最近发现现有框架的通用查询存储过程的性能慢,于是仔细研究了下代码:
Alter PROCEDURE [dbo].[AreaSelect]
@PageSize int=0,
@CurrentPage int=1,
@Identifier int=NULL,
@ParentId int=NULL,
@AreaLevel int=NULL,
@Children int=NULL,
@AreaName nvarchar(50)=NULL,
@Path nvarchar(MAX)=NULL,
@Status int=NULL,
@Alt int=NULL
AS
BEGIN
SET NOCOUNT ON;
IF (NOT @AreaName IS NULL) SET @AreaName='%'+@AreaName+'%'
IF (NOT @Path IS NULL) SET @Path='%'+@Path+'%'
IF (@PageSize>0)
BEGIN
DECLARE @TotalPage int
Select @TotalPage=Count(Identifier) FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
IF(@TotalPage%@PageSize=0)
BEGIN
SET @TotalPage=@TotalPage/@PageSize
END
ELSE
BEGIN
SET @TotalPage=Round(@TotalPage/@PageSize,0)+1
END
Select TOP (@PageSize) Identifier,ParentId,AreaLevel,Children,AreaName,Path,Status,Alt,@TotalPage as totalPage FROM Area Where
Identifier NOT IN (Select Top (@PageSize*(@CurrentPage-1))Identifier FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc)
AND
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc
END
ELSE
BEGIN
Select Identifier,ParentId,AreaLevel,Children,AreaName,Path,Status,Alt FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc
END
END
发现每次查询都需要按条件查询依次Area表,性能太低,于是利用临时表将符合条件的记录取出来,然后针对临时表进行查询,代码修改如下:
Alter PROCEDURE [dbo].[AreaSelect]
@PageSize int=0,
@CurrentPage int=1,
@Identifier int=NULL,
@ParentId int=NULL,
@AreaLevel int=NULL,
@Children int=NULL,
@AreaName nvarchar(50)=NULL,
@Path nvarchar(MAX)=NULL,
@Status int=NULL,
@Alt int=NULL
AS
BEGIN
SET NOCOUNT ON;
IF (NOT @AreaName IS NULL) SET @AreaName='%'+@AreaName+'%'
IF (NOT @Path IS NULL) SET @Path='%'+@Path+'%'
IF (@PageSize>0)
BEGIN
–创建临时表
Select
Identifier,ParentId,AreaLevel,Children,AreaName,Path,Status,Alt
INTO #temp_Area
FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc
DECLARE @TotalPage int
DECLARE @SumCount int
–取总数
Select @SumCount=Count(Identifier) FROM #temp_Area
IF(@SumCount%@PageSize=0)
BEGIN
SET @TotalPage=@SumCount/@PageSize
END
ELSE
BEGIN
SET @TotalPage=Round(@SumCount/@PageSize,0)+1
END
Select TOP (@PageSize) Identifier,ParentId,AreaLevel,Children,AreaName,
Path,Status,Alt,@TotalPage as totalPage,@SumCount as SumCount
FROM #temp_Area
Where
Identifier NOT IN (Select Top (@PageSize*(@CurrentPage-1))Identifier FROM #temp_Area))
END
ELSE
BEGIN
Select Identifier,ParentId,AreaLevel,Children,AreaName,Path,Status,Alt FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc
END
END
经过使用临时表的确提高性能,不过有发现一个问题,就是count(Identifier)的确很耗性能,于是又进行修改了
:
Alter PROCEDURE [dbo].[AreaSelect]
@PageSize int=0,
@CurrentPage int=1,
@Identifier int=NULL,
@ParentId int=NULL,
@AreaLevel int=NULL,
@Children int=NULL,
@AreaName nvarchar(50)=NULL,
@Path nvarchar(MAX)=NULL,
@Status int=NULL,
@Alt int=NULL
AS
BEGIN
SET NOCOUNT ON;
IF (NOT @AreaName IS NULL) SET @AreaName='%'+@AreaName+'%'
IF (NOT @Path IS NULL) SET @Path='%'+@Path+'%'
IF (@PageSize>0)
BEGIN
–创建中记录数
DECLARE @SumCount int
–创建临时表
Select
Identifier,ParentId,AreaLevel,Children,AreaName,Path,Status,Alt
INTO #temp_Area
FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc
–设置总记录数为刚操作的记录数
SET @SumCount=@@RowCount
DECLARE @TotalPage int
IF(@SumCount%@PageSize=0)
BEGIN
SET @TotalPage=@SumCount/@PageSize
END
ELSE
BEGIN
SET @TotalPage=Round(@SumCount/@PageSize,0)+1
END
Select TOP (@PageSize) Identifier,ParentId,AreaLevel,Children,AreaName,
Path,Status,Alt,@TotalPage as totalPage,@SumCount as SumCount
FROM #temp_Area
Where
Identifier NOT IN (Select Top (@PageSize*(@CurrentPage-1))Identifier FROM #temp_Area))
END
ELSE
BEGIN
Select Identifier,ParentId,AreaLevel,Children,AreaName,Path,Status,Alt FROM Area Where
(@Identifier IS NULL or Identifier=@Identifier)AND
(@ParentId IS NULL or ParentId=@ParentId)AND
(@AreaLevel IS NULL or AreaLevel=@AreaLevel)AND
(@Children IS NULL or Children=@Children)AND
(@AreaName IS NULL or AreaName Like @AreaName)AND
(@Path IS NULL or Path Like @Path)AND
(@Status IS NULL or Status=@Status)AND
(@Alt IS NULL or Alt=@Alt)
order by AreaName asc
END
END

