该控件在无限分类应用管理上用的比较多,使用方便,并支持拖拽更新分类层次。


源码下载 (源码内容包括,验证插件,树型表格,树型菜单实例代码)

因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索 引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强。曾经有一次我在JavaEye的 日志里面发现一个User-Agent是Java的爬虫一天之内爬取了将近100万次动态请求。这是一个用JDK标准类库编写的简单爬取网页程序,由于 JavaEye网站内部链接构成了回环导致程序陷入了死循环。对于JavaEye这种百万PV级别的网站来说,这种爬虫造成的访问压力会非常大,会导致网 站访问速度缓慢,甚至无法访问。
此外,相当数量的的网页爬虫目的是盗取目标网站的内容。比方说JavaEye网站就曾经被两个竞争对手网站爬取论坛帖子,然后在自己的论坛里面用机器人发帖,因此这种爬虫不仅仅影响网站访问速度,而且侵犯了网站的版权。
对于一个原创内容丰富,URL结构合理易于爬取的网站来说,简直就是各种爬虫的盘中大餐,很多网站的访问流量构成当中,爬虫带来的流量要远远超过 真实用户访问流量,甚至爬虫流量要高出真实流量一个数量级。像JavaEye网站虽然设置了相当严格的反爬虫策略,但是网站处理的动态请求数量仍然是真实 用户访问流量的2倍。可以肯定的说,当今互联网的网络流量至少有2/3的流量爬虫带来的。因此反爬虫是一个值得网站长期探索和解决的问题。
一、手工识别和拒绝爬虫的访问
有相当多的爬虫对网站会造成非常高的负载,因此识别爬虫的来源IP是很容易的事情。最简单的办法就是用netstat检查80端口的连接:
这行shell可以按照80端口连接数量对来源IP进行排序,这样可以直观的判断出来网页爬虫。一般来说爬虫的并发连接非常高。
如果使用lighttpd做Web Server,那么就更简单了。lighttpd的mod_status提供了非常直观的并发连接的信息,包括每个连接的来源IP,访问的URL,连接状 态和连接时间等信息,只要检查那些处于handle-request状态的高并发IP就可以很快确定爬虫的来源IP了。
拒绝爬虫请求既可以通过内核防火墙来拒绝,也可以在web server拒绝,比方说用iptables拒绝:
直接封锁爬虫所在的C网段地址。这是因为一般爬虫都是运行在托管机房里面,可能在一个C段里面的多台服务器上面都有爬虫,而这个C段不可能是用户宽带上网,封锁C段可以很大程度上解决问题。
有些人提出一种脑残的观点,说我要惩罚这些爬虫。我专门在网页里面设计动态循环链接页面,让爬虫掉进陷阱,死循环爬不出来,其实根本用不着设置陷 阱,弱智爬虫对正常网页自己就爬不出来,这样做多此一举不说,而且会让真正的搜索引擎降低你的网页排名。而且运行一个爬虫根本不消耗什么机器资源,相反, 真正宝贵的是你的服务器CPU资源和服务器带宽,简单的拒绝掉爬虫的请求是反爬虫最有效的策略。
二、通过识别爬虫的User-Agent信息来拒绝爬虫
有很多爬虫并不会以很高的并发连接爬取,一般不容易暴露自己;有些爬虫的来源IP分布很广,很难简单的通过封锁IP段地址来解决问题;另外还有很 多各种各样的小爬虫,它们在尝试Google以外创新的搜索方式,每个爬虫每天爬取几万的网页,几十个爬虫加起来每天就能消耗掉上百万动态请求的资源,由 于每个小爬虫单独的爬取量都很低,所以你很难把它从每天海量的访问IP地址当中把它准确的挖出来。
这种情况下我们可以通过爬虫的User-Agent信息来识别。每个爬虫在爬取网页的时候,会声明自己的User-Agent信息,因此我们就可 以通过记录和分析User-Agent信息来挖掘和封锁爬虫。我们需要记录每个请求的User-Agent信息,对于Rails来说我们可以简单的在 app/controllers/application.rb里面添加一个全局的before_filter,来记录每个请求的User-Agent信 息:
然后统计每天的production.log,抽取User-Agent信息,找出访问量最大的那些User-Agent。要注意的是我们只关注 那些爬虫的User-Agent信息,而不是真正浏览器User-Agent,所以还要排除掉浏览器User-Agent,要做到这一点仅仅需要一行 shell:
统计结果类似这样:
从日志就可以直观的看出每个爬虫的请求次数。要根据User-Agent信息来封锁爬虫是件很容易的事情,lighttpd配置如下:
使用这种方式来封锁爬虫虽然简单但是非常有效,除了封锁特定的爬虫,还可以封锁常用的编程语言和HTTP类库的User-Agent信息,这样就可以避免很多无谓的程序员用来练手的爬虫程序对网站的骚扰。
还有一种比较常见的情况,就是某个搜索引擎的爬虫对网站爬取频率过高,但是搜索引擎给网站带来了很多流量,我们并不希望简单的封锁爬虫,仅仅是希望降低爬虫的请求频率,减轻爬虫对网站造成的负载,那么我们可以这样做:
对百度的爬虫请求延迟10秒钟再进行处理,这样就可以有效降低爬虫对网站的负载了。
三、通过网站流量统计系统和日志分析来识别爬虫
有些爬虫喜欢修改User-Agent信息来伪装自己,把自己伪装成一个真实浏览器的User-Agent信息,让你无法有效的识别。这种情况下我们可以通过网站流量系统记录的真实用户访问IP来进行识别。
主流的网站流量统计系统不外乎两种实现策略:一种策略是在网页里面嵌入一段js,这段js会向特定的统计服务器发送请求的方式记录访问量;另一种 策略是直接分析服务器日志,来统计网站访问量。在理想的情况下,嵌入js的方式统计的网站流量应该高于分析服务器日志,这是因为用户浏览器会有缓存,不一 定每次真实用户访问都会触发服务器的处理。但实际情况是,分析服务器日志得到的网站访问量远远高于嵌入js方式,极端情况下,甚至要高出10倍以上。
现在很多网站喜欢采用awstats来分析服务器日志,来计算网站的访问量,但是当他们一旦采用Google Analytics来统计网站流量的时候,却发现GA统计的流量远远低于awstats,为什么GA和awstats统计会有这么大差异呢?罪魁祸首就是 把自己伪装成浏览器的网络爬虫。这种情况下awstats无法有效的识别了,所以awstats的统计数据会虚高。
其实作为一个网站来说,如果希望了解自己的网站真实访问量,希望精确了解网站每个频道的访问量和访问用户,应该用页面里面嵌入js的方式来开发自 己的网站流量统计系统。自己做一个网站流量统计系统是件很简单的事情,写段服务器程序响应客户段js的请求,分析和识别请求然后写日志的同时做后台的异步 统计就搞定了。
通过流量统计系统得到的用户IP基本是真实的用户访问,因为一般情况下爬虫是无法执行网页里面的js代码片段的。所以我们可以拿流量统计系统记录 的IP和服务器程序日志记录的IP地址进行比较,如果服务器日志里面某个IP发起了大量的请求,在流量统计系统里面却根本找不到,或者即使找得到,可访问 量却只有寥寥几个,那么无疑就是一个网络爬虫。
分析服务器日志统计访问最多的IP地址段一行shell就可以了:
