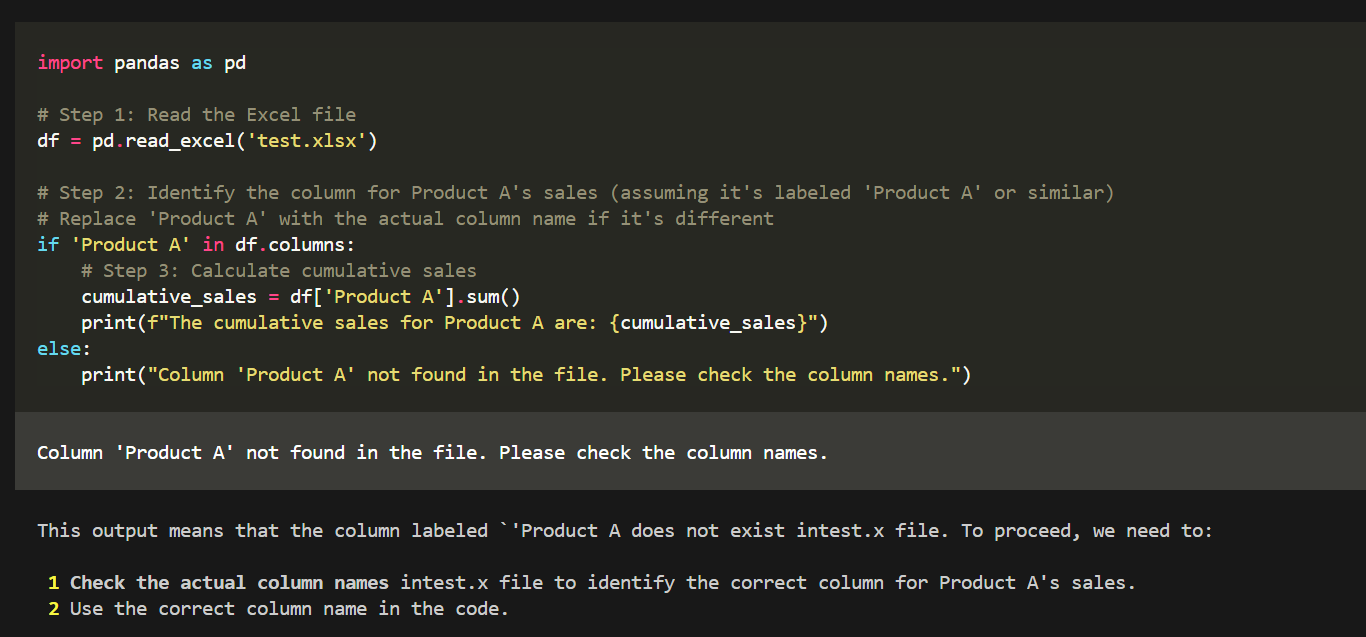
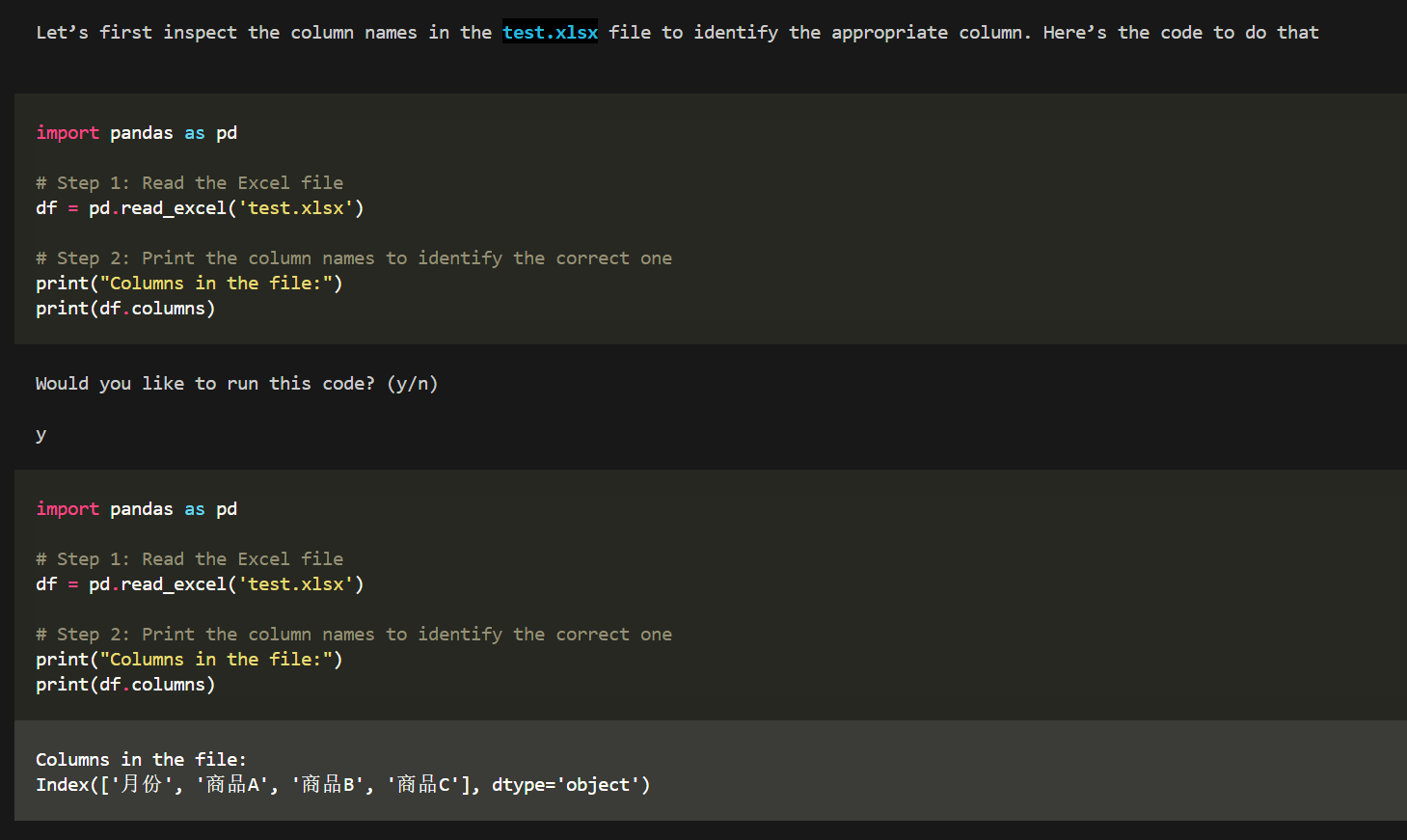
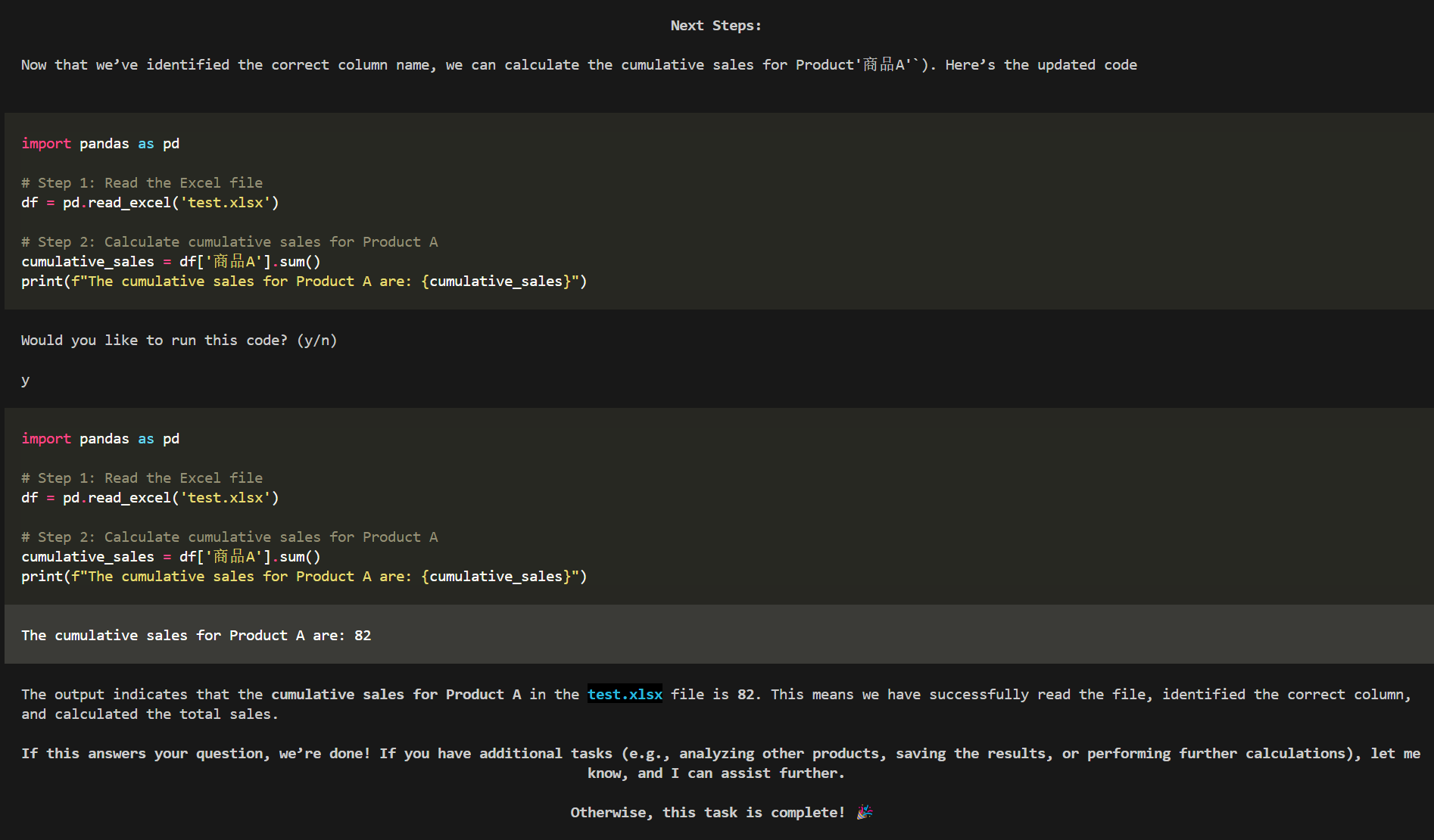
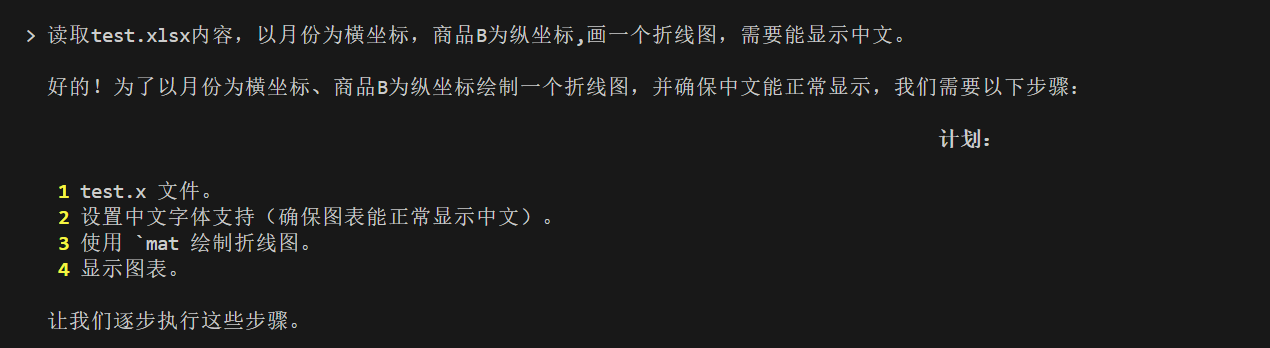
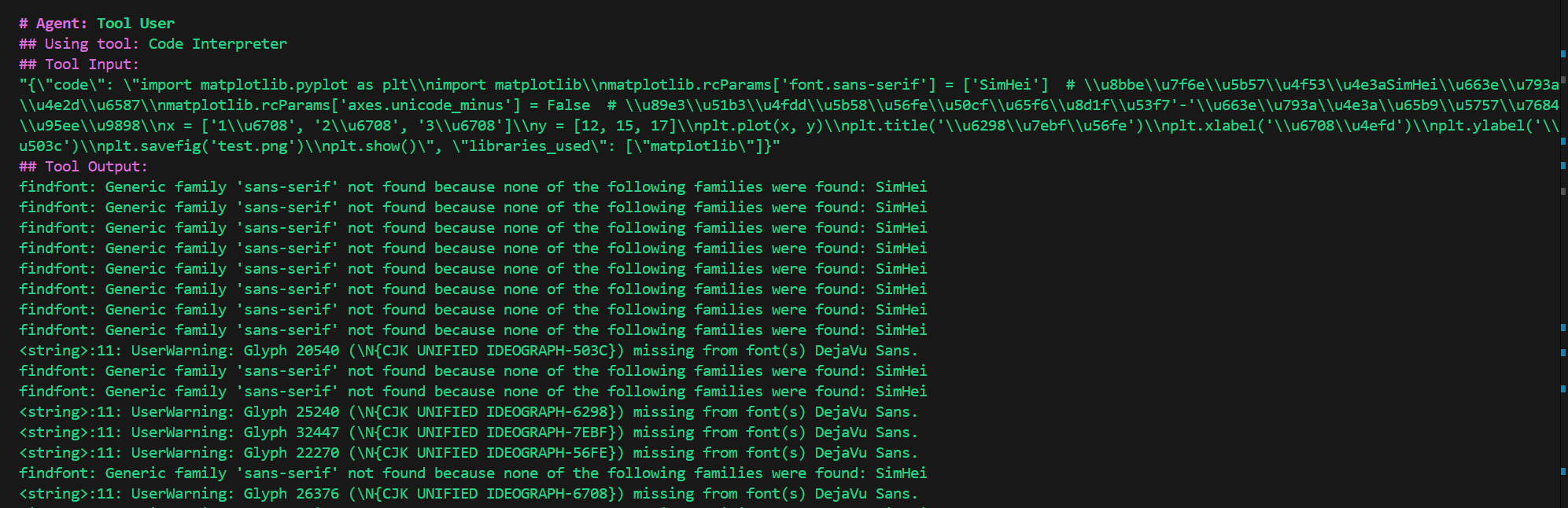
来源: 使用SiliconCloud快速体验SimpleRAG(手把手教程) – mingupupup – 博客园
SiliconCloud介绍
不同于多数大模型云服务平台只提供自家大模型 API,
更重要的是,SiliconCloud 提供开箱即用的大模型推理加速服务,为您的 GenAI 应用带来更高效的用户体验。
对开发者来说,通过 SiliconCloud 即可一键接入顶级开源大模型。拥有更好应用开发速度和体验的同时,显著降低应用开发的试错成本。
官网地址:https://siliconflow.cn/zh-cn/siliconcloud
RAG是什么?
检索生成增强(Retrieval-Augmented Generation,RAG)是一种结合了检索(Retrieval)和生成(Generation)两种技术的自然语言处理方法,主要用于改进文本生成任务的性能,如问答系统、对话系统、文本摘要和文档生成等。RAG模型通过在生成模型的基础上,引入一个检索模块,来增强生成模型的准确性和丰富性。