[SQL]利用@@RowCount优化性能
每次我们在使用查询分析器调试SQL语句的时候,通常会看到一些信息,提醒我们当前有多少个行受到了影响,这是些什么信息?在我们调用的时候这些信息有用吗?是否可以关闭呢?
答案是这些信息在我们的客户端的应用程序中是没有用的,这些信息是存储过程中的每个语句的DONE_IN_PROC 信息。
我们可以利用SET NOCOUNT 来控制这些信息,以达到提高程序性能的目的。
MSDN中帮助如下:
SET NOCOUNT
使返回的结果中不包含有关受 Transact-SQL 语句影响的行数的信息。
语法
SET NOCOUNT { ON | OFF }
注释
当 SET NOCOUNT 为 ON 时,不返回计数(表示受 Transact-SQL 语句影响的行数)。当 SET NOCOUNT 为 OFF 时,返回计数。
即使当 SET NOCOUNT 为 ON 时,也更新 @@ROWCOUNT 函数。
当 SET NOCOUNT 为 ON 时,将不给客户端发送存储过程中的每个语句的 DONE_IN_PROC 信息。当使用 Microsoft SQL Server 提供的实用工具执行查询时,在 Transact-SQL 语句(如 Select、Insert、Update 和 Delete)结束时将不会在查询结果中显示"nn rows affected"。
如果存储过程中包含的一些语句并不返回许多实际的数据,则该设置由于大量减少了网络流量,因此可显著提高性能。
SET NOCOUNT 设置是在执行或运行时设置,而不是在分析时设置。
权限
SET NOCOUNT 权限默认授予所有用户。
结论:我们应该在存储过程的头部加上SET NOCOUNT ON 这样的话,在退出存储过程的时候加上 SET NOCOUNT OFF这样的话,以达到优化存储过程的目的。
多说两句:
1:在查看SQLServer的帮助的时候,要注意“权限”这一节,因为某些语句是需要一定的权限的,而我们往往忽略。
2:@@ROWCOUNT是返回受上一语句影响的行数,包括找到记录的数目、删除的行数、更新的记录数等,不要认为只是返回查找的记录数目,而且@@ROWCOUNT要紧跟需要判断语句,否则@@ROWCOUNT将返回0。
3:如果使用表变量,在条件表达式中要使用别名来替代表名,否则系统会报错。
4:在CUD类的操作中一定要有事务处理。
5:使用错误处理程序,用来检查 @@ERROR 系统函数的 T-SQL 语句 (IF) 实际上在进程中清除了 @@ERROR 值,无法再捕获除零之外的任何值,必须使用 SET 或 Select 立即捕获错误代码。
[SQL]排名函数是SQL Server2005新加的功能。在SQL Server2005中有如下四
1. row_number
2. rank
3. dense_rank
4. ntile
下面分别介绍一下这四个排名函数的功能及用法。在介绍之前假设有一个t_table表,表结构与表中的数据如图1所示:
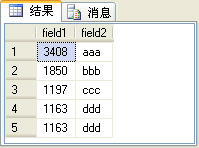
图1
其中field1字段的类型是int,field2字段的类型是varchar
一、row_number
row_number函数的用途是非常广泛,这个函数的功能是为查询出来的每一行记录生成一个序号。row_number函数的用法如下面的SQL语句所示:
select row_number() over(order by field1) as row_number,* from t_table
上面的SQL语句的查询结果如图2所示。
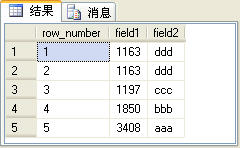
图2
其中row_number列是由row_number函数生成的序号列。在使用row_number函数是要使用over子句选择对某一列进行排序,然后才能生成序号。
实际上,row_number函数生成序号的基本原理是先使用over子句中的排序语句对记录进行排序,然后按着这个顺序生成序号。over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同,如下面的SQL语句所示:
select row_number() over(order by field2 desc) as row_number,* from t_table order by field1 desc
上面的SQL语句的查询结果如图3所示。
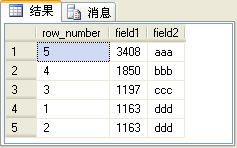
图3
我们可以使用row_number函数来实现查询表中指定范围的记录,一般将其应用到Web应用程序的分页功能上。下面的SQL语句可以查询t_table表中第2条和第3条记录:
with t_rowtable
as
(
select row_number() over(order by field1) as row_number,* from t_table
)
select * from t_rowtable where row_number>1 and row_number < 4 order by field1
as
(
select row_number() over(order by field1) as row_number,* from t_table
)
select * from t_rowtable where row_number>1 and row_number < 4 order by field1
上面的SQL语句的查询结果如图4所示。
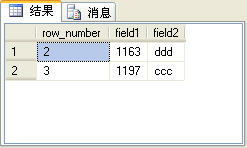
图4
上面的SQL语句使用了CTE,关于CTE的介绍将读者参阅《SQL Server2005杂谈(1):使用公用表表达式(CTE)简化嵌套SQL》。
另外要注意的是,如果将row_number函数用于分页处理,over子句中的order by 与排序记录的order by 应相同,否则生成的序号可能不是有续的。
当然,不使用row_number函数也可以实现查询指定范围的记录,就是比较麻烦。一般的方法是使用颠倒Top来实现,例如,查询t_table表中第2条和第3条记录,可以先查出前3条记录,然后将查询出来的这三条记录按倒序排序,再取前2条记录,最后再将查出来的这2条记录再按倒序排序,就是最终结果。SQL语句如下:
select * from (select top 2 * from( select top 3 * from t_table order by field1) a order by field1 desc) b order by field1
上面的SQL语句查询出来的结果如图5所示。
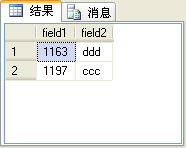
图5
这个查询结果除了没有序号列row_number,其他的与图4所示的查询结果完全一样。
二、rank
rank函数考虑到了over子句中排序字段值相同的情况,为了更容易说明问题,在t_table表中再加一条记录,如图6所示。
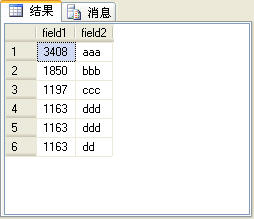
图6
在图6所示的记录中后三条记录的field1字段值是相同的。如果使用rank函数来生成序号,这3条记录的序号是相同的,而第4条记录会根据当前的记录 数生成序号,后面的记录依此类推,也就是说,在这个例子中,第4条记录的序号是4,而不是2。rank函数的使用方法与row_number函数完全相 同,SQL语句如下:
select rank() over(order by field1),* from t_table order by field1
上面的SQL语句的查询结果如图7所示。
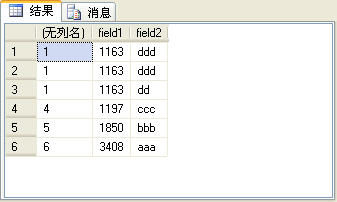
图7
三、dense_rank
dense_rank函数的功能与rank函数类似,只是在生成序号时是连续的,而rank函数生成的序号有可能不连续。如上面的例子中如果使用dense_rank函数,第4条记录的序号应该是2,而不是4。如下面的SQL语句所示:
select dense_rank() over(order by field1),* from t_table order by field1
上面的SQL语句的查询结果如图8所示。
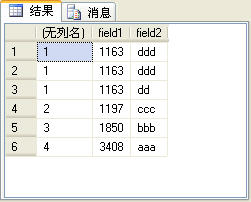
图8
读者可以比较图7和图8所示的查询结果有什么不同
四、ntile
ntile函数可以对序号进行分组处理。这就相当于将查询出来的记录集放到指定长度的数组中,每一个数组元素存放一定数量的记录。ntile函数为每条记 录生成的序号就是这条记录所有的数组元素的索引(从1开始)。也可以将每一个分配记录的数组元素称为“桶”。ntile函数有一个参数,用来指定桶数。下 面的SQL语句使用ntile函数对t_table表进行了装桶处理:
select ntile(4) over(order by field1) as bucket,* from t_table
上面的SQL语句的查询结果如图9所示。
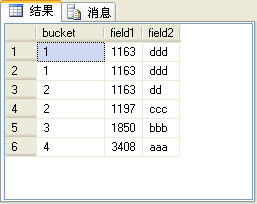
图9
由于t_table表的记录总数是6,而上面的SQL语句中的ntile函数指定了桶数为4。
也许有的读者会问这么一个问题,SQL Server2005怎么来决定某一桶应该放多少记录呢?可能t_table表中的记录数有些少,那么我们假设t_table表中有59条记录,而桶数是5,那么每一桶应放多少记录呢?
实际上通过两个约定就可以产生一个算法来决定哪一个桶应放多少记录,这两个约定如下:
1. 编号小的桶放的记录不能小于编号大的桶。也就是说,第1捅中的记录数只能大于等于第2桶及以后的各桶中的记录。
2. 所有桶中的记录要么都相同,要么从某一个记录较少的桶开始后面所有捅的记录数都与该桶的记录数相同。也就是说,如果有个桶,前三桶的记录数都是10,而第4捅的记录数是6,那么第5桶和第6桶的记录数也必须是6。
根据上面的两个约定,可以得出如下的算法:
// mod表示取余,div表示取整
if(记录总数 mod 桶数 == 0)
{
recordCount = 记录总数 div 桶数;
将每桶的记录数都设为recordCount
}
else
{
recordCount1 = 记录总数 div 桶数 + 1;
int n = 1; // n表示桶中记录数为recordCount1的最大桶数
m = recordCount1 * n;
while(((记录总数 – m) mod (桶数 – n)) != 0 )
{
n++;
m = recordCount1 * n;
}
recordCount2 = (记录总数 – m) div (桶数 – n);
将前n个桶的记录数设为recordCount1
将n + 1个至后面所有桶的记录数设为recordCount2
}
if(记录总数 mod 桶数 == 0)
{
recordCount = 记录总数 div 桶数;
将每桶的记录数都设为recordCount
}
else
{
recordCount1 = 记录总数 div 桶数 + 1;
int n = 1; // n表示桶中记录数为recordCount1的最大桶数
m = recordCount1 * n;
while(((记录总数 – m) mod (桶数 – n)) != 0 )
{
n++;
m = recordCount1 * n;
}
recordCount2 = (记录总数 – m) div (桶数 – n);
将前n个桶的记录数设为recordCount1
将n + 1个至后面所有桶的记录数设为recordCount2
}
根据上面的算法,如果记录总数为59,桶数为5,则前4个桶的记录数都是12,最后一个桶的记录数是11。
如果记录总数为53,桶数为5,则前3个桶的记录数为11,后2个桶的记录数为10。
就拿本例来说,记录总数为6,桶数为4,则会算出recordCount1的值为2,在结束while循环后,会算出recordCount2的值是1,因此,前2个桶的记录是2,后2个桶的记录是1。
[SQL]SQL Server 2005对海量数据的处理
超大型数据库的 大小常常达到数百GB,有时甚至要用TB来计算。而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长。这不但影响着数据库的运行效率,也增 大数据库的维护难度。除了表的数据量外,对表不同的访问模式也可能会影响性能和可用性。这些问题都可以通过对大表进行合理分区得到很大的改善。当表和索引 变得非常大时,分区可以将数据分为更小、更容易管理的部分来提高系统的运行效率。如果系统有多个CPU或是多个磁盘子系统,可以通过并行操作获得更好的性能。所以对大表进行分区是处理海量数据的一种十分高效的方法。本文通过一个具体实例,介绍如何创建和修改分区表,以及如何查看分区表。
SQL Server 2005是微软在推出SQL Server 2000后时隔五年推出的一个数据库平台,它的数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使用户可以构建和管理用于业务的高可用和高性能的数据应用程序。此外,SQL Server 2005结合了分析、报表、集成和通知功能。这使得企业可以构建和部署经济有 效的BI解决方案,帮助团队通过记分卡、Dashboard、Web Services和移动设备将数据应用推向业务的各个领域。无论是开发人员、数据库管理员、信息工作者还是决策者,SQL Server 2005都可以提供出创新的解决方案,并可从数据中获得更多的益处。
它所带来的新特性,如T-SQL的增强、数据分区、服务代理和与.Net Framework的集成等,在易管理性、可用性、可伸缩性和安全性等方面都有很大的增强。
2、表分区的具体实现方法
表分区分为水平分区和垂直分区。水平分区将表分为多个表。每个表包含的列数相同,但是行更少。例如,可以将一个包含十亿行的表水平分区成 12 个表,每个小表表示特定年份内一个月的数据。任何需要特定月份数据的查询只需引用相应月份的表。而垂直分区则是将原始表分成多个只包含较少列的表。水平分 区是最常用分区方式,本文以水平分区来介绍具体实现方法。
水平分区常用的方法是根据时期和使用对数据进行水平分区。例如本文例子,一个短信发送记录表包含最近一年的数据,但是只定期访问本季度的数据。在这种情况下,可考虑将数据分成四个区,每个区只包含一个季度的数据。
2.1、创建文件组
建立分区表先要创建文件组,而创建多个文件组主要是为了获得好的 I/O 平衡。一般情况下,文件组数最好与分区数相同,并且这些文件组通常位于不同的磁盘上。每个文件组可以由一个或多个文件构成,而每个分区必须映射到一个文件 组。一个文件组可以由多个分区使用。为了更好地管理数据(例如,为了获得更精确的备份控制),对分区表应进行设计,以便只有相关数据或逻辑分组的数据位于同一个文件组中。使用 Alter DATABASE,添加逻辑文件组名:
Alter DATABASE [DeanDB] ADD FILEGROUP [FG1]
DeanDB为数据库名称,FG1文件组名。创建文件组后,再使用 Alter DATABASE 将文件添加到该文件组中:
Alter DATABASE [DeanDB] ADD FILE ( NAME = N'FG1',
FILENAME = N'C:DeanDataFG1.ndf' , SIZE = 3072KB ,
FILEGROWTH = 1024KB ) TO FILEGROUP [FG1]
类似的建立四个文件和文件组,并把每一个存储数据的文件放在不同的磁盘驱动器里。
2.2、创建分区函数
创建分区表必须先确定分区的功能机制,表进行分区的标准是通过分区函数来决定的。创建数据分区函数有RANGE “LEFT | / RIGHT”两种选择。代表每个边界值在局部的哪一边。例如存在四个分区,则定义三个边界点值,并指定每个值是第一个分区的上边界 (LEFT) 还是第二个分区的下边界 (RIGHT)。代码如下:
Create PARTITION FUNCTION [SendSMSPF](datetime)
AS RANGE RIGHT FOR VALUES ('20070401', '20070701', '20071001')
2.3、创建分区方案
创建分区函数后,必须将其与分区方案相关联,以便将分区指向至特定的文件组。就是定义实际存放数据的媒体与各数据块的对应关系。多个数据表可以共用相同的 数据分区函数,一般不共用相同的数据分区方案。可以通过不同的分区方案,使用相同的分区函数,使不同的数据表有相同的分区条件,但存放在不同的媒介上。创 建分区方案的代码如下:
Create PARTITION SCHEME [SendSMSPS] AS PARTITION [SendSMSPF]
TO ([FG1], [FG2], [FG3], [FG4])
2.4、创建分区表
建立好分区函数和分区方案后,就可以创建分区表了。分区表是通过定义分区键值和分区方案相联系的。插入记录时,SQL SERVER会根据分区键值的不同,通过分区函数的定义将数据放到相应的分区。从而把分区函数、分区方案和分区表三者有机的结合起来。创建分区表的代码如 下:
Create TABLE SendSMSLog
([ID] [int] IDENTITY(1,1) NOT NULL,
[IDNum] [nvarchar](50) NULL,
[SendContent] NULL
[SendDate] [datetime] NOT NULL,
) ON SendSMSPS(SendDate)
2.5、查看分区表信息
系统运行一段时间或者把以前的数据导入分区表后,我们需要查看数据的具体存储情况,即每个分区存取的记录数,那些记录存取在那个分区等。我们可以通过$partition.SendSMSPF来查看,代码如下:
Select $partition.SendSMSPF(o.SendDate)
AS [Partition Number]
, min(o.SendDate) AS [Min SendDate]
, max(o.SendDate) AS [Max SendDate]
, count(*) AS [Rows In Partition]
FROM dbo.SendSMSLog AS o
GROUP BY $partition.SendSMSPF(o.SendDate)
ORDER BY [Partition Number]
在查询分析器里执行以上脚本。
2.6、维护分区
分区的维护主要设计分区的添加、减少、合并和在分区间转换。可以通过Alter PARTITION FUNCTION的选项SPLIT,MERGE和Alter TABLE的选项SWITCH来实现。SPLIT会多增加一个分区,而MEGRE会合并或者减少分区,SWITCH则是逻辑地在组间转换分区。
3、性能对比
我们对2650万数据,存储空间占用约4G的单表进行性能对比,测试环境为IBM365,CPU 至强2.7G*2、内存 16G、硬盘 136G*2,系统平台为Windows 2003 SP1+SQL Server 2005 SP1。
说明:
1、根据时间检索某一天记录所耗时间
2、单条记录插入所耗时间
3、根据时间删除某一天记录所耗时间
4、统计每月的记录数所需时间
从表1可以看出,对分区表进行操作比未分区的表要快,这是因为对分区表的操作采用了CPU和I/O的并行操作,检索数据的数据量也变小了,定位数据所耗时间变短。
4、结束语
对海量数据的处理一直是一个令人头痛的问题。分离的技术是所有设计者们首先考虑的问题,不管是分离应用程序功能还是分离数据访问,如果加以了合理规划,都 能十分有效的解决大数据表的运行效率低和维护成本高等问题。SQL Server 2005新增的表分区功能,可以对数据进行合理分区,当用户在访问部分数据时,SQL Server最佳化引擎可以根据数据的实体存放,找出最佳的执行方案,而不至于大海捞针。
[SQL] 加速SQL Server 2005中的表计数性能
【IT168 专稿】当我们希望获得一个表中符合条件的记录的行数时,一般借助于T-SQL函数count(*)来实现。不过,如果你的表中包含了数百万条记录,返回整个表的记录数可能需要花费较长时间,会导致查询性能非常低。
1.Count()函数
DBA们都知道如何使用count(*)函数,也知道它对性能的影响。SQL Server需要进行一次完整的索引/表扫描,才能返回表的记录总数。建议DBA不要针对这个表使用聚合函数count(),因为它会影响数据库的性能。 接下来我们在示例数据库AdventureWorkstation的查询分析器中执行以下查询语句:
use AdventureWorks
go
select count (*) from Sales.SalesOrderDetail
go
select count (*) from Sales.SalesOrderDetail
查询分析器返回的结果为121317行。
当我们点击SQL Server 2005 Management Studio工具栏中的“显示预计的执行计划”图标时,我们可以看到如下图示:

图1 查看count(*)执行计划
如上图所示,该函数执行过程中将从右至左执行如下操作:
•对整个表进行索引扫描,这是一个相当耗时的过程。
•接下来执行流聚合。
2.新方法row_count()
在SQL Server 2005的对象目录视图(Object Catalog Views)包含如下信息:sys.partitions和sys.allocation_units被用来获得整个表的记录总数。这个函数可以在SQL Server 2005中使用。
sys.partitions视图
sys.partitions视图包含了数据库中所有表和索引的每个分区在表中对应的每一行。即使SQL Server 2005中的所有表和索引并未显式分区,也至少在这个视图中包含一个分区。
该视图包含如下字段,它们将被用于这个新方法:
|
字段名称
|
数据类型
|
描述
|
|
partition_id
|
bigint
|
分区的ID,它在一个数据库中是唯一的。
|
|
object_id
|
int
|
分区所属表的ID。每个表至少包含一个分区。
|
|
index_id
|
int
|
分区所属对象内索引的ID。
0:heap表
1:具有集群索引
|
|
rows
|
bigint
|
分区中表的行数。
|
sys.allocation_units视图
sys.allocation_units视图包含了数据库中的每个分配单元在表中的每一行。
该视图中可以被新方法使用的字段如下:
|
字段名称
|
数据类型
|
描述
|
|
container_id
|
bigint
|
container_id=sys.partitions.partition_id
|
|
Type
|
tinyint
|
0 = 已删除
1 = 行内数据(除LOB之外的所有数据类型)
2 = 大型对象(LOB)数据(text、ntext、 image、xml)
3 = 行溢出数据
|
在这个新用户自定义函数row_count中,[sys.partitions]视图与[sys.allocation_units]视图是相关联的。过滤器的选择基于如下标准:
·[sys.allocation_units].type=1,只获得行数据,不包含诸如text、ntext、image等类型的大型对象。
·[sys.partitions].index_id为0表示是heap表,为1表示是集群表。
·[sys.partitions].rows不为空。
用户自定义函数row_count在每一个数据库中被执行,因此其权限为public。
函数代码
函数用法

