不多说了,直接看官方页面吧
http://opensource.adobe.com/wiki/display/cairngorm/Cairngorm

[问题]Asp.Net下的Session丢失问题
最近在做ASP.NET项目时,测试网站老是取不出Session中的值,在网上搜索了一下,找到一些解决方法,记录在这里。最后使用存储在StateServer中的办法解决了问题。
SessionState 的Timeout),其主要原因有三种。
一:有些杀病毒软件会去扫描您的Web.Config文件,那时Session肯定掉,这是微软的说法。
二:程序内部里有让Session掉失的代码,及服务器内存不足产生的。
三:程序有框架页面和跨域情况。
第一种解决办法是:使杀病毒软件屏蔽扫描Web.Config文件(程序运行时自己也不要去编辑它)
第二种是检查代码有无Session.Abandon()之类的。
第三种是在Window服务中将ASP.NET State Service 启动。
下面是帮助中的内容:
(ms-help://MS.VSCC.2003/MS.MSDNQTR.2003FEB.2052/cpguide/html/cpconsessionstate.htm)
ASP.NET 提供一个简单、易于使用的会话状态模型,您可以使用该模型跨多个 Web 请求存储任意数据和对象。它使用基于字典的、内存中的对象引用(这些对象引用存在于 IIS 进程中)缓存来完成该操作。使用进程内会话状态模式时请考虑下面的限制:
使用进程内会话状态模式时,如果 aspnet_wp.exe 或应用程序域重新启动,则会话状态数据将丢失。这些重新启动通常会在下面的情况中发生:
在应用程序的 Web.config 文件的 <processModel> 元素中,设置一个导致新进程在条件被满足时启动的属性,例如 memoryLimit。
修改 Global.asax 或 Web.config 文件。
更改到 Web 应用程序的 \Bin 目录。
用杀毒软件扫描并修改 Global.asax 文件、Web.config 文件或 Web 应用程序的 \Bin 目录下的文件。
如果在应用程序的 Web.config 文件的 <processModel> 元素中启用了网络园模式,请不要使用进程内会话状态模式。否则将发生随机数据丢失。
还有这二种:
一:在第一个页面置了SESSION,然后REDIRECT去第二个页面。解决方法是在REDIRECT中设置endResponse为FALSE。
二: ASP.NET中使用了ACCESS数据库,而且数据库是放在bin目录中的。解决方法是不要放会更新的文件在BIN目录中。
参考:http://www.dotnet247.com/247reference/msgs/58/290316.aspx
一:在第一个页面置了SESSION,然后REDIRECT去第二个页面。解决方法是在REDIRECT中设置endResponse为FALSE。
二: ASP.NET中使用了ACCESS数据库,而且数据库是放在bin目录中的。解决方法是不要放会更新的文件在BIN目录中。
参考:http://www.dotnet247.com/247reference/msgs/58/290316.aspx
Asp.net 默认配置下,Session莫名丢失的原因及解决办法
正常操作情况下Session会无故丢失。因为程序是在不停的被操作,排除Session超时的可能。另外,Session超时时间被设定成60分钟,不会这么快就超时的。
这次到CSDN上搜了一下帖子,发现好多人在讨论这个问题,然后我又google了一下,发现微软网站上也有类似的内容。
现在我就把原因和解决办法写出来。
原因:
由于Asp.net程序是默认配置,所以Web.Config文件中关于Session的设定如下:
<sessionState mode='InProc' stateConnectionString='tcpip=127.0.0.1:42424' SQLConnectionString='data source=127.0.0.1;Trusted_Connection=yes' cookieless='true' timeout='60'/>
我 们会发现sessionState标签中有个属性mode,它可以有3种取值:InProc、StateServer?SQLServer(大小写敏感) 。默认情况下是InProc,也就是将Session保存在进程内(IIS5是aspnet_wp.exe,而IIS6是W3wp.exe),这个进程不 稳定,在某些事件发生时,进程会重起,所以造成了存储在该进程内的Session丢失。
哪些情况下该进程会重起呢?微软的一篇文章告诉了我们:
1、配置文件中processModel标签的memoryLimit属性
2、Global.asax或者Web.config文件被更改
3、Bin文件夹中的Web程序(DLL)被修改
4、杀毒软件扫描了一些.config文件。
更多的信息请参考PRB: Session variables are lost intermittently in ASP.NET applications
解决办法:
前面说到的sessionState标签中mode属性可以有三个取值,除了InProc之外,还可以为StateServer、SQLServer。这两种存Session的方法都是进程外的,所以当aspnet_wp.exe重起的时候,不会影响到Session。
现在请将mode设定为StateServer。StateServer是本机的一个服务,可以在系统服务里看到服务名为ASP.NET State Service的服务,默认情况是不启动的。当我们设定mode为StateServer之后,请手工将该服务启动。
这样,我们就能利用本机的StateService来存储Session了,除非电脑重启或者StateService崩掉,否则Session是不会丢的(因Session超时被丢弃是正常的)。
除 此之外,我们还可以将Session通过其他电脑的StateService来保存。具体的修改是这样的。同样还在sessionState标签中,有个 stateConnectionString='tcpip=127.0.0.1:42424'属性,其中有个ip地址,默认为本机 (127.0.0.1),你可以将其改成你所知的运行了StateService服务的电脑IP,这样就可以实现位于不同电脑上的Asp.net程序互通 Session了。
如果你有更高的要求,需要在服务期重启时Session也不丢失,可以考虑将mode设定成SQLServer,同样需要修改sqlConnectionString属性。关于使用SQLServer保存Session的操作,请访问这里。
在使用StateServer或者SQLServer存储Session时,所有需要保存到Session的对象除了基本数据类型(默认的数据类型,如int、string等)外,都必须序列化。只需将[Serializable]标签放到要序列化的类前就可以了。
如:
[Serializable]
public class MyClass
{
……
}
具体的序列化相关的知识请参这里。
至此,问题解决。
参考文章:
ASP.NET Session State FAQ
ASP.NET Session State
[ASP.NET] Session 详解
PRB: Session Data Is Lost When You Use ASP.NET InProc Session State Mode
PRB: Session Data Is Lost When You Use ASP.NET InProc Session State Mode
ASP.NET HTTP 运行时
.NET 中的对象序列化
可能的原因1:
win2003 server下的IIS6默认设置下对每个运行在默认应用池中的工作者进程都会经过20多个小时后自动回收该进程,造成保存在该进程中的session丢失。
因为Session,Application等数据默认保存在运行该Web应用程序的工作者进程中,如果回收工作者进程,则会造成丢失。
解决办法:
修改配置,设置为不定时自动回收该工作者进程,比如设置为当超出占用现有物理内存60%后自动回收
该进程。通过使用默认应用程序池,可以确保多个应用程序间互相隔离,保证由于一个应用程序的崩溃不会影响另外的Web应用程序。还可以使一个独立的应用程序运行在一个指定的用户帐号特权之下。
如果使用StateServer方式或者Sql Server数据库方式来保存Session,则不受该设置的影响。
可能的原因2:
系统要运行在负载平衡的 Web 场环境中,而系统配置文件web.config中的Session状态却设置为InProc(即在本地存储会话状态),导至在用户访问量大 时,Session常经超时的情况。引起这个现象的原因主要是因为用户通过负载平衡IP来访问WEB应用系统,某段时候在某台服务器保存了Session 的会话状态,但在其它的WEB前端服务器中却没有保存Session的会话状态,而随着并发量的增大,负载平衡会当作路由随时访问空闲的服务器,结果空闲 的服务器并没有之前保存的Session会话状态。
解决办法:
1.当您在负载平衡的 Web 场环境中运行 ASP.NET Web 应用程序时,一定要使用 SqlServer 或 StateServer 会话状态模式,在项目中我们基于性能考虑并没有选择SqlServer模式来存储Session状态,而是选择一台SessionStateServer 服务器来用户的Session会话状态。我们要在系统配置文件web.config中设置如下:
<sessionState mode="StateServer" cookieless="false" timeout="240" stateConnectionString="tcpip=192.168.0.1:42424" stateNetworkTimeout="14400" />
还要添加一项
<machineKey validationKey="78AE3850338BFADCE59D8DDF58C9E4518E7510149C46142D7AAD7F1AD49D95D4" decryptionKey="5FC88DFC24EA123C" validation="SHA1"/>
