来源: NET Core 多身份校验与策略模式 – 无昵称老炮儿 – 博客园
背景需求:
系统需要对接到XXX官方的API,但因此官方对接以及管理都十分严格。而本人部门的系统中包含诸多子系统,系统间为了稳定,程序间多数固定Token+特殊验证进行调用,且后期还要提供给其他兄弟部门系统共同调用。
原则上:每套系统都必须单独接入到官方,但官方的接入复杂,还要官方指定机构认证的证书等各种条件,此做法成本较大。
so:
为了解决对接的XXX官方API问题,我们搭建了一套中继系统,顾名思义:就是一套用于请求中转的中继系统。在系统搭建的时,Leader提出要做多套鉴权方案,必须做到 动静结合 身份鉴权。
动静结合:就是动态Token 和 静态固定Token。
动态Token:用于兄弟部门系统或对外访问到此中继系统申请的Token,供后期调用对应API。
固定Token:用于当前部门中的诸多子系统,提供一个超级Token,此Token长期有效,且不会随意更换。
入坑:
因为刚来第一周我就接手了这个项目。项目处于申请账号阶段,即将进入开发。对接的是全英文文档(申请/对接流程/开发API….),文档复杂。当时我的感觉:OMG,这不得跑路?整个项目可谓难度之大。然后因为对内部业务也不熟悉,上手就看了微服务等相关系统代码,注:每套系统之间文档少的可怜,可以说系统无文档状态。
项目移交的时候,Leader之说让我熟悉并逐渐进入开发,让我请教同事。好嘛,请教了同事。同事也是接了前任离职的文档而已,大家都不是很熟悉。于是同事让我启新的项目也是直接对接微服务形式开发,一顿操作猛如虎。
项目开发第二周,已经打出框架模型并对接了部分API。此时,Leader开会问进度,结果来一句:此项目使用独立API方式运行,部署到Docker,不接入公司的微服务架构。好嘛,几天功夫白费了,真是取其糟粕去其精华~,恢复成WebAPI。
技术实现:
因为之前对身份认证鉴权这一块没有做太多的深入了解,Leader工期也在屁股追,就一句话:怎么快怎么来,先上后迭代。好嘛,为了项目方便,同时为了符合动静结合的身份认证鉴权 。于是,我用了 JWT+自定义身份认证 实现了需求。
方案一:多身份认证+中间件模式实现
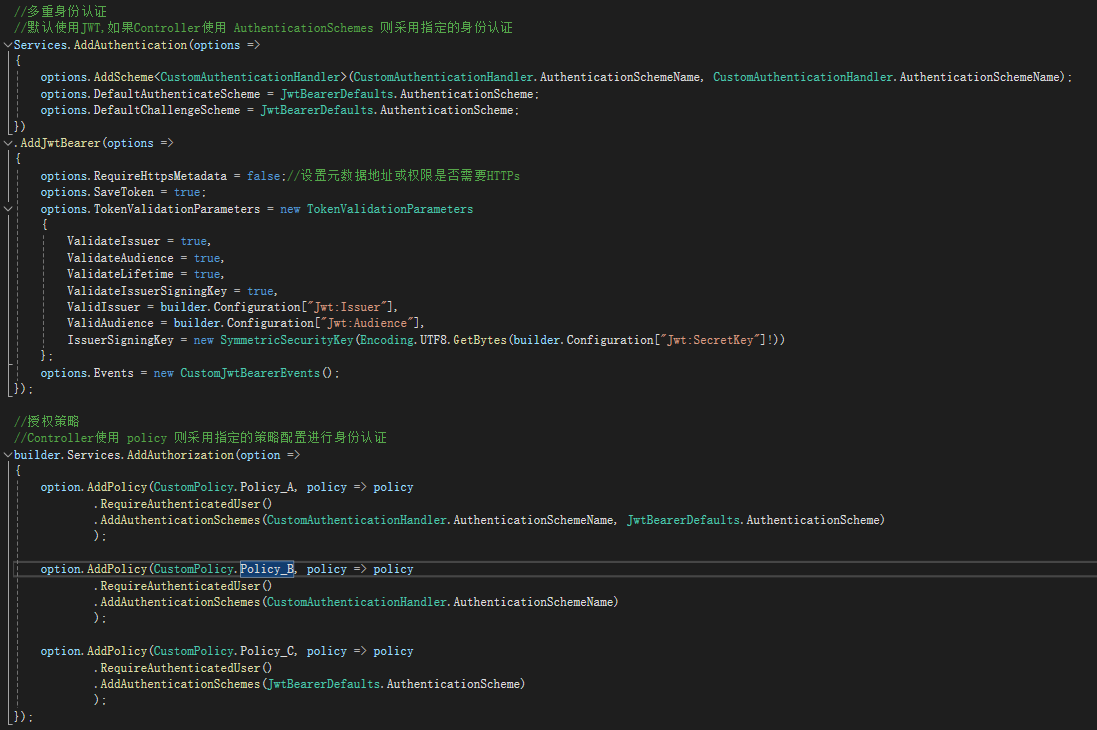
添加服务:Services.AddAuthentication 默认使用JWT
//多重身份认证
//默认使用JWT,如果Controller使用 AuthenticationSchemes 则采用指定的身份认证
Services.AddAuthentication(options =>
{
options.AddScheme<CustomAuthenticationHandler>(CustomAuthenticationHandler.AuthenticationSchemeName, CustomAuthenticationHandler.AuthenticationSchemeName);
options.DefaultAuthenticateScheme = JwtBearerDefaults.AuthenticationScheme;
options.DefaultChallengeScheme = JwtBearerDefaults.AuthenticationScheme;
})
.AddJwtBearer(options =>
{
options.RequireHttpsMetadata = false;//设置元数据地址或权限是否需要HTTPs
options.SaveToken = true;
options.TokenValidationParameters = new TokenValidationParameters
{
ValidateIssuer = true,
ValidateAudience = true,
ValidateLifetime = true,
ValidateIssuerSigningKey = true,
ValidIssuer = builder.Configuration["Jwt:Issuer"],
ValidAudience = builder.Configuration["Jwt:Audience"],
IssuerSigningKey = new SymmetricSecurityKey(Encoding.UTF8.GetBytes(builder.Configuration["Jwt:SecretKey"]!))
};
options.Events = new CustomJwtBearerEvents();
});自定义身份认证 CustomAuthenticationHandler.cs代码
public class CustomAuthenticationHandler : AuthenticationHandler<AuthenticationSchemeOptions>
{
public const string AuthenticationSchemeName = "CustomAuthenticationHandler";
private readonly IConfiguration _configuration;
public CustomAuthenticationHandler(
IOptionsMonitor<AuthenticationSchemeOptions> options,
ILoggerFactory logger,
UrlEncoder encoder,
ISystemClock clock,
IConfiguration configuration)
: base(options, logger, encoder, clock)
