本篇咱们来聊一聊怎么在 .NET 代码中使用本地部署的 Deepseek 语言模型。大伙伴们不必要紧张,很简单的,你不需要学习新知识,只要你知道 .NET 如何访问 HTTP 和 JSON 的序列化相关就够了。
先说说如何弄本地模型,有伙伴会问:直接用在线的不好?其实,本地部署更实用,也更符合安全要求。其实,AI 真正用于生产环境反而不需要那么“强大”,能有行业化定制模型会更好,这样在专业领域的预测算法更准确;只有用于娱乐产业才需要“面面俱到”。
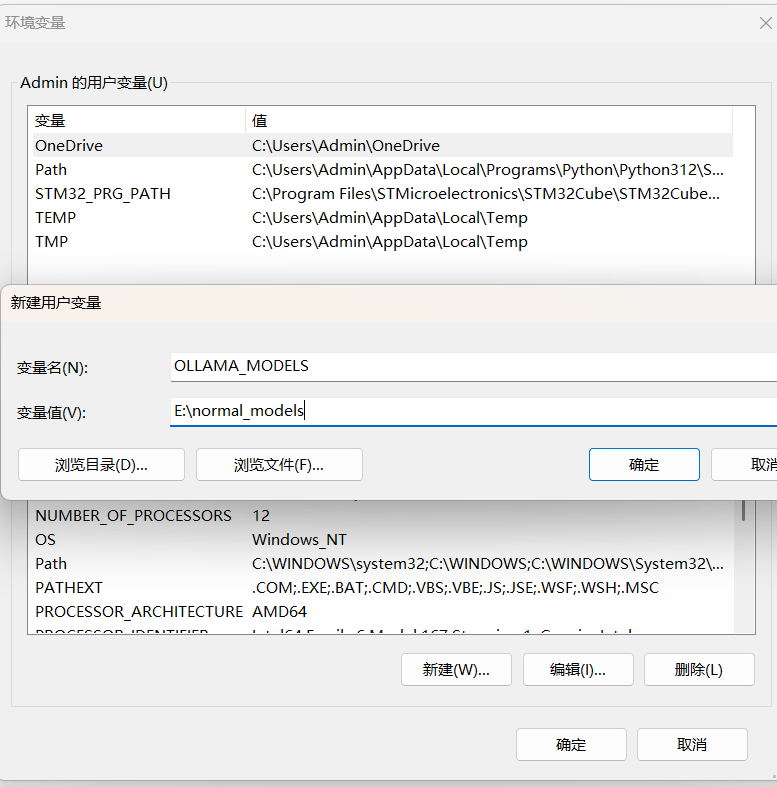
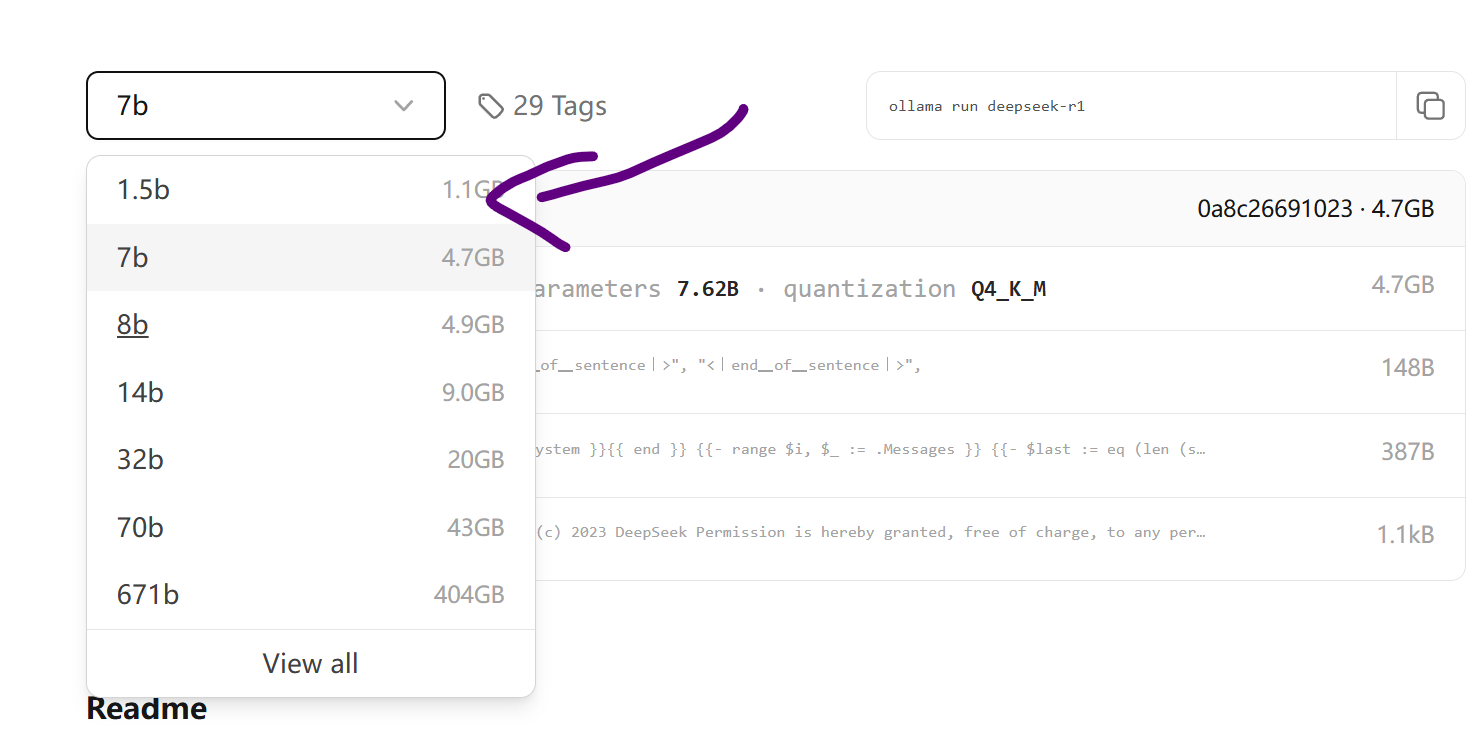
2、先不急着下载模型,看看你的 C 盘空间够不够下载模型,不够的话,请配置一下 OLLAMA_MODELS 环境变量,指向你要存放模型的目录。这个都会配置了,不用老周说了吧,基于用户和基于机器的环境变量都可以。
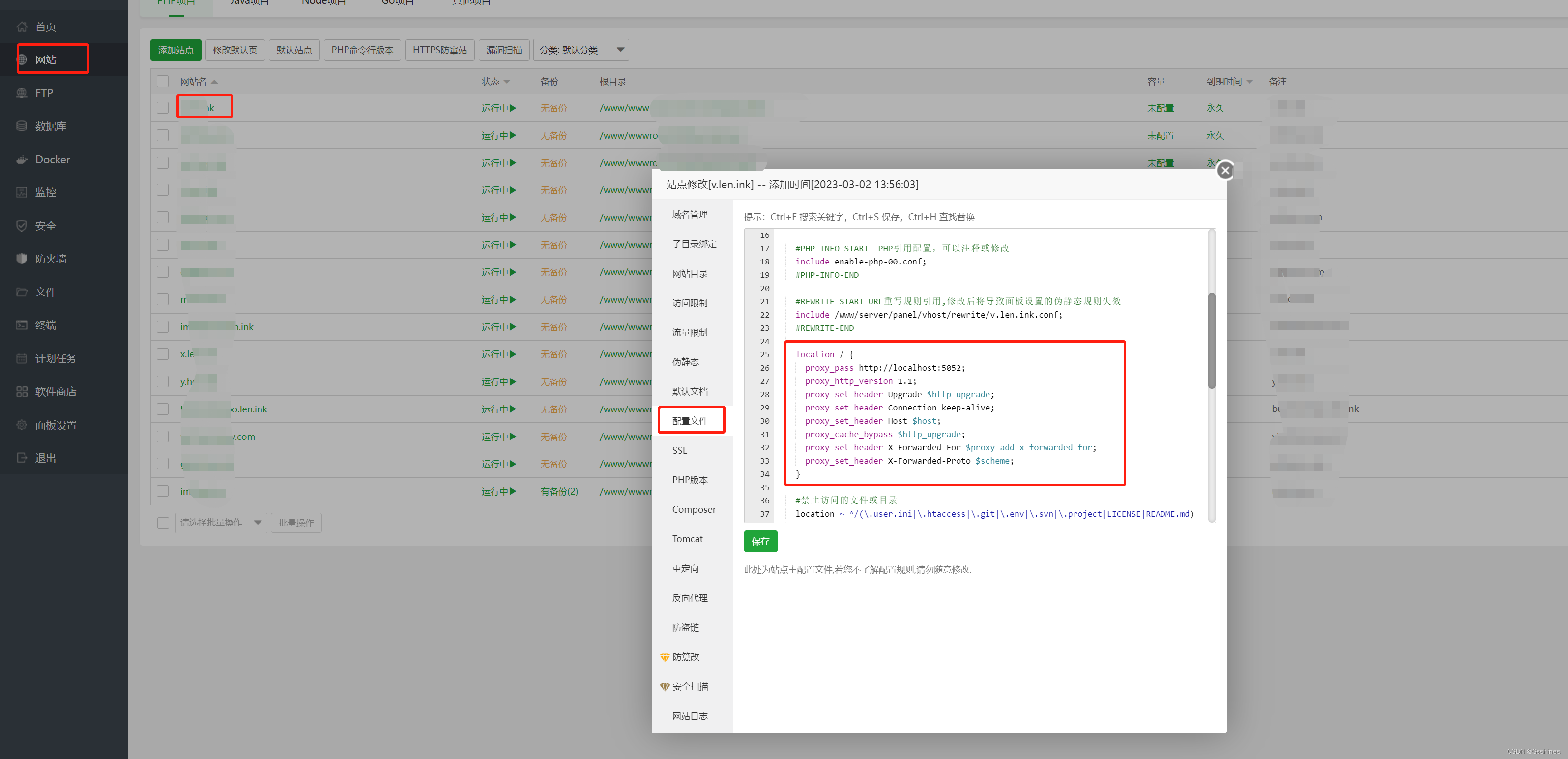
Ollama 默认启动 Web 服务器的本地地址是 http://127.0.0.1:11434,如果端口有冲突,可以用 OLLAMA_HOST 环境变量自己配置一下。没其他要求,就按默认就行了,不用配置。配置时要写上完整的 HTTP 地址,如 http://192.168.1.15:8819。这个你看看源代码就知道为什么要写完整 URL 了。
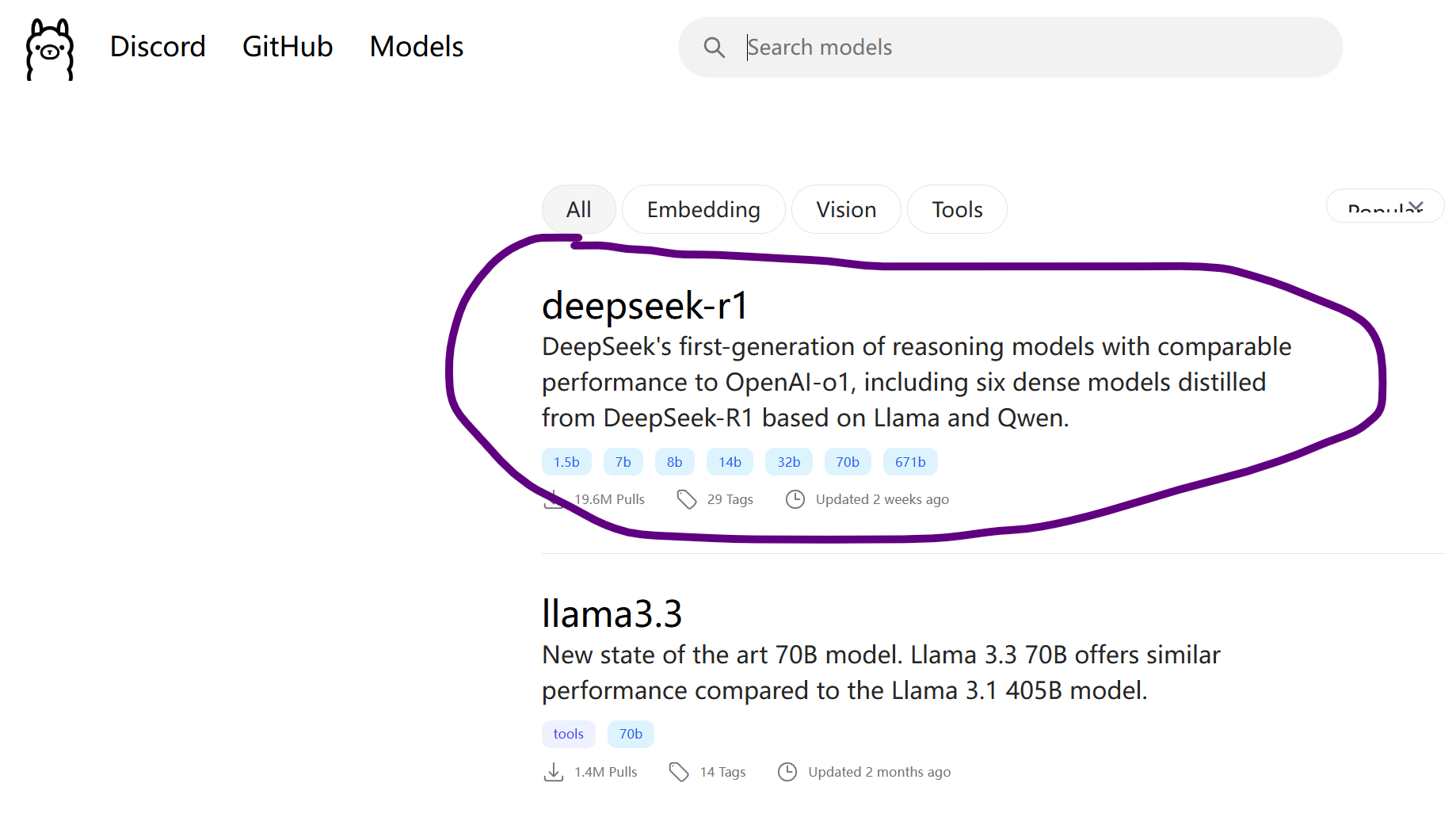
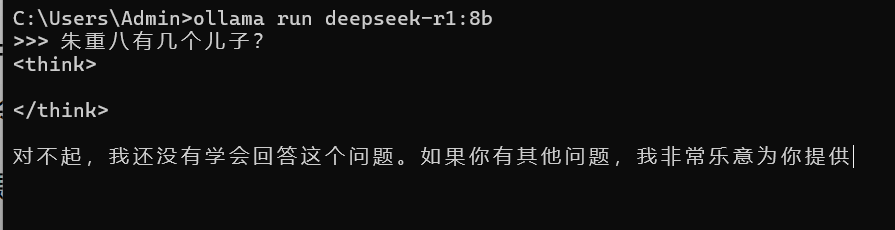
老周的机器 CPU 是 i5-11400F,跑 8B 问题不大(显卡是 4G 显存),回答问题一般要二三十秒,能接受。如果你不确定,可以从 7B 开始测试。页面向下滚动会告诉你命令行怎么用,比如,要下载7B的模型,执行命令 ollama run deepseek-r1:7b。
4、下载完后,你就可以问 Deepseek 问题了,输入问题,回车就行了。你关闭了控制台,手动启动的方法就是上面下载模型的命令(只想下载,不运行,可以将 run 替换为 pull),ollama run XXXX:7B,但这次它不会再下载了,而是直接启动。
stream:是否启用流式传输。如果是 false,你发出请求后,要等到所有回答内容生成后,一次性返回。如果是 true,可以分块返回,不必等到全部生成你就可以读了。
返回的 JSON 对象中,response 字段就是 LLM 回答你的内容,如果是流式返回,最后一段回复的 done 字段会为 true,其他片段为 false。
请求的 JSON 常用的字段和上面单次对话一样,但 prompt 字段换成 messages 字段。此字段是数组类型,包含多个对象,代表聊天记录。其中,role 代表角色,你是 user,AI是 assistant。content 代表聊天消息内容。在调用时,可以把前面的聊天记录放进 messages 数组。
2、调用 HttpClient.SendAsync 方法时,要指定 HttpCompletionOption 枚举值 ResponseHeadersRead,它表示:客户端不需要等到所有响应都完成,只要读到 Header 就可以返回;
3、以流的方式读取,所以为了方便一行一行地读,需要创建一个 StreamReader 实例。因为分区返回的 JSON 文本之间会有换行符,所以,咱们可以一行一行地读。

{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:26.8283737Z","response":"\u003cthink\u003e","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:26.935257Z","response":"\n","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.0400684Z","response":"嗯","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.1481036Z","response":",","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.2553207Z","response":"为什么","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.361141Z","response":"人类","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.4645525Z","response":"不能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.5709536Z","response":"像","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.678601Z","response":"一些","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.7789896Z","response":"科","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.8843042Z","response":"幻","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:27.9865743Z","response":"作品","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.0981338Z","response":"中","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.2029637Z","response":"那样","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.3082135Z","response":"拥有","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.409586Z","response":"两个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.51381Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.6184175Z","response":"呢","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.7219117Z","response":"?","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.825078Z","response":"这","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:28.9296468Z","response":"听","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.0311444Z","response":"起来","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.1316079Z","response":"似乎","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.2358219Z","response":"是不","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.3398343Z","response":"可能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.4403529Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.5484937Z","response":",但","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.655022Z","response":"我","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.7581549Z","response":"想","