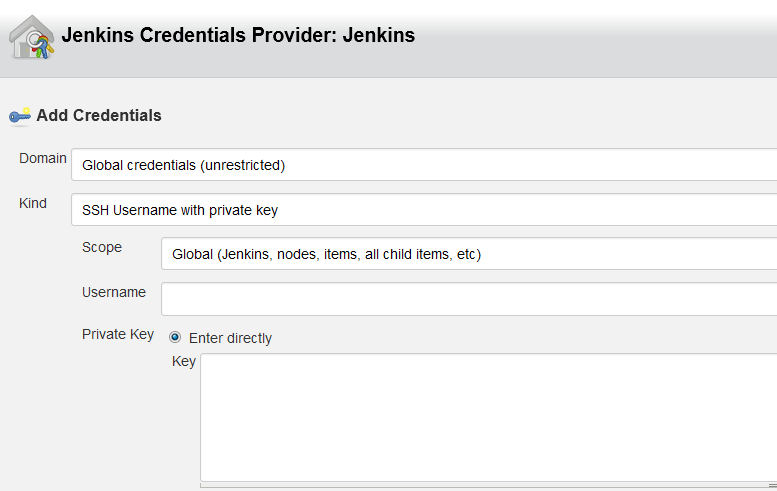
Google Protocol Buffer缺陷
来源: Google Protocol Buffer缺陷 – newzai的个人页面
之所以要列出protobuf的缺陷,就是为了在使用Protobuf的时候可以规避这些缺陷;没有一个工具是十全十美的,我们在使用工具的时候需要扬长避短,因此要对其优点和缺点都有所了解才可以设计出更好的软件系统!!!
1. repeated字段二义性
repeated字段代表传输0~N个数据对象。当传输的数据对象个数大于0时,接收方可以按照覆盖的方式,使用新的数据,替换之前的所有数据。但是,当传输的数据对象个数等于0的时候,接收方如何意会发送方的意图呢?是保留不变还是删除列表?
解决办法:影子字段,为每个repeated type name = i;增加一个include影子字段, optional bool include_name = i+1; 当 include_name 的值为true时,表示需要修改内容,当include_name为false时,接收方忽略name字段。
2. repeated字段冗余
repeated字段每次传输的是一个列表的所有对象的数据。列表的内容改变时,特别是有时候真是新增或者减少几个数据对象时,依旧需要传输整个完整的列表数据。这在数据量比较少的时候不成问题,但是如果列表的成员为成千上万个的时候,恐怕使用单一的repeated字段是无法满足的。在此时最好是repeated字段只传输那些变动的数据对象,例如值传输所有新增的,或者值传输所有被删除的。
解决办法:因此再次最好增加一个枚举和一个字段。
enum RepteateFieldOpType { add = 0; del = 1; replace = 3;}
optional RepteateFieldOpType op_name = i+2 [ default = replace];
3.消息对象冗余
protoc.exe代码生成器生成的消息对象不但引用了protobuf库的基础消息,而且还添加了很多额外的字段。生成的消息类无法直接用在工程的业务逻辑对象中。
因此,需要在工程中,重复定义一套业务对象,数据结构和protobuf 的message对象相当。并且在业务对象和消息对象之间进行数据的赋值。
解决办法:工程中,涉及到和业务逻辑对象相关的消息,最好采用自动化工具从class对象中提取字段,并且映射为消息。并使用工具自动生成class对象和protobuf 消息对象之间的负值,如toMessage和fromeMessage等方法。
4.数据类型单一
普通数据类型单一,可以使用最大化的方式解决。而复杂数据,protobuf只有一种模式,message。对于java,C#语言来说,可以认为是引用。但是对于C++语言来说,是映射为指针对象呢?还是普通的复合对象成员呢?一般情况下可以根据optional或者required来关联。复合对象使用required字段,指针对象使用optional字段。另外repeated代表的是一个列表,repeated message,是值对象的列表还是值引用(指针)的列表,这个也不好区分。 map(字典)也不能直接映射到protobuf.
以C++为例的解决方案:
对于C++ class中的普通数据成员,直接映射为protobuf的相应的数据成员。
对于C++class,映射为一个 message
对于 C++ class中的普通复合成员,直接映射为 required message即可。
对于C++ class中的指针复合成员,直接映射为optional message即可。既然是指针,那么传输的对象如果是整个类,和普通的复合成员也就没有多大的区别。但是如果此类设计到继承时,传输的时候可以只传输基类的内容,使得接收方可以根据基类的相关信息找到业务对象,而不是从新创建一个业务对象。因此还需要为每个指针复合成员定义一个find方法,用于把消息中的值,映射为业务对象。
5.继承问题
C++,Java,C++的类都很少是无父类的,在一个稍微复杂点的系统,业务对象都有自己的继承体系的。而protobuf的message和C的struct一样,是没有结构的概念的。
如何把C++中的继承体系映射到protobufmessage中,可以借鉴一下C的struct的做法。
有1中方式。第一种是分散式的,每个继承的子类都使用一个独立的消息,在消息中的第一个字段为父类的消息,并且名称固定为base。例如
Class A {}; Class B : public {}
message B {
required A base = 1;
…..
}
在多继承模式下,个人无能为力,那位有更好的 !!
另外一种方式是集中式,整个继承体系使用一个独立的类,把所有的子类都封装在一起,使用起来类似于C中的union。
例如
Class A ;
Class B : public A;
class C : public A;
message XX {
required message A a =1;
optional message B b = 2;
optional message C c = 3;
}