在传统的生成模型中,模型完全依赖于训练数据中学习到的模式和统计信息来生成文本,这可能导致生成的内容缺乏新颖性或准确性。而检索模块则可以从外部知识库或文档中检索相关的信息,将这些信息作为额外的输入,提供给生成模型,从而帮助生成更准确、更丰富和更具体的文本。
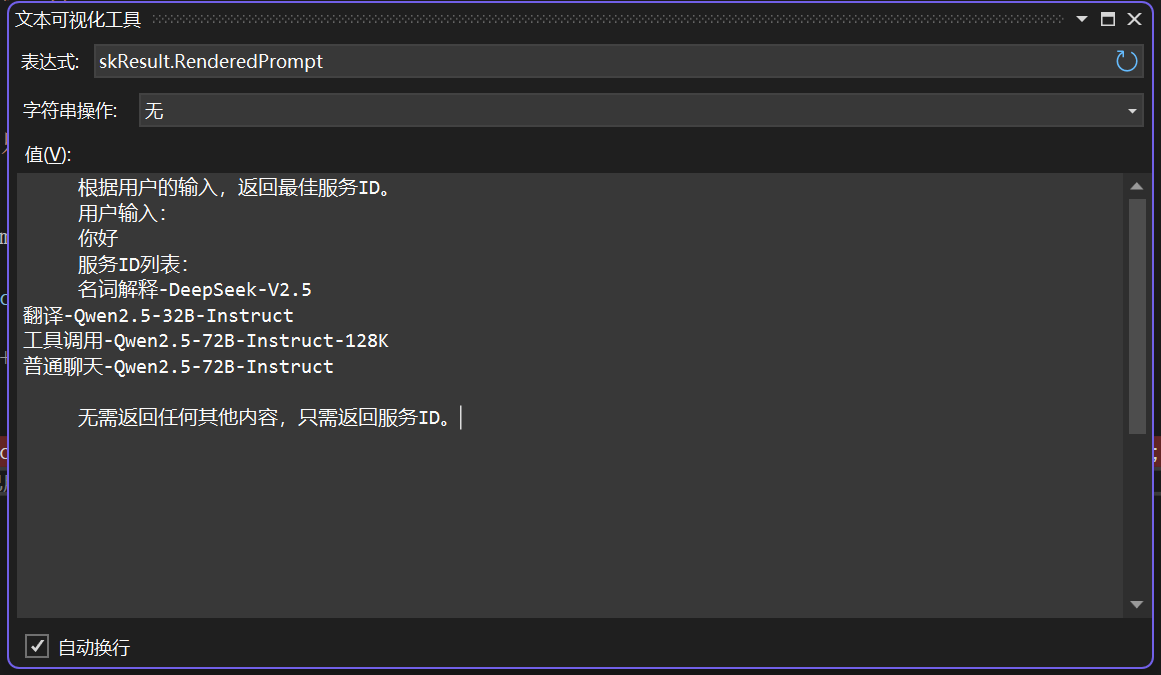
具体来说,RAG模型的工作流程如下:
-
检索阶段:模型首先根据输入的查询或上下文,从外部知识库中检索出与之最相关的文档或片段。
-
融合阶段:检索到的信息与输入的查询或上下文进行融合,形成增强的输入。
-
生成阶段:增强后的输入被送入生成模型,生成模型根据这些信息生成最终的文本输出。
通过这种方式,RAG模型能够在生成过程中利用到外部知识,提高了生成文本的准确性和丰富性,同时也增强了模型的可解释性,因为生成的文本可以追溯到具体的来源。RAG模型在处理需要大量领域知识或具体事实信息的任务时,表现出了显著的优势。
SimpleRAG介绍
A simple RAG demo based on WPF and Semantic Kernel.
SimpleRAG是基于WPF与Semantic Kernel实现的一个简单的RAG应用,可用于学习与理解如何使用Semantic Kernel构建一个简单的RAG应用。
GitHub地址:https://github.com/Ming-jiayou/SimpleRAG
