http://www.youku.com/playlist_show/id_2416830.html

[Chrome]Chrome源码刨析
【序】
开源是口好东西,它让这个充斥着大量工业垃圾代码和教材玩具代码的行业,多了一些艺术气息和美的潜质。它使得每个人,无论你来自米国纽约还是中国铁岭,都有机会站在巨人的肩膀上,如果不能,至少也可以抱一把大腿。。。
【一】 Chrome的多线程模型
0. Chrome的并发模型
1. Chrome的线程模型
现在我就是来抱大腿的,这条粗腿隶属于 Chrome(开源项目名称其实是Chromium,本来Chrome这个名字就够晦涩了,没想到它的本名还更上一层楼…),Google那充满狼子 野心的浏览器。每一个含着金勺子出生的人都免不了被仰慕并被唾骂,Chrome也不例外。关于Chrome的优劣好坏讨论的太多了,基本已经被嚼成甘蔗渣 了,没有人愿意再多张一口了。俗话说,内行看门道外行看热闹,大部分所谓的外行,是通过使用的真实感受来评定优劣的,这无疑是最好的方式。但偏偏还是有自 诩的内行,喜欢说内行话办外行事,一看到Chrome用到多进程就说垃圾废物肯定低能。拜托,大家都是搞技术的,你知道多进程的缺点,Google也知 道,他们不是政客,除了搞个噱头扯个蛋就一无所知了,人家也是有脸有皮的,写一坨屎一样的开源代码放出来遭世人耻笑难道会很开心?所谓技术的优劣,是不能 一概而论的,同样的技术在不同场合不同环境不同代码实现下,效果是有所不同的。既然Chrome用了很多看上去不是很美的技术,我们是不是也需要了解一下 它为什么要用,怎么用的,然后再开口说话?(恕不邀请,请自行对号入座…)。。。
人说是骡子是马拉出来遛遛,Google已经把 Chrome这匹驴子拉到了世人面前,大家可以随意的遛。我们一直自诩是搞科学的,就是在努力和所谓的艺术家拉开,人搞超女评委的,可以随意塞着屁眼用嘴 放屁,楞把李天王说是李天后,你也只能说他是艺术品位独特。你要搞科学就不行,说的不对,轻的叫无知,重的叫学术欺诈,结果一片惨淡。所以,既然代码都有 了,再说话,就只能当点心注点意了,先看,再说。。。
我已经开始遛Chrome这头驴了,确切一点, 是头壮硕的肥驴,项目总大小接近2G。这样的庞然大物要从头到脚每个毛孔的大量一遍,那估计不咽气也要吐血的,咱又不是做Code review,不需要如此拼命。每一个好的开源项目,都像是一个美女,这世界没有十全十美的美女,自然也不会有样样杰出的开源项目。每个美女都有那么一两 点让你最心动不已或者倍感神秘的,你会把大部分的注意力都放在上面细细品味,看开源,也是一样。Chrome对我来说,有吸引力的地方在于(排名分先 后…):
1. 它是如何利用多进程(其实也会有多线程一起)做并发的,又是如何解决多进程间的一些问题的,比如进程间通信,进程的开销;
2. 做为一个后来者,它的扩展能力如何,如何去权衡对原有插件的兼容,提供怎么样的一个插件模型;
3. 它的整体框架是怎样,有没有很NB的架构思想;
4. 它如何实现跨平台的UI控件系统;
5. 传说中的V8,为啥那么快。
但Chrome是一个跨平台的浏览器,其Linux和Mac版本正在开发过程中,所以我把所有的眼光都放在了windows版本中,所有的代码剖析都是基于windows版本的。话说,我本是浏览器新手、win api白痴以及并发处理的火星人,为了我的好奇投身到这个溜驴的行业中来,难免有学的不到位看的走眼的时候,各位看官手下超生,有错误请指正,实在看不下去,回家自己牵着遛吧。。。
扯淡实在是个体力活,所以后面我会少扯淡多说问题。。。
关于Chrome的源码下载和环境配置,大家看这里(windows版本),只想强调一点,一定要严格按照说明来配置环境,特别是vs2005的补丁和windows SDK的安装,否则肯定是编译不过的。。。
| 图1 Chrome的线程和进程模型 |
【一】 Chrome的多线程模型
0. Chrome的并发模型
如果你仔细看了前面的图,对Chrome的线程和进程框架应该有了个基本的了解。Chrome有一个主进程,称为Browser进程,它是老大,管理 Chrome大部分的日常事务;其次,会有很多Renderer进程,它们圈地而治,各管理一组站点的显示和通信(Chrome在宣传中一直宣称一个 tab对应一个进程,其实是很不确切的…),它们彼此互不搭理,只和老大说话,由老大负责权衡各方利益。它们和老大说话的渠道,称做 IPC(Inter-Process Communication),这是Google搭的一套进程间通信的机制,基本的实现后面自会分解。。。
|
不论是Browser进程还是Renderer 进程,都不只是光杆司令,它们都有一系列的线程为自己打理各种业务。对于Renderer进程,它们通常有两个线程,一个是Main thread,它负责与老大进行联系,有一些幕后黑手的意思;另一个是Render thread,它们负责页面的渲染和交互,一看就知道是这个帮派的门脸级人物。相比之下,Browser进程既然是老大,小弟自然要多一些,除了大脑般的 Main thread,和负责与各Renderer帮派通信的IO thread,其实还包括负责管文件的file thread,负责管数据库的db thread等等(一个更详细的列表,参见这里),它们各尽其责,齐心协力为老大打拼。它们和各Renderer进程的之间的关系不一样,同一个进程内的线程,往往需要很多的协同工作,这一坨线程间的并发管理,是Chrome最出彩的地方之一了。。。
|
1. Chrome的线程模型
仔细回忆一下我们大部分时候是怎么来用线程的, 在我足够贫瘠的多线程经历中,往往都是这样用的:起一个线程,传入一个特定的入口函数,看一下这个函数是否是有副作用的(Side Effect),如果有,并且还会涉及到多线程的数据访问,仔细排查,在可疑地点上锁伺候。。。
Chrome的线程模型走的是另一个路子,即,极力规避锁的存在。 换更精确的描述方式来说,Chrome的线程模型,将锁限制了极小的范围内(仅仅在将Task放入消息队列的时候才存在…),并且使得上层完全不需要 关心锁的问题(当然,前提是遵循它的编程模型,将函数用Task封装并发送到合适的线程去执行…),大大简化了开发的逻辑。。。