然后把统计结果和流量统计系统记录的IP地址进行对比,排除真实用户访问IP,再排除我们希望放行的网页爬虫,比方Google,百度,微软msn爬虫等等。最后的分析结果就就得到了爬虫的IP地址了。以下代码段是个简单的实现示意:
分析服务器日志里面请求次数超过3000次的IP地址段,排除白名单地址和真实访问IP地址,最后得到的就是爬虫IP了,然后可以发送邮件通知管理员进行相应的处理。
四、网站的实时反爬虫防火墙实现策略
通过分析日志的方式来识别网页爬虫不是一个实时的反爬虫策略。如果一个爬虫非要针对你的网站进行处心积虑的爬取,那么他可能会采用分布式爬取策 略,比方说寻找几百上千个国外的代理服务器疯狂的爬取你的网站,从而导致网站无法访问,那么你再分析日志是不可能及时解决问题的。所以必须采取实时反爬虫 策略,要能够动态的实时识别和封锁爬虫的访问。
要自己编写一个这样的实时反爬虫系统其实也很简单。比方说我们可以用memcached来做访问计数器,记录每个IP的访问频度,在单位时间之 内,如果访问频率超过一个阀值,我们就认为这个IP很可能有问题,那么我们就可以返回一个验证码页面,要求用户填写验证码。如果是爬虫的话,当然不可能填 写验证码,所以就被拒掉了,这样很简单就解决了爬虫问题。
用memcache记录每个IP访问计数,单位时间内超过阀值就让用户填写验证码,用Rails编写的示例代码如下:
这段程序只是最简单的示例,实际的代码实现我们还会添加很多判断,比方说我们可能要排除白名单IP地址段,要允许特定的User-Agent通过,要针对登录用户和非登录用户,针对有无referer地址采取不同的阀值和计数加速器等等。
此外如果分布式爬虫爬取频率过高的话,过期就允许爬虫再次访问还是会对服务器造成很大的压力,因此我们可以添加一条策略:针对要求用户填写验证码 的IP地址,如果该IP地址短时间内继续不停的请求,则判断为爬虫,加入黑名单,后续请求全部拒绝掉。为此,示例代码可以改进一下:
我们可以定义一个全局的过滤器,对所有请求进行过滤,出现在黑名单的IP地址一律拒绝。对非黑名单的IP地址再进行计数和统计:
如果某个IP地址单位时间内访问频率超过阀值,再增加一个计数器,跟踪他会不会立刻填写验证码,如果他不填写验证码,在短时间内还是高频率访问, 就把这个IP地址段加入黑名单,除非用户填写验证码激活,否则所有请求全部拒绝。这样我们就可以通过在程序里面维护黑名单的方式来动态的跟踪爬虫的情况, 甚至我们可以自己写个后台来手工管理黑名单列表,了解网站爬虫的情况。
这个策略已经比较智能了,但是还不够好!我们还可以继续改进:
1、用网站流量统计系统来改进实时反爬虫系统
还记得吗?网站流量统计系统记录的IP地址是真实用户访问IP,所以我们在网站流量统计系统里面也去操作memcached,但是这次不是增加计 数值,而是减少计数值。在网站流量统计系统里面每接收到一个IP请求,就相应的cache.decrement(key)。所以对于真实用户的IP来说, 它的计数值总是加1然后就减1,不可能很高。这样我们就可以大大降低判断爬虫的阀值,可以更加快速准确的识别和拒绝掉爬虫。
2、用时间窗口来改进实时反爬虫系统
爬虫爬取网页的频率都是比较固定的,不像人去访问网页,中间的间隔时间比较无规则,所以我们可以给每个IP地址建立一个时间窗口,记录IP地址最 近12次访问时间,每记录一次就滑动一次窗口,比较最近访问时间和当前时间,如果间隔时间很长判断不是爬虫,清除时间窗口,如果间隔不长,就回溯计算指定 时间段的访问频率,如果访问频率超过阀值,就转向验证码页面让用户填写验证码。
最终这个实时反爬虫系统就相当完善了,它可以很快的识别并且自动封锁爬虫的访问,保护网站的正常访问。不过有些爬虫可能相当狡猾,它也许会通过大 量的爬虫测试来试探出来你的访问阀值,以低于阀值的爬取速度抓取你的网页,因此我们还需要辅助第3种办法,用日志来做后期的分析和识别,就算爬虫爬的再 慢,它累计一天的爬取量也会超过你的阀值被你日志分析程序识别出来。
总之我们综合运用上面的四种反爬虫策略,可以很大程度上缓解爬虫对网站造成的负面影响,保证网站的正常访问。
插件功能给软件的使用者可以扩充软件功能的机会。我们不可能让软件适用于所有人,也不是所有的人都会出资帮助你实现他们的需求。插件功能提供了一个软件的高度可扩充性,允许用户作为软件的二次开发者,继续完善软件的功能。
为了在软件中加入插件功能,我们需要下面几个特别的条件:
(1) 本软件(此后我们称之为‘宿主程序’)需要开放自己的成员,包括属性、方法、事件为插件程序提供服务。
(2) 宿主程序要很好的隐藏一些信息,阻止插件程序有意或无意的破坏本身的功能。
(3) 宿主程序提供插件服务,方便插件功能的升级。
(4) 定义一个统一的标志信息,保证宿主程序可以正常的识别并运行插件程序而不会出现类型安全问题。
为此我们模仿Visual Studio .Net本身提供的Addin的实现机制来实现我们的插件程序。

第一步,制作接口。它是建立在宿主程序和插件之间的桥梁。
首先我们建立一个“插件标识”接口,这个接口用来标识我们的插件类的特性。
Public Interface IPlugins
Sub Connect(ByVal PluginsApp As IPluginsApplication)
End Interface
这个接口里面我们定义了一个方法Connect,用来启动我们的插件程序。也就是说,我们的宿主程序将会统一使用Connect方法启动插件程序。而对于插件程序,入口地址将是Connect方法。这个有点类似于普通应用程序的Main函数。Connect函数的参数IPluginsApplication表示我们宿主程序的实例,稍后将会进一步解释。
其次,我们建立一个“插件服务”接口,这个接口将宿主程序需要开放的属性、方法、实现定义出来,通过接口的方式提供给插件程序。
Public Interface IPluginsApplication
Event Display(ByVal sender As Object, ByVal e As EventArgs)
Property Caption() As String
Sub DisplayInput(ByVal TextAs String)
End Interface
在例子中我们简单定义了一个事件、一个属性和一个方法。插件程序在开发的时候只要引用了我们的“插件服务”接口就可以调用里面定义的内容了。
第二步,建立宿主程序。
但是光有接口是不能执行里面的内容的,必须要有一个实现了这个接口的实例才可以。这里我们让宿主程序实现这个接口,并且实现这些接口里面的内容,让插件程序可以进行操作。
Public Class Form1
Implements PluginsInterface.IPluginsApplication
Public Event Display(ByVal sender As Object, ByVal e As System.EventArgs) Implements PluginsInterface.IPluginsApplication.Display
