来源: MongoDB 与 SQL 代码间转化_weixin_41540362的博客-CSDN博客
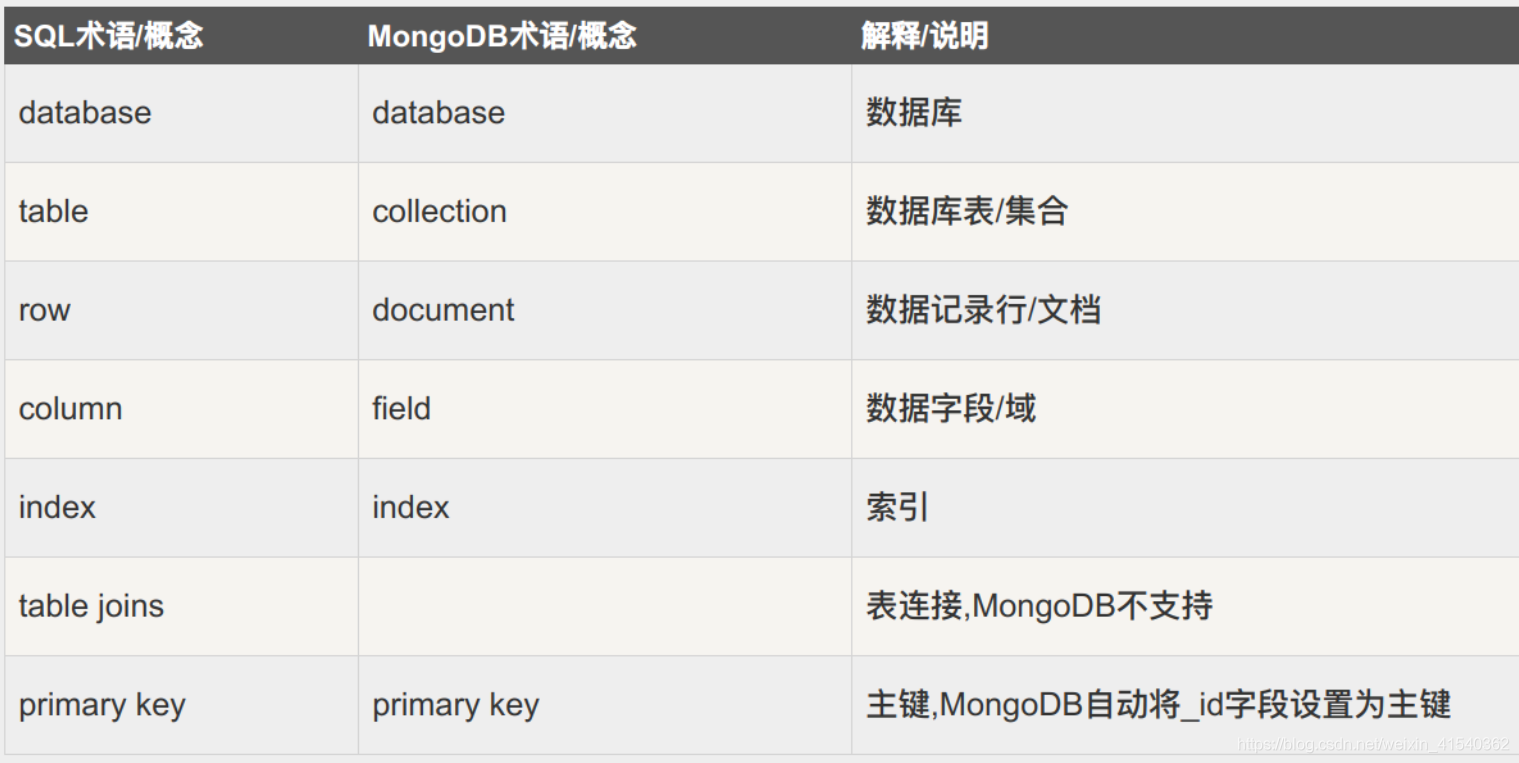
SQL与 MongoDB术语&解释
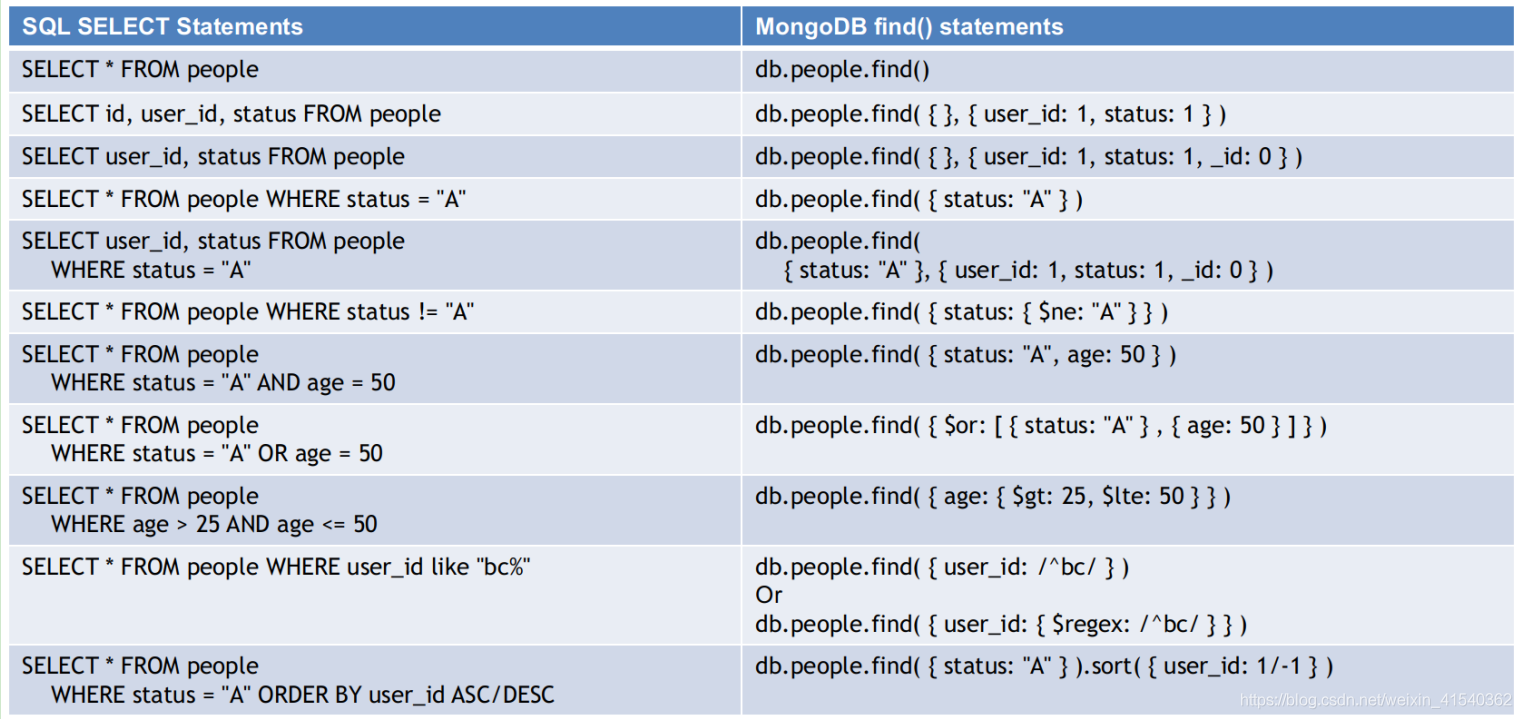
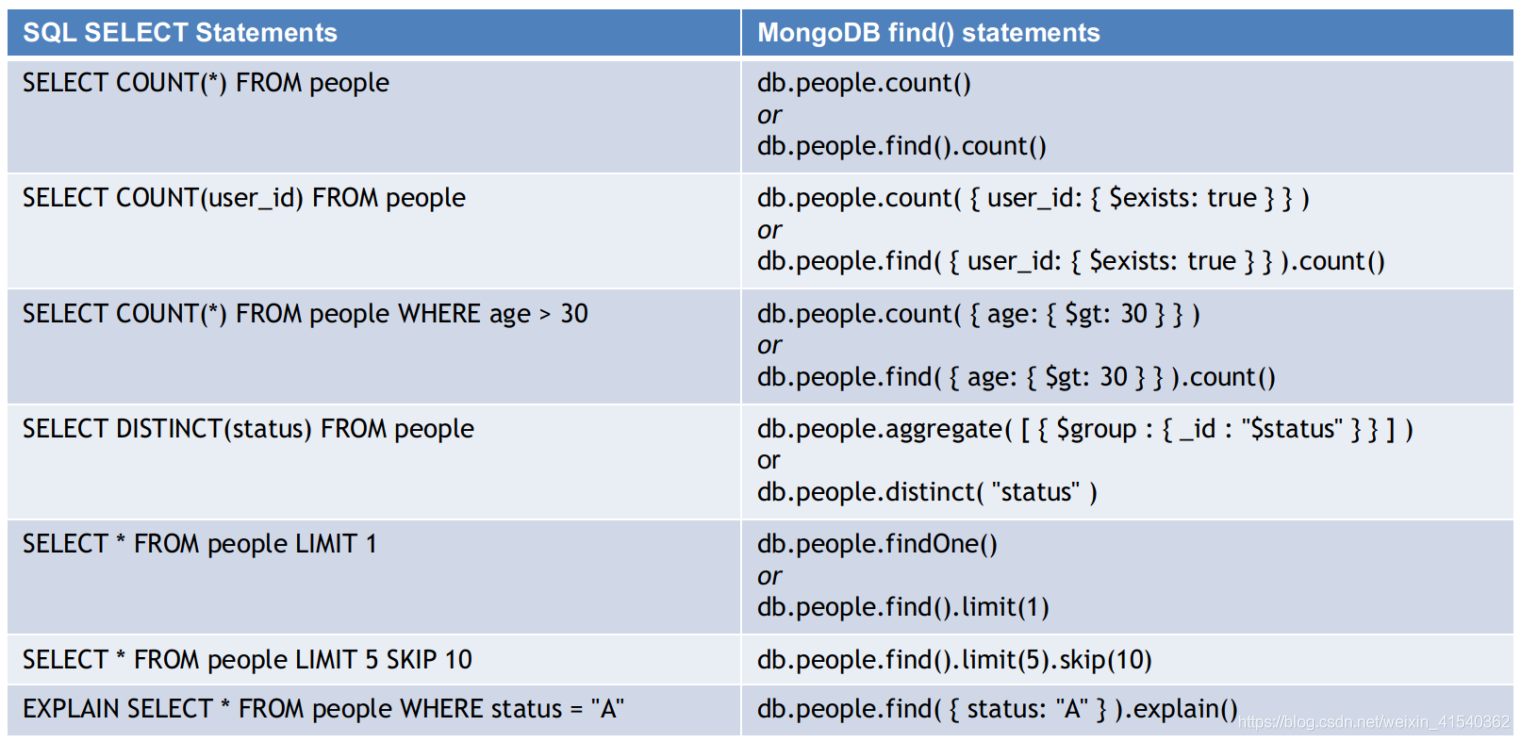
常用基础转化SQL模板

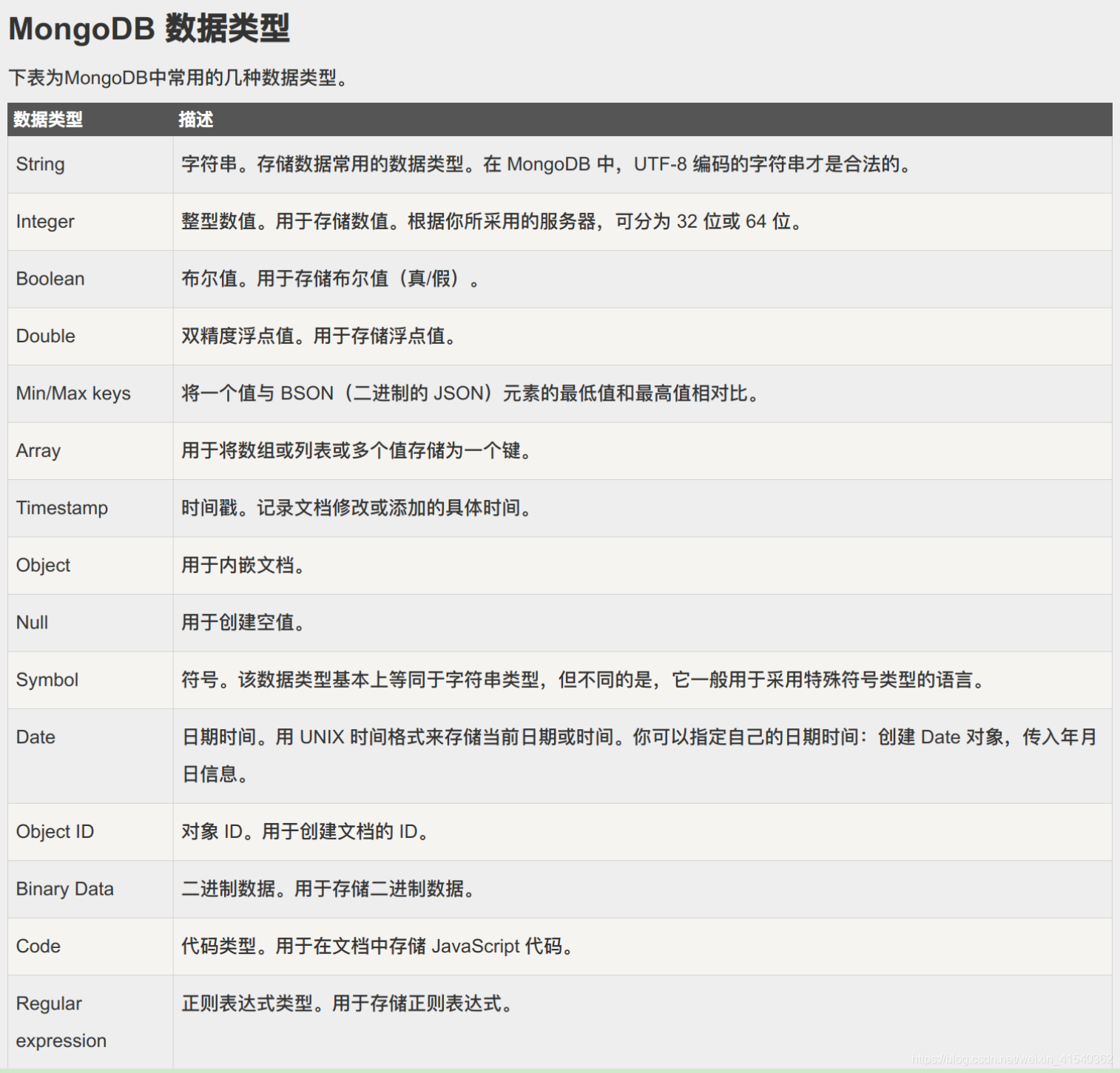

来源: MongoDB 查询$关键字 $in $or $all – minger_lcm – 博客园
属于:$in 满足其中一个元素的数据 把age=13,73 的数据显示
> db.user.find({age: { $in:[13,73]}})
{ "_id" : ObjectId("5ca7a4b0219efd687462f965"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 13, "hobby" : [ "羽毛球", "篮球", "足球" ] }
只要满足$in [] 里面的元素 都可以查询出来
> db.user.find({hobby:{$in:["足球","篮球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
> db.user.find({hobby:{$in:["羽毛球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
或者:$or 满足其中一个字段的元素数据
OR条件:
MongoDB的OR条件语句使用了操作符$or。如:> db.collection_name.find({$or: [{key1: value1}, {key2: value2}]})
查询 name="mike" 或者 name ="jack",两个条件其中一个条件成立,都返回数据