不过,从实现来说,Chrome的线程模型并没有什么神秘的地方(美女嘛,都是穿衣服比不穿衣服更有盼头…),它用到了消息循环的手段。每一个Chrome的线程,入口函数都差不多,都是启动一个消息循环(参见MessagePump类),等待并执行任务。而其中,唯一的差别在于,根据线程处理事务类别的不同,所起的消息循环有所不同。比如处理进程间通信的线程(注意,在Chrome中,这类线程都叫做IO线程,估计是当初设计的时候谁的脑门子拍错了…)启用的是MessagePumpForIO类,处理UI的线程用的是MessagePumpForUI类,一般的线程用到的是MessagePumpDefault类 (只讨论windows, windows, windows…)。不同的消息循环类,主要差异有两个,一是消息循环中需要处理什么样的消息和任务,第二个是循环流程(比如是死循环还是阻塞在某信 号量上…)。下图是一个完整版的Chrome消息循环图,包含处理Windows的消息,处理各种Task(Task是什么,稍后揭晓,敬请期 待…),处理各个信号量观察者(Watcher),然后阻塞在某个信号量上等待唤醒。。。
| 图2 Chrome的消息循环 |
当然,不是每一个消息循环类都需要跑那么一大圈的,有些线程,它不会涉及到那么多的事情和逻辑,白白浪费体力和时间,实在是不可饶恕的。因此,在实现中,不同的MessagePump类,实现是有所不同的,详见下表:
| MessagePumpDefault | MessagePumpForIO | MessagePumpForUI | |
| 是否需要处理系统消息 | 否 | 是 | 是 |
| 是否需要处理Task | 是 | 是 | 是 |
| 是否需要处理Watcher | 否 | 是 | 否 |
| 是否阻塞在信号量上 | 否 | 是 | 是 |
2. Chrome中的Task
从上面的表不难看出,不论是哪一种消息循环,必须处理的,就是Task(暂且遗忘掉系统消息的处理和Watcher,以后,我们会缅怀它们的…)。刨去其它东西的干扰,只留下Task的话,我们可以这样认为:Chrome中的线程从实现层面来看没有任何区别,它的区别只存在于职责层面,不同职责的线程,会处理不同的Task。最后,在铺天盖地西红柿来临之前,我说一下啥是Task。。。
简单的看,Task就是一个类,一个包含了 void Run()抽象方法的类(参见Task类…)。一个真实的任务,可以派生Task类,并实现其Run方法。每个MessagePump类中,会有一个 MessagePump::Delegate的类的对象(MessagePump::Delegate的一个实现,请参见MessageLoop 类…),在这个对象中,会维护若干个Task的队列。当你期望,你的一个逻辑在某个线程内执行的时候,你可以派生一个Task,把你的逻辑封装在 Run方法中,然后实例一个对象,调用期望线程中的PostTask方法,将该Task对象放入到其Task队列中去,等待执行。我知道很多人已经抄起了 板砖,因为这种手法实在是太常见了,就不是一个简单的依赖倒置,在线程池,Undo\Redo等模块的实现中,用的太多了。。。
但,我想说的是,虽说谁家过年都是吃顿饺子,这饺子好不好吃还是得看手艺,不能一概而论。在Chrome中,线程模型是统一且唯一的,这就相当于有了一套标准,它需要满足在各个线程上执行的几十上百种任务的需求,因此,必须在灵活行和易用性上有良好的表现,这就是设计标准的难度。为了满足这些需求,Chrome在底层库上做了足够的功夫:
- 它提供了一大套的模板封装(参见task.h),可以将Task摆脱继承结构、函数名、函数参数等限制(就是基于模板的伪function实现,想要更深入了解,建议直接看鼻祖《Modern C++》和它的Loki库…);
- 同时派生出CancelableTask、ReleaseTask、DeleteTask等子类,提供更为良好的默认实现;
- 在消息循环中,按逻辑的不同,将Task又分成即时处理的Task、延时处理的Task、Idle时处理的Task,满足不同场景的需求;
- Task派生自tracked_objects::Tracked,Tracked是为了实现多线程环境下的日志记录、统计等功能,使得Task天生就有良好的可调试性和可统计性;
这一套七荤八素的都搭建完,这才算是一个完整的Task模型,由此可知,这饺子,做的还是很费功夫的。。。
3. Chrome的多线程模型
工欲善其事,必先利其器。Chrome之所以费了老鼻子劲去磨底层框架这把刀,就是为了面对多线程这坨怪兽的时候杀的更顺畅一些。在Chrome的多线程模型下,加锁这个事情只发生在将Task放入某线程的任务队列中,其他对任何数据的操作都不需要加锁。当然,天下没有免费的午餐,为了合理传递Task,你需要了解每一个数据对象所管辖的线程,不过这个事情,与纷繁的加锁相比,真是小儿科了不知道多少倍。。。
|
|
| 图3 Task的执行模型 |
如果你熟悉设计模式,你会发现这是一个Command模式, 将创建于执行的环境相分离,在一个线程中创建行为,在另一个线程中执行行为。Command模式的优点在于,将实现操作与构造操作解耦,这就避免了锁的问 题,使得多线程与单线程编程模型统一起来,其次,Command还有一个优点,就是有利于命令的组合和扩展,在Chrome中,它有效统一了同步和异步处理的逻辑。。。
|
在一般的多线程模型中,我们需要分清楚啥是同步 啥是异步,在同步模式下,一切看上去和单线程没啥区别,但同时也丧失了多线程的优势(沦落成为多线程串行…)。而如果采用异步的模式,那写起来就麻烦 多了,你需要注册回调,小心管理对象的生命周期,程序写出来是嗷嗷恶心。在Chrome的多线程模型下,同步和异步的编程模型区别就不复存在了,如果是这 样一个场景:A线程需要B线程做一些事情,然后回到A线程继续做一些事情;在Chrome下你可以这样来做:生成一个Task,放到B线程的队列中,在该 Task的Run方法最后,会生成另一个Task,这个Task会放回到A的线程队列,由A来执行。如此一来,同步异步,天下一统,都是Task传来传 去,想不会,都难了。。。
