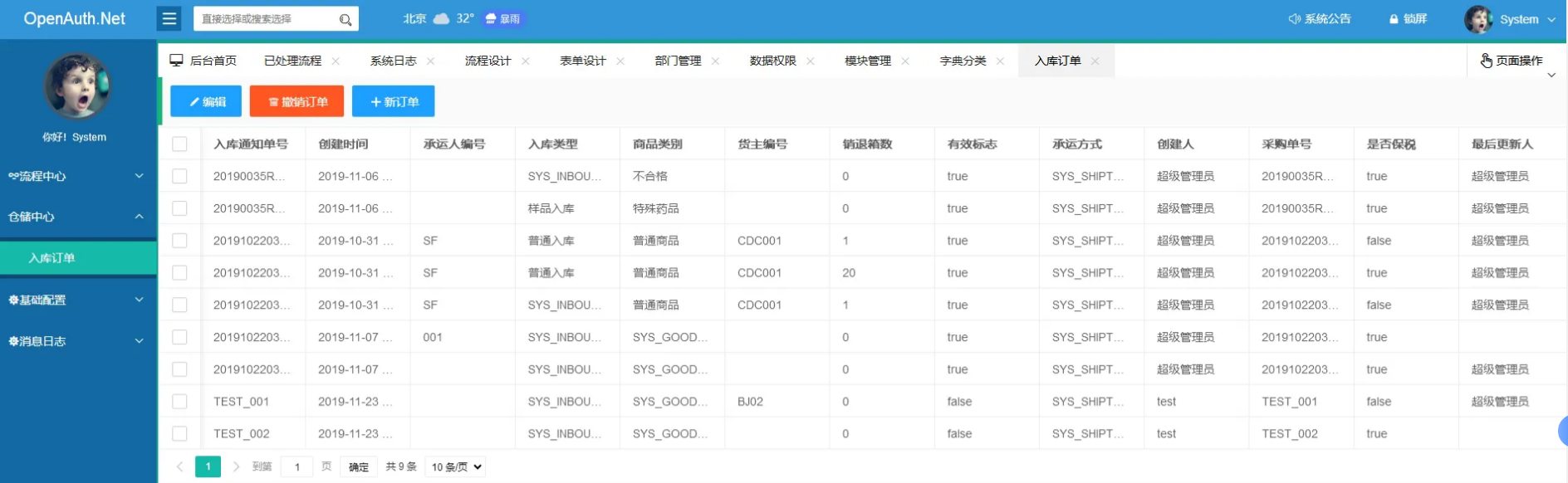
来源: layui实现table添加行功能 table里有select可选择可编辑 并且与form表单一起提交数据保存_layuitable 可编辑,有下拉框和输入框-CSDN博客
这个例子中的下拉框是 可选择 并且 可输入的 还有一个下拉框的点击事件 选择一个值的时候 带出后面几列的值
<%@ page language=”java” import=”java.util.*” pageEncoding=”UTF-8″%>
<%@ include file=”/WEB-INF/page/public/tag.jsp”%>
<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 4.01 Transitional//EN”>
<html>
<head>
<meta charset=”utf-8″>
<title><jsp:include page=”/WEB-INF/page/public/top_title.jsp”/></title>
<meta name=”renderer” content=”webkit”>
<meta http-equiv=”X-UA-Compatible” content=”IE=edge,chrome=1″>
<meta name=”viewport” content=”width=device-width, initial-scale=1, maximum-scale=1″>
<meta name=”apple-mobile-web-app-status-bar-style” content=”black”>
<meta name=”apple-mobile-web-app-capable” content=”yes”>
<meta name=”format-detection” content=”telephone=no”>
<link rel=”stylesheet” href=”${contextPath}/statics/css/layui.css” media=”all”/>
<style>
/* 防止下拉框的下拉列表被隐藏—必须设置— 此样式和表格的样式有冲突 如果表格列数太多 会出现错乱的情况 目前我的解决方法是忽略下拉框的美化渲染 <select lay-ignore> */
.layui-table-cell {
overflow: visible;
}
.layui-table-box {
overflow: visible;
}
.layui-table-body {
overflow: visible;
}
/* 设置下拉框的高度与表格单元相同 */
td .layui-form-select{
margin-top: -10px;
margin-left: -15px;
margin-right: -15px;
}
</style>
</head>
<body class=”childrenBody”>
<div style=”padding:15px;”>
<blockquote class=”layui-elem-quote”>
<span class=”layui-breadcrumb” style=”visibility: visible;”>
<a href=”main.html”>首页</a>
<span lay-separator=””>/</span>
<a href=”${contextPath}/storage/toList”>物料入库</a>
<span lay-separator=””>/</span>
<a><cite>物料入库新增</cite></a> </span>
</blockquote>
<form class=”layui-form” id=”fromId” action=”#”>
<fieldset class=”layui-elem-field”>
<div style=”padding-top:25px;” class=”layui-field-box”>
<div class=”layui-form-item”>
<label class=”layui-form-label”>入库单编号</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”storagecode” placeholder=”请输入” class=”layui-input” lay-verify=”required”>
</div>
<label class=”layui-form-label”>入库人</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”storageuser” placeholder=”请输入” class=”layui-input”>
</div>
<label class=”layui-form-label”>仓库</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”warehouseid” placeholder=”请输入” class=”layui-input”>
</div>
<label class=”layui-form-label”>金额</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”money” placeholder=”请输入” class=”layui-input”>
</div>
</div>
<div class=”layui-form-item”>
<label class=”layui-form-label”>入库日期</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”storagetime” placeholder=”请选择” class=”layui-input” id=”date”>
</div>
<label class=”layui-form-label”>制单人</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”documentmaker” placeholder=”请输入” class=”layui-input”>
</div>
<label class=”layui-form-label”>供应商</label>
<div class=”layui-input-inline” style=”width:13%”>
<input type=”text” name=”supplier” placeholder=”请输入” class=”layui-input”>
</div>
</div>
</div>
</fieldset>
<script type=”text/html” id=”selectTool”>
<select name=”selectDemo” lay-filter=”selectDemo” lay-search>
<option value=””>请选择或输入</option>
{{# layui.each(${selectByExample}, function(index, item){ }}