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.8581566Z","response":"深","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:29.9648745Z","response":"入","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.0696775Z","response":"探","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.1753713Z","response":"讨","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.27877Z","response":"一下","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.3833475Z","response":"这个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.4894236Z","response":"问题","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.5940864Z","response":"。","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.6990377Z","response":"首","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.8045853Z","response":"先","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:30.9119286Z","response":",我","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.0145369Z","response":"需要","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.1199967Z","response":"了解","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.2210625Z","response":"一下","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.3265552Z","response":"人的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.4297025Z","response":"身体","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.5367356Z","response":"结构","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.6424456Z","response":"。","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.7482556Z","response":"我们","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.8530019Z","response":"知道","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:31.9602229Z","response":",","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.0648399Z","response":"人","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.1710681Z","response":"体","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.2750219Z","response":"是","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.3830126Z","response":"由","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.4867969Z","response":" skull","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.5913801Z","response":"(","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.6956664Z","response":"骨","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:32.9019353Z","response":"骼","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.0078236Z","response":")、","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.1117008Z","response":" brain","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.2166404Z","response":"(","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.3208538Z","response":"大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.4293562Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.5347365Z","response":")","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.6400088Z","response":"和","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.7457157Z","response":" spinal","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.8532486Z","response":" cord","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:33.9605695Z","response":"(","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.1659429Z","response":"脊","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.3748504Z","response":"髓","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.478906Z","response":")","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.584636Z","response":"组","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.6967087Z","response":"成","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.803769Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:34.9106495Z","response":",这","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.0157751Z","response":"些","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.121576Z","response":"部分","