来源: Meteor与精益创业 – BitTiger.io – 知乎专栏
链接:https://zhuanlan.zhihu.com/p/20139000
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
今天要和大家分享的是目前最火爆的网站开发框架之一-Meteor。它是一个搭建在Node.js之上,用于快速开发动态网站的工具。Meteor和其他开发工具相比最大的优势就是它的动态更新。这个应该怎么理解呢?举个最简单的例子,你觉得Wikipedia和Google Doc最大的区别是什么呢。在现实生活中,两个人看一篇文章,一个人做标注,另一个人马上就可以看到。如果这两个人是在Wikipedia上看同一篇文章,一个人修改了文章中的一句话,另一个人如果不刷新页面是永远都不会看到更新的(这里可以不考虑Wikipedia审批的过程)。而如果两个人都是在用Google Doc做相同的事情,任何改动都是一目了然,而且是实时的。Meteor实现的就是这种实时动态的交互方式,把现实拉近网络。
网络开发技术的演变
网络技术的更新换代是非常之快的,真的可谓是日新月异。归根结底还是源于人类的本性上对网络的依赖。人是一种社交动物,而网络正是一种可以在很大程度上增强人类社交范围和能力的工具。在正式介绍Meteor之前,我觉得有必要先给对网络开发技术不熟悉的朋友普及一下网络开发技术的演变过程,网站开发大牛可以直接跳到下一个部分。
最开始的网站开发是非常简单纯粹的,前端就是用户的电脑浏览器,后端就是网站的服务器。前端只做两件事:发出请求,等待回复。后端呢,就储存着一个网页,有人来要的时候就发给他。网络构建就是这么简单。后面随着网页的内容越来越多,越来越复杂,后端开始逐渐根据功能分散成Apache Server + PHP + SQL DB。从名字也可以看出就是把服务器和数据库分置开来。这样可以更方便管理大量的数据。但在此时前端并没有发生任何变化,用户的浏览器还是继续做着要、等、拿三件事。
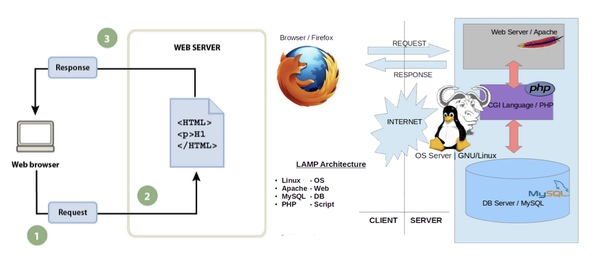 再之后,就来到了网络技术产生重大变革的时刻。随着AJAX (AJAX = Async JavaScript + XML) 技术的到来,Web 2.0走进了我们的生活。在这个阶段,前端发生了巨大的改变。JavaScript, CSS等技术使前端具备了处理数据的能力,再加上XML作为前后端信息交互的平台。前端用户的浏览器开始能够处理一些用户简单的交互需求,帮助后端服务器分担压力,大大提升了网站的响应和处理速度。
再之后,就来到了网络技术产生重大变革的时刻。随着AJAX (AJAX = Async JavaScript + XML) 技术的到来,Web 2.0走进了我们的生活。在这个阶段,前端发生了巨大的改变。JavaScript, CSS等技术使前端具备了处理数据的能力,再加上XML作为前后端信息交互的平台。前端用户的浏览器开始能够处理一些用户简单的交互需求,帮助后端服务器分担压力,大大提升了网站的响应和处理速度。
继续演进,就来到了现在MVC主导的时代,这也是大部分公司现在正在使用的网站架构模式。MVC = Model + View + Controller。 Model指的也就是data,讲我们怎么存储信息,对应的技术就是MySQL DB, MangoDB。 View指的是presentation,换句话说就是展示信息,和界面相关的东西,自然对应的就是Html, CSS, Javascript这些前端的技术;最后一个就是Controller了, 包含了所有和逻辑处理相关的部分。一开始这个设计方式可能更多地被用在服务器端。但随着Web2.0的到来,越来越多的网络开发framework像雨后春笋一样蓬勃发展,开始在前端也搭起了MVC的架构,比如AngularJS, Backbone都实现了这一点。更有甚者,直接将前端的Javascript直接渗透到后端。Node.js就是其中之一,它让只懂Javascript本来只能做前端的工程师变成了全栈同吃。再比如很多人都开始在用pure javascript的架构,最主要的一个代表就是MEAN = MongoDB + Express.js + Angular.js + Node.js
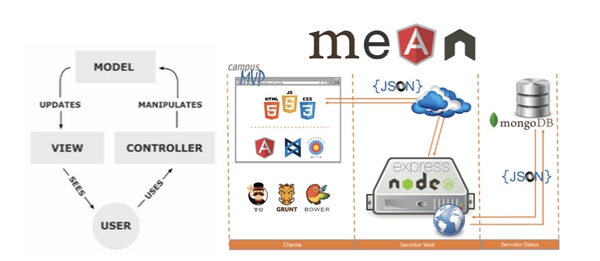 Meteor技术
Meteor技术
Meteor和我们上面提到的framework其实并没有非常大的区别,它也是辅助工程师搭建网站的一种工具。因为它是建立在Node.js之上,所以自然而然也就继承了Node.js所有的优势。比如你只需要会Javascript就可以全栈同吃。再比如Node.js是第三方插件,工具,资料最多的开源项目。因此很多时候你可能都不需要写很多代码,只是通过调用一些插件就能实现很多很复杂的功能。
在现在的互联网行业,很多用户需求都是由移动端驱动的。中国特殊的互联网市场环境更是将移动互联网推到了风口浪尖。以至于在做好web端开发的同时还要兼顾app的开发。做产品时你对技术的需求量就会很大。在application layer你可能需要有精通iOS和Andriod的工程师,在service layer你能需要构建懂逻辑处理和api架构的工程师,在data layer,你可能需要有精通数据处理的人。Meteor完美了解决的这方面的问题。它在你写前端网页的时候,会帮你自动生成iOS和Andriod app。可以说是一石三鸟。
现在Meteor在1.0版本主要是在用blaze来生成前端页面,它使用的是templating lanuage。你只需要写简单的html片段来包装你要展示的数据和逻辑,blaze就会自动帮你拼接成一个完整的页面。Meteor作为开源的framework,自然不能亏待了同为开源的兄弟们。不久后的2.0版本,它将支持大部分最新的前端开源framework,比如Angular.js,Facebook主导的React等等。所以很多现有的前端技术和实现方式都可以直接从其他的架构搬到Meteor。在后端数据库这边,Meteor只支持MongoDB,但在不远的未来它也将会支持其他比较流行的Database, 比如SQL,REST。