> db.user.find({$or:[{name:"mike"},{name:"jack"}]} )
{ "_id" : ObjectId("5ca7a4b0219efd687462f965"), "id" : 1, "name" : "jack", "age" : 73 }
{ "_id" : ObjectId("5ca7a4b7219efd687462f966"), "id" : 2, "name" : "mike", "age" : 84, "gender" : "男" }
$all: 满足所有元素的数据 符合列表里面元素条件就可以 显示数据

> db.user.find({hobby:{$all:["足球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
> db.user.find({hobby:{$all:["足球","羽毛球"] } })
{ "_id" : ObjectId("5ca7a4c4219efd687462f968"), "id" : 4, "name" : "xiaogang", "age" : 34, "hobby" : [ "羽毛球", "篮球", "足球" ] }
> db.user.find({hobby:{$all:["足球","桌球"] } })
最近公司要写一个项目,其中一个需求就是前端用户选择查询条件。
就是要做一个SQL转Mongo的方法,开始觉得简单,一上手就不觉得简单了,最开始想着自己来组装,但是发现好像自己能力有限确实手写不出来转换的方法,后来查遍了网上的资料,都只是转换单个SQL语句,不符合业务逻辑啊,就只有想其他办法。
最开始就是用SQL自带的那个转换的方法,但是转换出来并没有什么用,还是拼接不出方法。
后来看到geoserver上有个动态转sql的功能,然后就去下载了geotools的所有的依赖,然后反编译出来看源码,但是源码是看到了,也看到了实现的一些过程,但是太麻烦了,没看到能直接调用geotools的入口,这个方法也是作罢了。
后来我去github上面看解决方案,看到一个大神写了一个工具类,真的牛逼!