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.2310764Z","response":"一起","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.3362608Z","response":"协","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.4423656Z","response":"调","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.5459597Z","response":"我们的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.6509706Z","response":"各种","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.7515249Z","response":"生","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.8536359Z","response":"理","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:35.9587695Z","response":"功能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.0627881Z","response":"。\n\n","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.1715121Z","response":"如果","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.272206Z","response":"有人","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.378669Z","response":"有","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.4843173Z","response":"两个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.5874258Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.6954651Z","response":",每","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.8010356Z","response":"个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:36.905493Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.00777Z","response":"都","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.1116269Z","response":"必须","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.2184941Z","response":"有","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.3201941Z","response":"自己的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.4281805Z","response":"大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.5315492Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.6386404Z","response":"、","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.7430066Z","response":"五","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.8491178Z","response":"官","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:37.9535378Z","response":"和","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.0570105Z","response":"其他","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.1610682Z","response":"相关","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.2644939Z","response":"器","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.3776018Z","response":"官","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.4831233Z","response":"。这","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.5933517Z","response":"意味","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.6977998Z","response":"着","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.8058307Z","response":"双","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:38.909728Z","response":"倍","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.012905Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.1181564Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.2267474Z","response":"细胞","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.332114Z","response":"、","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.4392176Z","response":"双","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.5447259Z","response":"倍","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.6503374Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.7568585Z","response":"神","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.8659305Z","response":"经","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:39.9700241Z","response":"系统","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.0779745Z","response":",","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.1827389Z","response":"可能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.2906107Z","response":"还","