表1
IF EXISTS (Select name FROM dbo.sysobjects Where id = Object_id(N'[dbo].[row_count]') )
Drop FUNCTION [dbo].[row_count]
GO
Create FUNCTION dbo.row_count (@table_name sysname)
— @table_name we want to get count
RETURNS bigint
/*
——————————————————-
— Function Name: row_count
— Author: Mohamed Hassan
— Email: moh_hassan20@yahoo.com
— Development Date: 08/11/2008
— Version: 1.0
— Description: Return row count of the whole table, as a replacement for count(*) , give extra performance at least 70% over , than count(*) for large tables with millions of rows
— SQL Server: SQL server 2005
— Usage Example: select dbo.row_count ('Sales.SalesOrderDetail')
— Copyright:
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of the
License, or any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
——————————————————-
*/
AS
BEGIN
DECLARE @nn bigint — number of rows
IF @table_name IS NOT NULL
BEGIN
Select @nn = sum( p.rows )
FROM sys.partitions p
LEFT JOIN sys.allocation_units a ON p.partition_id = a.container_id
Where
p.index_id in(0,1) — 0 heap table , 1 table with clustered index
and p.rows is not null
and a.type = 1 — row-data only , not LOB
and p.object_id = object_id(@table_name)
END
RETURN (@nn)
END
GO
Drop FUNCTION [dbo].[row_count]
GO
Create FUNCTION dbo.row_count (@table_name sysname)
— @table_name we want to get count
RETURNS bigint
/*
——————————————————-
— Function Name: row_count
— Author: Mohamed Hassan
— Email: moh_hassan20@yahoo.com
— Development Date: 08/11/2008
— Version: 1.0
— Description: Return row count of the whole table, as a replacement for count(*) , give extra performance at least 70% over , than count(*) for large tables with millions of rows
— SQL Server: SQL server 2005
— Usage Example: select dbo.row_count ('Sales.SalesOrderDetail')
— Copyright:
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Lesser General Public License as
published by the Free Software Foundation, either version 3 of the
License, or any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
——————————————————-
*/
AS
BEGIN
DECLARE @nn bigint — number of rows
IF @table_name IS NOT NULL
BEGIN
Select @nn = sum( p.rows )
FROM sys.partitions p
LEFT JOIN sys.allocation_units a ON p.partition_id = a.container_id
Where
p.index_id in(0,1) — 0 heap table , 1 table with clustered index
and p.rows is not null
and a.type = 1 — row-data only , not LOB
and p.object_id = object_id(@table_name)
END
RETURN (@nn)
END
GO
函数用法
函数row_count被调用时,需要完整表名称schema.table name作为其输入参数。
例1:
选择dbo.row_count(schema.[table name]),如下面代码所示:
1 use AdventureWorks
use AdventureWorks
2go
3select dbo.row_count ('Sales.SalesOrderDetail')
use AdventureWorks2
go3
select dbo.row_count ('Sales.SalesOrderDetail')在查询分析器中,上述语句返回的结果为12317行,与前面使用count(*)返回的结果一致,但是其执行速度更快,性能更高。
例2:
Select top 5 TABLE_SCHEMA, TABLE_NAME, (TABLE_SCHEMA +'.'+TABLE_NAME) 'Full table name',
dbo.row_count(TABLE_SCHEMA +'.'+TABLE_NAME) rows
FROM INFORMATION_SCHEMA.TABLES
where TABLE_TYPE ='BASE TABLE'
ORDER BY rows desc
dbo.row_count(TABLE_SCHEMA +'.'+TABLE_NAME) rows
FROM INFORMATION_SCHEMA.TABLES
where TABLE_TYPE ='BASE TABLE'
ORDER BY rows desc
查询结果如下表:
表1
通过增加/删除行、截取表、批量插入/批量删除等操作详细的测试该函数,返回的结果与count(*)完全一致。
3.性能评测
我们将通过执行批处理命令来对比count(*)和用户自定义函数row_count的性能,如下代码所示:
select dbo.row_count ('Sales.SalesOrderDetail')
go
select count (*) from Sales.SalesOrderDetail
go
go
select count (*) from Sales.SalesOrderDetail
go
当查看执行计划时,我们发现第一个查询(row_count)的开销只占整个批处理开销的7%,用于此操作以及同一子树内此操作之前的所有操作的总开销只有0.03,如下图所示:
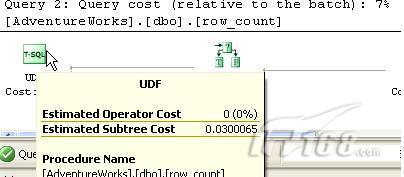
图2
而第二个查询(count(*))的开销则占整个批处理开销的93%,用于此操作以及同一子树内此操作之前的所有操作的总开销则为0.37,如下图所示:

图3
毫无疑问,用户自定义函数row_count()的性能是最好的,它占用了数据库极少的资源。两者的开销比例是93:7,这意味着row_count的性能比count(*)的性能高10倍多。
根据数据表的记录数不同,该对比结果可能会有所不同,但是总体来说,我们已经从中看出,新用户自定义函数要比count(*)函数好得多。在你需要获得整个表的记录数时,这个用户自定义函数可以大大提高你的查询语句性能。
4.结论
SQL Server 2005的内置函数count(*)在获得整个表的记录数时非常耗时,尤其对于具有数百万条记录的表时更是如此。
通过用户自定义函数“row_count”这个新方法,同样可以获得准确的结果,而且速度更快,可以获得更高的性能。
该函数可以在SQL Server 2005中使用,因为这些视图只有从这个版本才开始增加。
[C#]公交车路线查询系统后台数据库设计——换乘算法改进与优化
数据库下载 (该数据库已经输入了广州市350条公交车路线作为测试数据)
在《查询算法》 一文中已经实现了换乘算法,但是,使用存储过程InquiryT2查询从“东圃镇”到“车陂路口”的乘车路线时,发现居然用了5分钟才查找出结果,这样的 效率显然不适合实际应用。因此,有必要对原有的换乘算法进行优化和改进。在本文中,将给出一种改进的换乘算法,相比原有的算法,改进后的算法功能更强,效 率更优。
1. “压缩”RouteT0
假设RouteT0有以下几行

