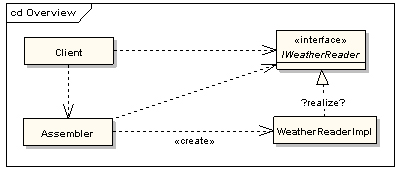
ASP.NET Portal Starter Kit数 据库结构总体上来讲是由网站引擎的核心表(用户表、角色表和角色关系表)和各个用户模块相关的表组成。核心表存储整个网站的用户权限的配置信息(详细的用 法及说明将放到《角色身份认证篇》中讲)。各用户模块存储各个功能模块的信息。各个用户功能模块表都是独立的。这样有利于新增模块扩展功能。同时也可将各 个功能模块的表分别部署到不同的数据库中提高程序的高伸缩性和可扩展性。数据的访问方式是全部通过存储过程进行的。这样做的好处有:1、提高了数据库的性能;2、杜绝了SQL注入式攻击(在我的理解上应该是);3、可将可将连接到SQL Server数据库用户的权限只配置成只能对指定存储过程进行执行操作,这样就进一步提高了数据库的安全性。
数据库中的表:
Portal_Announcements:公告信息表(在公告信息模块中用)
|
字段名 |
类型 |
含义 |
备注 |
|
ItemID |
Int |
链接Id |
主键(自动编号) |
|
ModuleID |
Int |
所属模块ID |
决定该公告在那个模块中显示(模块ID:用户配置文件PortalCfg.xml中的模块表ID,以下皆同) |
|
CreatedByUser |
Nvarchar(100) |
创建者 |
记录创建和修改该公告的用户 |
|
CreatedDate |
Datetime |
创建时间 |
记录创建和修改该公告的时间 |
|
Title |
Nvarchar(100) |
名称 |
|
|
MoreLink |
Nvarchar(150) |
更多细节的链接 |
|
|
MobileMoreLink |
Nvarchar(150) |
移动细节链接地址 |
在“移动设备浏览器”上的更多细节链接地址 |
|
ExpireDate |
Datetime |
有效日期 |
|
|
Description |
Nvarchar(2000) |
描述 |
|
Portal_Contacts:联系方式信息表(在联系方式模块中用)
|
字段名 |
类型 |
含义 |
备注 |
|
ItemID |
Int |
链接Id |
主键(自动编号) |
|
ModuleID |
Int |
所属模块ID |
决定该联系方式在那个模块中显示 |
|
CreatedByUser |
Nvarchar(100) |
创建者 |
记录创建和修改该联系方式的用户 |
|
CreatedDate |
Datetime |
创建时间 |
记录创建和修改该联系方式的时间 |
|
Name |
Nvarchar(50) |
联系人姓名 |
|
|
Role |
Nvarchar(100) |
联系人角色 |
与系统框架中的角色不同,理解成职位更合适 |
|
Email |
Nvarchar(100) |
联系人Email |
|
|
Contact1 |
Nvarchar(250) |
联系方式1 |
|
|
Contact2 |
Nvarchar(250) |
联系方式2 |
|
Portal_Discussion:用户讨论留言信息表(用户讨论模块用)
|
字段名 |
类型 |
含义 |
备注 |
|
ItemID |
Int |
链接Id |
主键(自动编号) |
|
ModuleID |
Int |
所属模块ID |
决定该讨论在那个模块中显示 |
|
Title |
Nvarchar(50) |
讨论标题 |
|
|
CreatedDate |
Datetime |
创建时间 |
记录创建该讨论的时间 |
|
Body |
Nvarchar(100) |
留言内容 |
|
|
CreatedByUser |
Nvarchar(100) |
创建者 |
记录创建和修改该讨论的用户 |
|
DisplayOrder |
Nvarchar(100) |
显示顺序 |
记录回复的讨论的时间和本身提交的时间 (可用作讨论留言的排序和显示回复关系) |
Portal_Documents:用户上传文档信息表(在显示文档信息模块中用)
|
字段名 |
类型 |
含义 |
备注 |
|
ItemID |
Int |
链接Id |
主键(自动编号) |
|
ModuleID |
Int |
所属模块ID |
决定该联系方式在那个模块中显示 |
|
CreatedByUser |
Nvarchar(100) |
创建者 |
记录创建和修改该联系方式的用户 |
|
CreatedDate |
Datetime |
创建时间 |
记录创建和修改该联系方式的时间 |
|
FileNameUrl |
Nvarchar(250) |
|
上传至服务器中的文件路径 |
|
FileFriendlyName |
Nvarchar(150) |
文档名称 |
友好的文件名称显示 |
|
Category |
Nvarchar(50) |
类别 |