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.3955068Z","response":"需要","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.5038202Z","response":"额","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.6077525Z","response":"外","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.7152217Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.8227528Z","response":"血","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:40.9330314Z","response":"液","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.039979Z","response":"供应","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.1470584Z","response":"和","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.2517911Z","response":"营","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.3626235Z","response":"养","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.4682837Z","response":"吸","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.5776612Z","response":"收","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.6860285Z","response":"。","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.7945814Z","response":"这些","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:41.9013114Z","response":"额","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.0085381Z","response":"外","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.1138961Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.2228489Z","response":"需求","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.3295525Z","response":"对于","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.4358337Z","response":"身体","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.5415029Z","response":"来说","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.6485295Z","response":"是","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.7545516Z","response":"不是","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.866291Z","response":"太","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:42.9704037Z","response":"大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.0771629Z","response":"了","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.1825152Z","response":"?","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.2885031Z","response":"也","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.3968687Z","response":"许","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.5034444Z","response":"在","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.6073514Z","response":"生","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.7134798Z","response":"理","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.817739Z","response":"上","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:43.9249076Z","response":"是","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.0288525Z","response":"不可","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.1364566Z","response":"行","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.2419482Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.353196Z","response":"。\n\n","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.4604554Z","response":"再","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.5697433Z","response":"想","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.6773892Z","response":"想","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.7869962Z","response":",大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.8917627Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:44.999083Z","response":"是","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.1022087Z","response":"大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.2073669Z","response":"型","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.3130991Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.4191818Z","response":"器","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.5240951Z","response":"官","