|
|
| 图4 Chrome的一种异步执行的解决方案 |
4. Chrome多线程模型的优缺点
一直在说Chrome在规避锁的问题,那到底锁 是哪里不好,犯了何等滔天罪责,落得如此人见人嫌恨不得先杀而后快的境地。《代码之美》的第二十四章“美丽的并发”中,Haskell设计人之一的 Simon Peyton Jones总结了一下用锁的困难之处,我罚抄一遍,如下:
- 锁少加了,导致两个线程同时修改一个变量;
- 锁多加了,轻则妨碍并发,重则导致死锁;
- 锁加错了,由于锁和需要锁的数据之间的联系,只存在于程序员的大脑中,这种事情太容易发生了;
- 加锁的顺序错了,维护锁的顺序是一件困难而又容易出错的问题;
- 错误恢复;
- 忘记唤醒和错误的重试;
- 而最根本的缺陷,是锁和条件变量不支持模块化的编程。比如一个转账业务中,A账户扣了100元钱,B账户增加了100元,即使这两个动作单独用锁保护维持其正确性,你也不能将两个操作简单的串在一起完成一个转账操作,你必须让它们的锁都暴露出来,重新设计一番。好好的两个函数,愣是不能组在一起用,这就是锁的最大悲哀;
通过这些缺点的描述,也就可以明白Chrome多线程模型的优点。它解决了锁的最根本缺陷,即,支持模块化的编程,你只需要维护对象和线程之间的职能关系即可,这个摊子,比之锁的那个烂摊子,要简化了太多。对于程序员来说,负担一瞬间从泰山降成了鸿毛。。。
而Chrome多线程模型的一个主要难点,在于线程与数据关系的设计上,你需要良好的划分各个线程的职责,如果有一个线程所管辖的数据,几乎占据了大半部分的Task,那么它就会从多线程沦为单线程,Task队列的锁也将成为一个大大的瓶颈。。。
|
从根本上来说,Chrome的线程模型解决的是 并发中的用户体验问题而不是联合工作的问题(参见我前面喷的“闲话并发”),它不是和Map/Reduce那样将关注点放在数据和执行步骤的拆分上,而是 放在线程和数据的对应关系上,这是和浏览器的工作环境相匹配的。设计总是和所处的环境相互依赖的,毕竟,在客户端,不会和服务器一样,存在超规模的并发处理任务,而只是需要尽可能的改善用户体验,从这个角度来说,Chrome的多线程模型,至少看上去很美。。。
[Django]翻译www.djangobook.com之第二章:Django快速上手
The Django Book 第2章:Django快速上手
revised by xin_wang
谢天谢地,安装Django非常容易。因为Django可以运行在任何可以运行Python的环境中,所以可以以多种方式进行配置。
在本章我们将尝试覆盖几种常见的Django安装场景。
安装Python
Django是以100%纯Python代码写就,所以你需要安装Python,Django要求安装Python2.3或更高版本。
如果你使用Linux或者MacOSX,你可能已经安装了Python
在命令行或者终端下输入“python”,如果出现类似如下提示,表示Python已经安装好了:
Python 2.4.1 (#2, Mar 31 2005, 00:05:10)
[GCC 3.3 20030304 (Apple Computer, Inc. build 1666)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
否则,出现错误提示“command not found”
你可以到http://www.python.org/download/下载Python安装
安装Django
安装官方发布版本的Django
到http://www.djangoproject.com/download/下载tarball的Django-*.tar.gz
Java代码 
- tar xzvf Django-*.tar.gz
- cd Django-*
- sudo python setup.py install
Windows下安装则是直接解压Django-*.tar.gz并运行python setup.py install
安装完以后,在Python交互环境下应该可以import django模块
Java代码
- >>> import django
- >>> django.VERSION
- (1, 0, 'official')
Python交互环境是一个命令行程序,在命令行下运行“python”即可进入交互环境
在这本书里,我们将会演示一些Python代码例子,这些例子看起来像是在交互环境里面输入的。
Python交互环境的提示符是三个大于号(>>>)
从Subversion安装Django
如果你想安装Django最新代码或者你想向Django贡献代码,你应该从Django的Subversion repository安装
Subversion是一个与CVS类似的开源版本控制系统,Django团队使用它来管理Django代码的变化。
你可以随时使用Subversion客户端获取最新的Django源代码,或者更新你本机Subversion工作拷贝"local checkout"中的
Django代码来获得Django开发人员所作的最新修改和增强。
最新的Django开发代码称为“the trunk”
得到最新的Django trunk:
1,确认你安装了Subversion客户端,下载地址为http://subversion.tigris.org
Subverion的文档http://svnbook.redbean.com
2,运行如下命令得到trunk“svn co http://code.djangoproject.com/svn/django/trunk django_src”
3,符号链接django_src/django来让django在你的Python site-packages目录下,或者更新PYTHONPATH指定它
从Subversion安装不需要运行“python setup.py install”