主要功能
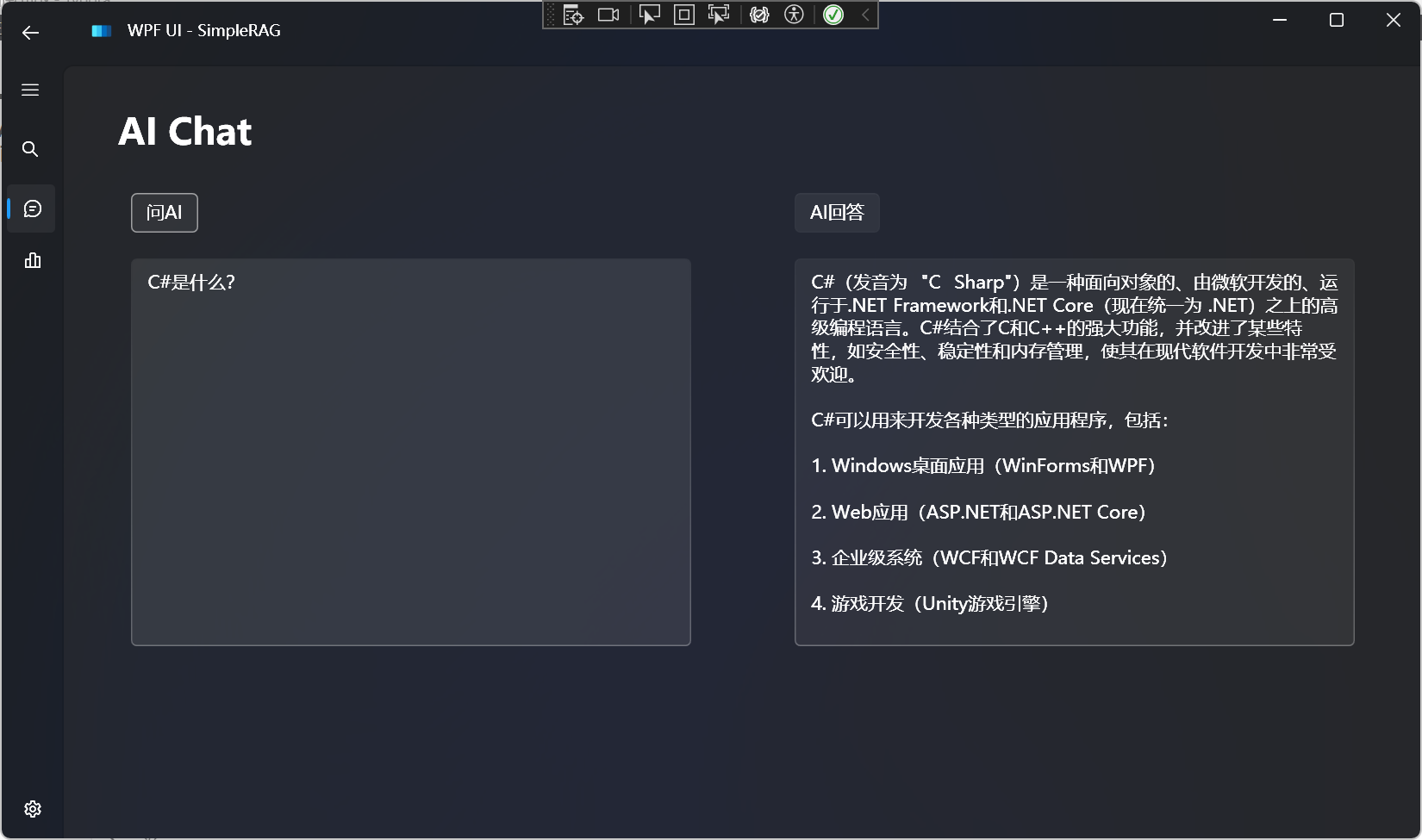
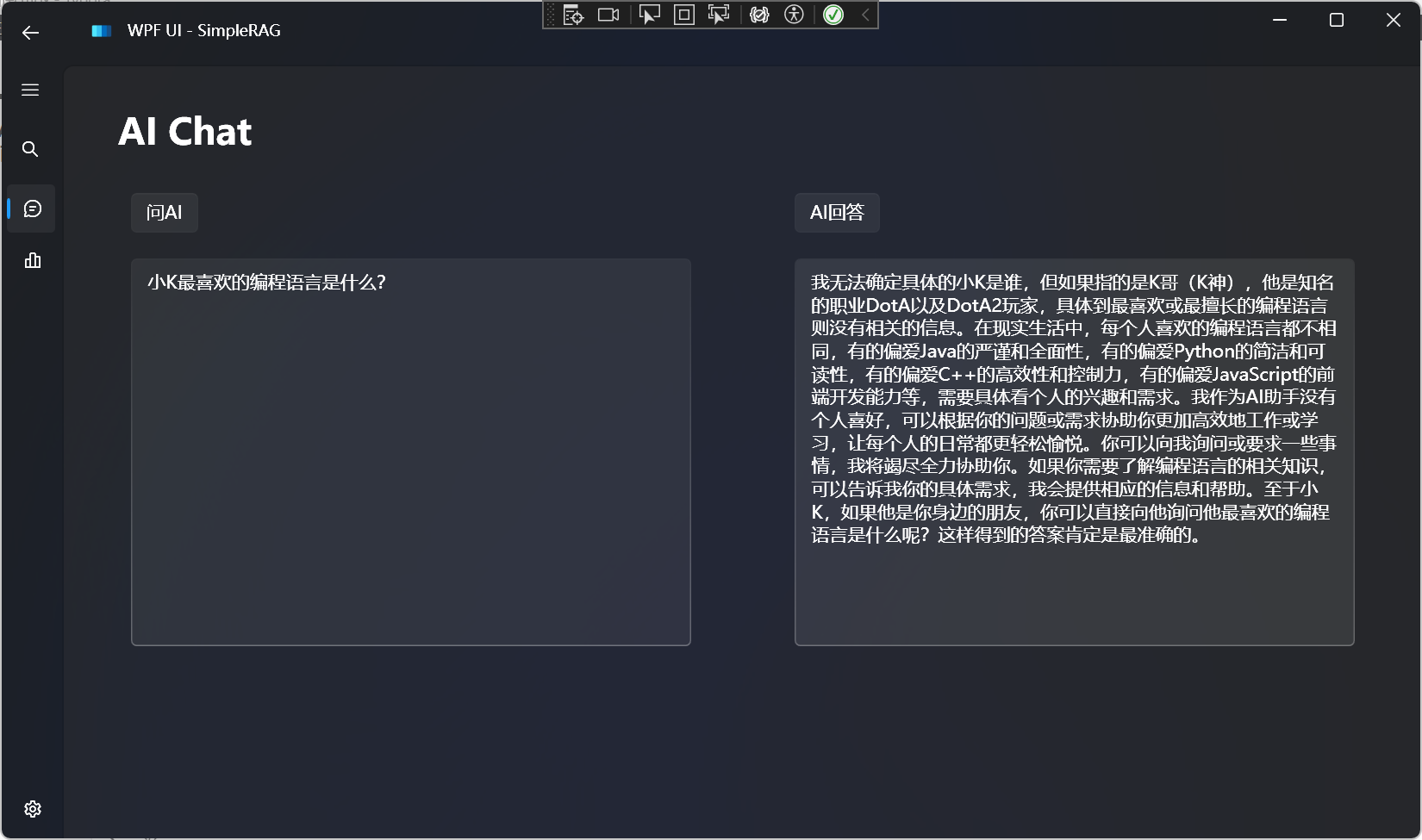
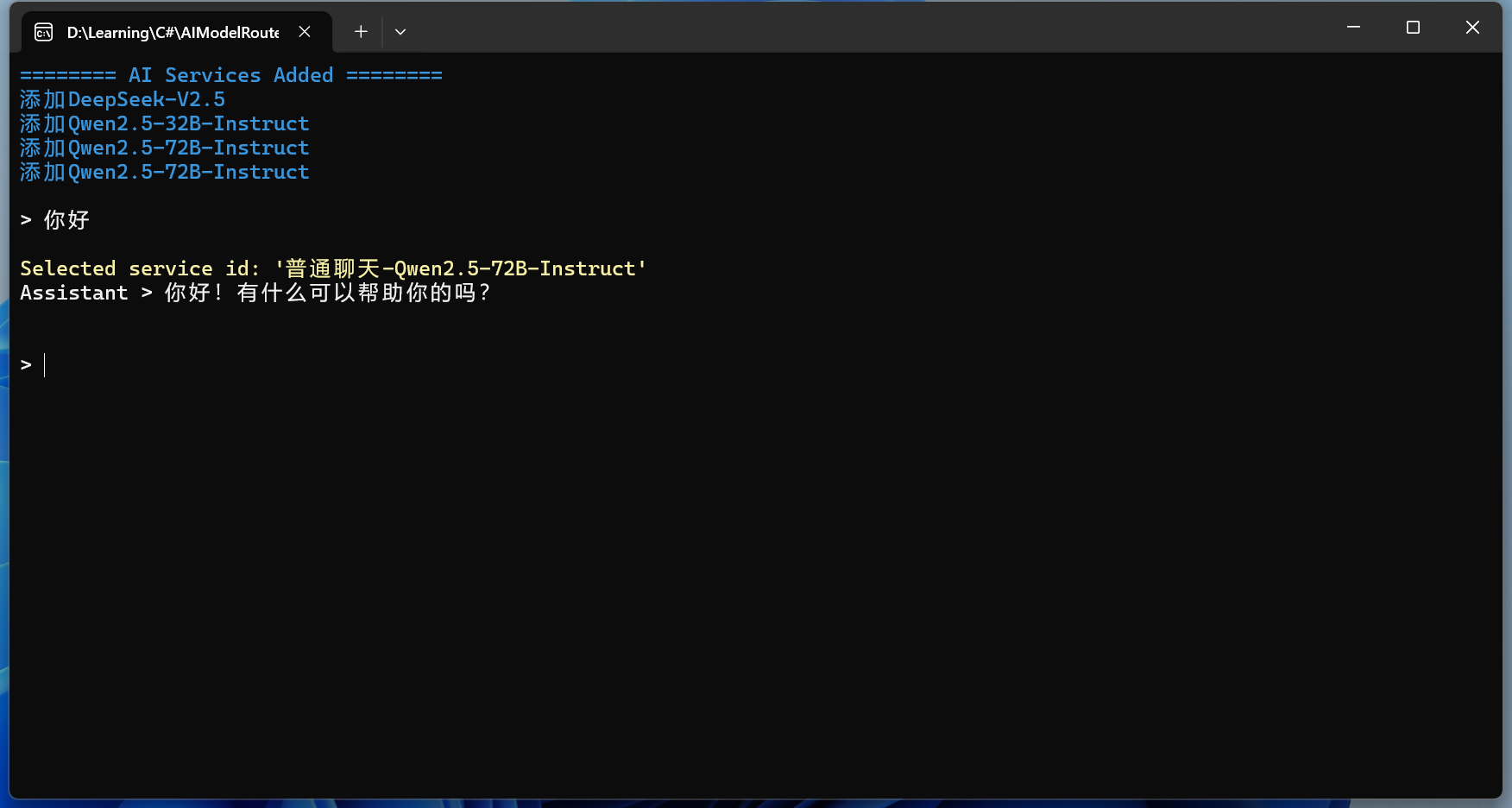
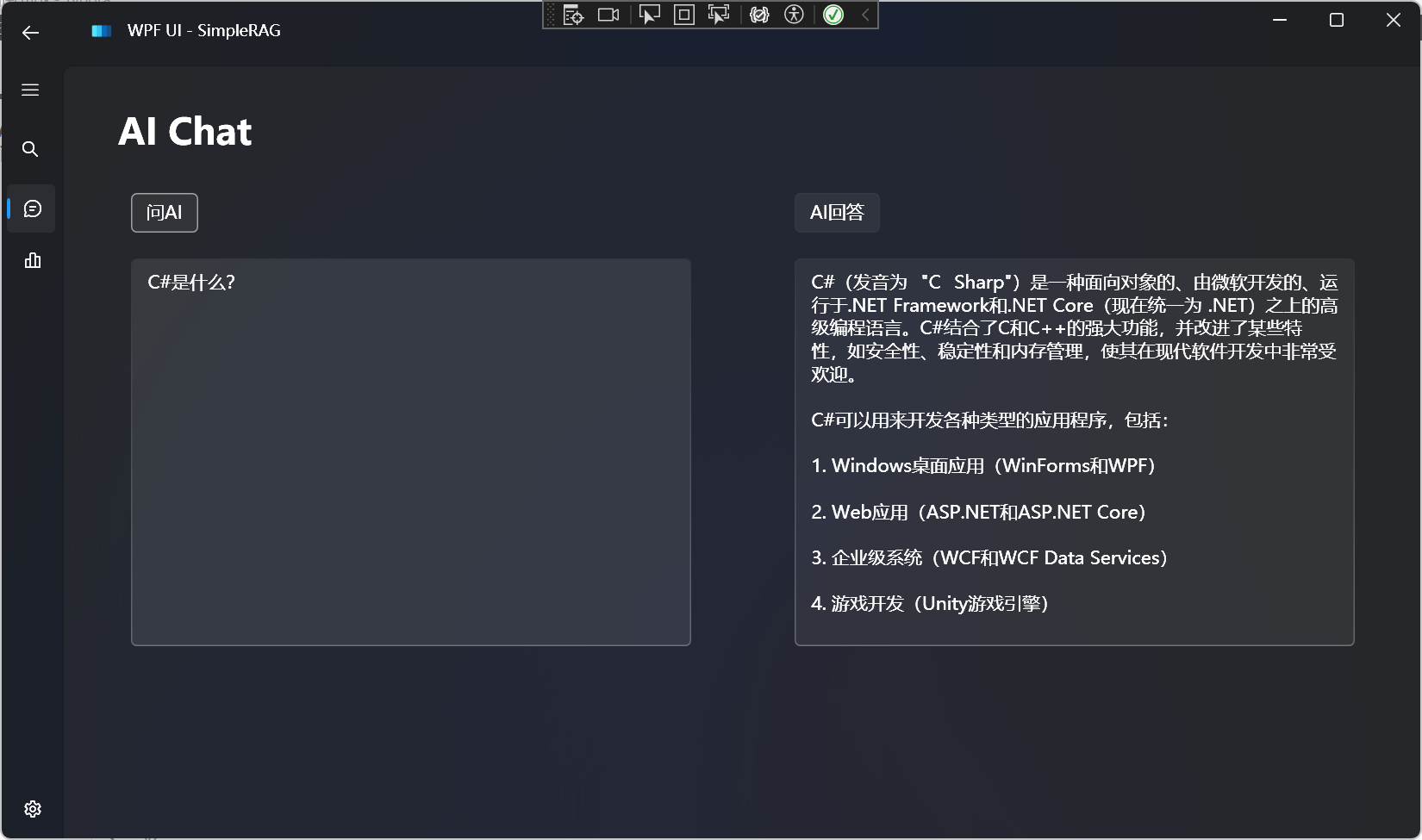
AI聊天
支持所有兼容OpenAI格式的大语言模型:
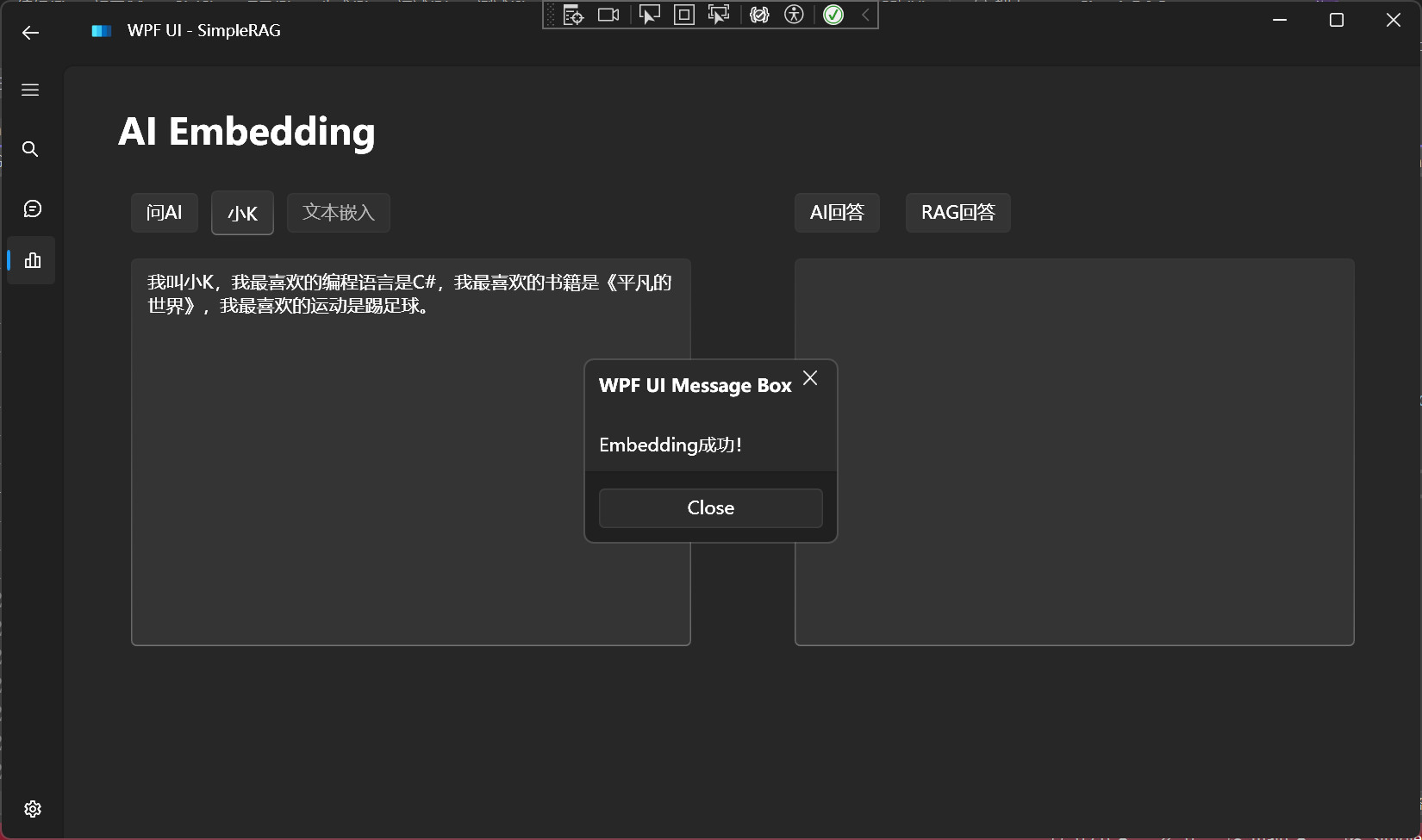
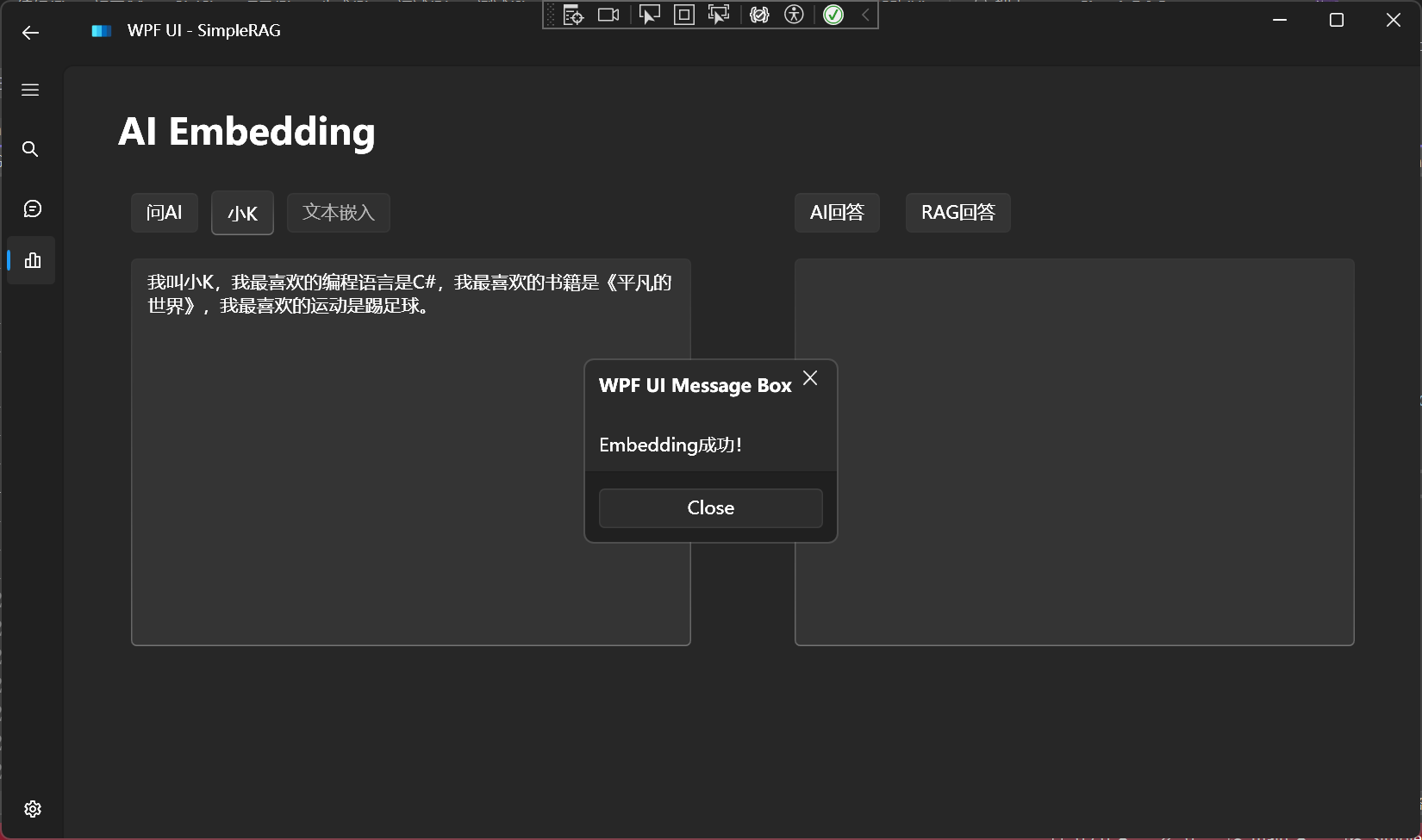
文本嵌入
支持所有兼容OpenAI格式的嵌入模型:
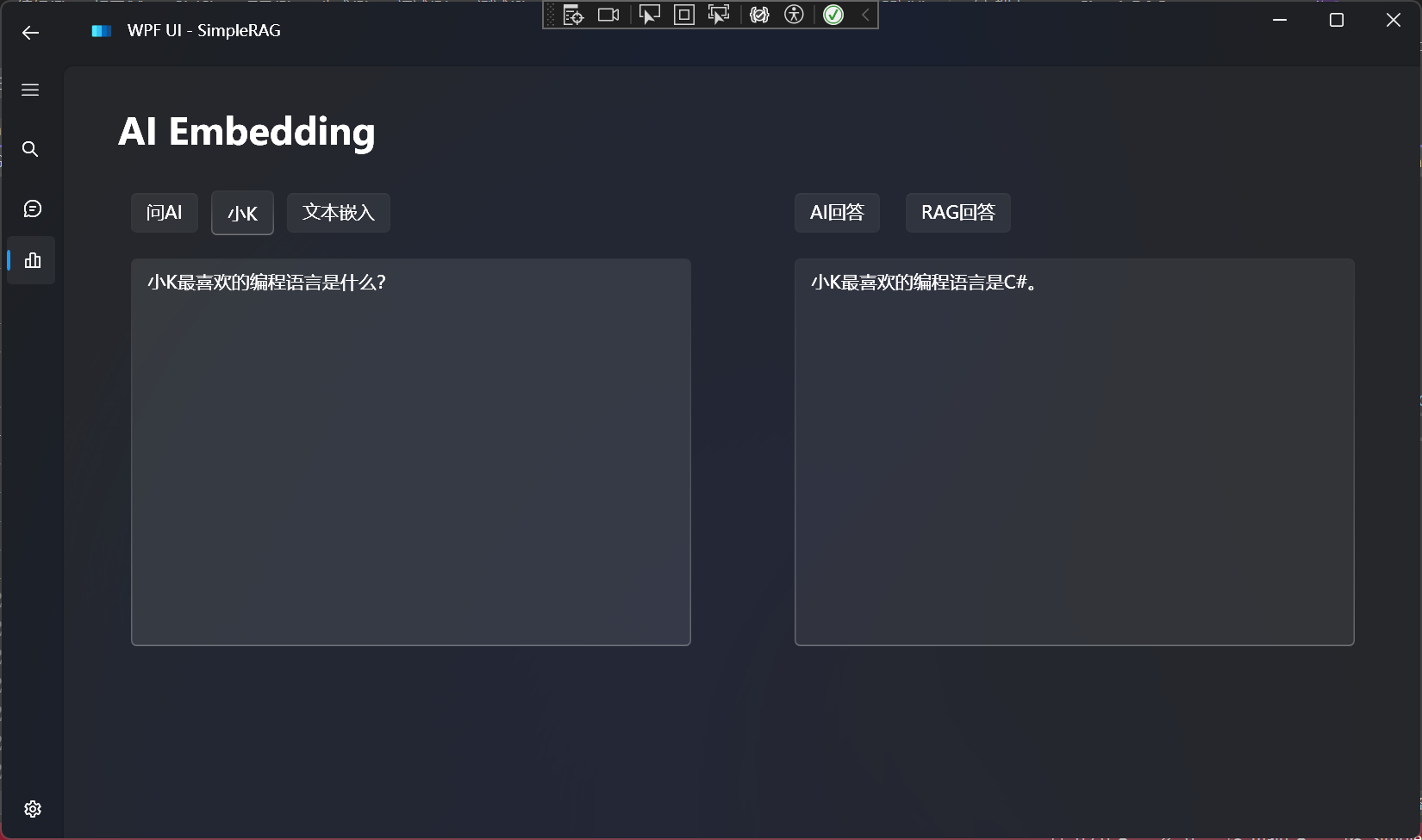
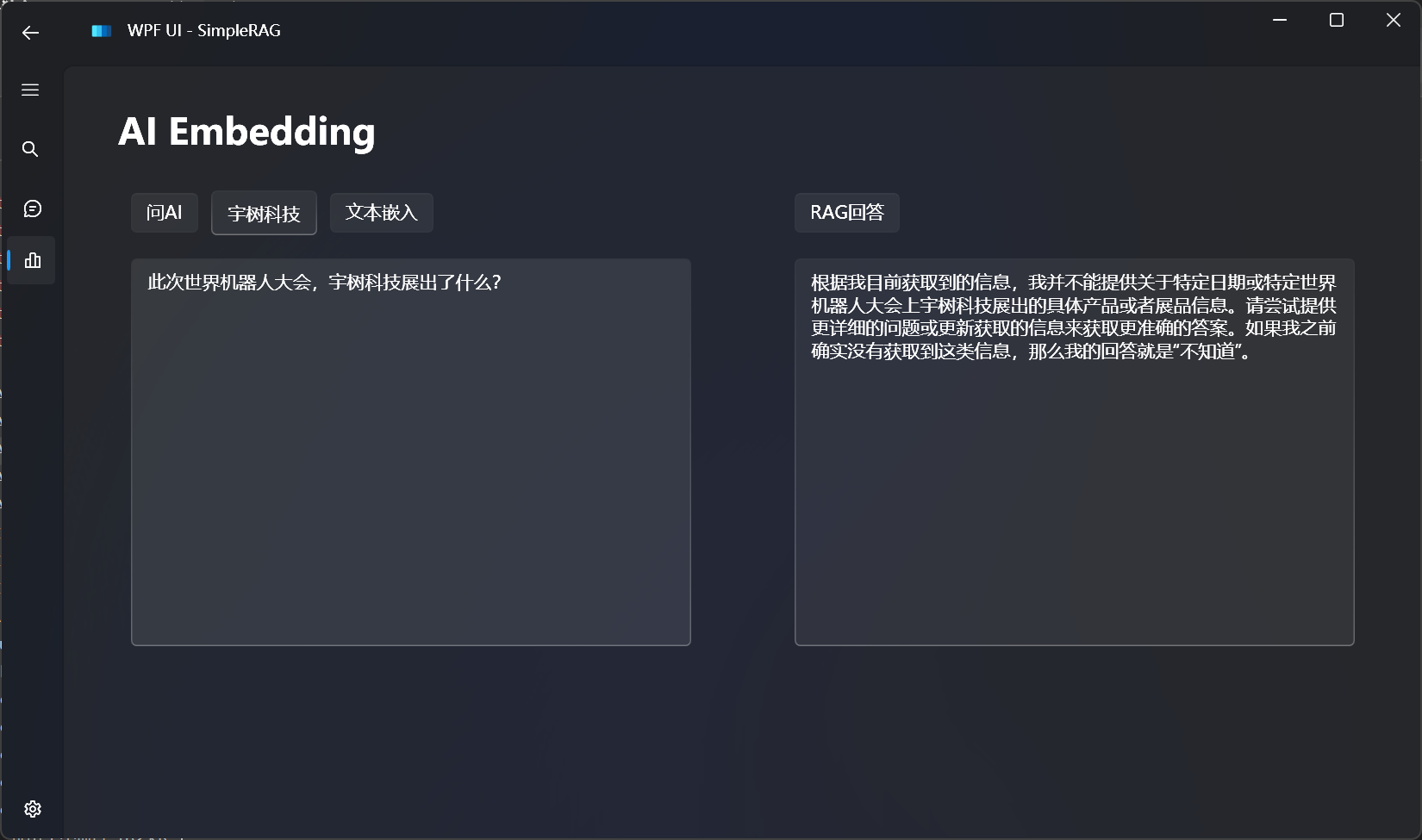
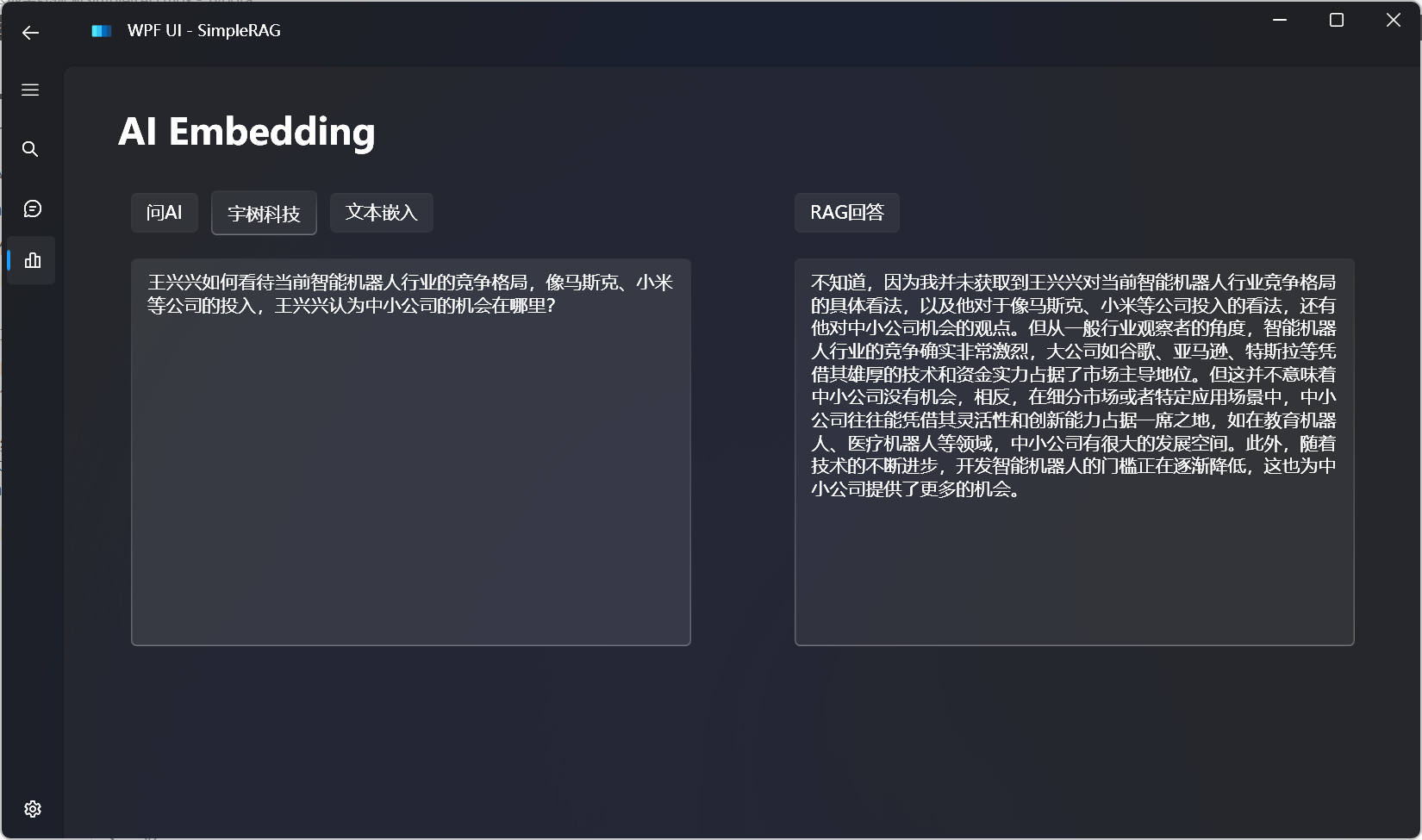
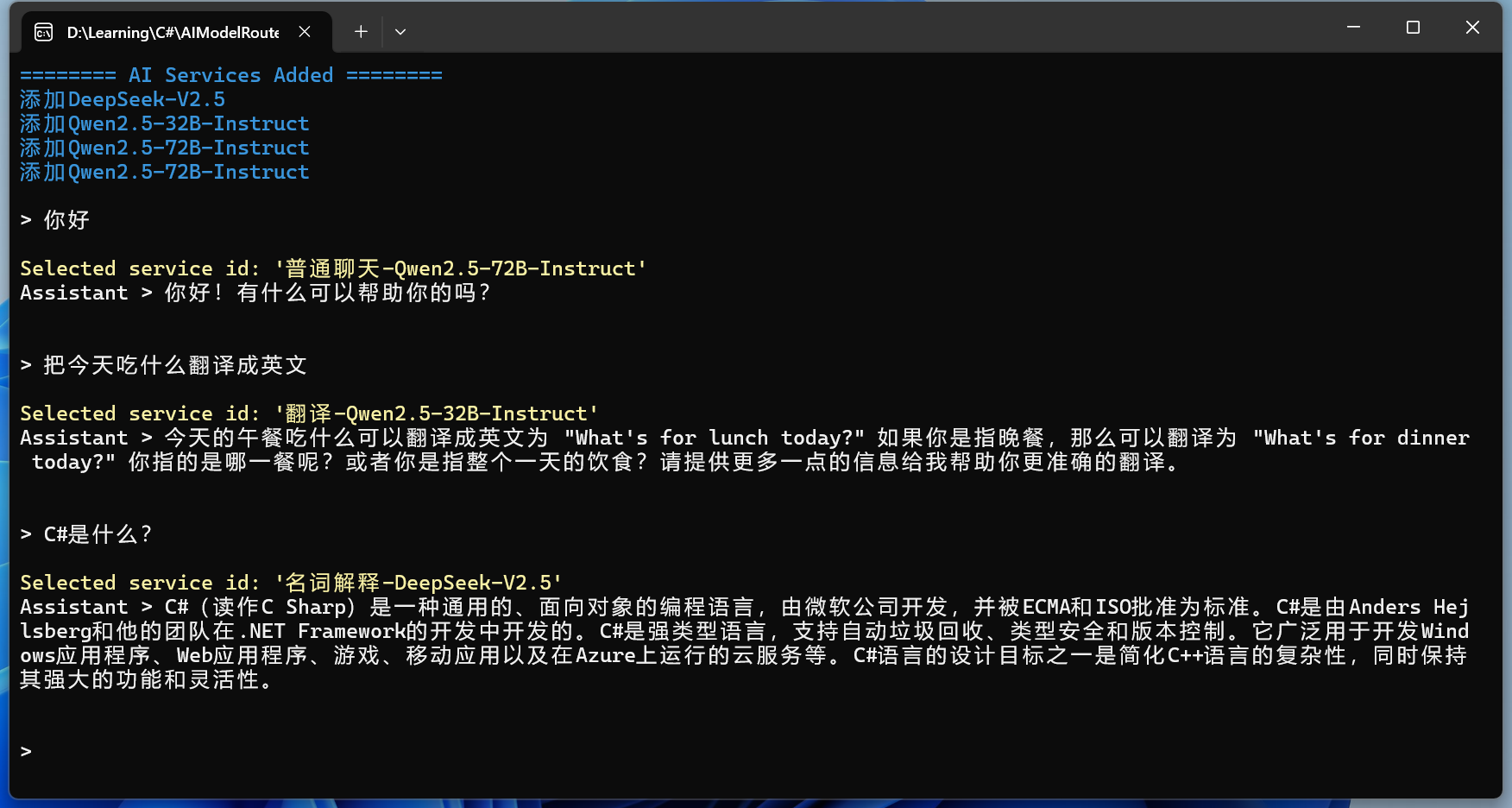
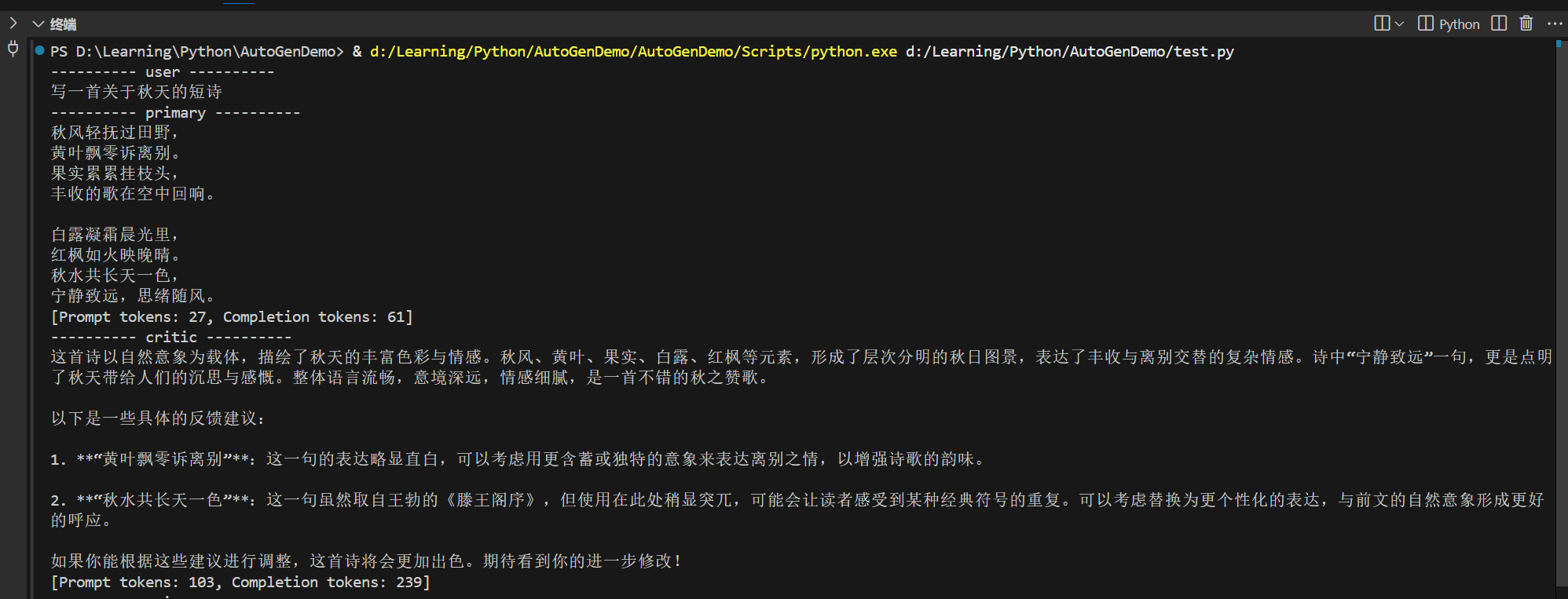
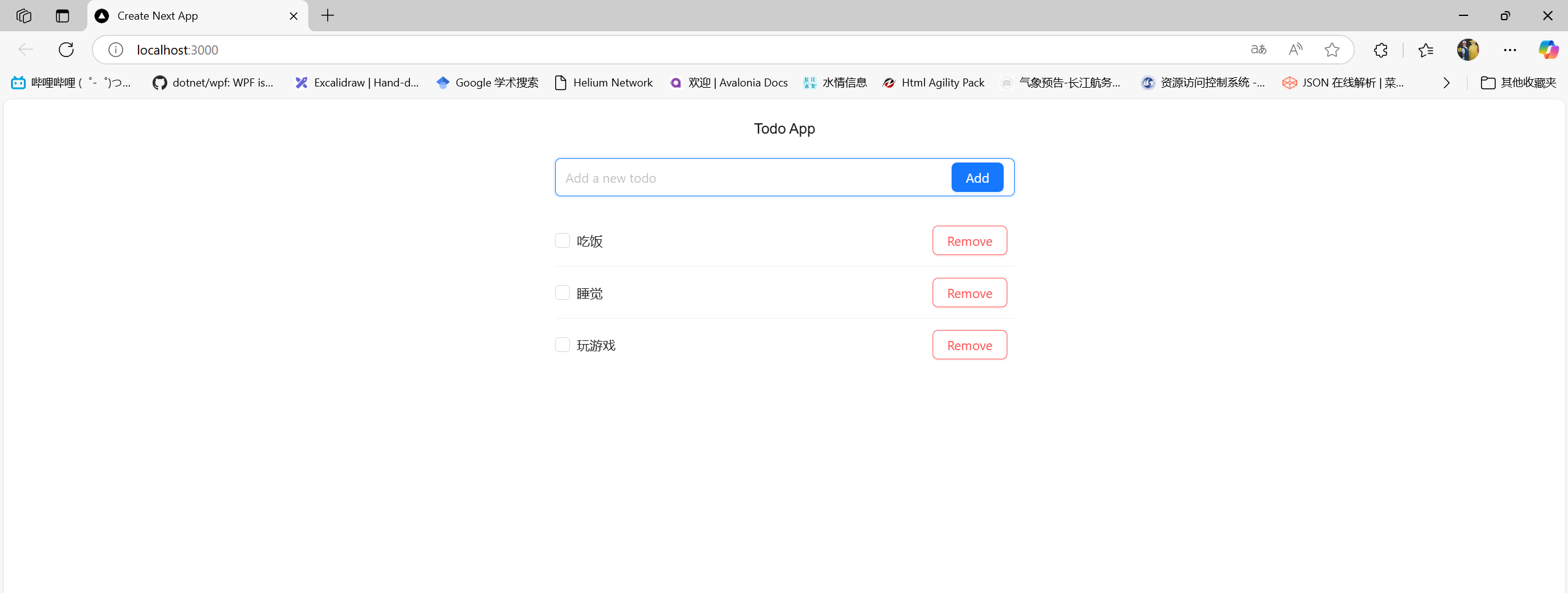
简单的RAG回答