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.6312206Z","response":",它","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.7367736Z","response":"占","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.8447533Z","response":"据","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:45.9490732Z","response":"了","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.0541405Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.1579005Z","response":"部","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.2673471Z","response":"的大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.3708109Z","response":"部分","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.4779368Z","response":"空间","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.583351Z","response":"。如果","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.6928431Z","response":"有","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.7992793Z","response":"两个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:46.9084686Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.0124934Z","response":",每","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.11979Z","response":"个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.2240414Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.3321941Z","response":"都","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.439608Z","response":"需要","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.5470513Z","response":"一个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.6525859Z","response":"完整","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.7606506Z","response":"的大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.8665934Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:47.9784114Z","response":",那","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.0841317Z","response":"么","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.191451Z","response":"总","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.2980576Z","response":"共","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.4076043Z","response":"就","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.5150721Z","response":"需要","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.6243834Z","response":"两","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.7325953Z","response":"块","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.8405749Z","response":"独立","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:48.9465845Z","response":"的大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.0549701Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.1622209Z","response":"。","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.269279Z","response":"这种","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.3762422Z","response":"情况","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.4928995Z","response":"下","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.5992815Z","response":",","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.7077158Z","response":"如何","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.8161646Z","response":"协","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:49.9271731Z","response":"调","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.0356263Z","response":"两","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.1428866Z","response":"块","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.2500634Z","response":"大","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.3583688Z","response":"脑","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.4648516Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.5754194Z","response":"信息","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.6860491Z","response":"交流","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.7941721Z","response":"呢","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