Django trunk经常更新bug fixs和增加feature,你可能要频繁更新它
在django_src目录下运行“svn update”即可更新代码
建立数据库
Django仅有的先决条件就是安装Python,但是本书关注Django引以为傲的众多优点之一,开发支持数据库的Web站点
所以你需要安装一个数据库服务器来存储数据
如果你只是想浅尝辄止,可以跳过这一步直接开始一个项目,可是请相信我们:你最终还是会装一个数据库,因为本书的
所有例子都假设你已经拥有一个数据库
Django1.0支持5个数据库引擎:
PostgreSQL(http://www.postgresql.org/)
SQLite 3(http://www.sqlite.org/)
MySQL(http://www.mysql.com/)
Microsoft SQL Server(http://www.microsoft.com/sql/)
Oracle(http://www.oracle.com/database/)
我们自己特别喜欢PostgreSQL,所以我们最先提到它
尽管如此,所有的这些数据库都在Django上工作得都很好
SQLite也值得特别注意,它是一个非常简单的数据库引擎,不需要任何服务器安装和配置
如果你只是想玩玩Django的话,SQLite是最容易安装的
使用PostgrSQL来和Django工作
如果你用PostgreSQL,你需要psycopg包,从http://initd.org/projects/psycopg1可以得到
确认你使用版本1而不是版本2,2还是beta版
如果你在Windows上使用PostgreSQL,可以从如下地址下载已经编译好的二进制psycopg
http://stickpeople.com/projects/python/win-psycopg/
使用SQLite 3来和Django工作
你需要SQLite 3而不是SQLite 2,从http://initd.org/tracker/pysqlite下载pysqlite
确认下载pysqlite的版本为2.0.3及以上
使用MySQL来和Django工作
Django需要MySQL版本4.0及以上,3.x版本不支持事务、嵌套存储过程以及其它标准SQL语句
你也需要MySQLdb包,下载地址http://sourceforge.net/projects/mysql-python
使用MSSQL来和Django工作
使用Oracle来和Django工作
不使用数据库来和Django工作
就像刚刚提到的,Django实际上不需要数据库
如果你仅仅希望Django来提供动态网页而不触及数据库也是可以的
和Django绑定的一些额外的工具需要数据库,如果你选择不使用数据库,你会错失那些特性
开始一个项目
如果这是你第一次使用Django,你必须注意一些初始化过程
运行“django-admin.py startproject mysite”将会在你的当前目录下创建一个mysite目录
注意,如果你使用setup.py安装Django,django-admin.py应该在你的PATH系统变量下
如果不在PATH里面,你可以从site-packages/django/bin找到它
考虑符号链接它到你的PATH里面,例如/usr/local/bin
一个项目就是一个Django实例的设置的集合,包括数据库配置、Django的专有设置以及应用程序专有设置
让我们看看startproject创建了什么:
/mysite/
__init__.py
manage.py
settings.py
urls.py
这些文件的说明如下:
manage.py
一个命令行工具,可以让你以多种方式与Django项目交互
setting.py
Django项目的配置
urls.py
Django项目的URL定义
如果你使用PHP,你可能习惯于将代码放在Web服务器的document root下,如/var/www
使用Django的话不要这样做,将Python代码放在document root下不是一个好主意
因为这样的话人们可能从Web看到你的代码,这并不安全
把你的代码放在document root以外的目录,如/home/mycode
开发用服务器
切换到mysite目录,运行“python manage.py runserver”,你将看到如下信息
Validating models…
0 errors found.
Django version 1.0, using settings 'mysite.settings'
Development server is running at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
这样你就启动了Django开发用服务器,这是一个包含在Django中的开发阶段使用的轻量级Web服务器
我们在Django中包含了这个服务器是为了快速开发,这样在产品投入应用之前,就可以不用处理生产环境中
web server的配置工作了。
这个服务器查看你的代码,如果有改动,它自动reload,让你不需重启快速修改你的项目
虽然这个开发用服务器对于开发来说简直棒透了,还是请克制一下把它用在任何形式的生产环境中的冲动。
这个服务器一次只能可靠地处理一个请求,而且根本没有经过任何安全性的检验
如果你的站点需要上线,请参考第21章的关于部署Django程序的介绍
默认情况下runserver命令启动服务器的端口为8000,只监听本地连接
如果你希望改变端口,增加一个命令行参数即可
python manage.py runserver 8080
你也可以改变服务器监听的IP地址,当你同其它开发者分享一个开发站点时很有用
python manage.py runserver 0.0.0.0:8080
上面的命令使得Django监听任何网络接口,这样的话就允许其它计算机连接该服务器
试着访问http://127.0.0.1:8000/,你将会看到“Welcome to Django”的页面
下一步是什么?