github地址我忘记了,实在是太不应该了,希望能帮到正在被这个折磨的人。
<dependency>
<groupId>com.github.vincentrussell</groupId>
<artifactId>sql-to-mongo-db-query-converter</artifactId>
<version>1.10</version>
</dependency>
String sql = “select column1 from my_table where xxx<50 and yyy>50” ;
QueryConverter queryConverter = new QueryConverter(sql);
MongoDBQueryHolder mongoDBQueryHolder = queryConverter.getMongoQuery();
Document query = mongoDBQueryHolder.getQuery();
String mongsql = query.toJson();//转好的sql转mongo语句,注意这里序列化了
Document d = org.bson.Document.parse(mongsql);
String js = com.mongodb.util.JSON.serialize(d);
Bson bson = BsonDocument.parse(js);
FindIterable findIterable = collection.find(bson).projection(document).limit(limit).skip(skip);//sql查询
MongoCursor cursor1 = findIterable.iterator();
以上就是实现的方式。希望能帮到人。
作者:ychl1
链接:https://www.jianshu.com/p/19e2ef4868ee
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. 下载
源码下载:http://files.cnblogs.com/tianzhiliang/CocoWatcher.rar
安装包下载:http://files.cnblogs.com/tianzhiliang/CocoWatcher_Setup.rar
2. 安装注意事项
|
1
2
3
4
5
6
7
8
9
10
|
<?xml version="1.0" encoding="utf-8" ?><configuration> <appSettings> <add key="ProcessAddress" value=" d:\war3.exe, d:\note.txt, d:\girl.jpg " /> </appSettings></configuration> |
 运行该守护程序需安装Windows服务,点击批处理文档“安装.bat”即可,“安装.bat”具体内容如下:
运行该守护程序需安装Windows服务,点击批处理文档“安装.bat”即可,“安装.bat”具体内容如下:
|
1
2
3
|
"%cd%\InstallUtil.exe" "%cd%\CocoWatcher.exe"net start "CocoWatcher"pause |
如果你想卸载该守护程序,点击批处理文档“卸载.bat”,“卸载.bat”具体内容如下:
|
1
2
3
4
|
net stop "CocoWatcher""%cd%\InstallUtil.exe" "%cd%\CocoWatcher.exe" -utaskkill /f /im CocoWatcher.exepause |
3. 需求分析
用户指定要守护的应用程序(数量不限),该应用程序不仅包括exe可执行文件,还包括诸如jpg、txt等所有能双击打开执行的应用程序。用户设定好要守护的应用程序后,关闭应用程序(包括合法和非法关闭),该应用程序要能立即重启打开。当电脑重启时,要守护的应用程序也能自动全部打开。
4. 详细设计
要实现上述需求,首先要提供一个配置档,让用户能随意配置要守护的应用程序。那么,该配置档要配置应用程序的什么信息呢?答案:应用程序的全路径。
好,我们已经知道了要守护的应用程序的全路径,接下来怎样完成守护任务呢?首先,我们应该打开任务管理器,查看一下正在运行的有哪些进程,然后逐一读取出这些进程的全路径,与要守护的应用程序的全路径比对,如果一致,说明要守护的应用程序已开启了,此时要分配一条线程监控该进程句柄,当该进程句柄返回信息,说明该进程已关闭,此时释放进程句柄内存,并重启该进程。如果遍历任务管理进程列表中所有进程,没有找到与要守护的应用程序的全路径一致的进程,说明要守护的应用程序尚未打开,此时要启动该应用程序,然后转入监控流程。
值得注意的是,一定要额外分配线程去监控要守护的应用程序,为什么?因为如果你用主线程(入口函数线程)去执行监控任务,会被长期阻塞,直到进程退出才会被激活,这样就无法运行后续程序。况且,监控程序要实现持续监控,要使用死循环,如果主线程进入死循环,就无法监控其他要守护的进程了。
5. 代码详解
Windows服务的开发步骤,请参考MSDN,此处略去。下面将关键代码贴出,加以解释。
读取配置档中“ProcessAddress”节点,获取要守护的应用程序全目录,验证应用程序全目录,如果合法,进入扫描任务管理器进程列表流程。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
/// <summary>/// 开始监控/// </summary>private void StartWatch(){ if (this._processAddress != null) { if (this._processAddress.Length > 0) { foreach (string str in _processAddress) { if (str.Trim() != "") { if (File.Exists(str.Trim())) { this.ScanProcessList(str.Trim()); } } } } }} |
打开任务管理器,查看一下正在运行的有哪些进程,然后逐一读取出这些进程的全路径,与要守护的应用程序的全路径比对,如果一致,说明要守护的应用程序已开启了,进入监控流程。如果遍历任务管理进程列表中所有进程,没有找到与要守护的应用程序的全路径一致的进程,说明要守护的应用程序尚未打开,此时要启动该应用程序,然后转入监控流程。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