Public Property Caption() As String Implements PluginsInterface.IPluginsApplication.Caption
Get
Return Me.Text
End Get
Set(ByVal value As String)
Me.Text = value
End Set
End Property
Public Sub DisplayInput(ByVal Text As String) Implements PluginsInterface.IPluginsApplication.DisplayInput
MsgBox("输入内容:" & Text)
End Sub
Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click
RaiseEvent Display(Me, New EventArgs)
Me.DisplayInput(Me.TextBox1.Text)
End Sub
End Class
我们用一个标准的Windows窗体来实现“插件服务”接口的内容。通过Caption属性可以更改窗体的标题,通过DisplayInput方法可以显示字符串。
这样我们的宿主程序由于实现了“插件服务”接口,就可以通过“插件服务”接口来将实例传递进插件程序。我们回到“插件标识”接口的Connect方法,插件的入口函数参数将宿主程序通过“插件服务”接口的实例传递到插件程序内,使得插件程序可以调用宿主程序开放的内容。而且由于通过接口传递,这些操作都是类型安全的。
第三步,寻找并启动插件。
插件程序将会以动态链接库的形式提供,这就需要我们的宿主程序找到插件程序的文件,判断是不是合法的插件,实例化并且启动。
首先我们必须定义一个插件存放的路径,比如运行目录下面的Plugins目录。然后寻找这一目录下面所有的dll文件进行判断。这里我们固定好路径和文件名。
对于找到的文件,通过反射我们就可以得到定义于这个dll文件中的所有类定义信息。通过刚才我们说的“插件标识”接口逐个判断,将实现了“插件标识”接口的类作为我们判断合法的插件类。然后使用实例化方法进行实例化。(注意,我们的插件程序默认一个无参数的实例化方法。)通过强制类型转换,将这个Object的实例转化为我们的“插件标识”接口实例,也就是IPlugins。由于此前我们已经判断过了,这个类实现了“插件标识”接口(也就是IPlugins接口),所以这个转换是安全的。最后通过IPlugins的Connect方法启动接口程序,将宿主程序,也就是我们的窗体实例通过参数传递。(由于我们的窗体已经实现了接口IPluginsApplication,所以这步操作也是安全的。)此后,程序将由插件接管,对于宿主程序,插件和宿主自己同时进行操作。
Dim pobj As PluginsInterface.IPlugins
Private Sub Button2_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button2.Click
Dim ass As Reflection.Assembly = Reflection.Assembly.LoadFile("E:\Visual Sutdio Project 2005\PluginsApplication\Plugins\bin\Debug\Plugins.dll")
Dim t As Type = Nothing
For Each t In ass.GetTypes
If t.IsClass AndAlso t.GetInterface(GetType(PluginsInterface.IPlugins).FullName, True) IsNot Nothing Then
Exit For
End If
Next
If t IsNot Nothing Then
pobj = ass.CreateInstance(t.FullName, True)
pobj.Connect(Me)
End If
End Sub
第四步,制作插件。
将一个类实现“插件标识”接口,用来表示这个类是宿主程序可识别的插件。同时必须实现Connect方法。通过Connect的参数,插件程序可以使用宿主程序通过“插件服务”接口提供的功能。
Public Class Plugins1
Implements PluginsInterface.IPlugins
Private WithEvents m_papp As PluginsInterface.IPluginsApplication
Public Sub Connect(ByVal PluginsApp As PluginsInterface.IPluginsApplication) Implements PluginsInterface.IPlugins.Connect
MsgBox("插件启动成功。")
Me.m_papp = PluginsApp
Me.m_papp.Caption = InputBox("请输入宿主程序的窗体标题")
Me.m_papp.DisplayInput(InputBox("请输入字符串"))
End Sub
Private Sub m_papp_Display(ByVal sender As Object, ByVal e As System.EventArgs) Handles m_papp.Display
Dim f As New Form1
f.ShowDialog()
End Sub
End Class
通过上述方法,我们就制作完成了一个简单的插件。
总结一下:
(1) 通过接口定义插件的标识,进行类型验证并启动插件程序。这样做的好处是统一了插件的类型并且可以安全的进行启动。
(2) 通过接口定义宿主程序希望公开的功能。这样做一方面保证了宿主程序不会被插件程序完全的控制,另一方面让插件程序可以安全的运行宿主提供的方法。缺点是宿主程序如果有多层嵌套的类关系需要开放的话,需要将所有的类都重新通过接口进行封装。
(3) 宿主程序、插件程序引用统一的接口程序,将插件的开发了宿主程序本身脱离,提高宿主的安全性,并且防止了循环引用的发生。
PS:本文所用到的程序代码 pluginsapplication.zip
pluginsapplication.zip
先来看看flash自动生成的网页是如何插入flash文件的:
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="zh_cn" lang="zh_cn">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>test</title>
<scrīpt language="javascrīpt">AC_FL_RunContent = 0;</scrīpt>
<scrīpt src="AC_RunActiveContent.js" language="javascrīpt"></scrīpt>
<style type="text/css">
<!–
body {