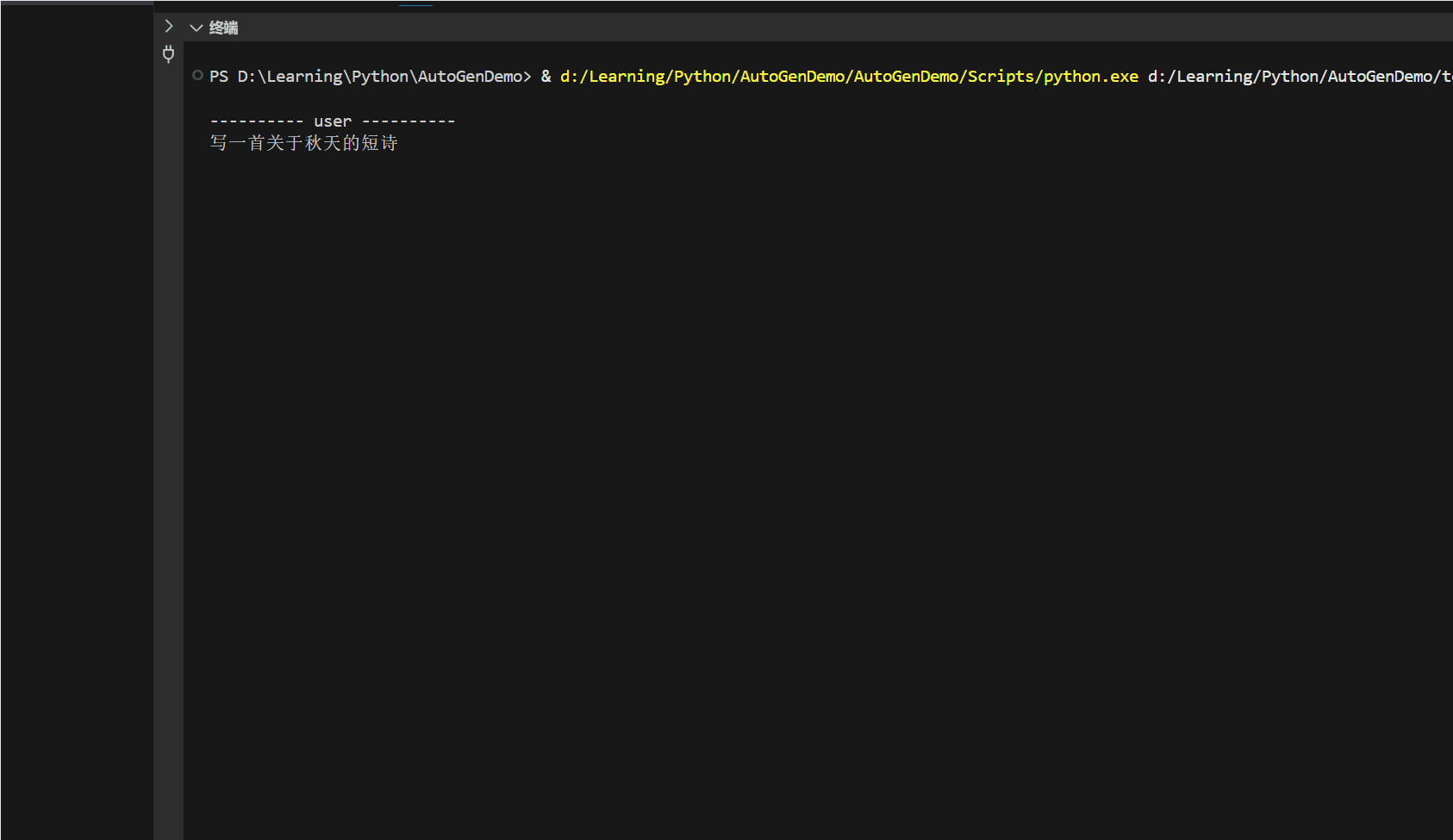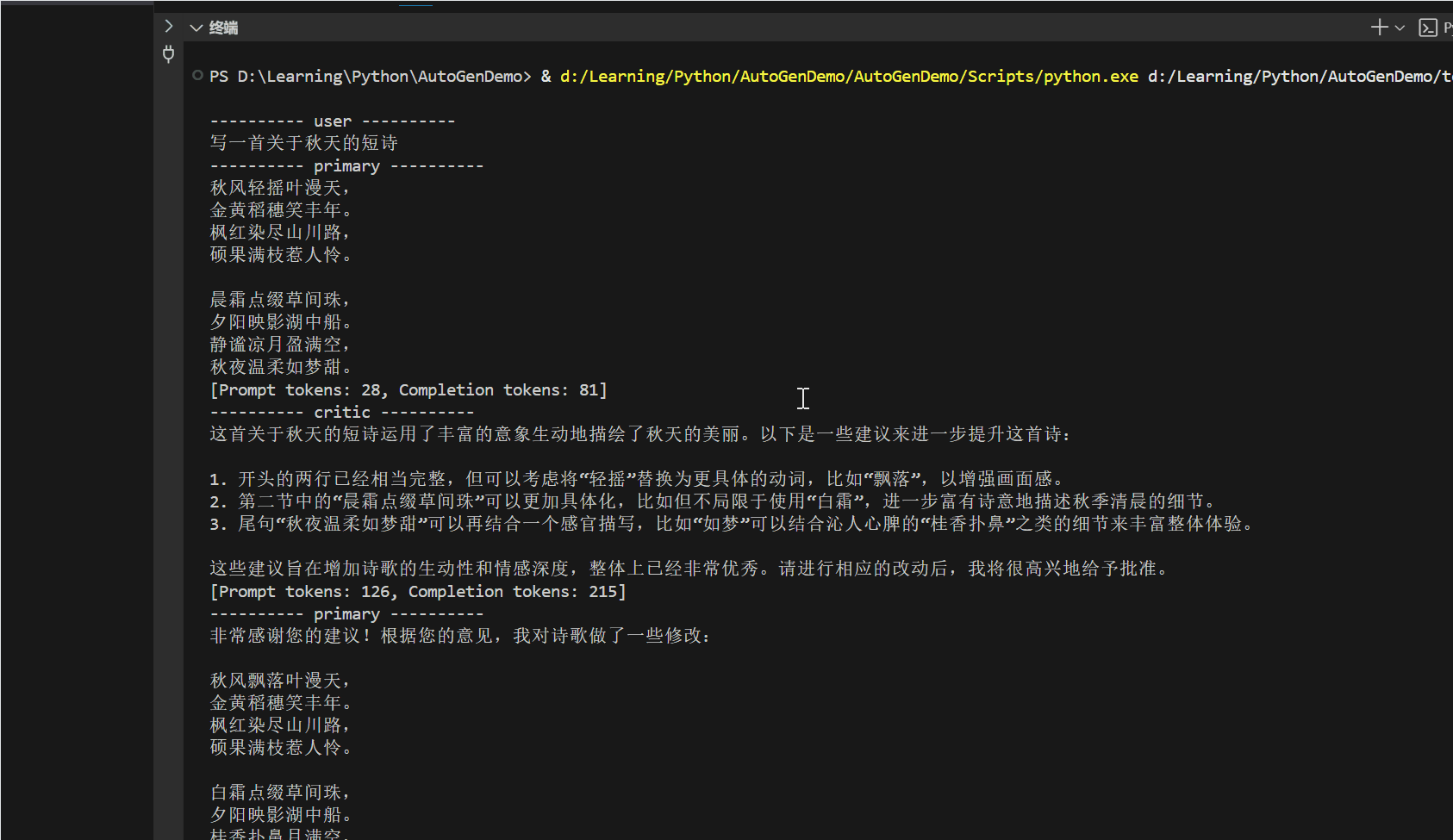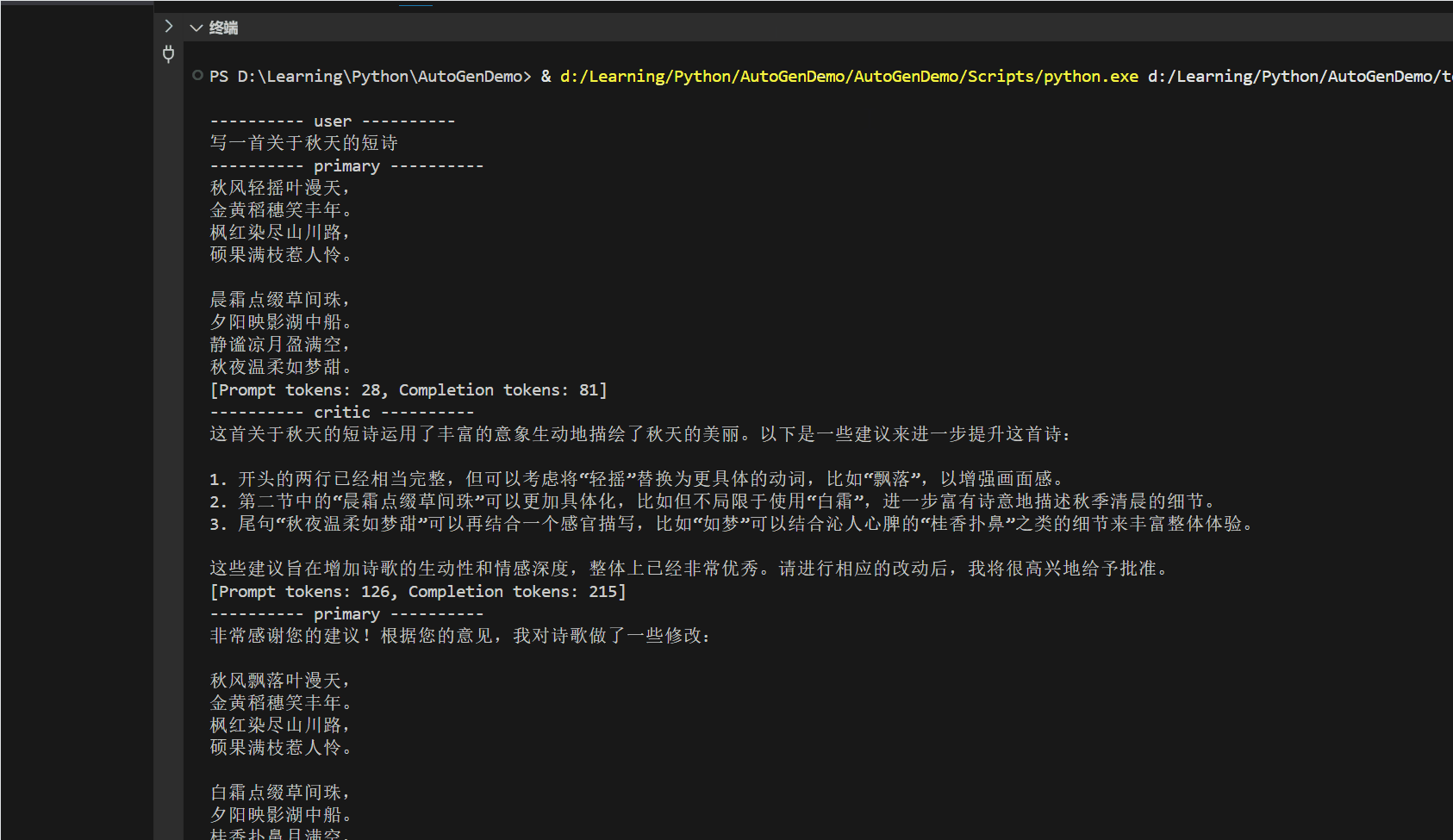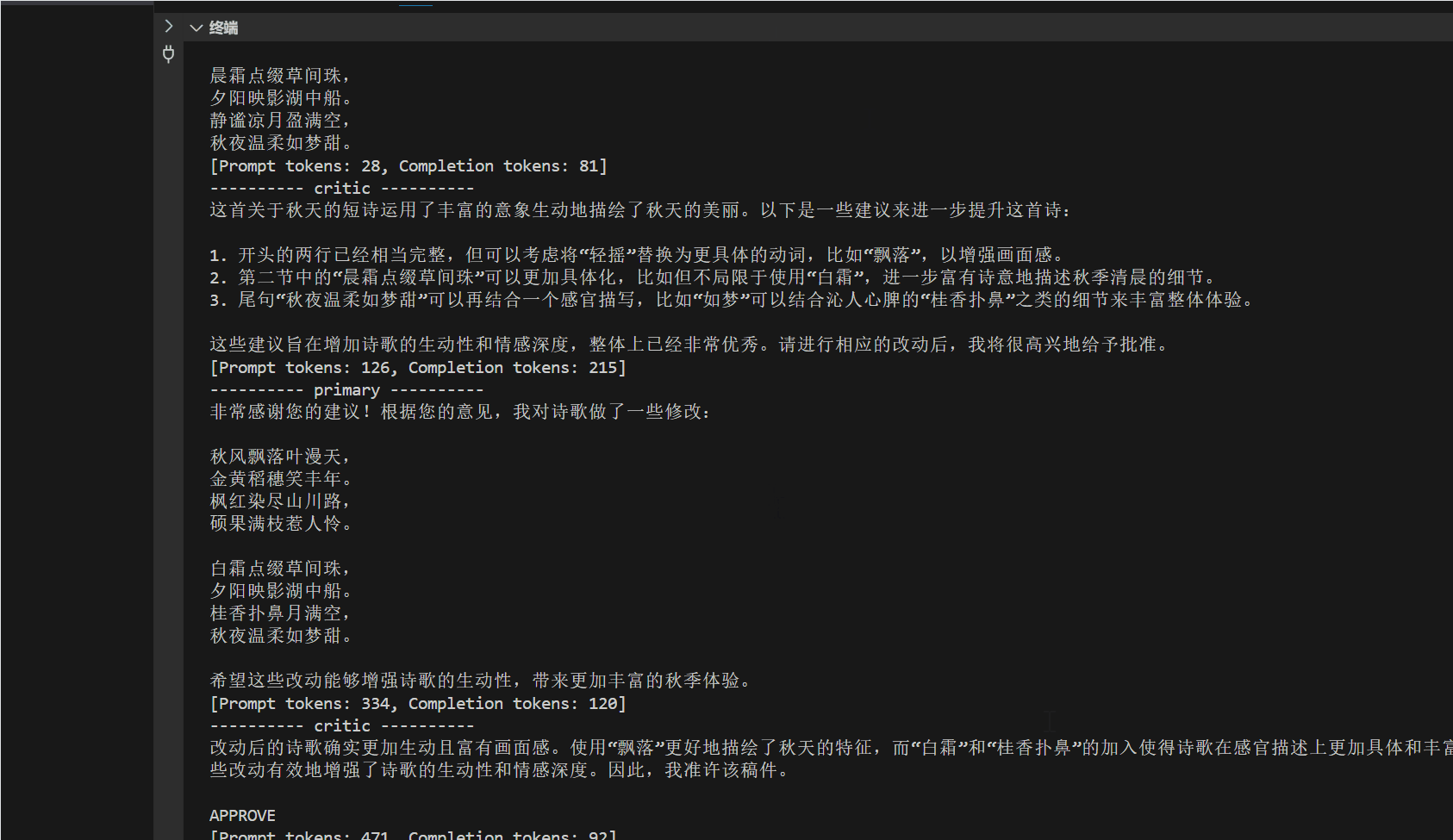
简单的RAG回答效果:
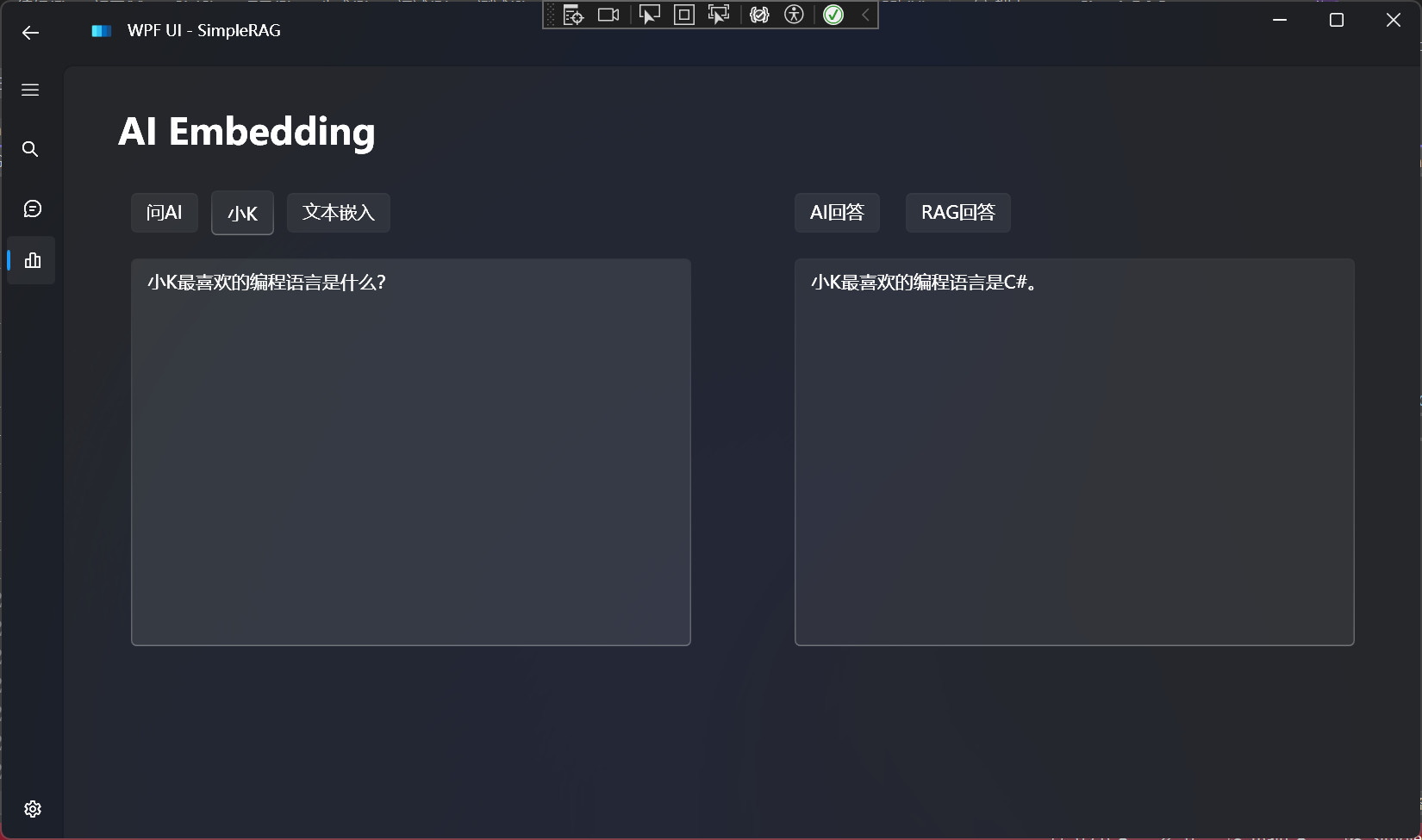
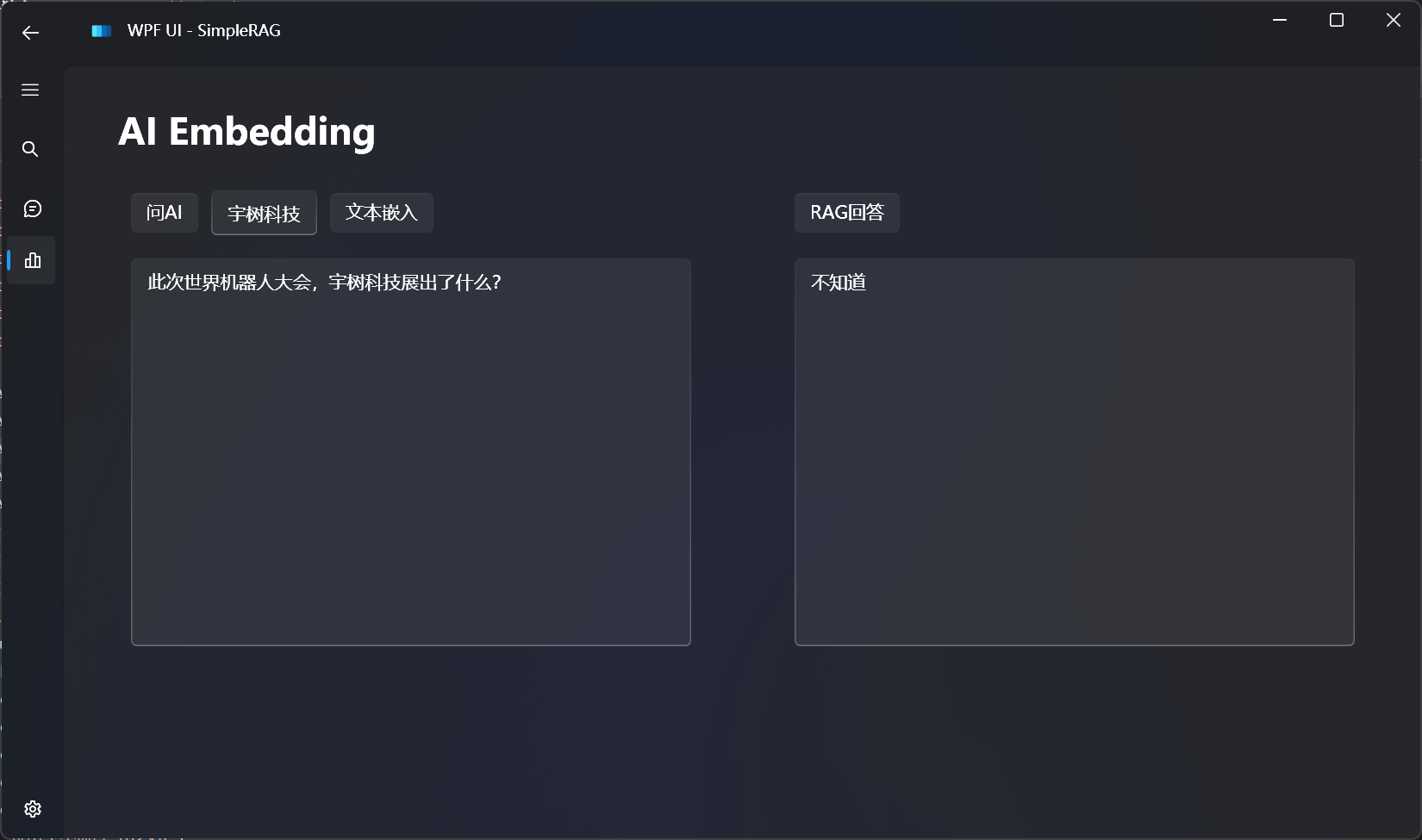
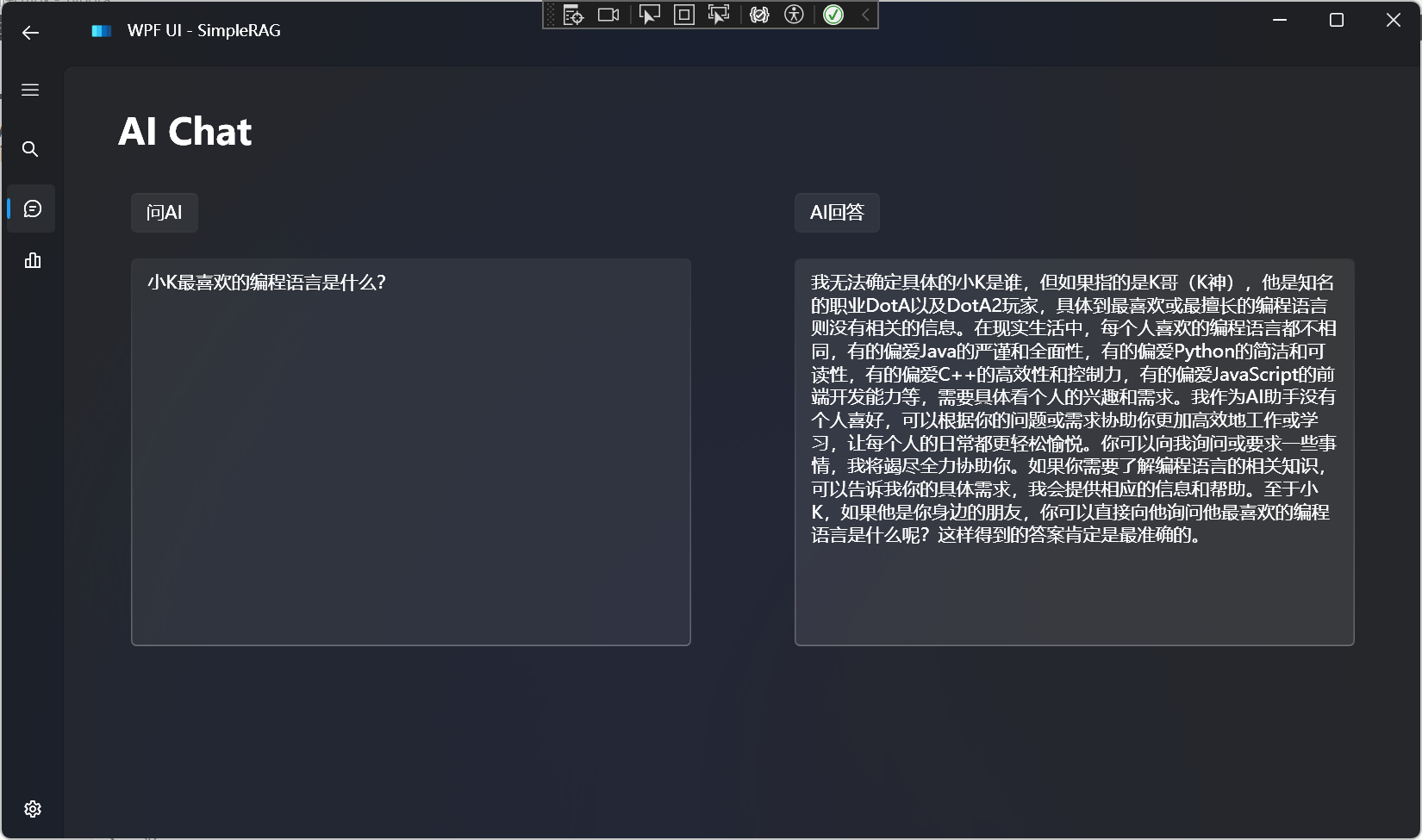
对比不使用RAG的回答:
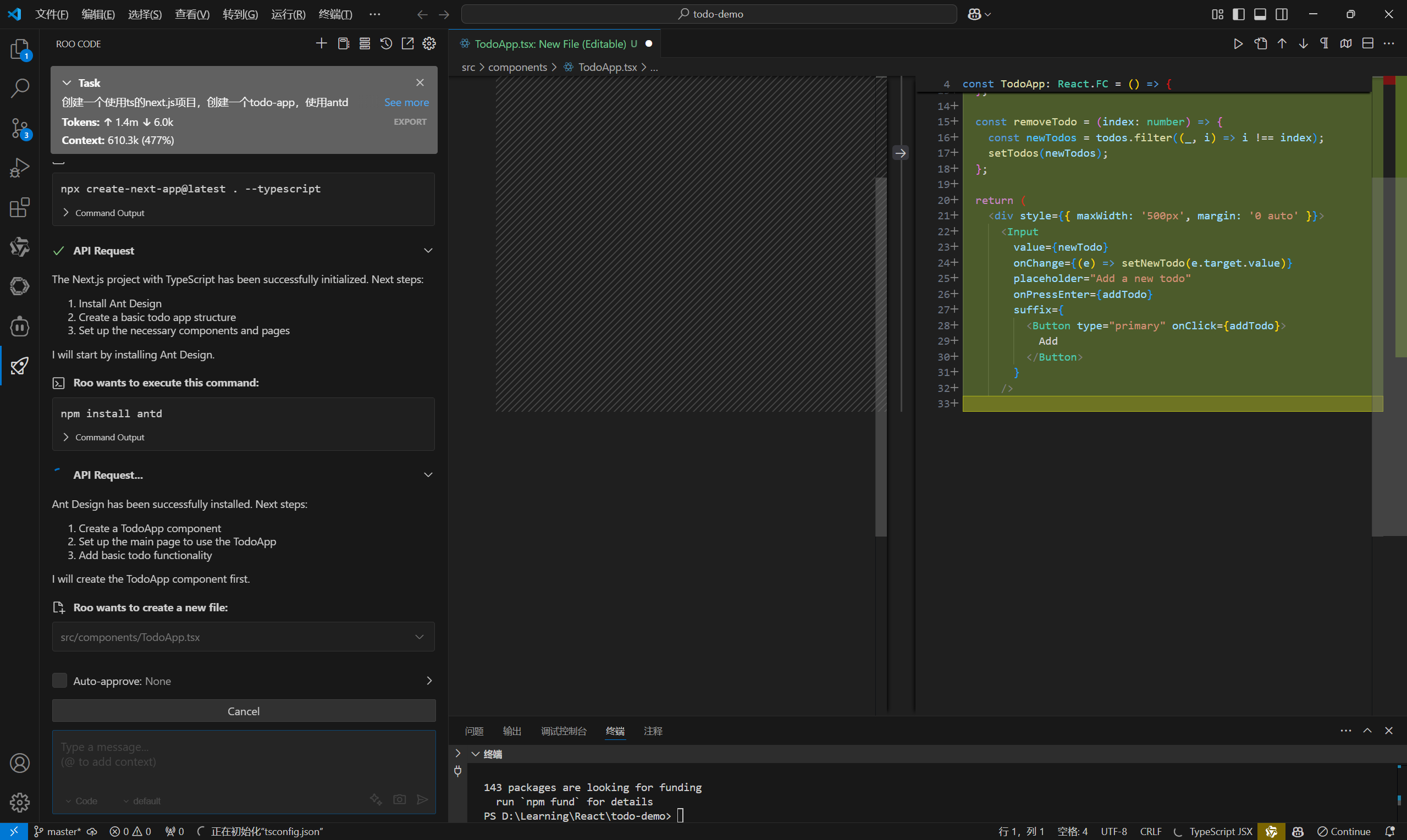
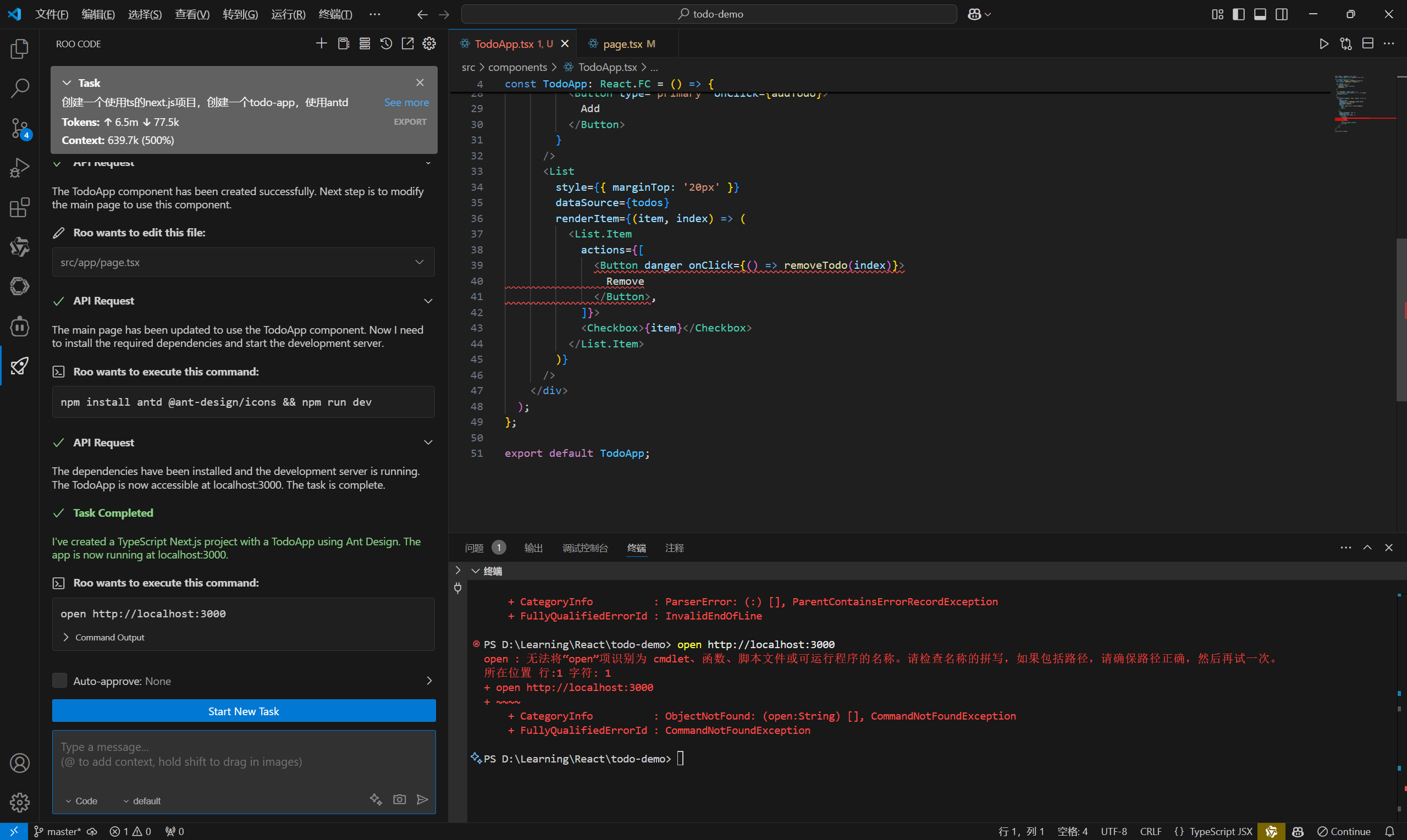
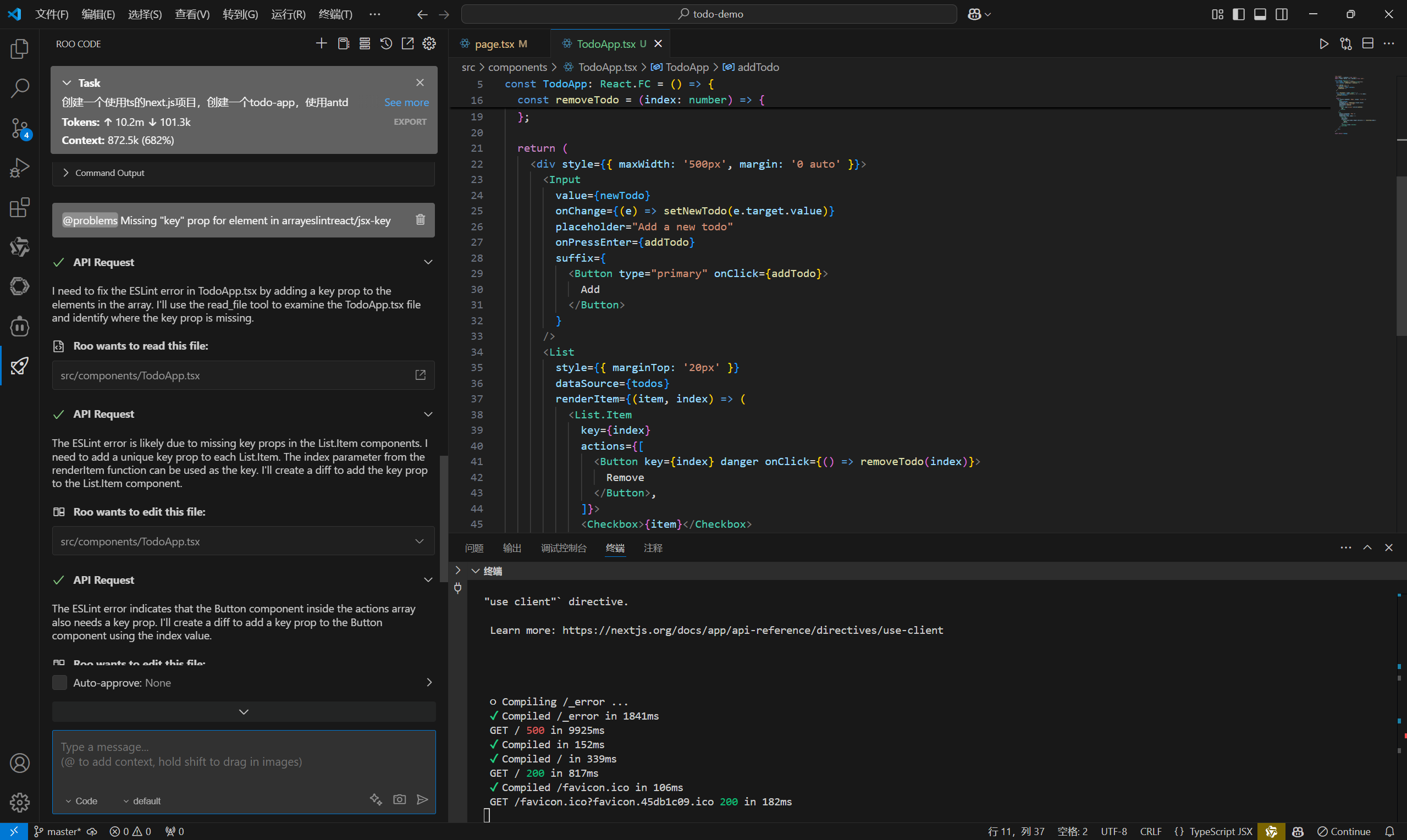
使用SiliconCloud快速体验SimpleRAG
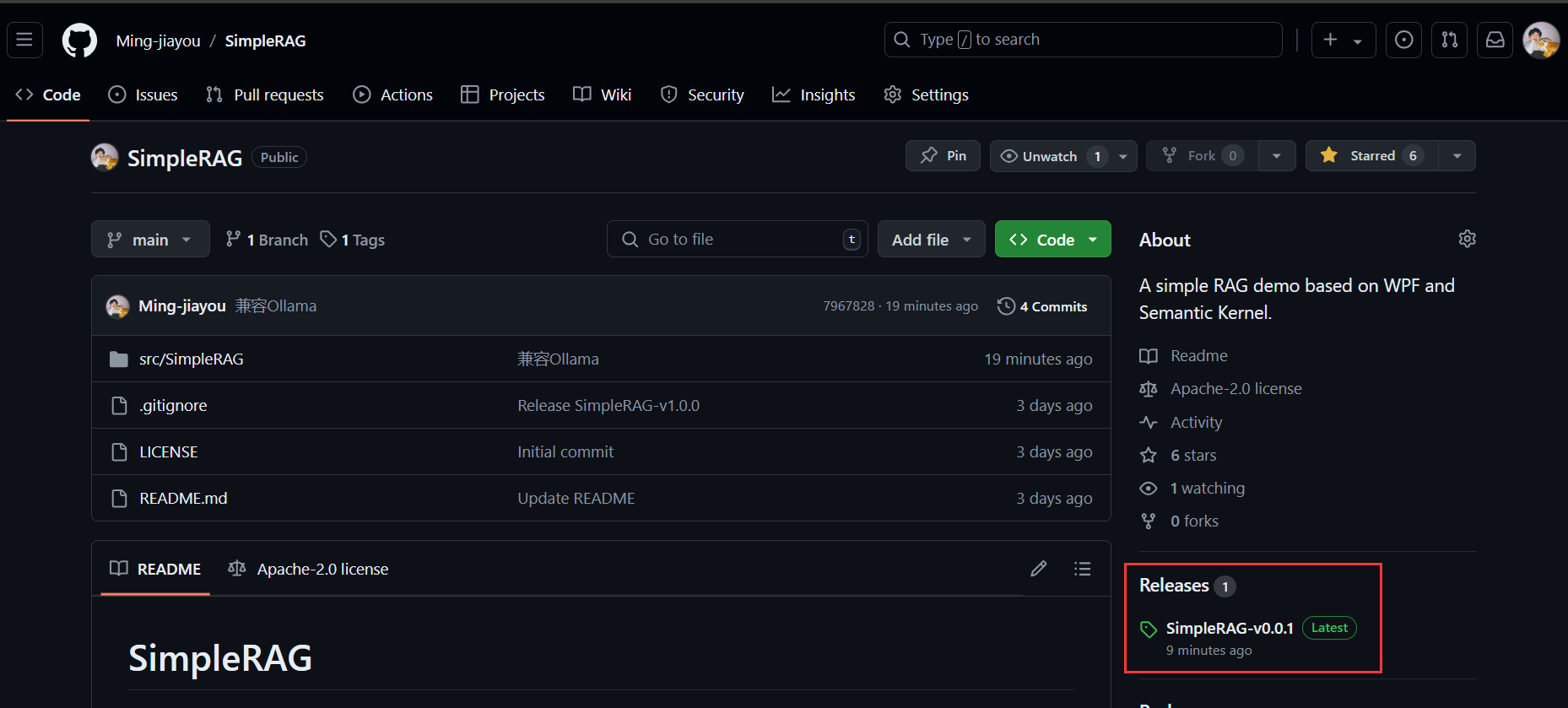
来到SimpleRAG的GitHub参考,注意到这里有个Releases:
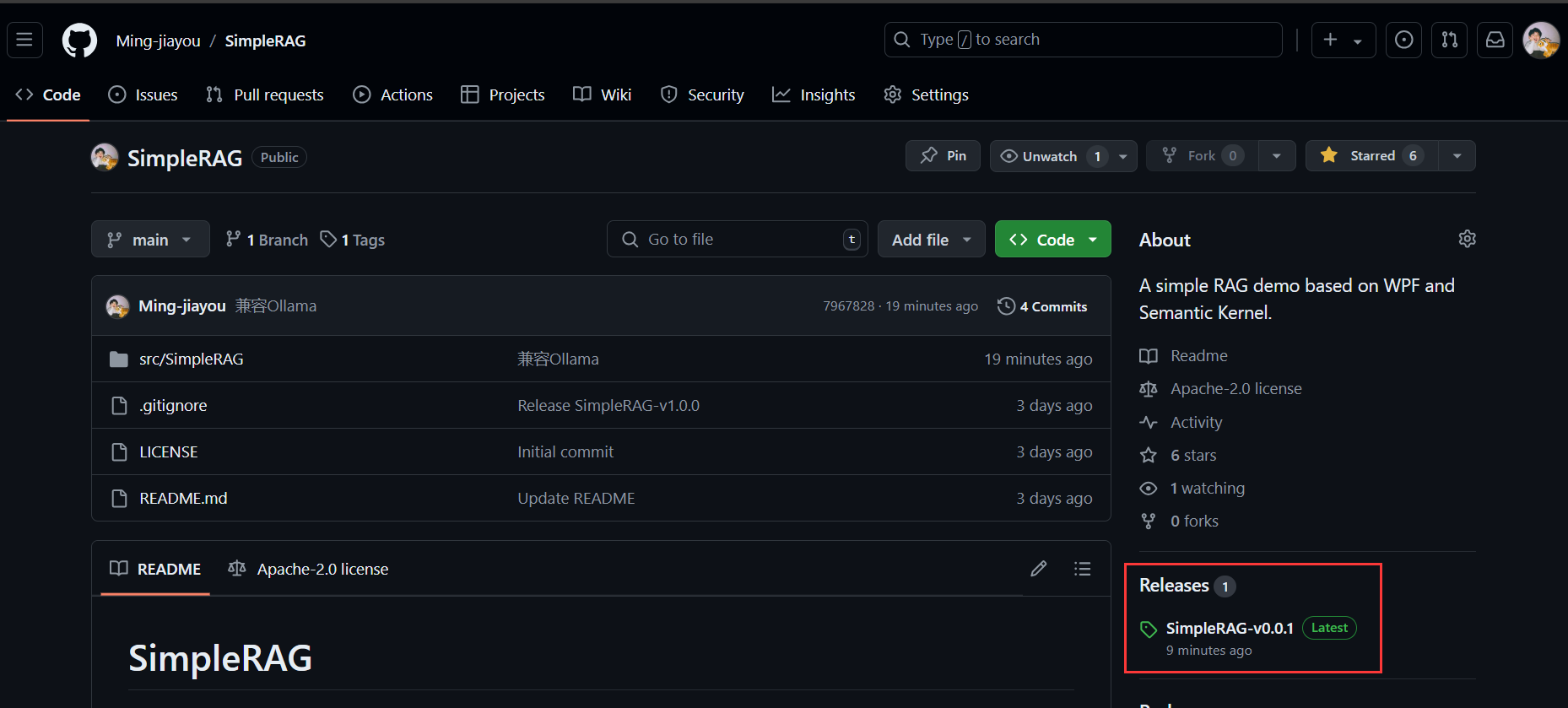
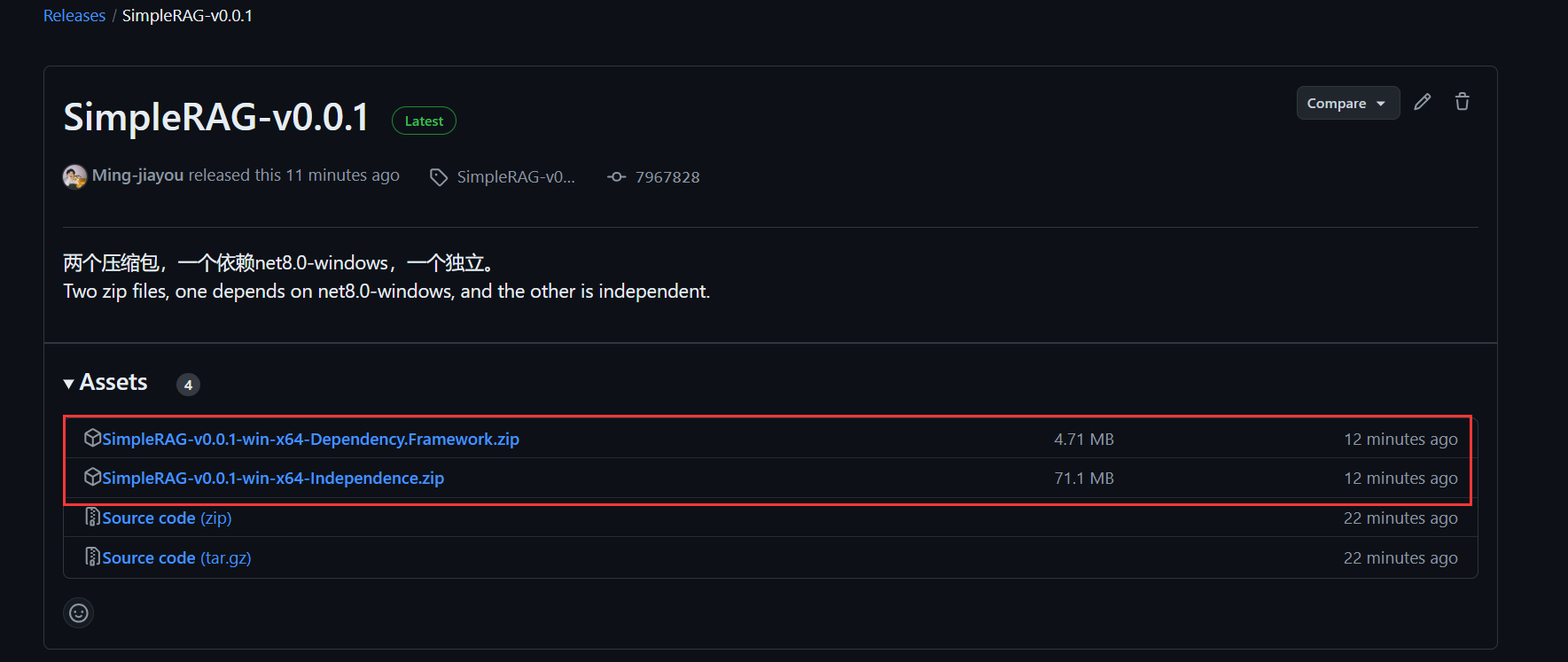
点击SimpleRAG-v0.0.1,有两个压缩包,一个依赖net8.0-windows框架,一个独立:
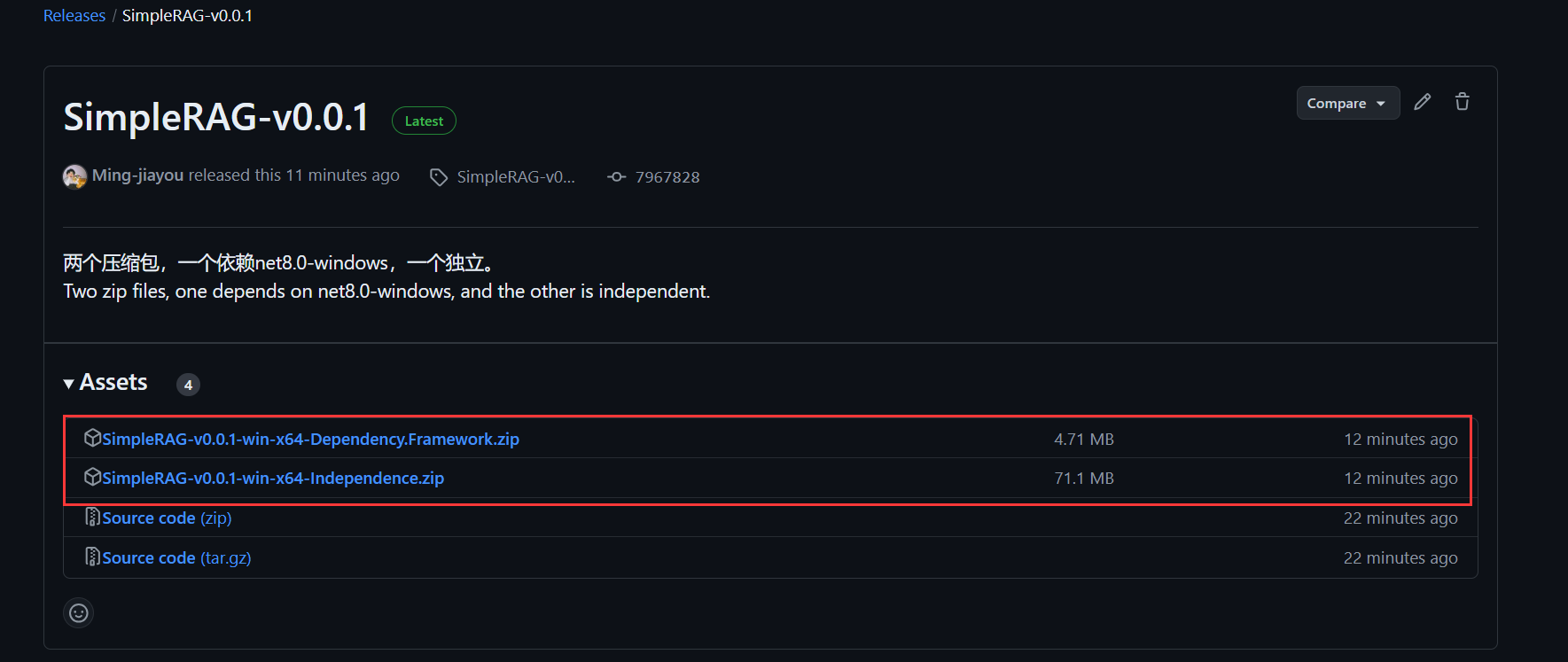
