存和CPU问题 谁能帮我??
我的电脑:P4,512M内存。。当我用了aspx系统建站两个星期后,就出现了速度极慢的情况,在进程里看到w3wp.exe狂占内存和CPU.
刚开始几十人注册时速度都不会有影响,但注册会员有100名以上后,再有多人同时注册时就出现了速度极慢的情况,简直导致瘫痪。
IIS中设置不正确。在.NET中,不要在IIS里限制内存的使用,不然当内存不足的时候,IIS会不断的重新起动。每次起动有30秒的时候用来重新加 载.NET包,所以,网站在加载.NET 包时狂慢。这也是我当时用.NET系统时碰到过的问题。
应用程序池--属性--回收--内存回收:消耗太多内存时回收工作进程:1、最大虚拟内存。2、最大使用的内存。两个选项都没选择
这里不要打勾。另一处是性能里的请求队列,不要打勾。
自已调调看就有经验了,我也是自已摸索出来的方法。
A:关于W3WP.EXE的知识.
Q : W3WP.EXE,应用程序,应用程序池之间的关系
A : 一个应用程序池可以包含多个应用程序,一个应用程序池创建一个W3WP.EXE进程.那么我们就不能简单的说一个进程池对应一个W3WP.EXE进程了!其实是多个应用进程池对应一个W3WP.EXE进程的.
Q : 如何启动和关闭W3WP.EXE这个进程
A : W3WP.EXE这个进程将在你访问www应用程序的时候启动.有人就会这么问了:"我启动了一个Web应用程序,发现系统自动创建了一个 W3wp.exe进程。但我关闭这个Web应用程序后,发现这个刚创建的W3Wp.exe进程还在,请问如何关闭该进程。"这个进程不会在你关闭了这个程 序以后,就马上关闭的.那是因为Http是无连接的访问,当你关闭了web网页,不会返回相应的关闭信息,所以W3WP.EXE这个进程不会因为你关闭了 web应用程序尔关闭.
Q : 那么如何关闭这个进程呢?
A : 在应用程序池的配置中,"空闲超时"中设定合适的时间,系统默认的是20分钟.设定好指定的时间,那么在这个时间范围内没有在访问应用程序,那么系统会自 动的关闭W3WP.EXE这个进程的.而不需要我们人为的干预的.也可以在Windows任务管理器里面,结束这个进程
Q : 如何让W3WP.EXE进程长时间的运行.
A : W3WP.EXE这个进程的默认生命是1740分钟,但依然是在这种默认的自然规律下,W3WP.EXE将在自己失业20分钟后,被系统直接枪杀.这样就可以看出,要想让W3WP.EXE长时间的生存,那我们可以通过”空闲超时”不作处理来达到我们的目的.
Q : 在IIS6下,经常出现w3wp.exe的内存及CPU占用不能及时释放,从而导致服务器响应速度很慢。
A: 解决内存占用过多,可以做以下配置
1、在IIS中对每个网站进行单独的应用程序池配置。即互相之间不影响。
2、设置应用程序池的回收时间,默认为1720小时,可以根据情况修改。再设置当内存占用超过多少(如500M),就自动回收内存。
解决CPU占用过多:
1、在IIS中对每个网站进行单独的应用程序池配置。即互相之间不影响。
2、设置应用程序池的CPU监视,不超过25%(服务器为4CPU),每分钟刷新,超过限制时关闭。
根据w3wp取得是那个一个应用程序池:
1、在任务管理器中增加显示pid字段。就可以看到占用内存或者cpu最高的进程pid
2、在命令提示符下运行iisapp -a。注意,第一次运行,会提示没有js支持,点击确定。然后再次运行就可以了。这样就可以看到pid对应的应用程序池。(iisapp实际上是存放在 C:\windows\system32目录下的一个VBS脚本,全名为iisapp.vbs,如果禁止了Vbs默认关联程序,那么就需要手动到该目录, 先择打开方式,然后选“Microsoft (r) Windows Based Script Host”来执行,就可以得到PID与应用程序池的对应关系。)
3、到iis中察看该应用程序池对应的网站,就ok了,做出上面的内存或CPU方面的限制,或检查程序有无死循环之类的问题。
A2 : by 小步舞曲
查看占用cpu的w3wp进程里面里面有那个用户呼叫的token
Q : 另一种加载了某程序后发生w3wp.exe问题
A: 修改C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322\CONFIG\machine.config,再配置 节点<processModel>中有一个属性"memoryLimit",这个属性的值是一个百分比,默认为"60"(注意,是60%不是 60M),即制定了ASP.NET进程能够使用所有物理内存的60%,当ASP.NET使用的内存量草果这个限额时,IIS会开始自动回收进程,即创建一 个新的进程去负责应付HTTP请求,而将旧进程所占用的内存回收.

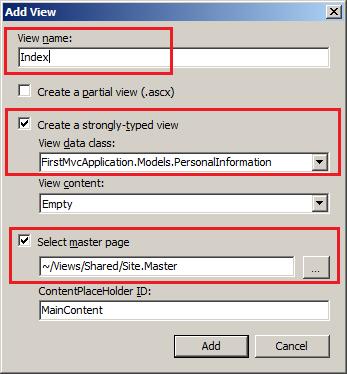






 主要研究技术:代码生成工具、Visio二次开发
主要研究技术:代码生成工具、Visio二次开发