/// <summary>/// 扫描进程列表,判断进程对应的全路径是否与指定路径一致/// 如果一致,说明进程已启动/// 如果不一致,说明进程尚未启动/// </summary>/// <param name="strAddress"></param>private void ScanProcessList(string address){ Process[] arrayProcess = Process.GetProcesses(); foreach (Process p in arrayProcess) { //System、Idle进程会拒绝访问其全路径 if (p.ProcessName != "System" && p.ProcessName != "Idle") { try { if (this.FormatPath(address) == this.FormatPath(p.MainModule.FileName.ToString())) { //进程已启动 this.WatchProcess(p, address); return; } } catch { //拒绝访问进程的全路径 this.SaveLog("进程(" + p.Id.ToString() + ")(" + p.ProcessName.ToString() + ")拒绝访问全路径!"); } } } //进程尚未启动 Process process = new Process(); process.StartInfo.FileName = address; process.Start(); this.WatchProcess(process, address);} |
分配一条线程,执行监控任务:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
/// <summary> /// 监听进程 /// </summary> /// <param name="p"></param> /// <param name="address"></param> private void WatchProcess(Process process, string address) { ProcessRestart objProcessRestart = new ProcessRestart(process, address); Thread thread = new Thread(new ThreadStart(objProcessRestart.RestartProcess)); thread.Start(); }public class ProcessRestart{ //字段 private Process _process; private string _address; /// <summary> /// 构造函数 /// </summary> public ProcessRestart() {} /// <summary> /// 构造函数 /// </summary> /// <param name="process"></param> /// <param name="address"></param> public ProcessRestart(Process process, string address) { this._process = process; this._address = address; } /// <summary> /// 重启进程 /// </summary> public void RestartProcess() { try { while (true) { this._process.WaitForExit(); this._process.Close(); //释放已退出进程的句柄 this._process.StartInfo.FileName = this._address; this._process.Start(); Thread.Sleep(1000); } } catch (Exception ex) { ProcessWatcher objProcessWatcher = new ProcessWatcher(); objProcessWatcher.SaveLog("RestartProcess() 出错,监控程序已取消对进程(" + this._process.Id.ToString() +")(" + this._process.ProcessName.ToString() + ")的监控,错误描述为:" + ex.Message.ToString()); } }} |
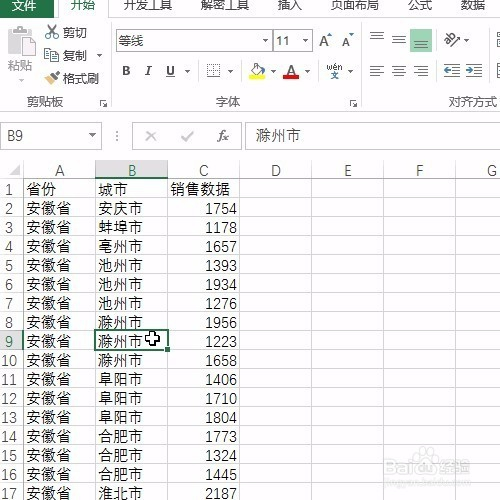
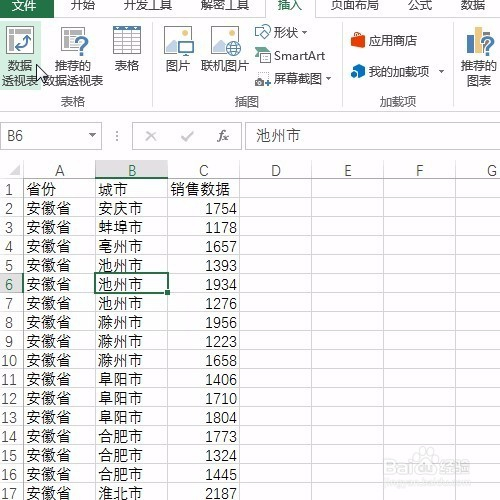
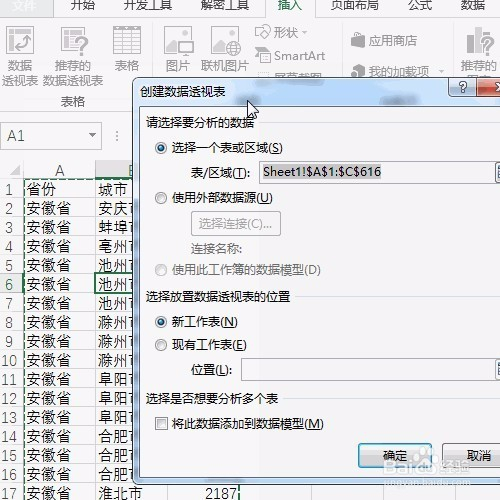
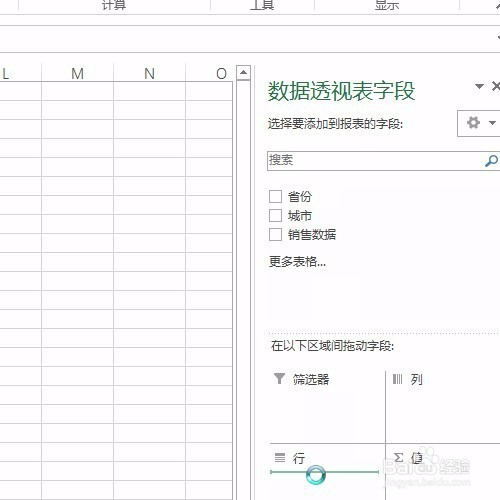
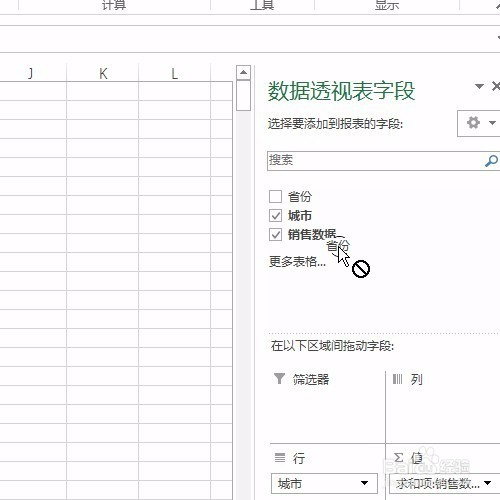
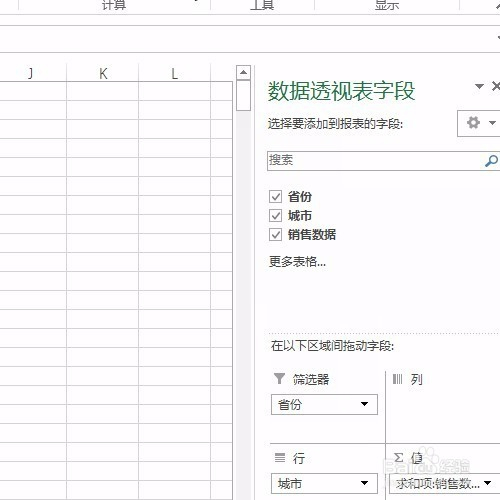
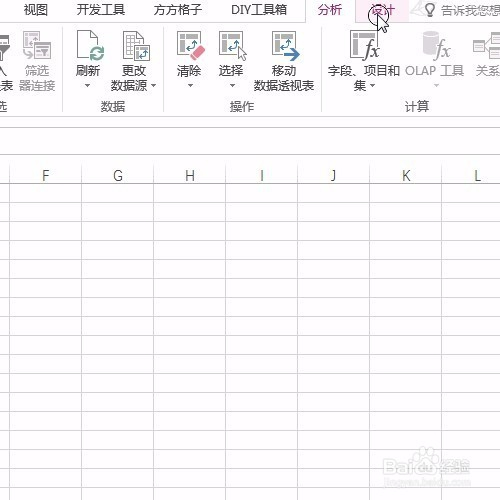
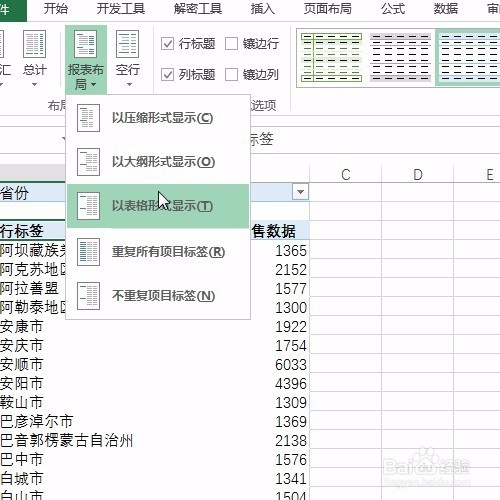
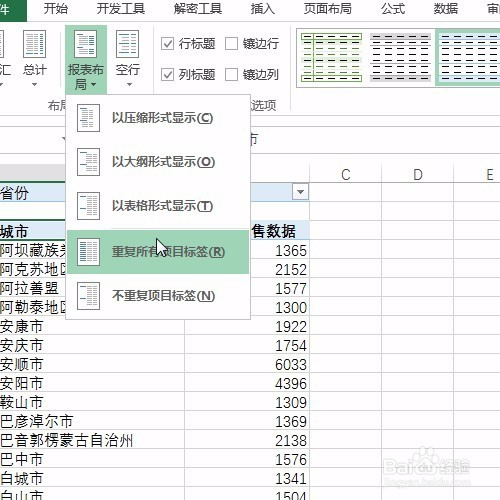
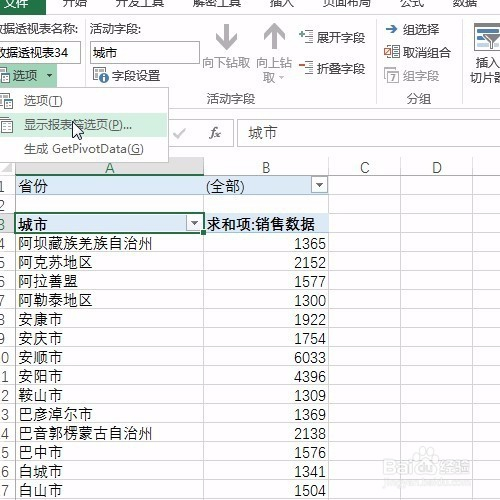
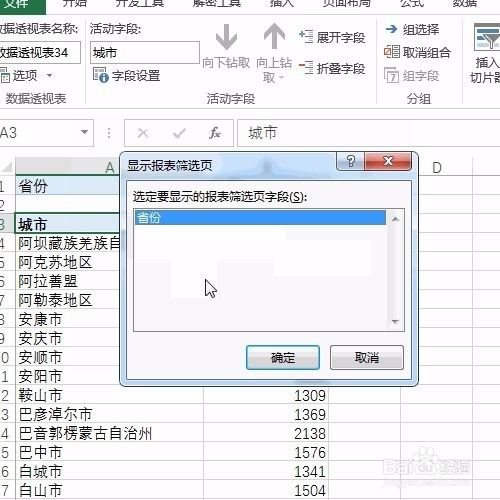
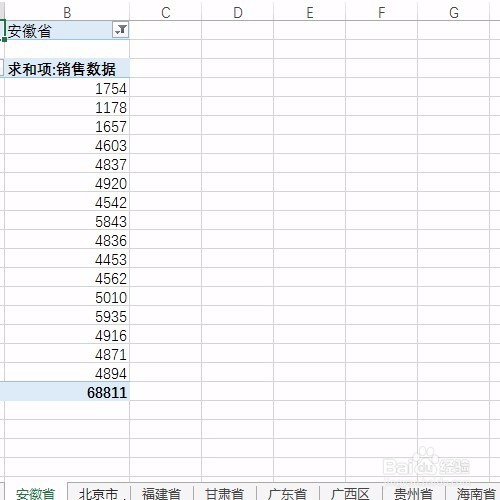
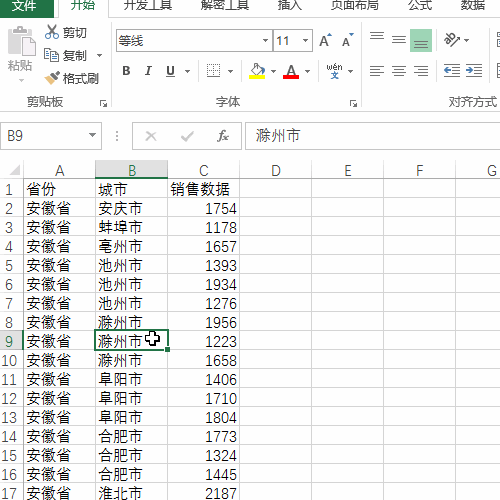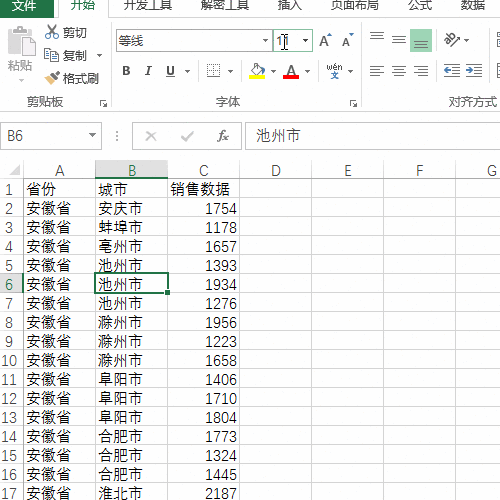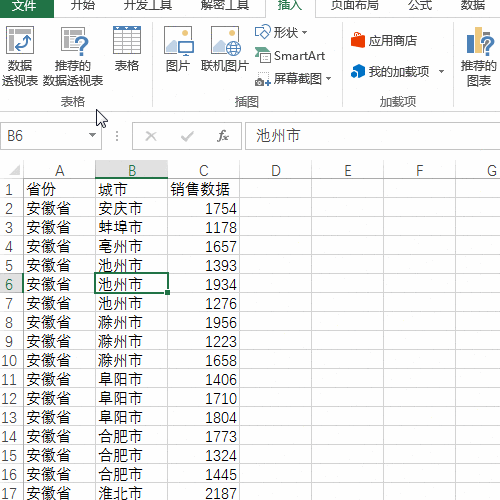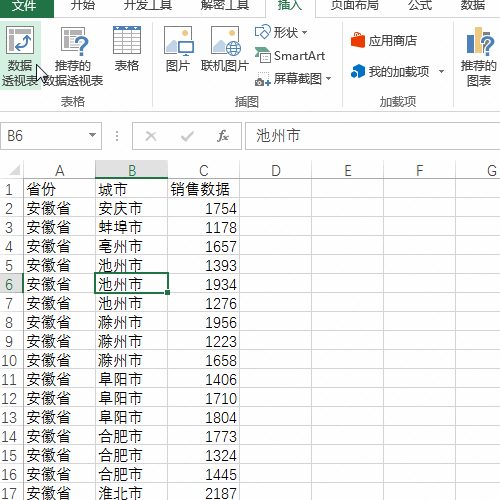
来源: Excel按某列字段拆分总表为若干个分表,简单!-百度经验
今天要和大家分享的是:Excel按某列字段,拆分总表为若干个分表,简单!详见下图动态演示和步骤分解。
来源: (完美解决)应用程序无法正常启动(0xc000007b),请单击确定关闭应用程序的解决方案_来者即是客,我们共同成长-CSDN博客
在整个过程中遇到的系统报错类型为:
①:应用程序无法正常启动0xc000007b,请单击确定关闭应用程序;
②:无法启动此程序,因为计算机中丢失MSVCP140.dll;
③:VC++2015 设置失败,一个或多个问题导致了安装失败……..;
④:Windows Update独立安装程序 此更新不适用于您的计算机
目录
1、应用程序无法正常启动0xc000007b,请单击确定关闭应用程序。
2、无法启动此程序,因为计算机中丢失MSVCP140.dll
3、VC++2015 设置失败,一个或多个问题导致了安装失败……..