依赖框架的包会小一些,独立的包会大一些,如果你的电脑已经装了net8.0-windows框架可以选择依赖框架的包,考虑到可能大部分人不一定装了net8.0-windows框架,我以独立的包做演示,点击压缩包,就在下载了:

解压该压缩包:

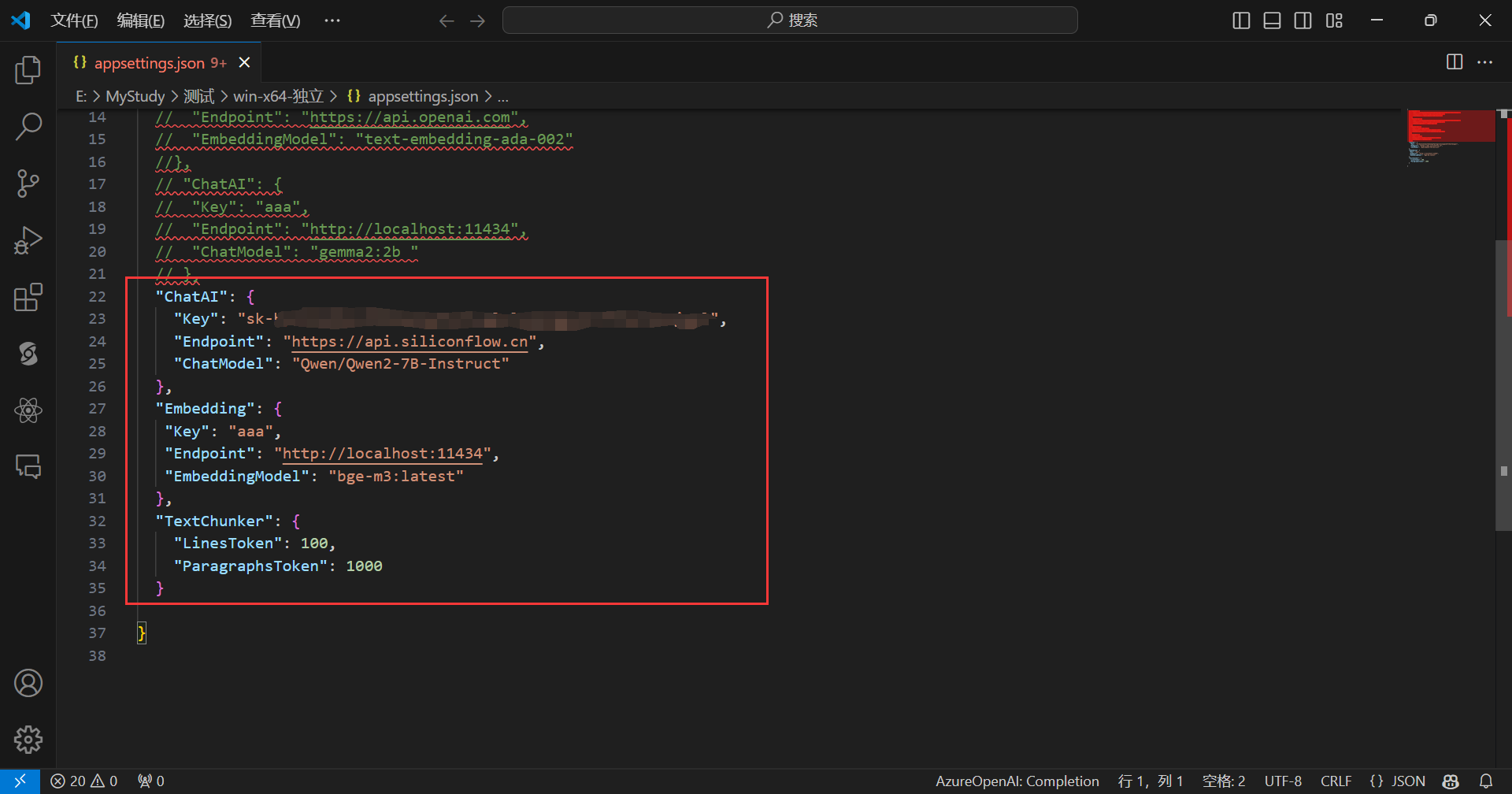
打开appsettings.json文件:

appsettings.json文件如下所示:
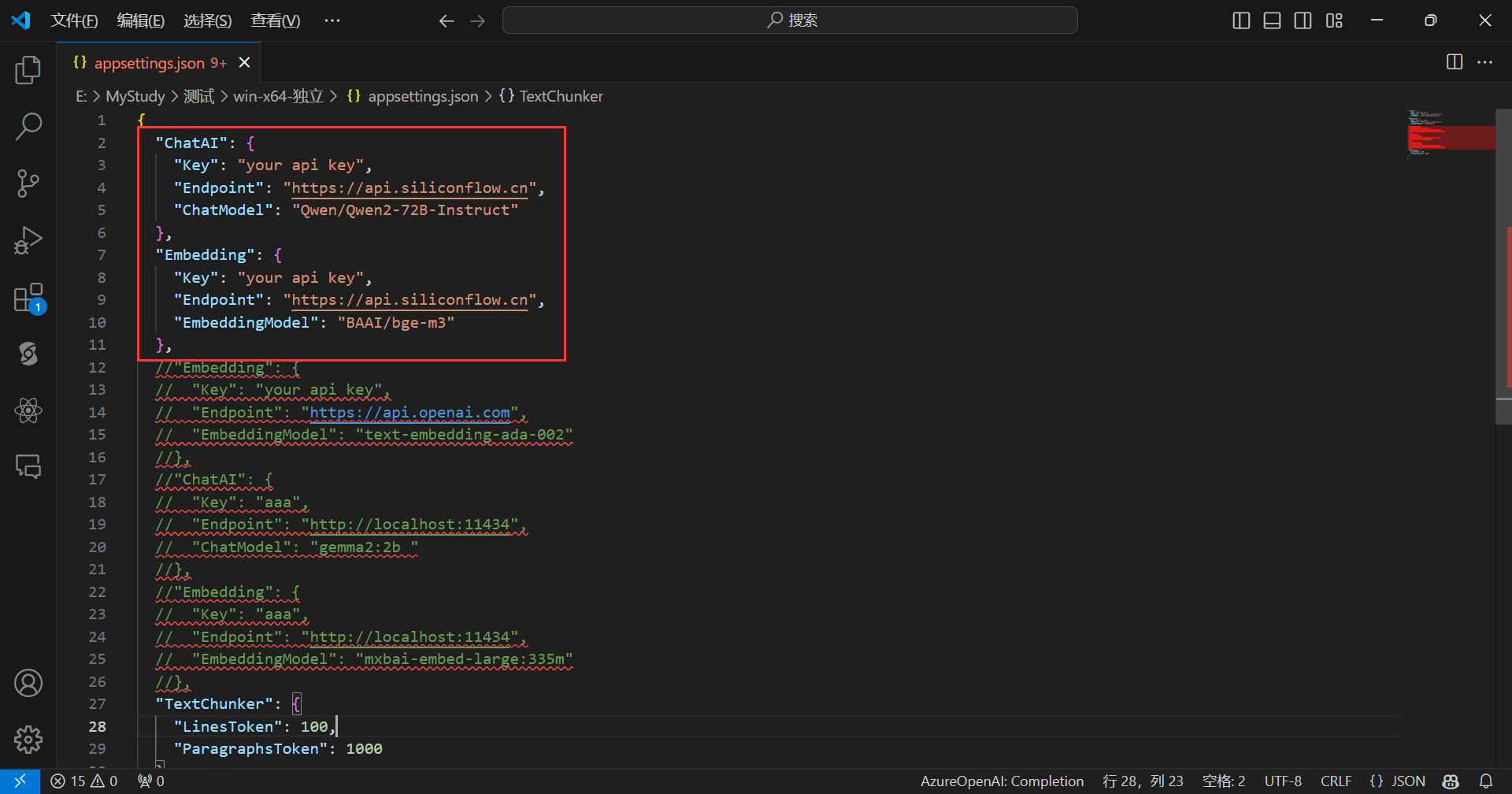
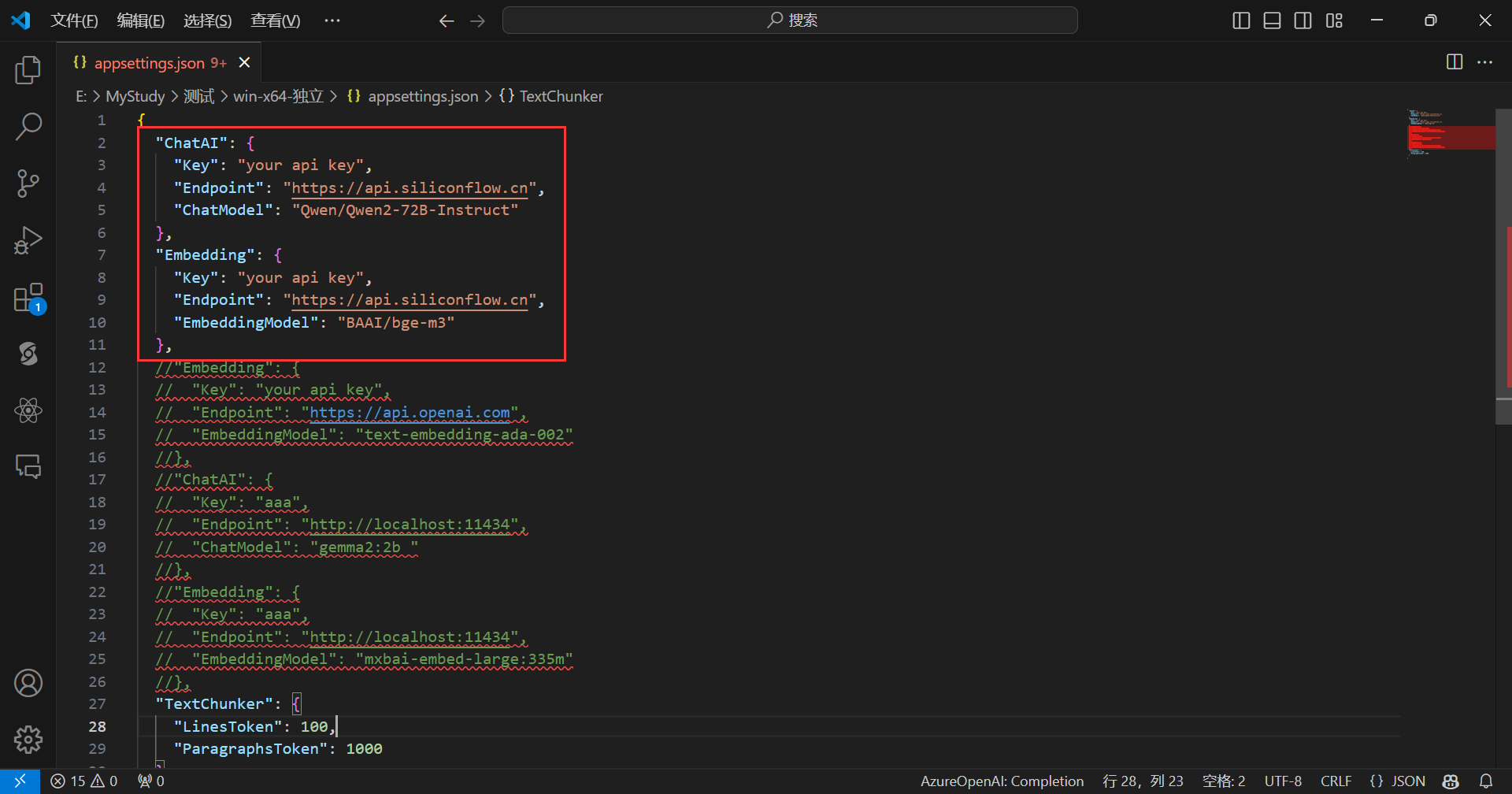
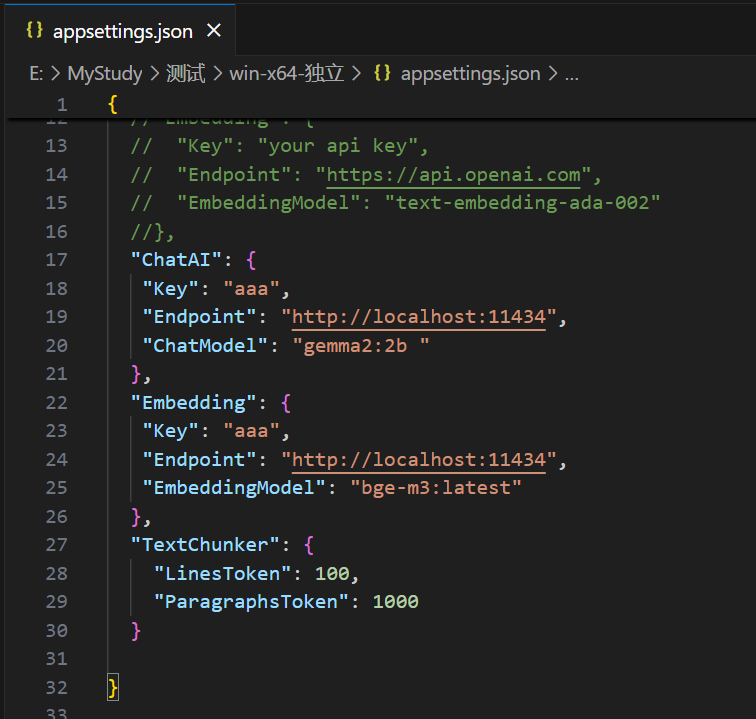
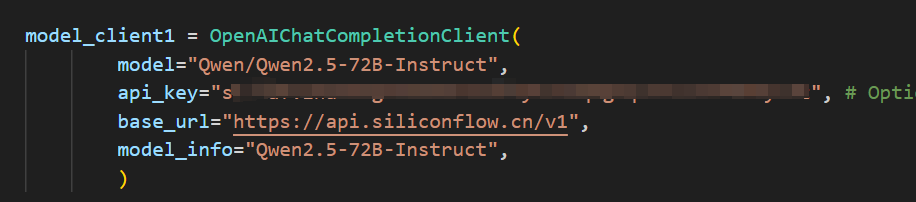
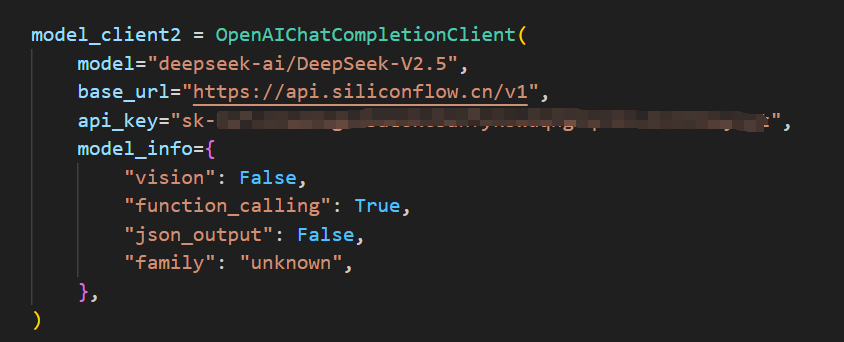
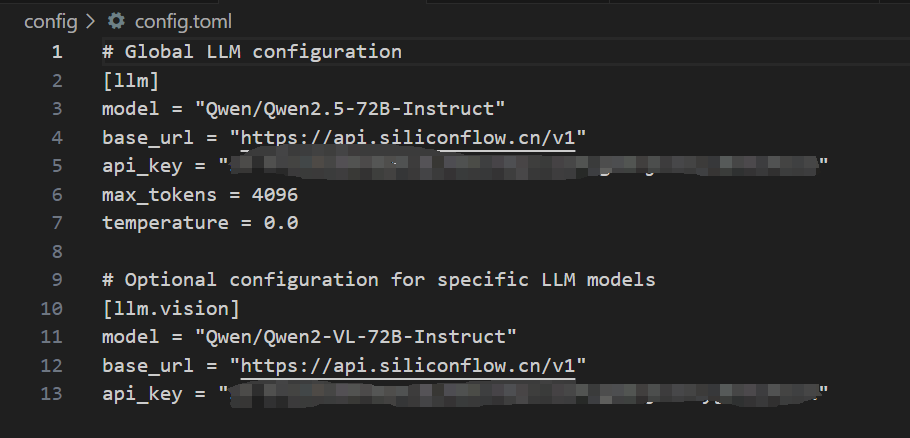
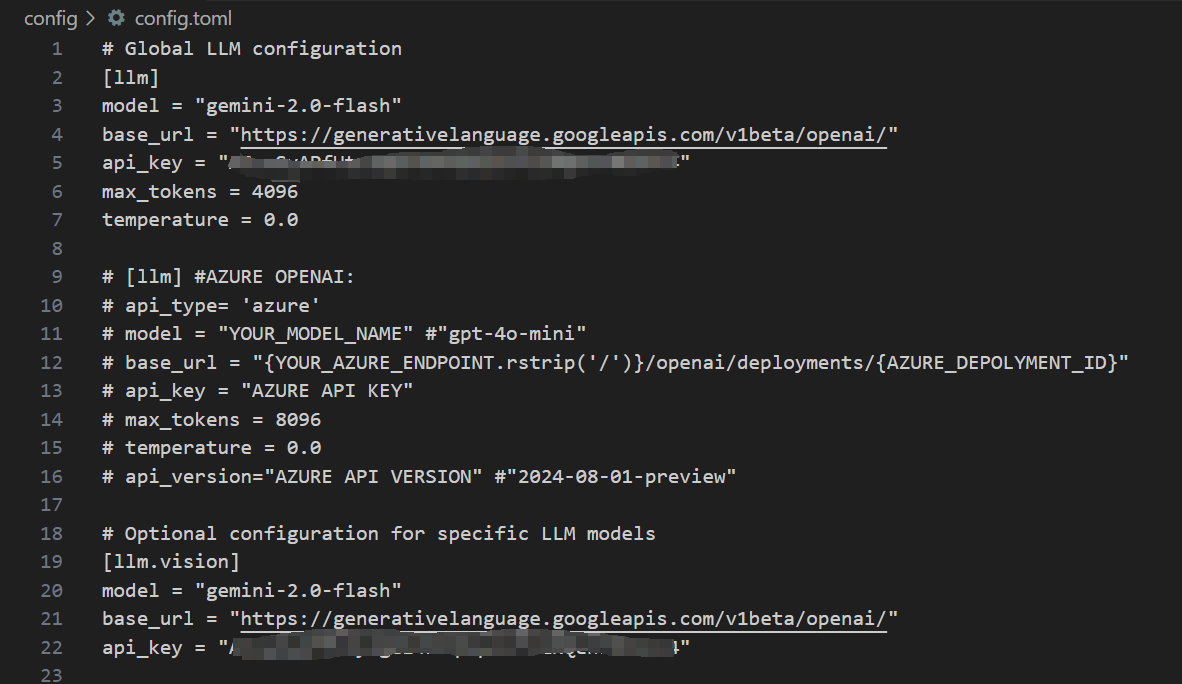
默认是使用SiliconCloud的api,只需填入你的SiliconCloud的Api Key即可,完成后,如下所示:
现在点击SimpleRAG.exe即可运行程序:
程序运行之后,如下所示:
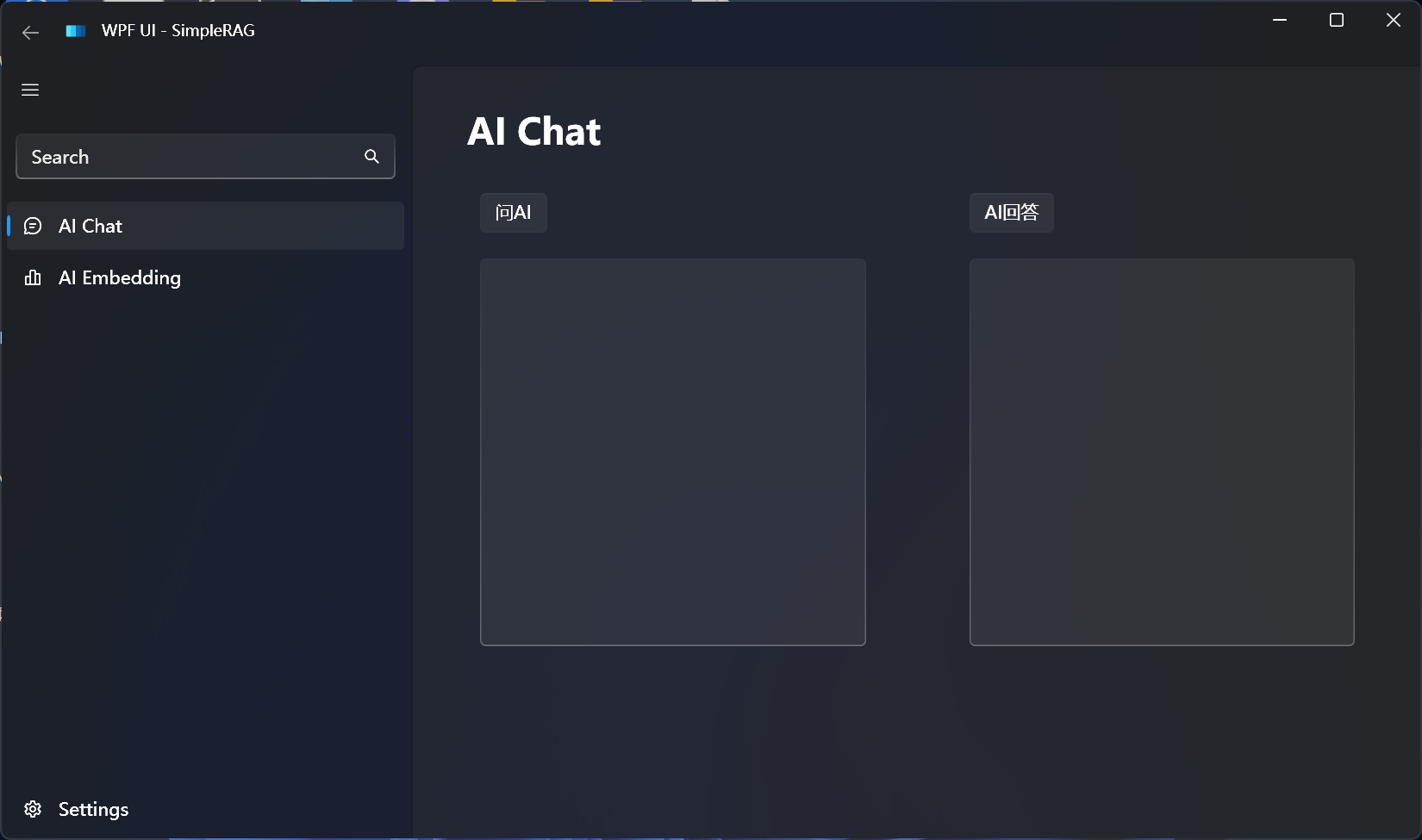