2. 我们同时还要在SessionStateServer 服务器中启动ASP.NET State Service服务,具体设置:控制面板>>管理工具>>服务>>ASP.NET State Service,把它设为自动启动即可。
3. 每台前端WEB服务的Microsoft“Internet 信息服务”(IIS)设置
要在 Web 场中的不同 Web 服务器间维护会话状态,Microsoft“Internet 信息服务”(IIS) 配置数据库中 Web 站点的应用程序路径(例如,\LM\W3SVC\2)与 Web 场中所有 Web 服务器必须相同。大小写也必须相同,因为应用程序路径是区分大小写的。在一台 Web 服务器上,承载 ASP.NET 应用程序的 Web 站点的实例 ID 可能是 2(其中应用程序路径是 \LM\W3SVC\2)。在另一台 Web 服务器上,Web 站点的实例 ID 可能是 3(其中应用程序路径是 \LM\W3SVC\3)。因此,Web 场中的 Web 服务器之间的应用程序路径是不同的。我们必须使Web 场Web 站点的实例 ID 相同即可。你可以在IIS中把某一个WEB配置信息保存为一个文件,其他Web 服务器的IIS配置可以来自这一个文件。您如果想知道具体的设置请访问Microsoft Support网站:
补充一些相关资料:
PRB: Session Variables Are Lost If You Use FRAMESET in Internet Explorer 6.0
http://support.microsoft.com/kb/323752/EN-US/#
PRB: Session Data Is Lost When You Use ASP.NET InProc Session State Mode
http://support.microsoft.com/?id=324772
PRB:如果您使用 SqlServer 或 StateServer 会话模式 Web 场中会丢失会话状态
http://support.microsoft.com/default.aspx?scid=kb;zh-cn;325056
http://support.microsoft.com/default.aspx?scid=kb;zh-cn;325056
ASP.NET Session State FAQ
http://www.eggheadcafe.com/articles/20021016.asp
http://www.eggheadcafe.com/articles/20021016.asp
[下载]JQuery中文API手册

[JQuery]JQuery取值
http://www.cnblogs.com/xlfj521/archive/2008/01/29/1057375.html
获取一组radio被选中项的值
var item = $('input[@name=items][@checked]').val();
获取select被选中项的文本
var item = $("select[@name=items] option[@selected]").text();
select下拉框的第二个元素为当前选中值
$('#select_id')[0].selectedIndex = 1;
radio单选组的第二个元素为当前选中值
$('input[@name=items]').get(1).checked = true;
获取值:
文本框,文本区域:$("#txt").attr("value");
多选框checkbox:$("#checkbox_id").attr("value");
单选组radio: $("input[@type=radio][@checked]").val();
下拉框select: $('#sel').val();
控制表单元素:
文本框,文本区域:$("#txt").attr("value",'');//清空内容
$("#txt").attr("value",'11');//填充内容
多选框checkbox: $("#chk1").attr("checked",'');//不打勾
$("#chk2").attr("checked",true);//打勾
if($("#chk1").attr('checked')==undefined) //判断是否已经打勾
单选组radio: $("input[@type=radio]").attr("checked",'2');//设置value=2的项目为当前选中项
下拉框select: $("#sel").attr("value",'-sel3');//设置value=-sel3的项目为当前选中项
$("<option value='1'>1111</option><option value='2'>2222</option>").appendTo("#sel")//添加下拉框的option
$("#sel").empty();//清空下拉框
[MVC]ASP.NET MVC文章推荐
JQuery for ASP.NET MVC preview 3
http://www.chrisvandesteeg.nl/2008/06/13/jquery-for-aspnet-mvc-preview-3/
哈哈,喜欢ASP.NET MVC和JQuery的朋友有福了….
另一篇:Using JQuery to perform Ajax calls in ASP.NET MVC
还有:
Using jQuery with ASP.NET MVC
http://www.chadmyers.com/Blog/archive/2007/12/13/using-jquery-with-asp.net-mvc.aspx
为ASP.NET MVC框架添加AJAX支持
http://www.infoq.com/cn/news/2007/12/ajax-aspnet-mvc
Troy Goode: SquaredRoot – SSL Links/URLs in MVC
http://www.squaredroot.com/post/2008/06/MVC-and-SSL.aspx
Code based ASP.NET MVC GridView
http://blog.maartenballiauw.be/post/2008/06/Code-based-ASPNET-MVC-GridView.aspx
该作者的BLOG关于ASP.NET MVC的文章不少,文章都不错,大家可以订阅来看:
http://blog.maartenballiauw.be/category/MVC.aspx
HydrogenCMS Released
http://gravitycube.net/blog/post/HydrogenCMS-Released.aspx
HydrogenCMS 是一个全功能的、低要求的、开源的CMS,它使用 asp.net mvc, linq2SQL, linq2xml, 还有 BlogEngine, Kigg的一些优点.
ViewData "dot" Notation Expressions in ASP.NET MVC
http://blog.eworldui.net/post/2008/05/ViewData-quot3bdotquot3b-Notation-Expressions-in-ASPNET-MVC.aspx
ASP.NET MVC 3比较COOL的一个地方….
作者的BLOG关于ASP.NET MVC的文章不错,大家可以收藏、订阅.
MVC Post-Redirect-Get Sample Updated
http://blog.eworldui.net/post/2008/06/MVC-Post-Redirect-Get-Sample-Updated.aspx
前一篇:ASP.NET MVC – Using Post, Redirect, Get Pattern(我翻译的:使用Post, Redirect, Get (PRG)模式).
ASP.NET MVC – Localization Helpers
http://blog.eworldui.net/post/2008/05/ASPNET-MVC—Localization.aspx
本地化。

ASP.NET MVC Tips
http://weblogs.asp.net/stephenwalther/archive/tags/Tips/ASP.NET+MVC/default.aspx
作者Stephen Walther是微软的一位项目经理,负责http://www.asp.net/网站中ASP.NET MVC部分的内容。这是一个系列的文章,关于ASP.NET MVC的一些技巧。对ASP.NET MVC有兴趣的朋友可关注.
http://blog.wekeroad.com/mvc-storefront/
直接引用园子上另外一位朋友的推荐词:这是Rob Conery的个人网站,他采用了Asp.Net MVC做了一个Demo, 不仅在codeplex上提供了这个项目的源代码,还提供了15个视频,这些视频的内容包括从项目的构思、到设计、再到实现和重构的一个完整的过程。
版权声明:本文原创发表于博客园,作者为QLeelulu
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则视为侵权。
另转一篇:ASP.NET MVC 资源大全,内容如下:
ASP.NET MVC官方网站
MVC 社区网站
MVC 搜索引擎
MVC 结构综述
MVC 101 Video
MVC Request 周期
MVC Routing
1. First tutorial on the subject
2. Store routes in the database
3. Store routes in the web.config
MVC 界面 UI
分页pagination view user control
UI 帮助方法 (Helper Methods) Automatically map to your controller classes
使用component controller class
部分视图 "Partial View" that you can provide with variable-based parameters
正确使用控件 ASP.NET user controls appropriately in an MVC application
MVC + AJAX:
MVC + ASP.NET Membership:
MVC + IIS 5/6
MVC Security
Secure controller actions
Secure controller actions with an XML file
REST
REST定义 – Wikipedia
How I Explained REST to My Wife
Illustrates on the concepts of REST in MVC
ASP.NET MVC in the context of REST
Build your site once and make it readable.
MVC Validation
Validation framework for MVC
Validator Toolkit
Article on how to add CAPTCHA
MVC 测试Testing
ASP.NET MVC Framework – Part 2: Testing
TDD while building an MVC application
Testing controller actions.
其他
RSS feed with the new ASP.NET MVC Framework.
错误处理Build action filters to handle errors.
缓存和压缩 Caching and compression.
开源项目MVC Contrib , docmentation and features and Code Camp Server.
MVC 书籍
[SQL]SQL Server2005索引
最近在总结SQL Server2005下性能调优方法,一个通用的调优方法。通过找到系统的瓶颈,然后解决瓶颈,提高性能。例如:当我们找到系统的瓶颈在于磁盘I/O上, 在不提高硬件配置的前提下,我们应该如果提高性能?通过各种各样的性能分析工具 :Profiler、SQLDiag、Perfmon等等。我们找到了一些影响性能的关键SQL,现在我们暂不考虑程序问题。对于这些SQL我们应该如何 改进呢?说起SQL,不得不提索引,这也就是我们今天要讨论的主题。
首先,什么是索引?从BookOnline上search了一下:
索引有什么类型:
在了解了上述概念后,如何正确使用索引对于程序的性能有着至关重要的作用。设计良好的索引可以减少磁盘 I/O 操作,并且消耗的系统资源也较少,从而可以提高查询性能。对于包含 Select、Update 或 Delete 语句的各种查询,索引会很有用。
在我们的coding中,得到相同的查询结果SQL的写法可以有多种,最重要的考虑因素之一是Where条件,Where条件限制了查询要返回的记录数目,查询优化程序会尝试判断已有的索引,分析对查找符合的记录是否有帮助。
查询优化程序要查看Where中的条件,以决定这些条件在限制SQLServer访问时是否有用。所以,有效的设置查询参数,决定了是否可以充分的利用索引。
查询参数可以包含一下操作:=、<、>、>=、<=、BETWEEN、部分like。其中,like当这样使用时会用到索 引:like '*%',但like'%*'就用不到索引。因为索引的摆放是依据字段值升序或降序排列,like'%*'这种用法,不能利用有序的数据结构,利用二分法 查找数据。
不适当的查询参数有:NOT 、!= 、<>、 !>、 !< 、NOT EXISTS、 NOT IN 、NOT LIKE等,还有一些不当的用法,例如:对数据进行计算,负向查询、等号左边使用函数、使用OR。上述语法都不用不上索引,降低程序的效率。
当我们了解了索引的用法后,在我们编写sql时考虑上述用法,充分利用索引,以高程序的性能。还有,在我们coding过程中,写好sql后,最好使用SQL Server自带的查询计划,来分析SQL执行成本、索引的使用情况,尽可能的使用索引来提高效率。
先说这么多,欢迎高手们提出更好的建议,我们一起进步。
[安全]163验证码识别
识别验证码一般是要经过“去干扰”,“切字”,“识别”三步处理。
一、切字:
切字即是将图片里的每个验证码都分别“切”开,这样才能进行下一步的验证码识别,并且“切字”切出来的“字”顺序也关系到识别出来的字符顺序,比如以下验证码样例图片:
![]()
则应该需要切出“7”,“4”,“3”,“7”,“7”五个字图。
对于不同的验证码图片,“切字”的方法也不尽相同,如对于一些验证码出现位置固定的验证码图片则可以直接从图形中分析出字坐标,再进行“切字”即 可。而对于一些采用了“变位”干扰的验证码图片(如163相册的)就不能采用固定坐标来“切字”了,并且对于某些字符相连的验证码图片(如Google 的),“切字”比“去干扰”还更头痛!!(-_#碰到这类的验证码图片,我一般放弃。咔咔!)
对163相册验证码图片进行“切字”其时还是很简单,因为验证码字符之间是没有任何相连,只是采用了“变位”干扰,但对于这种图形使用“去白拆分法”(嘿嘿,这方法名是我自己名的命)则基本是万能方法。
去白拆分法:
也就是先将空白的头尾行/列去掉,再按空白列拆分为多个子图,再将这几个子图的头尾空白行/列去掉,经过这几步处理后,那些拆分出来的子图就是最终“切”出来的验证码字图了。
1,去白:去除验证码图片的头尾空白行/列
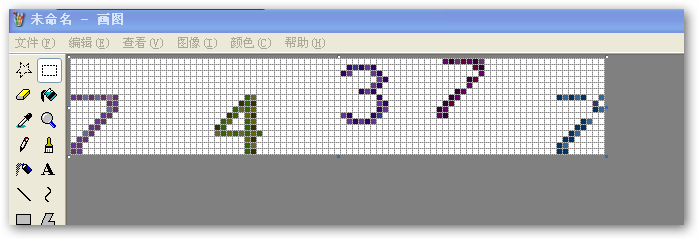
比如上面的验证码图片(为了便于说明我在画板程序中打开样例图并将图形放大了6倍和显示网格):
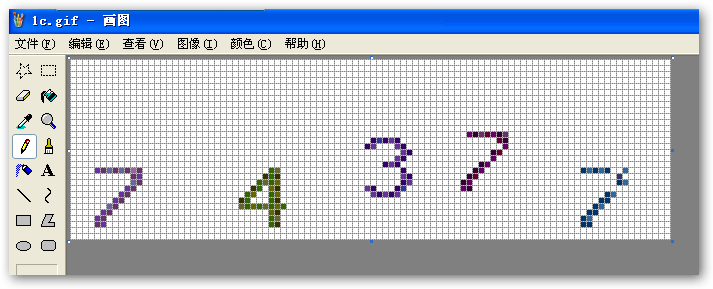
去空白的头尾行/列则是将下面的黄色区域都去掉,只留中间部分。
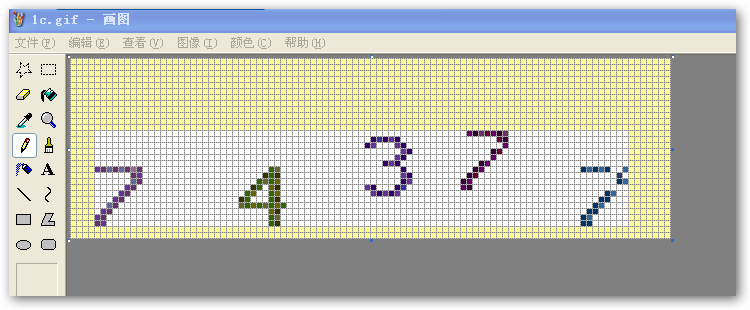
经过“去白”处理后,图形就变成了如下样式:
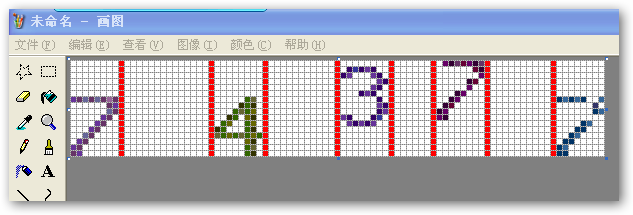
2,拆分 : 按空白列拆分图形,如下图根据红线部分拆分就基本将所有验证码字图(7,4,3,7,7)都“切”出来了,如图:
但要注意,经过上面折分后字图里也还是包含有空白的头尾行,所以也要“去白”处理,如下图:(也就是将那些黄色区域去掉)
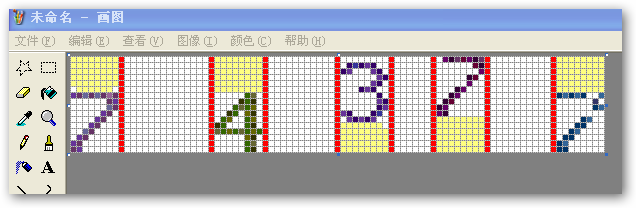
经这样处理后的“字图”就可以用于识别了:)
注意:对于某些被干扰破坏得很严重的图形,在进行“去白拆分”操作时要确保“切”到的字图高宽度为“源数字图”的大小。
如下图中的“5”字:

二、验证码识别:
当经过“去干扰”,“切字”处理后,识别就是一个很轻松的工作了。一般采用图形结构“相似度比较法”进行识别,这样对于一些在“去干扰”时就破坏了结构的字图(如上面图片中最后二个“7”字)也可以识别出来,但也因为是对图形结构进行“相似”比较,所以就存在有识别失败的可能性。
相似度比较法:
此方法是将每个“切”出来的字图和所有源数字图逐一比较,并得出一个图形结构的相似度值,然后再取相似度值最高的“源数字图”,这样“字图”对应的字符就识别出来了。
图形结构相似度:
假如将一幅图看成一个二维数组(一维下标对应X轴,二维下标对应Y轴),数组里的数据就是每个象素点的颜色值。那么求两副图图形结构的相似度值,则是等价于求两个二维数组里的数据的相似度统计。
假如有两个数组的数据分别如下:
二维数组A里的数据:("4"字的01图)
二维数组B里的数据:("4"字被干扰破坏后的01图,注意红色部分)
求A与B的相似度,则分别比较AB对应“行”里的数据,找出不相同点的数量,也就是共有3次不相同,所以相似度值大概为96% ,因此就可以认为B是A了。
注:对于相似度取什么值就可考虑AB“相等”,这个大家要权衡一下,毕竟取的值过低识差率可是很大的。
[框架]分布式计算开源框架Hadoop介绍
分布式计算开源框架Hadoop介绍

作者 岑文初 发布于 2008年8月4日 上午2时15分
在 SIP项目设计的过程中,对于它庞大的日志在开始时就考虑使用任务分解的多线程处理模式来分析统计,在我从前写的文章《Tiger Concurrent Practice –日志分析并行分解设计与实现》中有所提到。但是由于统计的内容暂时还是十分简单,所以就采用Memcache作为计数器,结合MySQL就完成了访问 控制以及统计的工作。然而未来,对于海量日志分析的工作,还是需要有所准备。现在最火的技术词汇莫过于“云计算”,在Open API日益盛行的今天,互联网应用的数据将会越来越有价值,如何去分析这些数据,挖掘其内在价值,就需要分布式计算来支撑海量数据的分析工作。
回过头来看,早先那种多线程,多任务分解的日志分析设计,其实是分布式计算的一个单机版缩略,如何将这种单机的工作进行分拆,变成协同工作的集群, 其实就是分布式计算框架设计所涉及的。在去年参加BEA大会的时候,BEA和VMWare合作采用虚拟机来构建集群,无非就是希望使得计算机硬件能够类似 于应用程序中资源池的资源,使用者无需关心资源的分配情况,从而最大化了硬件资源的使用价值。分布式计算也是如此,具体的计算任务交由哪一台机器执行,执 行后由谁来汇总,这都由分布式框架的Master来抉择,而使用者只需简单地将待分析内容提供给分布式计算系统作为输入,就可以得到分布式计算后的结果。
Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊、Facebook和Yahoo等等。 对于我来说,最近的一个使用点就是服务集成平台的日志分析。服务集成平台的日志量将会很大,而这也正好符合了分布式计算的适用场景(日志分析和索引建立就 是两大应用场景)。
当前没有正式确定使用,所以也是自己业余摸索,后续所写的相关内容,都是一个新手的学习过程,难免会有一些错误,只是希望记录下来可以分享给更多志同道合的朋友。
什么是Hadoop?
搞什么东西之前,第一步是要知道What(是什么),然后是Why(为什么),最后才是How(怎么做)。但很多开发的朋友在做了多年项目以后,都习惯是先How,然后What,最后才是Why,这样只会让自己变得浮躁,同时往往会将技术误用于不适合的场景。
Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是由Google的一篇论文所提及而被广为流传的, 简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任 务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这 种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执 行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的 任务分解执行方式。在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时 这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。(其实我一直认为Hadoop的卡通图标不应该是一个小象,应该是蚂蚁,分布式计算就好比 蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向扩展的曲线始终敌不过横向扩展的斜线)。任务分解处理以后,那就需要将处理以后的结果再汇总起 来,这就是Reduce要做的工作。

图1:MapReduce结构示意图
上图就是MapReduce大致的结构图,在Map前还可能会对输入的数据有Split(分割)的过程,保证任务并行效率,在Map之后还会有Shuffle(混合)的过程,对于提高Reduce的效率以及减小数据传输的压力有很大的帮助。后面会具体提及这些部分的细节。
HDFS是分布式计算的存储基石,Hadoop的分布式文件系统和其他分布式文件系统有很多类似的特质。分布式文件系统基本的几个特点:
- 对于整个集群有单一的命名空间。
- 数据一致性。适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无法看到文件存在。
- 文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且根据配置会由复制文件块来保证数据的安全性。

图2:HDFS结构示意图
上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理 者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括 了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地 文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文 件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。
文件写入:
- Client向NameNode发起文件写入的请求。
- NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
- Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
文件读取:
- Client向NameNode发起文件读取的请求。
- NameNode返回文件存储的DataNode的信息。
- Client读取文件信息。
文件Block复制:
- NameNode发现部分文件的Block不符合最小复制数或者部分DataNode失效。
- 通知DataNode相互复制Block。
- DataNode开始直接相互复制。
最后再说一下HDFS的几个设计特点(对于框架设计值得借鉴):
- Block的放置:默认不配置。一个Block会有三份备份,一份放在NameNode指定的DataNode,另一份放在 与指定DataNode非同一Rack上的DataNode,最后一份放在与指定DataNode同一Rack上的DataNode上。备份无非就是为了 数据安全,考虑同一Rack的失败情况以及不同Rack之间数据拷贝性能问题就采用这种配置方式。
- 心跳检测DataNode的健康状况,如果发现问题就采取数据备份的方式来保证数据的安全性。
- 数 据复制(场景为DataNode失败、需要平衡DataNode的存储利用率和需要平衡DataNode数据交互压力等情况):这里先说一下,使用 HDFS的balancer命令,可以配置一个Threshold来平衡每一个DataNode磁盘利用率。例如设置了Threshold为10%,那么 执行balancer命令的时候,首先统计所有DataNode的磁盘利用率的均值,然后判断如果某一个DataNode的磁盘利用率超过这个均值 Threshold以上,那么将会把这个DataNode的block转移到磁盘利用率低的DataNode,这对于新节点的加入来说十分有用。
- 数据交验:采用CRC32作数据交验。在文件Block写入的时候除了写入数据还会写入交验信息,在读取的时候需要交验后再读入。
- NameNode是单点:如果失败的话,任务处理信息将会纪录在本地文件系统和远端的文件系统中。
- 数 据管道性的写入:当客户端要写入文件到DataNode上,首先客户端读取一个Block然后写到第一个DataNode上,然后由第一个 DataNode传递到备份的DataNode上,一直到所有需要写入这个Block的NataNode都成功写入,客户端才会继续开始写下一个 Block。
- 安全模式:在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文 件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必 要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只 需要等待一会儿即可。
下面综合MapReduce和HDFS来看Hadoop的结构:

图3:Hadoop结构示意图
在Hadoop的系统中,会有一台Master,主要负责NameNode的工作以及JobTracker的工作。JobTracker的主要职责 就是启动、跟踪和调度各个Slave的任务执行。还会有多台Slave,每一台Slave通常具有DataNode的功能并负责TaskTracker的 工作。TaskTracker根据应用要求来结合本地数据执行Map任务以及Reduce任务。
说到这里,就要提到分布式计算最重要的一个设计点:Moving Computation is Cheaper than Moving Data。就是在分布式处理中,移动数据的代价总是高于转移计算的代价。简单来说就是分而治之的工作,需要将数据也分而存储,本地任务处理本地数据然后归 总,这样才会保证分布式计算的高效性。
为什么要选择Hadoop?
说完了What,简单地说一下Why。官方网站已经给了很多的说明,这里就大致说一下其优点及使用的场景(没有不好的工具,只用不适用的工具,因此选择好场景才能够真正发挥分布式计算的作用):
- 可扩展:不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。
- 经济:框架可以运行在任何普通的PC上。
- 可靠:分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。
- 高效:分布式文件系统的高效数据交互实现以及MapReduce结合Local Data处理的模式,为高效处理海量的信息作了基础准备。
使用场景:个人觉得最适合的就是海量数据的分析,其实Google最早提出MapReduce也就是为了海量数 据分析。同时HDFS最早是为了搜索引擎实现而开发的,后来才被用于分布式计算框架中。海量数据被分割于多个节点,然后由每一个节点并行计算,将得出的结 果归并到输出。同时第一阶段的输出又可以作为下一阶段计算的输入,因此可以想象到一个树状结构的分布式计算图,在不同阶段都有不同产出,同时并行和串行结 合的计算也可以很好地在分布式集群的资源下得以高效的处理。
作者介绍:岑文初,就职于阿里软件公司研发中心平台一部,任架构师。当前主要工作涉及阿里软件开发平台服务框架(ASF)设计与实现,服务集成平台(SIP)设计与实现。没有什么擅长或者精通,工作到现在唯一提升的就是学习能力和速度。个人Blog为:http://blog.csdn.net/cenwenchu79。
[Flex]Adobe的一天学会Flex视频集
在Aodbe的网站上,推出的一系列的Flex视频教程,希望对大家有用,最近一直在弄.net挺长时间没弄flex
看来,人在职场身不由己啊
http://www.adobe.com/devnet/flex/videotraining/
[ORM]从贫血到充血Domain Model模式
http://blog.csdn.net/ronghao100/archive/2008/07/04/2610470.aspx