4、Windows Update独立安装程序 此更新不适用于您的计算机
1、查看系统类型,不算SP1类型的话将系统升级为win Service SP1
2、在Win7 SP1系统的基础上进行打补丁KB976932
之前将电脑的系统装成了Win7 64位旗舰版的官方原版镜像,镜像名为:cn_windows_7_ultimate_x64_dvd_x15-66043.iso
当装上Qt creater后,打开是电脑就显示了应用程序无法正常启动0xc000007b,请单击确定关闭应用程序。
出现了这个报错后,在网上也查了好多文档和帖子,没有解决,差点儿又重装了系统
为了给后面的伙伴一个参考,写个帖子记录一下,少走一些坑
最开始也有按照网上的教程使用Direct进行修复,也修复成功了
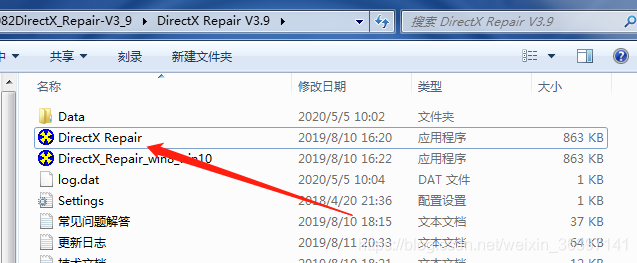
也使用了驱动精灵和360管家就行了运行库的修复和下载,无果
之后弹出的对话框显示“无法启动此程序,因为计算机中丢失MSVCP140.dll”

用了一些修复的工具,依然没有解决
如果单独下载一个“msvcp140.dll”是没用的,所有msvcp类文件都是微软VC++运行库的文件,140版本号代表是VC++2015的文件,缺少这个就安装VC++2015一般即可解决。
如果是32位程序出现这个提示就安装x86版VC++2015,64位程序就安装x64版。
微软官方下载vc++2015 里面包含(32/64)
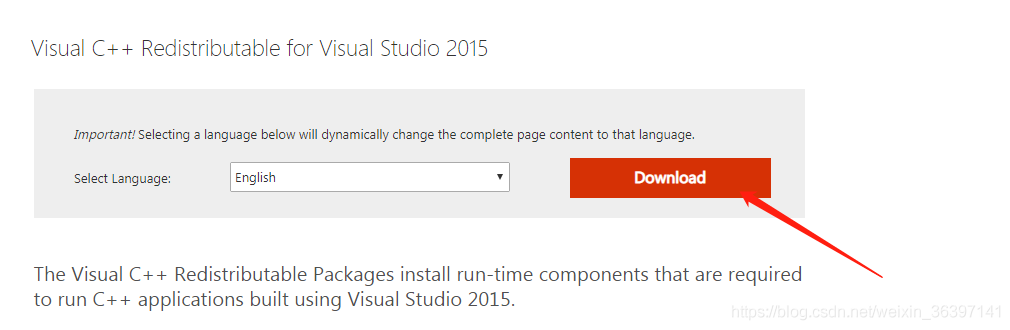
点击进行下载:(选择你的系统进行安装)
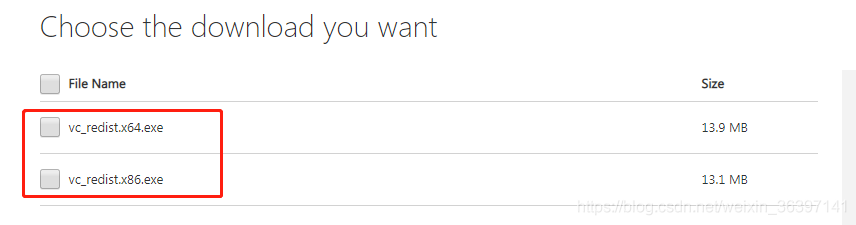
最后安装VC++2015 失败,操作显示为如下图片:

网上的一些博文没有说明白,说的详细,这里进行一个阐述
VC++2015 失败的时候,需要安装一个补丁,这个补丁在微软的官网就可以下载到(但是这个补丁是在windows SP1系统版本的基础上进行打的),不算很大,速度也可以
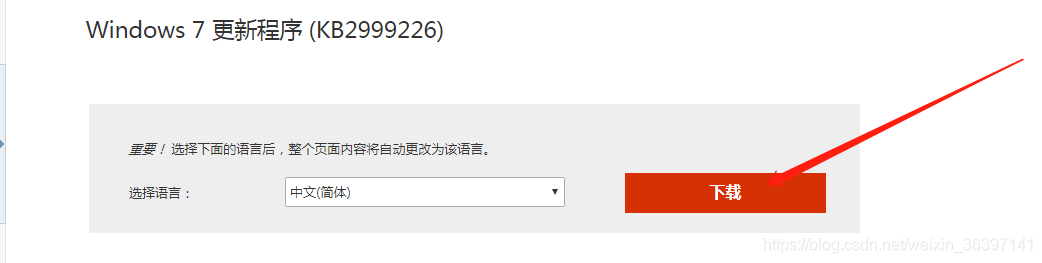
真是一环扣一环
到这里,补丁下载好了,安装出错了,显示“此更新不适用于您的计算机”
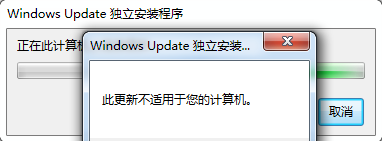
之后又按照网上的解决方案无果,最后看到了一个解决方案测试成功,当时也没觉得可以成功,抱着试一试的想法,也没有进行截图,这里就语言描述吧!