{
_configuration = configuration;
}
/// <summary>
/// 固定Token认证
/// </summary>
/// <returns></returns>
protected override async Task<AuthenticateResult> HandleAuthenticateAsync()
{
string isAnonymous = Request.Headers["IsAnonymous"].ToString();
if (!string.IsNullOrEmpty(isAnonymous))
{
bool isAuthenticated = Convert.ToBoolean(isAnonymous);
if (isAuthenticated)
return AuthenticateResult.NoResult();
}
string authorization = Request.Headers["Authorization"].ToString();
// "Bearer " --> Bearer后面跟一个空格
string token = authorization.StartsWith("Bearer ") ? authorization.Remove(0, "Bearer ".Length) : authorization;
if (string.IsNullOrEmpty(token))
return AuthenticateResult.Fail("请求头Authorization不允许为空。");
//通过密钥,进行加密、解密对比认证
if (!VerifyAuthorization(token))
return AuthenticateResult.Fail("传入的Authorization身份验证失败。");
return AuthenticateResult.Success(GetTicket());
}
private AuthenticationTicket GetTicket()
{
// 验证成功,创建身份验证票据
var claims = new[]
{
new Claim(ClaimTypes.Role, "Admin"),
new Claim(ClaimTypes.Role, "Public"),
};
var identity = new ClaimsIdentity(claims, Scheme.Name);
var principal = new ClaimsPrincipal(identity);
var ticket = new AuthenticationTicket(principal, new AuthenticationProperties(), this.Scheme.Name);
return ticket;
}
private bool VerifyAuthorization(string token)
{
//token: [0]随机生成64位字符串,[1]载荷数据,[2]采用Hash对[0]+[1]的签名
var tokenArr = token.Split('.');
if (tokenArr.Length != 3)
{
return false;
}
try
{
//1、先比对签名串是否一致
string signature = tokenArr[1].Hmacsha256HashEncrypt().ToLower();
if (!signature.Equals(tokenArr[2].ToLower()))
{
return false;
}
//解密
var aecStr = tokenArr[1].Base64ToString();
var clientId = aecStr.DecryptAES();
//2、再验证载荷数据的有效性
var clientList = _configuration.GetSection("FixedClient").Get<List<FixedClientSet>>();
var clientData = clientList.SingleOrDefault(it => it.ClientID.Equals(clientId));
if (clientData == null)
{
return false;
}
}
catch (Exception)
{
throw;
}
return true;
}
}使用中间件:UseMiddleware
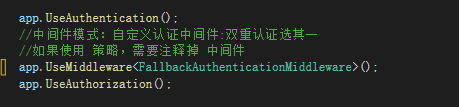
app.UseAuthentication();
//中间件模式:自定义认证中间件:双重认证选其一
//如果使用 策略,需要注释掉 中间件
app.UseMiddleware<FallbackAuthenticationMiddleware>(); //使用中间件实现
app.UseAuthorization();中间件FallbackAuthenticationMiddleware.cs代码实现
public class FallbackAuthenticationMiddleware
{
private readonly RequestDelegate _next;
private readonly IAuthenticationSchemeProvider _schemeProvider;
public FallbackAuthenticationMiddleware(RequestDelegate next, IAuthenticationSchemeProvider schemeProvider)