background-color: #999900;
}
–>
</style></head>
<body>
<!–影片中使用的 URL–>
<!–影片中使用的文本–>
<!–
eee
–>
<!– saved from url=(0013)about:internet –>
<scrīpt language="javascrīpt">
if (AC_FL_RunContent == 0) {
alert("此页需要 AC_RunActiveContent.js");
} else {
AC_FL_RunContent(
'codebase', 'http://download.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=9,0,0,0',
'width', '550',
'height', '400',
'src', 'test',
'quality', 'high',
'pluginspage', 'http://www.macromedia.com/go/getflashplayer',
'align', 'middle',
'play', 'true',
'loop', 'true',
'scale', 'showall',
'wmode', 'transparent',
'devicefont', 'false',
'id', 'test',
'bgcolor', '#666666',
'name', 'test',
'menu', 'true',
'allowFullScreen', 'false',
'allowscrīptAccess','sameDomain',
'flashvars','txt=wwwww',
'movie', 'test',
'salign', ''
); //end AC code
}
function sendvar(){
test.style.height=500;
test.SetVariable("mv","kkkkkk")
}
</scrīpt>
<noscrīpt>
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://download.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=9,0,0,0" width="550" height="400" id="test" align="middle">
<param name="allowscrīptAccess" value="sameDomain" />
<param name="allowFullScreen" value="false" />
<param name="movie" value="test.swf" /><param name="quality" value="high" /><param name="bgcolor" value="#666666" /><embed src="test.swf" quality="high" bgcolor="#666666" width="550" height="400" name="test" align="middle" allowscrīptAccess="sameDomain" allowFullScreen="false" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" />
</object>
</noscrīpt>
<br>
<label>xxx
<input type="submit" name="Submit" value="提交" ōnClick="sendvar()">
</label>
</body>
</html>
这个网页插入flash共使用了3种方式,应对各种情况,尽可能使swf文件在各种情况、各种浏览器中都能够正常显示运行。
先来看看第一种情况:
最开始使用javascrīpt插入swf文件,这种方式兼容性最好,可以同时兼容IE内核的浏览器及FireFox 浏览器,而且这种插入方式可以避免IE中控件激活框的出现,非常实用。这段自动生成的代码包含的内容很丰富,你可以在其中任意添加IE或者其他浏览器使用 的参数,例如:
'name', 'test',
'id', 'test',
这个是javascrīpt引用swf文件的变量名,使javascrit可以直接对该swf文件进行操作,其中IE只使用id变量就可以了,name变量是针对embed插入方式FireFox使用的。
虽然javascrīpt的插入方式优点多多,但是一旦用户禁用了javascrīpt,就不行了。下面说说第二种方式:
删除所有的javascrīpt代码(同时删除<noscrīpt>和</noscrīpt>)。
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://download.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=9,0,0,0" width="550" height="400" id="test" align="middle">
<param name="allowscrīptAccess" value="sameDomain" />
<param name="allowFullScreen" value="false" />
<param name="movie" value="test.swf" /><param name="quality" value="high" /><param name="bgcolor" value="#666666" />
这是IE使用的flash文件插入方式,如果只使用了这段代码,IE可以正常显示,但是FireFox就不能显示了。
第三种,embed插入方式
<embed src="test.swf" quality="high" bgcolor="#666666" width="550" height="400" name="test" align="middle" allowscrīptAccess="sameDomain" allowFullScreen="false" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" />
这种方式IE和FireFox都可以正常显示
第二种和第三种的参数解释可以参考下面的文章
http://space.flash8.net/space/?246908/action_viewspace_itemid_408019.html
就算不使用javascrīpt,后面两种flash插入方式也可以通过htm页面向flash传递变量:
1、object插入方式:
增加参数:<param name="flashvars" value="mv=hello!">
2、embed插入方式:
在后面加入: flashvars="mv=hello!"