原贴地址:Win7 64位系统VC++2015安装失败80240037解决方法
出现“此更新不适用于您的计算机” 这个错误是因为这个补丁是在Win7 SP1系统的基础上进行打补丁,我当时安装系统是dvd版,不算SP1的,之后按照教程进行了操作,需要将系统升级为Service Pack 1 (SP1)(产看方法为计算机—》右键属相—》查看windows版本信息)
我这个截图是升级后的,之前的不是不叫这个名字
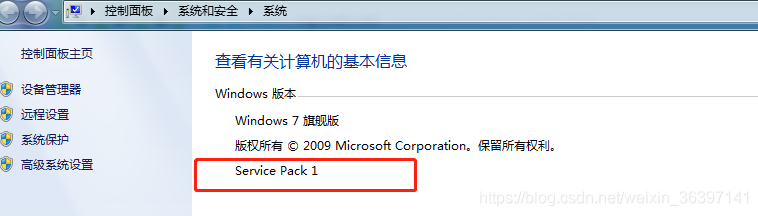
Win7 升级为SP1 补丁64位|32位下载|W补丁包KB976932
这个需要的时间比较长,成功更新系统后,就需要往回推着操作了
如果这两个操作进行完之后还没有解决的话,安装下面的运行库(不管之前有没有安装,再安装一遍,我也是之前用驱动精灵和360软件管家修复了允许库,任然无果,最后也是重新安装了这个运行库合集)
最后完美解决问题
来源: Python爬虫实践:如何优雅地删除豆瓣小组的帖子 – 简书
文章起源于自己的一个需求:想要删除掉自己的若干个小号在豆瓣小组上的发帖及回复记录。这是一件看似简单的事情,但是一遍一遍的重复操作实在让我感到非常绝望,特别是删除自己的回复时,有时候回复的帖子的回复有好几十页,得一页一页的翻。于是就想到用脚本来代替人力操作。对于一名职业为前端工程师的人而言,最容易想到的方法就是打开DevTools发个Ajax请求直接搞定了。不过经历过几次之后发现这种方法很难沉淀下来,于是就想能不能写到脚本里面。一开始依旧想到的是用NodeJS来实现,但是由于最近由于接触程序化交易比较多,发现如果再不温习一下Python大蟒蛇又要忘光了,于是就想借机同时练练Python。
先说结果
两种方式:
git clone https://github.com/acrazing/dbapi.git
cd dbapi
# 安装依赖
pip install -r requirements.txt
pip install dbapi
首先得安装,然后:
python -m dbapi.DoubanAPI test_client login "username" "password"
python -m dbapi.DoubanAPI test_api remove_commented_topic "topic_id"
# topic_id 可以通过下面这个命令拿到:
python -m dbapi.DoubanAPI test_api list_commented_topics
# 这个命令会返回所有自己回复过的帖子
python -m dbapi.DoubanAPI test_api remove_topic "topic_id"
# topic_id 可以通过下面这个命令拿到:
python -m dbapi.DoubanAPI test_api list_user_topics
# 这个命令会返回所有自己发布的帖子
dbcl2设置了HttpOnly,此外还需要一个动态idck。当然这些问题都可以通过把所有的Cookie添加到客户端搞定。通过浏览器抓包发现,相关操作主要有几下几个接口:
POST https://www.douban.com/accounts/login,登录前需要先获取bid等信息,登录时如果不设置redir_url,会自动跳转到豆瓣首页,如果登录失败,则不会跳转,可以据此判断登录是否成功,或者也可以用Cookie信息进行判断。跳转完成后会拿到所有会话所需要的Cookie信息,所以需要跟踪跳转GET https://www.douban.com/accounts/logout?source=group&ck=%s,这里的ck就是会话中的ckGET https://www.douban.com/group/people/%s/publish,有翻页GET https://www.douban.com/group/people/%s/reply,有翻页POST https://www.douban.com/j/group/topic/%s/remove_commentPOST https://www.douban.com/group/topic/%s/remove_comment此外还有一些已实现但是与此无关的接口,可以到代码中dbapi/endpoints.py中查看