{
_next = next;
_schemeProvider = schemeProvider;
}
/// <summary>
/// 身份认证方案
/// 默认JWT。JWT失败,执行自定义认证
/// </summary>
/// <param name="context"></param>
/// <returns></returns>
public async Task InvokeAsync(HttpContext context)
{
var endpoints = context.GetEndpoint();
if (endpoints == null || !endpoints.Metadata.OfType<IAuthorizeData>().Any() || endpoints.Metadata.OfType<IAllowAnonymous>().Any())
{
await _next(context);
return;
}
//默认JWT。JWT失败,执行自定义认证
var result = await Authenticate_JwtAsync(context);
if (!result.Succeeded)
result = await Authenticate_CustomTokenAsync(context);
// 设置认证票据到HttpContext中
if (result.Succeeded)
context.User = result.Principal;
await _next(context);
}
/// <summary>
/// JWT的认证
/// </summary>
/// <param name="context"></param>
/// <returns></returns>
private async Task<dynamic> Authenticate_JwtAsync(HttpContext context)
{
var verify = context.User?.Identity?.IsAuthenticated ?? false;
string authenticationType = context.User.Identity.AuthenticationType;
if (verify && authenticationType != null)
{
return new { Succeeded = verify, Principal = context.User, Message = "" };
}
await Task.CompletedTask;
// 找不到JWT身份验证方案,或者无法获取处理程序。
return new { Succeeded = false, Principal = new ClaimsPrincipal { }, Message = "JWT authentication scheme not found or handler could not be obtained." };
}
/// <summary>
/// 自定义认证
/// </summary>
/// <param name="context"></param>
/// <returns></returns>
private async Task<dynamic> Authenticate_CustomTokenAsync(HttpContext context)
{
// 自定义认证方案的名称
var customScheme = "CustomAuthenticationHandler";
var fixedTokenHandler = await context.RequestServices.GetRequiredService<IAuthenticationHandlerProvider>().GetHandlerAsync(context, customScheme);
if (fixedTokenHandler != null)
{
var Res = await fixedTokenHandler.AuthenticateAsync();
return new { Res.Succeeded, Res.Principal, Res.Failure?.Message };
}
//找不到CustomAuthenticationHandler身份验证方案,或者无法获取处理程序。
return new { Succeeded = false, Principal = new ClaimsPrincipal { }, Message = "CustomAuthenticationHandler authentication scheme not found or handler could not be obtained." };
}
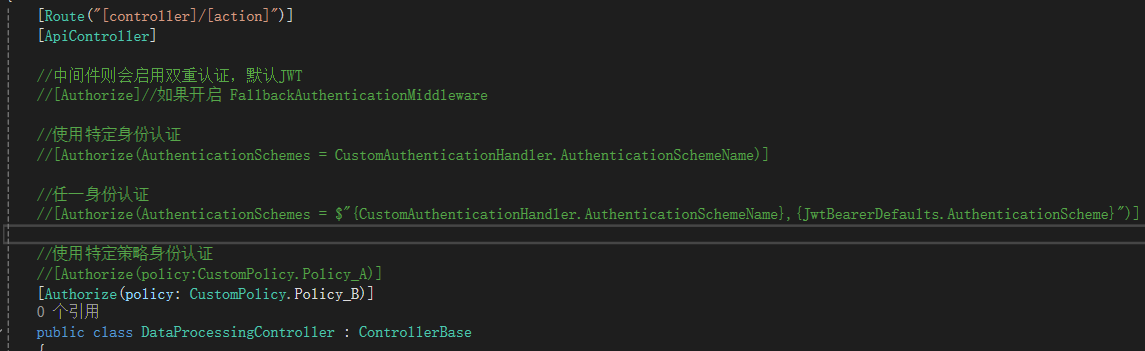
}方案二:通过[Authorize]标签的AuthenticationSchemes
因为中间件还要多维护一段中间件的代码,显得略微复杂,于是通过[Authorize(AuthenticationSchemes = “”)]方式。
//使用特定身份认证
//[Authorize(AuthenticationSchemes = CustomAuthenticationHandler.AuthenticationSchemeName)]
//任一身份认证
[Authorize(AuthenticationSchemes = $"{CustomAuthenticationHandler.AuthenticationSchemeName},{JwtBearerDefaults.AuthenticationScheme}")]