<option>{{ item.materialcode }}</option>
{{# }); }}
</select>
</script>
<script type=”text/html” id=”toolbarDemo”>
<div align=”right” class=”layui-btn-container”>
<button id=”addTable” class=”layui-btn layui-btn-sm layui-btn-normal” lay-event=”add”>添加行</button>
</div>
</script>
<script type=”text/html” id=”bar”>
<a class=”layui-btn layui-btn-danger layui-btn-xs” lay-event=”del”>删除</a>
</script>
<table id=”demo” lay-filter=”tableFilter”></table>
<div class=”layui-form-item” style=”margin-top: 30px;text-align: center;”>
<button class=”layui-btn” lay-submit=”” lay-filter=”*”>保存</button>
<a href=”${contextPath}/storage/toList” class=”layui-btn layui-btn-primary”>返回</a>
</div>
</form>
</div>
<script type=”text/
JavaScript” src=”${contextPath}/statics/layui.js”></script>
<script>
layui.use([‘laydate’,’table’,’form’,’
JQuery’], function(){
var table = layui.table,
form = layui.form,
laydate = layui.laydate,
//时间控件
laydate.render({
elem: ‘#date’ //指定元素
});
//下拉框监听事件
form.on(‘select(selectDemo)’, function(data){
//这里是当选择一个下拉选项的时候 把选择的值赋值给表格的当前行的缓存数据 否则提交到后台的时候下拉框的值是空的
var elem = data.othis.parents(‘tr’);
var dataindex = elem.attr(“data-index”);
$.each(tabledata,function(index,value){
if(value.LAY_TABLE_INDEX==dataindex){
value.materialcode = data.value;
}
});
//这个是根据下拉框选的值 查询后台 带出后面几列的数据并赋值给页面 没有需要的同学忽略掉即可
if(data.value){ $.ajax({
url:”${contextPath}/storage/toSelect”,
async:true,
type:”post”,
data:{“materialcode”:data.value},
success:function(data){
if(typeof(data) == ‘string’){
data = JSON.parse(data)
}
//给页面赋值
elem.find(“td[data-field=’materialname’]”).children().html(data.data.materialname);
elem.find(“td[data-field=’specifications’]”).children().html(data.data.specifications);
elem.find(“td[data-field=’warehouseid’]”).children().html(data.data.warehouseid);
elem.find(“td[data-field=’warningnumber’]”).children().html(data.data.warningnumber);
elem.find(“td[data-field=’topwarning’]”).children().html(data.data.topwarning);
elem.find(“td[data-field=’unitprice’]”).children().html(data.data.unitprice);
//给表格缓存赋值
$.each(tabledata,function(index,value){
if(value.LAY_TABLE_INDEX==dataindex){
value.materialname = data.data.materialname;
value.specifications = data.data.specifications;
value.warehouseid = data.data.warehouseid
value.warningnumber = data.data.warningnumber;
value.topwarning = data.data.topwarning
value.unitprice = data.data.unitprice;
}
});
}
});
}
});
//第一个实例 加载表格
var tableIns = table.render({
elem: ‘#demo’
,toolbar: ‘#toolbarDemo’
,defaultToolbar:[]
,limit:100
,cols: [[ //表头
{field: ‘materialcode’, title: ‘物料编号’,templet: ‘#selectTool’}
,{field: ‘materialname’, title: ‘物料名称’,edit: ‘text’}
,{field: ‘number’, title: ‘数量’,edit: ‘text’}
,{field: ‘specifications’, title: ‘规格’,edit: ‘text’}
,{field: ‘warehouseid’, title: ‘仓库’,edit: ‘text’}
,{field: ‘warningnumber’, title: ‘最低库存’,edit: ‘text’}
,{field: ‘topwarning’, title: ‘最高库存’,edit: ‘text’}
,{field: ‘unitprice’, title: ‘单价’,edit: ‘text’}
,{field: ‘subtotal’, title: ‘小计’}
,{title: ‘操作’,align:’center’, toolbar: ‘#bar’}
]]
,data:[{ “materialcode”: “”
,”materialname”: “”
,”number”: “”
,”specifications”: “”
,”warehouseid”: “”
,”warningnumber”: “”
,”topwarning”: “”