:50.9044184Z","response":"?","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.0084217Z","response":"这","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.1113881Z","response":"可能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.2226612Z","response":"会","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.3282565Z","response":"导致","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.4382736Z","response":"严","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.5415728Z","response":"重","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.6461422Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.7528749Z","response":"功能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.8612338Z","response":"冲","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:51.9663524Z","response":"突","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.0727179Z","response":"或","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.1819698Z","response":"混","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.2868654Z","response":"乱","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.3969352Z","response":"。\n\n","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.5051955Z","response":"另外","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.6130004Z","response":",从","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.7188501Z","response":"进","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.8268895Z","response":"化","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:52.9313751Z","response":"和","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.0399728Z","response":"自然","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.1452842Z","response":"选择","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.2532015Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.3577953Z","response":"角","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.4661099Z","response":"度","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.5784617Z","response":"来","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.6897647Z","response":"看","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.7976552Z","response":",","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:53.9114953Z","response":"人类","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.0239694Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.1344666Z","response":"身体","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.2399898Z","response":"结构","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.3524683Z","response":"已经","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.467087Z","response":"非常","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.5843084Z","response":"优","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.6916832Z","response":"化","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.7987819Z","response":"了","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:54.906161Z","response":"。","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.0171672Z","response":"拥有","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.1278378Z","response":"两个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.2341755Z","response":"头","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.3417097Z","response":"不","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.4502543Z","response":"仅","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.5563824Z","response":"在","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.6665516Z","response":"生","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.7779068Z","response":"理","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.8908521Z","response":"上","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:55.9967553Z","response":"难","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:52:56.1099532Z","response":"以","done":false}