如下图所示,当查询S1到S4的二次换乘路线时,将会产生3×2×4=24个结果

从图中可以看出,第1段路线中的3条线路的起点和站点都相同(第2、3段路线也是如此),事实上,换乘查询中关心的是两个站点之间有无线路可通,而不关心是乘坐什么路线,因此,可以将RouteT0压缩为:

如下图所示,压缩后,查询结果有原来的24条合并1组

查询结果为:
![]()
那么,为什么要对视图RouteT0进行压缩呢,原因如下:
(1)RouteT0是原有换乘算法频繁使用的视图,因此,RouteT0的数据量直接影响到查询的效率,压缩RouteT0可以减少RouteT0的数据量,加速查询效率。
(2)压缩RouteT0后,将中转站点相同的路线合并为1组,加速了对结果集排序的速度。
2.视图GRouteT0
在数据库中,将使用GRouteT0来描述压缩的RouteT0,由于本文使用的数据库的关系图与《查询算法》中有所不同,在给出GRouteT0的代码前,先说明一下:

主要的改变是Stop_Route使用了整数型的RouteKey和StopKey引用Route和Stop,而不是用路线名和站点名。
GRouteT0定义如下:
create view GRouteT0
as
select
StartStopKey,
EndStopKey,
min(StopCount) as MinStopCount,
max(StopCount) as MaxStopCount
from RouteT0
group by StartStopKey,EndStopKey
as
select
StartStopKey,
EndStopKey,
min(StopCount) as MinStopCount,
max(StopCount) as MaxStopCount
from RouteT0
group by StartStopKey,EndStopKey
注意,视图GRouteT0不仅有StartStopKey和EndStopKey列,还有MinStopCount列,MinStopCount是指从StartStop到EndStop的最短线路的站点数。例如:上述RouteT0对应的GRouteT0为:

3.二次查询算法
以下是二次换乘查询的存储过程GInquiryT2的代码,该存储过程使用了临时表来提高查询效率:
4.测试
(1) 测试环境
测试数据:广州市350条公交车路线
操作系统:Window XP SP2
数据库:SQL Server 2000 SP4 个人版
CPU:AMD Athlon(tm) 64 X2 Dual 2.4GHz
内存:2G
(2)选择用于测试的的站点
二次换乘查询的select语句使用的三张表#R1,#R2,#R3,因此,这三张表的数据量直接影响到二次换乘查询使用的时间:
显然,R1的数据量由起点决定,查询起始站点对应的#R1的数据量的SQL语句如下:
select Stop.StopName as '站点',count(StartStopKey) '#R1的数据量'
from RouteT0 full join Stop on RouteT0.StartStopKey=Stop.StopKey
group by Stop.StopName
order by count(StartStopKey) desc
from RouteT0 full join Stop on RouteT0.StartStopKey=Stop.StopKey
group by Stop.StopName
order by count(StartStopKey) desc
运行结果如下:

显然,但起点为“东圃镇”时,#R1的数据量最大,同理可得终点和#R3数据量关系如下:

因此,在仅考虑数据量的情况下,查询“东圃镇”到“车陂路口”所用的时间是最长的。在下文中,将使用“东圃镇”作为起点,“车陂路口”为终点对二次查询算法进行效率测试
(3)效率测试
测试语句如下:
exec GInquiryT2 '东圃镇','车陂路口'
测试结果:
查询结果如下:

输出如下:
从消息窗口的信息可以看出,查询大概用了1秒
5.效率优化
用GInquiryT2查询“东圃镇”到“车陂路口”仅用了1秒钟,那么,还能不能再优化呢?仔细分析输出的结果,可发现查询时最耗时的并不是换乘查询语句(140ms),而是筛选出第2段查询路线的语句(825ms),如图所示:

那么有没有方法可以提高筛选第2段路线的效率呢?答案是肯定的。只需把GRouteT0改成实表,并创建索引就行了。修改成实表后,就不需要把第2段路线缓存到临时表#R2中,修改后的GInquiryT2(重命名为GInquiryT2_1)如下:
下面,仍然用查询“东圃镇”到“车陂路口”为例测试改成实表后GInquiryT2的效率,测试语句如下:
exec GInquiryT2_1 '东圃镇','车陂路口'
消息窗口输出如下:
从输出可以看出,大概用了250ms
6.展开路线组
GInquiryT2查询给出的结果是10组最短路线,那么,怎样才能得到最短的10条路线,显然,只需将这10组路线展开即可(展开后的路线 数>=10),而最短的10条路线必然在展开的结果中。查询10条最短路线的存储过程GInquiryT2_Expand如下:
下面,仍然以查询“东圃镇”到“车陂路口”为例测试GInquiryT2_Expand,代码如下:
exec GInquiryT2_Expand '东圃镇','车陂路口'
查询结果如下:
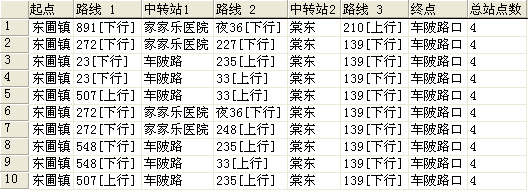
消息窗口输出如下:
由输出结果可看出,大约用了300ms
7.总结
下面,对本文使用的优化策略做一下总结:
(1)使用临时表;
(2)将频繁使用的视图改为表;
(3)从实际出发,合并RouteT0中类似的行,从而“压缩”RouteT0的数据量,减少查询生成的结果,提高查询和排序效率。
作者:
卢春城
转载:http://www.cnblogs.com/lucc/archive/2009/03/03/1401863.html
[SEO]个大搜索引擎网站提交入口
[应用]jimu:积木在线电脑
在网上看到了一个本土的 webOS :积木在线电脑 。它是一个基于 Flash 的应用,操作流畅,用户体验很好。功能也很强悍,内置了ZOHO提供的文档编辑功能和IM,还有一堆应用可以自主“安装”使用。