,”unitprice”: “”
,”subtotal”: “”
}]
,done: function(res, curr, count){
//如果是异步请求数据方式,res即为你接口返回的信息。
//如果是直接赋值的方式,res即为:{data: [], count: 99} data为当前页数据、count为数据总长度
tabledata = res.data;
//去掉下拉框的失焦事件 否则在下拉框里输入值 失焦后变回下拉选项里的值了 没有需要的同学忽略掉即可
$(‘.layui-form-select’).find(‘input’).unbind(“blur”);
//这里是表格重载的时候 回显下拉框的数据
$(‘tr’).each(function(e){
var $cr=$(this);
var dataindex = $cr.attr(“data-index”);
$.each(tabledata,function(index,value){
if(value.LAY_TABLE_INDEX==dataindex){
$cr.find(‘input’).val(value.materialcode);
}
});
});
//这里是下拉框输入值改变时触发 给表格缓存赋值 没有需要的同学忽略掉即可
$(‘.layui-form-select’).find(‘input’).on(“change”,function(e){
var $cr=$(e.target);
console.log($cr);
var dataindex = $cr.parents(‘tr’).attr(“data-index”);
var selectdata = $cr.val();
$.each(tabledata,function(index,value){
if(value.LAY_TABLE_INDEX==dataindex){
value.materialcode = selectdata;
}
});
});
//这里是数量的输入事件 计算小计用的 小计 = 数量 X 单价
var numberelem = $(‘.layui-table-main’).find(“td[data-field=’number’]”);
var unitpriceelem = $(‘.layui-table-main’).find(“td[data-field=’unitprice’]”);
numberelem.on(“input”,function(e){
var $cr=$(e.target);
var dataindex = $cr.parents(‘tr’).attr(“data-index”);
var unitprice = $cr.parents(‘tr’).find(“td[data-field=’unitprice’]”).children().html();
var sub = unitprice*e.target.value;
$cr.parents(‘tr’).find(“td[data-field=’subtotal’]”).children().html(sub);
$.each(tabledata,function(index,value){
if(value.LAY_TABLE_INDEX==dataindex){
value.subtotal = sub;
}
});
});
//这里是单价的输入事件 计算小计用的 小计 = 数量 X 单价
unitpriceelem.on(“input”,function(e){
var $cr=$(e.target);
var dataindex = $cr.parents(‘tr’).attr(“data-index”);
var number = $cr.parents(‘tr’).find(“td[data-field=’number’]”).children().html();
var sub = number*e.target.value;
$cr.parents(‘tr’).find(“td[data-field=’subtotal’]”).children().html(sub);
$.each(tabledata,function(index,value){
if(value.LAY_TABLE_INDEX==dataindex){
value.subtotal = sub;
}
});
});
}
});
var tabledata;
//监听工具条删除按钮
table.on(‘tool(tableFilter)’, function(obj){
if(obj.event === ‘del’){
obj.del();
};
}
);
//头工具栏添加按钮事件
table.on(‘toolbar(tableFilter)’, function(obj){
if(obj.event === ‘add’){
tabledata.push({
“materialcode”: “”
,”materialname”: “”
,”number”: “”
,”specifications”: “”
,”warehouseid”: “”
,”warningnumber”: “”
,”topwarning”: “”
,”unitprice”: “”
,”subtotal”: “”
})
table.reload(‘demo’, {
data: tabledata
});
};
});
//提交数据到后台保存
form.on(‘submit(*)’, function(data){
// console.log(data.elem) //被执行事件的元素DOM对象,一般为button对象
// console.log(data.form) //被执行提交的form对象,一般在存在form标签时才会返回
// console.log(data.field) //当前容器的全部表单字段,名值对形式:{name: value}
// console.log(tabledata) //当前容器的全部表单字段,名值对形式:{name: value}
$.ajax({
url:”${contextPath}/storage/toSave”,
async:true,
type:”post”,
data:$(data.form).serialize()+’&tabledata=’+JSON.stringify(tabledata),
success:function(data){
if(typeof(data) == ‘string’){
data = JSON.parse(data)
}
if(data.code == 0){
layer.msg(data.msg);
window.location.href=”${contextPath}/storage/toList”;
}else{
layer.msg(data.msg);
}
}
});
return false; //阻止表单跳转。如果需要表单跳转,去掉这段即可。
});
});
</script>
</body>
</html>
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_26814945/article/details/83275765