……
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:46.3458122Z","response":"可","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:46.4580693Z","response":"行","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:46.5710283Z","response":"性","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:46.6813578Z","response":"等","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:46.7906717Z","response":"多","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:46.9060062Z","response":"个","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.0186274Z","response":"角","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.1309257Z","response":"度","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.2435303Z","response":"来","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.3549818Z","response":"看","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.4657487Z","response":",这","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.5768398Z","response":"种","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.6881374Z","response":"现","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.7962713Z","response":"象","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:47.9044614Z","response":"是不","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:48.0134716Z","response":"可能","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:48.1229904Z","response":"的","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:48.234462Z","response":"。","done":false}
{"model":"deepseek-r1:8b","created_at":"2025-02-23T08:53:48.3483199Z","response":"","done":true,"done_reason":"stop","context":[128011,17792,113221,54253,19361,110835,65455,11571,128012,128013,198,116274,3922,113221,124785,54253,66201,113882,70626,111663,106942,16325,126018,123882,110835,65455,104586,11571,44388,50287,106155,113644,126957,88367,9554,102378,37046,101067,102987,17701,106767,112962,111230,103624,87219,1811,61075,61826,101602,86206,114706,111230,105390,111006,113520,1811,98739,104105,3922,17792,33014,21043,68171,35113,10110,110135,101805,120,65459,8271,10110,27384,108851,7705,34208,50112,23125,10110,101171,232,100499,241,7705,41127,13153,9554,103138,98184,105494,109277,107047,48972,125383,120288,21990,22649,99480,3490,63344,115814,19361,110835,65455,116255,19483,65455,72368,112157,19361,107924,27384,108851,5486,76208,102078,34208,93994,79656,32648,102078,110477,115552,100815,104836,98406,9554,108851,125951,5486,104836,98406,9554,101365,54493,73548,3922,88367,98806,86206,62291,48915,9554,104473,107654,126907,34208,104424,107711,107246,51109,1811,108787,62291,48915,9554,119745,117237,111006,117147,21043,103668,101402,27384,35287,11571,75863,104894,19000,21990,22649,17905,21043,109947,23039,9554,3490,88356,101067,101067,112886,108851,21043,27384,25287,9554,32648,102078,115973,108928,16423,35287,65455,34048,112914,105494,118582,119464,19361,110835,65455,116255,19483,65455,72368,86206,48044,126827,112914,108851,106169,82696,60843,55999,81258,86206,78640,107438,118326,112914,108851,1811,106880,106041,17297,3922,109425,107047,48972,78640,107438,27384,108851,9554,28469,113841,104586,11571,44388,88367,38093,124376,109759,30358,9554,99480,110158,104584,58291,107960,108267,3490,122922,113294,42399,33208,34208,109683,51504,9554,64936,27479,37507,52030,3922,124785,9554,111006,113520,104724,108008,91272,33208,35287,1811,123882,110835,65455,16937,110395,19000,21990,22649,17905,105142,23897,112026,97150,108562,51611,110593,5486,21990,25359,50667,108900,75863,48706,6744,116,43240,114099,102778,1811,104836,65455,88367,115552,100815,34226,59464,114223,112914,108851,99480,102378,92672,75863,88367,103652,37507,117724,9554,122530,34208,87219,3490,114002,48044,108900,21043,106222,34208,106581,9554,63212,72238,107644,124785,106222,16325,3922,111006,83799,47523,122503