我们已经安装好一切的东西并且让服务器运行了,让我们写一点基本代码来展示怎样使用Django提供动态页面
[Python]Python的web框架汇总
1.Snakelets
Snakelets 是一个 Python 编写的web server,从我了解的j几种 web framework 来讲,我认为snakelet功能似乎更强,它是一个象servlet的一个东西,许多东西已经做好了,象模板,用户认证(提供多种方式)等,看了那个Frog,我还是很喜欢他的,小研究了一下他的代码,发现实在有点复杂,不容易明白,目前没有一个合适的入门教材,而且本身有些复杂,所以处于放弃状态~
2.Django
Django是一个高级 Python web framework,它鼓励快速开发和干净的、MVC设计。它包括一个模板系统,对象相关的映射和用于动态创建管理界面的框架。
他没发布之前就已经吸引了不少人了, 比以前的,更加注重整体设计
特性介绍:
对象相关的映射
完全在Python中定义你的数据模型。你可以免费得到一个丰富的,动态访问数据库的API--但如果需要你仍然可以写SQL语句。
URL 分发
URL的设计漂亮,cruft-free,没有框架的特定限定。象你喜欢的一样灵活。
模版系统
使用DjanGo强大而可扩展的模板语言来分隔设计、内容和Python代码。
Cache系统
可以挂在内存缓冲或其它的框架实现超级缓冲 -- 实现你所需要的粒度。
自动化的管理界面
不需要你花大量的工作来创建人员管理和更新内容的接界。DjanGo可以自动完成。
支持多种数据库
已经支持PostgreSQL, MySQL, Sqlite3
我倾向使用他,但是很遗憾没调试成功~ ![]()
3.Karrigell
作 为简单web开发解决, Karrigell已经包含了web服务,Python 脚本引擎,和 100% 纯Python的数据库: KirbyBase ; 你所要关心的就是创建自个儿的动态web 应用. 这个是我目前主要研究的对象,因为DjanGo没有运行成功,而据介绍Karrigell也是一个非常优秀的 web framework 框架.现在环境设置成功了,如果可以,就可以开始入门学习了~
karrigell是利用mod_python与 apache集成,不需要再运行自已的server,Karrigell不需要挂接处理。写一个.py, .hip, .pih,.ks都是可以的。.py就是普通的python程序,print的结果会作为结果输出。.hip就是Html in Python ,与.py有些象,但在 Python 顶层可以直接以字符串形式写html的代码。.pih就是Python in Html,与其它的 Python Html 模板很象,就是在 Html 模板中嵌入 Python 程序。使用<% %>来包括。.ks就是Karrigell Service,它与 CherryPy 中的方法发布有些象,但不用设置哪个方法需要发布,也不是类的写法,只是函数的写法。
4.Quixote
快速进入 无畏的骑士! 豆瓣 的主要动力系统!正因为这个,我对他的关注也多了很多~
这个框架目前国内使用的人不多,但是豆瓣正是使用了他而成功的,目前这个框架我还没开始尝试
下面有一些资料可以帮你了解他~
http://quixote.ca/
http://www.mems-exchange.org/software/quixote/apps.html
其实Python的Web 开发框架还有很多,象TurboGears ,但我目前接触的比较多的就这几个,其他的在啄木鸟社区还有很多介绍,感兴趣的,可以自己去看看,也欢迎大家能推荐一些比较好用的Web 开发框架介绍,和使用经验,共同体验python的开发乐趣~
[DB4O]db4objects 7.4应用笔记
db4o是面向对象的数据库,复杂应用就不说了,说点简单的。
数据库嘛,简单的操作就是添加,删除,更新和查询。
1、添加
添加非常简单:
先建一个需要存储的对象
public class Model { public int ID { get; set; } public string Name { get; set; } public override string ToString() { return string.Format("ID:{0} , Name:{1}", ID, Name); } }
在进行存储操作
using (IObjectContainer db = Db4oFactory.OpenFile("d:\\d.dat")) { db.Store(new Model() { ID = 1, Name = "Test" }); }
或者
IObjectContainer db = Db4oFactory.OpenFile("d:\\d.dat"); db.Store(new Model() { ID = 1, Name = "Test" }); db.Dispose();
2、更新
更新操作就有一个引用的概念。怎么确定是删除的对象,在db4o中是通过ObjectRefence来操作的。对象的指向一定要正确啦。所以虽然也是用Store方法进行更新操作,但是,不能直接更新。比如对于上面添加的一条记录使用
IObjectContainer db = Db4oFactory.OpenFile("d:\\d.dat");
db.Store(new Model() { ID = 1, Name = "Test" });
db.Dispose();
db.Store(new Model() { ID = 1, Name = "Test" });
db.Dispose();
并不会更新,而是一个添加操作。而下面的操作也无法更新:
using (IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName))
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
db.Store(new Model() { ID = 1, Name = "Test2" });
}
}
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
db.Store(new Model() { ID = 1, Name = "Test2" });
}
}
需要更新引用才可以。因此要写成:
using (IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName))
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
((Model)list[i]).Name = "Test2";
db.Store(list[i]);
}
}
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
((Model)list[i]).Name = "Test2";
db.Store(list[i]);
}
}
在循环中list[i]是无法直接赋值的。不能像下面那样用:
using (IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName))