|
|
Content |
Image |
内容(二进制) |
上传到数据库中的内容 |
|
ContentType |
Nvarchar(50) |
类型 |
上传文件的类型 |
|
ContentSize |
Int |
大小 |
上传文件的大小 |
Portal_Events:事件信息表(在显示事件信息的模块中使用)
|
字段名 |
类型 |
含义 |
备注 |
|
ItemID |
Int |
链接Id |
主键(自动编号) |
|
ModuleID |
Int |
所属模块ID |
决定该事件在那个模块中显示 |
|
CreatedByUser |
Nvarchar(100) |
创建者 |
记录创建和修改该事件的用户 |
|
CreatedDate |
Datetime |
创建时间 |
记录创建和修改该事件的时间 |
|
Title |
Nvarchar(100) |
事件名称 |
|
|
WhereWhen |
Nvarchar(150) |
发生地点 |
|
|
Description |
Nvarchar(2000) |
描述 |
|
|
ExpireDate |
Datetime |
有效日期 |
|
Portal_HtmlText:静态HTML信息表(在显示静态静态HTML的模块中用,可用于显示新闻等文本)
|
字段名 |
类型 |
含义 |
备注 |
|
ModuleID |
Int |
所属模块ID |
决定该静态HTML在那个模块中显示(主键,限定一个模块只对应一个静态HTML文件) |
|
DesktopHtml |
Ntext |
桌面HTML内容 |
|
|
MobileSummary |
Ntext |
移动摘要 |
在“移动设备浏览器”上显示的摘要 |
|
MobileDetails |
Ntext |
移动细节 |
在“移动设备浏览器”上显示的细节 |
Portal_Links:链接信息表(快速链接模块和连接模块用)
|
字段名 |
类型 |
含义 |
备注 |
|
ItemID |
Int |
链接Id |
主键(自动编号) |
|
ModuleID |
Int |
所属模块ID |
决定该链接在那个模块中显示 |
|
CreatedByUser |
Nvarchar(100) |
创建者 |
记录创建和修改该链接的用户 |
|
CreatedDate |
Datetime |
创建时间 |
记录创建和修改该链接的时间 |
|
Title |
Nvarchar(100) |
名称 |
|
|
Url |
Nvarchar(250) |
链接地址 |
|
|
MobileUrl |
Nvarchar(250) |
移动链接地址 |
|
|
ViewOrder |
Int |
排序号 |
|
|
Description |
Nvarchar(2000) |
描述 |
|
Portal_Roles:角色信息表(门户网站引擎核心表)
|
字段名 |
类型 |
含义 |
备注 |
|
RoleID |
Int |
角色Id |
主键(自动编号) |
|
PortalID |
Int |
门户网址ID |
可架设多个门户站点而共用一个数据库,通过PortalID区分 |
|
RoleName |
Nvarchar(50) |
角色名称 |
Portal_UserRoles:用户角色关系表(门户网站引擎核心表)
|
字段名 |
类型 |
含义 |
备注 |
|
UserID |
Int |
用户Id |
关联用户信息表(Portal_Roles) |
|
RoleID |
Int |
角色Id |
管理角色信息表(Portal_Users) |
Portal_Users:用户信息表(门户网站引擎核心表)
|
字段名 |
类型 |
含义 |
备注 |
|
UserID |
Int |
用户Id |
主键(自动编号) |
|
Name |
Nvarchar(50) |
用户姓名 |
|
|
Password |
Nvarchar(50) |
密码 |
采用MD5的加密方式存储 |
|
Email |
Nvarchar(100) |
用户Email |
用于登录,并设置成唯一性索引(可防止注册相同的Email,这样设置后当有相同的Email插入时程序就会抛出异常,捕获这个异常就可判断Email是否重复,这样就可以省掉判断Email是否重复的代码) |
数据库中的存储过程:
|
存储过程名称 |
说明 |
|
Portal_AddAnnouncement |
添加新公告 |
|
Portal_AddContact |
添加新联系方式 |
|
Portal_AddEvent |
添加新事件 |
|
Portal_AddLink |
添加新链接 |
|
Portal_AddMessage |
新建一条新的讨论留言,其中@ParentID的参数为被回复留言的Id,通过该ID找到该留言的DisplayOrder,加上新增留言的时间就是新留言的DisplayOrder。 |