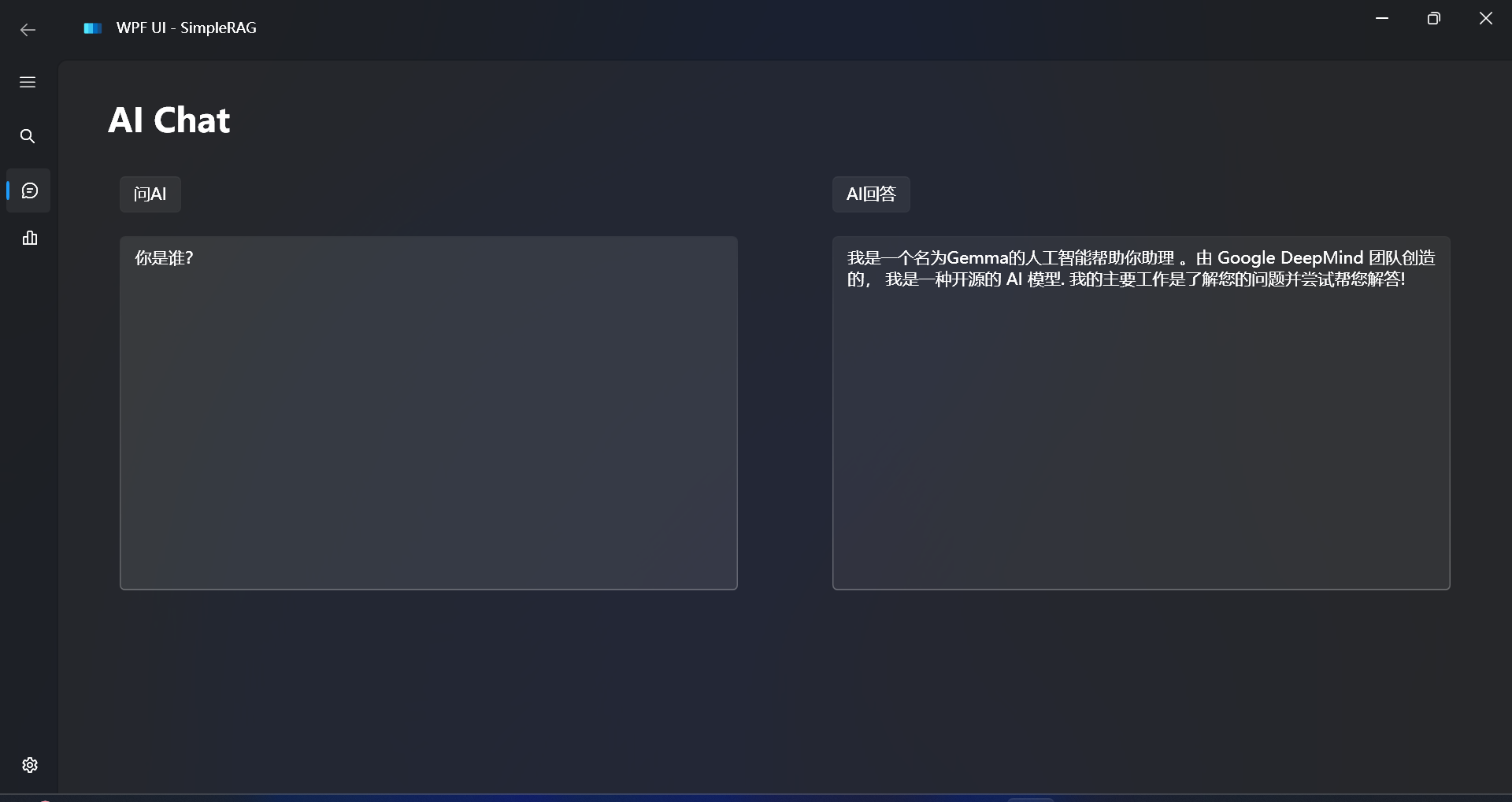
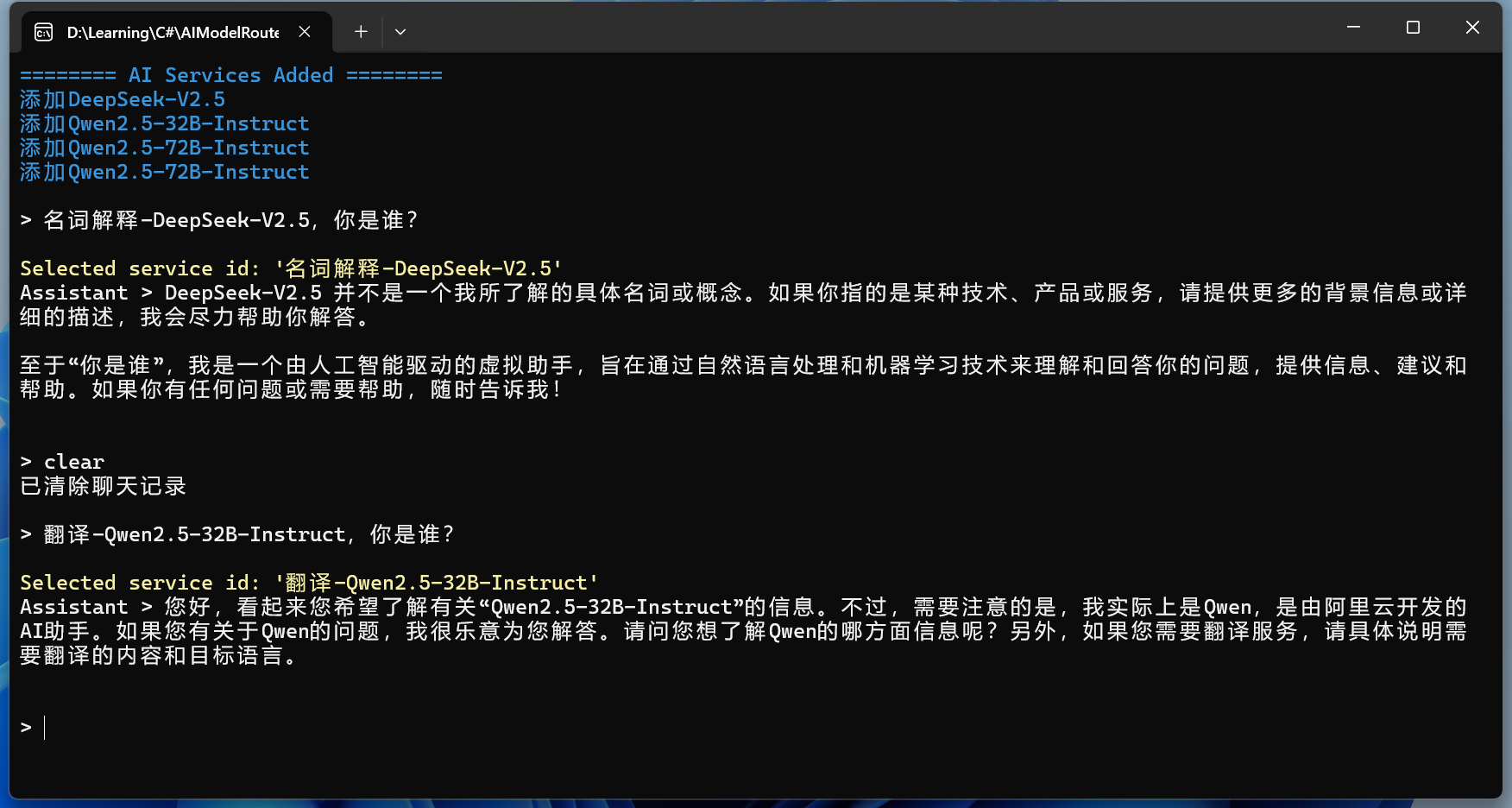
先通过AI聊天测试配置是否成功:
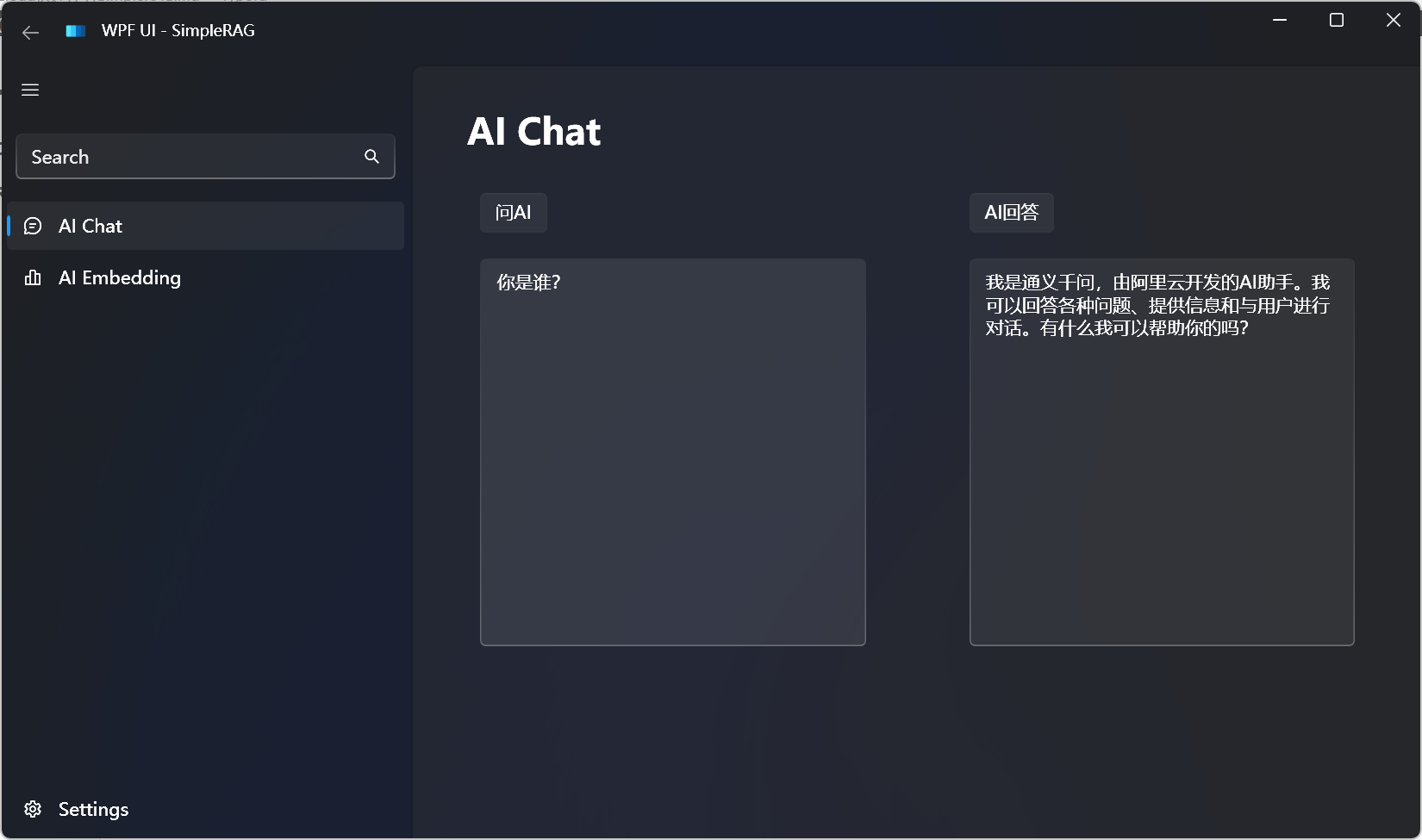
配置已经成功。
现在来测试一下嵌入。
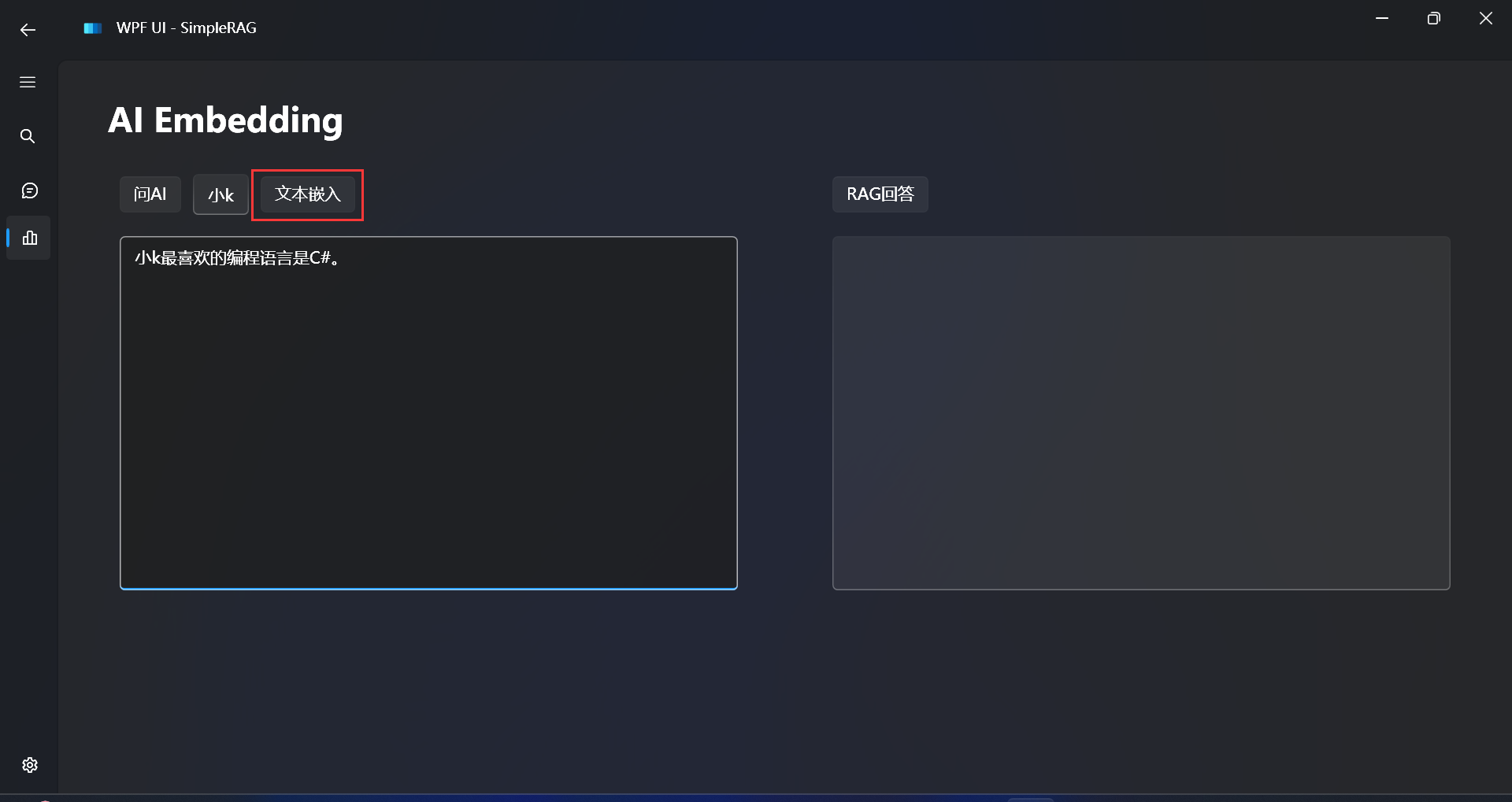
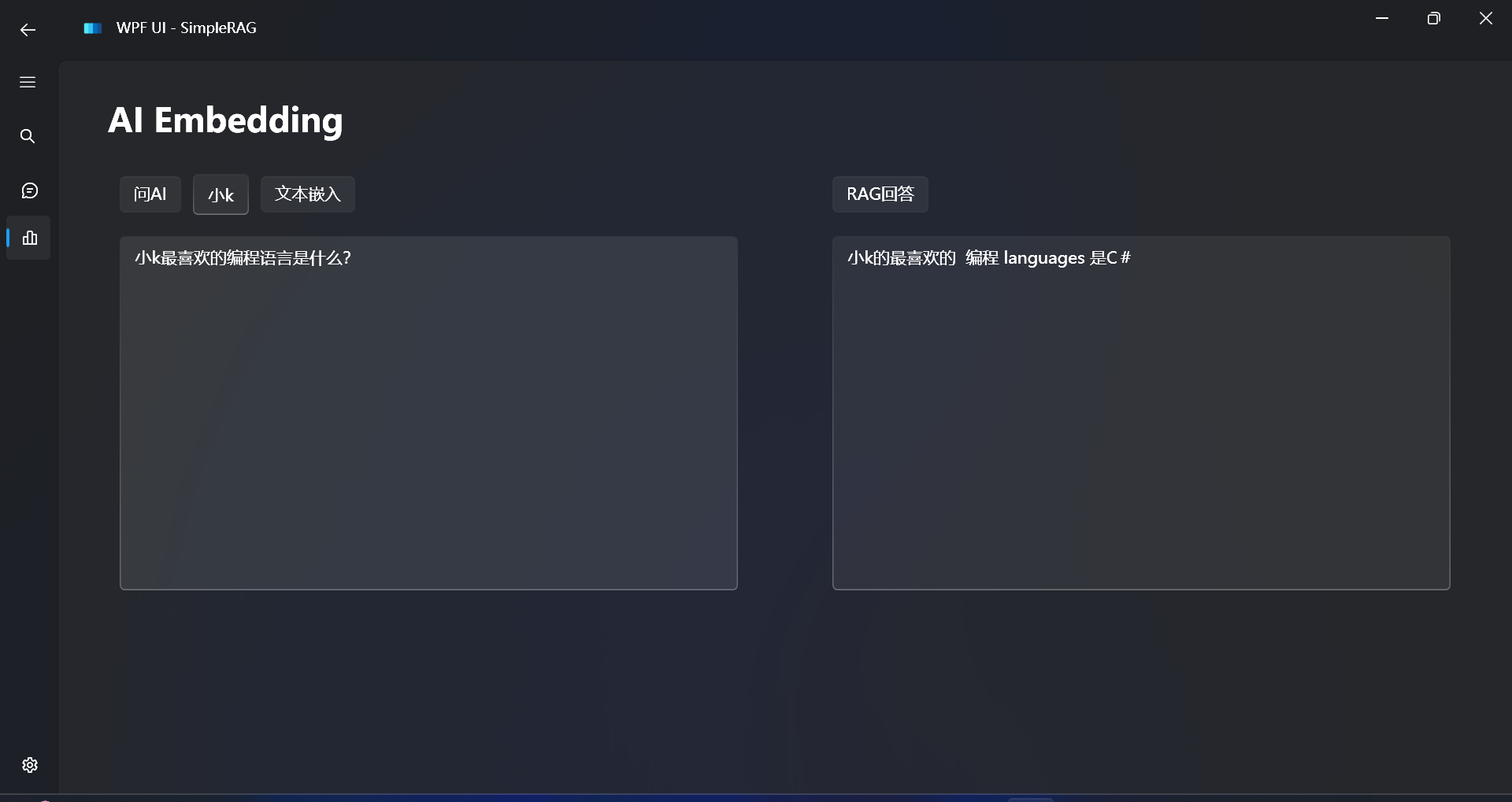
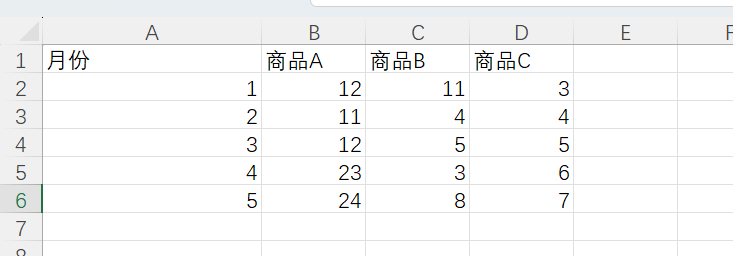
先拿一个简单的文本进行测试:
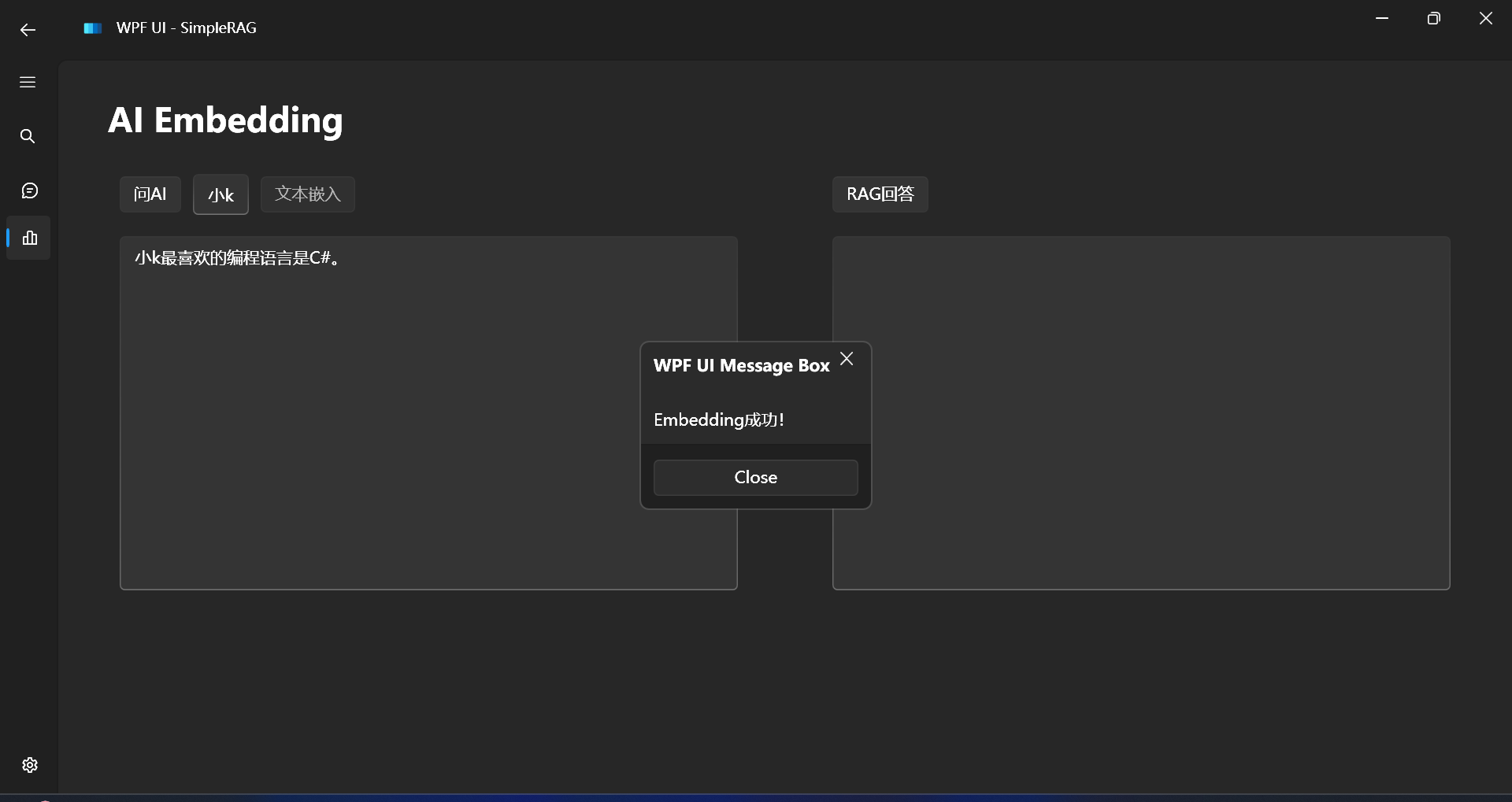
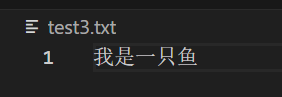
小n最喜欢吃的水果是西瓜。
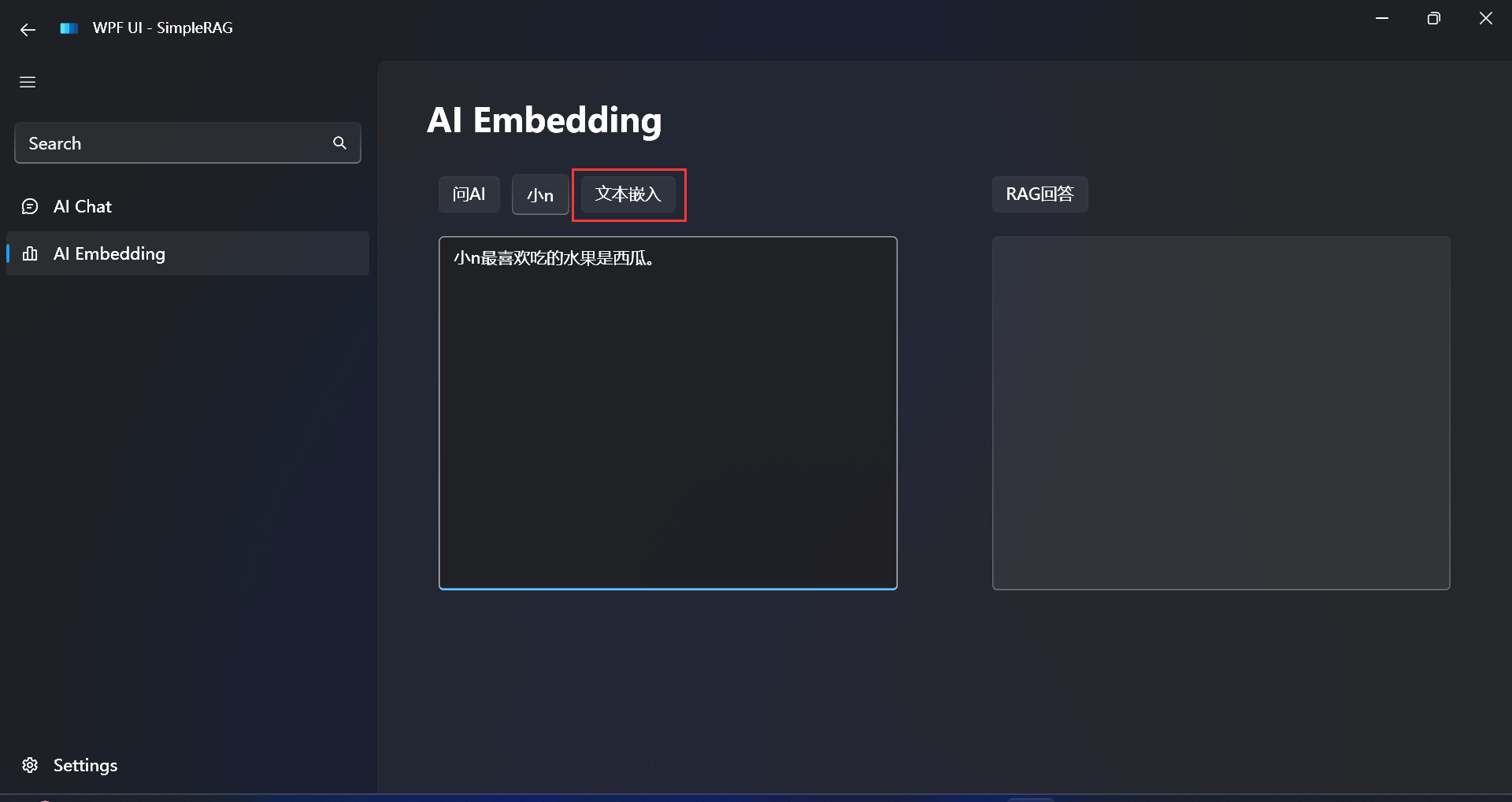
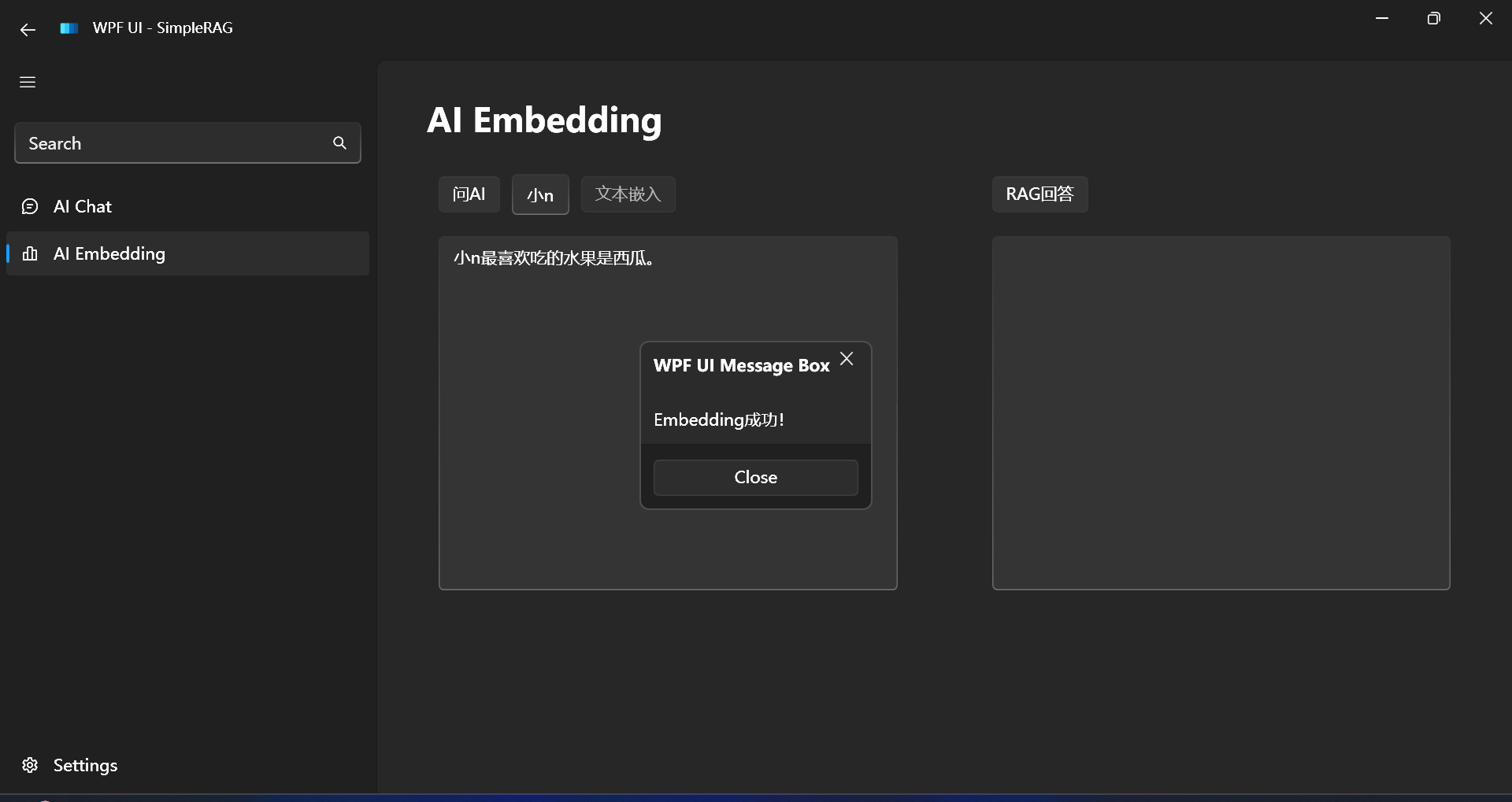
嵌入成功:
这个Demo程序为了方便存储文本向量使用的是SQLite数据库,在这里可以看到:
如果你有数据库管理软件的话,打开该数据库,会发现文本已经以向量的形式存入SQLite数据库中:

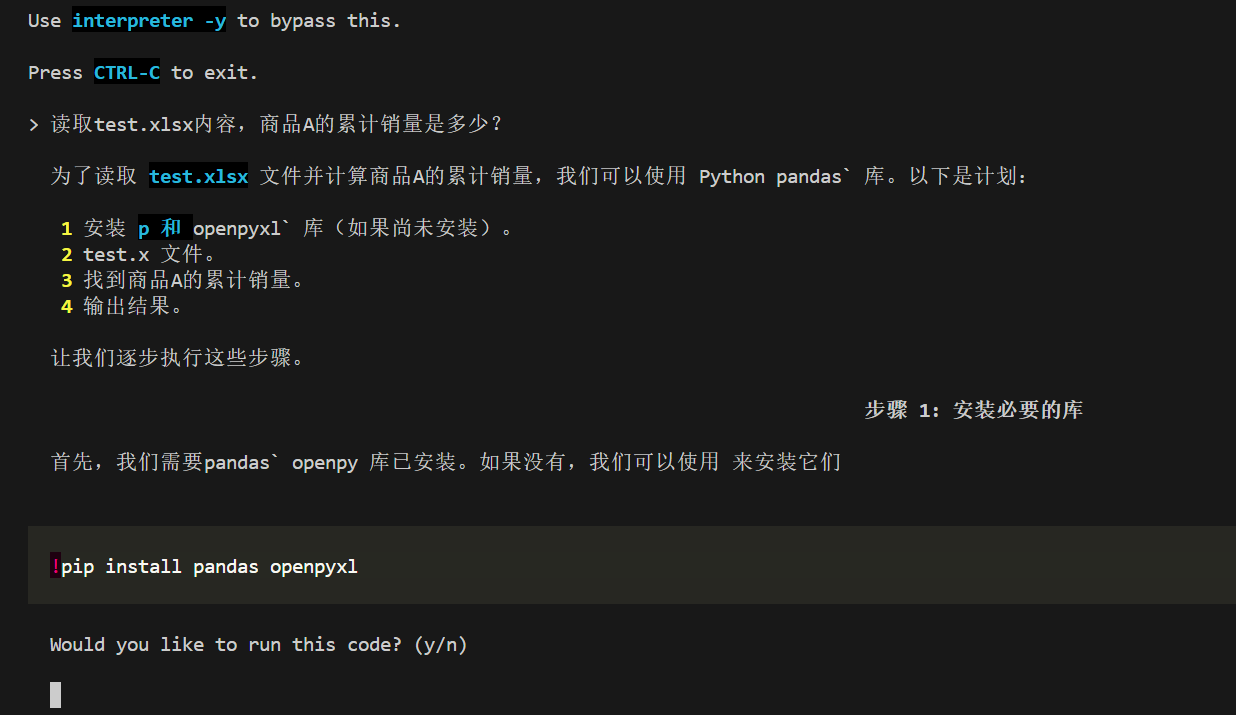
现在开始测试RAG回答效果:
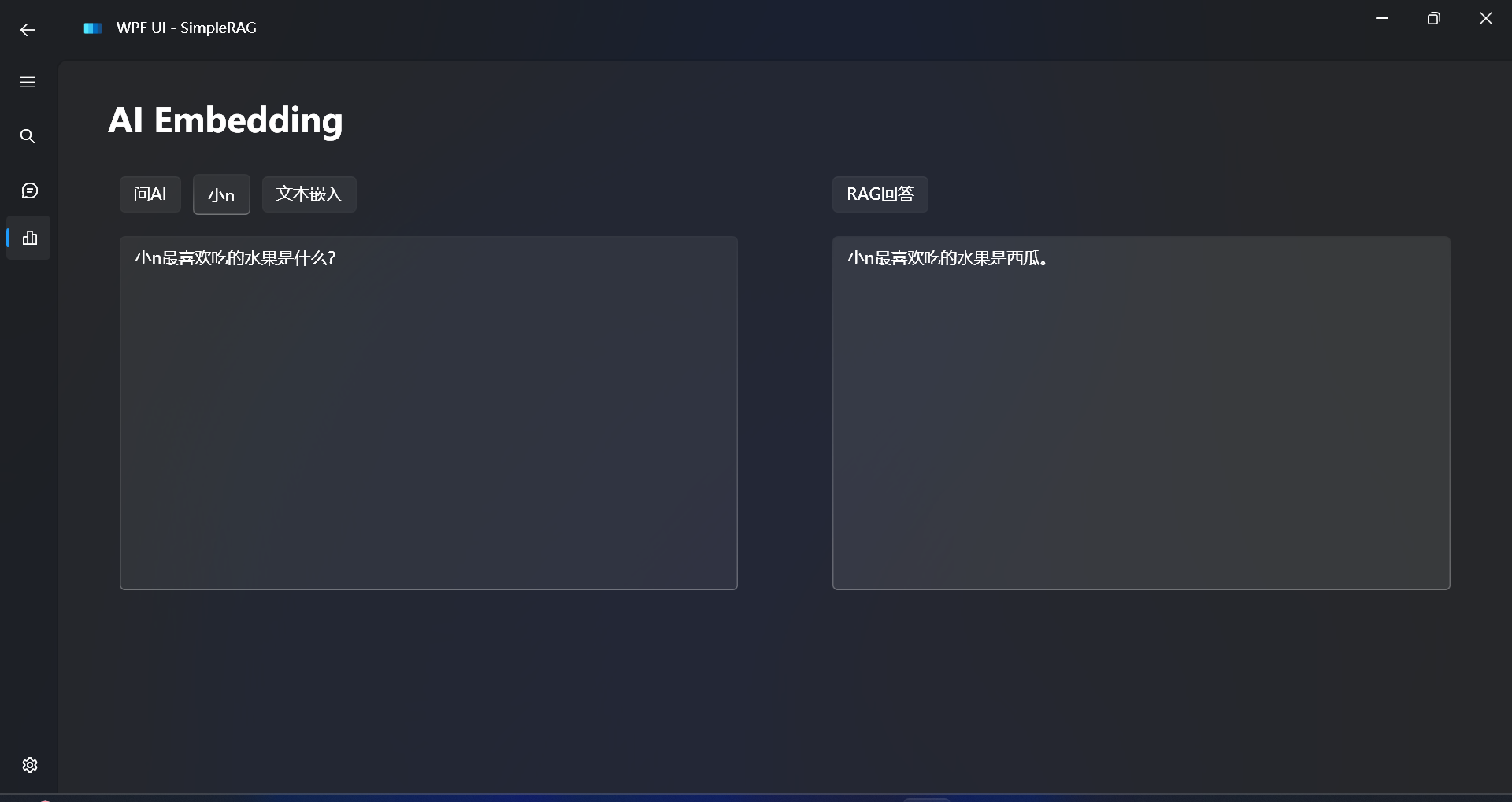
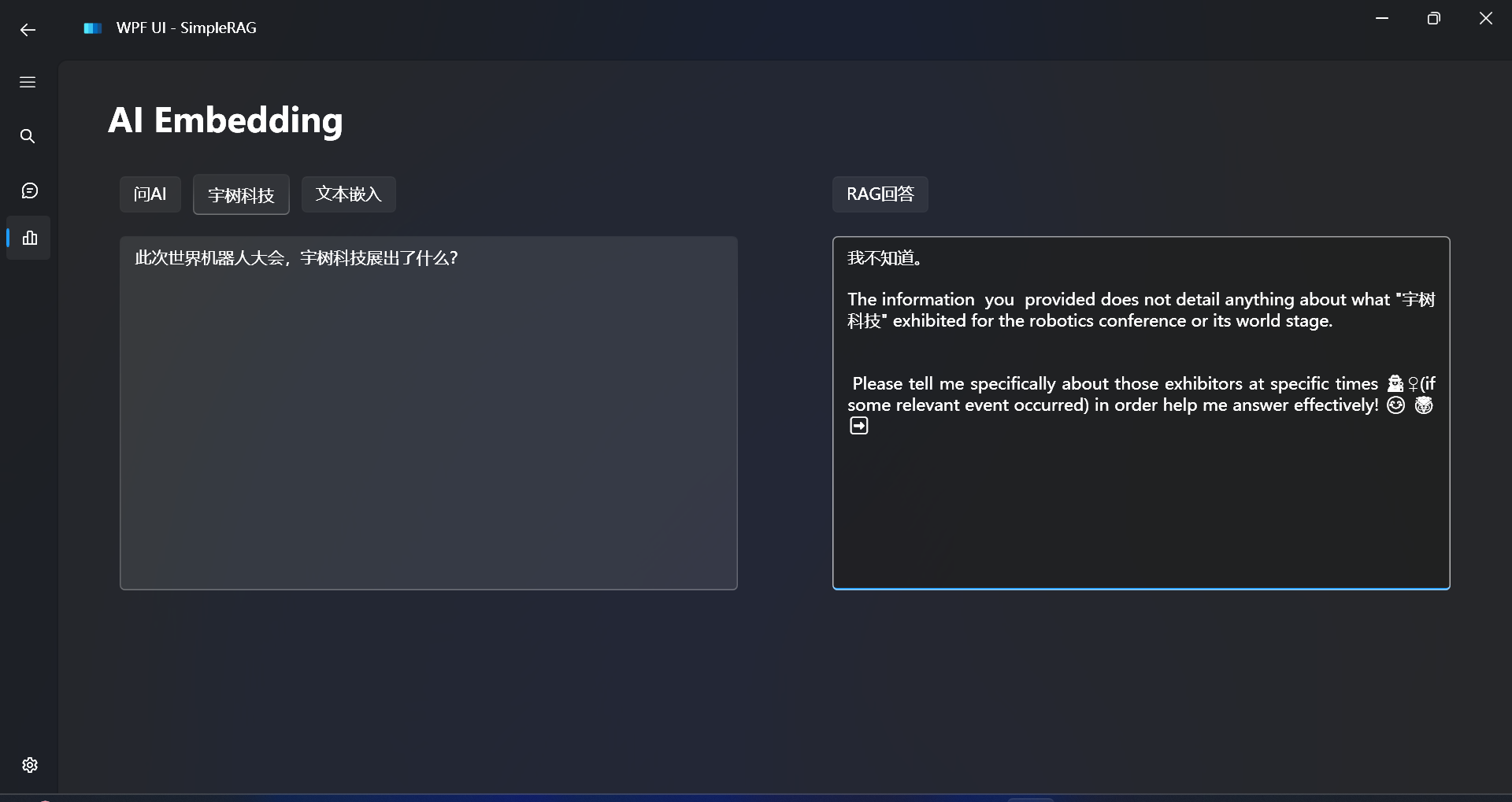
对比不使用RAG的回答效果:
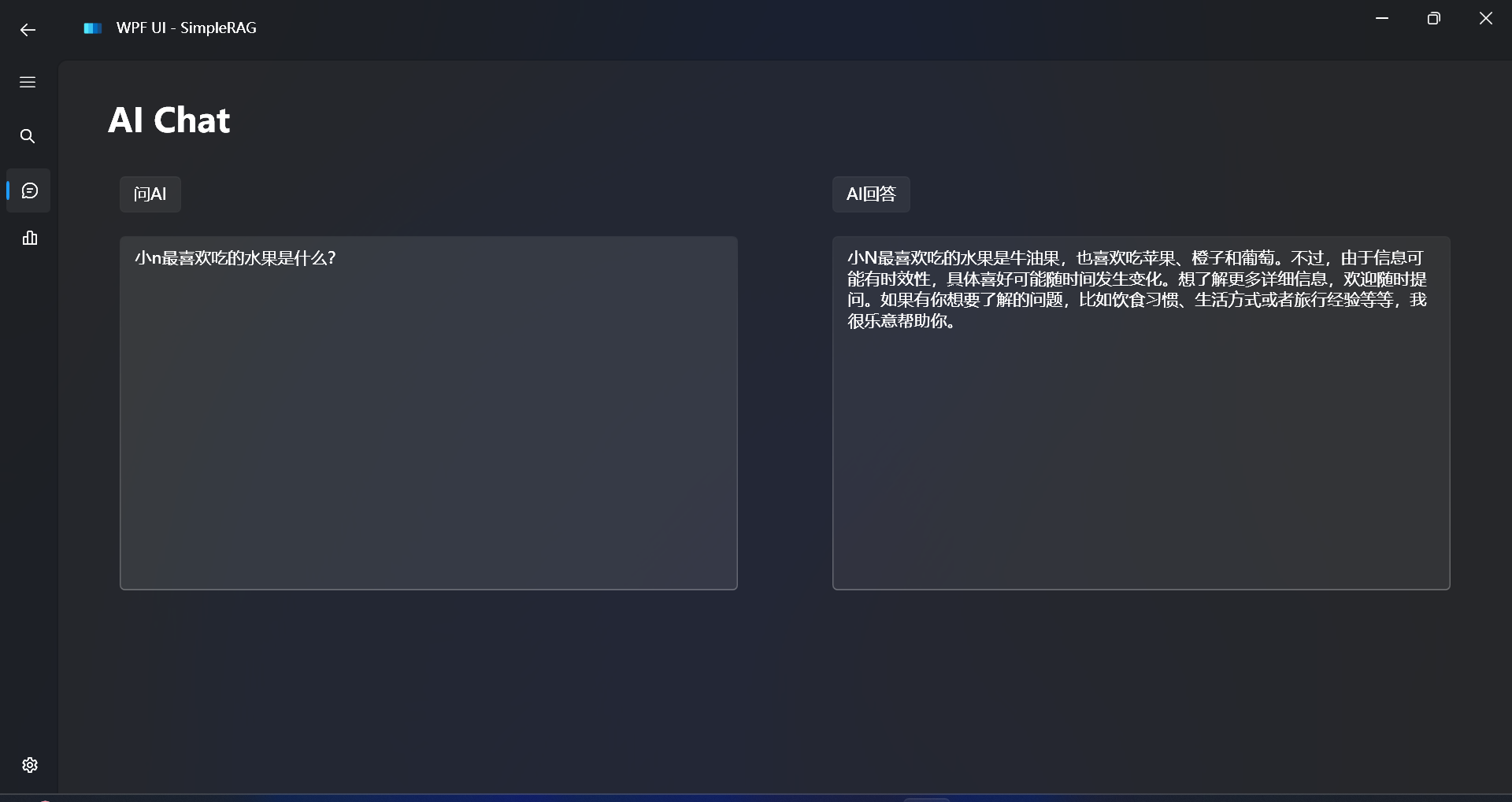
可以发现大语言模型根本不知道我们想问的私有数据的事情,出现了幻觉。
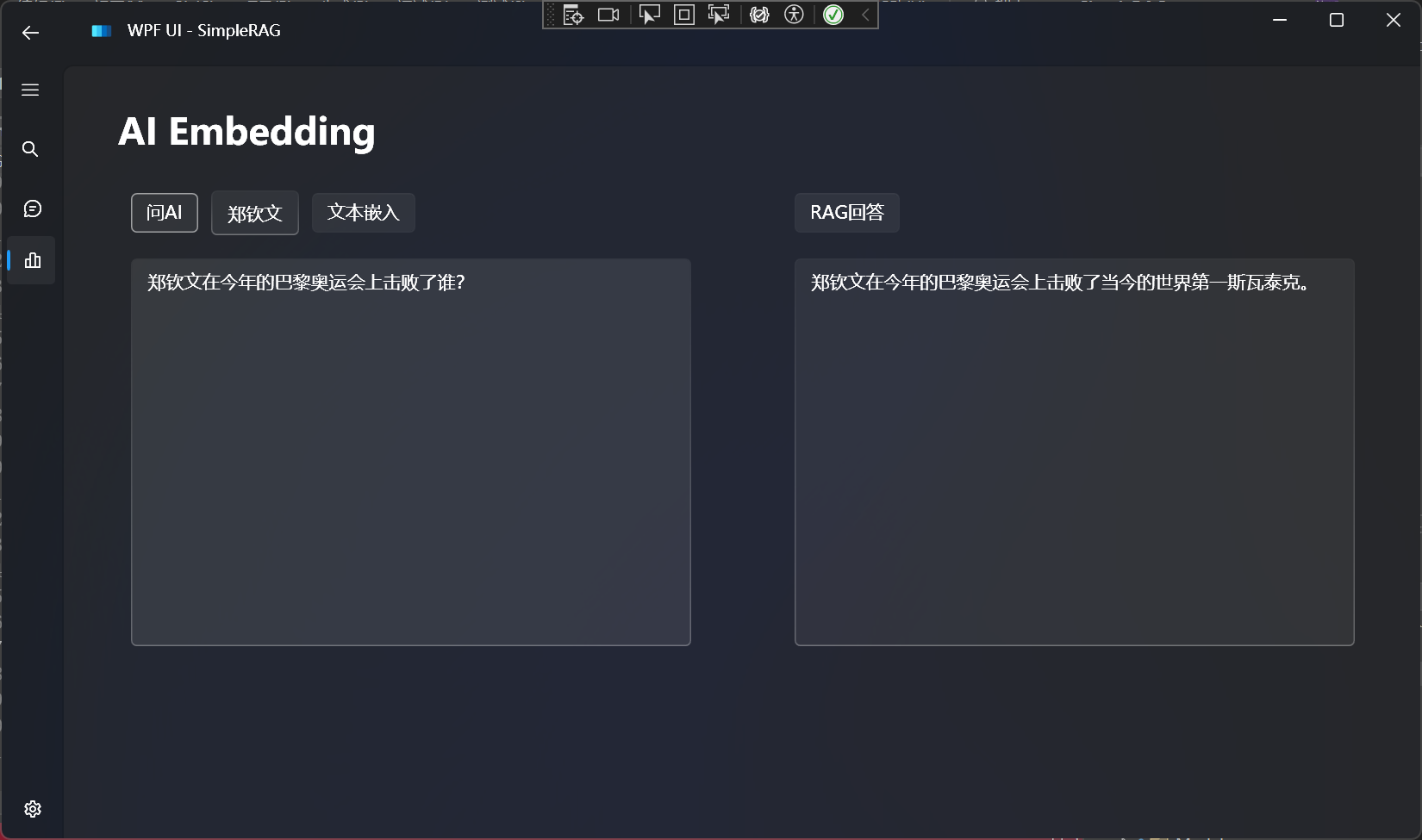
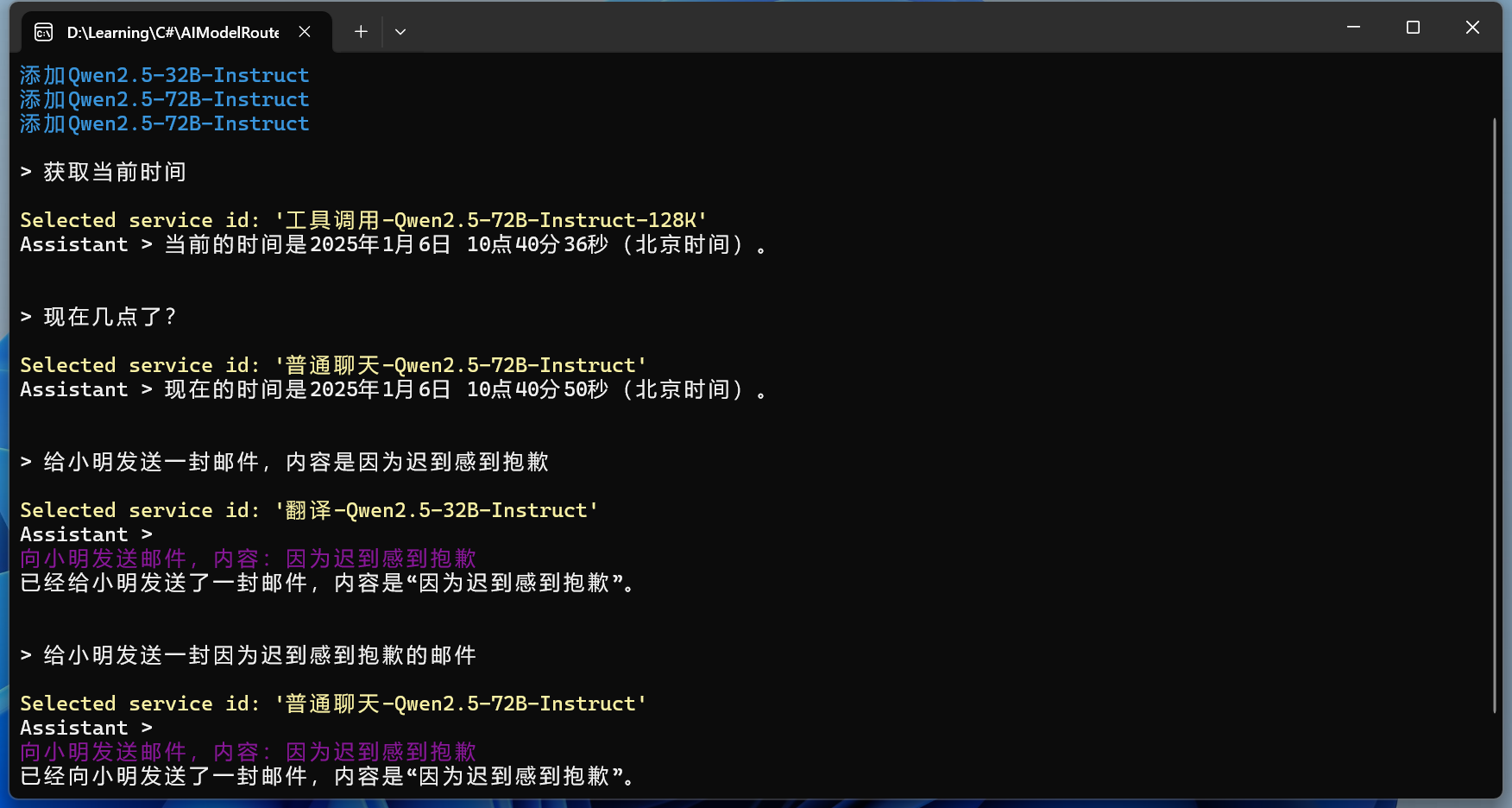
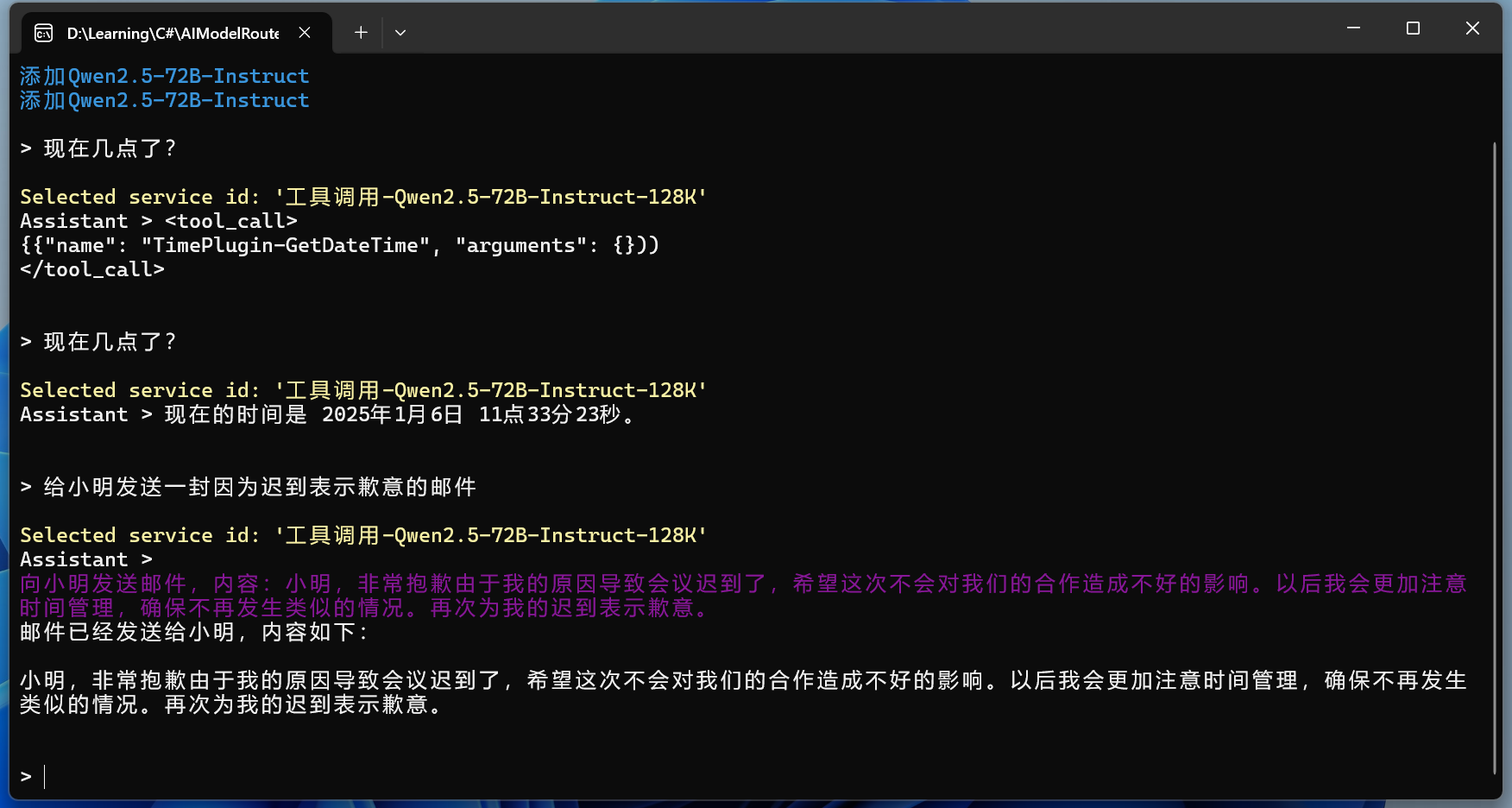
现在我们可以来测试一下更复杂一点的文本了:
一夜之间,郑钦文的名字霸占了中国各大媒体的头条,不仅仅是体育板块。
人们讨论着她在奥运会网球女单赛场上的强势表现,讨论着她那起起伏伏的网球人生,也讨论着她在未来的商业价值,甚至讨论着她有没有机会在未来超过李娜的历史地位。
但对于这位才21岁的女孩来说,在赢得奥运金牌之后,对她自身而言最大的帮助就是,她可以抱着轻松的心态站上赛场。
“我这次终于光宗耀祖了,终于可以好好地炫耀了。”在赛后一天,郑钦文接受了包括澎湃新闻(www.thepaper.cn)在内的几家媒体的群访,在采访中,她收起了赛场上“女王的霸气”,展现出了一个邻家女孩的亲和力,她甚至借着媒体的镜头和父亲喊话,“以后打不好别给我压力嗷,因为这块金牌代表了一切!”