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
list[i] = new Model() { Name = "tttttt", ID = 2 };
db.Store(list[i]);
}
}
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
list[i] = new Model() { Name = "tttttt", ID = 2 };
db.Store(list[i]);
}
}
可以给Model对象添加一个方法:
public class Model
{
public int ID { get; set; }
public string Name { get; set; }
{
public int ID { get; set; }
public string Name { get; set; }
public void SetValue(Model model)
{
this.ID = model.ID;
this.Name = model.Name;
}
{
this.ID = model.ID;
this.Name = model.Name;
}
public override string ToString()
{
return string.Format("ID:{0} , Name:{1}", ID, Name);
}
}
{
return string.Format("ID:{0} , Name:{1}", ID, Name);
}
}
然后使用:
using (IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName))
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
((Model)list[i]).SetValue(new Model() { Name = "tttttt", ID = 2 });
db.Store(list[i]);
}
}
{
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
((Model)list[i]).SetValue(new Model() { Name = "tttttt", ID = 2 });
db.Store(list[i]);
}
}
当然,也可以像下面一样用:
IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName);
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
((Model)list[i]).SetValue(new Model() { Name = "tttttt", ID = 2 });
db.Store(list[i]);
}
db.Dispose();
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
for (int i = 0; i < list.Count; i++)
{
((Model)list[i]).SetValue(new Model() { Name = "tttttt", ID = 2 });
db.Store(list[i]);
}
db.Dispose();
3、删除
删除和更新差不多,也需要删除引用,可以有下面两种用法。
using (IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName)) { IObjectSet list = db.QueryByExample(new Model() { ID = 1 }); for (int i = 0; i < list.Count; i++) { db.Delete(list[i]); } }
或者
IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName); IObjectSet list = db.QueryByExample(new Model() { ID = 1 }); for (int i = 0; i < list.Count; i++) { db.Delete(list[i]); } db.Dispose();
4、查询
更新和删除实际上已经用了查询,查询语句可以写成:
using (IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName)) { IObjectSet list = db.QueryByExample(new Model() { ID = 2 }); for (int i = 0; i < list.Count; i++) { Console.WriteLine(((Model)list[i]).ToString()); } }
或者
IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName); IObjectSet list = db.QueryByExample(new Model() { ID = 1 }); for (int i = 0; i < list.Count; i++) { Console.WriteLine(list[i].ToString()); } db.Dispose();
上面是根据对象查的。下面根据是按类型,用到的方法是Query。
IObjectContainer db = Db4oFactory.OpenFile(Util.YapFileName); IList<Model> list = db.Query<Model>(typeof(Model)); for (int i = 0; i < list.Count; i++) { Console.WriteLine(list[i].ToString()); } db.Dispose();
把所有的Model类型的数据都查询出来了就。
5、简单讲解
查询的时候,比如
IObjectSet list = db.QueryByExample(new Model() { ID = 1 });
是查找所有ID为1的Model类型的数据。
如果要查找Name为“123”就写成:
IObjectSet list = db.QueryByExample(new Model() { Name = "123" });
6、封装
下面给两个操作的封装类:
对象封装
或者
注意,以上两个封装并没有封装更新的方法,更新的时候需要新查询数据然后再更新。
[Flash]Adobe CS4 发布

来看官网的中文介绍吧 ![]()
http://www.adobe.com/cn/products/creativesuite/
Flash CS4 新功能:
http://www.adobe.com/cn/products/flash/features/?view=topnew
[HTML]Pre标签自动换行