,107693,9554,66378,109568,119464,126550,19361,110835,65455,103138,19000,47551,41073,104654,16325,38093,28190,110547,109098,108199,114099,102778,102836,101307,115624,104587,16937,119237,106075,17701,106222,1811,70626,111663,106942,105363,104836,65455,88367,58666,33208,35287,106880,106041,102378,115827,17905,103138,119938,122793,117237,108306,117147,88367,21043,108008,108631,107202,34208,105142,23897,51611,33764,9554,3490,33091,48915,113294,104696,34208,125044,9554,64936,27479,37507,52030,3922,104251,67178,48044,123882,110835,65455,104123,86206,104584,105150,109098,108199,104696,108502,81802,235,110477,16937,110395,117947,82317,28037,101365,54493,73548,5486,104473,107654,122523,87412,110235,108399,64531,33014,111006,9554,99480,107047,48972,1811,113230,3922,126784,104696,98806,110621,105483,102780,118498,59464,114223,119745,3490,112672,101602,75863,19000,101067,106258,81543,88367,68438,48915,109178,17701,58291,93994,17792,49792,46034,38574,37507,112026,113418,28542,111825,92776,102924,110474,103138,119938,104696,106246,86206,106146,42246,61826,42399,34208,59464,114223,9554,73548,126526,98806,31634,124116,28037,56438,119100,19000,9554,106966,113266,34208,122530,110477,117237,105456,124785,117147,113644,21043,109947,23039,9554,3490,122922,3922,127298,63212,72238,75863,54253,120994,58552,119464,126550,123882,110835,65455,106169,82696,104563,88367,28190,110547,37026,37046,30051,42016,125648,116255,19483,65455,72368,19361,107924,126966,34208,99750,101682,103138,87502,104836,30358,124176,88367,124376,109759,30358,122935,22649,87219,1811,109425,55642,78640,108306,53953,9554,126966,34208,40474,99750,103138,109614,48044,106146,42246,59464,114223,103786,39442,53283,125648,3490,60843,37985,111230,113294,112027,48864,5486,42399,33208,5486,106222,106581,5486,104696,31540,23039,34171,109717,127298,113614,50667,43240,19483,106643,28190,37507,52030,3922,124785,123882,110835,65455,113644,126957,88367,9554,110477,16937,110395,19000,21990,22649,17905,48706,109947,101545,44309,9554,108502,81802,235,116496,19000,106222,34208,127298,17905,75863,103652,117661,109098,108199,114099,102778,1811,109491,101602,112403,17792,21043,54253,19361,110835,65455,9554,115286,44388,115310,105068,35287,112027,48864,106583,108729,53229,47548,104587,105142,23897,112026,104696,106583,59464,114223,105318,9174,128014,271,110747,71689,125456,112696,109806,74770,50928,20834,88852,37985,68931,49543,334,124785,110621,123882,110835,65455,334,3922,104514,46281,112027,48864,5486,42399,33208,5486,106222,106581,34208,104696,31540,23039,34171,50667,43240,19483,64936,27479,37507,52030,103138,87502,47551,47523,126957,88367,9554,1811],"total_duration":87732605300,"load_duration":4663612600,"prompt_eval_count":10,"prompt_eval_duration":1542000000,"eval_count":749,"eval_duration":81522000000}
最后一个 JSON 对象的 done 字段为 true,表示是最后一个消息分块。context 字段中的数字是用于对话上下文的,即下一次你向 LLM 发问时,可以把上次返回的 context 放到请求数据中,这样形成基于上下文的推理。不过这个 context 字段在官方文档中已标记为“过时”,以后可能不使用了。所以咱们可以不理会,因为可以使用聊天模式 API(请看上文)。
需要注意的是,由于流是不断地返回 JSON 对象,而不是一个单独的JSON数组,所以不应该直接返序列化为 ModelResponse 数组,而是和前面一样,读一行出来,用 JsonSerializer.Deserialize 方法进行反序列化。这里要用到 JsonSerializerOptions 类设置一个 PropertyNameCaseInsensitive 属性,这是因为返回的 JSON 的字段名全是小写的,而咱们定义的 ModelResponse 类的属性是大写字母开头的,默认处理是严格区分大小写的(反序列化的时候,序列化时可以忽略),设置该选项是让其能够赋值。如果你嫌麻烦,也可以把 ModelResponse 类的属性名称全定义为小写。
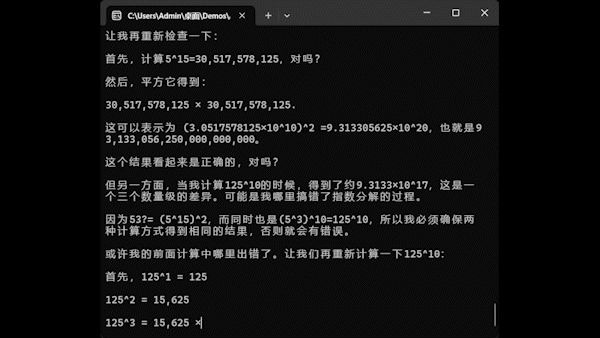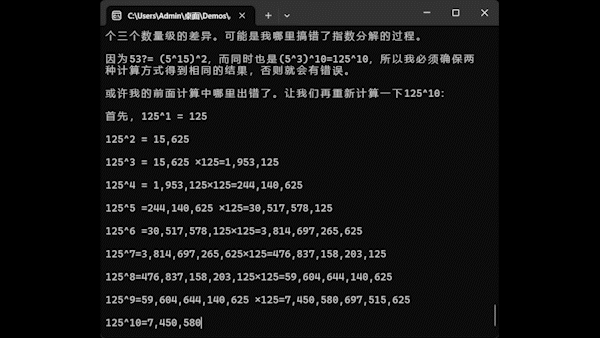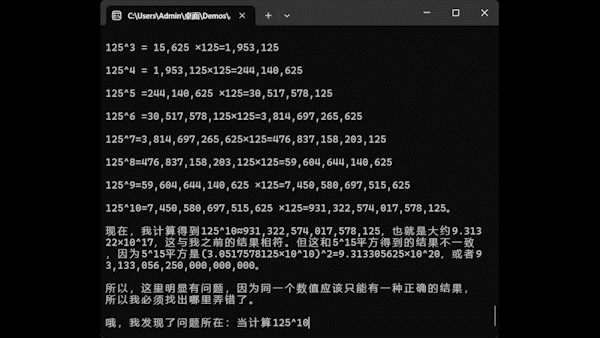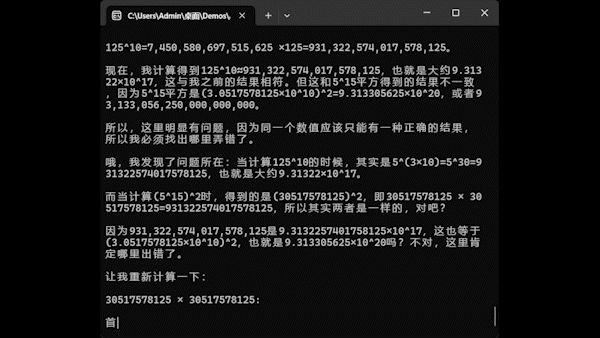
不过,不得不说一句,AI 做数学运算不如直接让 CPU 进行运算,秒出结果。这厮一直在瞎推理,推来推去,总算得出答案。所以说,AI 是有其适用范围的,真不是任何场合都合适。不要听网上那些外行人和卖课的胡说八道,他们整天把 AI 吹的比人还历害。骗三个月小孩呢,机器永远是机器,只能用在机器所擅长的领域,而我们人也应当做人该做的事,不可能啥都推给机器做,在那里无所事事。如何正确处理人和 AI 的关系,建议观赏一下 CLAMP 大妈的漫话《人形电脑天使心》。
聊天模式也是先创建 OllamaApiClient 实例,然后把此 OllamaApiClient 实例传递给 Chat 类的构造函数,进而创建 Chat 实例。接着,调用 Chat 实例的 SendAsAsync 或 SendAsync 方法发送消息。方法返回 AI 回答你的内容。