接下来要谈的是Meteor最吸引人的页面动态更新特性。虽然同为pure Javascript framework,它和MEAN还是很不同的。和MEAN架构最大的不同,MEAN你还是要做很多数据的同步,数据通信,前端后端的API的设计。Meteor在一个框架里面实现了前端后端的开发同步开发。具体来讲就是数据库中的数据发生任何变化的时候,用Meteor搭建的app是不需要人为参与就能实现前端页面更新。这在任何其他的framework里面是不可能实现的,你基本都要通过API来实现前后端信息的同步。Meteor采取的解决方案是在前端也建立一个数据库,叫做miniMango。它是跑在memory里面,通过DDP自动和后端同步,保持前后端统一。这也就使UI的更新速度非常的快 (这个技术叫做reactive rendering)。当你在前端执行任何操作的时候,你只需要去修改前端这边的数据库,后端数据库更新全部交给Meteor和DDP协议去自动执行。这里另一个好处就是Latency Compensation。不管你的网络多么糟糕,页面的反应速度都像是零延迟一样,因为你和后端没有任何交互。反过来当服务器端数据库里面的数据更新的时候,它会通知所有和它相连的所有前端数据库更新数据。为了防止给前端造成造成储存压力,这个同步机制是建立在data subscription和publication之上的,前端在建立自己的数据库之前要先告诉后端它关心什么数据,以后后端就会只推送和更新那些数据。
人无完人,Meteor当然也不可能是完美的。它也有一些缺点,和它不擅长的事。
- 它不适合做静态页面。因为它高度强调实时,所有的内容都是Javascript动态生成的。
- 它不适合做独立App。全栈技术更注重整体运行效益,对用户交互体验的设计还是有所欠缺的。
- 它不容易继承现有架构。技术上很难将现有的网站构架直接转移到Meteor使用
- 它是一个全栈技术。所以你不能只在局部使用Meteor,不能说只在前端使用
Meteor和精益创业
精益创业的核心思想就是在你有一个想法之后:
1. 快速制作和发布产品;
2. 观测用户的使用过程;
3. 在收集的中发现问题,总结经验;
4. 回到原点,优化你的解决方案。
周而复始,快速迭代,不断重复这个循环,直到你能寻找到最优解。这里就要谈到一个MVP,他不是NBA里面的最有价值球员,它指的是minimal viable product,最小可用的验证版本。一开始你制作的产品不可能是面面俱到。就算你有这个能力,也不应该一开始就包罗万象,把所有的功能都上线。快速迭代的核心理念就是在初期只做最核心的功能,在不断的验证过程中完善你的产品,减少无用的功能,增加有价值的功能。你一开始设计的功能去掉一半再去掉一半可能才是你真正的核心有价值的功能。这种创业模式完全符合Meteor快速精简的特性。
正像之前说的Meteor可能不能用来只做一个独立App或者是复杂的交互网站,但是它能在最短的时间内生成一个可用的版本。量化来讲,Meteor最适合用于制作不超过15个页面的网站。举个例子,现在很多移动端的App都依附于微信做开发,因为通过微信端口的用户倒流,获取用户的成本是最低的。微信所允许的最大页面数量也不过15个。所以这已经完全可以满足MVP的需求。
用Meteor制作这么一个网站基本分4步:
1. 绘制原型图,把想法展示出来;
2. 做出UI框架, 生成Meteor template,做出基本页面;
3. 完成从页面到逻辑的转化,实现功能;
4. 优化data publication和 data subscription。
每个阶段有一个人负责,整个制作过程基本不需要2周。你可以想象在创业初期,如果使用Meteor作为网站构建技术,迭代速度是非常快的。
最后,把Meteor官方给出的7项原则分享给大家作为总结:
1. Data on the Wire. Don’t send HTML over the network. Send data and let the client decide how to render it.
2. One Language. Write both the client and the server parts of your interface in JavaScript.
3. Database Everywhere. Use the same transparent API to access your database from the client or the server.
4. Latency Compensation. On the client, use prefetching and model simulation to make it look like you have a zero-latency connection to the database.
5. Full Stack Reactivity. Make realtime the default. All layers, from database to template, should make an event-driven interface available.
6. Embrace the Ecosystem. Meteor is open source and integrates, rather than replaces, existing open source tools and frameworks. Simplicity Equals Productivity. The best way to make something seem simple is to have it actually be simple. Accomplish this through clean, classically beautiful APIs.