通过以上两种方式,flash都可以收到一个变量名为“mv”的变量,内容为“hello!" 。
作者 Tim Buntel 译者 曹如进
Adobe Flash Builder 4 beta为Flex开发者们,不管是新手还是老手,提供了更多的机会来创建以数据为中心的富互联网应用。这样一个由专业工具,一个开源框架以及无处不在的 客户端所组成的Flash平台,让你能够发布出令人瞠目的表现内容和应用程序。
尽管如此,大多数的应用还依赖于平台之外的服务。也许你的应用程序为企业数据库中存储的信息提供了报表以及数据可视化的功能,抑或你的富电子商务应 用程序需要与现有的订单管理系统,或者第三方的支付服务进行集成。那么你只需要连接到相应的服务器或者服务,这种应用特性就可以使得上述一切像发送电子邮 件般的简单,例如通过使用云托管服务和第三方的API查询数据库等等。
在以往的版本中,开发者必须学会各种技巧手工编写连接服务器和服务的代码。例如,需要知道连接一个SOAP服务使用的MXML标签不同于连接 ColdFusion组件或者PHP类。此外,你通常还得编写一些对于web开发者来说很少见,很困惑的代码,如事件监听和故障处理。
在Flash Builder 4 beta中,Adobe改变了这一切,它采用了一种全新的方式创建以数据为中心的应用程序。新环境下的Flex开发者可以快速的连接到数据和服务,并将它 们绑定到富UI控件上。这些创建面向数据的高级应用的新方法使得经验丰富的开发者们受益匪浅。
使用Flash Builder 4 beta进行以数据为中心的开发主要包括三个步骤:
在这篇文章中,你将会经历创建一个简单数据管理应用的主要步骤。在这个场景中,你有一张Oracle数据库中的表,并想要创建一个Flex应用来允许用户查看它的数据以及新增,更新和删除记录。
为了更好的理解这篇文章,你需要使用下面的软件和文件:
之前有过Flex Builder的使用经验会很有帮助,但这不是必要的。你需要熟悉一种服务端技术例如ColdFusion,Java或者PHP。
由于在Adobe Flash Player中运行的应用程序不能直接与Oracle数据库交互,因此你需要利用一个服务来完成该任务:它可以接受来自Flex发来的请求并传递到数据库 中;还可以将数据库中的数据用一种可理解的格式发回给Flex。这样的远程服务有着相当多的实现方式,在Flash Builder 4 beta中已经内嵌支持了使用ColdFusion,PHP和Java创建服务,而其他类型的服务可以像SOAP web服务或者HTTP服务一样使用。使用ColdFusion是个理想的选择,因为它可以和任何后端数据库交互,且它语法的简单性使得你仅仅需要少量的 标签即可完成创建一个数据接入服务。加之ColdFusion支持一个高性能的名为AMF的协议与Flex应用程序进行数据交换。另外PHP和Java也 同样支持AMF,因此你大可以随心所欲的使用自己最熟悉和认为最高效的服务端技术。
使用ColdFusion,你需要为Flex应用程序执行的每一个数据操作创建一个ColdFusion组件(CFC)函数,如:获取一张表的 所有记录,向表中增加一条新的记录,以及删除一条记录等等。CFC中的函数可以返回弱类型和强类型的数据(例如,如果你正在采用一种更加面向对象的方式进 行开发的话,可以使用getAllRecords函数返回一个ColdFusion的查询对象或者一个对象数组);Flex两种类型的数据都能处理。最后一定要确保cffunction标签的access属性标记为remote后再测试组件。好了,到此为止你已经可以在Flex应用程序中使用这个服务了。
在Flash Builder 4 beta中,新的数据/服务面板位于中心位置,主要是用来管理和交互你的应用程序中使用到的所有服务器和服务。它采用一个树状视图来表示所有服务中可用的 数据和操作。视图中呈现的数据和服务可以来源于不同的地方。例如,其中一个可能是ColdFusion组件或者PHP类,另外一个可能是云托管的第三方 RESTful服务。尽管如此,你不必担心它们在服务端如何实现,因为现在将结果绑定到UI组件、编写代码来调用操作都能统一到一个方法中。
为了让服务得以使用,Flash Builder 4 beta会自动检查内部服务并创建树状视图。在Flash Builder 4 beta中选择数据->连接到ColdFusion(或 者你的服务使用到的技术)。对ColdFusion而言,你只需要简单地提供一个想使用的服务名称(例如,EmployeeSvc),并将它定向到文件系 统中的CFC即可。这一步骤会依服务使用技术的不同而略有变化(例如,你也许会为web服务指定WSDL),但是结果一定是一样的:Flash Builder 4 beta通过在内部检查服务来发现返回的操作和数据类型,继而在数据/服务面板上创建服务的树状视图。
如果有必要的话,你还可以继续向服务树状视图中加入其它服务,或者也可以马上就在应用程序中使用已有的服务。如果服务是弱数据类型,那么需要一个额外的步骤。因为一个弱类型的服务仅返回数据,而没有关于数据所代表含义的信息。
比方说,你的CFC函数返回了一个ColdFusion查询对象,而Flash Builder 4 beta看到的只是一堆记录,它并不知道这些记录代表的是产品集合还是员工集合或是销售订单的集合;这仅仅是一堆数据而已。为了关联操作结果的数据类 型,Flash Builder 4 beta允许你手工配置操作返回的数据类型。当然,如果你在服务端使用强类型的数据类型,这步是可以略去的。
想要设置弱类型服务的返回类型,你可以右键点击数据/服务面板(例如,getAllItems操作),然后选择配置返回类型。向导会帮助你建立服务端弱类型数据与Flex应用程序中的强类型的映射关系。它通过给出一个真实的操作样例数据来让你决定选择什么样的类型。过程中你需要为操作返回的自定义类型指定一个名称,例如可以把返回的每一条记录称为Employee或者SalesOrder,还可以指定数据类型中的字段和格式——如将name的类型设置为string,员工的id设置为数字(见图1)。

图1. 配置操作返回类型
既然你已经定义好了服务中所有的操作以及返回的数据类型,那么现在需要做的就是在应用程序中 的某个地方显示那些操作的结果。Flex框架中包含了大量的控件用以数据绑定,包括数据网格(data grids),列表控件(list boxes),表单域(form fields)等等。这些组件可以显示数据并允许用户与你的服务进行交互。
一开始就在设计视图中对UI进行布局,以及绑定操作到组件上会很简单。只要切换编辑器从源代码视图到设计视图,你就可以从组件面板中拖动组件到应用程序的画布(canvas)上并进行精确定位。
选择DataGrid组件(在组件面板里数据控件组的下面),将它拖放到页面中。你会发现它没有绑定到任何数据;如果运行程序,会发现它仅仅是 一个三列的空网格。为了能够让网格显示从你的服务操作中获取的数据,你只需要简单地将数据/服务面板中的操作拖拽到网格上即可。结束之后你会发现,网格将 会显示从操作返回的列。这时,保存项目,运行,就得到了一个正在使用你的ColdFusion服务填充网格的应用程序。这一切都无需编写任何代码,无需事 先任何事件监听器,无需知道服务端是ColdFusion还是Java或者SOAP。你还可以用很多其他方法来快速创建基于数据类型和服务的应用程序 UI。如可以从一个数据类型生成表单并且创建主从表,可以将一个服务拖拽到按钮组件中,然后每当用户点击这个按钮,就会触发操作的执行(例如,调用保存操 作),还可以将操作拖拽到图表控件上等等。
数据和服务特性并不是仅仅在设计视图中有用。通过使用服务模型生成的子类,你可以获得关于所有操作和数据类型,甚至值对象的自定义行为的代码提示。
Flash Builder 4 beta以数据为中心的新特色功能,可以极大地提高你在创建以数据为中心的应用程序时的生产力。虽然在Flex Builder 3中也可以创建同样的应用,但是要花费更多的精力。这种新的高级数据特性,已经超越了生产力;它们能够让你实现在以前看来极度困难或是不可能的功能。比 如,客户端数据管理特性可以让你将客户端的常见数据服务操作(选择,创建,更新和删除记录)与服务端相应的数据操作进行映射。这将使得你能够批量处理操 作,而撤销功能可以使用户重做一些改变等等。另外一个强大的特性是支持自动分页。如果你要显示大量的记录,那么在应用程序一次性读取和加载它们的时候,会 有性能问题。而分页会自动地每次按需取出一小部分的记录;你需要做的只是提供一个能够接受某行开始以及所需读取的记录数为参数的服务,而Flash Builder 4 beta负责实现客户端的所有逻辑。
不管你是一名经验丰富的Flex开发者还是刚刚接触这个技术的新手,Flash Builder 4 beta都能够让你充分利用已有的服务端数据和服务逻辑知识,轻松的创建富应用开发体验。下载好软件后,今天就可以开始让你的用户看到数据新的呈现方式。 同时也别忘了看看Adobe实验室的视频和教程哦.

Tim Buntel是Flash Builder(以前叫做Flex Builder)的高级产品经理。在2007年加入Flex小组之前,他曾担任多年的Adobe ColdFusion高级产品经理。
在描述这2个强力工具之前,先说一下这两个应用背后的框架,apparat,是一个基于Java构造的开源框架,用于优化SWC和SWF,我们可以从GoogleCode中发现这个不起眼的开源项目(主要是GoogleCode中,项目太多了的缘故):
http://code.google.com/p/apparat/
而基于此框架诞生的2个强力应用工具,第一是TurboDieselSportInjection(名字太长了,连原作者也说他并不善于起名字,简称TDSI)。
它是从整个apparat框架中派生出来的一个针对性工具,允许你链接封装的__bytecode(供AVM解释的机器码)并使用全新内存API的工具。这个工具内置对机器码和Alchemy操作的支持!