public class DataProcessingController : ControllerBase
{
}方案二:通过[Authorize]标签的policy
如果还有其他身份认证,那不断增加AuthenticationSchemes拼接在Controller的头顶,显得不太好看,且要是多个Controller使用,也会导致维护麻烦,于是改用策略方式。
在Program.cs添加服务AddAuthorization。使用策略的好处是增加易维护性。
//授权策略
//Controller使用 policy 则采用指定的策略配置进行身份认证
builder.Services.AddAuthorization(option =>
{
option.AddPolicy(CustomPolicy.Policy_A, policy => policy
.RequireAuthenticatedUser()
.AddAuthenticationSchemes(CustomAuthenticationHandler.AuthenticationSchemeName, JwtBearerDefaults.AuthenticationScheme)
);
option.AddPolicy(CustomPolicy.Policy_B, policy => policy
.RequireAuthenticatedUser()
.AddAuthenticationSchemes(CustomAuthenticationHandler.AuthenticationSchemeName)
);
option.AddPolicy(CustomPolicy.Policy_C, policy => policy
.RequireAuthenticatedUser()
.AddAuthenticationSchemes(JwtBearerDefaults.AuthenticationScheme)
);
}); //使用特定策略身份认证
[Authorize(policy:CustomPolicy.Policy_B)]
public class DataProcessingController : ControllerBase
{
} /// <summary>
/// 策略类
/// </summary>
public static class CustomPolicy
{
public const string Policy_A= "Policy_A";
public const string Policy_B = "Policy_B";
public const string Policy_C = "Policy_C";
}最后附上截图:
添加服务:
使用中间件:
控制器:
这样,整套中继系统就能完美的满足Leader的需求,且达到预期效果。
源码Demo:https://gitee.com/LaoPaoE/project-demo.git
最后附上:
AuthorizeAttribute 同时使用 Policy 和 AuthenticationSchemes 和 Roles 时是怎么鉴权的流程:
- AuthenticationSchemes鉴权:
- AuthenticationSchemes 属性指定了用于验证用户身份的认证方案(如Cookies、Bearer Tokens等)。
- ASP.NET Core会根据这些认证方案对用户进行身份验证。如果用户未通过身份验证(即未登录或未提供有效的认证信息),则请求会被拒绝,并可能重定向到登录页面。
- Roles鉴权(如果指定了Roles):
- 如果AuthorizeAttribute中还指定了 Roles 属性,那么除了通过身份验证外,用户还必须属于这些角色之一。
- ASP.NET Core会检查用户的角色信息,以确定用户是否属于 Roles 属性中指定的一个或多个角色。
- Policy鉴权(如果指定了Policy):
- Policy 属性指定了一个或多个授权策略,这些策略定义了用户必须满足的额外条件才能访问资源。
- ASP.NET Core会调用相应的 IAuthorizationHandler 来评估用户是否满足该策略中的所有要求。这些要求可以基于角色、声明(Claims)、资源等定义。
- 如果用户不满足策略中的任何要求,则授权失败,并返回一个HTTP 403 Forbidden响应。
鉴权顺序和组合
- 通常,AuthenticationSchemes的验证会首先进行,因为这是访问任何受保护资源的前提。
- 如果AuthenticationSchemes验证通过,接下来会根据是否指定了Roles和Policy来进一步进行鉴权。
- Roles和Policy的鉴权顺序可能因ASP.NET Core的具体版本和配置而异,但一般来说,它们会作为独立的条件进行评估。
- 用户必须同时满足AuthenticationSchemes、Roles(如果指定)和Policy(如果指定)中的所有条件,才能成功访问受保护的资源。
注意事项
- 在某些情况下,即使AuthenticationSchemes和Roles验证都通过,但如果Policy中的要求未得到满足,用户仍然无法访问资源。
- 可以通过自定义 IAuthorizationRequirement 和 IAuthorizationHandler 来实现复杂的授权逻辑,以满足特定的业务需求。
- 确保在应用程序的身份验证和授权配置中正确设置了AuthenticationSchemes、Roles和Policy,以便它们能够协同工作,提供有效的访问控制。