我觉得我的网速不是很好,但是使用起来基本没有卡的感觉,也没有把浏览器拖慢,作为一个全 Flash 的应用,我觉得很不容易,他们真的是用心在做。这里帮忙宣传一下,表示支持。
BTW,现在它们好像还是内测阶段,想要体验的可以点击下面的链接获取邀请:
http://ijimu.cn/?register=true&inviteCode=7298b866-5ddf-4e29-af1c-7ec174cff86c
本文链接: http://www.zhuoqun.net/html/y2009/1215.html 转载请注明出处,谢谢。
[SQL]SQL Server 2008中的用户自定义表类型
目前的批量删除和批量更新,很是烦人,解决方案无非三种:
XML,SQL自定义函数split,和CLR实现split。这几种都比较烦人,代码很多,维护麻烦,很不爽。
现在SQL2008新增的一个功能,我也不知道中文名怎么翻译,暂且叫他表参数吧。
大家可以看看示例:
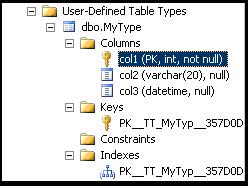
这个就是用户定义的表类型:
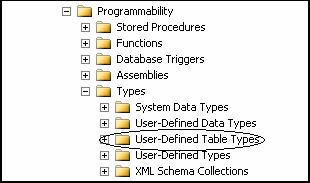
然后给他定义一个类型:
— ================================
— Create User-defined Table Type
— ================================
USE Test
GO
— Create the data type
Create TYPE dbo.MyType AS TABLE
(
col1 int NOT NULL,
col2 varchar(20) NULL,
col3 datetime NULL,
PRIMARY KEY (col1)
)
GO
可以看到,生成的表类型的组成情况,并且居然可以给表类型建立索引,呵呵
这个是操作 表类型的脚本:
DECLARE @MyTable MyType
Insert INTO @MyTable(col1,col2,col3)
VALUES (1,'abc','1/1/2000'),
(2,'def','1/1/2001'),
(3,'ghi','1/1/2002'),
(4,'jkl','1/1/2003'),
(5,'mno','1/1/2004')
Select * FROM @MyTable
下面演示如何将表参数作为一个存储过程参数传递,以及ADO.NET的代码
SQL部分:
USE [Test]
GO
Create TABLE [dbo].[MyTable] (
[col1] [int] NOT NULL PRIMARY KEY,
[col2] [varchar](20) NULL,
[col3] [datetime] NULL,
[UserID] [varchar] (20) NOT NULL
)
GO
Create PROC usp_AddRowsToMyTable @MyTableParam MyType READONLY,
@UserID varchar(20) AS
Insert INTO MyTable([col1],[col2],[col3],[UserID])
Select [col1],[col2],[col3],@UserID
FROM @MyTableParam
GO
如何在sql中调用此存储过程:
DECLARE @MyTable MyType
Insert INTO @MyTable(col1,col2,col3)
VALUES (1,'abc','1/1/2000'),
(2,'def','1/1/2001'),
(3,'ghi','1/1/2002'),
(4,'jkl','1/1/2003'),
(5,'mno','1/1/2004')
EXEC usp_AddRowsToMyTable @MyTableParam = @MyTable, @UserID = 'Kathi'
Select * FROM MyTable
其中还涉及到一个权限问题,需要执行以下代码:
GRANT EXECUTE ON TYPE::dbo.MyType TO TestUser;
从.net app那调用此存储过程:
'Create a local table
Dim table As New DataTable("temp")
Dim col1 As New DataColumn("col1", System.Type.GetType("System.Int32"))
Dim col2 As New DataColumn("col2", System.Type.GetType("System.String"))
Dim col3 As New DataColumn("col3", System.Type.GetType("System.DateTime"))
table.Columns.Add(col1)
table.Columns.Add(col2)
table.Columns.Add(col3)
'Populate the table
For i As Integer = 20 To 30
Dim vals(2) As Object
vals(0) = i
vals(1) = Chr(i + 90)
vals(2) = System.DateTime.Now
table.Rows.Add(vals)
Next
'Create a command object that calls the stored proc
Dim command As New SqlCommand("usp_AddRowsToMyTable", conn)
command.CommandType = CommandType.StoredProcedure
'Create a parameter using the new type
Dim param As SqlParameter = command.Parameters.Add("@MyTableParam", SqlDbType.Structured)
command.Parameters.AddWithValue("@UserID", "Kathi")
'Set the value of the parameter
param.Value = table
'Execute the query
command.ExecuteNonQuery()
详情可以参看:
http://www.sqlteam.com/article/sql-server-2008-table-valued-parameters
[SQL]SQL Server 2005中xml类型和函数的简单应用
大家都知道SQL Server 2005新增了xml字段类型,我们可以利用它来实现批量操作数据库的需要,减少应用程序频繁、反复的建立数据库连接的情况发生,比如批量删除,我们可以在应用程序中构建如下xml:
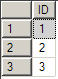
 <Delete><ID>1</ID><ID>2</ID><ID>3</ID></Delete>
<Delete><ID>1</ID><ID>2</ID><ID>3</ID></Delete>在数据库中可以通过下面的脚本获得这些ID:
Select T.ID.value('.', 'int') As IDFrom @xmlParam.nodes('/Delete/ID') as T(ID)运行结果如下:
将xml类型作为存储过程的参数,批量删除的存储过程如下:
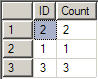
Create Procedure pro_Batch_Delete@xmlParam xmlAsDelete from t_TableName Where ID in (Select T.ID.value('.', 'int') As ID From @xmlParam.nodes('/Delete/ID') as T(ID))大家也知道,DataSet中的数据可以直接序列化成xml,通过dataSet.GetXml(),我们可以将这个xml作为存储过程参数,实现稍微复杂的功能,比如批量插入数据,在数据库中怎样将这个xml转换为表呢,我们先看DataSet序列化的xml结构:
<DataSet> <Table><ID>1</ID><Count>1</Count></Table> <Table><ID>2</ID><Count>2</Count></Table> <Table><ID>3</ID><Count>3</Count></Table></DataSet>当然也可以包含多个表,这里我们以一个表举例,转换脚本如下:
Declare @Xml xmlSet @Xml = '<DataSet> <Table><ID>1</ID><Count>1</Count></Table> <Table><ID>2</ID><Count>2</Count></Table> <Table><ID>3</ID><Count>3</Count></Table></DataSet>'Select T2.ID.value('.', 'int') As ID, T3.[Count].value('.','int') As [Count]From (Select T.Records.query('ID') As ID, T.Records.query('Count') As [Count] From @Xml.nodes('/DataSet/Table') As T(Records) ) As T1Cross Apply T1.ID.nodes('ID') As T2(ID)Cross Apply T1.[Count].nodes('Count') As T3([Count])执行此脚本,可以得到我们想要的表:
批量插入记录的存储过程如下:
Create Procedure pro_Batch_Insert@xmlParam xmlAsInsert Into t_TableName (ID, [Count])( Select T2.ID.value('.', 'int') As ID, T3.[Count].value('.','int') As [Count] From (Select T.Records.query('ID') As ID, T.Records.query('Count') As [Count] From @xmlParam.nodes('/DataSet/Table') As T(Records) ) As T1 Cross Apply T1.ID.nodes('ID') As T2(ID) Cross Apply T1.[Count].nodes('Count') As T3([Count]))同样,可以实现批量update的功能,这里不具体列举了,实现核Insert是基本相同的。
这里只使用部分SQL2005关于xml几个谓词和函数,在MSDN中都有说明,还有其他更强大的功能等大家一起去发掘.