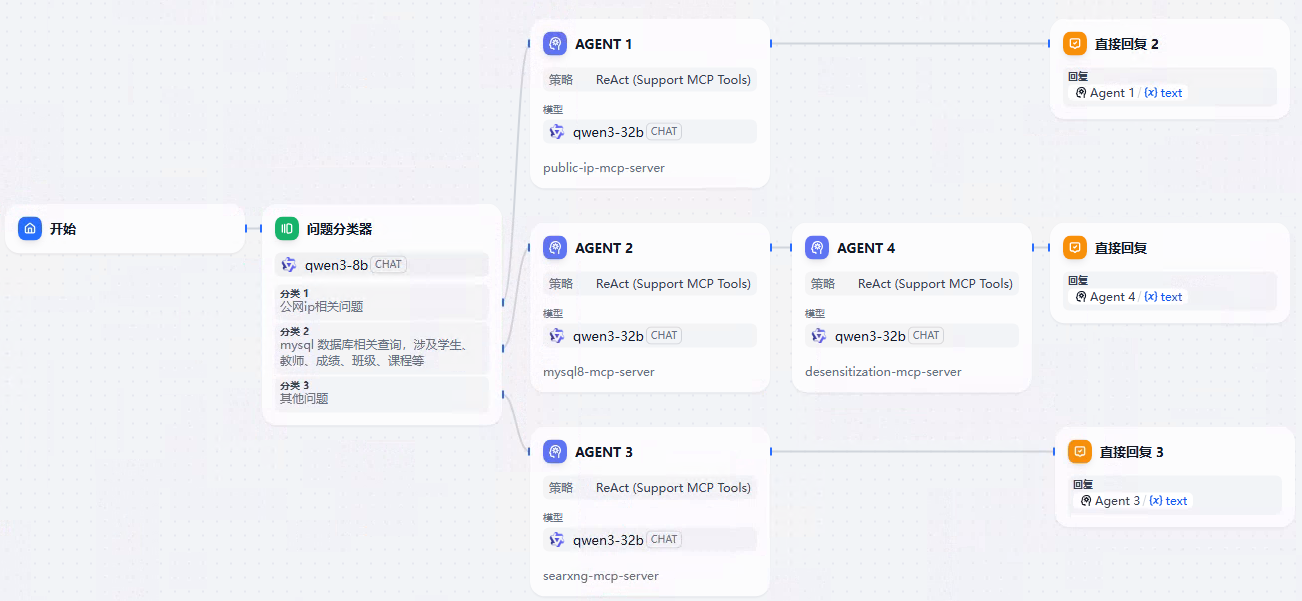
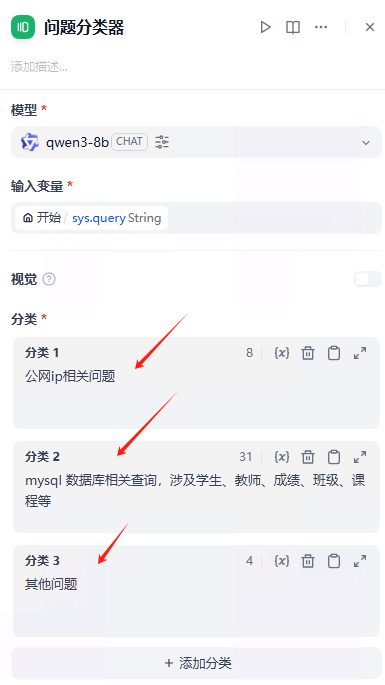
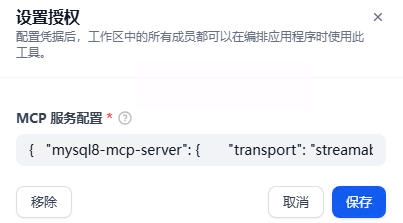
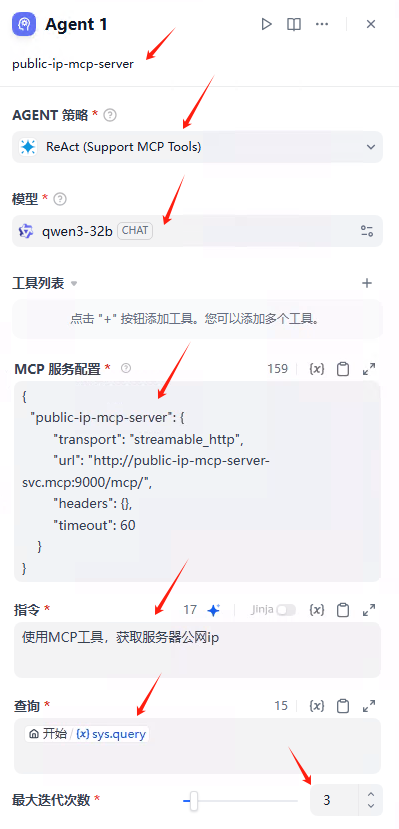
来源: Agent Neo – Flowith推出的AI Agent,能持续不断地执行任务 | AI工具集
Agent Neo是什么
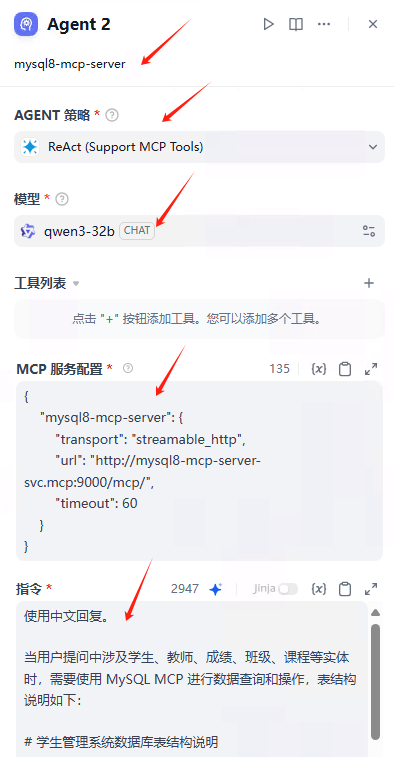
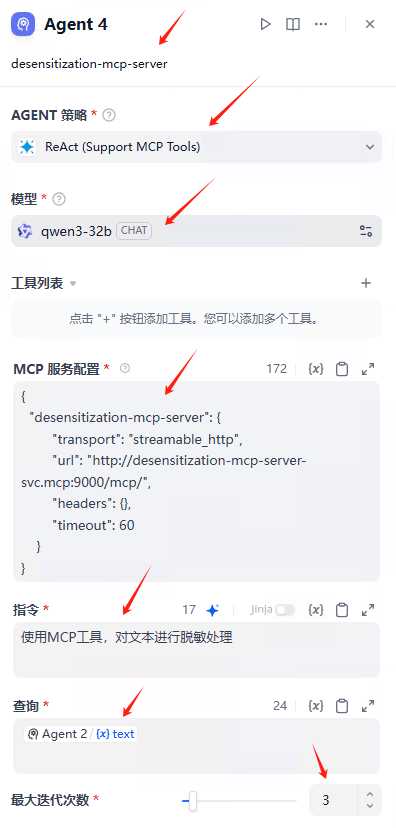
Agent Neo是Flowith推出的创新 AI Agent。Agent Neo具备无限步骤,无限上下文,无限工具的核心能力,能持续执行复杂任务、处理海量信息和调用多种大模型与工具。Agent Neo 结合 Flowith 的知识库功能,用户上传知识库,能快速构建数字分身或生成高质量内容。Flowith 提供Agent社区,用户能将自己的工作流做成 Recipe 分享到社区里。Agent Neo交互界面美观且富有创意,提供透明化的工作流程,适用于复杂任务自动化、知识管理与分享等场景。Agent Neo目前为邀请制,需激活码使用。

Agent Neo的主要功能
- 无限步骤(Unlimited Steps):Agent Neo能进行无限深度的推理,支持持续不断地工作,能执行需要长时间运行的复杂任务。
- 多步骤优化(Multi-step Refinement):基于多个步骤优化网页,提供最佳的结果。
- 24/7云端执行(24/7 Cloud Execution):支持全天候云端执行任务,用户的设备处于休眠状态,任务也能不间断地运行。
- 无限输出长度(Unlimited Output Length):支持生成任意长度的响应,不会出现内容截断的情况。
- 超智能重新规划(Super-Intelligent Re-Planning):在执行过程中,根据最终目标智能地调整计划。
Agent Neo的官方示例
- Prompt:Please generate a detailed ‘The Hunger Games’ setting collection, and draw rich and detailed illustrations based on the content of the book. The final presentation form is an immersive experience website with rich animation effects. Please ensure that all key content has correct diagrams. You need to generate relevant content in batches to ensure that each major element has a relevant visual image and picture.(请生成详细的《饥饿游戏》背景集,根据书中的内容绘制丰富而详细的插图。最终呈现形式是一个具有丰富动画效果的沉浸式体验网站。请确保所有关键内容都有正确的图表。你需要批量生成相关内容,确保每个主要元素都有相关的视觉图像和图片。”)

- Prompt:introduce flowith 2.0.(介绍 Flowith 2.0)

Agent Neo的性能表现
Agent Neo 在通用 AI Agent 能力测试 GAIA 中表现出色,刷新所有难度级别的最新最佳性能评分。

如何使用Agent Neo
- 获取邀请码:Agent Neo目前为邀请制,需获取激活码后使用。
- 注册并登录:访问 Flowith 官方网站,完成注册,用邀请码登录。
- 进入 Agent Neo 模式:在 Flowith 平台中找到打开 Agent Mode,调用 Agent Neo。
- 设置任务:
- 输入任务描述:告诉 Agent Neo 想要完成的任务,例如生成报告、创建网页、续写故事等。
- 选择或上传知识库:如果任务需要特定的知识背景,选择已有的知识库或上传相关文档,让 Agent Neo 从中获取信息。
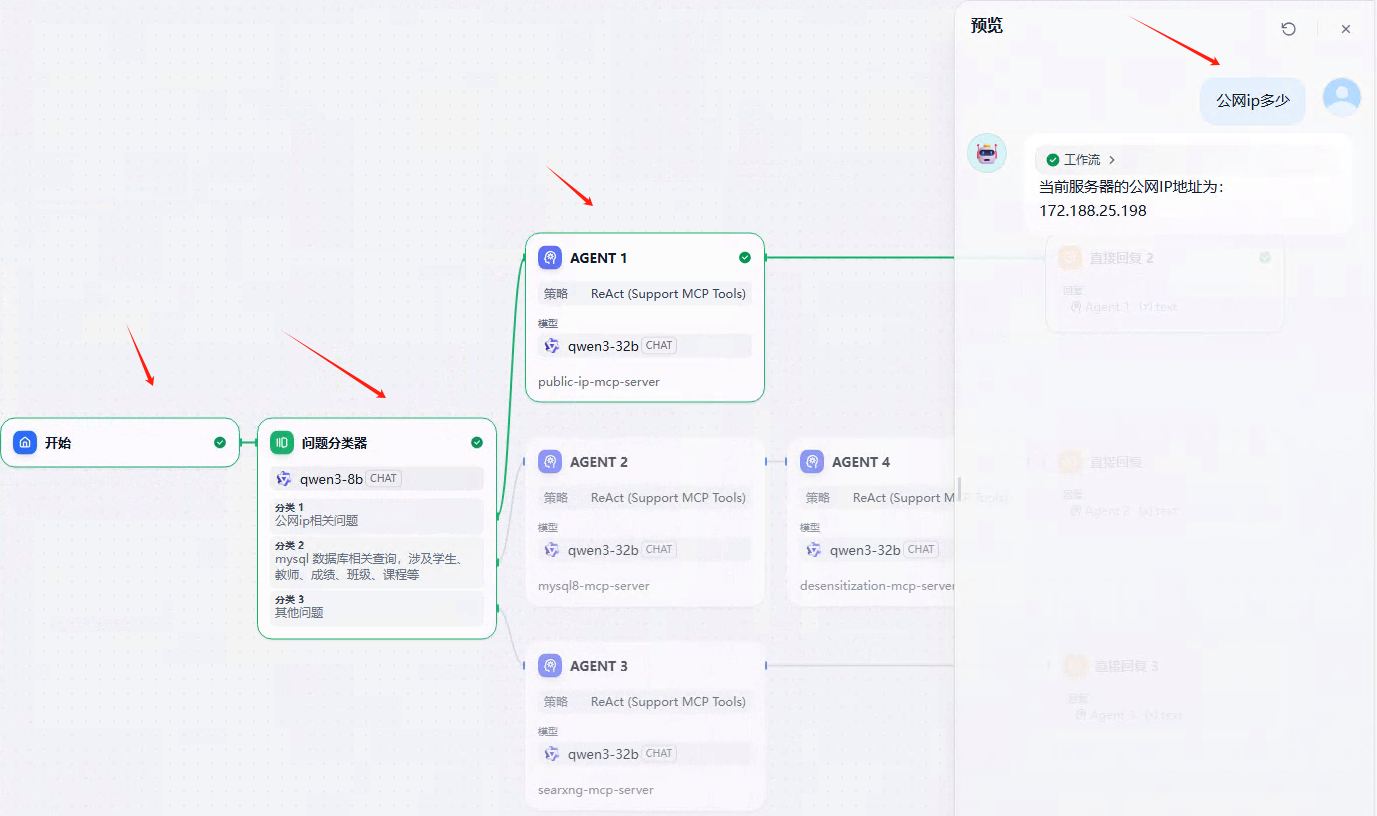
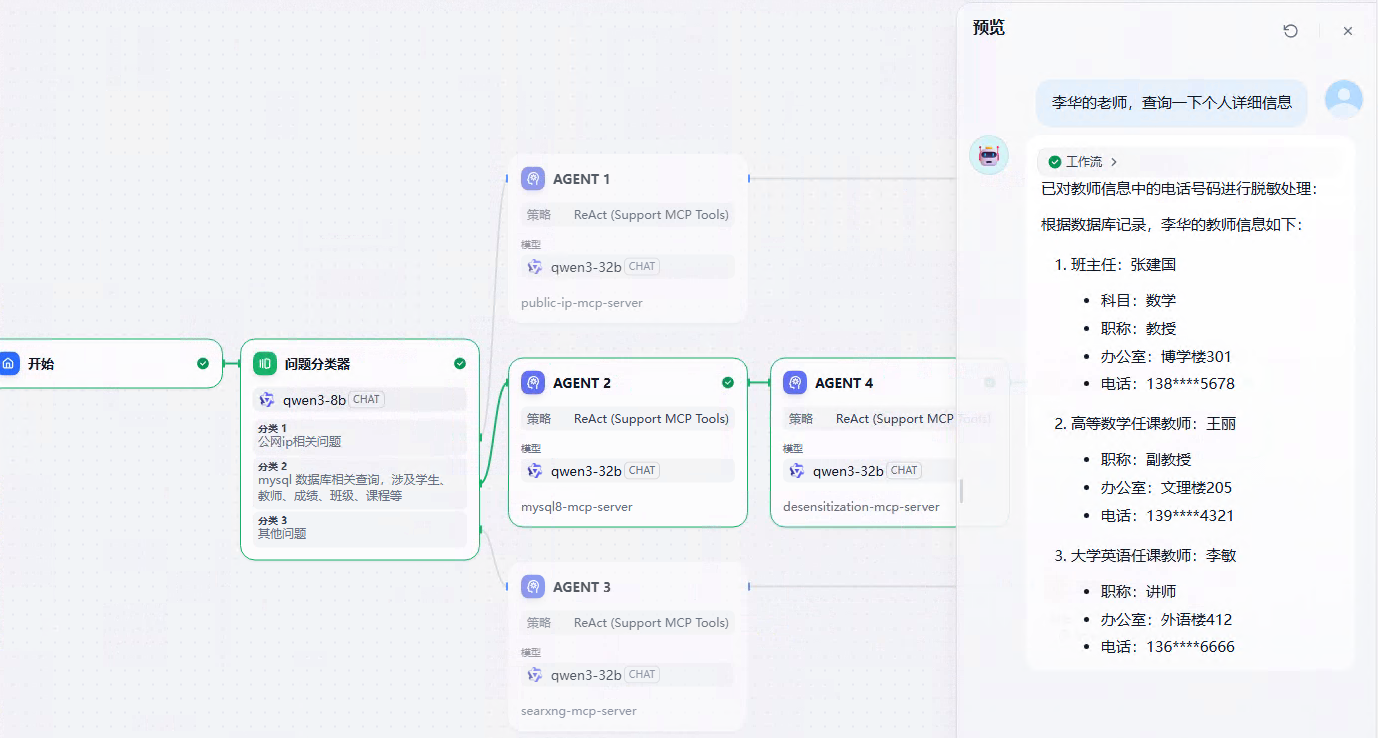
- 任务规划:Agent Neo 自动规划任务的工作流,包括信息搜集、内容生成、工具调用等。
- 实时交互:在任务执行过程中,Agent Neo 根据需要与用户交互,例如确认信息、获取反馈或调整任务方向。
- 查看结果:任务完成后,将结果呈现给用户,例如生成的网页、文档或报告。
- 修改结果:用户根据需要对生成的内容进行修改或优化,Agent Neo 支持用户直接在可视化界面或代码层面进行调整。
- 保存工作流:用户将完成的任务保存为工作流(Recipe),方便后续复用或分享给其他用户。
- 社区分享:将工作流发布到 Flowith 的 Agent 社区,与其他用户共享经验和创意。
Agent Neo的应用场景
- 自动化任务执行:自动执行重复性任务,如数据收集、报告生成和监控任务,提高效率和准确性。
- 复杂项目管理:基于无限步骤和深度推理来规划和管理项目,直至完成。
- 内容创作与编辑:续写故事、生成文章或优化网页内容,支持创意写作和多步骤内容精炼。
- 知识库构建与应用:用户上传和分析知识库,提高任务执行的精准性和效率。
- 数字分身创建:创建具有专业知识和历史记忆的数字分身,模拟对话或自动化客户服务。