Group,用户People等模块等DoubanAPI,对会话缓存,登录登出等操作进行统一管理,并引入了各个模块BaseAPI统一网络请求,并且返回数据有可能是html或者json,所以提供了三个相关接口,同时部分接口需要显式调用ck,所以提供了相关接口requests实现read接口返回的数据都是html格式,这里使用lxml及xpath进行读取logging输出日志略,请参考源代码
除了小组相关API外,还实现了用户People相关的部分API,可以实现获取用户profile,关注用户及关注者,代码在dbapi/People.py中。利用这几个API设计了一个多线程爬虫,用来爬取豆瓣上的热门用户,代码在test/relation.py中,爬取的结果放在__relation__.json中。目前我注册了4个豆瓣账号,开了4个线程进行爬取。最开始由一个种子用户sevear,爬取其关注的用户中关注者大于100的用户,然后逐渐将关注者最小值加到现在的10000。目前已发布到Github的结果中,已经爬取了33599个用户,其中1069个用户的关注者超过了10000。发现了一些比较有趣用户,比如熊阿姨等;也发现热门的用户大多都会贴上自己的微信公众号,微博等信息;还有很多从05年就开始使用豆瓣的重度用户,也有很多注销了的账号。虽然我也很多年前就注册了豆瓣,但是一直没有发现除了发租房贴,看电影评价,听FM(现在已经不用了)之外还有什么其它价值。也许这些人可以给我答案。
setuptools等,并且不熟悉相关的基础包。所以几乎得从零开始,是件很头疼的事情,所幸的是Python的包都比较有名气,包管理等网络上也有很多教程,查找起来都比较容易。感谢互联网~test/relation.py测试发现,目前存在内存泄漏问题,但是捣鼓了半天没有查到问题所在,已经没有兴趣继续花时间了~Please try later以及检测到你的IP有非正常请求发出balabala提示~账号和帐号, 帖子和贴子,求语文老师作者:一路行歌
链接:https://www.jianshu.com/p/6be4845847b6
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
买了本崔大的爬虫书,前边装MongoDB的时候首先出现了各种各样的问题!真是让人头痛!为了以后出现意外,先记录下解决方法。
问题如下:
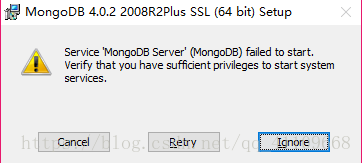
一、
有一篇文章说直接ignore掉,但是经过测试并不行。因为这样的话log文件夹下就不会生成
这可能会造成之后配置系统服务时出错!
废话少说,直接上菜
我的解决方法(大佬勿喷):
(由于我是自定义磁盘安装的)
1.将磁盘名及文件夹名改为英文,一路next,当让选择
不要勾选左下角的选项(从改文章学来的),然后一路next就行了,这样就不会出现让人头痛的Verify that you have sufficient privileges to start system services了。
二、配置系统服务出现的问题
很不负责任的说,我整了3天,基本什么问题都碰到过,崔大说管理员运行cmd再输入mongod –bind_ip 0.0.0.0 –logpath “C:\MongoDB\Server\3.4\logs\mongodb.log” –logappend –dbpath “C:\MongoDB\Server\3.4\data\db” –port 27017 –serviceName “MongoDB” –serviceDisplayName “MongoDB” –install是因为他用的是3.4.4版的MongoDB。我下载的是4.0.2版的
我翻了好多文章,有一篇说4版的不用这么配置,然后我就冒着重新安装的风险试了一下,果然成功!记录步骤如下:
1.先在cmd(管理员身份运行)cd到MongoDB的bin文件夹下,再输入:mongod -dbpath X:\mongo\data\db 我的是X:\mongo\data\db路径,你需要查看自己的路径。
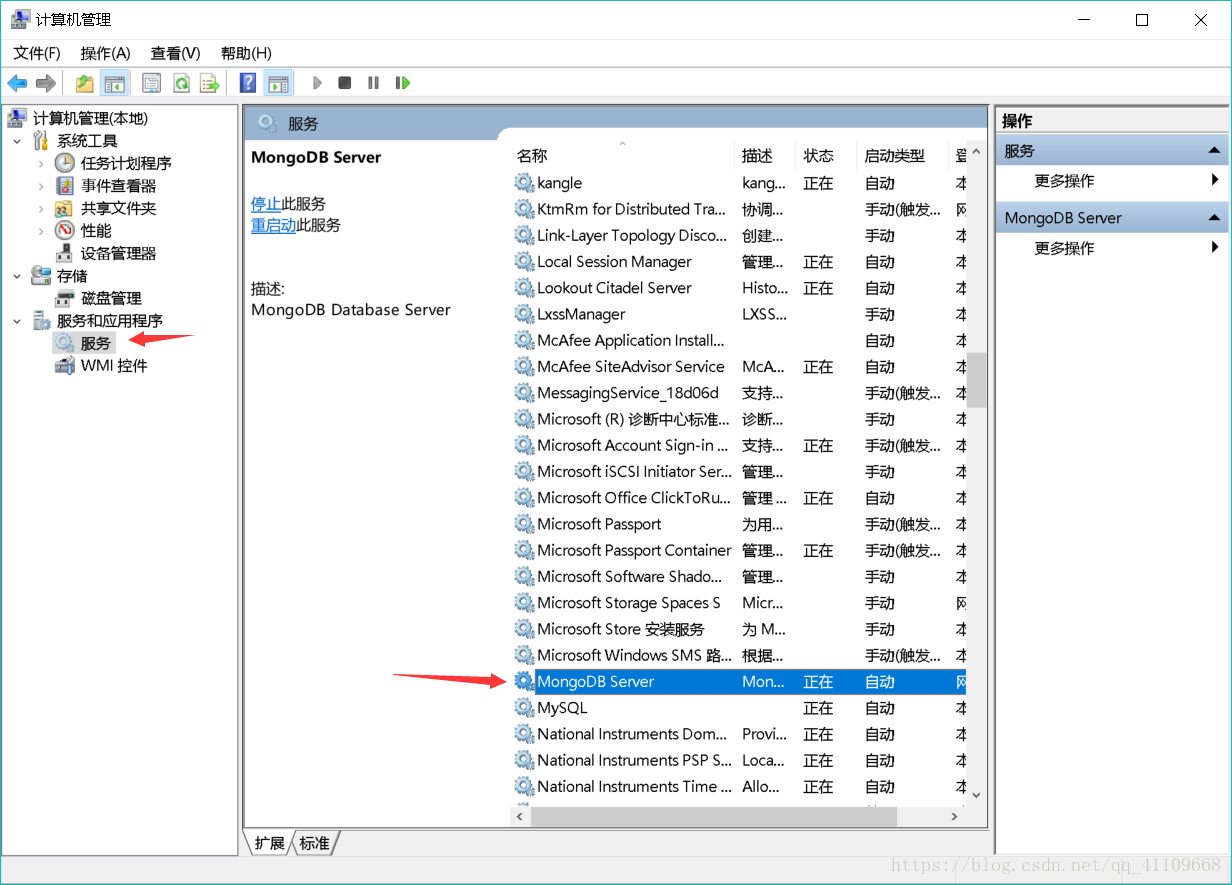
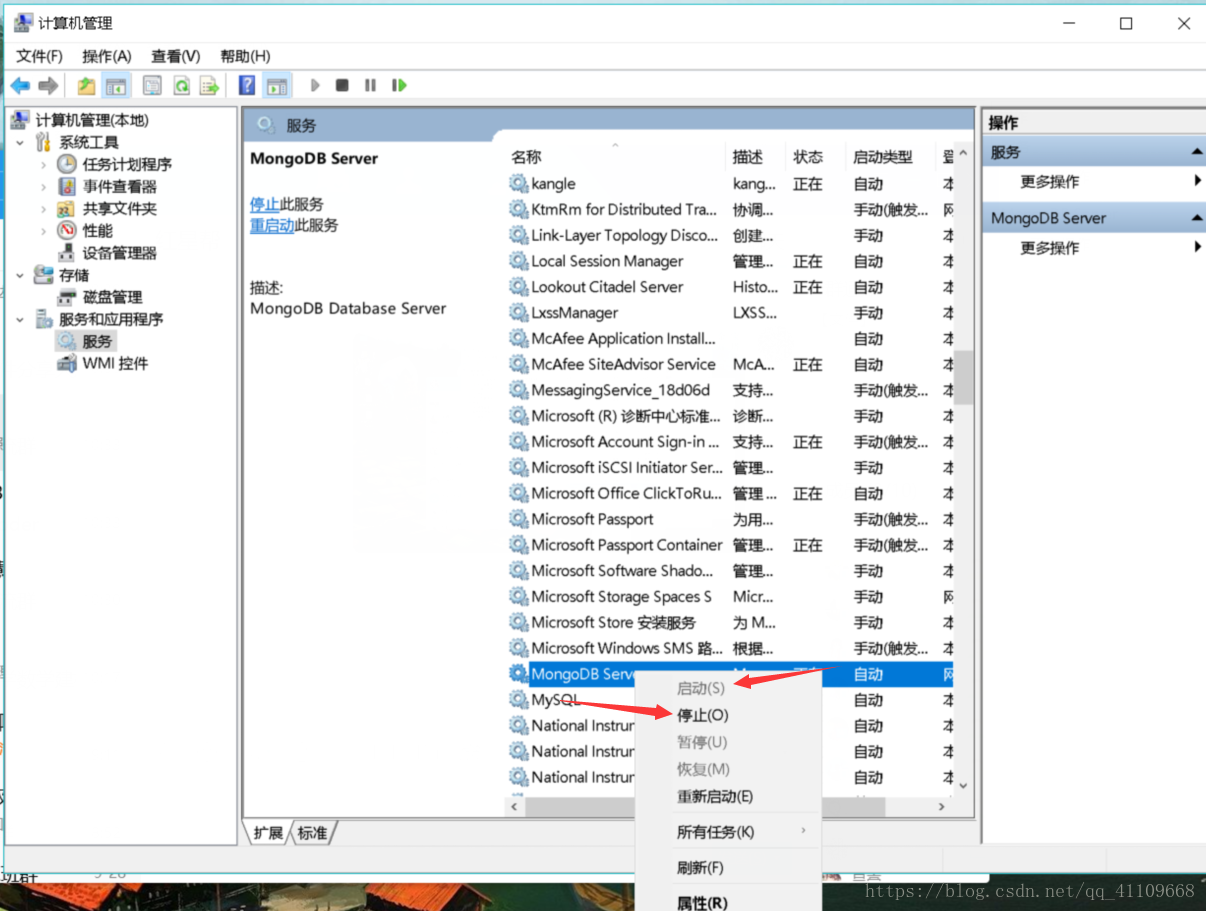
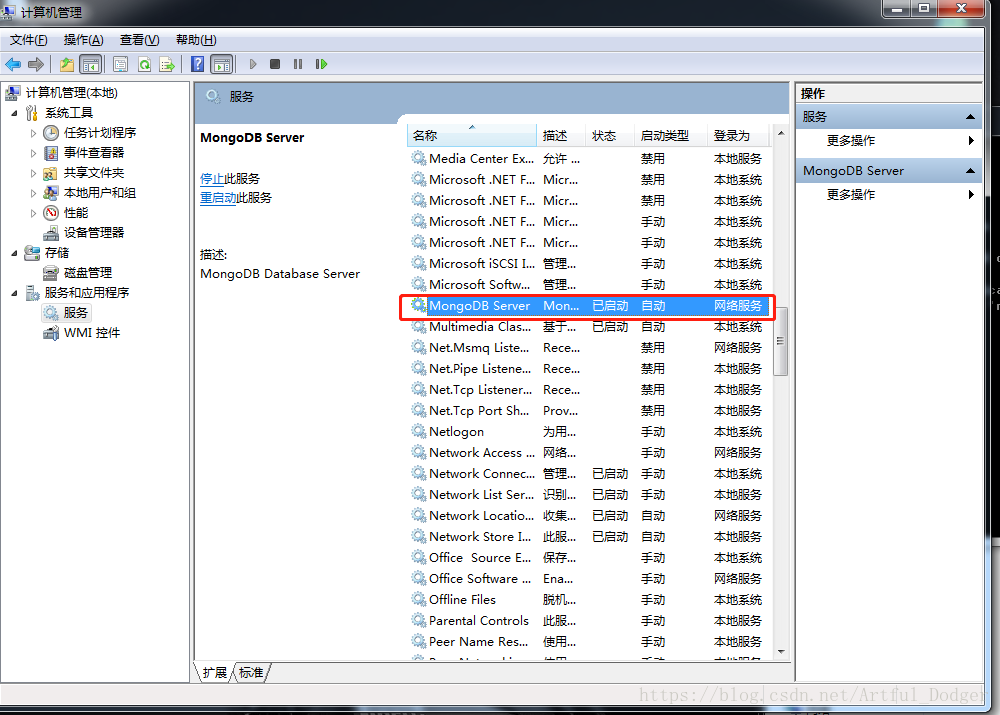
2.打开计算机管理查看是否成功自动启动
右键MongoDB Server:
如图,成功设置其开机启动方式了!
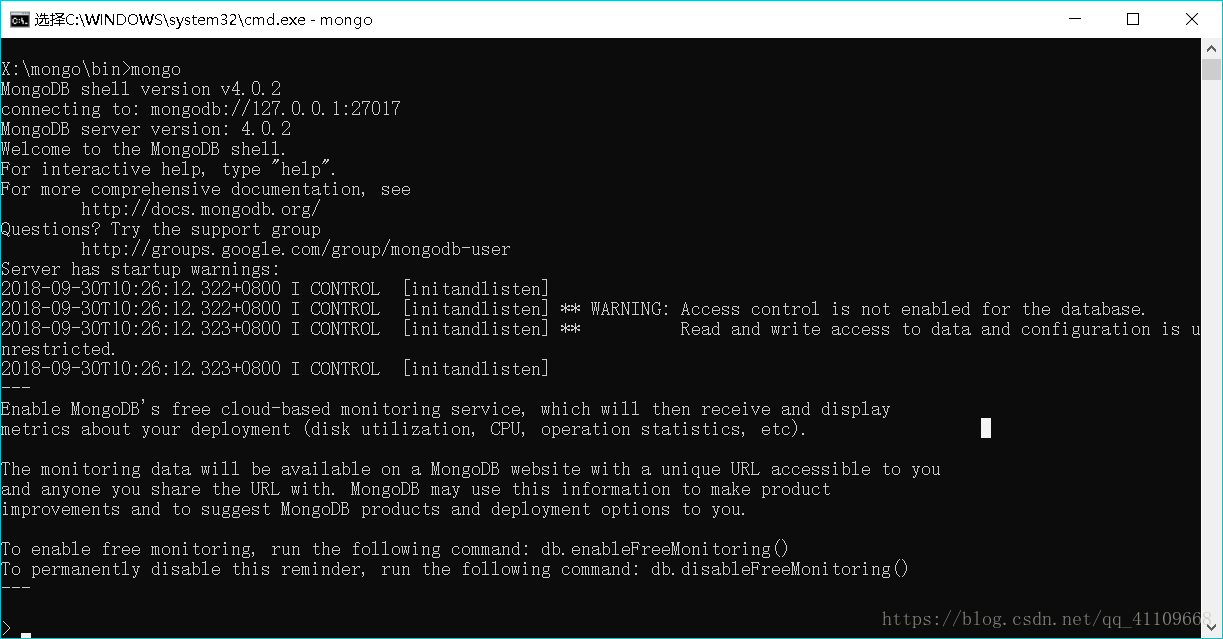