第二个工具也很惊奇,叫做Reducer。 这个工具也是从apparat框架中派生出来的,用于优化SWF/SWC文件,主要是让文件尺寸变的更小,但是不影响到组件功能,作者描述到,如果你在 SWF或者SWC中使用PNG图形,实际上对于图形元素,SWF/SWC并不会进行压缩处理。Reducer这个工具就是为了安全的让开发者优化 [Embed]标签并且以后也能正常使用压缩后的元件,它将压缩有所无损的高质量图片以降低文件尺寸。
RSS(Really Simple Syndication,真正简单的连锁)是一种 Web 内容连锁格式。RSS 成为通过 Web 连锁新闻内容的标准格式。刚好我现在vs的环境也是.net,因为在.NET3.5下,MS集成了RSS对象。这样一改变,就很大的方便了创建和读取 RSS了。
首先搞了个Rss.aspx页面,在Page_Load方法里面显示让它以标准的xml格式输出
Response.Cache.SetNoStore();
Response.ContentType = "application/xml";
然后根据需要订阅的页面传过来的参数进行一番判断。把所有符合条件的资源都放在DataTable里面。
接着用MemoryStream对象对xml进行操作,就不多说了,看了代码就会明白,同时也给自己做个备忘。如下:
MemoryStream ms = new MemoryStream();
XmlTextWriter xmlTW = new XmlTextWriter(ms, Encoding.UTF8);
xmlTW.Formatting = Formatting.Indented;
xmlTW.WriteStartDocument();
xmlTW.WriteStartElement("rss");
xmlTW.WriteAttributeString("version", "2.0");
xmlTW.WriteStartElement("channel");
if (WebID == 0)
{
}
else
{
xmlTW.WriteElementString("title", "欢迎订阅"+WebDs.Tables[0].Rows[0] ["Web_Name"].ToString()+">>"+ColumnDs.Tables[0].Rows[0]["ColumnName"].ToString());
xmlTW.WriteElementString("link", ColumnDs.Tables[0].Rows[0]["CoulumnUrl"].ToString());
xmlTW.WriteElementString("description", "");
}
DataTable dt = ds.Tables[0];
foreach (DataRow dr in dt.Rows)
{
xmlTW.WriteStartElement("item");
xmlTW.WriteElementString("title", dr["Article_Title"].ToString());
xmlTW.WriteElementString("link", GetNewsLink(dr));
xmlTW.WriteElementString("pubDate",string.Format("{0:R}",dr["CreateTime"]));
xmlTW.WriteElementString("author", dr["UserLogin_FullName"].ToString());
xmlTW.WriteElementString("description", Pub_Config.nohtml(Pub_Config.Substrin(dr["Article_Body"], 400)));
xmlTW.WriteEndElement();
}
xmlTW.WriteEndElement();
xmlTW.WriteEndElement();
xmlTW.WriteEndDocument();
xmlTW.Flush();
byte[] buffer = ms.ToArray();
Response.Write(Encoding.UTF8.GetString(buffer));
Response.End();
xmlTW.Close();
ms.Close();
ms.Dispose();
要注意的是:
1.XML格式是大小写敏感的,这就意味着,XML元素的起始和终止标签必须匹配,拼写和大小写都必须一致。
2.RSS2.0的根元素是< rss>元素,这个元素可以有一个版本号的属性,例如:
< rssversion="2.0">
…
< /rss>
< rss>元素只有一个子元素< channel>,用来描述聚合的内容。在< channel>元素里面有三个必需的子元素,用来描述Web站点的信息。这三个元素是:
title—定义聚合文件的名称,一般来说,还会包括Web站点的名称;
link—Web站点的URL;
description—Web站点的一段简短的描述。
除此之外,还有一些可选元素来描述站点信息。这些元素的更多信息请参见RSS2.0规范。
每一个新闻项目放在一个单独的< item>元素中。< channel>元素可以有任意数量的< item>元素。每个< item>元素可以有多种的子元素,唯一的要求是最少必须包含< title>元素和< description>元素其中一个作为子元素。以下列出了一些相关的< item>子元素:
title—新闻项目的标题;
link—新闻项目的URL;
description—新闻项目的大纲;
author—新闻项目的作者;
pubDate—新闻项目的发布日期
3.< item>子元素尤其要注意的是pubDate的格式,RSS要求日期必须按照RFC822日期和时间规范进行格式化,此格式要求:开头是一个可选的3字母星期缩写加一个逗号,
.
接着必须是日加上3字母缩写的月份和年份,最后是一个带时区名的时间。
我们可以用Stirng.foemat()来转化如期格式,就如我上面那个例子。
最终结果:

前言:网上有不少文章是讲行转列的,但是大部分都是直接贴代码,忽视了中间过程,本人自己思考了下为什么要这样实现,并且做了如下的笔记,对有些懂的人来说可能没有价值,希望对还不懂的人有一点借鉴意义。
对于有些业务来说,数据在表中的存储和其最终的Grid表现恰好相当于把源表倒转,那么这个时候我们就碰到了如何把行转化为列的问题,为了简化问题,我们且看如下查询出来的数据,您不必关心表的设计以及SQL语句:

假设用到的SQL语句为:
这个表存储了两个人在不同时代(时代是固定的三个:年轻、中年和老年)拥有的金币,其中:
张三在年轻、中年和老年时期分别拥有1000、5000、800个金币;
李四在年轻、中年和老年时期分别拥有1200、6000、500个金币。
现在我们想把两人在不同阶段拥有的金币用类似如下的表格来展现:
| 姓名 | 年轻 | 中年 | 老年 |
| 张三 | 1000 | 5000 | 800 |
| 李四 | 1200 | 6000 | 500 |
我们现在考虑用最简单和直接的办法来实现,其实关键是如何创建那些需要增加的列,且如何设定其值,现在我们来创建“年轻”列,关键的问题是,这一列的值如何设定?合法的逻辑应该是这样:如果该行不是“年轻”时代,那么其“金钱”我们认为是0,那么SQL语句如何写呢?
如果是用的sql server,那么肯定要用到case了:
如果用的是oracle,那么要用到decode函数,decode(1+1,3,'错',2,'是',5,'错','都不满足下返回的值'),这 个函数将返回“是”,具体用法限于篇幅这里不再介绍,相信大家从这个式子可以大概了解到其意思,用decode创建“年轻”列的句子是:完整的sql语句如下所示:
现在我们来看看其执行结果:

相信看到这个结果,大家都知道下一步该做什么,那就是分组:按姓名分组,并且对三个时代的金钱进行求和:
这里用到了子查询,是为了逻辑更清晰一点,其实可以不用子查询;至于oracle下的sql语句,除了要使用decode之外,其余几乎一致,本人正是在oracle中实现之后才研究了下sql server下的实现方式。
最后看看结果:

事实上,当列不固定的时候,比如除了“年轻”、“中年”、“老年”以外还有其他的未知的时代,实现思路其实基本一致,只是需要动态生成sql而已。
原文地址: ASP.NET MVC Action Filter – Caching and Compression
下载源码: Source.zip
关于Action Filter你可以参考我的另外一篇文章: ASP.NET MVC : Action过滤器(Filtering)
缓存在开发高扩充性WEB程序的时候扮演着很重要的角色.我们可以将HTTP请求在一个定义的时间内缓存在用户的浏览器中,如果用户在定义的时间内请求同一个URL,那么用户的请求将会从用户浏览器的缓存中加载,而不是从服务器.你可以在ASP.NET MVC应用程序中使用下面的Action Filter来实现同样的事情:
using System; using System.Web; using System.Web.Mvc; public class CacheFilterAttribute : ActionFilterAttribute { /// <summary> /// Gets or sets the cache duration in seconds. The default is 10 seconds. /// </summary> /// <value>The cache duration in seconds.</value> public int Duration { get; set; } public CacheFilterAttribute() { Duration = 10; } public override void OnActionExecuted(FilterExecutedContext filterContext) { if (Duration <= 0) return; HttpCachePolicyBase cache = filterContext.HttpContext.Response.Cache; TimeSpan cacheDuration = TimeSpan.FromSeconds(Duration); cache.SetCacheability(HttpCacheability.Public); cache.SetExpires(DateTime.Now.Add(cacheDuration)); cache.SetMaxAge(cacheDuration); cache.AppendCacheExtension("must-revalidate, proxy-revalidate"); } }
你可以好像下面一样在你的Controller Action 方法中使用这个Filter :
[CacheFilter(Duration = 60)] public void Category(string name, int? page)
下面是在firebug中当 缓存Filter 没有应用的时候的截图 :

下面的截图是应用了 Cache Filter 时候的截图 :
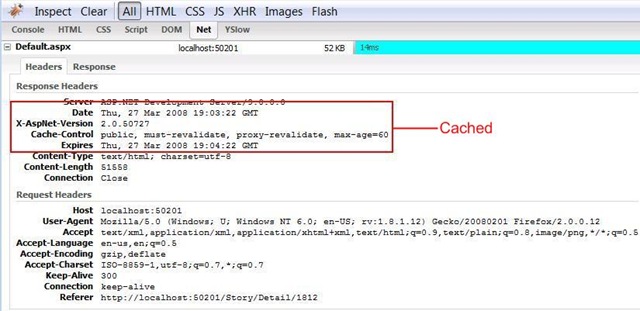
另外一个很重要的事情就是压缩.现在的浏览器都可以接收压缩后的内容,这可以节省大量的带宽.你可以在你的ASP.NET MVC 程序中应用下面的Action Filter 来压缩你的Response :
using System.Web; using System.Web.Mvc; public class CompressFilter : ActionFilterAttribute { public override void OnActionExecuting(FilterExecutingContext filterContext) { HttpRequestBase request = filterContext.HttpContext.Request; string acceptEncoding = request.Headers["Accept-Encoding"]; if (string.IsNullOrEmpty(acceptEncoding)) return; acceptEncoding = acceptEncoding.ToUpperInvariant(); HttpResponseBase response = filterContext.HttpContext.Response; if (acceptEncoding.Contains("GZIP")) { response.AppendHeader("Content-encoding", "gzip"); response.Filter = new GZipStream(response.Filter, CompressionMode.Compress); } else if (acceptEncoding.Contains("DEFLATE")) { response.AppendHeader("Content-encoding", "deflate"); response.Filter = new DeflateStream(response.Filter, CompressionMode.Compress); } } }
然后将这个Filter应用到你的Controller Action 中 :
[CompressFilter] public void Category(string name, int? page)
下面是没有应用压缩的时候的截图 :

下面的截图是应用了压缩Filter后的情形 :
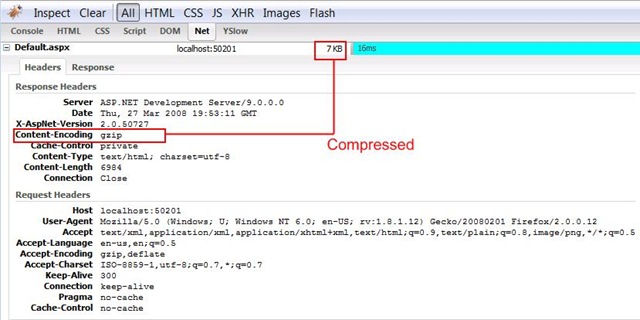
你当然也可以将这两个Filter都应用到同一个Action方法上,就好像下面所示 :
[CompressFilter(Order = 1)] [CacheFilter(Duration = 60, order = 2)] public void Category(string name, int? page)
下面是截图 :
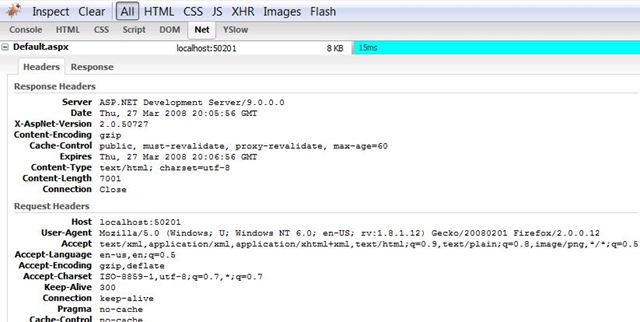
Enjoy!!!
下载源码: Source.zip

实体对象类:
1,使用Find搜索单个匹配值
2,使用FindAll搜索多个匹配值
3,是用Contains检查满足条件的值是否存在
4,使用ForEach 对每个列表对象进行操作
5,使用sort排序,按类别 id排序