|
Portal_AddRole |
添加角色信息 |
|
Portal_AddUser |
添加一个新用户,返回用户的Id |
|
Portal_AddUserRole |
添加用户角色关系 |
|
Portal_DeleteAnnouncement |
删除公告信息(注:以下删除部分若无特殊说明均为删除指定ItemID的信息) |
|
Portal_DeleteContact |
删除联系方式 |
|
Portal_DeleteDocument |
删除用户上传文档 |
|
Portal_DeleteEvent |
删除事件信息 |
|
Portal_DeleteLink |
删除链接信息 |
|
Portal_DeleteModule |
当删除一个模块时,联动的删除该模块相关的全部信息 |
|
Portal_DeleteRole |
删除角色信息 |
|
Portal_DeleteUser |
删除用户 |
|
Portal_DeleteUserRole |
删除角色用户关系 |
|
Portal_GetAnnouncements |
根据ModuleID(模块ID)返回有效期内的公告信息 |
|
Portal_GetAuthRoles |
像是没有用到该存储过程,而且该存储过程涉及的表数据库中没有(在用户配置文件中有类似的表),需要在深入研究 |
|
Portal_GetContacts |
根据ModuleID(模块ID)返回联系方式 |
|
Portal_GetDocumentContent |
根据文档的(ItemID)获取存储在数据库中的文档信息 |
|
Portal_GetDocuments |
根据ModuleID(模块ID)返回用户上传文档信息 |
|
Portal_GetEvents |
根据ModuleID(模块ID)返回有效期内的事件信息 |
|
Portal_GetHtmlText |
根据ModuleID(模块ID)返回静态HTML文本信息 |
|
Portal_GetLinks |
根据ModuleID(模块ID)返回连接信息,并按(ViewOrder)排序号排序 |
|
Portal_GetNextMessageID |
获取讨论的下一条留言 |
|
Portal_GetPortalRoles |
获取指定门户站点(指定PortalID)的全部角色信息 |
|
Portal_GetPrevMessageID |
获取讨论的上一条留言 |
|
Portal_GetRoleMembership |
根据角色ID获取该角色对应的用户成员信息 |
|
Portal_GetRolesByUser |
根据用户Email获取用户角色信息 |
|
Portal_GetSingleAnnouncement |
根据公告的(ItemID),获取单个公告的信息 |
|
Portal_GetSingleContact |
根据联系方式的(ItemID),获取单个联系方式的信息 |
|
Portal_GetSingleDocument |
根据文档的(ItemID),获取单个文档的信息 |
|
Portal_GetSingleEvent |
根据事件的(ItemID),获取单个事件的信息 |
|
Portal_GetSingleLink |
根据链接的(ItemID),获取单个链接的信息 |
|
Portal_GetSingleMessage |
根据留言的(ItemID),获取单个留言的信息 |
|
Portal_GetSingleRole |
根据角色ID,获取单个角色的信息 |
|
Portal_GetSingleUser |
根据用户Email,获取单个用户的信息 |
|
Portal_GetThreadMessages |
根据父留言信息的DisplayOrder,返回按时间顺序和回复关系返回子留言信息 |
|
Portal_GetTopLevelMessages |
根据ModuleID(模块ID)返回顶层留言信息 |
|
Portal_GetUsers |
获取全部的用户信息,并按Email排序 |
|
Portal_UpdateAnnouncement |
更新公告信息 |
|
Portal_UpdateContact |
更新联系方式信息 |
|
Portal_UpdateDocument |
更新文档信息,当未找到指定文档ID时添加新的文档信息 |
|
Portal_UpdateEvent |
更新事件信息 |
|
Portal_UpdateHtmlText |
更新静态HTML文本信息 |
|
Portal_UpdateLink |
更新指定的连接信息 |
|
Portal_UpdateRole |
更新角色信息 |
|
Portal_UpdateUser |
更新用户信息 |
|
Portal_UserLogin |
根据email和password返回登录的用户姓名(用于判断用户登录是否通过) |
更多相关内容:点击这里>>