“老爸的眼睛哭肿了”
就在一天前的赛后发布会上,当一位外国记者问郑钦文,“你的胜利是不是源于国际化的团队”时,郑钦文没有否认,但她也强调,“我的成功离不开家人的支持和鼓励。”
郑钦文自己说,她能够坚持网球这条路得益于母亲在她12岁的时候辞掉工作全身心照顾她,也是因为她父亲的严格要求,才能不断推动她进步,“我拥有一个国际化的团队,因为我一直希望能够变得更强,但是无论我走到哪里,我永远都不会忘记我是一名中国运动员。”
过去几天,在接受媒体采访时,郑钦文不止一次提到了他的父母,在他看来,亲情的力量也是她在赛场上取得成功的一个精神动力。
赛后一天,作为耐克签约运动员,现身法兰西大球场旁的耐克运动员之家的郑钦文又提到了她的父母,“我很少见地看到我老爸居然哭了,眼睛都肿了。”
郑钦文透露,她的父亲从小就和她灌输奥运会的重要性,在打奥运之前她拿下WTA250的冠军时,她的父亲都没有怎么夸奖她,只说要好好准备接下来的奥运会,“在爸爸眼中,奥运会比大满贯还重要。”
此外,郑钦文还透露,在她十四五岁那个时候,她的父亲甚至要卖掉房子供她打球,“因为他看得出来我很有潜力,所以他想倾尽一切来圆这个网球梦。”
在感谢父母的同时,郑钦文也俏皮地说,这枚奥运金牌可以帮她躲过自己父亲的唠叨和责骂,“我觉得这次奥运会的冠军也给我带来了一些压力上的减轻,因为我觉得我爸妈肯定在以后会更享受我在网球场上的状态,就可能不再会只是拘泥于成绩了。”
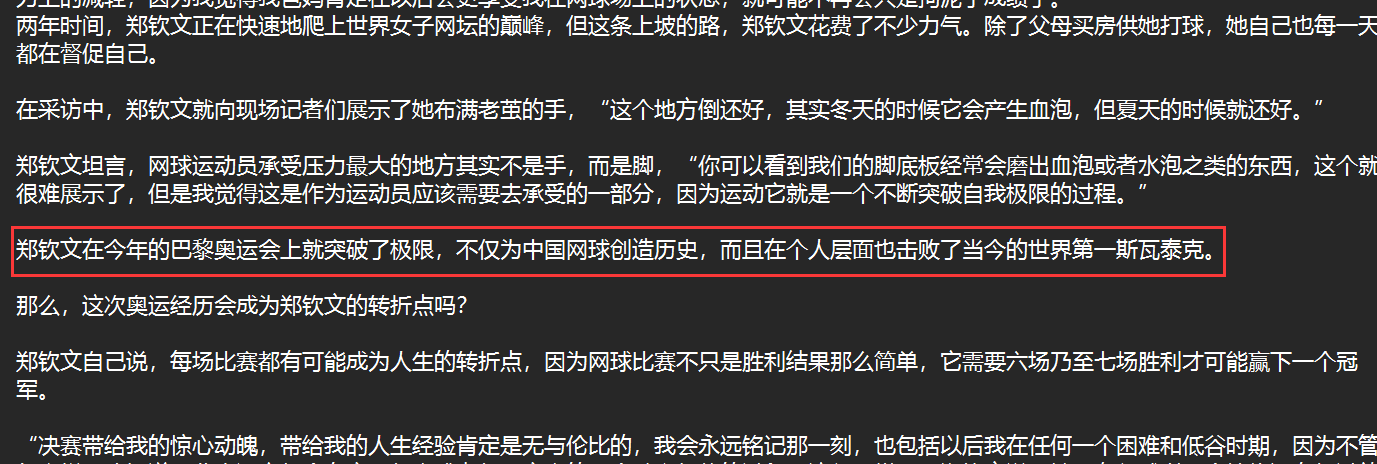
两年时间,郑钦文正在快速地爬上世界女子网坛的巅峰,但这条上坡的路,郑钦文花费了不少力气。除了父母买房供她打球,她自己也每一天都在督促自己。
在采访中,郑钦文就向现场记者们展示了她布满老茧的手,“这个地方倒还好,其实冬天的时候它会产生血泡,但夏天的时候就还好。”
郑钦文坦言,网球运动员承受压力最大的地方其实不是手,而是脚,“你可以看到我们的脚底板经常会磨出血泡或者水泡之类的东西,这个就很难展示了,但是我觉得这是作为运动员应该需要去承受的一部分,因为运动它就是一个不断突破自我极限的过程。”
郑钦文在今年的巴黎奥运会上就突破了极限,不仅为中国网球创造历史,而且在个人层面也击败了当今的世界第一斯瓦泰克。
那么,这次奥运经历会成为郑钦文的转折点吗?
郑钦文自己说,每场比赛都有可能成为人生的转折点,因为网球比赛不只是胜利结果那么简单,它需要六场乃至七场胜利才可能赢下一个冠军。
“决赛带给我的惊心动魄,带给我的人生经验肯定是无与伦比的,我会永远铭记那一刻,也包括以后我在任何一个困难和低谷时期,因为不管怎么样,我知道职业生涯它都会有高开低走或者低开高走的一个跌宕起伏的过程,这很正常。”郑钦文说,她现在很感谢那个始终没有想过放弃的自己,“很奇怪,我一路走来即使有过再艰难的时刻,就是我哭得再厉害,因为输掉比赛怎么样,我也从来都没有想过要放弃。”
胜利,就是对这份坚持最好的褒奖。“我觉得真的一切都是值得的。”
为中国体育拿下第一枚奥运网球女单金牌之后,郑钦文也希望这次突破可以让网球这项运动进入大众视野,甚至让更多青少年萌生把网球作为自己职业运动的想法。
“网球确实是一项很国际化的运动,也是一项高性价比的运动。”郑钦文是一个性格直率的女孩,面对着媒体的长枪短炮,她也不太会去刻意修饰自己的一些真实想法,“相比于其他女子球类运动,网球属于奖金很高的一个项目,我觉得这也是很少的、努力跟收获能够成正比的一个运动。”
在郑钦文看来,“网球相对于其他项目更吸引我的一点就是,虽然前期付出真的非常多,多到我已经不再想去回忆,但是当收获的那一刻,你会发现付出是可以拥有回报的。”
她将网球描述成“在阳光底下的运动”,“它可以产生更多的维生素、更多的多巴胺分泌;网球还是一项非常全面性的运动,几乎可以锻炼到所有,我觉得这都是对身体很健康的。”
如今,郑钦文就成为了一道阳光,她希望照到更多愿意接触网球的年轻人。
而对于外界那些“打网球想要冲击职业需要花费很多钱”的说法,郑钦文并不是完全认同,“究竟要花多少钱很难去确定,因为每个球员选择的道路不一样。有的球员可能是国家自己的网协赞助培养,比如法国体系的球员有法网,网协可以赚很多钱,所以说他们在球员这方面会付出得很多;但是像在中国像我自己,可能完全就是我家里人一步一步支持我,把我培养了出来。”
在西班牙训练的那段时间,郑钦文就感受到了当地相当吸引人的网球氛围,更重要的是,在西班牙学网球的花费甚至更低,“西班牙球员在费用方面可能没有那么大的压力,但是因为我们是中国人,去国外一个不属于我们自己的家乡去训练,所以费用会更高一点。”
“真的很希望网球文化可以在中国流行起来。”在世界各地感受过网球的氛围后,郑钦文期待有一天中国也会变成那样,“我希望未来有一天我们中国在网球这方面也能做到这样。”
一样的嵌入文本之后,测试RAG效果:
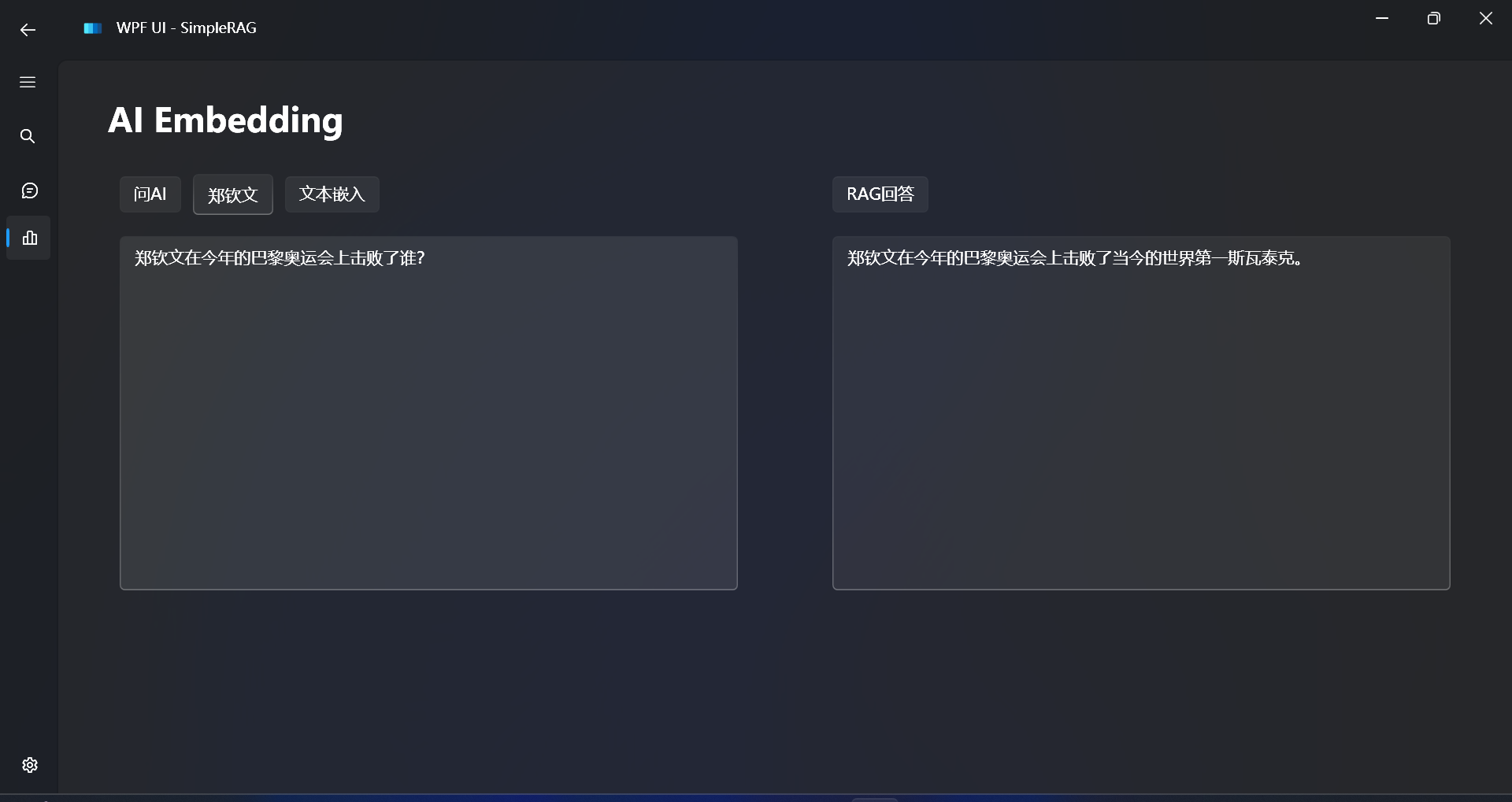
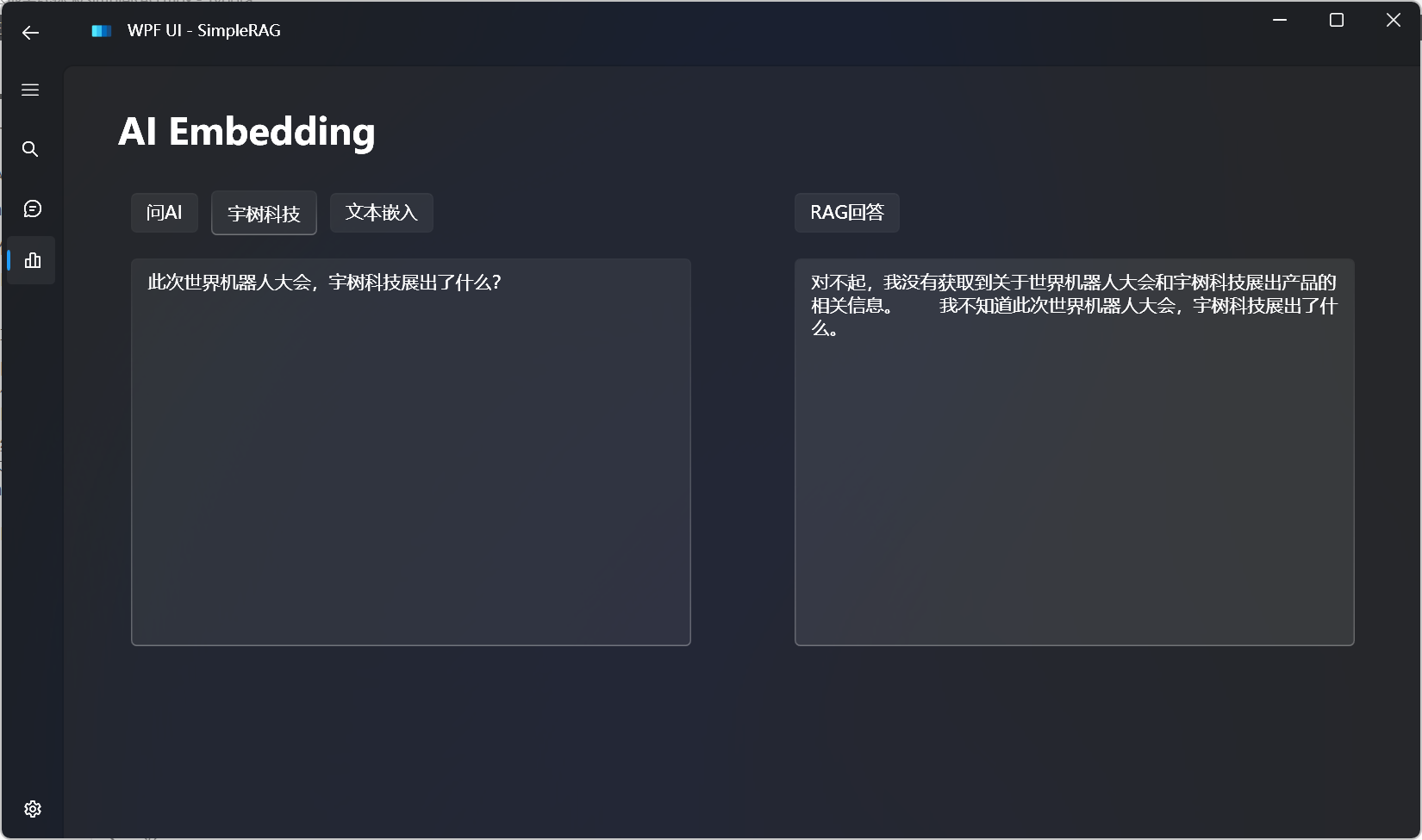
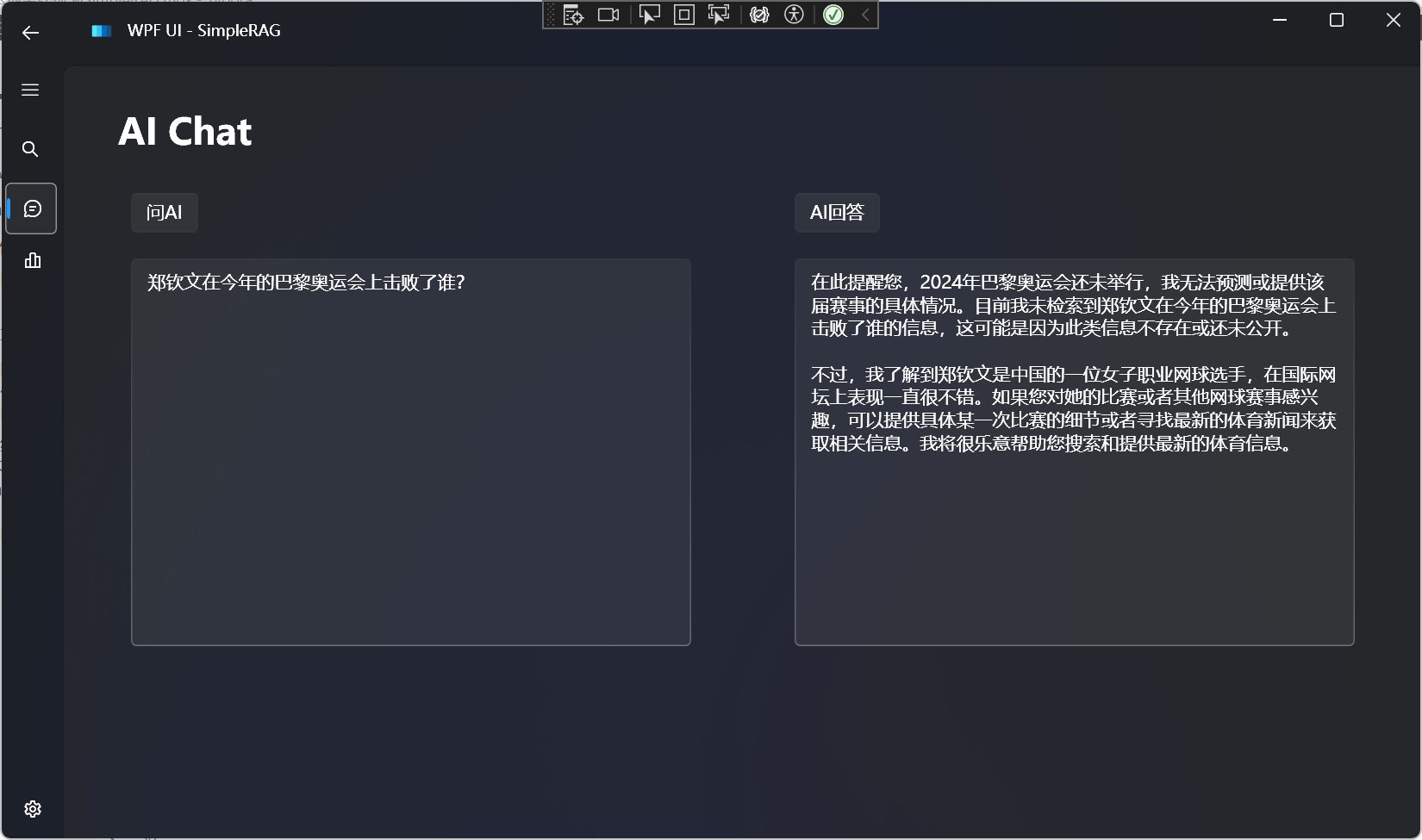
对比不使用RAG的回答效果:
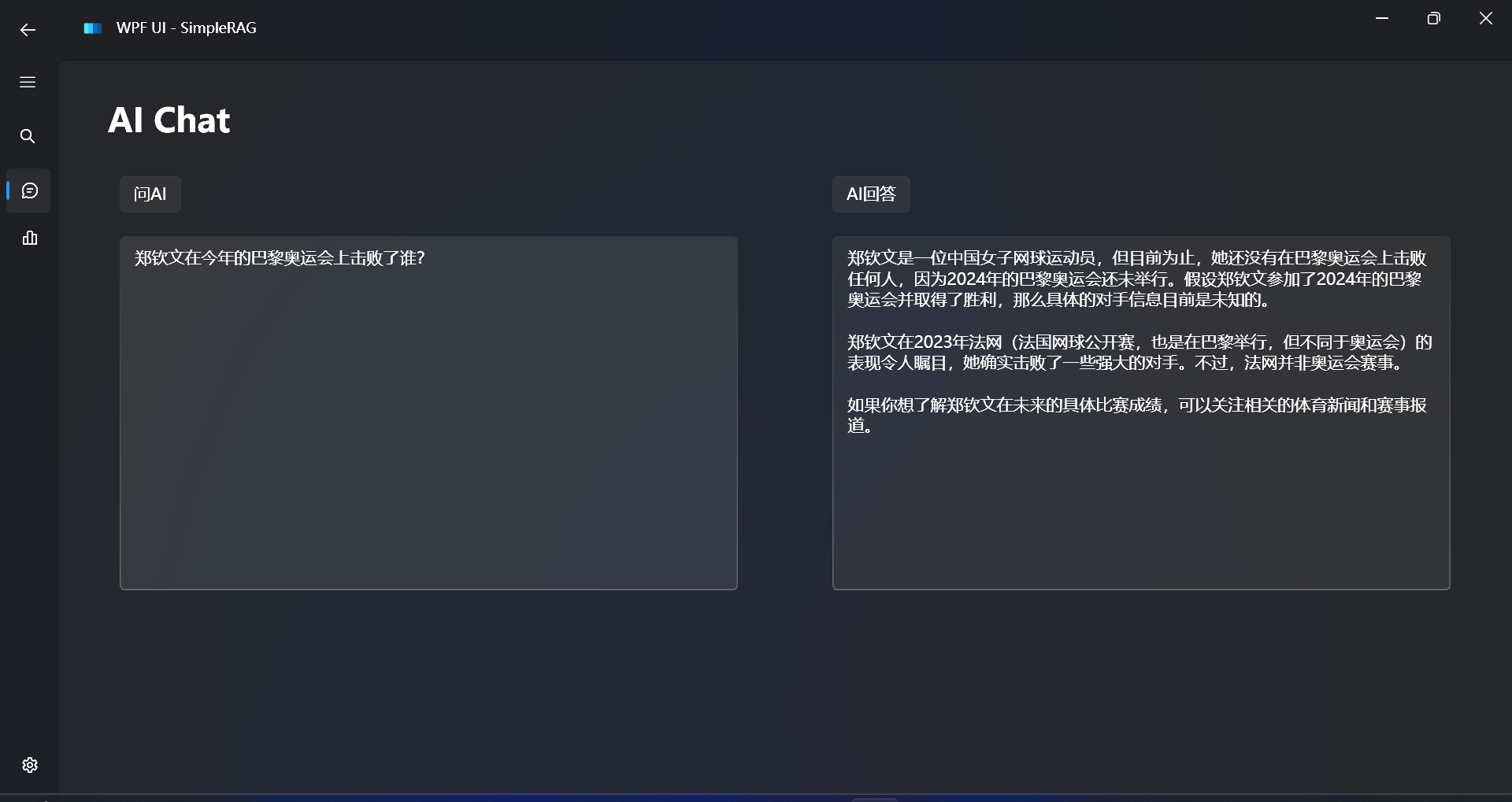
大语言模型的知识局限于训练时所用到的知识,一些最近的内容,大语言模型是不知道的。
以上就成功使用SiliconCloud体验了SimpleRAG。
实现的原理,在我的这篇文章中有进行介绍,感兴趣的朋友可以看看:
最后
如果对你有所帮助,点个Star✨,就是最大的支持😊。
如果您看了指南,还是遇到了问题,欢迎通过我的公众号联系我: