作者:林学鹏
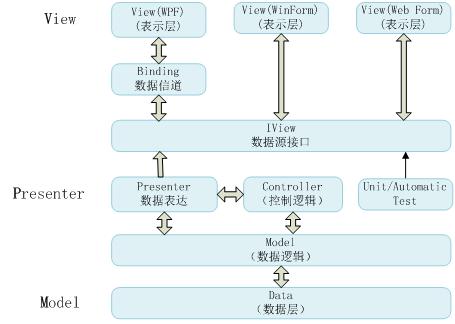
ORM的全称是Object Relational Mapping,即对象关系映射。它的实质就是将关系数据(库)中的业务数据用对象的形式表示出来,并通过面向对象(Object-Oriented)的 方式将这些对象组织起来,实现系统业务逻辑的过程。在ORM过程中最重要的概念是映射(Mapping),通过这种映射可以使业务对象与数据库分离。从面 向对象来说,数据库不应该和业务逻辑绑定到一起,ORM则起到这样的分离作用,使数据库层透明,开发人员真正的面向对象。图 1简单说明了ORM在多层系统架构中的这个作用。

图1:ORM在多层系统架构中的作用
目 前大多数项目或产品都使用关系型数据库实现业务数据的存储,这样在开发过程中,常常有一些业务逻辑需要直接用写SQL语句实现,但这样开发的结果是:遍地 布满SQL语句。这些高藕合的SQL语句给系统的改造和升级带来很多无法预计的障碍。为了提高项目的灵活性,特别是快速开发,ORM是一个不错的选择。举 个简单的例子:在使用ORM的系统中,当数据库模型改变时,不再需要理会逻辑代码和SQL语句中涉及到该模型的所有改动,只需要将该模型映射的对象稍作改 动,甚至不做改动就可以满足要求。

本页内容
一、ORM的工具实现:Grove
优秀的ORM工具不仅可以帮助我们很好的理解对象及对象的关系,而且工具本身会帮助我们维护这些关系。基于这个理念,我设计了基于.NET的ORM工具——Grove orM Development Toolkit。
Grove orM Development Toolkit包含Grove和Toolkit两部分内容。Grove为ORM提供对象持久、关系对象查询、简单事务处理、简单异常管理等功能。数据持久 包括一些对象的Insert、Delete、Update、Retrieve等功能,关系对象查询则提供一些基于对象的复杂关系查询,包括对应到数据库功 能的子查询、关联查询(JOIN)、函数支持(count、avg、max、min)、聚合等。Toolkit是基于VS.NET 2002/2003的VSIP开发的外接程序,职责是帮助开发人员快速映射关系数据库中的业务模型到符合Grove要求的映射实体类,以及映射数据库中复 杂关系查询到Grove要求的关系映射实体,暂时只提供C#支持。图 2是Grove内部类实现关系图。

图 2: Grove内部类实现关系图
在ORM实现的前期工作中,为了实现屏蔽各种数据库之间的操作差异,我们需要定义数据操作公有接口,封装基本的数据库Insert,Update,Delete,Query等操作。
public interface IDbOperator
{
int ExecNonQuery(string cmdText);
int ExecDataSet(string cmdText,DataSet entity);
object ExecScalar(string cmdText);
…
}
再定义一个数据库操作工厂类,实现各种不同类型数据的适配。
public abstract class DbOperatorFactory:IDbOperator
然后实现各种数据库的操作类,以SQLServer为例。
internal class SqlDbOperator:DbOperatorFactory
完成后,就是ORM主角——实体(Entity)的实现。ORM中实体的定义可以通过实体类自身包含数据模型元数据的方式实现,也可以通过定义XML的元描述实现。下面讲述了通过实体类自身映射的实现。
实 体(Entity)是实际业务数据的载体,包含业务数据模型的元描述,可以直接由数据库中的某张表或视图生成,也可以根据需要手工创建。.NET中提供了 System.Attribute,该类包含访问和测试自定义属性的简便方法。.NET Framework预定义了一些属性类型并使用它们控制运行时行为。我们可以通过继承System.Attribute基类自定义用于描述实体对象映射时 所需要的数据模型元数据,包括表名,字段名,字段长度,字段类型等一些常用的数据。
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Struct)]
public class DataTableAttribute : Attribute
AttributeUsage用来表示该自定义属性可以被绑定在什么样的对象上,这里表示应用在Class或者Struct之上。
抽象一些具有相同特征的属性,使之成为自定义属性的基类。
[AttributeUsage(AttributeTargets.Property)]
public class BaseFieldAttribute:Attribute
定义一般字段所需要的自定义属性类。
[AttributeUsage(AttributeTargets.Property)]
public class DataFieldAttribute : BaseFieldAttribute
定义关键字字段所需的自定义属性类。
[AttributeUsage(AttributeTargets.Property)]
public class KeyFieldAttribute : BaseFieldAttribute
定义外键字段所需要的自定义属性类。
[AttributeUsage(AttributeTargets.Property)]
public class ForeignKeyFieldAttribute : BaseFieldAttribute
在以上自定义属性类完成后,我们需要一个用于访问实体在运行期绑定的自定义属性及属性数据的一个Help类。
internal class TypeHelper
实体定义完成后,我们需要根据实体类中绑定的自定义属性构造出运行期需要的SQL语句,为了收集实体类定义中的数据结构描述,我们需要定义一个类来说明实体在运行期所引用到的所有关于数据持久的信息,包括关键字字段,外键字段,一般字段等。
internal class TypeInfo
同时需要一个字段元数据描述类,描述字段在数据库中的名称,大小,是否可为空,列类型等信息。
internal class ColumnInfo
以上条件具备后,我们需要定义一个解析类,负责转换数据的程序类型到数据库字段类型,并且构造出Insert,Update,Delete,Query等操作所需要的SQL语句。
internal class SqlEntityParser
将上面的操作组合起来就是实体类对象操作员。
public class ObjectOperator
实现新增一个记录到数据库中,就是创建了一个新的实体对象,并交由对象操作员进行持久化。
public void Insert(object o)
{
TypeInfo info1=new TypeInfo(o.GetType());//根据实例或者实体描述信息
SQLCommand sc=info1.BuildInsertCommand(o);//构造SQL命令对象
DbOperator.Parameters=sc.Parameters;//赋值SQL命令所需的参数
DbOperator.ExecNonQuery(sc.CommandText);//执行SQL命令
}
这里的SQLCommand对象封装了SQL命令处理时所需要的一些值,包含SQL语句,命令参数(Parameter)等。
二、Grove在开发中的实际应用
安装Grove Kit要求Visual Studio 2003 及.NET Framework 1.1支持。从Grove网站下载安装包之后,解压缩GroveKit.zip,执行安装。
在GroveKit安装结束后,打开VS.NET,在VS.NET的启动画面上,您会看到Grove Develop Kit的标志,表示GroveKit已被正确安装。
2.1生成映射实体类
本文将以C# 项目为例解释Grove在开发中的具体应用。项目名WebApp1,操作系统 Windows 2000,数据库SQL Server 2000,数据库实例名:WebApp1,表结构定义如下:
|
Customers
|
CustomerID int(4) PK
CustomerName varchar(50)
CustomerDesc varchar(200)
Status tinyint
|
|
Addresses
|
AddressID int(4) PK
CustomerID int(4) FK
Address varchar(200)
|
|
1.
|
在 VS.NET中,打开“文件->新建->项目”,在Visual C#项目选择ASP.NET WEB应用程序,确定后生成WebApp1项目,在项目中添加对Grove.dll的引用,Grove.dll位于GroveKit的安装路径下,您也可 以通过.NET Configuration将Grove添加到程序集缓存中。
|
|
2.
|
在VS.NET中,打开“工具->Grove Tool Kit”,在GroveToolKit中设置数据库连接属性,并保存。

图3 设置数据库连接串
|
|
3.
|
配置当前Web项目的web.config(在</configuration>之前加入以下配置)
<appSettings>
<add key="DBConnString" value="Server=localhost;Uid=sa;Pwd=sa;Database=WebApp1" />
</appSettings>
|
|
4.
|
4)在VS.NET解决方案资源管理器中选中Entities,并在GroveToolKit中选择表名,点击GroveToolKit的toolbar中的Preview Entity Class按钮,出现该表的实体映射类预览窗口。

图4 预览实体映射类
|
|
5.
|
检查当前预览的实体类,点击生成文件按钮,该实体类将被生成到解决方案资源管理器当前选中的路径下。
|
|
6.
|
重复4,5步骤就可以生成其他表的映射实体类。
Customer.cs
using System;
using Grove.ORM;
[DataTable("Customers")]
public class Customer
{
int _CustomerID;
string _CustomerName;
string _CustomerDesc;
int _Status;
[KeyField("CustomerID")]
public int CustomerID
{
get{return this._CustomerID;}
set{this._CustomerID=value;}
}
[DataField("CustomerName")]
public string CustomerName
{
get{return this._CustomerName;}
set{this._CustomerName=value;}
}
[DataField("CustomerDesc")]
public string CustomerDesc
{
get{return this._CustomerDesc;}
set{this._CustomerDesc=value;}
}
[DataField("Status")]
public int Status
{
get{return this._ Status;}
set{this._ Status=value;}
}
}
Address.cs
using System;
using Grove.ORM;
[DataTable("Addresses")]
public class Address
{
int _AddressID;
int _CustomerID;
string _Address;
[KeyField("AddressID")]
public int AddressID
{
get{return this._AddressID;}
set{this._AddressID=value;}
}
[ForeignKeyField("CustomerID")]
public int CustomerID
{
get{return this._CustomerID;}
set{this._CustomerID=value;}
}
[DataField("Address")]
public string CustomerAddress
{
get{return this._Address;}
set{this._Address=value;}
}
}
代码1.实体映射类
|
2.2对象持久化
Grove提供ObjectOperator实现对映射实体对象的数据库持久工作,并通过IObjectQuery接口实现对复杂数据库关系映射实体的查询,主要接口如下:
|
Insert
|
新增一个对象
|
|
Update
|
根据条件更新一个对象
|
|
Remove
|
根据条件删除一个对象
|
|
RemoveChilds
|
删除所有关系对象
|
|
Retrieve
|
返回一个对象
|
|
RetrieveChilds
|
返回所有关系对象
|
|
GetDataReader
|
返回IDataReader
|
|
GetObjectSet
|
返回对象集合
|
|
GetObjectSource
|
根据对象定义返回DataSet
|
|
GetCount
|
从数据源返回记录条数
|
|
BeginTranscation
|
在数据库支持事务的基础上,开始事务处理
|
|
Commit
|
完成当前事务
|
|
Rollback
|
回退当前事务
|
2.3数据查询
如 一般的关系型数据库所具有的查询功能一样,Grove也有着非常丰富的查询功能,如对象查询、函数查询、子查询、排序查询等。这里对对象查询做简单介绍, 其它查询读者可以自行参考Grove的开发文档。Grove提供ObjectQuery 帮助ObjectOperator从数据源查询数据, ObjectOperator 需要通过ObjectQuery解析实体对象中的属性(System.Arrtibute)定义,并构造查询语句。ObjectQuery在运行时往往需 要定义筛选语句(请参考筛选语句的语法定义)。例如,检索Customer对象,当State 属性等于WA的情况:
ObjectQuery query=new ObjectQuery(typeof(Customer),"this.State='WA'");
当检索需要返回所有对象时,则不需要定义筛选语句
ObjectQuery query=new ObjectQuery(typeof(Customer),"");
2.4筛选语句的语法定义
在ObjectQuery中使用的筛选允许你在定义的时候,根据使用面向对象语法规则进行定义筛选语句。
|
!, not
|
用于比较布尔型,例如:
!Order.CustomerID.Contains(Customer.CustomerID)
|
|
<, >, <= , >=
|
用于值比较,例如:
Order.Quantity >= 12
|
|
=, !=, <>, = =
|
用于值判断,例如:
Customer.Country = 'USA' and Customer.Region != 'WA'
|
|
and, &&
|
用于逻辑判断,例如:
Customer.Country = 'USA' and Customer.Region = 'WA'
|
|
or, ||
|
用于逻辑判断,例如:
Customer.LastName = 'Smith' or Customer.LastName = 'Jones'
|
三、总结
以 上就是ORM的简单实现,复杂的关系对象映射及关系映射实体的查询也是ORM中尤为重要的一块处理,为了屏蔽各数据库之间的SQL差异,很多好的ORM框 架都提供一种符合面向对象语言本身语法规则的Query Language支持,例如实现对数据库函数的支持时,会通过定义一些公开的,与编程语言接近的语言来实现,比如说定义 Object.Size(),Object.Sum()等类方法式操作语法,在逻辑判断的时候提供一些语言本身的逻辑运算符支持,比如c#中 的&&表示and,||表示or等等这些一系列的面向对象编程风格的支持,都很好地为基于关系型数据库支持的系统开发向“面向对象”提供 了有力的支持。Grove目前对关系对象查询有很好的支持,感兴趣可以到Grove的网站了解详细信息。