3.最后,在cmd中进入MongoDB交互环境:
成功了…….忙活了3天。遇到警告我选择的是从头再来,一步一步看自己哪儿出问题了。希望对大家有点用处。
来源: MongoDB安装过程中的坑(最后一步卡住)_Artful_Dodger的博客-CSDN博客
1.笔者之前安装MongoDB的时候一路next下去,结果最后一步苦等了一个多小时也没完成,最终从头再来分分钟搞定。
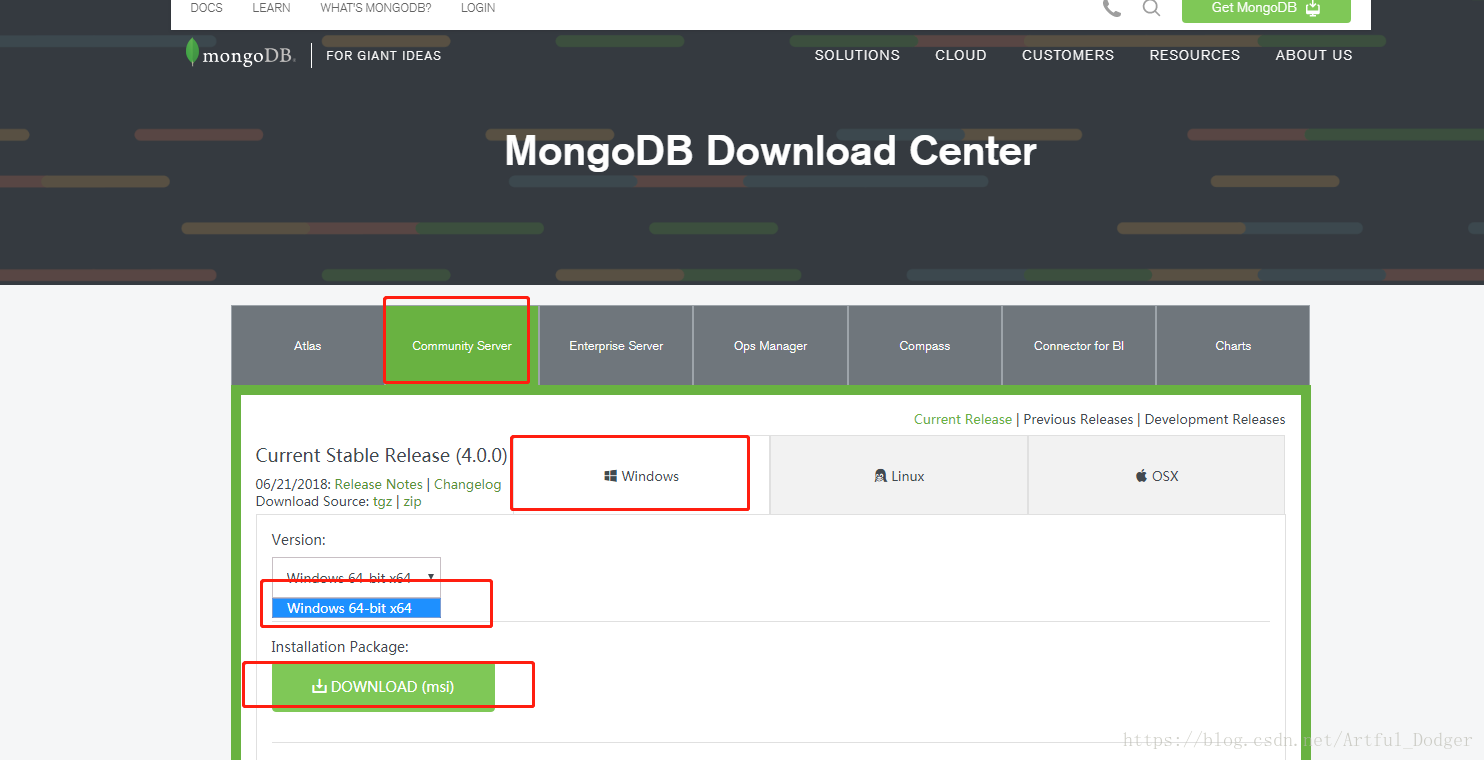
官网下载地址:https://www.mongodb.com/download-center#community 下载 安装包。
2.和大多数软件安装一样,双击开始运行>>下一步
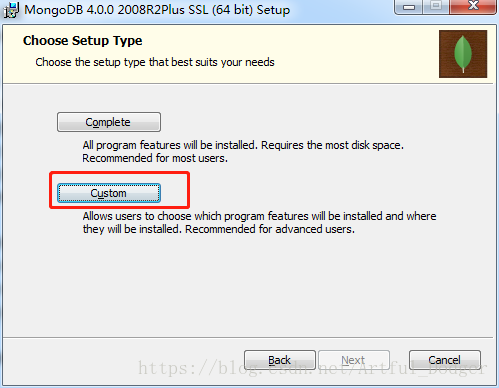
3.选择“custom”自定义安装路径——记得创建一个文件夹如:MongoDB“因为安装会产生几个分散的文件”
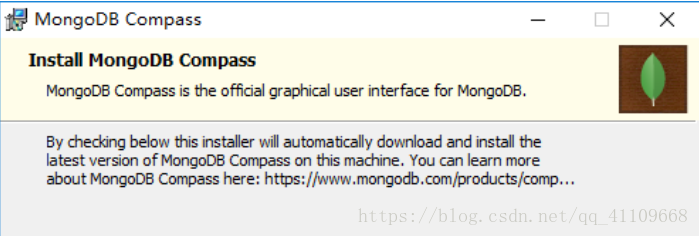
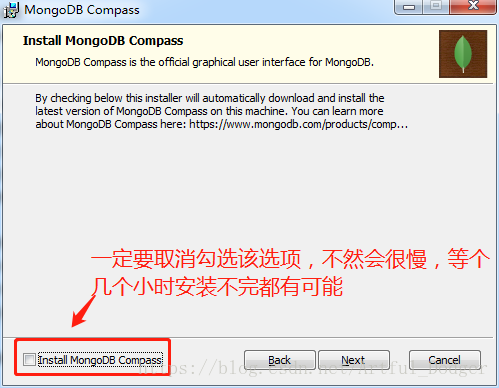
4.前面只要点击下一步都没问题,接下来的一步千万要小心,笔者之前就是一个不留神麻溜的点击了“next”,结果苦等了一个小时也没结束。重要的事情说三遍,“取消”、“取消”、“取消勾选左侧的Install MongoDB Copmpass”选项。
至此一路next下去就安装成功了。
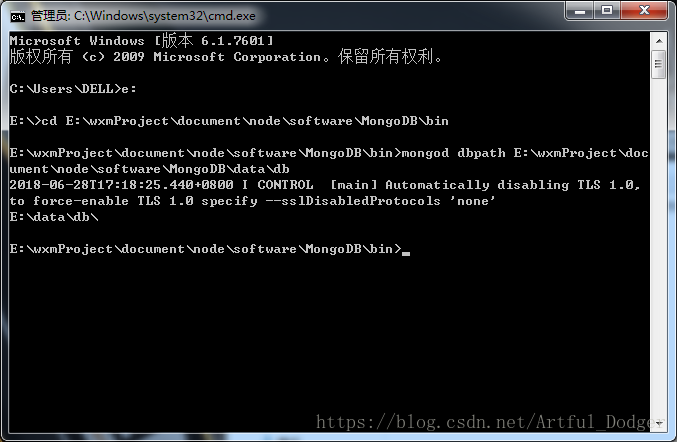
5.MongoDB配置:在MongoDB\data目录下创建文件用来存放数据库文件>>“E:\wxmProject\document\node\software\MongoDB\data\db”因为启动mongodb服务之前必须创建数据库文件的存放文件夹,否则命令不会自动创建,而且不能启动成功。
6.启动MongoDB服务
1.打开cmd命令行,进入MongoDB\bin目录下
2.输入如下的命令启动mongodb服务:mongod –dbpath E:\wxmProject\document\node\software\MongoDB\data\db
(中间遇到了点问题,笔者操作的这台电脑在第2步按下回车键的时候提示缺少:api-ms-win-crt-runtime-l1-1-0.dll文件,于是到别人电脑上考了这个,后来发现又提示:
3.按下回车键即食在我们创建的数据库存放路径db目录下启动。
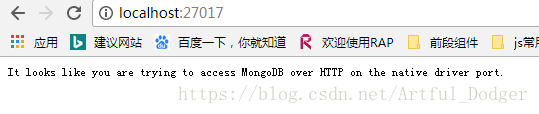
4.在浏览器输入http://localhost:27017 (27017是mongodb的端口号)查看,若显示如下则表示连接成功,否则查看端口是否被占用,杀掉相应进程cmd里重新走第2步。
来源: MongoDB中的 Limit和Skip方法实现分页,Sort实现排序,Count实现统计个数,distinct去除重复数据(八) – 极客分享
MongoDB也有Limit读取指定数量的数据记录,Skip 跳过指定数量的数据,它俩结合起来就可以做一个分页
Sort是MongoDB内置的排序方法,和上面的Limit,Skip可以合用
准备测试数据
语法
db.collection.find().limit(Number) //Number 读取的记录条数
开始测试
注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。
语法
开始测试
这样就可以查询从第3个文档开始,查询2个文档,
执行顺序:先skip() 再 limit(),右到左
MongoDB中 sort() 方法可以根据指定字段进行数值比较排序,参数1 是正序(递增),参数 -1 是倒叙(递减)
语法
db.collection.find().sort({字段名:参数(1或-1)})
准备数据
正序
倒叙
db.collection.find().limit().skip().sort()
执行顺序从右到左,先sort(),再skip(),再limit()
语法:
db.collection.find({条件}).count()
或者
db.collection.count({条件})
测试
1、查询所有的文档条数
2、查询成绩在85分及以上的同学的分数
另一种方法
语法 :
db.collection.distinct(去重字段名,{条件})