pre标签会原样保留HTML内容的格式,可是如果宽度过大会把页面撑坏,这时候需要自动换行来帮忙:
Wrapping the pre tag
Making preformated text wrap in CSS3, Mozilla, Opera and IEis the tip that let's you use the pre tag to keep the formatting, without cursing yourself when some of the content is too long and doesn't wrap:
/* Browser specific (not valid) styles to make preformatted text wrap */ pre { white-space: pre-wrap; /* css-3 */ white-space: -moz-pre-wrap; /* Mozilla, since 1999 */ white-space: -pre-wrap; /* Opera 4-6 */ white-space: -o-pre-wrap; /* Opera 7 */ word-wrap: break-word; /* Internet Explorer 5.5+ */ }父标记最好加个DIV,并设置CSS属性:word-wrap: break-word;white-space : normal;
[OO]深入理解面向对象软件设计(一) —— 从具体例子谈起
java和C#通常被认为是完全面向对象的语言,所有基本代码必须写在某个类中。但是,很多java和C#程序员编写的代码并不是真正面向对象的。有这种事?确实有,面向对象的编程语言只是提供了封装、继承和多态的机制,并不能保证我们用它写出的程序是面向对象的,即使我们把“人”和“狗”的代码糅合在一起,也不会导致编译和运行出错,我们来看一个c#编写的“人与狗的故事”:
class Program { static void Main(string[] args) { Story story = new Story(); Console.WriteLine(story.GetStory1()); Console.Read(); } } public class Story { private string dogName = "Aliths";//狗的名字 private string masterName = "Peter";//狗主人的名字 private string masterBabyName = "Jim";//狗主人的baby的名字 private string friendA = "Borbo";//A朋友的名字 private string babyA = "LiLy";//A朋友的baby的名字 public string GetStory1() { StringBuilder storyStr = new StringBuilder(" 人与狗的故事\r\n\r\n"); storyStr.Append(string.Format(" 傍晚,{0}带着儿子{1}和爱犬{2}出门散步," , masterName, masterBabyName, dogName)); storyStr.Append(string.Format("遇到了熟人{0},{0}带着女儿{1}在玩。\r\n" , friendA, babyA)); storyStr.Append(string.Format(" {0}将{1}和{2}交给{3}照看," , masterName, masterBabyName, dogName, friendA)); storyStr.Append("自己去附近商店买烟。"); storyStr.Append(string.Format("这时{0}咬了{1}。{1}大哭,{2}气得遍地找板儿砖," , dogName, babyA, friendA)); storyStr.Append(string.Format("然后一板儿砖下去将{0}拍得满地找牙。\r\n" , dogName)); //…… storyStr.Append(string.Format("\r\n\r\n……")); return storyStr.ToString(); } }
这段代码包含两个类Program和Story,单纯从语言层面讲,是面向对象的。但Story中把故事、狗和多个人等的代码糅合在一起(如果故事情节涉 及板砖和商店的细节,还会更乱,而且不仅用到人的名字,还有年龄穿着等,故事有时间地点等等,为例子简单,没有提及),称为面向对象的设计,完全说不过 去。
如果需求不发生变化,这段代码不会有太大问题,没必要把类分的那么清楚。但需求还是变了,要求增加一个故事二:狗主人在另一天出门时遇到了朋友B,给B讲述了发生在前几天的故事一,并且讲述中他添油去醋,并没有按故事一的实际情节讲,我们来看代码:
这时代码已经变得无法忍受了,如果需求再变,不堪设想。也许有的朋友要说,需求不至于一直变吧,我想说:需求不变才不正常,因为需求是人类思想的反映,人的想法是不断变化的,整个世界也在变化。高楼大厦之所以没有经常拆了重建,并不是人们对它满意,而是反复拆建需要大量时间和金钱。而 软件相对于建筑来说,只有设计过程(写文档和编码都是设计),没有建造过程,真正的建造过程是在代码写完后由计算机瞬间完成(编译成二进制exe、 dll),所以人们只要不满意就可能让它“重建”。可以设想一下,假如代码完成后要由人工打纸带(像最初的程序,0打孔,1不打)来编译,或许随便找一个 B/S程序够一个人打几年的,这时需求还是会变,但不会要求程序员去修改了——将就着用吧,不然就洗洗睡先。
认同了需求是变化的,就要找办法解决问题,面向对象相对于面向过程的主要优势之一就在应对变化上,可能也是面向对象在系统软件开发方面流行的主要原因。上述代码有些过于初级,有一定经验的程序员可能会把代码写成这样:

Story有发生时间、地点等属性和GetStory方法,Person有被咬(被咬后的反映)和打狗等方法,如果故事情节涉及Brick(板砖)和 Shop(商店)的细节,还会有这两个类,这样基本有了貌似单一职责的几个类。其实,这仅仅是对代码的“归类”,没有做到单一职责,比如Person中的 BefallBite(被狗咬)方法会遇到这样的问题:
如果Person实例是小孩,反映可能是坐在地上大哭
如果是大人,可能是找板砖
如果是狗主人家的小孩,狗可能只是轻咬他玩得,不会哭,会跟狗一起玩
如果是大人,又是狗主人被咬,不一定舍得板砖拍……
……
显然,Person还应该有一些子类:

这样就基本有了职责单一的类结构。但我们还是发现了问题,Person的子类比较多,如果再加上“根据被狗咬的部位不同反映不同”(Baby被咬屁股不会 坐地上哭,可能是趴着哭;大人被咬右手可能无法拿板砖),那么子类将会更多。这时仅仅靠最基本的单一职责原则及其它几条原则已经不能做出良好的面向对象设 计,设计模式就是在面向对象的基础上进一步提高软件应对变化能力的“良药”。本例是典型的桥接模式应用场景,笔者将在后续博文中用更复杂更完整的例子和大家共同学习设计模式的综合运用。
PS 1:
本文提到的三种编码方式应该可以代表三种编码阶段,在结尾提到了设计模式,其实在知道用设计模式后还有三个阶段,纯属个人看法:
1、在单一职责等基本原则做的不太好时就接触了设计模式,根据各种模式定义的场景大量运用。这种阶段去做大项目,遇到的问题往往比最初级的混合编码阶段还多。
2、基本功底打得扎实后,逐步学习运用设计模式,遇到问题能够根据设计模式定义进行思索,合理解决问题
3、设计模式的定义经常不记得,设计和编码时只根据基本原则进行,遇到问题就重构代码,重构后发现好像和某种模式定义的场景类似,查书后确定是一样的……
呵呵,设计模式最好不要强求,自然形成就好。
PS 2:
刚开始写博客,对编辑器不熟悉,我贴的代码好好的,发布后对齐格式有点乱,反复几次搞不定;还有贴个类图要先截图存gif,再传上来,很麻烦。请高手留言指点,多谢!我用的编辑器是 TinyMCE(推荐)
[MVC]一个小Forum Web程序示例,使用ASP.NET MVC Framework,Repo
本文简单介绍以下内容:
1. Repository模式简介以及结合IQueryable改进的Repository模式;
2. 简单的TDD实践,使用ReSharper 4.0插件简化操作;
3. 结合使用依赖注入(Dependency Injection[中文翻译])工具StructureMap[文档下载],实现模块之间的松散耦合。
4. 提供一个很简单的论坛程序示例,Step by Step介绍以上内容。
差不多内容的blog示例在Codeplex上也早就有了,介绍MVC TDD和StructureMap的英文文章也挺多,本人才疏学浅,文采很烂,写本文是一是为了自己更深的掌握这些内容,二是为了让喜爱MVC的朋友也能 获得一些帮助,也是第一次写东西放首页上,请各位前辈多提意见和建议。
Repository简介
介绍Repository的文章比较少,其实这个模式相当简单,首先对它做一个简单的介绍:

这就是一个比较简单的Repository模式,首先创建一个IRepository接口,这个接口定义一系列契约,然后创建一个实现这个接口的类,负责它的具体操作。然后在Context中对它进行实例化(在本示例中,实例由依赖注入框架完成)。
当然这个模式还可以结合简单工厂模式对它进行扩充,由工厂来完成它的实例创建工作。
应用程序整体结构
下面介绍一下本示例的结构,也是比较简单的:
首先,我们使用ASP.NET MVC Framwork Preview 5,所有的操作(发帖、回帖、删帖等)都是由在相应的Controller中的Action来完成的。关于MVC这里就不做详细介绍了。我这里创建了一个 类库项目:TinyForum.Service,在这个项目中,创建一个IForumService定义一组契约,我们在Controller中需要一个 它的实例字段(为了好看,图中为属性,字段在Class diagram中不显示关系)来完成操作(如图)。

上图中的ForumService类中,需要对数据操作进行封装。为了使用不同的数据库,还得建立一个项目:TinyForum.Data,在这个项目中,我们会定义一个IForumRepository接口,又由这个接口定义一组对数据库的操作,所有操作返回类型都为IQueryable类型,这样非常的方便,在ForumService中就可以对它进行任意的转换,也不会因为返回大量的IList还可能需要做进一步的筛选影响性能。
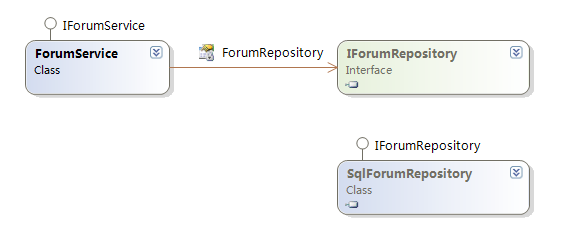
这是ForumService的实现:
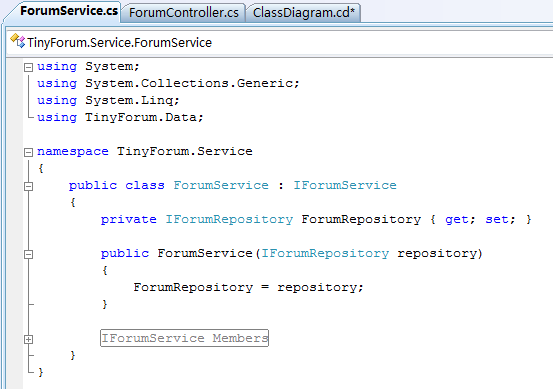
这是IForumRepository的定义(随意定义了2个方法):
很显然,在ForumService中,需要一个对IForumRepository的依赖,在实现的代码中,我们创建了一个构造方法来获 得这个对象,这时候出现一个麻烦问题,因为我们需要在上下文中去创建我们需要的IForumRepository的实例,这样做会造成可能需要修改 ForumService的代码,这样是违反OCP原则的;
同时ForumController也需要一个对IForumService的依赖,并且要在构造方法中获得它的示例,而MVC默认的Controller构造方法是无参的,编译可以通过,不过运行的时候会得到一个黄色的异常页面,大概是这样:

看来需要使用一个依赖注入工具来解救我们。我这里使用的StructureMap。
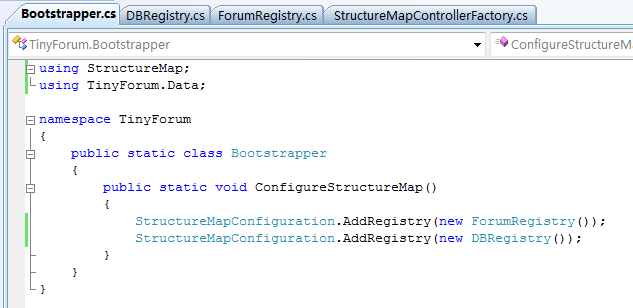
在Web项目中,添加StructureMap引用,并在Controllers目录下添加一个StructureMapControllerFactory,如图:

然后我们需要为StructureMap做一点配置,让它知道该做什么,首先创建一个StructureMap的注册表:ForumRegistry

另外还要添加一个注册表,用于让SQLRepository获得ForumDataContext(Linq):
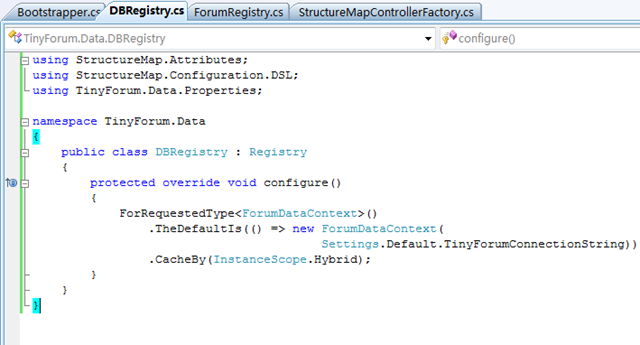
都不是很复杂,代码已经解释得很详细了,就不做累述了。
最后需要添加一个Bootstrapper,并添加到Global.asax.cs中去,启动的时候就执行。

基本结构就介绍到这里。
目前的解决方案截图:
怕文章又臭又长,所以干脆分开写(至少不长,呵呵),下一个部分将介绍使用Resharper插件、和TDD步骤,并象征性实现一些基本的功能。
[C#]C# 3.0将偷懒进行到底
C# 3.0将偷懒进行到底
本文为博客园zpino原创
http://www.cnblogs.com/zpino/ 转载请说明出处!
最近在MS中了解到了一些东西。首先我要说,我绝对是一个新手。
要说核心原理,俺最多能给你搬来一点,要是刨根问底的话,去找MSDN。
隐藏类型局部变量
这个很多人都知道(–!我现在才知道。貌似很受打击,有点孤陋寡闻)
注意:
1 var 不是一个类型。顶多就像一个占位的东西。编译后替换成int string等等.而且只能作为局部变量!
2 var的值不能为null。不然编译器不能推断。
3 不能为对象和集合的初始化。但是可以初始化数组,包括多维数组。 var q=new{1,2,3};
初始化语句
扩展方法
这个也是一个很方便的东西
可以扩展一个类的方法。
比如
extensions就是一个扩展方法。
为什么会有这个效果呢?
其实之前我建立一个静态类,和一个静态方法。而且方法接受的参数是 extensions(this int k)。
上代码^_^
这样就非常简单的实现不修改代码
直接扩展方法。
其中代码:
被编译成了
这个指针之类的有关系,俺暂时没有深入了解,所以不乱忽悠了。
注意:
1 方法扩展有优先级。实例方法>所在的namespace>别的namespace
2 记得类、方法要用静态。
匿名对象
匿名类型。不创建类 直接构建一个匿名类型,甚至不用写属性的类型,编译的时候会自动判断,使用起来和平时没区别。
只是有点局限性,不适合跨越传递。
注意:
1 其中声明的qq和vv可以互相赋值。只要编译器判断的属性类型相同。
2 声明的匿名类型全部继承Object
–!写完了,有兴趣的,记得装个VS2008试试。不知道在公司用这些老板会不会发飙?:-D